

කාලානුරූපව, යතුරු කට්ටලයක් මඟින් අදාළ දත්ත සෙවීමේ කාර්යය පැන නගී, අපට අවශ්ය මුළු වාර්තා සංඛ්යාව ලැබෙන තුරු.
වඩාත්ම "ජීවමාන" උදාහරණය වන්නේ ප්රදර්ශනය කිරීමයි පැරණිතම ගැටළු 20 ක්, ලැයිස්තුගත කර ඇත සේවකයින්ගේ ලැයිස්තුවේ (උදාහරණයක් ලෙස, එකම දෙපාර්තමේන්තුව තුළ). වැඩ කරන ක්ෂේත්රවල කෙටි සාරාංශ සහිත විවිධ කළමනාකරණ "උපකරණ පුවරු" සඳහා, සමාන මාතෘකාවක් බොහෝ විට අවශ්ය වේ.

ලිපියෙහි, එවැනි ගැටළුවක් විසඳීමේ "බොළඳ" අනුවාදයක්, "බුද්ධිමත්" සහ ඉතා සංකීර්ණ ඇල්ගොරිතමයක් PostgreSQL මත ක්රියාත්මක කිරීම අපි සලකා බලමු. සොයාගත් දත්ත වලින් පිටවීමේ කොන්දේසියක් සහිත SQL හි "ලූප්", එය සාමාන්ය සංවර්ධනය සඳහා සහ වෙනත් සමාන අවස්ථා වලදී භාවිතා කිරීම සඳහා ප්රයෝජනවත් විය හැකිය.
අපි පරීක්ෂණ දත්ත කට්ටලයක් ගනිමු . වර්ග කළ අගයන් ගැළපෙන විට ප්රතිදාන වාර්තා වරින් වර “පැනීම” සිදු නොවන පරිදි, ප්රාථමික යතුරක් එක් කිරීමෙන් විෂය දර්ශකය දිගු කරන්න. ඒ අතරම, මෙය වහාම එයට සුවිශේෂත්වයක් ලබා දෙන අතර, වර්ග කිරීමේ අනුපිළිවෙලෙහි සුවිශේෂත්වය අපට සහතික කරයි:
CREATE INDEX ON task(owner_id, task_date, id);
-- а старый - удалим
DROP INDEX task_owner_id_task_date_idx;එය ඇසෙන පරිදි, එය ලියා ඇත
පළමුව, අපි ඉදිරිපත් කරන්නන්ගේ හැඳුනුම්පත් ලබා දෙමින් ඉල්ලීමේ සරලම අනුවාදය සටහන් කරමු. :
SELECT
*
FROM
task
WHERE
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
ORDER BY
task_date, id
LIMIT 20; 
ටිකක් කණගාටුයි - අපි ඇණවුම් කළේ වාර්තා 20 ක් පමණක් වන අතර, ඉන්ඩෙක්ස් ස්කෑන් අපට ආපසු ලබා දුන්නේය පේළි 960 යි, එයද පසුව වර්ග කිරීමට සිදු විය ... සහ අපි අඩුවෙන් කියවීමට උත්සාහ කරමු.
unnest + ARRAY
අපට උපකාර වන පළමු සලකා බැලීම - අපට අවශ්ය නම් මුළු 20 වර්ග කර ඇත වාර්තා, එය කියවීමට ප්රමාණවත් වේ එක් එක් සඳහා එකම අනුපිළිවෙලට 20 කට වඩා වැඩි නොවේ යතුර. යහපත, සුදුසු දර්ශකය (owner_id, task_date, id) අප සතුව ඇත.
නිස්සාරණය කිරීමේ සහ "තීරු බවට හැරවීමේ" එකම යාන්ත්රණය භාවිතා කරමු. අනුකලිත වගු ප්රවේශය, ලෙස . තවද ශ්රිතය භාවිතා කරමින් array එකකට convolution යොදන්න ARRAY():
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 -- ограничиваем тут...
)) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; -- ... и тут - тоже 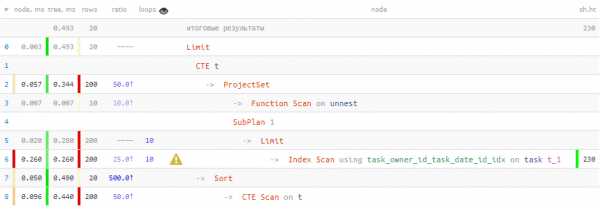
ඔහ්, එය දැනටමත් වඩා හොඳයි! 40% වේගවත් සහ 4.5 ගුණයකින් අඩු දත්ත කියවීමට සිදු විය.
CTE හරහා වගු වාර්තා ද්රව්යකරණයමම එය සටහන් කරමි සමහර අවස්ථාවලදී CTE එකක "එතීමෙන්" තොරව උප විමසුමක සෙවීමෙන් පසු වාර්තා ක්ෂේත්ර සමඟ වහාම වැඩ කිරීමට උත්සාහ කිරීම හේතු විය හැක. "ගුණ කිරීම" InitPlan මෙම ක්ෂේත්ර ගණනට සමානුපාතික වේ:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1)
Buffers: shared hit=16
InitPlan 1 (returns $0)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 2 (returns $1)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 3 (returns $2)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4"
InitPlan 4 (returns $3)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
එකම වාර්තාව 4 වරක් "සෙවුම්" කරන ලදී... PostgreSQL 11 දක්වා, මෙම හැසිරීම නිතිපතා සිදු වන අතර, විසඳුම වන්නේ මෙම අනුවාදවල ප්රශස්තකරණය සඳහා කොන්දේසි විරහිත මායිමක් වන CTE එකක "එතන්න" ය.
පුනරාවර්තන සමුච්චකය
පෙර අනුවාදයේ, සමස්තයක් වශයෙන්, අපි කියවමු පේළි 200 යි අවශ්ය සඳහා 20. දැනටමත් 960 නොවේ, නමුත් ඊටත් වඩා අඩුය - එය කළ හැකිද?
අපට අවශ්ය දැනුම භාවිතා කිරීමට උත්සාහ කරමු මුළු 20 වාර්තා. එනම්, අපට අවශ්ය ප්රමාණයට ළඟා වන තුරු පමණක් අපි දත්ත අඩු කිරීම පුනරාවර්තනය කරන්නෙමු.
පියවර 1: ආරම්භක ලැයිස්තුව
නිසැකවම, අපගේ "ඉලක්ක" ඇතුළත් කිරීම් 20 ලැයිස්තුව අපගේ හිමිකරු_id යතුරු වලින් එකක් සඳහා "පළමු" ඇතුළත් කිරීම් වලින් ආරම්භ විය යුතුය. එමනිසා, අපි මුලින්ම එවැනි දෙයක් සොයා ගනිමු එක් එක් යතුරු සඳහා "ඉතා පළමු" සහ එය ලැයිස්තුවට දමන්න, අපට අවශ්ය අනුපිළිවෙලට එය වර්ග කරන්න - (task_date, id).
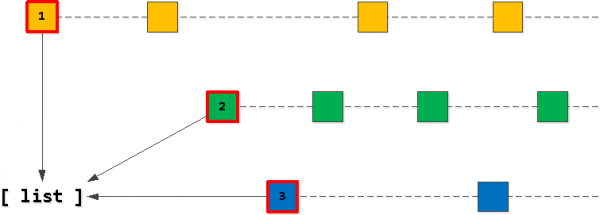
පියවර 2: "ඊළඟ" වාර්තා සොයා ගන්න
දැන් අපි අපේ ලැයිස්තුවෙන් පළමු ඇතුළත් කිරීම ගෙන ආරම්භ කළහොත් "පියවර" තවදුරටත් දර්ශකයේ පහළට හිමිකරු_id-යතුර සුරැකීමත් සමඟ, සොයා ගන්නා ලද සියලුම වාර්තා ප්රතිඵලයක් ලෙස තෝරාගැනීමේ ඊළඟ ඒවා වේ. ඇත්ත වශයෙන්ම, පමණි අපි යොදන ලද යතුර හරස් කරන තුරු ලැයිස්තුවේ දෙවන ප්රවේශය.
අපි දෙවන ප්රවේශය “හරස්” කළ බව පෙනී ගියහොත්, එසේ නම් පළමුවැන්න වෙනුවට අවසාන කියවූ ප්රවේශය ලැයිස්තුවට එක් කළ යුතුය (එකම හිමිකරු_id සමඟ), ඉන්පසු ලැයිස්තුව නැවත අනුපිළිවෙලට සකසනු ලැබේ.
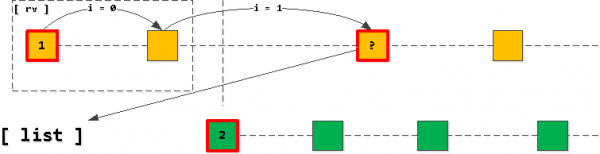
එනම්, ලැයිස්තුවේ එක් එක් යතුරු සඳහා ඇතුළත් කිරීම් එකකට වඩා නොමැති බව අපට සැමවිටම ලැබේ (ඇතුල්වීම් අවසන් වී ඇත්නම් සහ අපි “හරස්” කර නොමැති නම්, පළමු ප්රවේශය ලැයිස්තුවෙන් අතුරුදහන් වන අතර කිසිවක් එකතු නොකෙරේ. ), සහ ඔවුන් සෑම විටම වර්ග කර ඇත යෙදුම් යතුරේ ආරෝහණ අනුපිළිවෙලින් (task_date, id).
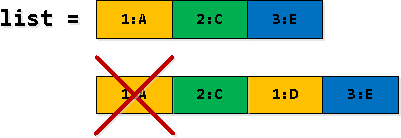
පියවර 3: වාර්තා පෙරීම සහ පුළුල් කිරීම
අපගේ පුනරාවර්තන තේරීමේ පේළි කොටසෙහි, සමහර වාර්තා rv අනුපිටපත් කර ඇත - පළමුව අපි "ලැයිස්තුවේ 2 වන ප්රවේශයේ මායිම තරණය කිරීම" වැනි දේ සොයා ගනිමු, පසුව අපි එය ලැයිස්තුවෙන් 1 වැනි ලෙස ආදේශ කරමු. එබැවින් පළමු සිදුවීම පෙරා දැමිය යුතුය.
භයානක අවසාන විමසුම
WITH RECURSIVE T AS (
-- #1 : заносим в список "первые" записи по каждому из ключей набора
WITH wrap AS ( -- "материализуем" record'ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list -- сортируем список в нужном порядке
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
-- #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го
SELECT
CASE
-- если ничего не найдено для ключа 1-й записи
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] -- убираем ее из списка
-- если мы НЕ пересекли прикладной ключ 2-й записи
WHEN X.not_cross THEN
T.list -- просто протягиваем тот же список без модификаций
-- если в списке уже нет 2-й записи
WHEN T.list[2] IS NULL THEN
-- просто возвращаем пустой список
'{}'
-- пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}')
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( -- "материализуем" record
SELECT
CASE
-- если все-таки "перешагнули" через 2-ю запись
WHEN NOT T.not_cross
-- то нужная запись - первая из спписка
THEN T.list[1]
ELSE ( -- если не пересекли, то ключ остался как в предыдущей записи - отталкиваемся от нее
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
-- если 2-й записи уже нет в списке, но мы хоть что-то нашли
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE -- ничего не нашли или "перешагнули"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND -- ограничиваем тут количество
T.list IS DISTINCT FROM '{}' -- или пока список не кончился
)
-- #3 : "разворачиваем" записи - порядок гарантирован по построению
SELECT
(rv).*
FROM
T
WHERE
not_cross; -- берем только "непересекающие" записи 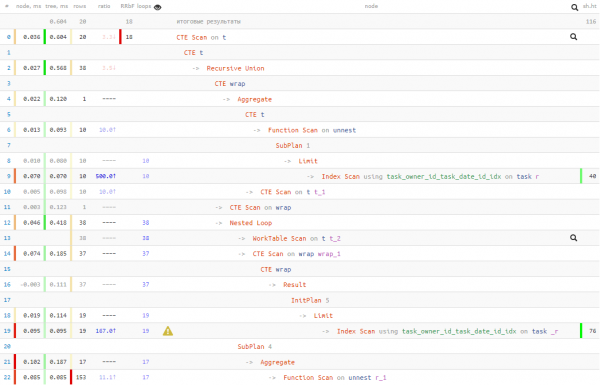
මේ අනුව, අපි 50% ක්රියාත්මක කිරීමේ කාලය සඳහා 20% දත්ත කියවීම් වෙළඳාම් කරන ලදී. එනම්, කියවීම දිගු විය හැකි බව විශ්වාස කිරීමට ඔබට හේතුවක් තිබේ නම් (උදාහරණයක් ලෙස, දත්ත බොහෝ විට හැඹිලියේ නොමැති අතර, ඔබ ඒ සඳහා තැටියට යා යුතුය), එවිට ඔබට අඩු කියවීම මත රඳා පැවතිය හැකිය.
ඕනෑම අවස්ථාවක, ක්රියාත්මක කිරීමේ කාලය "බොළඳ" පළමු විකල්පයට වඩා හොඳ විය. නමුත් මෙම විකල්ප 3න් භාවිතා කරන්නේ කුමක්ද යන්න ඔබට භාරයි.
මූලාශ්රය: www.habr.com
