


Ahojte všetci! Volám sa Dmitrij Samsonov a pracujem ako vedúci systémový administrátor v Odnoklassniki. Máme viac ako 7 000 fyzických serverov, 11 000 kontajnerov v našom cloude a 200 aplikácií, ktoré v rôznych konfiguráciách tvoria 700 rôznych klastrov. Prevažná väčšina serverov beží CentOS 7.
Dňa 14. augusta 2018 bola zverejnená informácia o zraniteľnosti FragmentSmack
() a SegmentSmack (). Ide o zraniteľnosti s vektorom sieťového útoku a pomerne vysokým skóre (7.5), ktoré ohrozuje odmietnutie služby (DoS) z dôvodu vyčerpania zdrojov (CPU). Oprava jadra pre FragmentSmack v tom čase nebola navrhnutá, navyše vyšla oveľa neskôr ako zverejnenie informácií o zraniteľnosti. Na odstránenie SegmentSmack bolo navrhnuté aktualizovať jadro. V ten istý deň vyšiel aj samotný aktualizačný balík, ostávalo ho už len nainštalovať.
Nie, vôbec nie sme proti aktualizácii jadra! Existujú však nuansy...
Ako aktualizujeme jadro pri výrobe
Vo všeobecnosti nie je nič zložité:
- sťahovanie balíkov;
- Nainštalujte ich na množstvo serverov (vrátane serverov hosťujúcich náš cloud);
- Uistite sa, že nič nie je zlomené;
- Uistite sa, že všetky štandardné nastavenia jadra sú použité bez chýb;
- Počkajte niekoľko dní;
- Skontrolujte výkon servera;
- Prepnúť nasadenie nových serverov na nové jadro;
- Aktualizujte všetky servery podľa dátového centra (po jednom dátovom centre, aby sa minimalizoval vplyv na používateľov v prípade problémov);
- Reštartujte všetky servery.
Opakujte pre všetky vetvy jadier, ktoré máme. Momentálne je to:
- Sklad CentOS 7 3.10 - pre väčšinu bežných serverov;
- Vanilka 4.19 - za nas , pretože potrebujeme BFQ, BBR atď.;
- Elrepo kernel-ml 5.2 - pre , pretože 4.19 sa správala nestabilne, ale sú potrebné rovnaké funkcie.
Ako ste možno uhádli, reštartovanie tisícok serverov trvá najdlhšie. Keďže nie všetky zraniteľnosti sú kritické pre všetky servery, reštartujeme iba tie, ktoré sú priamo dostupné z internetu. V cloude, aby sme neobmedzovali flexibilitu, nepripájame externe prístupné kontajnery k jednotlivým serverom s novým jadrom, ale reštartujeme všetkých hostiteľov bez výnimky. Našťastie je tam postup jednoduchší ako pri bežných serveroch. Napríklad kontajnery bez stavu sa môžu počas reštartu jednoducho presunúť na iný server.
Stále je však veľa práce, ktorá môže trvať niekoľko týždňov a v prípade problémov s novou verziou až niekoľko mesiacov. Útočníci tomu veľmi dobre rozumejú, preto potrebujú plán B.
FragmentSmack/SegmentSmack. Alternatívne riešenie
Našťastie pre niektoré zraniteľnosti takýto plán B existuje a nazýva sa Workaround. Najčastejšie ide o zmenu nastavení jadra/aplikácie, ktorá môže minimalizovať možný efekt alebo úplne eliminovať zneužívanie zraniteľností.
V prípade FragmentSmack/SegmentSmack toto riešenie:
«Predvolené hodnoty 4 MB a 3 MB v súboroch net.ipv4.ipfrag_high_thresh a net.ipv4.ipfrag_low_thresh (a ich náprotivky pre ipv6 net.ipv6.ipfrag_high_thresh a net.ipv6.ipfrag_low_thresh) môžete zmeniť na 256 alebo 192 kB nižšie. Testy ukazujú malé až významné poklesy využitia CPU počas útoku v závislosti od hardvéru, nastavení a podmienok. Môže však dôjsť k určitému vplyvu na výkon v dôsledku ipfrag_high_thresh=262144 bajtov, pretože do frontu opätovného zostavenia sa naraz zmestia iba dva fragmenty s veľkosťou 64 kB. Existuje napríklad riziko, že aplikácie, ktoré pracujú s veľkými paketmi UDP, sa pokazia".
Samotné parametre popísané nasledovne:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
Nemáme veľké UDP na produkčné služby. V sieti LAN nie je fragmentovaná prevádzka, vo WAN je fragmentovaná prevádzka, ale nie významná. Neexistujú žiadne známky - môžete zaviesť riešenie!
FragmentSmack/SegmentSmack. Prvá krv
Prvým problémom, na ktorý sme narazili, bolo, že cloudové kontajnery niekedy aplikovali nové nastavenia len čiastočne (iba ipfrag_low_thresh) a niekedy ich nepoužili vôbec – jednoducho sa zrútili na začiatku. Nebolo možné problém stabilne reprodukovať (všetky nastavenia boli bez problémov aplikované manuálne). Pochopenie toho, prečo sa kontajner na začiatku zrúti, tiež nie je také jednoduché: nenašli sa žiadne chyby. Jedna vec bola istá: vrátením nastavení späť sa vyriešil problém s pádmi kontajnerov.
Prečo nestačí aplikovať Sysctl na hostiteľa? Kontajner žije vo vlastnej vyhradenej sieti Namespace, teda aspoň v kontajneri sa môže líšiť od hostiteľa.
Ako presne sa v kontajneri použijú nastavenia Sysctl? Keďže naše kontajnery nie sú privilegované, nebudete môcť zmeniť žiadne nastavenie Sysctl prechodom do samotného kontajnera – jednoducho nemáte dostatok práv. Na spustenie kontajnerov náš cloud v tom čase používal Docker (teraz ). Parametre nového kontajnera boli odovzdané Dockerovi cez API, vrátane potrebných nastavení Sysctl.
Pri prehľadávaní verzií sa ukázalo, že Docker API nevracia všetky chyby (aspoň vo verzii 1.10). Keď sme sa pokúsili spustiť kontajner pomocou „docker run“, konečne sme videli aspoň niečo:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
Hodnota parametra nie je platná. Ale prečo? A prečo to neplatí len niekedy? Ukázalo sa, že Docker negarantuje poradie, v ktorom sa použijú parametre Sysctl (najnovšia testovaná verzia je 1.13.1), takže niekedy sa ipfrag_high_thresh pokúšal nastaviť na 256K, keď bol ipfrag_low_thresh stále 3M, to znamená, že horná hranica bola nižšia ako spodná hranica, čo viedlo k chybe.
V tom čase sme už používali vlastný mechanizmus na rekonfiguráciu kontajnera po spustení (zmrazenie kontajnera po a vykonávanie príkazov v mennom priestore kontajnera cez ), a do tejto časti sme pridali aj zápis parametrov Sysctl. Problém bol vyriešený.
FragmentSmack/SegmentSmack. Prvá krv 2
Predtým, ako sme stihli porozumieť použitiu Workaround v cloude, začali prichádzať prvé zriedkavé sťažnosti od používateľov. V tom čase prešlo niekoľko týždňov od začiatku používania Workaround na prvých serveroch. Počiatočné vyšetrovanie ukázalo, že boli prijaté sťažnosti na jednotlivé služby, a nie na všetky servery týchto služieb. Problém sa opäť stal mimoriadne neistým.
Najprv sme skúsili vrátiť späť nastavenia Sysctl, ale to nemalo žiadny účinok. Rôzne manipulácie s nastaveniami servera a aplikácie tiež nepomohli. Pomohol reštart. Reštart pre Linux rovnako neprirodzené, ako aj normálne podmienky pre prácu s Windows Za starých čias. Fungovalo to však a my sme to pripísali „chybe jadra“ pri aplikácii nových nastavení Sysctl. Akí sme to boli hlúpi...
O tri týždne neskôr sa problém zopakoval. Konfigurácia týchto serverov bola pomerne jednoduchá: Nginx v režime proxy/balancer. Nie je veľká premávka. Nová poznámka na úvod: počet 504 chýb na klientoch sa každým dňom zvyšuje (). Graf zobrazuje počet 504 chýb za deň pre túto službu:
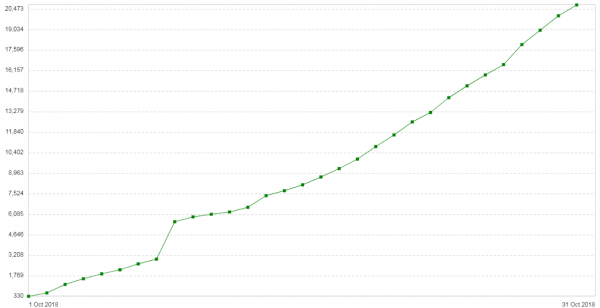
Všetky chyby sú o rovnakom backende – o tom, ktorý je v cloude. Graf spotreby pamäte pre fragmenty balíkov na tomto backende vyzeral takto:
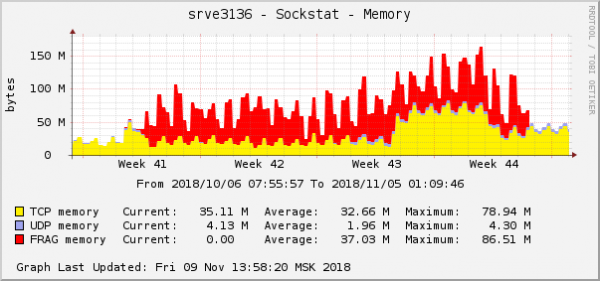
Toto je jeden z najzreteľnejších prejavov problému v grafoch operačného systému. V cloude bol v rovnakom čase opravený ďalší problém so sieťou s nastaveniami QoS (Traffic Control). Na grafe spotreby pamäte pre fragmenty paketov to vyzeralo úplne rovnako:
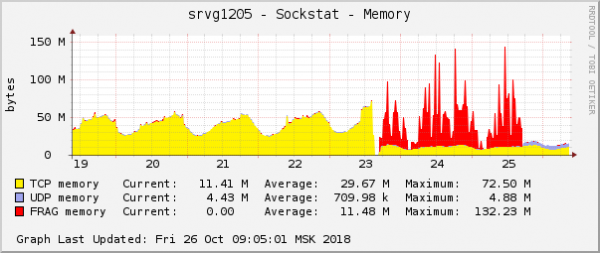
Predpoklad bol jednoduchý: ak vyzerajú na grafoch rovnako, potom majú rovnaký dôvod. Navyše, akékoľvek problémy s týmto typom pamäte sú extrémne zriedkavé.
Podstatou opraveného problému bolo, že sme použili plánovač paketov fq s predvolenými nastaveniami v QoS. V predvolenom nastavení vám na jedno pripojenie umožňuje pridať do frontu 100 paketov a niektoré pripojenia v situáciách nedostatku kanálov začali zahlcovať front. V tomto prípade sú pakety zahodené. V štatistike tc (tc -s qdisc) to možno vidieť takto:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
„464545 flows_plimit“ sú pakety zahodené v dôsledku prekročenia limitu frontu jedného pripojenia a „zahodené 464545“ je súčet všetkých zahodených paketov tohto plánovača. Po zvýšení dĺžky frontu na 1 tisíc a reštartovaní kontajnerov sa problém prestal vyskytovať. Môžete si sadnúť a vypiť smoothie.
FragmentSmack/SegmentSmack. Posledná krv
Po prvé, niekoľko mesiacov po oznámení zraniteľností jadra bola konečne vydaná oprava pre FragmentSmack (pamätajte, že augustové oznámenie vydalo iba opravu pre SegmentSmack), čo nám dalo šancu opustiť Workaround, ktorý nám spôsobil dosť problémov. Počas tohto obdobia sme už migrovali niektoré servery na nové jadro a teraz sme museli začať od začiatku. Prečo sme aktualizovali jadro bez toho, aby sme čakali na opravu FragmentSmack? Faktom je, že proces ochrany pred týmito zraniteľnosťami sa zhodoval (a zlúčil) s procesom aktualizácie samotného Workaroundu. CentOS (čo trvá ešte dlhšie ako aktualizácia samotného jadra). Okrem toho je SegmentSmack nebezpečnejšia zraniteľnosť a jej oprava bola okamžite k dispozícii, takže to aj tak dávalo zmysel. Avšak samotná aktualizácia jadra CentOS nemohli sme kvôli zraniteľnosti FragmentSmack, ktorá sa objavila počas CentOS Verzia 7.5 bola opravená až vo verzii 7.6, takže sme museli zastaviť aktualizáciu na 7.5 a začať odznova s aktualizáciou na 7.6. Aj toto sa stáva.
Po druhé, vrátili sa nám zriedkavé sťažnosti používateľov na problémy. Teraz už s istotou vieme, že všetky súvisia s nahrávaním súborov z klientov na niektoré z našich serverov. Navyše cez tieto servery prešiel veľmi malý počet uploadov z celkového množstva.
Ako si pamätáme z príbehu vyššie, vrátenie Sysctl nepomohlo. Reštart pomohol, ale dočasne.
Podozrenia týkajúce sa Sysctl neboli odstránené, no tentokrát bolo potrebné nazbierať čo najviac informácií. Bol tu tiež obrovský nedostatok schopnosti reprodukovať problém s nahrávaním na klientovi, aby bolo možné presnejšie študovať, čo sa deje.
Analýza všetkých dostupných štatistík a protokolov nás nepriblížila k pochopeniu toho, čo sa deje. Existoval akútny nedostatok schopnosti reprodukovať problém, aby sme „cítili“ špecifické spojenie. Nakoniec sa vývojárom pomocou špeciálnej verzie aplikácie podarilo dosiahnuť stabilnú reprodukciu problémov na testovacom zariadení pri pripojení cez Wi-Fi. To bol prelom vo vyšetrovaní. Klient sa pripojil k Nginxu, ktorý sa pripojil k backendu, ktorým bola naša Java aplikácia.
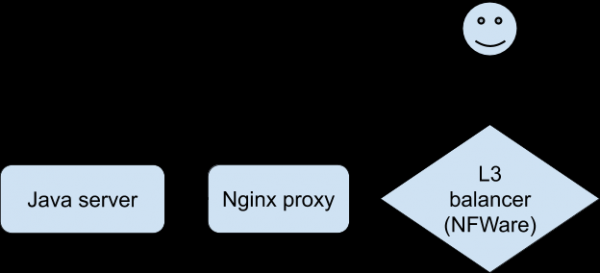
Dialóg o problémoch bol takýto (opravený na strane proxy Nginx):
- Klient: žiadosť o získanie informácií o sťahovaní súboru.
- Java server: odpoveď.
- Klient: POST so súborom.
- Java server: chyba.
Zároveň Java server zapíše do protokolu, že od klienta bolo prijatých 0 bajtov údajov a proxy server Nginx zapíše, že požiadavka trvala viac ako 30 sekúnd (30 sekúnd je časový limit klientskej aplikácie). Prečo časový limit a prečo 0 bajtov? Z pohľadu HTTP všetko funguje ako má, no POST so súborom akoby zo siete zmizol. Okrem toho zmizne medzi klientom a Nginx. Je čas vyzbrojiť sa Tcpdump! Najprv však musíte pochopiť konfiguráciu siete. Nginx proxy stojí za L3 balancerom . Tunelovanie sa používa na doručovanie paketov z balancéra L3 na server, ktorý k paketom pridáva svoje hlavičky:
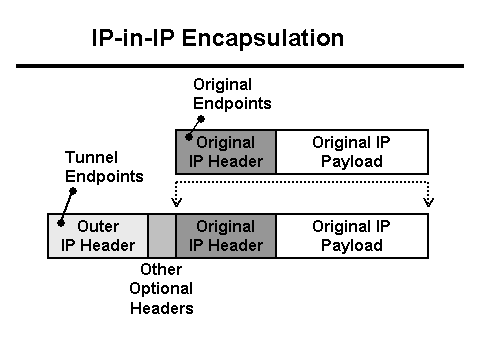
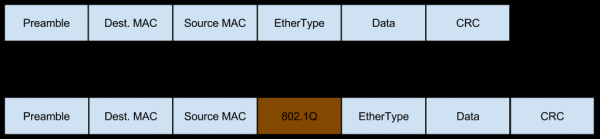
V tomto prípade sieť prichádza na tento server vo forme prevádzky označenej Vlan, ktorá tiež pridáva svoje vlastné polia do paketov:
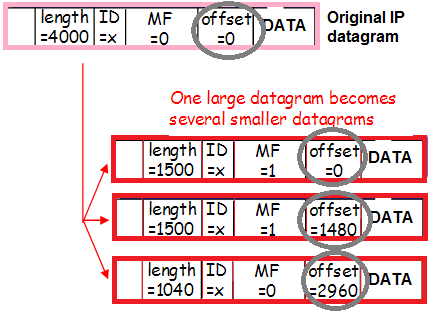
A táto návštevnosť môže byť tiež fragmentovaná (to isté malé percento prichádzajúcej fragmentovanej návštevnosti, o ktorej sme hovorili pri hodnotení rizík z Workaround), čo tiež mení obsah hlavičiek:
Ešte raz: pakety sú zapuzdrené Vlan tagom, zapuzdrené tunelom, fragmentované. Aby sme lepšie pochopili, ako sa to deje, pozrime sa na trasu paketov od klienta k proxy Nginx.
- Paket dosiahne vyvažovač L3. Pre správne smerovanie v rámci dátového centra je paket zapuzdrený v tuneli a odoslaný na sieťovú kartu.
- Keďže hlavičky paketu + tunela sa nezmestia do MTU, paket je rozrezaný na fragmenty a odoslaný do siete.
- Prepínač za L3 balancerom pri príjme paketu k nemu pridá Vlan tag a pošle ho ďalej.
- Prepínač pred serverom proxy Nginx vidí (na základe nastavení portu), že server očakáva paket zapuzdrený Vlan, takže ho odošle tak, ako je, bez odstránenia značky Vlan.
- Linux prijíma fragmenty jednotlivých balíkov a lepí ich do jedného veľkého balíka.
- Ďalej sa paket dostane na rozhranie Vlan, kde sa z neho odstráni prvá vrstva – Vlan encapsulation.
- Potom Linux odošle ho do rozhrania Tunnel, kde sa z neho odstráni ďalšia vrstva – zapuzdrenie tunela.
Problémom je odovzdať toto všetko ako parametre tcpdump.
Začnime od konca: existujú čisté (bez zbytočných hlavičiek) IP pakety od klientov s odstráneným zapuzdrením vlan a tunela?
tcpdump host <ip клиента>
Nie, žiadne takéto balíčky na serveri neboli. Takže problém musí byť skôr. Existujú nejaké pakety s odstráneným iba zapuzdrením Vlan?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx je adresa IP klienta v hexadecimálnom formáte.
32:4 — adresa a dĺžka poľa, v ktorom je zapísaná SCR IP v tunelovom pakete.
Adresa poľa sa musela vybrať hrubou silou, keďže na internete píšu o 40, 44, 50, 54, ale IP adresa tam nebola. Môžete sa tiež pozrieť na jeden z paketov v hex (parameter -xx alebo -XX v tcpdump) a vypočítať IP adresu, ktorú poznáte.
Existujú fragmenty paketov bez odstránenia zapuzdrenia Vlan a tunela?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Táto mágia nám ukáže všetky fragmenty, vrátane toho posledného. Pravdepodobne sa to isté dá filtrovať podľa IP, ale neskúšal som to, pretože takýchto paketov nie je príliš veľa a tie, ktoré som potreboval, sa dali ľahko nájsť vo všeobecnom toku. Tu sú:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 V 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), dĺžka 62: (tos 0x0, ttl 63, id 53652, offset 1480, príznaky [žiadne], proto IPIP (4), dĺžka 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 .............
Ide o dva fragmenty jedného balenia (rovnaké ID 53652) s fotografiou (v prvom balení je viditeľné slovo Exif). Vzhľadom na to, že na tejto úrovni sú balíky, ale nie v zlúčenej podobe na skládkach, problém je jednoznačne s montážou. Konečne o tom existujú listinné dôkazy!
Dekodér paketov neodhalil žiadne problémy, ktoré by bránili zostaveniu. Vyskúšali ste to tu: . Najprv, keď sa tam pokúsite niečo vložiť, dekodér nemá rád formát paketu. Ukázalo sa, že medzi Srcmac a Ethertype boli nejaké ďalšie dva oktety (nesúvisiace s informáciami o fragmentoch). Po ich odstránení začal dekodér fungovať. Neukázala však žiadne problémy.
Čokoľvek sa dá povedať, nič iné sa nenašlo okrem tých Sysctl. Zostávalo len nájsť spôsob, ako identifikovať problémové servery, aby sme pochopili rozsah a rozhodli sa o ďalších krokoch. Požadované počítadlo bolo nájdené dostatočne rýchlo:
netstat -s | grep "packet reassembles failed”
Je tiež v snmpd pod OID=1.3.6.1.2.1.4.31.1.1.16.1 ().
„Počet zlyhaní zistených algoritmom opätovného zostavenia IP (z akéhokoľvek dôvodu: vypršal časový limit, chyby atď.)
V skupine serverov, na ktorých sa problém skúmal, sa na dvoch toto počítadlo zvyšovalo rýchlejšie, na dvoch pomalšie a na dvoch ďalších sa nezvyšovalo vôbec. Porovnanie dynamiky tohto počítadla s dynamikou chýb HTTP na serveri Java odhalilo koreláciu. To znamená, že merač môže byť monitorovaný.
Mať spoľahlivý indikátor problémov je veľmi dôležité, aby ste mohli presne určiť, či vrátenie Sysctl pomáha, pretože z predchádzajúceho príbehu vieme, že to z aplikácie nemožno okamžite pochopiť. Tento indikátor by nám umožnil identifikovať všetky problémové oblasti vo výrobe skôr, ako to používatelia objavia.
Po vrátení Sysctl sa chyby monitorovania zastavili, čím sa dokázala príčina problémov, ako aj to, že rollback pomáha.
Vrátili sme späť nastavenia fragmentácie na iných serveroch, kde do hry vstúpilo nové monitorovanie, a niekde sme fragmentom pridelili ešte viac pamäte, ako bolo predtým predvolené (toto bola štatistika UDP, ktorej čiastočná strata nebola na všeobecnom pozadí badateľná) .
Najdôležitejšie otázky
Prečo sú pakety fragmentované na našom vyrovnávacom zariadení L3? Väčšina paketov, ktoré prichádzajú od používateľov k balancérom, sú SYN a ACK. Veľkosti týchto balení sú malé. Ale keďže podiel takýchto paketov je veľmi veľký, na ich pozadí sme si nevšimli prítomnosť veľkých paketov, ktoré sa začali fragmentovať.
Dôvodom bol nefunkčný konfiguračný skript na serveroch s rozhraním Vlan (v tom čase bolo vo výrobe veľmi málo serverov s označenou prevádzkou). Advmss nám umožňuje sprostredkovať klientovi informáciu, že pakety v našom smere by mali mať menšiu veľkosť, aby sa po pripojení hlavičiek tunelov k nim nemuseli fragmentovať.
Prečo vrátenie Sysctl nepomohlo, ale reštart áno? Odvolaním Sysctl sa zmenilo množstvo pamäte dostupnej na zlúčenie balíkov. Zároveň zrejme samotný fakt pretečenia pamäte pre fragmenty viedol k spomaleniu pripojení, čo viedlo k tomu, že fragmenty sa vo fronte dlho oneskorovali. To znamená, že proces prebiehal v cykloch.
Reštart vymazal pamäť a všetko sa vrátilo do poriadku.
Bolo možné zaobísť sa bez riešenia Workaround? Áno, ale existuje vysoké riziko, že používatelia v prípade útoku zostanú bez služby. Samozrejme, že používanie Workaround malo za následok rôzne problémy, vrátane spomalenia jednej zo služieb pre používateľov, no napriek tomu veríme, že kroky boli opodstatnené.
Veľká vďaka Andrey Timofeev () za pomoc pri vedení vyšetrovania, ako aj Alexejovi Krenevovi () - za titánsku prácu aktualizácie Centos a jadrá servera. V tomto prípade sa proces musel niekoľkokrát reštartovať, čo malo za následok, že trval mnoho mesiacov.
Zdroj: hab.com
