

Pozdravujem habr.
Ak niekto zneužíva systém a vyskytol sa problém s výkonom úložiska (IO, spotrebované miesto na disku), potom by šanca, že ClickHouse bol obsadený ako náhrada, mala byť jedna. Toto vyhlásenie naznačuje, že implementácia tretej strany sa už používa napríklad ako démon prijímajúci metriky alebo .
ClickHouse opísané problémy dobre rieši. Napríklad po prenesení 2TiB dát z whisper sa zmestia do 300GiB. Nebudem sa podrobne zaoberať porovnávaním, existuje veľa článkov na túto tému. Navyše donedávna nebolo s naším úložiskom ClickHouse všetko ideálne.
Problémy so spotrebovaným priestorom
Na prvý pohľad by všetko malo fungovať dobre. Sledovanie , vytvorte konfiguráciu pre schému ukladania metrík (ďalej retention), potom vytvorte tabuľku podľa odporúčania vybraného backendu pre graphite-web: + alebo v závislosti od použitého zásobníka. A... časovaná bomba vybuchne.
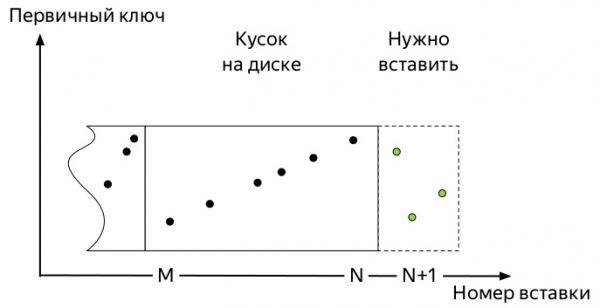
Aby ste pochopili, ktorý z nich, musíte vedieť, ako fungujú vložky a aká je ďalšia životná cesta údajov v tabuľkách motorov rodiny *MergeTree ClickHouse (grafy prevzaté z Alexey Zatelepin):
- Vložené
блокúdajov. V našom prípade to boli metriky, ktoré prišli.

- Každý takýto blok je pred zápisom na disk zoradený podľa kľúča.
ORDER BYšpecifikované pri vytváraní tabuľky. - Po triedení,
кусок(part) údaje sa zapisujú na disk.
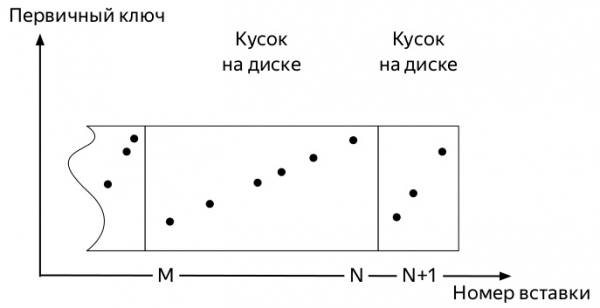
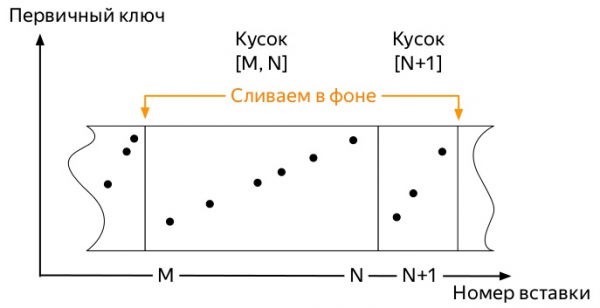
- Server sleduje na pozadí, aby takých kusov nebolo veľa a spúšťa pozadie
слияния(merge, ďalej zlúčiť).
- Server prestane spúšťať zlučovanie, len čo do neho prestanú aktívne prúdiť údaje
партицию(partition), ale proces môžete spustiť manuálne pomocou príkazuOPTIMIZE. - Ak v oddiele zostane iba jeden kus, potom nebudete môcť spustiť zlúčenie pomocou obvyklého príkazu; musíte použiť
OPTIMIZE ... FINAL
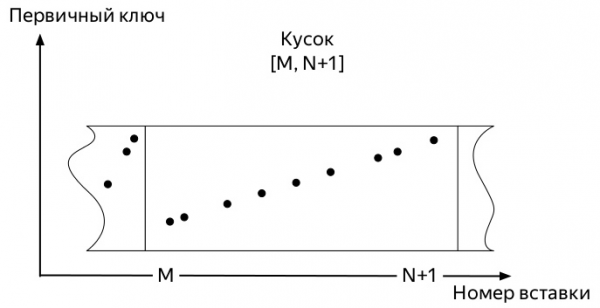
Takže prichádzajú prvé metriky. A zaberajú trochu miesta. Nasledujúce udalosti sa môžu mierne líšiť v závislosti od mnohých faktorov:
- Rozdeľovací kľúč môže byť buď veľmi malý (deň) alebo veľmi veľký (niekoľko mesiacov).
- Konfigurácia uchovávania môže vyhovovať niekoľkým významným prahom agregácie údajov v rámci aktívneho oddielu (kde sa zaznamenávajú metriky), alebo nemusí.
- Ak existuje veľa údajov, potom sa najskoršie časti, ktoré už môžu byť v dôsledku zlučovania na pozadí obrovské (ak zvolíte neoptimálny kľúč na rozdelenie), nezlúčia s čerstvými malými kúskami.
A vždy to skončí rovnako. Priestor, ktorý zaberajú metriky v ClickHouse, sa zväčší iba vtedy, ak:
- neuplatňujú
OPTIMIZE ... FINALručne alebo - nevkladajte údaje do všetkých partícií priebežne, aby sa skôr či neskôr spustilo zlučovanie na pozadí
Druhá metóda sa javí ako najjednoduchšia na implementáciu, a preto je nesprávna a bola vyskúšaná ako prvá.
Napísal som pomerne jednoduchý python skript, ktorý posielal fiktívne metriky pre každý deň za posledné 4 roky a spúšťal cron každú hodinu.
Keďže celá prevádzka ClickHouse DBMS je založená na tom, že tento systém skôr či neskôr vykoná všetku prácu na pozadí, no nevedno kedy, nevedel som sa dočkať momentu, kedy sa staré obrovské kusy rozhodnú začať splývať s nové malé. Bolo jasné, že musíme hľadať spôsob, ako automatizovať nútené optimalizácie.

Informácie v systémových tabuľkách ClickHouse
Poďme sa pozrieť na štruktúru tabuľky . Toto sú komplexné informácie o každej časti všetkých tabuliek na serveri ClickHouse. Obsahuje okrem iného nasledujúce stĺpce:
- názov db (
database); - názov tabuľky (
table); - názov a ID oddielu (
partition&partition_id); - kedy bol diel vytvorený (
modification_time); - minimálny a maximálny dátum v kuse (rozdelenie sa vykonáva podľa dňa) (
min_date&max_date);
K dispozícii je aj stôl , s nasledujúcimi zaujímavými oblasťami:
- názov db (
Tables.database); - názov tabuľky (
Tables.table); - metrický vek, kedy by sa mala použiť ďalšia agregácia (
age);
Takže:
- Máme tabuľku kúskov a tabuľku agregačných pravidiel.
- Skombinujeme ich priesečník a získame všetky tabuľky *GraphiteMergeTree.
- Hľadáme všetky oddiely, v ktorých:
- viac ako jeden kus
- alebo nastal čas na uplatnenie ďalšieho agregačného pravidla a
modification_timestarší ako tento moment.
Реализация
Táto žiadosť
SELECT
concat(p.database, '.', p.table) AS table,
p.partition_id AS partition_id,
p.partition AS partition,
-- Самое "старое" правило, которое может быть применено для
-- партиции, но не в будущем, см (*)
max(g.age) AS age,
-- Количество кусков в партиции
countDistinct(p.name) AS parts,
-- За самую старшую метрику в партиции принимается 00:00:00 следующего дня
toDateTime(max(p.max_date + 1)) AS max_time,
-- Когда партиция должна быть оптимизированна
max_time + age AS rollup_time,
-- Когда самый старый кусок в партиции был обновлён
min(p.modification_time) AS modified_at
FROM system.parts AS p
INNER JOIN
(
-- Все правила для всех таблиц *GraphiteMergeTree
SELECT
Tables.database AS database,
Tables.table AS table,
age
FROM system.graphite_retentions
ARRAY JOIN Tables
GROUP BY
database,
table,
age
) AS g ON
(p.table = g.table)
AND (p.database = g.database)
WHERE
-- Только активные куски
p.active
-- (*) И только строки, где правила аггрегации уже должны быть применены
AND ((toDateTime(p.max_date + 1) + g.age) < now())
GROUP BY
table,
partition
HAVING
-- Только партиции, которые младше момента оптимизации
(modified_at < rollup_time)
-- Или с несколькими кусками
OR (parts > 1)
ORDER BY
table ASC,
partition ASC,
age ASCvráti každý z oddielov tabuľky *GraphiteMergeTree, ktorých zlúčenie by malo uvoľniť miesto na disku. Zostáva už len prejsť ich všetky so žiadosťou OPTIMIZE ... FINAL. Finálna implementácia zohľadňuje aj fakt, že nie je potrebné dotýkať sa priečok s aktívnym záznamom.
To je presne to, čo projekt robí . Bývalí kolegovia z Yandex.Market si to vyskúšali vo výrobe, výsledok práce si môžete pozrieť nižšie.
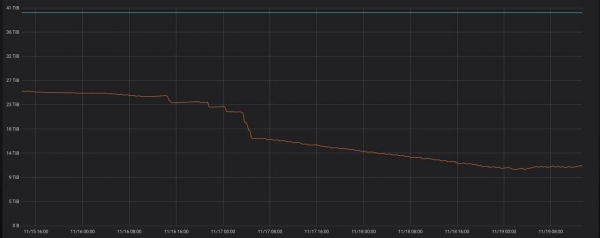
Ak spustíte program na serveri s ClickHouse, jednoducho začne pracovať v režime démona. Raz za hodinu sa vykoná požiadavka, ktorá skontroluje, či sa neobjavili nové oddiely staršie ako tri dni, ktoré je možné optimalizovať.
Naše najbližšie plány sú poskytovať aspoň deb balíčky, a ak je to možné, aj rpm.
namiesto záveru
Za posledných 9+ mesiacov som bol vo svojej spoločnosti strávil veľa času majstrovaním na križovatke ClickHouse a graphite-webu. Bola to dobrá skúsenosť, ktorá viedla k rýchlemu prechodu z šepotu na ClickHouse ako úložisko metrík. Dúfam, že tento článok je niečo ako začiatok série o tom, aké vylepšenia sme urobili v rôznych častiach tohto balíka a čo sa urobí v budúcnosti.
Na vývoj požiadavky sa strávilo niekoľko litrov piva a admin dní spolu s , za čo sa mu chcem poďakovať. A tiež za recenziu tohto článku.
Zdroj: hab.com
