

Pozrieme sa, ako Zabbix pracuje s databázou TimescaleDB ako backendom. Ukážeme vám, ako začať od začiatku a ako migrovať z PostgreSQL. Poskytneme tiež porovnávacie testy výkonu týchto dvoch konfigurácií.

HighLoad++ Siberia 2019. Tomsk Hall. 24. júna, 16:00. Tézy a . Ďalšia konferencia HighLoad++ sa bude konať 6. a 7. apríla 2020 v Petrohrade. Podrobnosti a lístky .
Andrey Gushchin (ďalej len AG): – Som technik technickej podpory ZABBIX (ďalej len „Zabbix“), školiteľ. V technickej podpore pracujem viac ako 6 rokov a mám priamu skúsenosť s výkonom. Dnes budem hovoriť o výkone, ktorý môže TimescaleDB poskytnúť v porovnaní s bežným PostgreSQL 10. Tiež úvodná časť o tom, ako to funguje vo všeobecnosti.
Hlavné výzvy v oblasti produktivity: od zberu údajov po čistenie údajov
Po prvé, existujú určité výkonnostné problémy, ktorým čelí každý monitorovací systém. Prvou výzvou v oblasti produktivity je rýchly zber a spracovanie údajov.

Dobrý monitorovací systém by mal rýchlo, včas prijať všetky údaje, spracovať ich podľa spúšťacích výrazov, teda spracovať ich podľa nejakých kritérií (v rôznych systémoch je to iné) a uložiť do databázy, aby sa tieto údaje mohli použiť v budúcnosti.

Druhou výkonnostnou výzvou je ukladanie histórie. Často ukladajte do databázy a majte rýchly a pohodlný prístup k týmto metrikám, ktoré boli zhromaždené počas určitého časového obdobia. Najdôležitejšie je, že tieto údaje je vhodné získať, použiť v prehľadoch, grafoch, spúšťačoch, v niektorých prahových hodnotách, pre upozornenia atď.

Treťou výkonnostnou výzvou je vyčistenie histórie, teda keď sa dostanete do bodu, kedy nepotrebujete ukladať žiadne podrobné metriky, ktoré sa zbierali počas 5 rokov (aj mesiacov alebo dvoch mesiacov). Niektoré uzly siete boli odstránené alebo niektorí hostitelia, metriky už nie sú potrebné, pretože sú už zastarané a už sa nezbierajú. Toto všetko je potrebné vyčistiť, aby sa vaša databáza príliš nezväčšila. Vo všeobecnosti je vymazanie histórie najčastejšie vážnym testom pre úložisko – často výrazne ovplyvňuje výkon.
Ako vyriešiť problémy s vyrovnávacou pamäťou?
Teraz budem hovoriť konkrétne o Zabbixovi. V Zabbixe sa prvé a druhé volanie rieši pomocou vyrovnávacej pamäte.

Zber a spracovanie údajov – Na ukladanie všetkých týchto údajov používame pamäť RAM. Tieto údaje budú teraz diskutované podrobnejšie.
Aj na strane databázy je nejaké ukladanie do vyrovnávacej pamäte pre hlavné výbery - pre grafy a iné veci.
Ukladanie do vyrovnávacej pamäte na strane samotného servera Zabbix: máme ConfigurationCache, ValueCache, HistoryCache, TrendsCache. Čo to je?

ConfigurationCache je hlavná vyrovnávacia pamäť, do ktorej ukladáme metriky, hostiteľov, dátové položky, spúšťače; všetko, čo potrebujete na spracovanie predspracovania, zber údajov, od ktorých hostiteľov zbierať, s akou frekvenciou. To všetko je uložené v ConfigurationCache, aby sa nedostalo do databázy a nevytváralo zbytočné dotazy. Po spustení servera túto vyrovnávaciu pamäť aktualizujeme (vytvoríme) a pravidelne aktualizujeme (v závislosti od nastavení konfigurácie).
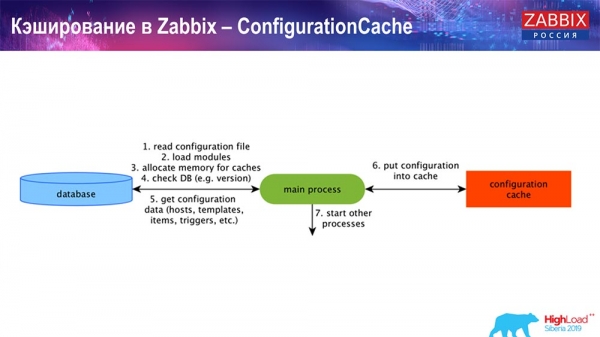
Ukladanie do vyrovnávacej pamäte v Zabbix. Zber dát
Tu je diagram dosť veľký:
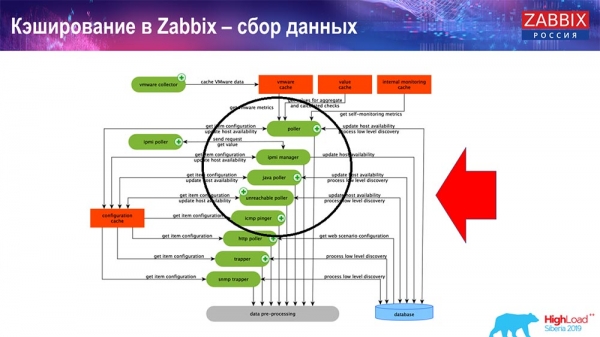
Hlavnými v schéme sú tieto kolektory:
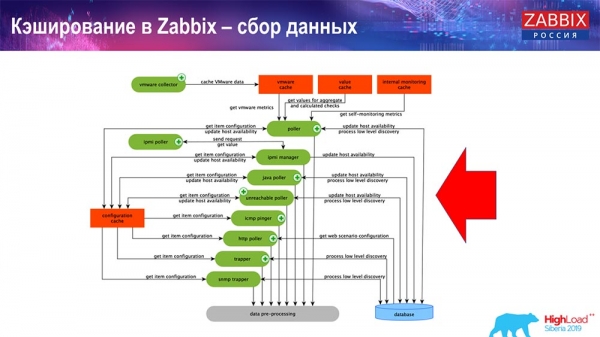
Sú to samotné montážne procesy, rôzne „pollery“, ktoré sú zodpovedné za rôzne typy zostáv. Zhromažďujú údaje cez icmp, ipmi a rôzne protokoly a prenášajú ich do predspracovania.
Preprocessing HistoryCache
Taktiež, ak máme vypočítané dátové prvky (tí, ktorí poznajú Zabbix vedia), teda vypočítané, agregačné dátové prvky, berieme ich priamo z ValueCache. Ako sa to naplní, vám poviem neskôr. Všetky tieto kolektory používajú ConfigurationCache na prijímanie svojich úloh a potom ich odovzdávajú na predbežné spracovanie.
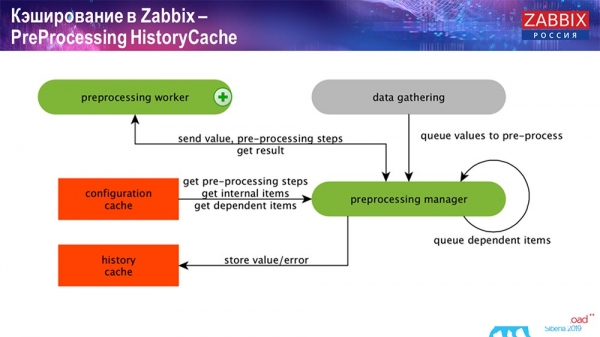
Predspracovanie tiež používa ConfigurationCache na získanie krokov predspracovania a spracováva tieto údaje rôznymi spôsobmi. Od verzie 4.2 sme ho presunuli na server proxy. To je veľmi výhodné, pretože samotné predspracovanie je pomerne náročná operácia. A ak máte veľmi veľký Zabbix s veľkým počtom dátových prvkov a vysokou frekvenciou zberu, potom to značne zjednodušuje prácu.
Preto, keď tieto údaje nejakým spôsobom spracujeme pomocou predbežného spracovania, uložíme ich do HistoryCache, aby sme ich mohli ďalej spracovávať. Týmto je zber údajov ukončený. Prejdeme k hlavnému procesu.
Práca synchronizátora histórie
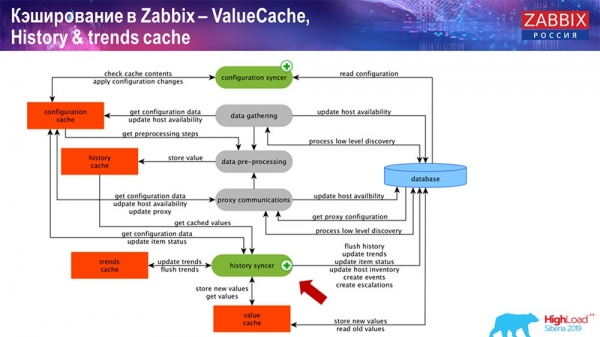
Hlavným procesom v Zabbixe (keďže ide o monolitickú architektúru) je synchronizácia histórie. Toto je hlavný proces, ktorý sa zaoberá špecificky atómovým spracovaním každého dátového prvku, teda každej hodnoty:
- hodnota prichádza (berie ju z HistoryCache);
- skontroluje v Configuration syncer: či existujú nejaké spúšťače pre výpočet - vypočíta ich;
ak existuje - vytvára udalosti, vytvára eskaláciu za účelom vytvorenia výstrahy, ak je to potrebné podľa konfigurácie; - zaznamenáva spúšťače pre následné spracovanie, agregáciu; ak agregujete za poslednú hodinu atď., ValueCache si túto hodnotu zapamätá, aby neprešla do tabuľky histórie; ValueCache je teda naplnená potrebnými údajmi, ktoré sú potrebné na výpočet spúšťačov, vypočítaných prvkov atď.;
- potom History syncer zapíše všetky údaje do databázy;
- databáza ich zapíše na disk – tu sa proces spracovania končí.
Databáza. Ukladanie do vyrovnávacej pamäte
Na strane databázy, keď si chcete pozrieť grafy alebo nejaké reporty o udalostiach, sú rôzne cache. Ale v tejto správe o nich nebudem hovoriť.
Pre MySQL existuje Innodb_buffer_pool a množstvo rôznych vyrovnávacích pamätí, ktoré možno tiež nakonfigurovať.
Ale toto sú hlavné:
- shared_buffers;
- efektívna_veľkosť_cache;
- shared_pool.

Pre všetky databázy som povedal, že existujú určité vyrovnávacie pamäte, ktoré vám umožňujú ukladať do pamäte RAM údaje, ktoré sú často potrebné pre dopyty. Majú na to svoje technológie.
O výkone databázy
V súlade s tým existuje konkurenčné prostredie, to znamená, že server Zabbix zbiera údaje a zaznamenáva ich. Po reštarte tiež načítava z histórie, aby naplnila ValueCache a tak ďalej. Tu môžete mať skripty a zostavy, ktoré používajú Zabbix API, ktoré je postavené na webovom rozhraní. Zabbix API vstupuje do databázy a prijíma potrebné údaje na získanie grafov, správ alebo nejakého zoznamu udalostí, nedávnych problémov.
Veľmi obľúbeným vizualizačným riešením je aj Grafana, ktorú naši užívatelia využívajú. Možnosť priameho prihlásenia cez Zabbix API aj cez databázu. Vytvára to tiež určitú konkurenciu pri získavaní údajov: na dodržanie rýchleho poskytovania výsledkov a testovania je potrebné jemnejšie a lepšie vyladenie databázy.

Vymazáva sa história. Zabbix má gazdinú
Tretí hovor, ktorý sa používa v Zabbix, je vymazanie histórie pomocou Housekeeper. Housekeeper sleduje všetky nastavenia, to znamená, že naše dátové prvky indikujú, ako dlho uchovávať (v dňoch), ako dlho uchovávať trendy a dynamiku zmien.
Nehovoril som o TrendCache, ktorý počítame za chodu: prichádzajú dáta, agregujeme ich za jednu hodinu (väčšinou sú to čísla za poslednú hodinu), množstvo je priemerné/minimálne a zaznamenávame raz za hodinu v tabuľka dynamiky zmien („Trendy“) . „Housekeeper“ spúšťa a odstraňuje údaje z databázy pomocou bežných výberov, čo nie je vždy efektívne.
Ako pochopiť, že je to neúčinné? Na grafoch výkonnosti interných procesov môžete vidieť nasledujúci obrázok:
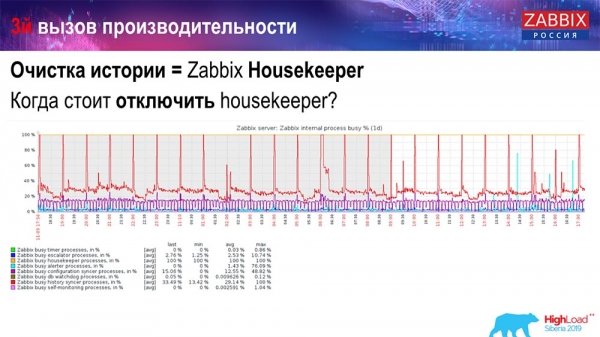
Váš synchronizátor histórie je neustále zaneprázdnený (červený graf). A „červený“ graf, ktorý je navrchu. Toto je „Hospodár“, ktorý sa spustí a čaká, kým databáza vymaže všetky riadky, ktoré zadala.
Zoberme si nejaké ID položky: musíte vymazať posledných 5 tisíc; samozrejme podla indexov. Ale zvyčajne je súbor údajov dosť veľký - databáza ho stále číta z disku a ukladá do vyrovnávacej pamäte, čo je pre databázu veľmi nákladná operácia. V závislosti od jeho veľkosti to môže viesť k určitým problémom s výkonom.
Housekeeper môžete zakázať jednoduchým spôsobom - máme známe webové rozhranie. Nastavenia v Administrácii všeobecne (nastavenia pre “Hospodár”) zakážeme interné vedenie pre internú históriu a trendy. V súlade s tým to už Housekeeper nekontroluje:

Čo môžete urobiť ďalej? Vypli ste to, vaše grafy sa vyrovnali... Aké ďalšie problémy môžu v tomto prípade nastať? Čo môže pomôcť?
Rozdelenie na oddiely
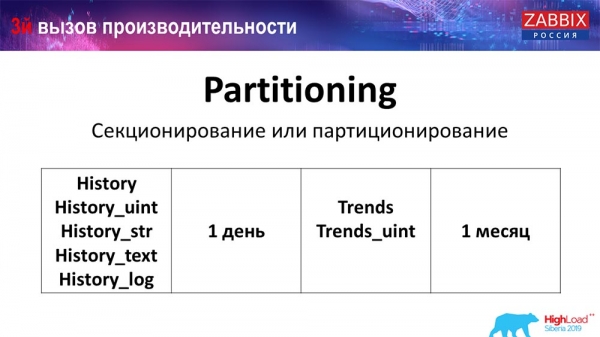
Zvyčajne je to nakonfigurované iným spôsobom v každej relačnej databáze, ktorú som uviedol. MySQL má svoju vlastnú technológiu. Celkovo sú však veľmi podobné, pokiaľ ide o PostgreSQL 10 a MySQL. Samozrejme, existuje veľa vnútorných rozdielov v tom, ako je to všetko implementované a ako to všetko ovplyvňuje výkon. Vo všeobecnosti však vytvorenie nového oddielu často vedie aj k určitým problémom.

V závislosti od vášho nastavenia (koľko údajov vytvoríte za jeden deň) zvyčajne nastavia minimum - to je 1 deň / dávka a pre „trendy“ dynamika zmien - 1 mesiac / nová dávka. Toto sa môže zmeniť, ak máte veľmi veľké nastavenie.
Povedzme hneď o veľkosti nastavenia: až 5 5 nových hodnôt za sekundu (takzvané nvps) - toto sa bude považovať za malé „nastavenie“. Priemer - od 25 do XNUMX tisíc hodnôt za sekundu. Všetko, čo je uvedené vyššie, sú už veľké a veľmi veľké inštalácie, ktoré vyžadujú veľmi starostlivú konfiguráciu databázy.
Pri veľmi veľkých inštaláciách nemusí byť 1 deň optimálny. Osobne som videl oddiely na MySQL s veľkosťou 40 gigabajtov za deň (a môže ich byť viac). Ide o veľmi veľké množstvo údajov, čo môže viesť k určitým problémom. Je potrebné znížiť.
Prečo potrebujete rozdelenie?
Myslím, že každý vie, čo poskytuje rozdelenie na oddiely, je rozdelenie tabuliek. Často sú to samostatné súbory na disku a požiadavky na rozpätie. Optimálne vyberie jeden oddiel, ak je súčasťou bežného rozdelenia.
Najmä pre Zabbix sa používa podľa rozsahu, podľa rozsahu, to znamená, že používame časovú značku (bežné číslo, čas od začiatku epochy). Zadáte začiatok dňa/koniec dňa a toto je oddiel. Ak teda požadujete údaje staré dva dni, všetko sa z databázy získa rýchlejšie, pretože stačí načítať jeden súbor do vyrovnávacej pamäte a vrátiť ho (namiesto veľkej tabuľky).

Mnohé databázy zrýchľujú aj insert (vkladanie do jednej dcérskej tabuľky). Zatiaľ hovorím abstraktne, ale aj toto je možné. Rozdelenie často pomáha.
Elasticsearch pre NoSQL
Nedávno sme vo verzii 3.4 implementovali riešenie NoSQL. Pridaná možnosť písať v Elasticsearch. Môžete písať určité typy: vyberiete si - buď napíšte čísla alebo nejaké znaky; máme reťazcový text, môžete zapisovať protokoly do Elasticsearch... Podľa toho webové rozhranie pristúpi aj k Elasticsearch. V niektorých prípadoch to funguje skvele, ale momentálne sa to dá použiť.

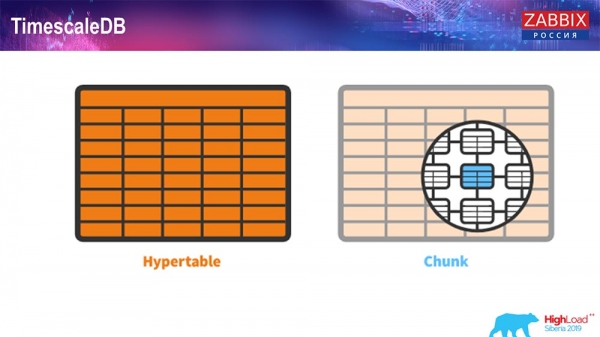
Časová mierkaDB. Hypertabuľky
Pre 4.4.2 sme venovali pozornosť jednej veci, ako je TimescaleDB. Čo to je? Toto je rozšírenie pre PostgreSQL, to znamená, že má natívne rozhranie PostgreSQL. Toto rozšírenie vám navyše umožňuje oveľa efektívnejšie pracovať s údajmi z časových radov a má automatické rozdelenie. Ako to vyzerá:

Toto je hypertable - takýto koncept existuje v Timescale. Toto je hypertabuľka, ktorú vytvoríte a obsahuje kúsky. Kusy sú oddiely, ak sa nemýlim, sú to podradené tabuľky. Je to naozaj účinné.
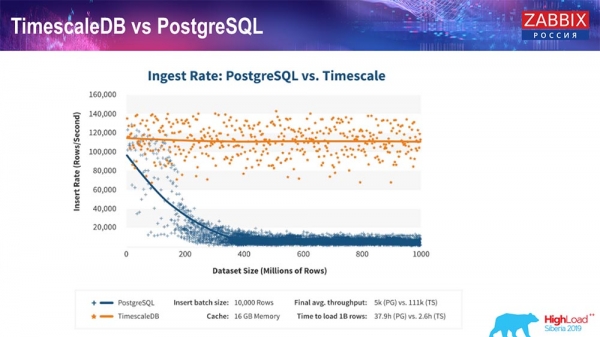
TimescaleDB a PostgreSQL
Ako uisťujú výrobcovia TimescaleDB, na spracovanie dopytov, najmä insertov, používajú presnejší algoritmus, ktorý umožňuje približne konštantný výkon so zväčšujúcou sa veľkosťou insertu datasetu. To znamená, že po 200 miliónoch riadkov Postgres sa bežný začne veľmi prehýbať a stráca výkon doslova na nule, zatiaľ čo Timescale vám umožňuje vkladať vložky čo najefektívnejšie s akýmkoľvek množstvom údajov.
Ako nainštalovať TimescaleDB? Je to jednoduché!
Je to v dokumentácii, je to popísané - môžete si to nainštalovať z balíkov pre ľubovoľné... Závisí to od oficiálnych balíkov Postgres. Dá sa zostaviť ručne. Stalo sa, že som musel zostaviť databázu.
Na Zabbix jednoducho aktivujeme rozšírenie. Myslím, že tí, ktorí používali Extention v Postgrese... Jednoducho si Extention aktivujete, vytvoríte pre databázu Zabbix, ktorú používate.
A posledný krok...
Časová mierkaDB. Migrácia tabuliek histórie
Musíte vytvoriť hypertabuľku. Na to existuje špeciálna funkcia – Create hypertable. V ňom je prvým parametrom tabuľka, ktorá je potrebná v tejto databáze (pre ktorú je potrebné vytvoriť hypertabuľku).

Pole, pomocou ktorého sa má vytvoriť, a chunk_time_interval (toto je interval chunkov (oddielov, ktoré je potrebné použiť). 86 400 je jeden deň.
Parameter Migrate_data: Ak vložíte hodnotu true, potom sa všetky aktuálne údaje migrujú do vopred vytvorených blokov.
Sám som použil migrate_data – trvá to dosť času v závislosti od veľkosti vašej databázy. Mal som vyše terabajtu – jeho vytvorenie trvalo viac ako hodinu. V niektorých prípadoch som počas testovania vymazal historické údaje pre text (history_text) a reťazec (history_str), aby som ich nepreniesol – neboli pre mňa naozaj zaujímavé.
A robíme poslednú aktualizáciu v našom db_extention: inštalujeme timescaledb, aby databáza a najmä náš Zabbix pochopili, že existuje db_extention. Aktivuje ju a používa správnu syntax a dopyty do databázy pomocou tých „funkcií“, ktoré sú potrebné pre TimescaleDB.
Konfigurácia servera
Použil som dva servery. Prvý server je pomerne malý virtuálny stroj, 20 procesorov, 16 gigabajtov RAM. Nakonfiguroval som na ňom Postgres 10.8:

Operačný systém bol Debian, súborový systém – xfs. Urobil som minimálne nastavenia pre použitie konkrétne tejto databázy, okrem toho, čo bude používať samotný Zabbix. Na tomto počítači bol nainštalovaný aj server Zabbix, PostgreSQL a load agenti.

Použil som 50 aktívnych agentov, ktoré používajú LoadableModule na rýchle generovanie rôznych výsledkov. Sú to tí, ktorí generovali reťazce, čísla atď. Databázu som naplnil množstvom údajov. Spočiatku konfigurácia obsahovala 5 XNUMX dátových prvkov na hostiteľa a približne každý dátový prvok obsahoval spúšťač - aby to bolo skutočné nastavenie. Niekedy dokonca potrebujete na použitie viac ako jeden spúšťač.

Interval aktualizácie a samotnú záťaž som reguloval nielen použitím 50 agentov (pridávaním ďalších), ale aj použitím dynamických dátových prvkov a skrátením intervalu aktualizácie na 4 sekundy.
Skúška výkonnosti. PostgreSQL: 36 tisíc NVP
Prvé spustenie, prvé nastavenie, ktoré som mal, bolo na čistom PostreSQL 10 na tomto hardvéri (35 tisíc hodnôt za sekundu). Vo všeobecnosti, ako vidíte na obrazovke, vkladanie údajov trvá zlomky sekundy - všetko je dobré a rýchle, disky SSD (200 gigabajtov). Jediná vec je, že 20 GB sa zaplní pomerne rýchlo.
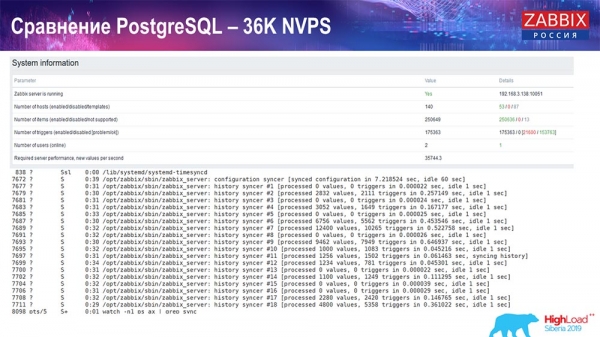
Takýchto grafov bude v budúcnosti pomerne veľa. Toto je štandardný panel výkonu servera Zabbix.
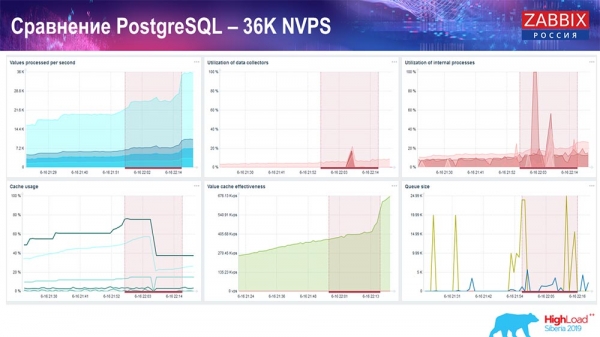
Prvý graf je počet hodnôt za sekundu (modrý, vľavo hore), v tomto prípade 35 tisíc hodnôt. Toto (hore v strede) je načítanie procesov zostavovania a toto (vpravo hore) je načítanie interných procesov: synchronizátorov histórie a housekeepera, ktoré tu (v strede dole) beží už nejaký čas.
Tento graf (v strede dole) zobrazuje využitie ValueCache – koľko ValueCache zasiahne spúšťače (niekoľko tisíc hodnôt za sekundu). Ďalším dôležitým grafom je štvrtý (vľavo dole), ktorý ukazuje využitie HistoryCache, o ktorej som hovoril, čo je buffer pred vložením do databázy.
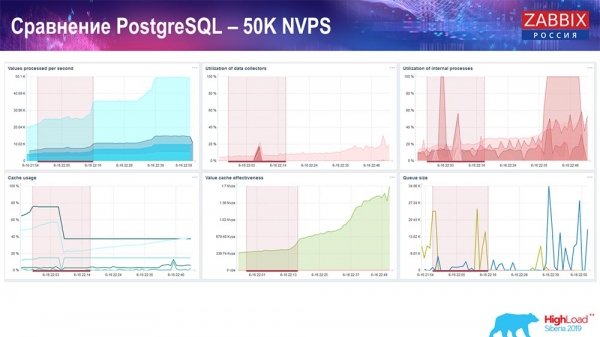
Skúška výkonnosti. PostgreSQL: 50 tisíc NVP
Ďalej som zvýšil zaťaženie na 50 tisíc hodnôt za sekundu na rovnakom hardvéri. Pri načítaní Housekeeperom bolo zaznamenaných 10 2 hodnôt za 3-XNUMX sekundy s výpočtom. Čo je v skutočnosti zobrazené na nasledujúcej snímke obrazovky:
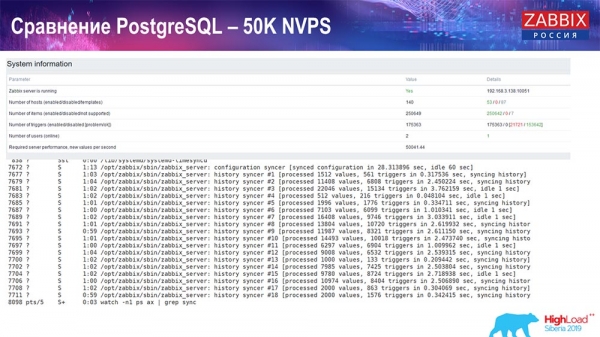
„Housekeeper“ už začína prekážať v práci, ale vo všeobecnosti je zaťaženie lapačov histórie stále na úrovni 60 % (tretí graf vpravo hore). HistoryCache sa už začína aktívne napĺňať, kým Housekeeper beží (vľavo dole). Bola asi pol gigabajtu, plná na 20 %.
Skúška výkonnosti. PostgreSQL: 80 tisíc NVP
Potom som to zvýšil na 80 tisíc hodnôt za sekundu:
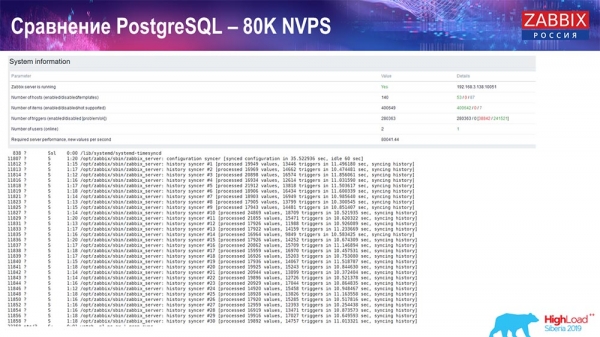
Išlo približne o 400 tisíc dátových prvkov, 280 tisíc spúšťačov. Vložka, ako vidíte, čo sa týka záťaže potápačov histórie (bolo ich 30), bola už dosť vysoká. Potom som zvýšil rôzne parametre: potápače histórie, vyrovnávaciu pamäť... Na tomto hardvéri sa zaťaženie potápačov histórie začalo zvyšovať na maximum, takmer „na polici“ - podľa toho sa HistoryCache dostalo do veľmi vysokej záťaže:
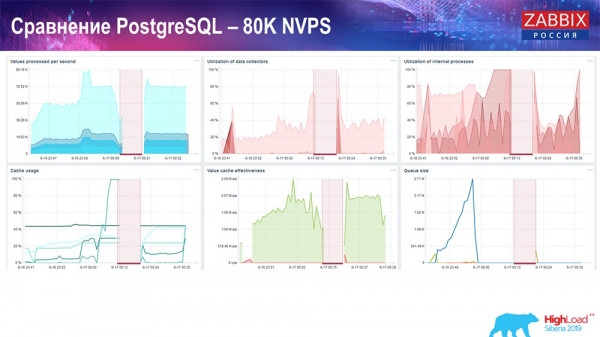
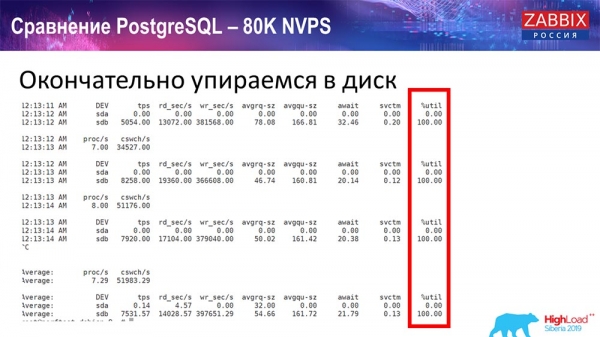
Celý ten čas som sledoval všetky systémové parametre (ako je využívaný procesor, RAM) a zistil som, že vyťaženie disku je maximálne - na tomto hardvéri, na tomto virtuálnom stroji som dosiahol maximálnu kapacitu tohto disku. „Postgres“ začal v takej intenzite dosť aktívne vyhadzovať dáta a disk už nestíhal zapisovať, čítať...
Vzal som si ďalší server, ktorý už mal 48 procesorov a 128 gigabajtov RAM:
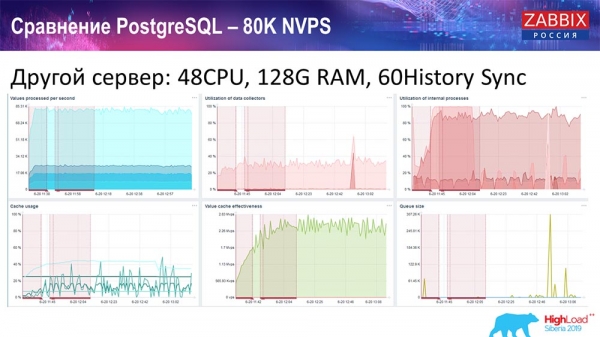
Tiež som to „vyladil“ - nainštaloval History syncer (60 kusov) a dosiahol prijateľný výkon. V skutočnosti nie sme „na polici“, ale to je asi hranica produktivity, kde je už potrebné s tým niečo robiť.
Skúška výkonnosti. Časový rozsahDB: 80 tisíc NVP
Mojou hlavnou úlohou bolo používať TimescaleDB. Každý graf zobrazuje pokles:
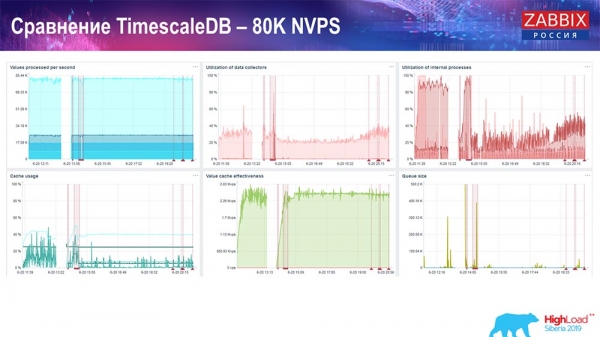
Tieto zlyhania sú presne migráciou údajov. Potom sa na serveri Zabbix načítavací profil potápačov histórie, ako vidíte, veľa zmenil. Umožňuje vám vkladať dáta takmer 3-krát rýchlejšie a používať menej HistoryCache – podľa toho budete mať dáta doručené včas. Opäť platí, že 80 XNUMX hodnôt za sekundu je pomerne vysoká rýchlosť (samozrejme, nie pre Yandex). Celkovo ide o pomerne veľké nastavenie s jedným serverom.
Test výkonu PostgreSQL: 120 tisíc NVP
Ďalej som zvýšil hodnotu počtu dátových prvkov na pol milióna a dostal som vypočítanú hodnotu 125 tisíc za sekundu:
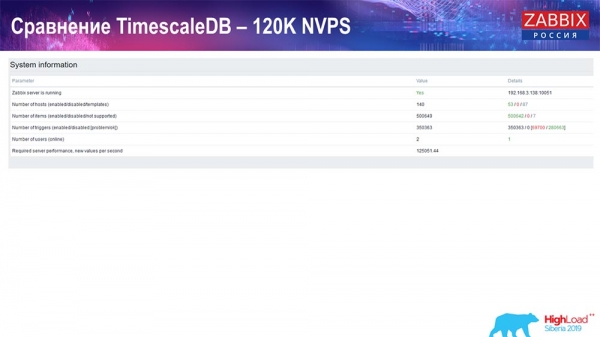
A dostal som tieto grafy:
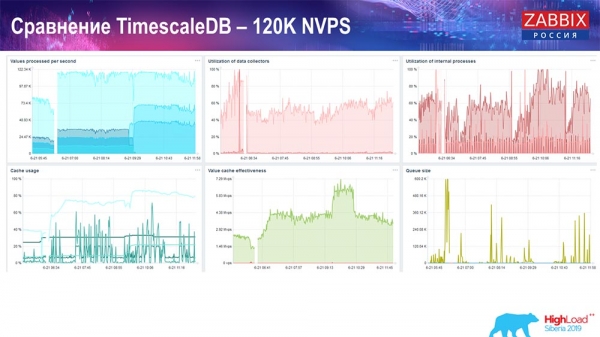
V zásade ide o funkčné nastavenie, ktoré môže fungovať pomerne dlho. Ale keďže som mal len 1,5 terabajtový disk, spotreboval som ho za pár dní. Najdôležitejšie je, že v tom istom čase boli vytvorené nové oddiely na TimescaleDB, a to bolo úplne bez povšimnutia pre výkon, čo sa o MySQL povedať nedá.
Oddiely sa zvyčajne vytvárajú v noci, pretože to vo všeobecnosti blokuje vkladanie a prácu s tabuľkami a môže viesť k degradácii služby. V tomto prípade to tak nie je! Hlavnou úlohou bolo otestovať možnosti TimescaleDB. Výsledkom bolo nasledujúce číslo: 120 tisíc hodnôt za sekundu.
V komunite sú aj príklady:
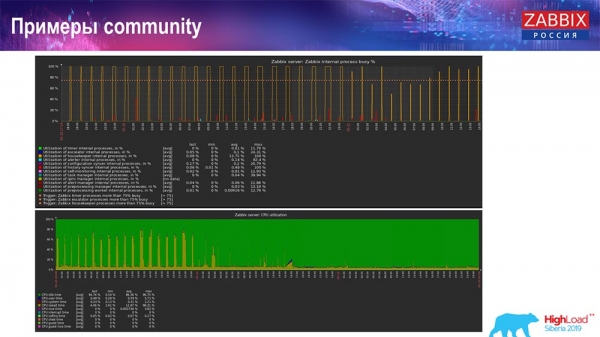
Osoba tiež zapla TimescaleDB a záťaž na používanie io.weight klesla na procesor; a používanie prvkov interného procesu sa tiež znížilo v dôsledku zahrnutia TimescaleDB. Navyše sú to obyčajné palacinkové disky, teda obyčajný virtuálny stroj na obyčajných diskoch (nie SSD)!
Pre niektoré malé nastavenia, ktoré sú obmedzené výkonom disku, je TimescaleDB podľa môjho názoru veľmi dobrým riešením. Umožní vám pokračovať v práci pred migráciou na rýchlejší hardvér databázy.
Pozývam vás všetkých na naše podujatia: Konferencia v Moskve, Summit v Rige. Použite naše kanály - Telegram, fórum, IRC. Ak máte nejaké otázky, príďte k nám, môžeme sa o všetkom porozprávať.
Otázky publika
Otázka od publika (ďalej - A): - Ak sa TimescaleDB tak ľahko konfiguruje a poskytuje také zvýšenie výkonu, možno by sa to malo použiť ako najlepší postup na konfiguráciu Zabbix s Postgres? A má toto riešenie nejaké úskalia a nevýhody, alebo ak by som sa predsa len rozhodol vyrobiť Zabbix pre seba, môžem si jednoducho vziať Postgres, hneď si tam nainštalovať Timescale, používať ho a nemyslieť na problémy?

AG: – Áno, povedal by som, že toto je dobré odporúčanie: ihneď použite Postgres s rozšírením TimescaleDB. Ako som už povedal, veľa dobrých recenzií, napriek tomu, že táto „funkcia“ je experimentálna. Ale v skutočnosti testy ukazujú, že je to skvelé riešenie (s TimescaleDB) a myslím si, že sa bude vyvíjať! Sledujeme, ako sa toto rozšírenie vyvíja, a podľa potreby vykonáme zmeny.
Už pri vývoji sme sa spoliehali na jednu z ich známych „vlastností“: s kúskami sa dalo pracovať trochu inak. Ale potom to v ďalšom vydaní zrušili a museli sme sa prestať spoliehať na tento kód. Odporúčam použiť toto riešenie v mnohých nastaveniach. Ak používate MySQL... Pre priemerné nastavenia funguje dobre akékoľvek riešenie.
a: – Na posledných grafoch z komunity bol graf s „Hospodárkou“:
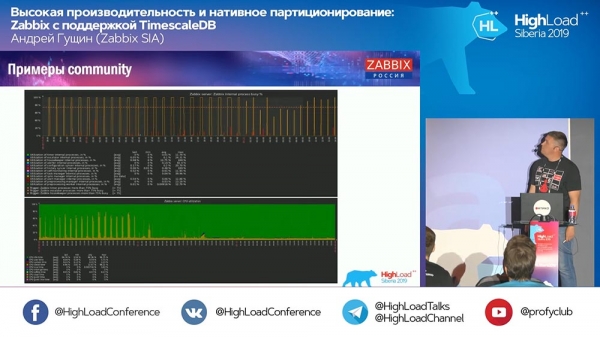
Pokračoval v práci. Čo robí Housekeeper s TimescaleDB?
AG: – Teraz to nemôžem s istotou povedať – pozriem sa na kód a poviem vám to podrobnejšie. Dotazy TimescaleDB nepoužíva na odstránenie častí, ale na ich agregáciu. Na túto technickú otázku ešte nie som pripravený odpovedať. Viac sa dozvieme v stánku dnes alebo zajtra.
a: – Mám podobnú otázku – o vykonaní operácie odstránenia v Timescale.
Odpoveď (odpoveď z publika): – Keď vymažete dáta z tabuľky, ak to urobíte cez delete, tak musíte prejsť cez tabuľku – vymazať, vyčistiť, označiť všetko pre budúce vysávanie. V časovej mierke, keďže máte kúsky, môžete klesnúť. Zhruba povedané, jednoducho poviete súboru, ktorý je vo veľkých údajoch: „Vymazať!“
Timescale jednoducho chápe, že takýto kus už neexistuje. A keďže je integrovaný do plánovača dopytov, používa háčiky na zachytenie vašich podmienok pri výbere alebo iných operáciách a okamžite pochopí, že tento kus už neexistuje – „Už tam nepôjdem!“ (údaje nie sú k dispozícii). To je všetko! To znamená, že skenovanie tabuľky je nahradené odstránením binárneho súboru, takže je rýchle.
a: – Témy non-SQL sme sa už dotkli. Pokiaľ som pochopil, Zabbix v skutočnosti nepotrebuje upravovať údaje a toto všetko je niečo ako denník. Je možné použiť špecializované databázy, ktoré nedokážu meniť svoje dáta, ale zároveň ich oveľa rýchlejšie ukladajú, hromadia a distribuujú - napríklad Clickhouse, niečo ako Kafka?... Kafka je tiež log! Je možné ich nejako integrovať?
AG: - Je možné vykonať vykládku. Od verzie 3.4 máme určitú „funkciu“: do súborov môžete zapisovať všetky historické súbory, udalosti, všetko ostatné; a potom ho poslať do akejkoľvek inej databázy pomocou nejakého handlera. V skutočnosti veľa ľudí prerába a zapisuje priamo do databázy. Potápači histórie toto všetko za behu zapisujú do súborov, otáčajú tieto súbory atď. a vy to môžete preniesť do Clickhouse. Nemôžem povedať o plánoch, ale možno bude pokračovať ďalšia podpora riešení NoSQL (napríklad Clickhouse).
a: – Vo všeobecnosti sa ukazuje, že sa môžete úplne zbaviť postgresov?
AG: – Samozrejme, najťažšou časťou v Zabbixe sú historické tabuľky, ktoré spôsobujú najviac problémov a udalostí. V tomto prípade, ak dlho neukladáte udalosti a ukladáte históriu s trendmi v nejakom inom rýchlom úložisku, vo všeobecnosti si myslím, že nebudú žiadne problémy.
a: – Viete odhadnúť, o koľko rýchlejšie bude všetko fungovať, ak prejdete napríklad na Clickhouse?
AG: – nemám to odskúšané. Myslím si, že prinajmenšom rovnaké čísla sa dajú dosiahnuť celkom jednoducho, vzhľadom na to, že Clickhouse má svoje vlastné rozhranie, ale nemôžem to s istotou povedať. Je lepšie otestovať. Všetko závisí od konfigurácie: koľko máte hostiteľov atď. Vkladanie je jedna vec, ale aj tieto dáta potrebujete získať – Grafana alebo niečo iné.
a: – Hovoríme teda o rovnocennom boji, a nie o veľkej výhode týchto rýchlych databáz?
AG: – Myslím si, že keď sa integrujeme, budú presnejšie testy.
a: – Kam sa podel starý dobrý RRD? Prečo ste prešli na SQL databázy? Spočiatku sa všetky metriky zbierali na RRD.
AG: – Zabbix mal RRD, možno vo veľmi starodávnej verzii. Vždy existovali databázy SQL – klasický prístup. Klasický prístup je MySQL, PostgreSQL (existujú už veľmi dlho). Takmer nikdy sme nepoužívali spoločné rozhranie pre databázy SQL a RRD.


Nejaké inzeráty 🙂
Ďakujeme, že ste zostali s nami. Páčia sa vám naše články? Chcete vidieť viac zaujímavého obsahu? Podporte nás zadaním objednávky alebo odporučením priateľom, , jedinečný analóg serverov základnej úrovne, ktorý sme pre vás vymysleli: (k dispozícii s RAID1 a RAID10, až 24 jadier a až 40 GB DDR4).
Dell R730xd 2 krát lacnejší v dátovom centre Equinix Tier IV v Amsterdame? Len tu v Holandsku! Dell R420 – 2x E5-2430 2.2 GHz 6C 128 GB DDR3 2 x 960 GB SSD 1 Gb/s 100 TB – od 99 USD! Čítať o
Zdroj: hab.com
