

Ahojte všetci, volám sa Alexander a pracujem v spoločnosti CIAN ako inžinier, so zameraním na správu systémov a automatizáciu infraštruktúrnych procesov. V komentároch k jednému z našich predchádzajúcich článkov sme boli požiadaní o vysvetlenie, odkiaľ berieme našich 4 TB logov denne a čo s nimi robíme. Áno, máme veľa logov a vytvorili sme vyhradený infraštruktúrny klaster na ich spracovanie, čo nám umožňuje rýchlo riešiť problémy. V tomto článku sa s vami podelím o to, ako sme ho za posledný rok prispôsobili na zvládnutie tohto neustále rastúceho toku údajov.
Kde sme začali?
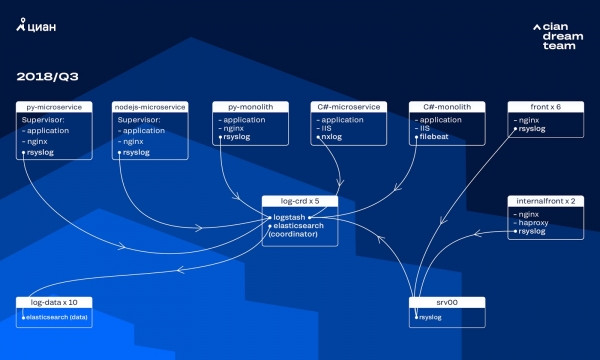
V posledných rokoch záťaž na cian.ru rýchlo rástla a do tretieho štvrťroka 2018 dosiahla návštevnosť 11.2 milióna unikátnych používateľov mesačne. Počas tohto obdobia sme v kritických momentoch strácali až 40 % našich protokolov, čo nám bránilo v rýchlom riešení incidentov a strácalo značné množstvo času a úsilia na ich riešenie. Často sme tiež nedokázali nájsť hlavnú príčinu problému a po čase sa opakoval. Bola to nočná mora, ktorú bolo potrebné riešiť.
V tom čase sme používali klaster 10 dátových uzlov s ElasticSearch verzie 5.5.2 so štandardným nastavením indexu pre ukladanie protokolov. Implementovali sme ho pred viac ako rokom ako populárne a cenovo dostupné riešenie: tok protokolov nebol vtedy taký veľký, takže nemalo zmysel vymýšľať vlastné konfigurácie.
Logstash spracovával prichádzajúce protokoly na rôznych portoch cez päť koordinátorov ElasticSearch. Každý index, bez ohľadu na veľkosť, pozostával z piatich shardov. Boli implementované hodinové a denné rotácie, čo viedlo k tomu, že do klastra sa každú hodinu pridalo približne 100 nových shardov. Pokiaľ bol objem protokolov nízky, klaster zvládal úlohu efektívne a nikto sa nezameriaval na jeho nastavenia.
Problémy s rýchlym rastom
Objem vygenerovaných protokolov rýchlo rástol, pretože sa dva procesy prekrývali. Na jednej strane sa rozrastala používateľská základňa služby. Na druhej strane sme začali aktívne prechádzať na architektúru mikroslužieb a rozbíjať naše staré monolity C# a Python. Niekoľko desiatok nových mikroslužieb, ktoré nahradili časti monolitu, vygenerovalo pre infraštruktúrny klaster výrazne viac protokolov.
Práve škálovanie viedlo k tomu, že sa klaster stal prakticky nezvládnuteľným. Keď začali prichádzať logy rýchlosťou 20 000 správ za sekundu, časté a zbytočné rotácie zvýšili počet shardov na 6 000, s viac ako 600 shardmi na uzol.
To viedlo k problémom s alokáciou RAM a keď uzol havaroval, všetky shardy migrovali súčasne, čím sa zvýšila prevádzka a zaťažili zostávajúce uzly, čo prakticky znemožnilo zapisovať údaje do klastra. A počas tohto obdobia sme zostali bez protokolov. A ak by sa vyskytol problém s... server Celkovo sme strácali 1/10 klastra. Veľký počet malých indexov zvyšoval zložitosť.
Bez protokolov by sme nedokázali pochopiť príčinu incidentu a skôr či neskôr by sme mohli zopakovať tie isté chyby. To bolo vo filozofii nášho tímu neprijateľné, pretože všetky naše pracovné mechanizmy sú navrhnuté tak, aby sa predišlo opakovaniu rovnakých problémov. Na dosiahnutie tohto cieľa sme potrebovali kompletný zber protokolov a ich doručenie takmer v reálnom čase, pretože tím pohotovostných technikov monitoroval upozornenia nielen z metrík, ale aj z protokolov. Pre pochopenie rozsahu problému bol celkový objem protokolov v tom čase približne 2 TB za deň.
Stanovili sme si cieľ úplne eliminovať stratu protokolov a skrátiť čas potrebný na doručenie protokolov do klastra ELK na maximálne 15 minút počas udalostí vyššej moci (tento údaj sme následne použili ako interný kľúčový ukazovateľ výkonnosti).
Nový mechanizmus rotácie a uzly typu „hot-warm“
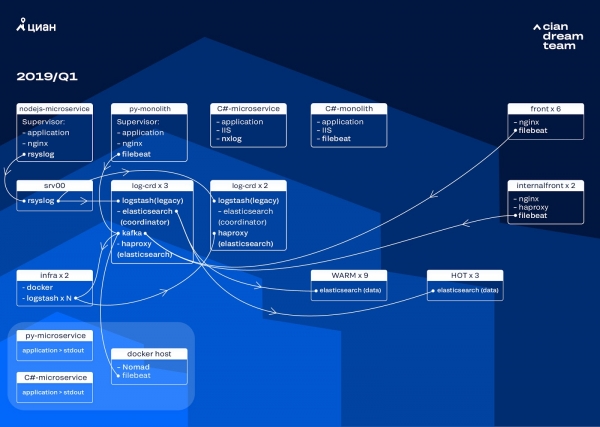
Konverziu klastra sme začali aktualizáciou ElasticSearch z verzie 5.5.2 na 6.4.3. Náš klaster verzie 5 opäť havaroval, a tak sme sa rozhodli ho vypnúť a úplne aktualizovať – aj tak sa nevyskytovali žiadne záznamy. Prechod sme teda dokončili len za pár hodín.
Najvýznamnejšou transformáciou v tejto fáze bola implementácia Apache Kafka na troch uzloch s koordinátorom, ktorý slúžil ako medziľahlý buffer. Broker správ nám zabránil strate protokolov počas problémov s ElasticSearch. Zároveň sme do klastra pridali dva uzly a prešli na architektúru hot-warm s tromi „horúcimi“ uzlami umiestnenými v rôznych rackoch v dátovom centre. Na tieto uzly sme presmerovali protokoly, ktoré sa absolútne nesmú stratiť – NGINX, ako aj protokoly chýb aplikácií – pomocou masky. Na zostávajúce uzly sme odosielali menej dôležité protokoly – debug, warning a podobne – a po 24 hodinách sme migrovali aj „kritické“ protokoly z „horúcich“ uzlov.
Aby sme sa vyhli zvyšovaniu počtu malých indexov, prešli sme z rotácie na základe času na mechanizmus rollover. Na fórach bolo veľa informácií o tom, aká nespoľahlivá je rotácia na základe veľkosti indexu, a preto sme sa rozhodli použiť rotáciu na základe počtu dokumentov v indexe. Analyzovali sme každý index a určili počet dokumentov, po ktorých by sa mala spustiť rotácia. Týmto spôsobom sme dosiahli optimálnu veľkosť shardu nepresahujúcu 50 GB.
Optimalizácia klastrov
Problémy sme však úplne neodstránili. Bohužiaľ, stále sa objavovali malé indexy: nedosiahli zadanú veľkosť, neboli rotované a boli odstránené globálnym čistením indexov pre indexy staršie ako tri dni, pretože sme odstránili rotáciu na základe dátumu. To viedlo k strate údajov, pretože index úplne zmizol z klastra a pokus o zápis do neexistujúceho indexu narušil logiku kurátora, ktorého sme používali na správu. Alias zápisu bol prevedený na index a narušil logiku rolloveru, čo spôsobilo, že niektoré indexy nekontrolovateľne narástli na 600 GB.
Napríklad pre konfiguráciu rotácie:
сurator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
Ak neexistoval alias pre rollover, vyskytla sa nasledujúca chyba:
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Tento problém sme nechali na ďalšiu iteráciu a zamerali sme sa na iný aspekt: prešli sme na logiku spracovania prichádzajúcich protokolov založenú na pull-based technológii (odstránenie redundantných informácií a ich obohatenie). Umiestnili sme ju do Dockeru, ktorý spúšťame cez Docker-compose, a tiež sme hostili logstash-exporter, ktorý odosiela metriky do Prometheusu na monitorovanie toku protokolov v reálnom čase. To nám umožnilo bezproblémovo meniť počet inštancií Logstash zodpovedných za spracovanie každého typu protokolu.
Počas vylepšovania klastra vzrástla návštevnosť cian.ru na 12,8 milióna unikátnych používateľov mesačne. V dôsledku toho naše transformácie mierne zaostávali za zmenami v produkčnom prostredí a narazili sme na situáciu, keď teplé uzly nedokázali zvládnuť záťaž a spomalili doručovanie protokolov. Horúce dáta sme prijímali bez prerušenia, ale pri iných dátach sme museli zasiahnuť a vykonať manuálne prenosy, aby sme rovnomerne rozložili indexy.
Zároveň škálovanie a zmena nastavení inštancií logstash v klastri bola komplikovaná skutočnosťou, že išlo o lokálny docker-compose a všetky akcie sa vykonávali manuálne (na pridanie nových koncových bodov bolo potrebné manuálne prejsť všetky servery a všade spustiť docker-compose up -d).
Redistribúcia protokolov
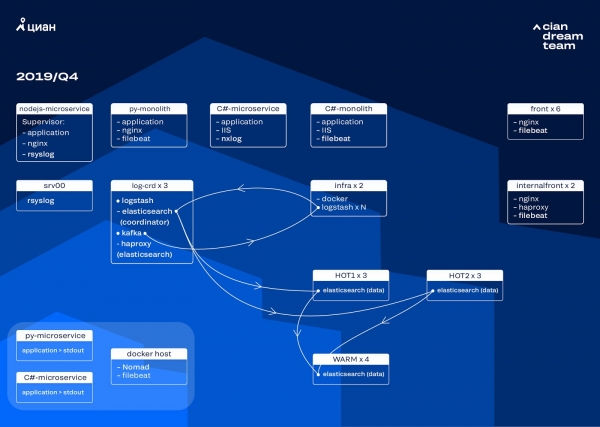
V septembri tohto roku sme stále pílili monolit, zaťaženie klastra sa zvyšovalo a tok protokolov sa blížil k 30 tisícom správ za sekundu.
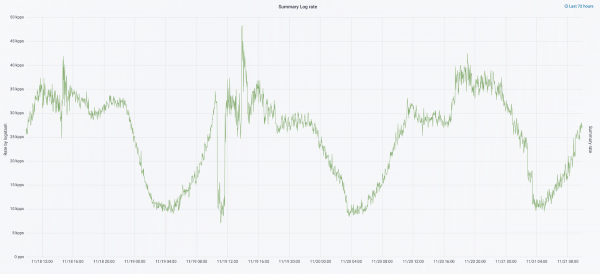
Ďalšiu iteráciu sme začali s aktualizáciou hardvéru. Zmenili sme počet koordinátorov z piatich na tri, nahradili sme dátové uzly a získali sme peniaze aj úložný priestor. Používame dve konfigurácie uzlov:
- Pre horúce uzly: E3-1270 v6 / 960Gb SSD / 32 Gb x 2 x 2 (3 pre Hot1 a 3 pre Hot3).
- Pre „teplé“ uzly: E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
V tejto iterácii sme presunuli index s protokolmi prístupu k mikroslužbám, ktorý zaberá rovnaký priestor ako protokoly front-endového Nginxu, do druhej skupiny troch „horúcich“ uzlov. Dáta teraz uchovávame na „horúcich“ uzloch 20 hodín a potom ich presunieme na „teplé“ uzly, aby sme ich pridali k zostávajúcim protokolom.
Problém so zanikaním malých indexov sme vyriešili prekonfigurovaním ich rotácie. Indexy sa teraz rotujú každých 23 hodín, aj keď obsahujú málo údajov. Tým sa mierne zvýšil počet shardov (teraz okolo 800), ale z hľadiska výkonu klastra je to tolerovateľné.
V dôsledku toho má klaster teraz šesť „horúcich“ uzlov a iba štyri „teplé“ uzly. To spôsobuje mierne oneskorenie dotazov v dlhých časových intervaloch, ale zvýšenie počtu uzlov tento problém v budúcnosti vyrieši.
Táto iterácia tiež riešila nedostatok poloautomatického škálovania. Aby sme to vyriešili, nasadili sme infraštruktúrny klaster Nomad – podobný tomu, ktorý už máme v produkčnom prostredí. V súčasnosti sa počet inštancií Logstash automaticky neškáluje na základe zaťaženia, ale aj k tomu dospejeme.
Plány do budúcnosti
Implementovaná konfigurácia sa dobre škáluje a momentálne uchovávame 13,3 TB dát – všetky protokoly po dobu štyroch dní, čo je potrebné na analýzu núdzových upozornení. Niektoré protokoly konvertujeme na metriky, ktoré ukladáme v Graphite. Pre uľahčenie práce technikov máme metriky pre infraštruktúrny klaster a skripty na poloautomatickú opravu bežných problémov. Po zvýšení počtu dátových uzlov, ktoré je plánované na budúci rok, prejdeme na uchovávanie dát zo štyroch na sedem dní. To bude postačovať pre operačnú prácu, pretože sa vždy snažíme čo najrýchlejšie vyšetrovať incidenty a telemetrické údaje sú k dispozícii pre dlhodobé vyšetrovania.
V októbri 2019 vzrástla návštevnosť cian.ru na 15,3 milióna unikátnych používateľov mesačne. Toto sa stalo vážnym testom architektúry doručovania protokolov.
Momentálne sa pripravujeme na aktualizáciu ElasticSearch na verziu 7. To si však bude vyžadovať aktualizáciu mapovaní mnohých indexov ElasticSearch, pretože boli migrované z verzie 5.5 a vo verzii 6 boli zastarané (vo verzii 7 jednoducho neexistujú). To znamená, že počas procesu aktualizácie nevyhnutne dôjde k nejakej neočakávanej udalosti, ktorá nás nechá bez protokolov, kým sa problém nevyrieši. Zo všetkých funkcií vo verzii 7 sa najviac tešíme na Kibanu s jej vylepšeným rozhraním a novými filtrami.
Dosiahli sme náš hlavný cieľ: zastavili sme stratu protokolov a znížili sme prestoje nášho infraštruktúrneho klastra z dvoch alebo troch výpadkov týždenne na len niekoľko hodín údržby mesačne. Všetka táto práca je v produkčnom prostredí prakticky nepostrehnuteľná. Teraz však dokážeme presne určiť, čo sa deje s našou službou, rýchlo a spoľahlivo a bez obáv zo straty protokolov. Celkovo sme spokojní a šťastní a pripravujeme sa na nové úspechy, o ktoré sa neskôr podelíme.
Zdroj: hab.com
