


Ahoj, Habr! Som Artem Karamyshev, vedúci tímu pre správu systémov. V priebehu minulého roka sme uviedli na trh mnoho nových produktov. Chceli sme, aby naše API služby boli ľahko škálovateľné, odolné voči chybám a pripravené na rýchly rast záťaže používateľov. Naša platforma je postavená na OpenStacku a rád by som sa s vami podelil o niektoré problémy s odolnosťou komponentov voči chybám, ktoré sme museli riešiť, aby sme dosiahli systém odolný voči chybám. Myslím si, že to bude zaujímavé pre tých, ktorí tiež vyvíjajú produkty na OpenStacku.
Celková odolnosť platformy závisí od odolnosti jej komponentov. Postupne teda prejdeme všetkými vrstvami, kde sme identifikovali a riešili riziká.
Video verzia tohto príbehu, ktorého pôvodným zdrojom bola prezentácia na konferencii Uptime day 4, ktorú organizovala , môžete sa pozrieť .
Odolnosť fyzickej architektúry voči chybám
Verejná časť cloudu MCS sa v súčasnosti nachádza v dvoch dátových centrách úrovne Tier III, ktoré sú prepojené vyhradenou sieťou s dark fiber so samostatnými fyzickými redundanciami a priepustnosťou 200 Gb/s. Úroveň Tier III poskytuje potrebnú úroveň odolnosti voči chybám pre fyzickú infraštruktúru.
Tmavé vlákno je redundantné na fyzickej aj logickej úrovni. Proces redundancie kanálov bol iteratívny a hoci sa vyskytli problémy, neustále zlepšujeme prepojenie medzi dátovými centrami.
Napríklad nedávno, počas práce vo vrte neďaleko jedného z našich dátových centier, bager prerazil potrubie, v ktorom sa nachádzal primárny aj záložný optický kábel. Náš bezpečný komunikačný kanál s dátovým centrom bol v jednom bode, teda vo vrte, zraniteľný. V dôsledku toho sme stratili časť našej infraštruktúry. Poučili sme sa z toho a podnikli sme niekoľko krokov vrátane inštalácie ďalších optických káblov v susednom vrte.
Naše dátové centrá obsahujú body prítomnosti pre telekomunikačných poskytovateľov, ktorým vysielame naše prefixy cez BGP. Pre každý smer siete sa vyberá najlepšia metrika, čo nám umožňuje poskytovať najlepšiu kvalitu pripojenia rôznym klientom. Ak je pripojenie cez jedného poskytovateľa prerušené, prekonfigurujeme naše smerovanie cez dostupných poskytovateľov.
V prípade výpadku poskytovateľa automaticky prepneme na ďalšieho poskytovateľa. Ak zlyhá jedno dátové centrum, máme zrkadlovú kópiu našich služieb v druhom dátovom centre, ktoré preberá celú záťaž.
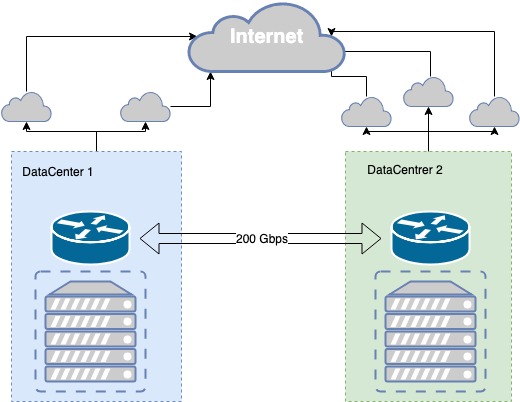
Odolnosť fyzickej infraštruktúry
Čo používame pre odolnosť voči chybám na úrovni aplikácie
Naša služba je postavená na viacerých open-source komponentoch.
ExaBGP — služba, ktorá implementuje množstvo funkcií pomocou dynamického smerovacieho protokolu založeného na BGP. Aktívne ju používame na inzerciu našich bielych IP adries, prostredníctvom ktorých používatelia pristupujú k API.
HAProxy — vyrovnávač záťaže pre vysoké zaťaženie, ktorý vám umožňuje konfigurovať vysoko flexibilné pravidlá vyvažovania prevádzky na rôznych vrstvách modelu OSI. Používame ho na vyvažovanie záťaže naprieč všetkými službami: databázami, sprostredkovateľmi správ, službami API, webovými službami a našimi internými projektmi – všetky sú poháňané technológiou HAProxy.
API aplikácia — webová aplikácia napísaná v jazyku Python, pomocou ktorej používateľ spravuje svoju infraštruktúru, svoje služby.
Žiadosť pracovníka (ďalej len „worker“) je infraštruktúrny démon v službách OpenStack, ktorý umožňuje prenos príkazov API do infraštruktúry. Napríklad vytvorenie disku prebieha v workerovi a požiadavka na vytvorenie sa odošle do aplikácie API.
Architektúra štandardu aplikácií OpenStack
Väčšina služieb vyvinutých pre OpenStack sa snaží riadiť jednotnou paradigmou. Služba sa zvyčajne skladá z dvoch častí: API a workerov (backendových exekútorov). API je typicky WSGI aplikácia napísaná v jazyku Python, ktorá beží buď ako samostatný proces (démon), alebo pomocou webového servera, ako je Nginx alebo Apache. API spracováva požiadavku používateľa a odovzdáva ďalšie pokyny aplikácii worker na vykonanie. Tento prenos prebieha prostredníctvom sprostredkovateľa správ, zvyčajne RabbitMQ; iné typy sú slabo podporované. Keď správy dosiahnu sprostredkovateľa, workeri ich spracujú a v prípade potreby vrátia odpoveď.
Táto paradigma predpokladá izolované spoločné body zlyhania: RabbitMQ a databázu. RabbitMQ je však izolovaný v rámci jednej služby a teoreticky by mohol byť špecifický pre každú službu. V MCS preto tieto služby čo najviac oddeľujeme a vytvárame samostatnú databázu a samostatný RabbitMQ pre každý jednotlivý projekt. Tento prístup je výhodný, pretože ak dôjde k zlyhaniu v zraniteľnom bode, ovplyvnená je iba časť služby, nie celá služba.
Počet pracovných aplikácií nie je obmedzený, takže API je možné jednoducho horizontálne škálovať za vyvažovačmi, aby sa zvýšil výkon a odolnosť voči chybám.
Niektoré služby vyžadujú koordináciu v rámci služby – keď prebiehajú zložité sekvenčné operácie medzi API a pracovníkmi. V tomto prípade sa používa jedno koordinačné centrum, klastrový systém ako Redis, Memcache atď., ktorý umožňuje jednému pracovníkovi povedať druhému, že mu je pridelená úloha („prosím, nepreber si ju“). My používame etcd. Pracovníci zvyčajne aktívne komunikujú s databázou, zapisujú a čítajú z nej informácie. Ako našu databázu používame mariadb, ktorá sa nachádza v našom klastri s viacerými hlavnými úlohami.
Táto klasická samostatná služba je organizovaná spôsobom všeobecne akceptovaným pre OpenStack. Možno ju považovať za uzavretý systém s pomerne jednoduchými možnosťami škálovania a odolnosti voči chybám. Napríklad, na zabezpečenie odolnosti voči chybám API stačí pred API umiestniť vyrovnávač záťaže. Škálovanie workerov sa dosiahne zvýšením ich počtu.
Slabými stránkami celej schémy sú RabbitMQ a MariaDB. Ich architektúra si zaslúži samostatný článok. V tomto článku by som sa chcel zamerať na odolnosť API voči chybám.
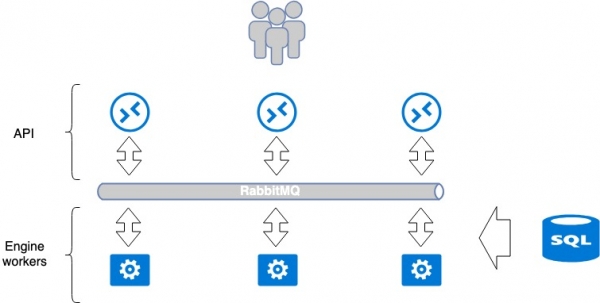
Architektúra aplikácií OpenStack: Vyvažovanie a odolnosť voči chybám pre cloudovú platformu
Ako zabezpečiť odolnosť HAProxy Load Balanceru voči chybám pomocou ExaBGP
Aby sme zabezpečili škálovateľnosť, rýchlosť a odolnosť našich API, nainštalovali sme vyrovnávač záťaže. Zvolili sme HAProxy. Podľa môjho názoru má všetky potrebné vlastnosti pre naše potreby: vyrovnávanie záťaže na viacerých vrstvách OSI, rozhranie pre správu, flexibilitu a škálovateľnosť, širokú škálu metód vyrovnávania záťaže a podporu tabuliek relácií.
Prvým problémom, ktorý bolo potrebné vyriešiť, bola odolnosť samotného vyrovnávača záťaže voči chybám. Samotná inštalácia vyrovnávača záťaže vytvára jediný bod zlyhania: ak vyrovnávač záťaže zlyhá, služba prestane fungovať. Aby sme tomu predišli, použili sme HAProxy v spojení s ExaBGP.
ExaBGP umožňuje mechanizmus kontroly stavu služby. Tento mechanizmus sme použili na kontrolu stavu HAProxy a v prípade problémov sme službu HAProxy deaktivovali z BGP.
Schéma ExaBGP+HAProxy
- Na tri servery inštalujeme potrebný softvér, ExaBGP a HAProxy.
- Na každom zo serverov vytvoríme rozhranie spätnej slučky.
- Na všetkých troch serveroch registrujeme na tomto rozhraní rovnakú bielu IP adresu.
- Biela IP adresa sa oznamuje internetu prostredníctvom ExaBGP.
Tolerancia chýb sa dosahuje zverejňovaním rovnakej IP adresy zo všetkých troch serverov. Z pohľadu siete je rovnaká adresa prístupná z troch rôznych ďalších uzlov (next hop). Router vidí tri identické trasy, vyberie trasu s najvyššou prioritou na základe vlastnej metriky (zvyčajne rovnaká trasa) a prevádzka je smerovaná iba na jeden zo serverov.
V prípade problémov s HAProxy alebo zlyhania servera ExaBGP prestane inzerovať trasu a prevádzka sa plynulo prepne na iný server.
Týmto spôsobom sme dosiahli odolnosť balancera voči chybám.
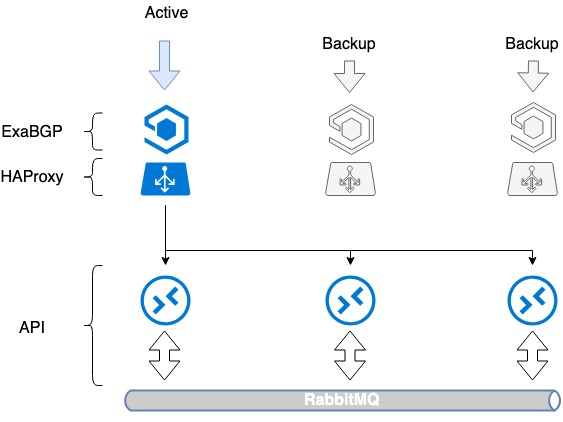
Tolerancia chýb HAProxy Load Balancer
Nastavenie nebolo dokonalé: naučili sme sa, ako zálohovať HAProxy, ale nenaučili sme sa, ako rozložiť záťaž medzi služby. Preto sme nastavenie mierne rozšírili a prešli na vyrovnávanie záťaže medzi viacerými verejnými IP adresami.
Vyvažovanie záťaže založené na DNS plus BGP
Problém s vyrovnávaním záťaže pred naším HAProxy zostáva nevyriešený. Dá sa však vyriešiť pomerne jednoducho, ako sme to urobili my pre náš vlastný.
Na vyváženie troch serverov budete potrebovať tri verejné IP adresy a starý dobrý DNS. Každá z týchto adries je priradená k loopback rozhraniu každej HAProxy a inzerovaná na internete.
OpenStack používa na správu zdrojov katalóg služieb, ktorý definuje koncový bod API pre každú službu. V tomto katalógu špecifikujeme názov domény – public.infra.mail.ru – ktorý sa prostredníctvom DNS prepojí na tri rôzne IP adresy. Výsledkom je vyvažovanie záťaže medzi týmito tromi adresami pomocou DNS.
Keďže však pri oznamovaní bielych IP adries nekontrolujeme priority výberu serverov, ešte nejde o vyváženie. Zvyčajne sa vyberie iba jeden server na základe najvyššej IP adresy, zatiaľ čo ostatné dva zostanú nečinné, pretože v protokole BGP nie sú uvedené žiadne metriky.
Začali sme distribuovať trasy cez ExaBGP s rôznymi metrikami. Každý vyrovnávač záťaže propaguje všetky tri biele IP adresy, ale jedna z nich, primárna IP adresa pre daný vyrovnávač záťaže, je propagovaná s minimálnou metrikou. Takže, kým sú všetky tri vyrovnávače záťaže v prevádzke, požiadavky na prvú IP adresu idú na prvý vyrovnávač záťaže, požiadavky na druhú na druhý a požiadavky na tretiu na tretí.
Čo sa stane, keď jeden z vyrovnávačov záťaže zlyhá? Ak zlyhá ktorýkoľvek vyrovnávač záťaže, jeho primárna adresa je stále inzerovaná ostatnými dvoma a prevádzka sa medzi nimi prerozdeľuje. Týmto spôsobom poskytujeme používateľovi viacero IP adries prostredníctvom DNS. Vyrovnávaním prostredníctvom DNS a rôznych metrík dosahujeme rovnomerné rozloženie záťaže medzi všetkými tromi vyrovnávačmi záťaže a zároveň zachovávame odolnosť voči chybám.
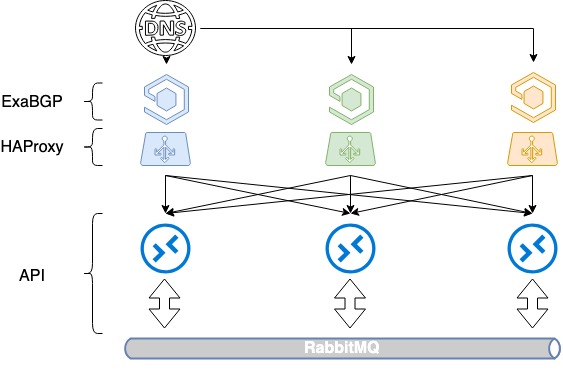
Vyrovnávanie záťaže HAProxy s DNS a BGP
Interakcia medzi ExaBGP a HAProxy
Takže sme implementovali ochranu pred výpadkom servera zastavením hlásení trás. HAProxy však môže prestať fungovať aj z iných dôvodov ako zlyhanie servera: administratívne chyby, zlyhania interných služieb. Chceme aj v týchto prípadoch odstrániť nefunkčný vyrovnávač záťaže z vyrovnávania záťaže, takže potrebujeme iný mechanizmus.
Preto sme v nadväznosti na predchádzajúcu schému implementovali systém heartbeat medzi ExaBGP a HAProxy. Ide o softvérovú implementáciu interakcie medzi ExaBGP a HAProxy, kde ExaBGP používa vlastné skripty na kontrolu stavu aplikácií.
Na to je potrebné v konfigurácii ExaBGP nakonfigurovať kontrolu stavu, ktorá dokáže skontrolovať stav HAProxy. V našom prípade sme v HAProxy nakonfigurovali backend a na strane ExaBGP sme ho kontrolovali jednoduchým GET požiadavkom. Ak sa oznamovanie zastaví, HAProxy je pravdepodobne nedostupný a nie je potrebné ho oznamovať.
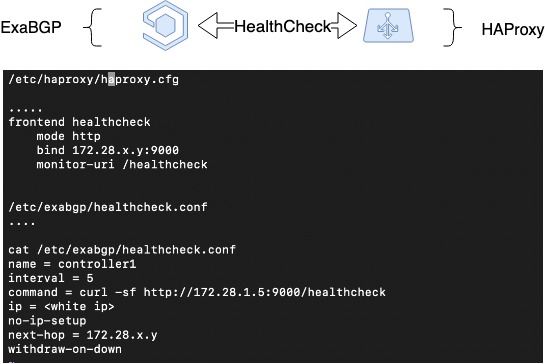
Kontrola stavu HAProxy
HAProxy Peers: Synchronizácia relácií
Ďalšou vecou, ktorú bolo potrebné urobiť, bola synchronizácia relácií. Pri práci s distribuovanými vyrovnávačmi záťaže je ukladanie informácií o reláciách klientov zložité. HAProxy je však jedným z mála vyrovnávačov záťaže, ktoré to dokážu vďaka svojej funkcii Peers, ktorá umožňuje zdieľanie tabuľky relácií medzi rôznymi procesmi HAProxy.
Existujú rôzne metódy vyvažovania: jednoduché, ako napr. , a rozšírené, kde sa relácia klienta zapamätá a klient je zakaždým presmerovaný na ten istý server. Chceli sme implementovať druhú možnosť.
HAProxy používa na ukladanie klientskych relácií pripútané tabuľky. Ukladajú zdrojovú IP adresu klienta, vybranú cieľovú adresu (backend) a niektoré servisné informácie. Pripútané tabuľky sa zvyčajne používajú na ukladanie párov zdrojová IP adresa a cieľová IP adresa, čo je obzvlášť užitočné pre aplikácie, ktoré nemôžu preniesť kontext používateľskej relácie pri prepínaní na iný vyrovnávač záťaže, napríklad v režime vyrovnávania záťaže RoundRobin.
Naučením tabuľky stick presúvať sa medzi rôznymi procesmi HAProxy (medzi ktorými dochádza k vyrovnávaniu záťaže) budú naše vyrovnávače záťaže schopné pracovať s jedným fondom tabuliek stick. To umožní bezproblémové prepnutie klientskej siete pri zlyhaní jedného vyrovnávača záťaže a klientske relácie budú naďalej obsluhované na rovnakých backendoch, ktoré boli predtým vybrané.
Pre správnu funkciu je potrebné vyriešiť problém so zdrojovou IP adresou vyrovnávača záťaže, z ktorej je relácia nadviazaná. V našom prípade ide o dynamickú adresu na rozhraní spätnej slučky.
Partneri fungujú správne iba za určitých podmienok. Konkrétne, časové limity TCP musia byť dostatočne dlhé alebo prepínanie musí byť dostatočne rýchle, aby sa zabránilo ukončeniu relácie TCP. Napriek tomu to umožňuje bezproblémové prepínanie.
Máme službu v IaaS postavenú s použitím rovnakej technológie. , s názvom Octavia. Je založený na dvoch HAProxy procesoch a má natívnu podporu pre peer-ov. V tejto službe sa výborne osvedčil.
Obrázok schematicky znázorňuje pohyb partnerských tabuliek medzi tromi inštanciami HAProxy a je poskytnutá konfigurácia, ktorá ilustruje, ako je to možné nastaviť:
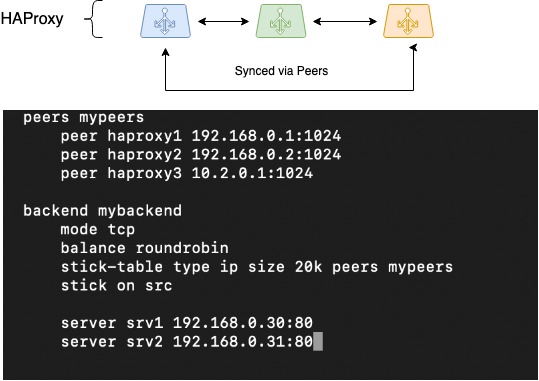
HAProxy Peers (synchronizácia relácií)
Ak implementujete podobnú schému, mali by ste ju starostlivo otestovať. Nie je zaručené, že bude fungovať na 100 %. Ale aspoň nestratíte svoje trvalé tabuľky, keď si budete potrebovať zapamätať zdrojovú IP adresu klienta.
Obmedzenie počtu súčasných požiadaviek od toho istého klienta
Akákoľvek verejne dostupná služba vrátane našich API môže byť vystavená záplave požiadaviek. Príčiny sa môžu značne líšiť, od chýb používateľov až po cielené útoky. Pravidelne sa stretávame s IP DDoS útokmi. Klienti často robia chyby vo svojich skriptoch, čo spôsobuje mini-DDoS útoky.
V každom prípade sú potrebné dodatočné bezpečnostné opatrenia. Zjavným riešením je obmedziť počet požiadaviek API a vyhnúť sa plytvaniu časom CPU spracovaním škodlivých požiadaviek.
Na implementáciu týchto obmedzení používame limity rýchlosti postavené na HAProxy s použitím rovnakých tabuliek. Limity sa dajú pomerne ľahko konfigurovať a umožňujú vám obmedziť počet požiadaviek API, ktoré môže používateľ vykonať. Algoritmus si pamätá zdrojovú IP adresu, z ktorej sú požiadavky vykonané, a obmedzuje počet simultánnych požiadaviek na používateľa. Prirodzene, vypočítali sme priemerný profil zaťaženia API pre každú službu a nastavili sme limit približne 10-krát vyšší ako táto hodnota. Situáciu naďalej pozorne sledujeme a držíme prst na pulze.
Ako to funguje v praxi? Máme zákazníkov, ktorí neustále používajú naše API na automatické škálovanie. Ráno vytvoria približne dvesto až tristo virtuálnych strojov a večer ich vymažú. V prípade OpenStacku si vytvorenie virtuálneho stroja, najmä so službami PaaS, vyžaduje aspoň 1 000 požiadaviek na API, pretože interakcie medzi službami prebiehajú aj prostredníctvom API.
Tieto presuny úloh vytvárajú pomerne značnú záťaž. Túto záťaž sme vyhodnotili, zozbierali denné špičky, desaťnásobne ich zvýšili a to sa stalo naším limitom rýchlosti. Sledujeme situáciu. Často vidíme boty a skenery, ktoré sa snažia zistiť, či máme nejaké CGA skripty, ktoré sa dajú spustiť, a aktívne ich obmedzujeme.
Ako bezproblémovo aktualizovať kódovú základňu pre používateľov
Toleranciu chýb implementujeme aj na úrovni procesu nasadzovania kódu. Počas nasadzovania sa vyskytujú zlyhania, ale ich vplyv na dostupnosť služieb je možné minimalizovať.
Naše služby neustále aktualizujeme a musíme zabezpečiť, aby sa aktualizácie kódovej bázy vykonávali bez vplyvu na používateľov. Dosiahli sme to využitím možností správy HAProxy a implementáciou funkcie Graceful Shutdown v našich službách.
Na vyriešenie tohto problému bolo potrebné zabezpečiť správu balancera a „správne“ vypnutie služby:
- Správa HAProxy sa vykonáva prostredníctvom štatistického súboru, čo je v podstate socket definovaný v konfiguračnom súbore HAProxy. Príkazy mu možno posielať cez stdio. Naším primárnym nástrojom na správu konfigurácie je však Ansible, takže má vstavaný modul na správu HAProxy, ktorý aktívne používame.
- Väčšina našich API a Engine služieb podporuje elegantné vypnutie: pri vypínaní čakajú na dokončenie aktuálnej úlohy, či už ide o HTTP požiadavku alebo inú servisnú úlohu. To isté sa deje s workerom. Pozná všetky úlohy, ktoré vykonáva, a ukončí sa, keď sú všetky úspešne dokončené.
Vďaka týmto dvom bodom vyzerá náš algoritmus bezpečného nasadenia takto.
- Vývojár zostaví nový balík kódu (v našom prípade RPM), otestuje ho vo vývojovom prostredí, otestuje ho v prostredí stage a ponechá ho v repozitári stage.
- Vývojár nastaví úlohu nasadenia s veľmi podrobným popisom „artefaktov“: verzia nového balíka, popis novej funkcionality a ďalšie podrobnosti o nasadení, ak je to potrebné.
- Správca systému spustí aktualizáciu. Spustí Ansible playbook, ktorý následne vykoná nasledujúce:
- Prevezme balík z repozitára fázy a na jeho základe aktualizuje verziu balíka v produkčnom repozitári.
- Generuje zoznam backendov pre aktualizovanú službu.
- Vypne prvú službu, ktorá sa práve aktualizuje v HAProxy, a čaká na ukončenie jej procesov. Vďaka plynulému vypnutiu zabezpečíme úspešné dokončenie všetkých aktuálnych požiadaviek klientov.
- Po úplnom zastavení API a workerov a vypnutí HAProxy sa kód aktualizuje.
- Ansible spúšťa služby.
- Pre každú službu sa vyžiadajú špecifické „úchytky“, ktoré vykonávajú jednotkové testovanie oproti sérii preddefinovaných kľúčových testov. Vykonáva sa základné overenie nového kódu.
- Ak sa v predchádzajúcom kroku nenašli žiadne chyby, aktivuje sa backend.
- Poďme k ďalšiemu backendu.
- Po aktualizácii všetkých backendov sa spustia funkčné testy. Ak chýbajú, vývojár skontroluje všetky nové funkcie, ktoré implementoval.
Týmto sa nasadenie dokončí.
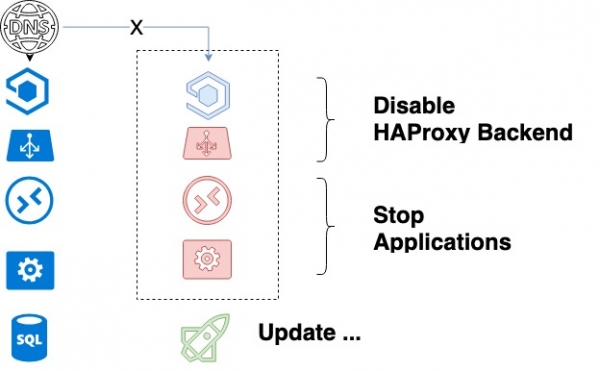
Cyklus aktualizácie služby
Tento systém by nefungoval, keby sme nemali jedno pravidlo. Súčasne udržiavame starú aj novú verziu. Od začiatku, počas vývoja softvéru, dbáme na to, aby aj zmeny v databáze služby nenarušili predchádzajúci kód. V dôsledku toho sa kódová základňa aktualizuje postupne.
Záver
V rámci svojich myšlienok o webovej architektúre odolnej voči chybám by som rád zopakoval jej kľúčové body:
- fyzická odolnosť voči chybám;
- odolnosť siete voči chybám (vyvažovače, BGP);
- odolnosť voči chybám používaného a vyvíjaného softvéru.
Prajem všetkým stabilnú prevádzku!
Zdroj: hab.com
