

Poznámka. preklad.: Tento článok, ktorý napísal Galo Navarro, ktorý zastáva pozíciu hlavného softvérového inžiniera v európskej spoločnosti Adevinta, je fascinujúcim a poučným „vyšetrovaním“ v oblasti prevádzky infraštruktúry. Jej pôvodný názov bol v preklade mierne rozšírený z dôvodu, ktorý autor vysvetľuje hneď na začiatku.
Poznámka od autora: Vyzerá ako tento príspevok oveľa viac pozornosti, ako sa očakávalo. Stále ma hnevajú komentáre, že názov článku je zavádzajúci a niektorí čitatelia sú z toho smutní. Rozumiem dôvodom toho, čo sa deje, a preto vám napriek riziku zničenia celej intrigy chcem okamžite povedať, o čom je tento článok. Zvláštna vec, ktorú som videl pri migrácii tímov na Kubernetes, je, že kedykoľvek sa vyskytne problém (napríklad zvýšená latencia po migrácii), prvá vec, ktorá je obviňovaná, je Kubernetes, ale potom sa ukáže, že orchestrátor v skutočnosti nie je obviňovať. Tento článok hovorí o jednom takom prípade. Jeho názov opakuje výkrik jedného z našich vývojárov (neskôr uvidíte, že Kubernetes s tým nemá nič spoločné). Nenájdete tu žiadne prekvapivé odhalenia o Kubernetes, ale môžete očakávať pár dobrých lekcií o zložitých systémoch.
Pred pár týždňami môj tím migroval jednu mikroslužbu na základnú platformu, ktorá zahŕňala CI/CD, runtime založené na Kubernetes, metriky a ďalšie vychytávky. Presun bol skúšobného charakteru: plánovali sme ho vziať ako základ a v najbližších mesiacoch previesť približne 150 ďalších služieb. Všetci sú zodpovední za fungovanie niektorých z najväčších online platforiem v Španielsku (Infojobs, Fotocasa atď.).
Po tom, čo sme aplikáciu nasadili do Kubernetes a presmerovali do nej časť prevádzky, nás čakalo alarmujúce prekvapenie. Oneskorenie (latencia) požiadavky v Kubernetes boli 10-krát vyššie ako v EC2. Vo všeobecnosti bolo potrebné buď nájsť riešenie tohto problému, alebo upustiť od migrácie mikroslužby (a prípadne celého projektu).
Prečo je latencia v Kubernetes oveľa vyššia ako v EC2?
Aby sme našli prekážku, zhromaždili sme metriky pozdĺž celej cesty žiadosti. Naša architektúra je jednoduchá: brána API (Zuul) posiela požiadavky na inštancie mikroslužieb v EC2 alebo Kubernetes. V Kubernetes používame NGINX Ingress Controller a backendy sú bežné objekty ako s aplikáciou JVM na platforme Spring.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Zdá sa, že problém súvisí s počiatočnou latenciou v backende (problémovú oblasť som na grafe označil ako „xx“). Na EC2 trvala odozva aplikácie asi 20 ms. V Kubernetes sa latencia zvýšila na 100-200 ms.
Rýchlo sme zamietli pravdepodobných podozrivých súvisiacich so zmenou runtime. Verzia JVM zostáva rovnaká. Problémy s kontajnermi s tým tiež nemali nič spoločné: aplikácia už úspešne bežala v kontajneroch na EC2. Načítava? Pozorovali sme však vysoké latencie aj pri 1 požiadavke za sekundu. Zanedbať by sa dali aj prestávky na odvoz odpadu.
Jeden z našich správcov Kubernetes sa pýtal, či má aplikácia externé závislosti, pretože dotazy DNS spôsobovali v minulosti podobné problémy.
Hypotéza 1: Rozlíšenie názvu DNS
Pre každú požiadavku naša aplikácia pristupuje k inštancii AWS Elasticsearch jeden až trikrát v doméne, ako je napríklad elastic.spain.adevinta.com. V našich kontajneroch , takže môžeme skontrolovať, či hľadanie domény skutočne trvá dlho.
DNS dotazy z kontajnera:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecPodobné požiadavky z jednej z inštancií EC2, kde je aplikácia spustená:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecVzhľadom na to, že vyhľadávanie trvalo asi 30 ms, bolo jasné, že rozlíšenie DNS pri prístupe k Elasticsearch skutočne prispieva k zvýšeniu latencie.
Bolo to však zvláštne z dvoch dôvodov:
- Už máme veľa aplikácií Kubernetes, ktoré interagujú so zdrojmi AWS bez toho, aby trpeli vysokou latenciou. Nech už je dôvod akýkoľvek, týka sa to konkrétne tohto prípadu.
- Vieme, že JVM vykonáva in-memory DNS cache. Na našich obrázkoch je zapísaná hodnota TTL
$JAVA_HOME/jre/lib/security/java.securitya nastavte na 10 sekúnd:networkaddress.cache.ttl = 10. Inými slovami, JVM by mal ukladať do vyrovnávacej pamäte všetky dotazy DNS na 10 sekúnd.
Aby sme potvrdili prvú hypotézu, rozhodli sme sa na chvíľu prestať volať DNS a zistiť, či problém zmizol. Najprv sme sa rozhodli prekonfigurovať aplikáciu tak, aby komunikovala priamo s Elasticsearch podľa IP adresy, a nie cez názov domény. To by si vyžadovalo zmeny kódu a nové nasadenie, takže sme doménu jednoducho namapovali na jej IP adresu /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comTeraz kontajner dostal IP takmer okamžite. To viedlo k určitému zlepšeniu, ale boli sme len o niečo bližšie k očakávaným úrovniam latencie. Hoci rozlíšenie DNS trvalo dlho, skutočný dôvod nám stále unikal.
Diagnostika cez sieť
Rozhodli sme sa analyzovať návštevnosť z kontajnera pomocou tcpdumpaby ste videli, čo sa presne deje v sieti:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Potom sme poslali niekoľko žiadostí a stiahli ich zachytenie (kubectl cp my-service:/capture.pcap capture.pcap) na ďalšiu analýzu v .
Na DNS dotazoch nebolo nič podozrivé (okrem jednej maličkosti, o ktorej budem hovoriť neskôr). V spôsobe, akým naša služba riešila každú požiadavku, však boli určité zvláštnosti. Nižšie je snímka obrazovky zachytávania, ktorá ukazuje, že žiadosť bola prijatá pred začatím odpovede:
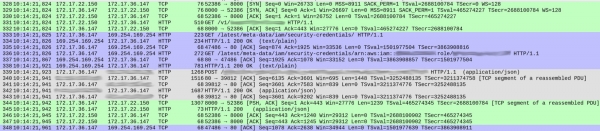
Čísla balíkov sú uvedené v prvom stĺpci. Kvôli prehľadnosti som farebne odlíšil rôzne toky TCP.
Zelený prúd začínajúci paketom 328 ukazuje, ako klient (172.17.22.150) nadviazal TCP spojenie s kontajnerom (172.17.36.147). Po úvodnom podaní ruky (328-330) priniesol balíček 331 HTTP GET /v1/.. — prichádzajúca požiadavka na našu službu. Celý proces trval 1 ms.
Sivý stream (z paketu 339) ukazuje, že naša služba odoslala požiadavku HTTP do inštancie Elasticsearch (nedochádza k žiadnemu TCP handshake, pretože používa existujúce pripojenie). Trvalo to 18 ms.
Zatiaľ je všetko v poriadku a časy zhruba zodpovedajú očakávaným oneskoreniam (20-30 ms pri meraní od klienta).
Modrý úsek však trvá 86 ms. Čo sa v nej deje? S paketom 333 naša služba odoslala požiadavku HTTP GET na /latest/meta-data/iam/security-credentialsa hneď po ňom cez rovnaké pripojenie TCP ďalšia požiadavka GET na /latest/meta-data/iam/security-credentials/arn:...
Zistili sme, že sa to opakovalo pri každej požiadavke počas sledovania. Rozlíšenie DNS je v našich kontajneroch skutočne trochu pomalšie (vysvetlenie tohto javu je celkom zaujímavé, ale nechám si ho na samostatný článok). Ukázalo sa, že príčinou dlhých oneskorení boli volania na službu AWS Instance Metadata pri každej požiadavke.
Hypotéza 2: zbytočné volania do AWS
Oba koncové body patria do . Naša mikroservis používa túto službu pri spustení Elasticsearch. Obe výzvy sú súčasťou základného autorizačného procesu. Koncový bod, ku ktorému sa pristupuje pri prvej požiadavke, vydá rolu IAM priradenú k inštancii.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleDruhá požiadavka žiada druhý koncový bod o dočasné povolenia pre túto inštanciu:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Klient ich môže používať krátkodobo a musí pravidelne získavať nové certifikáty (predtým Expiration). Model je jednoduchý: AWS z bezpečnostných dôvodov často strieda dočasné kľúče, ale klienti ich môžu na niekoľko minút ukladať do vyrovnávacej pamäte, aby kompenzovali výkonnostnú penalizáciu spojenú so získavaním nových certifikátov.
AWS Java SDK by mala prevziať zodpovednosť za organizáciu tohto procesu, ale z nejakého dôvodu sa tak nestane.
Po hľadaní problémov na GitHub sme narazili na problém . Pomohla nám určiť smer, ktorým ďalej „kopať“.
AWS SDK aktualizuje certifikáty, keď nastane jedna z nasledujúcich podmienok:
- Dátum spotreby (
Expiration) Spadnúť doEXPIRATION_THRESHOLD, pevne zakódované na 15 minút. - Od posledného pokusu o obnovenie certifikátov uplynulo viac času ako
REFRESH_THRESHOLD, pevne zakódované na 60 minút.
Aby sme videli skutočný dátum vypršania platnosti certifikátov, ktoré dostávame, spustili sme vyššie uvedené príkazy cURL z kontajnera aj z inštancie EC2. Doba platnosti certifikátu prijatého z kontajnera sa ukázala byť oveľa kratšia: presne 15 minút.
Teraz je všetko jasné: na prvú žiadosť naša služba dostala dočasné certifikáty. Keďže neboli platné viac ako 15 minút, AWS SDK sa ich pri následnej žiadosti rozhodne aktualizovať. A to sa stalo pri každej žiadosti.
Prečo sa doba platnosti certifikátov skrátila?
Metaúdaje inštancie AWS sú navrhnuté tak, aby fungovali s inštanciami EC2, nie s Kubernetes. Na druhej strane sme nechceli meniť rozhranie aplikácie. Na to sme použili - nástroj, ktorý pomocou agentov na každom uzle Kubernetes umožňuje používateľom (inžinierom nasadzujúcim aplikácie do klastra) priraďovať roly IAM kontajnerom v podoch, ako keby to boli EC2 inštancie. KIAM zachytáva hovory služby AWS Instance Metadata a spracováva ich zo svojej vyrovnávacej pamäte, pričom ich predtým prijal od AWS. Z pohľadu aplikácie sa nič nemení.
KIAM dodáva krátkodobé certifikáty pod. To dáva zmysel, ak vezmeme do úvahy, že priemerná životnosť modulu je kratšia ako životnosť inštancie EC2. Predvolená doba platnosti certifikátov .
V dôsledku toho, ak prekryjete obe predvolené hodnoty na seba, nastáva problém. Platnosť každého certifikátu poskytnutého aplikácii vyprší po 15 minútach. AWS Java SDK si však vynúti obnovenie každého certifikátu, ktorému zostáva menej ako 15 minút do dátumu vypršania platnosti.
Výsledkom je, že dočasný certifikát je nútený obnovovať s každou požiadavkou, čo znamená niekoľko volaní rozhrania AWS API a spôsobuje výrazné zvýšenie latencie. V AWS Java SDK sme našli , ktorý spomína podobný problém.
Riešenie sa ukázalo ako jednoduché. Jednoducho sme prekonfigurovali KIAM tak, aby požadoval certifikáty s dlhšou dobou platnosti. Akonáhle sa to stalo, požiadavky začali prúdiť bez účasti služby AWS Metadata a latencia klesla na ešte nižšie úrovne ako v EC2.
Závery
Na základe našich skúseností s migráciami jedným z najčastejších zdrojov problémov nie sú chyby v Kubernetes alebo iných prvkoch platformy. Nerieši ani žiadne zásadné nedostatky v mikroslužbách, ktoré prenášame. Problémy často vznikajú jednoducho preto, že spájame rôzne prvky.
Miešame komplexné systémy, ktoré spolu nikdy predtým neinteragovali, pričom očakávame, že spolu vytvoria jeden väčší systém. Bohužiaľ, čím viac prvkov, tým väčší priestor pre chyby, tým vyššia entropia.
V našom prípade vysoká latencia nebola výsledkom chýb alebo zlých rozhodnutí v Kubernetes, KIAM, AWS Java SDK alebo v našej mikroslužbe. Bol výsledkom kombinácie dvoch nezávislých predvolených nastavení: jedno v KIAM, druhé v AWS Java SDK. Ak sa to vezme samostatne, oba parametre dávajú zmysel: aktívna politika obnovy certifikátu v AWS Java SDK a krátka doba platnosti certifikátov v KAIM. Ale keď ich spojíte dokopy, výsledky sa stanú nepredvídateľnými. Dve nezávislé a logické riešenia nemusia mať pri kombinácii zmysel.
PS od prekladateľa
Viac o architektúre nástroja KIAM na integráciu AWS IAM s Kubernetes nájdete na od jeho tvorcov.
Prečítajte si aj na našom blogu:
- «»;
- «»;
- «»;
- «".
Zdroj: hab.com
