

Ahojte všetci! Volám sa Golov Nikolay. Predtým som pracoval v Avito a šesť rokov som spravoval dátovú platformu, to znamená, že som pracoval na všetkých databázach: analytickej (Vertica, ClickHouse), streamingovej a OLTP (Redis, Tarantool, VoltDB, MongoDB, PostgreSQL). Za tento čas som sa zaoberal veľkým množstvom databáz – veľmi odlišných a nezvyčajných a s neštandardnými prípadmi ich použitia.
Momentálne pracujem v ManyChat. V podstate ide o startup – nový, ambiciózny a rýchlo rastúci. A keď som prvýkrát vstúpil do spoločnosti, vyvstala klasická otázka: „Čo by si mal teraz mladý startup vziať z trhu DBMS a databáz?“
V tomto článku, na základe mojej správy na , na túto otázku odpoviem. Video verzia správy je k dispozícii na adrese .
Všeobecne známe databázy 2020
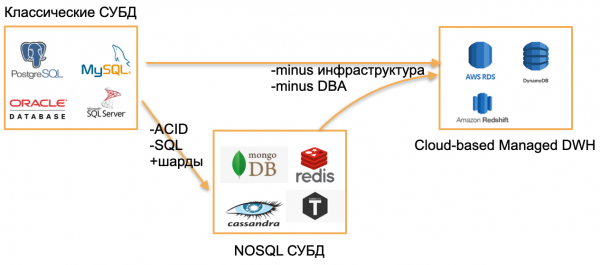
Je rok 2020, poobzeral som sa okolo seba a videl som tri typy databáz.
Prvý typ - klasické OLTP databázy: PostgreSQL, SQL Server, Oracle, MySQL. Boli napísané už dávno, ale sú stále aktuálne, pretože sú tak známe komunite vývojárov.
Druhý typ je základy od "nuly". Pokúsili sa vzdialiť od klasických vzorov tým, že opustili SQL, tradičné štruktúry a ACID, pridali vstavané sharding a ďalšie atraktívne funkcie. Ide napríklad o Cassandru, MongoDB, Redis alebo Tarantool. Všetky tieto riešenia chceli ponúknuť trhu niečo zásadne nové a obsadili svoje miesto, pretože sa ukázali ako mimoriadne vhodné pre určité úlohy. Tieto databázy budem označovať zastrešujúcim pojmom NOSQL.
„Nulky“ skončili, zvykli sme si na databázy NOSQL a svet z môjho pohľadu urobil ďalší krok – spravované databázy. Tieto databázy majú rovnaké jadro ako klasické OLTP databázy alebo nové NoSQL. Nepotrebujú však DBA a DevOps a bežia na spravovanom hardvéri v cloude. Pre vývojára je to „len základ“, ktorý niekde funguje, ale nikoho nezaujíma, ako je nainštalovaný na server, kto server nakonfiguroval a kto ho aktualizuje.
Príklady takýchto databáz:
- AWS RDS je spravovaný obal pre PostgreSQL/MySQL.
- DynamoDB je AWS analógom databázy založenej na dokumentoch, podobne ako Redis a MongoDB.
- Amazon Redshift je riadená analytická databáza.
Ide v podstate o staré databázy, no vybudované v riadenom prostredí, bez nutnosti práce s hardvérom.
Poznámka. Príklady sú pre prostredie AWS, ale ich analógy existujú aj v Microsoft Azure, Google Cloud alebo Yandex.Cloud.
čo je na tom nové? V roku 2020 nič z toho.
Koncept bez servera
Skutočnou novinkou na trhu v roku 2020 sú riešenia bez servera alebo bez servera.
Pokúsim sa vysvetliť, čo to znamená, na príklade bežnej služby alebo backendovej aplikácie.
Na nasadenie bežnej backendovej aplikácie si kúpime alebo prenajmeme server, skopírujeme naň kód, zverejníme koncový bod vonku a pravidelne platíme za prenájom, elektrinu a služby dátového centra. Toto je štandardná schéma.
Existuje nejaký iný spôsob? So službami bez servera môžete.
Na čo sa zameriava tento prístup: neexistuje server, dokonca neexistuje ani prenájom virtuálnej inštancie v cloude. Ak chcete službu nasadiť, skopírujte kód (funkcie) do úložiska a publikujte ho do koncového bodu. Potom jednoducho zaplatíme za každé volanie tejto funkcie, pričom úplne ignorujeme hardvér, kde sa vykonáva.
Pokúsim sa tento prístup ilustrovať obrázkami.
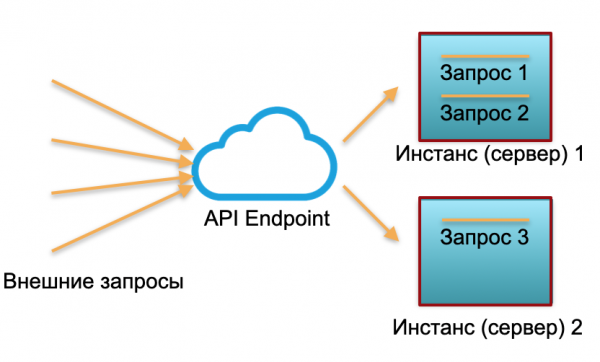
Klasické nasadenie. Máme službu s určitým zaťažením. Vyvolávame dve inštancie: fyzické servery alebo inštancie v AWS. Externé požiadavky sa odosielajú do týchto inštancií a tam sa spracúvajú.
Ako môžete vidieť na obrázku, servery nie sú likvidované rovnako. Jedna je využitá na 100 %, existujú dve požiadavky a jedna je len na 50 % – čiastočne nečinná. Ak neprídu tri požiadavky, ale 30, celý systém nebude schopný zvládnuť záťaž a začne sa spomaľovať.
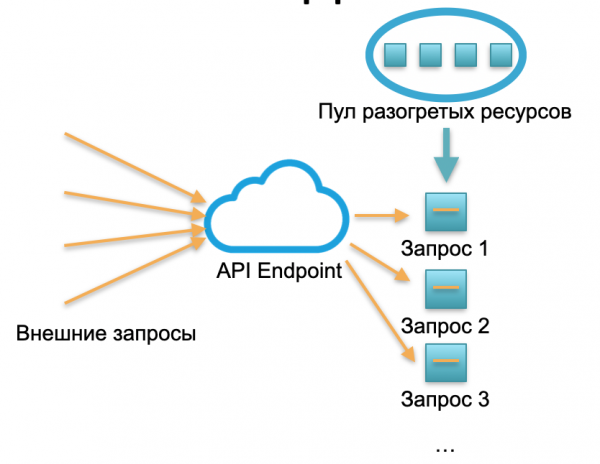
Bezserverové nasadenie. V prostredí bez serverov takáto služba nemá inštancie ani servery. Existuje určitá zásoba vyhrievaných zdrojov - malé pripravené kontajnery Docker s nasadeným funkčným kódom. Systém prijíma externé požiadavky a pre každú z nich bezserverový rámec vytvorí malý kontajner s kódom: spracuje túto konkrétnu požiadavku a kontajner zabije.
Jedna požiadavka - jeden kontajner zdvihnutý, 1000 požiadaviek - 1000 kontajnerov. A nasadenie na hardvérové servery je už dielom poskytovateľa cloudu. Je úplne skrytý bezserverovým rámcom. V tomto koncepte platíme za každý hovor. Napríklad jeden hovor prišiel za deň – zaplatili sme za jeden hovor, prišlo milión za minútu – zaplatili sme milión. Alebo v sekunde sa to tiež stane.
Koncept publikovania funkcie bez servera je vhodný pre službu bez stavu. A ak potrebujete (štátnu) stavovú službu, potom k službe pridáme databázu. V tomto prípade, keď ide o prácu so stavom, každá stavová funkcia jednoducho zapisuje a číta z databázy. Navyše z databázy ktoréhokoľvek z troch typov opísaných na začiatku článku.
Aké je spoločné obmedzenie všetkých týchto databáz? Ide o náklady na neustále používaný cloud alebo hardvérový server (alebo niekoľko serverov). Nezáleží na tom, či používame klasickú alebo spravovanú databázu, či máme Devops a admina alebo nie, stále platíme za prenájom hardvéru, elektriny a dátového centra 24/7. Ak máme klasickú základňu, platíme za pána a otroka. Ak ide o vysoko zaťaženú databázu, platíme za 10, 20 alebo 30 serverov a platíme neustále.
Prítomnosť trvalo rezervovaných serverov v štruktúre nákladov bola predtým vnímaná ako nutné zlo. Bežné databázy majú aj iné ťažkosti, ako sú limity na počet pripojení, obmedzenia škálovania, geograficky distribuovaný konsenzus – dajú sa nejako vyriešiť v určitých databázach, ale nie naraz a nie ideálne.
Bezserverová databáza - teória
Otázka roku 2020: Je možné urobiť databázu aj bez servera? Každý už počul o backende bez servera... skúsime urobiť databázu bez servera?
Znie to zvláštne, pretože databáza je stavová služba, ktorá nie je príliš vhodná pre infraštruktúru bez servera. Zároveň je stav databázy veľmi veľký: gigabajty, terabajty av analytických databázach dokonca petabajty. Nie je také ľahké ho zdvihnúť v ľahkých kontajneroch Docker.
Na druhej strane takmer všetky moderné databázy obsahujú obrovské množstvo logiky a komponentov: transakcie, koordináciu integrity, procedúry, relačné závislosti a veľa logiky. Pre dosť veľa databázovej logiky stačí malý stav. Gigabajty a terabajty priamo využíva iba malá časť databázovej logiky, ktorá sa podieľa na priamom vykonávaní dotazov.
V súlade s tým myšlienka znie: ak časť logiky umožňuje vykonávanie bez štátnej príslušnosti, prečo nerozdeliť základňu na časti Stateful a Stateless.
Bez serverov pre riešenia OLAP
Pozrime sa na praktických príkladoch, ako môže vyzerať rozrezanie databázy na časti Stateful a Stateless.
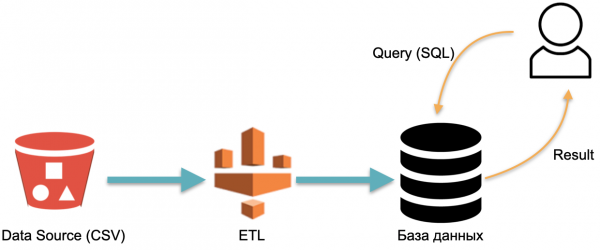
Máme napríklad analytickú databázu: externé údaje (červený valec vľavo), proces ETL, ktorý načíta údaje do databázy, a analytik, ktorý do databázy posiela SQL dotazy. Ide o klasickú schému prevádzky dátového skladu.
V tejto schéme sa ETL podmienečne vykonáva raz. Potom treba neustále platiť za servery, na ktorých beží databáza údajmi naplnenými ETL, aby bolo na čo posielať dopyty.
Pozrime sa na alternatívny prístup implementovaný v AWS Athena Serverless. Neexistuje žiadny trvalo vyhradený hardvér, na ktorom sa ukladajú stiahnuté dáta. Namiesto tohto:
- Používateľ odošle dotaz SQL spoločnosti Athena. Optimalizátor Athena analyzuje dotaz SQL a hľadá v úložisku metadát (Metadáta) špecifické údaje potrebné na vykonanie dotazu.
- Optimalizátor na základe zozbieraných údajov stiahne potrebné údaje z externých zdrojov do dočasného úložiska (dočasná databáza).
- SQL dotaz od užívateľa sa vykoná v dočasnom úložisku a výsledok sa vráti užívateľovi.
- Dočasné úložisko sa vymaže a zdroje sa uvoľnia.
V tejto architektúre platíme len za proces vykonania požiadavky. Žiadne požiadavky - žiadne náklady.
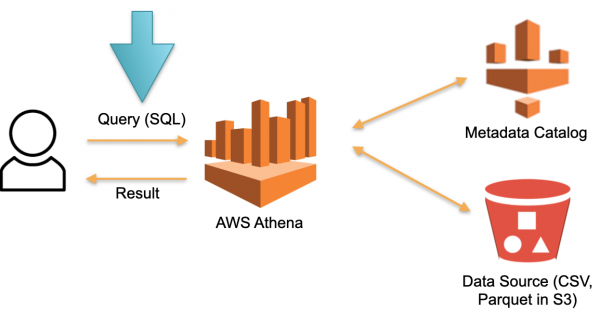
Toto je pracovný prístup a je implementovaný nielen v Athena Serverless, ale aj v Redshift Spectrum (v AWS).
Príklad Athena ukazuje, že databáza Serverless pracuje na skutočných dopytoch s desiatkami a stovkami terabajtov údajov. Stovky terabajtov budú vyžadovať stovky serverov, ale my za ne nemusíme platiť – platíme za požiadavky. Rýchlosť každej požiadavky je (veľmi) nízka v porovnaní so špecializovanými analytickými databázami ako Vertica, ale neplatíme za prestoje.
Takáto databáza je použiteľná pre zriedkavé analytické ad-hoc dopyty. Napríklad, keď sa spontánne rozhodneme otestovať hypotézu na nejakom gigantickom množstve údajov. Athena je pre tieto prípady ako stvorená. Pre bežné požiadavky je takýto systém drahý. V takom prípade uložte údaje do vyrovnávacej pamäte v nejakom špecializovanom riešení.
Bez servera pre riešenia OLTP
Predchádzajúci príklad sa zaoberal úlohami OLAP (analytické). Teraz sa pozrime na úlohy OLTP.
Predstavme si škálovateľný PostgreSQL alebo MySQL. Vybudujme bežnú riadenú inštanciu PostgreSQL alebo MySQL s minimálnymi zdrojmi. Keď inštancia dostane väčšiu záťaž, pripojíme ďalšie repliky, ktorým rozdelíme časť záťaže na čítanie. Ak neexistujú žiadne požiadavky alebo zaťaženie, repliky vypneme. Prvá inštancia je predloha a zvyšok sú repliky.
Táto myšlienka je implementovaná v databáze s názvom Aurora Serverless AWS. Princíp je jednoduchý: požiadavky z externých aplikácií prijíma zástupná flotila. Keď vidí nárast zaťaženia, prideľuje výpočtové zdroje z vopred zahriatych minimálnych inštancií - pripojenie sa vytvorí čo najrýchlejšie. Zakázanie inštancií prebieha rovnakým spôsobom.
V rámci Aurory existuje koncept Aurora Capacity Unit, ACU. Toto je (podmienečne) inštancia (server). Každý konkrétny ACU môže byť master alebo slave. Každá jednotka kapacity má vlastnú RAM, procesor a minimálny disk. Podľa toho je jeden majster, zvyšok sú repliky len na čítanie.
Počet spustených jednotiek Aurora Capacity Unit je konfigurovateľný parameter. Minimálne množstvo môže byť jedna alebo nula (v tomto prípade databáza nefunguje, ak nie sú žiadne požiadavky).
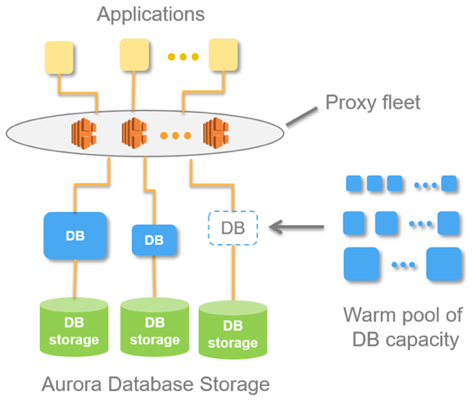
Keď základňa dostane požiadavky, flotila proxy zvýši Aurora CapacityUnits, čím sa zvýšia výkonové zdroje systému. Schopnosť zvyšovať a znižovať zdroje umožňuje systému „žonglovať“ so zdrojmi: automaticky zobrazovať jednotlivé ACU (nahrádzať ich novými) a zavádzať všetky aktuálne aktualizácie stiahnutých zdrojov.
Základňa Aurora Serverless dokáže škálovať zaťaženie pri čítaní. Dokumentácia to však priamo nehovorí. Môže to mať pocit, že môžu zdvihnúť multimajstra. Neexistuje žiadna mágia.
Táto databáza je vhodná na to, aby ste sa vyhli míňaniu veľkých množstiev peňazí na systémy s nepredvídateľným prístupom. Napríklad pri vytváraní stránok MVP alebo marketingových vizitiek zvyčajne neočakávame stabilnú záťaž. Preto, ak nie je prístup, za prípady neplatíme. Keď dôjde k neočakávanej záťaži, napríklad po konferencii alebo reklamnej kampani, davy ľudí navštívia stránku a záťaž sa dramaticky zvýši, Aurora Serverless automaticky prevezme túto záťaž a rýchlo pripojí chýbajúce zdroje (ACU). Potom konferencia prebehne, všetci zabudnú na prototyp, servery (ACU) stmavnú a náklady klesnú na nulu - pohodlné.
Toto riešenie nie je vhodné pre stabilné vysoké zaťaženie, pretože nezvyšuje zaťaženie pri písaní. Všetky tieto pripojenia a odpojenia zdrojov sa vyskytujú v takzvanom „bode mierky“ - v bode v čase, keď databáza nie je podporovaná transakciou alebo dočasnými tabuľkami. Napríklad do týždňa sa bod škály nemusí stať a základňa funguje na rovnakých zdrojoch a jednoducho sa nemôže rozširovať ani zmenšovať.
Neexistuje žiadna mágia - je to obyčajný PostgreSQL. Ale proces pridávania strojov a ich odpájania je čiastočne automatizovaný.
Dizajnovo bez serverov
Aurora Serverless je stará databáza prepísaná pre cloud, aby sa využili niektoré z výhod Serverless. A teraz vám poviem o základni, ktorá bola pôvodne napísaná pre cloud, pre bezserverový prístup – Serverless-by-design. Bol okamžite vyvinutý bez predpokladu, že bude bežať na fyzických serveroch.
Tento základ sa nazýva Snowflake. Má tri kľúčové bloky.
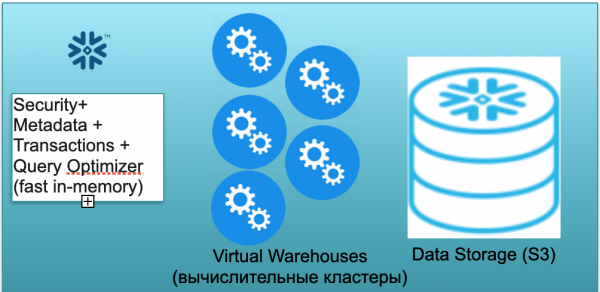
Prvým je blok metadát. Ide o rýchlu službu v pamäti, ktorá rieši problémy so zabezpečením, metadátami, transakciami a optimalizáciou dotazov (zobrazené na obrázku vľavo).
Druhým blokom je sada virtuálnych výpočtových klastrov na výpočty (na obrázku je sada modrých kruhov).
Tretím blokom je systém ukladania dát založený na S3. S3 je bezrozmerné úložisko objektov v AWS, niečo ako bezrozmerný Dropbox pre podnikanie.
Pozrime sa, ako funguje Snowflake za predpokladu studeného štartu. To znamená, že existuje databáza, údaje sa do nej načítajú, neprebiehajú žiadne dotazy. V súlade s tým, ak neexistujú žiadne požiadavky na databázu, potom sme aktivovali rýchlu službu metaúdajov v pamäti (prvý blok). A máme tu úložisko S3, kde sa ukladajú tabuľkové dáta, rozdelené na takzvané mikropartície. Pre jednoduchosť: ak tabuľka obsahuje transakcie, potom mikropartície sú dni transakcií. Každý deň je samostatný mikrooddiel, samostatný súbor. A keď databáza funguje v tomto režime, platíte len za miesto, ktoré zaberajú dáta. Okrem toho je sadzba za sedadlo veľmi nízka (najmä s prihliadnutím na značnú kompresiu). Služba metadát tiež funguje nepretržite, ale na optimalizáciu dopytov nepotrebujete veľa zdrojov a službu možno považovať za shareware.
Teraz si predstavme, že používateľ prišiel do našej databázy a odoslal SQL dotaz. SQL dotaz je okamžite odoslaný do služby Metadata na spracovanie. Podľa toho táto služba po prijatí požiadavky analyzuje požiadavku, dostupné údaje, používateľské oprávnenia a ak je všetko v poriadku, zostaví plán spracovania požiadavky.
Potom služba iniciuje spustenie výpočtového klastra. Výpočtový klaster je zhluk serverov, ktoré vykonávajú výpočty. To znamená, že ide o klaster, ktorý môže obsahovať 1 server, 2 servery, 4, 8, 16, 32 - toľko, koľko chcete. Vyhodíte požiadavku a okamžite sa spustí spustenie tohto klastra. Naozaj to trvá sekundy.
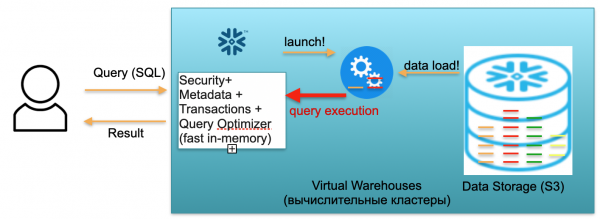
Potom, po spustení klastra, sa mikropartície potrebné na spracovanie vašej požiadavky začnú kopírovať do klastra z S3. To znamená, že si predstavme, že na vykonanie SQL dotazu potrebujete dva oddiely z jednej tabuľky a jeden z druhej. V tomto prípade sa do klastra skopírujú iba tri potrebné oddiely a nie všetky tabuľky. To je dôvod, prečo a práve preto, že všetko je umiestnené v jednom dátovom centre a prepojené veľmi rýchlymi kanálmi, celý proces prenosu prebieha veľmi rýchlo: v sekundách, veľmi zriedka v minútach, pokiaľ nehovoríme o nejakých obludných požiadavkách. V súlade s tým sa mikropartície skopírujú do výpočtového klastra a po dokončení sa na tomto výpočtovom klastri vykoná SQL dotaz. Výsledkom tejto požiadavky môže byť jeden riadok, niekoľko riadkov alebo tabuľka – sú odoslané externe používateľovi, aby si ju mohol stiahnuť, zobraziť vo svojom BI nástroji alebo inak použiť.
Každý SQL dotaz dokáže nielen čítať agregáty z predtým načítaných údajov, ale aj načítať/generovať nové údaje v databáze. To znamená, že to môže byť dopyt, ktorý napríklad vloží nové záznamy do inej tabuľky, čo vedie k tomu, že sa vo výpočtovom klastri objaví nový oddiel, ktorý sa zase automaticky uloží do jedného úložiska S3.
Scenár popísaný vyššie, od príchodu používateľa po zvýšenie klastra, načítanie údajov, vykonanie dotazov, získanie výsledkov, je platený sadzbou za minúty používania zvýšeného virtuálneho výpočtového klastra, virtuálneho skladu. Sadzba sa líši v závislosti od zóny AWS a veľkosti klastra, ale v priemere je to niekoľko dolárov za hodinu. Klaster štyroch počítačov je dvakrát drahší ako klaster dvoch strojov a klaster ôsmich strojov je stále dvakrát tak drahý. K dispozícii sú možnosti 16, 32 strojov v závislosti od zložitosti požiadaviek. Ale platíte len za tie minúty, kedy cluster skutočne beží, pretože keď nie sú žiadne požiadavky, dáte ruky preč a po 5-10 minútach čakania (konfigurovateľný parameter) zhasne sám, uvoľnite zdroje a staňte sa slobodnými.
Úplne reálny scenár je, keď odošlete požiadavku, klaster vyskočí, relatívne povedané, za minútu, počíta ďalšiu minútu, potom päť minút do vypnutia a nakoniec zaplatíte za sedem minút prevádzky tohto klastra a nie mesiace a roky.
Prvý scenár opísal použitie Snowflake v nastavení pre jedného používateľa. Teraz si predstavme, že používateľov je veľa, čo je bližšie k reálnemu scenáru.
Povedzme, že máme veľa analytikov a správ Tableau, ktorí neustále bombardujú našu databázu veľkým počtom jednoduchých analytických SQL dotazov.
Okrem toho, povedzme, že máme vynaliezavých Data Scientists, ktorí sa snažia robiť s dátami obludné veci, operujú s desiatkami terabajtov, analyzujú miliardy a bilióny riadkov dát.
Pre dva typy pracovného zaťaženia opísané vyššie vám Snowflake umožňuje vytvoriť niekoľko nezávislých výpočtových klastrov rôznych kapacít. Navyše tieto výpočtové klastre fungujú nezávisle, ale so spoločnými konzistentnými údajmi.
Pre veľký počet ľahkých dopytov môžete vytvoriť 2-3 malé klastre, každý približne 2 počítače. Toto správanie je možné implementovať okrem iného pomocou automatických nastavení. Takže povieš: „Snehová vločka, zdvihni malý zhluk. Ak sa zaťaženie na ňom zvýši nad určitý parameter, zdvihnite podobný druhý, tretí. Keď záťaž začne ustupovať, uhaste prebytok.“ Takže bez ohľadu na to, koľko analytikov príde a začne si prezerať správy, každý má dostatok zdrojov.
Zároveň, ak analytici spia a nikto sa nepozerá na správy, zhluky môžu úplne stmavnúť a prestanete za ne platiť.
Zároveň v prípade náročných dopytov (od Data Scientists) môžete vytvoriť jeden veľmi veľký klaster pre 32 počítačov. Tento klaster bude tiež zaplatený iba za tie minúty a hodiny, keď tam beží vaša obrovská požiadavka.
Vyššie popísaná príležitosť umožňuje rozdeliť nielen 2, ale aj viac druhov záťaže do klastrov (ETL, monitoring, materializácia reportov,...).
Poďme si zhrnúť Snowflake. Základ spája krásny nápad a realizovateľnú realizáciu. V ManyChat používame Snowflake na analýzu všetkých údajov, ktoré máme. Nemáme tri klastre ako v príklade, ale 5 až 9 rôznych veľkostí. Na niektoré úlohy máme konvenčné 16-strojové, 2-strojové a tiež supermalé 1-strojové. Úspešne rozložia náklad a umožňujú nám veľa ušetriť.
Databáza úspešne škáluje zaťaženie čítania a zápisu. To je obrovský rozdiel a obrovský prielom v porovnaní s rovnakou „Aurorou“, ktorá prenášala iba zaťaženie čítania. Snowflake vám umožňuje škálovať vaše pracovné zaťaženie pri písaní pomocou týchto výpočtových klastrov. To znamená, ako som už spomínal, v ManyChate používame niekoľko klastrov, malé a supermalé klastre slúžia najmä na ETL, na načítanie dát. A analytici už žijú na stredných klastroch, ktoré záťaž ETL absolútne neovplyvňuje, takže pracujú veľmi rýchlo.
V súlade s tým je databáza vhodná pre úlohy OLAP. Nanešťastie však ešte nie je použiteľný pre pracovné zaťaženia OLTP. Po prvé, táto databáza je stĺpcová so všetkými z toho vyplývajúcimi dôsledkami. Po druhé, samotný prístup, kedy pri každej požiadavke v prípade potreby zdvihnete výpočtový klaster a zahltíte ho dátami, bohužiaľ zatiaľ nie je dostatočne rýchly na zaťaženie OLTP. Čakanie sekúnd na úlohy OLAP je normálne, ale pre úlohy OLTP je to neprijateľné; 100 ms by bolo lepších alebo 10 ms by bolo ešte lepšie.
Celkový
Bezserverová databáza je možná rozdelením databázy na bezstavovú a stavovú časť. Možno ste si všimli, že vo všetkých vyššie uvedených príkladoch časť Stateful relatívne vzaté ukladá mikrooddiely v S3 a Stateless je optimalizátor, ktorý pracuje s metaúdajmi a rieši problémy s bezpečnosťou, ktoré sa dajú nastoliť ako nezávislé ľahké bezstavové služby.
Vykonávanie SQL dotazov môže byť vnímané aj ako služby ľahkého stavu, ktoré sa môžu objaviť v režime bez servera, ako sú napríklad počítačové klastre Snowflake, stiahnuť iba potrebné údaje, spustiť dotaz a „vypnúť“.
Bezserverové databázy na úrovni produkcie sú už dostupné na použitie, fungujú. Tieto databázy bez servera sú už pripravené zvládnuť úlohy OLAP. Bohužiaľ, pre úlohy OLTP sa používajú... s nuansami, pretože existujú obmedzenia. Na jednej strane je to mínus. Ale na druhej strane je to príležitosť. Možno jeden z čitateľov nájde spôsob, ako urobiť databázu OLTP úplne bez servera, bez obmedzení Aurory.
Dúfam, že vás to zaujalo. Budúcnosť je bez serverov :)
Zdroj: hab.com
