

Ahojte všetci! Som backendový vývojár, ktorý píše mikroslužby v jazyku Java + Spring. Pracujem v jednom z interných tímov vývoja produktov v Tinkoff.

V našom tíme často vyvstáva otázka optimalizácie dopytov v DBMS. Vždy chcete byť o niečo rýchlejší, no nie vždy si vystačíte s premyslene vytvorenými indexmi – musíte hľadať nejaké riešenia. Pri jednom z týchto potuliek po webe pri hľadaní rozumných optimalizácií pri práci s databázami som našiel , autor knihy SQL Performance Explained. Toto je zriedkavý typ blogu, v ktorom si môžete prečítať všetky články za sebou.
Rád by som vám preložil krátky článok od Marcusa. Možno ho do istej miery nazvať manifestom, ktorý sa snaží upozorniť na starý, no stále aktuálny problém výkonu ofsetovej operácie podľa štandardu SQL.
Miestami autora doplním vysvetlivkami a komentármi. Všetky takéto miesta budem označovať ako „približne“. pre väčšiu prehľadnosť
Malý úvod
Myslím si, že veľa ľudí vie, aká problematická a pomalá je práca s výberom stránok cez offset. Vedeli ste, že sa dá celkom jednoducho nahradiť efektívnejším dizajnom?
Kľúčové slovo offset teda povie databáze, aby preskočila prvých n záznamov v požiadavke. Databáza však ešte potrebuje načítať týchto prvých n záznamov z disku v danom poradí (poznámka: aplikujte triedenie, ak je zadané) a až potom bude možné vrátiť záznamy od n+1. Najzaujímavejšie je, že problém nie je v konkrétnej implementácii v DBMS, ale v pôvodnej definícii podľa normy:
…riadky sú najprv zoradené podľa a potom obmedzená zrušením počtu riadkov špecifikovaných v od začiatku...
-SQL:2016, Časť 2, 4.15.3 Odvodené tabuľky (poznámka: v súčasnosti najpoužívanejší štandard)
Kľúčovým bodom je, že offset má jediný parameter - počet záznamov, ktoré sa majú preskočiť, a to je všetko. Podľa tejto definície môže DBMS iba získať všetky záznamy a potom vyradiť nepotrebné. Je zrejmé, že táto definícia ofsetu nás núti robiť prácu navyše. A nezáleží na tom, či je to SQL alebo NoSQL.
Len trochu viac bolesti
Problémy s ofsetom sa tým nekončia a tu je dôvod. Ak medzi čítanie dvoch strán údajov z disku iná operácia vloží nový záznam, čo sa stane v tomto prípade?
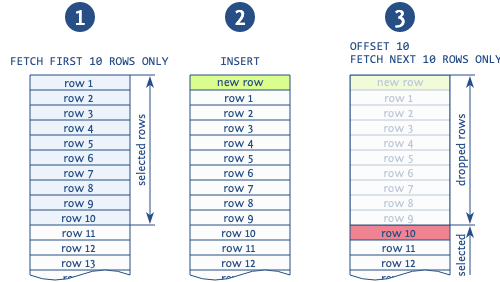
Keď sa offset používa na preskočenie záznamov z predchádzajúcich strán, v situácii pridávania nového záznamu medzi čítaniami rôznych stránok s najväčšou pravdepodobnosťou získate duplikáty (poznámka: je to možné, keď čítame stránku po stránke pomocou poradia podľa konštrukcie, potom v strede nášho výstupu môže dostať nový záznam).
Obrázok jasne znázorňuje túto situáciu. Základňa prečíta prvých 10 záznamov, po ktorých sa vloží nový záznam, ktorý posunie všetky načítané záznamy o 1. Potom základňa preberie novú stranu z ďalších 10 záznamov a nezačne od 11., ako by mala, ale od 10., duplikuje tento záznam. S používaním tohto výrazu sú spojené aj ďalšie anomálie, no toto je najbežnejšie.
Ako sme už zistili, nejde o problémy konkrétneho DBMS alebo ich implementácií. Problém je v definovaní stránkovania podľa štandardu SQL. Hovoríme DBMS, ktorú stránku má načítať alebo koľko záznamov má preskočiť. Databáza jednoducho nie je schopná optimalizovať takúto požiadavku, pretože na to je príliš málo informácií.
Je tiež potrebné objasniť, že to nie je problém s konkrétnym kľúčovým slovom, ale skôr so sémantikou dopytu. Existuje niekoľko ďalších syntaxí, ktoré sú svojou problematickou povahou totožné:
- Kľúčové slovo offset je ako už bolo spomenuté.
- Konštrukcia limitu dvoch kľúčových slov [offset] (hoci samotný limit nie je taký zlý).
- Filtrovanie podľa dolných hraníc na základe číslovania riadkov (napríklad row_number(), rownum atď.).
Všetky tieto výrazy vám jednoducho povedia, koľko riadkov sa má preskočiť, žiadne ďalšie informácie alebo kontext.
Ďalej v tomto článku sa kľúčové slovo offset používa ako súhrn všetkých týchto možností.
Život bez OFFSETU
Teraz si predstavme, aký by bol náš svet bez všetkých týchto problémov. Ukazuje sa, že život bez ofsetu nie je taký ťažký: pomocou výberu môžete vybrať iba tie riadky, ktoré sme ešte nevideli (poznámka: teda tie, ktoré neboli na predchádzajúcej strane), pomocou podmienky kde.
V tomto prípade vychádzame zo skutočnosti, že výbery sa vykonávajú na objednanom súbore (starý dobrý poriadok). Keďže máme usporiadanú množinu, môžeme pomocou pomerne jednoduchého filtra získať iba údaje, ktoré sú za posledným záznamom predchádzajúcej stránky:
SELECT ...
FROM ...
WHERE ...
AND id < ?last_seen_id
ORDER BY id DESC
FETCH FIRST 10 ROWS ONLYTo je celý princíp tohto prístupu. Samozrejme, veci sú zábavnejšie, keď triedite podľa mnohých stĺpcov, ale myšlienka je stále rovnaká. Je dôležité poznamenať, že tento dizajn je použiteľný pre mnohých -rozhodnutia.
Tento prístup sa nazýva metóda vyhľadávania alebo stránkovanie sady kľúčov. Rieši problém s pohyblivým výsledkom (poznámka: situácia s písaním medzi čítaniami popísaná vyššie) a samozrejme to, čo všetci milujeme, funguje rýchlejšie a stabilnejšie ako klasický offset. Stabilita spočíva v tom, že čas spracovania požiadavky sa nezvyšuje úmerne s počtom požadovanej tabuľky (poznámka: ak sa chcete dozvedieť viac o práci rôznych prístupov k stránkovaniu, môžete . Nájdete tam aj porovnávacie benchmarky pre rôzne metódy).
Jedna z diapozitívov že stránkovanie kľúčmi, samozrejme, nie je všemocné – má svoje obmedzenia. Najvýraznejšie je, že nemá schopnosť čítať náhodné stránky (poznámka: nekonzistentne). V dobe nekonečného rolovania (pozn.: na frontende) to však nie je až taký problém. Zadanie čísla stránky na klikanie je v dizajne UI aj tak zlé rozhodnutie (pozn.: názor autora článku).
A čo nástroje?
Stránkovanie na klávesoch často nie je vhodné kvôli nedostatku inštrumentálnej podpory pre túto metódu. Väčšina vývojových nástrojov, vrátane rôznych rámcov, neumožňuje presne si vybrať, ako sa bude stránkovanie vykonávať.
Situáciu sťažuje fakt, že opísaný spôsob vyžaduje end-to-end podporu v použitých technológiách – od DBMS až po vykonanie AJAX požiadavky v prehliadači s nekonečným rolovaním. Namiesto zadávania iba čísla strany teraz musíte zadať sadu kľúčov pre všetky strany naraz.
Postupne však rastie počet rámcov, ktoré podporujú stránkovanie na kľúčoch. Tu je to, čo momentálne máme:
- pre Java;
- pre Ruby;
- и pre Djanga;
- pre Python;
- — API kritérií pre implementáciu JPA;
- pre Perl;
- , mapovač pre Node.js .
(Poznámka: niektoré odkazy boli odstránené z dôvodu, že v čase prekladu neboli niektoré knižnice aktualizované od roku 2017-2018. V prípade záujmu si môžete pozrieť pôvodný zdroj.)
Práve v tejto chvíli je potrebná vaša pomoc. Ak vyvíjate alebo podporujete rámec, ktorý akokoľvek využíva stránkovanie, potom vás žiadam, naliehavo vás žiadam, aby ste poskytli natívnu podporu pre stránkovanie kľúčov. Ak máte otázky alebo potrebujete pomoc, rád vám pomôžem (, , ) (poznámka: z mojej skúsenosti s Marcusom môžem povedať, že je naozaj nadšený zo šírenia tejto témy).
Ak používate hotové riešenia, o ktorých si myslíte, že si zaslúžia podporu pre stránkovanie pomocou kľúčov, vytvorte požiadavku alebo dokonca ponúknite hotové riešenie, ak je to možné. Môžete tiež odkazovať na tento článok.
Záver
Dôvod, prečo nie je taký jednoduchý a užitočný prístup, akým je stránkovanie kľúčmi, nie je rozšírený v tom, že je technicky náročný na implementáciu alebo vyžaduje veľké úsilie. Hlavným dôvodom je, že mnohí sú zvyknutí vidieť a pracovať s ofsetom - tento prístup je diktovaný samotnou normou.
Výsledkom je, že len málo ľudí premýšľa o zmene prístupu k stránkovaniu, a preto sa inštrumentálna podpora zo strany rámcov a knižníc vyvíja slabo. Preto, ak je vám blízka myšlienka a cieľ stránkovania bez ofsetu, pomôžte ju šíriť!
Zdroj:
Autor: Markus Winand
Zdroj: hab.com
