

Pavel Selivanov, architekt riešení Southbridge a učiteľ Slurm, vystúpil s prezentáciou na DevOpsConf 2019. Táto prednáška je súčasťou jednej z tém hĺbkového kurzu o Kubernetes „Slurm Mega“.
sa koná v Moskve 18. – 20. novembra.
— Moskva, 22. – 24. novembra.
vždy k dispozícii.

Pod strihom je prepis správy.
Dobré popoludnie, kolegovia a tí, ktorí s nimi súcitíte. Dnes budem hovoriť o bezpečnosti.
Vidím, že dnes je v hale veľa ochrankárov. Vopred sa vám ospravedlňujem, ak budem používať výrazy zo sveta bezpečnosti nie presne tak, ako je to u vás zvykom.
Stalo sa, že asi pred šiestimi mesiacmi som narazil na jeden verejný klaster Kubernetes. Verejné znamená, že existuje n-tý počet menných priestorov; v týchto menných priestoroch sú používatelia izolovaní vo svojom mennom priestore. Všetci títo používatelia patria do rôznych spoločností. Predpokladalo sa, že tento klaster by sa mal použiť ako CDN. To znamená, že vám dajú klaster, dajú vám tam používateľa, prejdete tam do svojho menného priestoru, rozmiestnite svoje fronty.
Moja predchádzajúca spoločnosť sa snažila predať takúto službu. A bol som požiadaný, aby som prepichol klaster, aby som zistil, či je toto riešenie vhodné alebo nie.
Prišiel som do tohto klastra. Dostal som obmedzené práva, obmedzený menný priestor. Chlapci tam pochopili, čo je bezpečnosť. Čítali o Role-based access control (RBAC) v Kubernetes – a prekrútili to tak, že som nemohol spúšťať moduly oddelene od nasadení. Nepamätám si problém, ktorý som sa snažil vyriešiť spustením modulu bez nasadenia, ale naozaj som chcel spustiť iba modul. Pre šťastie som sa rozhodol pozrieť, aké práva mám v klastri, čo môžem robiť, čo nie a čo tam pokazili. Zároveň vám poviem, čo nesprávne nakonfigurovali v RBAC.
Stalo sa, že za dve minúty som dostal admina do ich klastra, pozrel som si všetky susedné menné priestory, videl som tam bežiace produkčné fronty spoločností, ktoré už službu zakúpili a nasadili. Sotva som sa dokázal zastaviť v tom, aby som k niekomu prišiel a nedal na hlavnú stránku nejakú nadávku.
Na príkladoch vám poviem, ako som to urobil a ako sa pred tým chrániť.
Najprv mi však dovoľte predstaviť sa. Volám sa Pavel Selivanov. Som architekt v Southbridge. Rozumiem Kubernetes, DevOps a všetkým možným veciam. Inžinieri Southbridge a ja to všetko staviame a ja sa radím.
Okrem našich hlavných aktivít sme v poslednom období rozbehli projekty s názvom Slurms. Snažíme sa našu schopnosť pracovať s Kubernetes trochu priblížiť širokým masám, naučiť ďalších ľudí pracovať aj s K8.
O čom budem dnes hovoriť? Téma správy je zrejmá – o bezpečnosti klastra Kubernetes. Chcem však hneď povedať, že táto téma je veľmi rozsiahla - a preto chcem okamžite objasniť, o čom určite nebudem hovoriť. Nebudem hovoriť o otrepaných výrazoch, ktoré už boli na internete použité stokrát. Všetky druhy RBAC a certifikátov.
Budem hovoriť o tom, čo mňa a mojich kolegov bolí na bezpečnosti v klastri Kubernetes. Tieto problémy vidíme medzi poskytovateľmi, ktorí poskytujú klastre Kubernetes, ako aj medzi klientmi, ktorí k nám prichádzajú. A to aj od klientov, ktorí k nám prichádzajú z iných poradenských admin spoločností. To znamená, že rozsah tragédie je skutočne veľmi veľký.
Existujú doslova tri body, o ktorých dnes budem hovoriť:
- Používateľské práva vs práva pod. Používateľské práva a práva pod nie sú to isté.
- Zhromažďovanie informácií o klastri. Ukážem, že môžete zbierať všetky potrebné informácie z klastra bez toho, aby ste v tomto klastri mali špeciálne práva.
- DoS útok na klaster. Ak nemôžeme zbierať informácie, budeme môcť v každom prípade vytvoriť klaster. Budem hovoriť o DoS útokoch na prvky riadenia klastrov.
Ďalšou všeobecnou vecou, ktorú spomeniem, je to, na čom som to všetko testoval, na čom určite môžem povedať, že to všetko funguje.
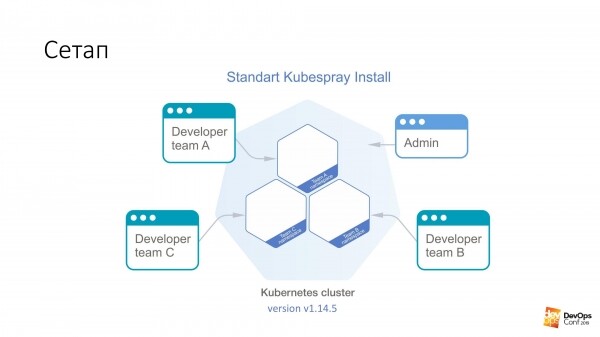
Za základ berieme inštaláciu klastra Kubernetes pomocou Kubespray. Ak niekto nevie, toto je vlastne súbor rolí pre Ansible. Pri našej práci ho používame neustále. Dobré je, že ho môžete váľať kdekoľvek – môžete ho navaliť na kusy železa alebo niekde do obláčika. Jeden spôsob inštalácie funguje v princípe na všetko.
V tomto klastri budem mať Kubernetes v1.14.5. Celý klaster Cube, ktorý budeme uvažovať, je rozdelený do menných priestorov, každý menný priestor patrí samostatnému tímu a členovia tohto tímu majú prístup ku každému mennému priestoru. Nemôžu ísť do rôznych menných priestorov, iba do svojich vlastných. Existuje však určitý účet správcu, ktorý má práva na celý klaster.
Sľúbil som, že prvá vec, ktorú urobíme, je získanie administrátorských práv pre klaster. Potrebujeme špeciálne pripravený modul, ktorý rozbije klaster Kubernetes. Všetko, čo musíme urobiť, je aplikovať ho na klaster Kubernetes.
kubectl apply -f pod.yamlTento modul dorazí k jednému z majstrov klastra Kubernetes. A potom nám klaster šťastne vráti súbor s názvom admin.conf. V Cube tento súbor ukladá všetky správcovské certifikáty a zároveň konfiguruje klastrové API. Takto ľahko sa dá získať prístup správcu k, myslím, 98 % klastrov Kubernetes.
Opakujem, tento modul vytvoril jeden vývojár vo vašom klastri, ktorý má prístup k nasadeniu svojich návrhov do jedného malého menného priestoru, všetko je upnuté RBAC. Nemal žiadne práva. Certifikát sa však napriek tomu vrátil.
А теперь о специально подготовленном поде. Запускаем на любом образе. Для примера возьмём debian:jessie.
Máme túto vec:
tolerations:
- effect: NoSchedule
operator: Exists
nodeSelector:
node-role.kubernetes.io/master: "" Čo je tolerancia? Mastery v klastri Kubernetes sú zvyčajne označené niečím, čo sa nazýva poškvrna. A podstatou tejto „infekcie“ je, že hovorí, že struky nemožno priradiť k hlavným uzlom. Nikto sa však neobťažuje naznačiť v žiadnom struku, že je tolerantný voči „infekcii“. Sekcia Tolerancia len hovorí, že ak má niektorý uzol NoSchedule, tak náš uzol je tolerantný voči takejto infekcii – a nie sú žiadne problémy.
Ďalej hovoríme, že náš spod je nielen tolerantný, ale chce sa špecificky zamerať aj na pána. Pretože majstri majú to najchutnejšie, čo potrebujeme – všetky certifikáty. Preto hovoríme nodeSelector – a na masteroch máme štandardné označenie, ktoré vám umožňuje vybrať zo všetkých uzlov v klastri presne tie uzly, ktoré sú master.
S týmito dvoma úsekmi určite príde k majstrovi. A bude mu dovolené tam žiť.
Ale len prísť k pánovi nám nestačí. Toto nám nič nedá. Ďalej tu máme tieto dve veci:
hostNetwork: true
hostPID: true Špecifikujeme, že náš modul, ktorý spustíme, bude žiť v mennom priestore jadra, v mennom priestore siete a v mennom priestore PID. Po spustení modulu na hlavnom zariadení bude môcť vidieť všetky skutočné živé rozhrania tohto uzla, počúvať všetku premávku a vidieť PID všetkých procesov.
Potom ide o maličkosti. Vezmite si etcd a prečítajte si, čo chcete.
Najzaujímavejšia vec je táto funkcia Kubernetes, ktorá je tam štandardne prítomná.
volumeMounts:
- mountPath: /host
name: host
volumes:
- hostPath:
path: /
type: Directory
name: host A jeho podstatou je, že v pod môžeme povedať, že spustíme aj bez práv na tento klaster, že chceme vytvoriť zväzok typu hostPath. To znamená prebrať cestu od hostiteľa, na ktorom spustíme – a brať ju ako zväzok. A potom to nazývame menom: hostiteľ. Celú túto cestu hostiteľa namontujeme do modulu. V tomto príklade do adresára /host.
Ešte raz to zopakujem. Povedali sme modulu, aby prišiel k hlavnému modulu, dostal tam hostiteľskú sieť a hostPID – a namontoval celý koreňový adresár hlavného modulu do tohto modulu.
Chápete, že v Debiane beží bash a tento bash beží pod rootom. To znamená, že sme práve dostali root na master bez toho, aby sme mali akékoľvek práva v klastri Kubernetes.
Potom je celou úlohou prejsť do podadresára /host /etc/kubernetes/pki, ak sa nemýlim, vyzdvihnúť tam všetky hlavné certifikáty klastra a podľa toho sa stať správcom klastra.
Ak sa na to pozriete takto, toto sú niektoré z najnebezpečnejších práv v moduloch – bez ohľadu na to, aké práva má používateľ:
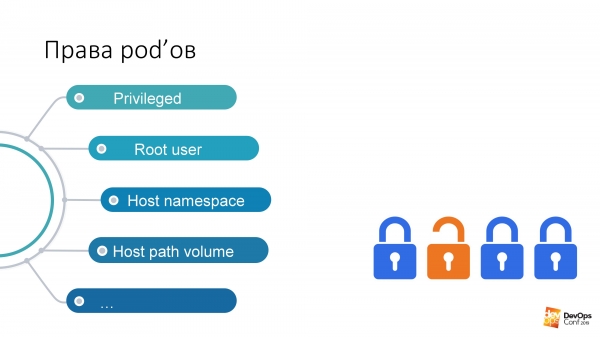
Ak mám práva na spustenie pod v nejakom mennom priestore klastra, potom má táto pod predvolene tieto práva. Môžem spustiť privilegované moduly, a to sú vo všeobecnosti všetky práva, prakticky root na uzle.
Môj obľúbený je Root user. A Kubernetes má túto možnosť Run As Non-Root. Ide o typ ochrany pred hackermi. Viete, čo je to „moldavský vírus“? Ak sa zrazu stanete hackerom a prídete do môjho klastra Kubernetes, potom sa my, úbohí správcovia, pýtame: „Uveďte, prosím, vo svojich moduloch, s ktorými hacknete môj klaster, spustite ho ako non-root. V opačnom prípade sa stane, že proces spustíte vo svojom pod pod rootom a bude pre vás veľmi ľahké hacknúť ma. Prosím, chráňte sa pred sebou."
Objem cesty hostiteľa je podľa môjho názoru najrýchlejší spôsob, ako získať požadovaný výsledok z klastra Kubernetes.
Ale čo s tým všetkým robiť?
Myšlienka, ktorá by mala prísť na každého normálneho správcu, ktorý sa stretne s Kubernetes, je: „Áno, povedal som vám, Kubernetes nefunguje. Sú v nej diery. A celá kocka je svinstvo.“ V skutočnosti existuje niečo ako dokumentácia a ak sa tam pozriete, je tam sekcia .
Toto je objekt yaml – môžeme ho vytvoriť v klastri Kubernetes – ktorý kontroluje bezpečnostné aspekty konkrétne v popise modulov. To znamená, že v skutočnosti riadi práva na používanie akejkoľvek hostiteľskej siete, hostPID, určitých typov zväzkov, ktoré sú v moduloch pri spustení. To všetko sa dá opísať pomocou bezpečnostnej politiky Pod.
Najzaujímavejšia vec na bezpečnostnej politike pod je, že v klastri Kubernetes nie sú všetky inštalátory PSP len tak popísané, sú jednoducho predvolene vypnuté. Bezpečnostná politika pod je povolená pomocou doplnku pre prístup.
Dobre, nasaďte bezpečnostnú politiku pod do klastra, povedzme, že máme v mennom priestore nejaké moduly služieb, ku ktorým majú prístup iba správcovia. Povedzme, že vo všetkých ostatných prípadoch majú moduly obmedzené práva. Pretože s najväčšou pravdepodobnosťou vývojári nemusia vo vašom klastri spúšťať privilegované moduly.
A zdá sa, že u nás je všetko v poriadku. A náš klaster Kubernetes nemožno hacknúť za dve minúty.
Je tu problém. S najväčšou pravdepodobnosťou, ak máte klaster Kubernetes, monitorovanie je nainštalované vo vašom klastri. Dokonca by som zašiel tak ďaleko, že by som predpovedal, že ak má váš klaster monitorovanie, bude sa volať Prometheus.
To, čo vám poviem, bude platiť pre operátora Prometheus aj Prometheus dodávaný v čistej forme. Otázkou je, že ak nemôžem tak rýchlo získať správcu do klastra, potom to znamená, že musím hľadať viac. A môžem hľadať pomocou vášho sledovania.
Asi každý číta rovnaké články na Habrého a monitoring sa nachádza v mennom priestore monitoringu. Helm chart sa volá zhruba rovnako pre každého. Hádam, že ak spravíte helm install stable/prometheus, skončíte s približne rovnakými názvami. A s najväčšou pravdepodobnosťou ani nebudem musieť hádať názov DNS vo vašom klastri. Pretože je to štandardné.
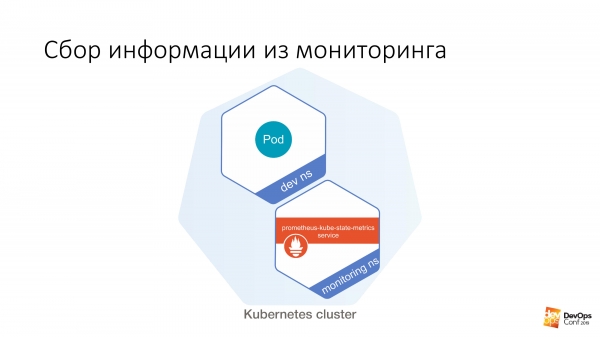
Ďalej tu máme určitý dev ns, v ktorom môžete spustiť určitý modul. A potom z tohto modulu je veľmi ľahké urobiť niečo také:
$ curl http://prometheus-kube-state-metrics.monitoring prometheus-kube-state-metrics je jedným z exportérov Prometheus, ktorý zhromažďuje metriky zo samotného Kubernetes API. Je tam veľa údajov, čo beží vo vašom klastri, čo to je, aké s tým máte problémy.
Ako jednoduchý príklad:
kube_pod_container_info{namespace=“kube-system”,pod=”kube-apiserver-k8s- 1″,container=”kube-apiserver”,image=
"gcr.io/google-containers/kube-apiserver:v1.14.5"
,image_id=»docker-pullable://gcr.io/google-containers/kube- apiserver@sha256:e29561119a52adad9edc72bfe0e7fcab308501313b09bf99df4a96 38ee634989″,container_id=»docker://7cbe7b1fea33f811fdd8f7e0e079191110268f2 853397d7daf08e72c22d3cf8b»} 1
Zadaním jednoduchej žiadosti o zvlnenie z neprivilegovaného modulu môžete získať nasledujúce informácie. Ak neviete, akú verziu Kubernetes používate, ľahko vám to povie.
A najzaujímavejšie je, že okrem prístupu kube-state-metrics môžete rovnako jednoducho pristupovať priamo k samotnému Prometheusu. Odtiaľ môžete zbierať metriky. Odtiaľ môžete dokonca vytvárať metriky. Aj teoreticky si takýto dotaz môžete postaviť z klastra v Prometheus, ktorý ho jednoducho vypne. A vaše monitorovanie prestane fungovať z klastra úplne.
A tu vyvstáva otázka, či nejaký externý monitoring sleduje váš monitoring. Práve som dostal príležitosť fungovať v klastri Kubernetes bez akýchkoľvek následkov pre mňa. Ani nebudete vedieť, že tam pôsobím, keďže tam už nie je žiadny monitoring.
Rovnako ako v prípade PSP sa zdá, že problém je v tom, že všetky tieto fantastické technológie - Kubernetes, Prometheus - jednoducho nefungujú a sú plné dier. Nie naozaj.
Existuje taká vec - .
Ak ste normálny admin, tak o Network Policy s najväčšou pravdepodobnosťou viete, že toto je len ďalší yaml, ktorých je už v klastri veľa. A niektoré sieťové zásady určite nie sú potrebné. A aj keď si prečítate, čo je sieťová politika, že ide o yaml firewall Kubernetes, umožňuje vám to obmedziť prístupové práva medzi mennými priestormi, medzi podmi, potom ste sa určite rozhodli, že firewall vo formáte yaml v Kubernetes je založený na nasledujúcich abstrakciách ... Nie, nie. To určite nie je potrebné.
Aj keď ste svojim bezpečnostným špecialistom nepovedali, že pomocou Kubernetes si môžete vytvoriť veľmi jednoduchý a jednoduchý firewall, a to veľmi podrobný. Ak to ešte nevedia a neobťažujú vás: „No, dajte mi, dajte mi...“ Potom v každom prípade potrebujete sieťovú politiku na zablokovanie prístupu k niektorým servisným miestam, ktoré možno stiahnuť z vášho klastra bez akéhokoľvek oprávnenia.
Ako v príklade, ktorý som uviedol, môžete získať metriky stavu kube z ľubovoľného priestoru názvov v klastri Kubernetes bez toho, aby ste na to mali akékoľvek práva. Sieťové politiky uzavreli prístup zo všetkých ostatných menných priestorov do monitorovacieho menného priestoru a to je všetko: žiadny prístup, žiadne problémy. Vo všetkých existujúcich grafoch, štandardnom Prometheus aj Prometheus, ktorý je u operátora, existuje jednoducho možnosť v hodnotách kormidla jednoducho pre nich povoliť sieťové politiky. Stačí ich zapnúť a budú fungovať.
Je tu naozaj jeden problém. Ako normálny bradatý správca ste sa s najväčšou pravdepodobnosťou rozhodli, že sieťové pravidlá nie sú potrebné. A po prečítaní najrôznejších článkov o zdrojoch ako Habr ste sa rozhodli, že flanel, najmä s režimom hostiteľskej brány, je to najlepšie, čo si môžete vybrať.
Čo robiť?
Môžete skúsiť presadiť sieťové riešenie, ktoré máte vo svojom klastri Kubernetes, skúste ho nahradiť niečím funkčnejším. Napríklad pre rovnaké Calico. Chcem však hneď povedať, že úloha zmeniť sieťové riešenie v pracovnom klastri Kubernetes je celkom netriviálna. Dvakrát som to riešil (oba razy však teoreticky), ale dokonca sme si ukázali, ako sa to robí na Slurms. Našim študentom sme ukázali, ako zmeniť sieťové riešenie v klastri Kubernetes. V zásade sa môžete pokúsiť zabezpečiť, aby nedošlo k prestojom na produkčnom klastri. Ale asi sa ti to nepodarí.
A problém je v skutočnosti vyriešený veľmi jednoducho. V klastri sú certifikáty a viete, že platnosť vašich certifikátov vyprší o rok. Nuž, a zvyčajne normálne riešenie s certifikátmi v klastri – prečo si robíme starosti, vytvoríme v blízkosti nový klaster, ten starý necháme zhniť a všetko nanovo nasadíme. Je pravda, že keď to zhnije, budeme musieť jeden deň sedieť, ale tu je nový zhluk.
Keď zdvihnete nový klaster, súčasne vložte Calico namiesto flanelu.
Čo robiť, ak sú vaše certifikáty vydávané na sto rokov a klaster sa nechystáte premiestniť? Existuje niečo ako Kube-RBAC-Proxy. Toto je veľmi skvelý vývoj, ktorý vám umožňuje vložiť sa ako kontajner postranného vozíka do ľubovoľného modulu v klastri Kubernetes. A v skutočnosti pridáva autorizáciu do tohto modulu prostredníctvom RBAC samotného Kubernetes.
Je tu jeden problém. Predtým bolo toto riešenie Kube-RBAC-Proxy zabudované do Prometheus operátora. Ale potom bol preč. Moderné verzie sa teraz spoliehajú na skutočnosť, že máte sieťovú politiku a zatvoríte ju pomocou nich. A preto budeme musieť graf trochu prepísať. V skutočnosti, ak idete do , su tam priklady ako to pouzivat ako sajdkar a grafy bude treba minimalne prepisovat.
Je tu ešte jeden malý problém. Prometheus nie je jediný, kto rozdáva svoje metriky len tak hocikomu. Všetky naše klastrové komponenty Kubernetes sú tiež schopné vrátiť svoje vlastné metriky.
Ale ako som už povedal, ak nemôžete získať prístup ku klastra a zhromažďovať informácie, môžete aspoň trochu ublížiť.
Takže rýchlo ukážem dva spôsoby, ako môže byť klaster Kubernetes zničený.
Budete sa smiať, keď vám to poviem, toto sú dva prípady zo skutočného života.
Metóda jedna. Vyčerpanie zdrojov.
Spustíme ďalší špeciálny modul. Bude mať takúto sekciu.
resources:
requests:
cpu: 4
memory: 4Gi Ako viete, požiadavky predstavujú množstvo CPU a pamäte, ktoré je rezervované na hostiteľovi pre konkrétne moduly s požiadavkami. Ak máme štvorjadrový hostiteľ v klastri Kubernetes a štyri CPU pody tam prídu s požiadavkami, znamená to, že k tomuto hostiteľovi už nebudú môcť prísť žiadne pody s požiadavkami.
Ak spustím takýto modul, spustím príkaz:
$ kubectl scale special-pod --replicas=...Potom sa nikto iný nebude môcť nasadiť do klastra Kubernetes. Pretože všetky uzly vyčerpajú požiadavky. A tým zastavím váš klaster Kubernetes. Ak to urobím večer, dokážem nasadenia zastaviť na pomerne dlhú dobu.
Ak sa znova pozrieme na dokumentáciu Kubernetes, uvidíme túto vec s názvom Limit Range. Nastavuje prostriedky pre objekty klastra. Môžete napísať objekt Limit Range v yaml, použiť ho na určité menné priestory - a potom v tomto mennom priestore môžete povedať, že máte predvolené, maximálne a minimálne zdroje pre pody.
Pomocou takejto veci môžeme obmedziť používateľov v konkrétnych produktových menných priestoroch tímov v možnosti označovať na svojich moduloch najrôznejšie škaredé veci. Ale nanešťastie, aj keď používateľovi poviete, že nemôže spúšťať moduly s požiadavkami na viac ako jeden procesor, existuje taký úžasný príkaz na škálovanie alebo môžu škálovať cez palubnú dosku.
A odtiaľ pochádza metóda číslo dva. Spúšťame 11 111 111 111 111 modulov. To je jedenásť miliárd. Nie je to preto, že som si také číslo vymyslel, ale preto, že som ho sám videl.
Skutočný príbeh. Neskoro večer som sa chystal opustiť kanceláriu. Vidím skupinu vývojárov, ktorí sedia v rohu a horúčkovito niečo robia so svojimi notebookmi. Idem za chalanmi a pýtam sa: "Čo sa ti stalo?"
O niečo skôr, okolo deviatej večer, sa jeden z vývojárov chystal na odchod domov. A rozhodol som sa: "Teraz zmenším svoju aplikáciu na jednu." Jeden som stlačil, no internet sa trochu spomalil. Znova stlačil ten, stlačil ten a klikol na Enter. Štukal som do všetkého, čo sa dalo. Potom ožil internet – a všetko sa začalo zmenšovať na toto číslo.
Je pravda, že tento príbeh sa neodohral na Kubernetes, v tom čase to bol Nomad. Skončilo to tým, že po hodine našich pokusov zastaviť Nomada od vytrvalých pokusov o škálovanie, Nomad odpovedal, že neprestane škálovať a nebude robiť nič iné. "Som unavený, odchádzam." A schúlil sa.
Prirodzene som sa pokúsil urobiť to isté na Kubernetes. Kubernetes nebol spokojný s jedenástimi miliardami toboliek, povedal: „Nemôžem. Presahuje vnútorné chrániče úst." Ale 1 000 000 000 strukov by mohlo.
V reakcii na jednu miliardu sa kocka nestiahla do seba. Naozaj sa začal škálovať. Čím ďalej proces šiel, tým viac času mu trvalo vytvorenie nových strúčikov. Proces však stále pokračoval. Jediný problém je, že ak môžem neobmedzene spúšťať pody vo svojom mennom priestore, tak aj bez požiadaviek a limitov môžem spustiť toľko podov s niektorými úlohami, že pomocou týchto úloh sa uzly začnú sčítavať v pamäti, v CPU. Keď spustím toľko modulov, informácie z nich by mali ísť do úložiska, teda atď. A keď tam príde príliš veľa informácií, úložisko sa začne vracať príliš pomaly – a Kubernetes začne byť nudné.
A ešte jeden problém... Ako viete, ovládacie prvky Kubernetes nie sú jedna centrálna vec, ale niekoľko komponentov. Ide najmä o správcu kontroléra, plánovača atď. Všetci títo chlapci začnú robiť zároveň zbytočnú, hlúpu prácu, ktorá časom začne zaberať viac a viac času. Správca radiča vytvorí nové moduly. Plánovač sa pre nich pokúsi nájsť nový uzol. S najväčšou pravdepodobnosťou vám čoskoro dôjdu nové uzly vo vašom klastri. Klaster Kubernetes začne pracovať čoraz pomalšie.
Ale rozhodol som sa ísť ešte ďalej. Ako viete, v Kubernetes existuje taká vec, ktorá sa nazýva služba. V predvolenom nastavení vo vašich klastroch služba s najväčšou pravdepodobnosťou funguje pomocou tabuliek IP.
Ak napríklad spustíte jednu miliardu modulov a potom pomocou skriptu prinútite Kubernetis vytvoriť nové služby:
for i in {1..1111111}; do
kubectl expose deployment test --port 80
--overrides="{"apiVersion": "v1",
"metadata": {"name": "nginx$i"}}";
done Na všetkých uzloch klastra bude približne súčasne generovaných viac a viac nových pravidiel iptables. Okrem toho sa pre každú službu vygeneruje jedna miliarda pravidiel iptables.
Skontroloval som to celé na niekoľkých tisícoch, až desiatich. A problém je, že už pri tomto prahu je dosť problematické urobiť ssh do uzla. Pretože pakety, ktoré prechádzajú toľkými reťazcami, sa začínajú cítiť nie veľmi dobre.
A aj toto je všetko vyriešené pomocou Kubernetes. Existuje taký objekt kvóty prostriedkov. Nastavuje počet dostupných zdrojov a objektov pre menný priestor v klastri. V každom mennom priestore klastra Kubernetes môžeme vytvoriť objekt yaml. Pomocou tohto objektu môžeme povedať, že máme pre tento menný priestor pridelený určitý počet požiadaviek a limitov a potom môžeme povedať, že v tomto mennom priestore je možné vytvoriť 10 služieb a 10 podov. A jediný developer sa môže po večeroch aspoň udusiť. Kubernetes mu povie: „Nemôžete zmenšiť svoje moduly na toto množstvo, pretože zdroj prekračuje kvótu.“ To je všetko, problém vyriešený. .
V tejto súvislosti vzniká jeden problematický bod. Cítite, aké ťažké je vytvoriť menný priestor v Kubernetes. Aby sme ho vytvorili, musíme vziať do úvahy veľa vecí.
Kvóta zdrojov + limitný rozsah + RBAC
• Vytvorte menný priestor
• Vo vnútri vytvorte limitný rozsah
• Vytvorte vnútornú kvótu zdrojov
• Vytvorte servisný účet pre CI
• Vytvorte rolové väzby pre CI a používateľov
• Voliteľne spustite potrebné servisné moduly
Preto by som rád využil túto príležitosť a podelil sa o svoj vývoj. Existuje niečo, čo sa nazýva operátor SDK. Toto je spôsob, akým môže klaster Kubernetes písať operátory. Môžete písať príkazy pomocou Ansible.
Najprv to bolo napísané v Ansible a potom som videl, že existuje operátor SDK a prepísal som rolu Ansible na operátor. Tento príkaz vám umožňuje vytvoriť objekt v klastri Kubernetes nazývaný príkaz. Vo vnútri príkazu vám umožňuje opísať prostredie pre tento príkaz v jazyku yaml. A v rámci tímového prostredia nám umožňuje popísať, že alokujeme toľko zdrojov.
petite .
A na záver. Čo s tým všetkým robiť?
Najprv. Bezpečnostná politika pod je dobrá. A napriek tomu, že žiadny z inštalátorov Kubernetes ich dodnes nepoužíva, stále ich musíte používať vo svojich klastroch.
Sieťová politika nie je len ďalšou zbytočnou funkciou. To je v klastri skutočne potrebné.
LimitRange/ResourceQuota – je čas to využiť. Začali sme to používať už dávno a dlho som si bol istý, že to používajú všetci. Ukázalo sa, že je to zriedkavé.
Okrem toho, čo som spomenul počas správy, existujú nezdokumentované funkcie, ktoré vám umožňujú zaútočiť na klaster. Vydané nedávno .
Niektoré veci sú také smutné a bolestivé. Napríklad za určitých podmienok môžu cubelety v klastri Kubernetes poskytnúť obsah adresára warlocks neoprávnenému používateľovi.
Existuje návod, ako zreprodukovať všetko, čo som vám povedal. Existujú súbory s produkčnými príkladmi toho, ako vyzerajú zásady ResourceQuota a Pod. A tohto všetkého sa môžete dotknúť.
Ďakujem všetkým.
Zdroj: hab.com
