


Živjo vsem! Moje ime je Dmitrij Samsonov in delam kot vodilni sistemski administrator pri Odnoklassniki. Imamo več kot 7 fizičnih strežnikov, 11 vsebnikov v našem oblaku in 200 aplikacij, ki v različnih konfiguracijah tvorijo 700 različnih grozdov. Velika večina strežnikov deluje CentOS 7.
14. avgusta 2018 so bile objavljene informacije o ranljivosti FragmentSmack
() in SegmentSmack (). Gre za ranljivosti z vektorjem omrežnega napada in dokaj visoko oceno (7.5), ki grozi z zavrnitvijo storitve (DoS) zaradi izčrpanosti virov (CPU). Popravek jedra za FragmentSmack takrat ni bil predlagan, poleg tega se je pojavil veliko pozneje kot objava informacij o ranljivosti. Za odstranitev SegmentSmack je bilo predlagano posodobitev jedra. Sam paket posodobitev je bil izdan še isti dan, preostala je le še namestitev.
Ne, sploh nismo proti posodabljanju jedra! Vendar pa obstajajo nianse ...
Kako posodobimo jedro v proizvodnji
Na splošno nič zapletenega:
- Prenos paketov;
- Namestite jih na več strežnikov (vključno s strežniki, ki gostijo naš oblak);
- Prepričajte se, da ni nič pokvarjeno;
- Prepričajte se, da so vse standardne nastavitve jedra uporabljene brez napak;
- Počakajte nekaj dni;
- Preverite delovanje strežnika;
- Preklopite namestitev novih strežnikov na novo jedro;
- Posodobite vse strežnike po podatkovnih centrih (en podatkovni center naenkrat, da zmanjšate vpliv na uporabnike v primeru težav);
- Znova zaženite vse strežnike.
Ponovimo za vse veje jeder, ki jih imamo. Trenutno je:
- Zaloga CentOS 7 3.10 - za večino običajnih strežnikov;
- Vanilla 4.19 - za naše , ker potrebujemo BFQ, BBR itd.;
- Elrepo kernel-ml 5.2 - za , ker se je 4.19 včasih obnašal nestabilno, vendar so potrebne iste funkcije.
Kot ste morda uganili, ponovni zagon več tisoč strežnikov traja najdlje. Ker niso vse ranljivosti kritične za vse strežnike, ponovno zaženemo samo tiste, ki so neposredno dostopni iz interneta. V oblaku, da ne omejujemo fleksibilnosti, zunanje dostopnih vsebnikov ne vežemo na posamezne strežnike z novim jedrom, ampak ponovno zaženemo vse gostitelje brez izjeme. Na srečo je tam postopek enostavnejši kot pri običajnih strežnikih. Na primer, vsebniki brez stanja se lahko preprosto premaknejo na drug strežnik med ponovnim zagonom.
Dela pa je še veliko in lahko traja več tednov, v primeru težav z novo različico pa tudi več mesecev. Napadalci to zelo dobro razumejo, zato potrebujejo načrt B.
FragmentSmack/SegmentSmack. Rešitev
Na srečo za nekatere ranljivosti obstaja tak načrt B in imenuje se rešitev. Najpogosteje je to sprememba nastavitev jedra/aplikacije, ki lahko minimizira možni učinek ali popolnoma odpravi izkoriščanje ranljivosti.
V primeru FragmentSmack/SegmentSmack ta rešitev:
«Spremenite lahko privzeti vrednosti 4 MB in 3 MB v net.ipv4.ipfrag_high_thresh in net.ipv4.ipfrag_low_thresh (ter njunih ustreznih vrednostih za ipv6 net.ipv6.ipfrag_high_thresh in net.ipv6.ipfrag_low_thresh) na 256 kB oziroma 192 kB oz. nižje. Testi kažejo majhne do znatne padce porabe procesorja med napadom, odvisno od strojne opreme, nastavitev in pogojev. Vendar pa lahko pride do določenega vpliva na zmogljivost zaradi ipfrag_high_thresh=262144 bajtov, saj se lahko v čakalno vrsto za ponovno sestavljanje hkrati prilegata le dva 64K fragmenta. Obstaja na primer tveganje, da se aplikacije, ki delujejo z velikimi paketi UDP, pokvarijo".
Sami parametri opisano kot sledi:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
Nimamo velikih UDP-jev za proizvodne storitve. V LAN ni razdrobljenega prometa; v WAN je razdrobljen promet, vendar ne pomemben. Ni znakov - lahko uvedete rešitev!
FragmentSmack/SegmentSmack. Prva kri
Prva težava, na katero smo naleteli, je bila, da so oblačni vsebniki včasih le delno uporabili nove nastavitve (samo ipfrag_low_thresh), včasih pa jih sploh niso uporabili - preprosto so se zrušili na začetku. Težave ni bilo mogoče stabilno reproducirati (vse nastavitve so bile uporabljene ročno brez težav). Tudi razumeti, zakaj se vsebnik zruši na začetku, ni tako enostavno: napake niso bile najdene. Nekaj je bilo gotovo: povrnitev nastavitev reši težavo z zrušitvami vsebnika.
Zakaj ni dovolj, da uporabite Sysctl na gostitelju? Vsebnik živi v svojem namenskem omrežnem imenskem prostoru, torej vsaj v vsebniku se lahko razlikuje od gostitelja.
Kako natančno se nastavitve Sysctl uporabljajo v vsebniku? Ker so naši vsebniki neprivilegirani, ne boste mogli spremeniti nobene nastavitve Sysctl tako, da greste v sam vsebnik - preprosto nimate dovolj pravic. Za zagon vsebnikov je naš oblak takrat uporabljal Docker (zdaj ). Parametri novega vsebnika so bili posredovani Dockerju prek API-ja, vključno s potrebnimi nastavitvami Sysctl.
Med iskanjem po različicah se je izkazalo, da Docker API ne vrača vseh napak (vsaj v različici 1.10). Ko smo poskušali zagnati vsebnik prek »docker run«, smo končno videli vsaj nekaj:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
Vrednost parametra ni veljavna. Ampak zakaj? In zakaj ne velja le včasih? Izkazalo se je, da Docker ne zagotavlja vrstnega reda, v katerem so uporabljeni parametri Sysctl (zadnja testirana različica je 1.13.1), zato so včasih ipfrag_high_thresh poskušali nastaviti na 256K, ko je bil ipfrag_low_thresh še vedno 3M, kar pomeni, da je bila zgornja meja nižja od spodnje meje, kar je povzročilo napako.
Takrat smo že uporabljali lasten mehanizem za rekonfiguracijo vsebnika po zagonu (zamrznitev vsebnika po in izvajanje ukazov v imenskem prostoru vsebnika prek ), temu delu pa smo dodali tudi pisanje parametrov Sysctl. Problem je bil rešen.
FragmentSmack/SegmentSmack. Prva kri 2
Preden smo imeli čas razumeti uporabo rešitve Workaround v oblaku, so začele prihajati prve redke pritožbe uporabnikov. Takrat je minilo že nekaj tednov od začetka uporabe Workarounda na prvih strežnikih. Prvotna preiskava je pokazala, da so bile pritožbe prejete zoper posamezne storitve in ne na vse strežnike teh storitev. Problem je spet postal zelo negotov.
Najprej smo poskusili z razveljavitvijo nastavitev Sysctl, vendar to ni imelo učinka. Različne manipulacije z nastavitvami strežnika in aplikacije prav tako niso pomagale. Pomagal je ponovni zagon. Ponovni zagon za Linux tako nenaravno kot normalno stanje za delo z Windows V starih časih. Delovalo je, in to smo pripisali "napaki v jedru" pri uporabi novih nastavitev Sysctl. Kako neumno od nas ...
Tri tedne kasneje se je težava ponovila. Konfiguracija teh strežnikov je bila precej preprosta: Nginx v načinu proxy/balancer. Ni veliko prometa. Nova uvodna opomba: število napak 504 na odjemalcih se vsak dan povečuje (). Graf prikazuje število 504 napak na dan za to storitev:
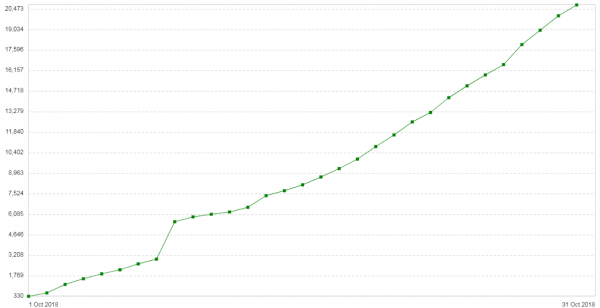
Vse napake so o istem ozadju – o tistem, ki je v oblaku. Graf porabe pomnilnika za fragmente paketa na tem ozadju je bil videti takole:
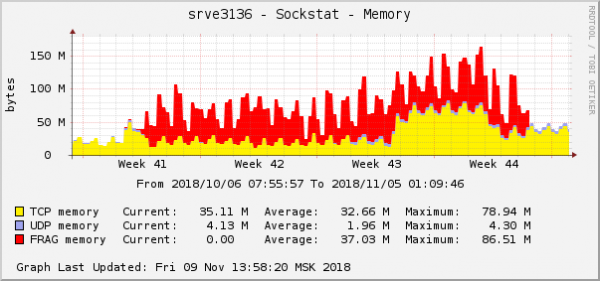
To je ena najbolj očitnih manifestacij težave v grafih operacijskega sistema. V oblaku je bila istočasno odpravljena še ena težava omrežja z nastavitvami QoS (nadzor prometa). Na grafu porabe pomnilnika za fragmente paketov je bilo videti popolnoma enako:
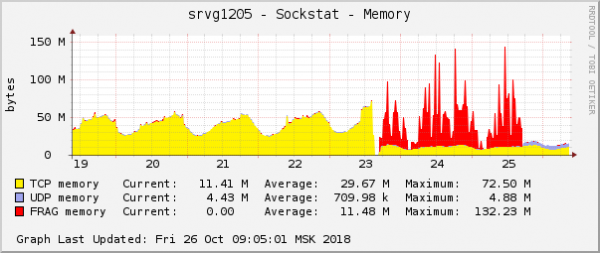
Predpostavka je bila preprosta: če sta na grafih videti enako, potem imata enak razlog. Poleg tega so težave s to vrsto pomnilnika izjemno redke.
Bistvo odpravljene težave je bilo v tem, da smo uporabili razporejevalnik paketov fq s privzetimi nastavitvami v QoS. Privzeto za eno povezavo omogoča dodajanje 100 paketov v čakalno vrsto, nekatere povezave pa so v primerih pomanjkanja kanala začele zamašiti čakalno vrsto do zmogljivosti. V tem primeru se paketi zavržejo. V statistiki tc (tc -s qdisc) je to mogoče videti takole:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
“464545 flows_plimit” so paketi, ki so bili izpuščeni zaradi prekoračitve omejitve čakalne vrste ene povezave, “dropped 464545” pa je vsota vseh izpuščenih paketov tega razporejevalnika. Po povečanju čakalne vrste na 1 tisoč in ponovnem zagonu vsebnikov se težava ni več pojavljala. Lahko se usedete in popijete smoothie.
FragmentSmack/SegmentSmack. Zadnja kri
Prvič, nekaj mesecev po objavi ranljivosti jedra je bil končno izdan popravek za FragmentSmack (ne pozabite, avgustovska objava je izdala le popravek za SegmentSmack), kar nam je dalo priložnost, da opustimo Workaround, ki nam je povzročal kar nekaj težav. V tem času smo že nekaj strežnikov prenesli na novo jedro in zdaj smo morali začeti iz nič. Zakaj smo posodobili jedro, ne da bi čakali na popravek za FragmentSmack? Dejstvo je, da je postopek zaščite pred temi ranljivostmi sovpadal (in se združil) s samim postopkom posodabljanja Workarounda. CentOS (kar traja še dlje kot posodabljanje samo jedra). Poleg tega je SegmentSmack nevarna ranljivost in popravek zanjo je bil takoj na voljo, zato je bilo vseeno smiselno. Vendar pa je že sama posodabljanje jedra CentOS nismo mogli zaradi ranljivosti FragmentSmack, ki se je pojavila med CentOS Napaka pri različici 7.5 je bila odpravljena šele v različici 7.6, zato smo morali ustaviti posodobitev na 7.5 in začeti znova s posodobitvijo na 7.6. Tudi to se dogaja.
Drugič, redke pritožbe uporabnikov o težavah so se vrnile k nam. Zdaj že zagotovo vemo, da so vsi povezani z nalaganjem datotek odjemalcev na nekatere naše strežnike. Poleg tega je šlo zelo majhno število prenosov od skupne mase skozi te strežnike.
Kot se spomnimo iz zgornje zgodbe, vrnitev Sysctla ni pomagala. Ponovni zagon je pomagal, vendar začasno.
Sumov glede Sysctla sicer niso odpravili, tokrat pa je bilo treba zbrati čim več informacij. Bilo je tudi veliko pomanjkanje zmožnosti reproduciranja težave pri nalaganju na odjemalcu, da bi lahko natančneje preučili, kaj se dogaja.
Analiza vseh razpoložljivih statistik in dnevnikov nas ni približala razumevanju dogajanja. Prišlo je do akutnega pomanjkanja zmožnosti reprodukcije problema, da bi »občutili« določeno povezavo. Končno je razvijalcem s posebno različico aplikacije uspelo doseči stabilno reprodukcijo težav na testni napravi, ko je povezana prek Wi-Fi. To je bil preboj v preiskavi. Odjemalec se je povezal z Nginxom, ki je posredoval zaledju, ki je bila naša aplikacija Java.
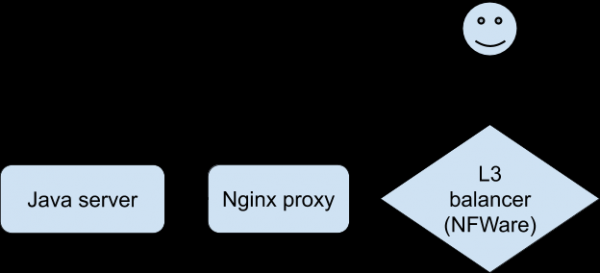
Dialog za težave je bil takšen (popravljeno na strani posrednika Nginx):
- Odjemalec: zahteva za prejemanje informacij o prenosu datoteke.
- Strežnik Java: odgovor.
- Odjemalec: POST z datoteko.
- Java strežnik: napaka.
Hkrati strežnik Java zapiše v dnevnik, da je od odjemalca prejel 0 bajtov podatkov, proxy Nginx pa zapiše, da je zahteva trajala več kot 30 sekund (30 sekund je časovna omejitev odjemalske aplikacije). Zakaj časovna omejitev in zakaj 0 bajtov? Z vidika HTTP vse deluje, kot bi moralo, vendar se zdi, da POST z datoteko izgine iz omrežja. Poleg tega izgine med stranko in Nginxom. Čas je, da se oborožite s Tcpdump! Toda najprej morate razumeti konfiguracijo omrežja. Proxy Nginx stoji za izravnalnikom L3 . Tuneliranje se uporablja za dostavo paketov iz izravnalnika L3 na strežnik, ki paketom doda svoje glave:
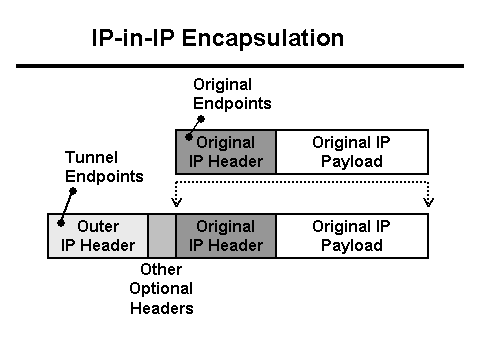
V tem primeru pride omrežje do tega strežnika v obliki Vlan označenega prometa, ki paketom doda tudi svoja polja:
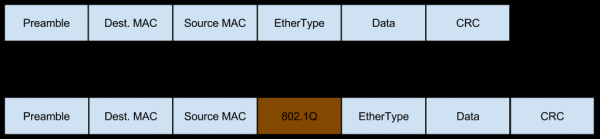
In ta promet je lahko tudi razdrobljen (ta isti majhen odstotek dohodnega razdrobljenega prometa, o katerem smo govorili pri ocenjevanju tveganj iz rešitve Workaround), kar spremeni tudi vsebino glav:
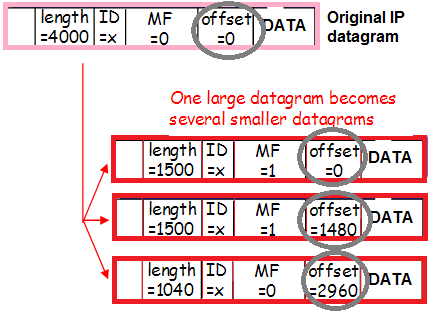
Še enkrat: paketi so enkapsulirani z oznako Vlan, enkapsulirani s tunelom, fragmentirani. Da bi bolje razumeli, kako se to zgodi, izsledimo pot paketa od odjemalca do proxyja Nginx.
- Paket doseže izravnalnik L3. Za pravilno usmerjanje znotraj podatkovnega centra je paket enkapsuliran v tunel in poslan na omrežno kartico.
- Ker se glave paketa + tunela ne prilegajo v MTU, je paket razrezan na fragmente in poslan v omrežje.
- Stikalo za L3 balancerjem, ko prejme paket, mu doda oznako Vlan in ga pošlje naprej.
- Stikalo pred proxyjem Nginx vidi (glede na nastavitve vrat), da strežnik pričakuje paket, enkapsuliran v Vlan, zato ga pošlje takšnega, kot je, ne da bi odstranil oznako Vlan.
- Linux sprejema delčke posameznih paketov in jih lepi v en velik paket.
- Nato paket doseže vmesnik Vlan, kjer se z njega odstrani prva plast - enkapsulacija Vlan.
- Potem Linux pošlje ga v vmesnik Tunnel, kjer se iz njega odstrani še ena plast - enkapsulacija tunela.
Težava je posredovati vse to kot parametre v tcpdump.
Začnimo od konca: ali obstajajo čisti (brez nepotrebnih glav) paketi IP od odjemalcev, z odstranjeno enkapsulacijo vlan in tunela?
tcpdump host <ip клиента>
Ne, na strežniku ni bilo takih paketov. Torej mora biti problem že prej. Ali obstajajo paketi z odstranjeno samo enkapsulacijo Vlan?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx je naslov IP odjemalca v šestnajstiški obliki.
32:4 — naslov in dolžina polja, v katerem je zapisan SCR IP v paketu Tunel.
Naslov polja je bilo treba izbrati na silo, saj na internetu pišejo o 40, 44, 50, 54, vendar tam ni bilo IP naslova. Prav tako lahko pogledate enega od paketov v hex (parameter -xx ali -XX v tcpdump) in izračunate naslov IP, ki ga poznate.
Ali obstajajo fragmenti paketov brez odstranjene enkapsulacije Vlan in Tunnel?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Ta čarovnija nam bo pokazala vse fragmente, vključno z zadnjim. Verjetno je isto stvar mogoče filtrirati po IP-ju, vendar nisem poskusil, ker takšnih paketov ni veliko in tiste, ki sem jih potreboval, sem zlahka našel v splošnem toku. Tukaj so:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 V 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), dolžina 62: (tos 0x0, ttl 63, ID 53652, odmik 1480, zastavice [brez], proto IPIP (4), dolžina 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 .............
Gre za dva fragmenta enega paketa (isti ID 53652) s fotografijo (v prvem paketu je vidna beseda Exif). Glede na to, da obstajajo paketi na tej ravni, vendar ne v združeni obliki na odlagališčih, je očitno problem pri sestavljanju. Končno obstajajo dokumentarni dokazi o tem!
Paketni dekoder ni razkril nobenih težav, ki bi preprečile gradnjo. Poskusil tukaj: . Sprva, ko poskušate nekaj vstaviti tja, dekoderju ni všeč oblika paketa. Izkazalo se je, da sta med Srcmacom in Ethertype nekaj dodatnih dveh oktetov (nista povezana z informacijami o fragmentih). Po njihovi odstranitvi je dekoder začel delovati. Vendar pa ni pokazalo težav.
Karkoli že kdo reče, nič drugega ni bilo najdeno razen tistih Sysctl. Preostalo je le najti način za identifikacijo težavnih strežnikov, da bi razumeli obseg in se odločili za nadaljnje ukrepe. Zahtevani števec je bil najden dovolj hitro:
netstat -s | grep "packet reassembles failed”
Je tudi v snmpd pod OID=1.3.6.1.2.1.4.31.1.1.16.1 ().
»Število napak, ki jih je zaznal algoritem za ponovno sestavljanje IP (iz katerega koli razloga: časovna omejitev, napake itd.).«
Med skupino strežnikov, na katerih je bila obravnavana težava, je na dveh ta števec naraščal hitreje, na dveh počasneje, na dveh pa se sploh ni povečal. Primerjava dinamike tega števca z dinamiko napak HTTP na strežniku Java je pokazala korelacijo. To pomeni, da bi lahko merilnik spremljali.
Imeti zanesljiv indikator težav je zelo pomembno, da lahko natančno ugotovite, ali povrnitev Sysctl nazaj pomaga, saj iz prejšnje zgodbe vemo, da tega ni mogoče takoj razumeti iz aplikacije. Ta indikator bi nam omogočil, da identificiramo vsa problematična področja v proizvodnji, preden jih uporabniki odkrijejo.
Po vrnitvi Sysctl-a so napake v spremljanju prenehale, tako da je bil vzrok za težave dokazan, pa tudi dejstvo, da povrnitev pomaga.
Povrnili smo nastavitve fragmentacije na drugih strežnikih, kjer je prišlo v poštev novo spremljanje, nekje pa smo za fragmente namenili celo več pomnilnika, kot je bilo prej privzeto (to je bila statistika UDP, katere delna izguba na splošnem ozadju ni bila opazna) .
Najpomembnejša vprašanja
Zakaj so paketi na našem izravnalniku L3 fragmentirani? Večina paketov, ki prispejo od uporabnikov do izravnalnikov, sta SYN in ACK. Velikosti teh paketov so majhne. Ker pa je delež takih paketov zelo velik, na njihovem ozadju nismo opazili prisotnosti velikih paketov, ki so se začeli drobiti.
Razlog je bil pokvarjen konfiguracijski skript na strežnikih z vmesniki Vlan (takrat je bilo v proizvodnji zelo malo strežnikov z označenim prometom). Advmss nam omogoča, da odjemalcu posredujemo informacijo, da morajo biti paketi v naši smeri manjši, tako da jih po tem, ko jim pripnemo glave tunela, ni treba fragmentirati.
Zakaj Sysctl rollback ni pomagal, ponovni zagon pa je? Povrnitev Sysctla je spremenila količino pomnilnika, ki je na voljo za združevanje paketov. Hkrati je očitno samo dejstvo prelivanja pomnilnika za fragmente povzročilo upočasnitev povezav, zaradi česar so bili fragmenti dolgo časa zakasnjeni v čakalni vrsti. Se pravi, proces je šel v ciklih.
Ponovni zagon je počistil pomnilnik in vse se je vrnilo v red.
Ali je bilo mogoče storiti brez rešitve? Da, vendar obstaja velika nevarnost, da uporabniki ostanejo brez storitve v primeru napada. Seveda je uporaba Workarounda povzročila različne težave, vključno z upočasnitvijo ene od storitev za uporabnike, vendar kljub temu menimo, da so bili ukrepi upravičeni.
Najlepša hvala Andreju Timofejevu () za pomoč pri vodenju preiskave, pa tudi Aleksej Krenev () - za titansko delo posodabljanja Centos in strežniška jedra. V tem primeru je bilo treba postopek večkrat znova zagnati, zaradi česar je trajal več mesecev.
Vir: www.habr.com
