

je odprtokodni stolpčni sistem za upravljanje baz podatkov za spletno analitično obdelavo poizvedb (OLAP), ki ga je ustvaril Yandex. Uporabljajo ga Yandex, CloudFlare, VK.com, Badoo in druge storitve po vsem svetu za shranjevanje res velikih količin podatkov (vstavljanje na tisoče vrstic na sekundo ali petabajtov podatkov, shranjenih na disku).
V navadnem, “string” DBMS, katerega primeri so MySQL, Postgres, MS SQL Server, so podatki shranjeni v naslednjem vrstnem redu:
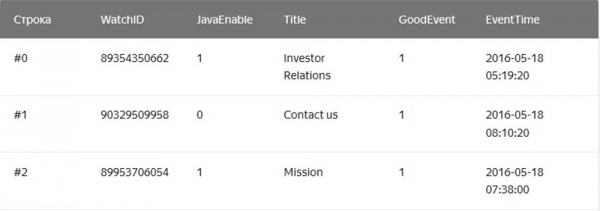
V tem primeru so vrednosti, ki se nanašajo na eno vrstico, fizično shranjene v bližini. V stolpčnih DBMS so vrednosti iz različnih stolpcev shranjene ločeno, podatki iz enega stolpca pa so shranjeni skupaj:
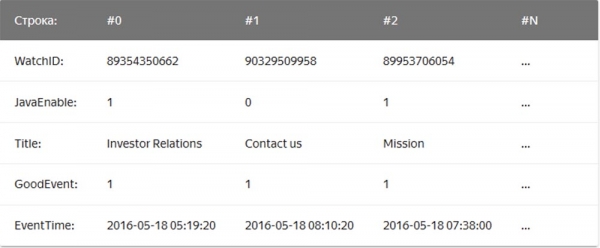
Primeri stolpčnih DBMS so Vertica, Paraccel (Actian Matrix, Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise, Actian Vector), LucidDB, SAP HANA, Google Dremel, Google PowerDrill, Druid, kdb+.
Podjetje za posredovanje pošte Clickhouse začel uporabljati leta 2018 za poročanje in bil zelo navdušen nad njegovo preprostostjo, razširljivostjo, podporo SQL in hitrostjo. Hitrost tega DBMS je mejila na magijo.
preprostost
Clickhouse je nameščen v Ubuntu z enim samim ukazom. Če poznate SQL, lahko takoj začnete uporabljati Clickhouse za svoje potrebe. Vendar to ne pomeni, da lahko v MySQL zaženete »show create table« in nato kopirate in prilepite SQL v Clickhouse.
V primerjavi z MySQL obstajajo pomembne razlike v vrstah podatkov v definicijah sheme tabel, zato boste še vedno potrebovali nekaj časa, da spremenite definicije sheme tabel in se naučite mehanizmov tabel, da se boste počutili udobno.
Clickhouse odlično deluje brez kakršne koli dodatne programske opreme, če pa želite uporabiti replikacijo, boste morali namestiti ZooKeeper. Analiza uspešnosti poizvedb kaže odlične rezultate - sistemske tabele vsebujejo vse informacije, vse podatke pa je mogoče pridobiti s starim in dolgočasnim SQL.
Produktivnost
- primerjave Clickhouse z Vertico in MySQL na konfiguraciji strežnika: dve vtičnici Intel® Xeon® CPU E5-2650 v2 @ 2.60 GHz; 128 GiB RAM; md RAID-5 na 8 6TB SATA HDD, ext4.
- primerjava Clickhousea s shrambo v oblaku Amazon RedShift.
- Izvlečki iz bloga :

Baza podatkov ClickHouse ima zelo preprosto zasnovo – vsa vozlišča v gruči imajo enako funkcionalnost in za koordinacijo uporabljajo samo ZooKeeper. Zgradili smo majhno gručo več vozlišč in izvedli testiranje, med katerim smo ugotovili, da ima sistem precej impresivno zmogljivost, kar ustreza navedenim prednostim v analitičnih primerjalnih testih DBMS. Odločili smo se, da si podrobneje ogledamo koncept ClickHouse. Prva ovira pri raziskovanju je bilo pomanjkanje orodij in majhna skupnost ClickHouse, zato smo se poglobili v zasnovo tega DBMS, da bi razumeli, kako deluje.
ClickHouse ne podpira prejemanja podatkov neposredno od Kafke, ker je le baza podatkov, zato smo v Go napisali lastno storitev adapterja. Prebral je kodirana sporočila Cap'n Proto iz Kafke, jih pretvoril v TSV in v paketih prek vmesnika HTTP vstavil v ClickHouse. Kasneje smo to storitev preoblikovali za uporabo knjižnice Go v povezavi z lastnim vmesnikom ClickHouse za izboljšanje učinkovitosti. Pri ocenjevanju uspešnosti sprejemanja paketov smo odkrili pomembno stvar – izkazalo se je, da je pri ClickHouse ta uspešnost močno odvisna od velikosti paketa, torej števila sočasno vstavljenih vrstic. Da bi razumeli, zakaj se to zgodi, smo pogledali, kako ClickHouse shranjuje podatke.
Glavni motor oziroma družina tabelnih motorjev, ki jih uporablja ClickHouse za shranjevanje podatkov, je MergeTree. Ta motor je konceptualno podoben algoritmu LSM, ki se uporablja v Google BigTable ali Apache Cassandra, vendar se izogiba izdelavi vmesne pomnilniške tabele in zapisuje podatke neposredno na disk. To mu zagotavlja odlično prepustnost pisanja, saj je vsak vstavljeni paket razvrščen samo po primarnem ključu, stisnjen in zapisan na disk, da tvori segment.
Odsotnost pomnilniške tabele ali koncepta »svežesti« podatkov tudi pomeni, da jih je mogoče samo dodajati, sistem ne podpira spreminjanja ali brisanja. Trenutno je edini način za brisanje podatkov ta, da jih izbrišete po koledarskih mesecih, saj segmenti nikoli ne presežejo meje meseca. Ekipa ClickHouse si aktivno prizadeva narediti to funkcijo prilagodljivo. Po drugi strani omogoča pisanje in združevanje segmentov brez sporov, tako da se prepustnost sprejema linearno spreminja s številom sočasnih vstavljanj, dokler ne pride do zasičenosti V/I ali jedra.
Vendar to tudi pomeni, da sistem ni primeren za majhne pakete, zato se za medpomnjenje uporabljajo Kafkine storitve in vstavljalci. Nato ClickHouse v ozadju še naprej nenehno izvaja združevanje segmentov, tako da se bo veliko majhnih informacij združilo in posnelo večkrat, s čimer se bo povečala intenzivnost snemanja. Vendar pa bo preveč nepovezanih delov povzročilo agresivno dušenje vstavkov, dokler se spajanje nadaljuje. Ugotovili smo, da je najboljši kompromis med vnosom v realnem času in zmogljivostjo vnosa v tabelo vnesti omejeno število vstavkov na sekundo.
Ključ do uspešnosti branja tabele je indeksiranje in lokacija podatkov na disku. Ne glede na to, kako hitra je obdelava, ko mora motor pregledati terabajte podatkov z diska in uporabiti le del tega, bo trajalo nekaj časa. ClickHouse je stolpčna trgovina, zato vsak segment vsebuje datoteko za vsak stolpec (stolpec) z razvrščenimi vrednostmi za vsako vrstico. Na ta način je mogoče najprej preskočiti celotne stolpce, ki manjkajo v poizvedbi, nato pa je mogoče z vektoriziranim izvajanjem vzporedno obdelati več celic. Da bi se izognili popolnemu skeniranju, ima vsak segment majhno indeksno datoteko.
Glede na to, da so vsi stolpci razvrščeni po “primarnem ključu”, indeksna datoteka vsebuje samo oznake (zajete vrstice) vsake N-te vrstice, da jih lahko hranimo v pomnilniku tudi za zelo velike tabele. Na primer, lahko nastavite privzete nastavitve na »označi vsako 8192. vrstico«, nato pa »pičlo« indeksiranje tabele z 1 trilijonom. vrstice, ki se zlahka prilegajo pomnilniku, bodo imele samo 122 znakov.
Razvoj sistema
Razvoj in izboljšave Clickhouse lahko spremljamo na in se prepričajte, da proces "odraščanja" poteka z impresivno hitrostjo.
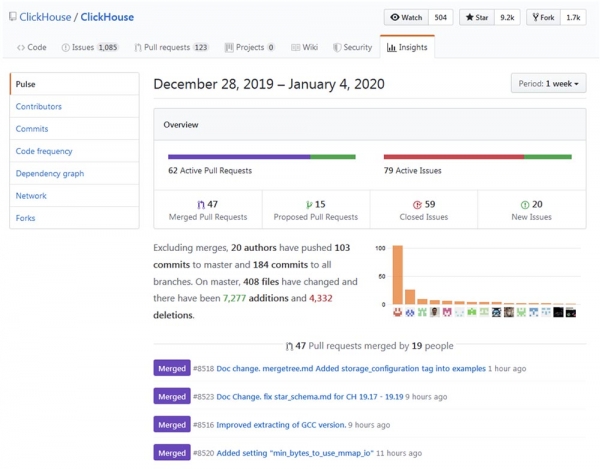
Priljubljenost
Zdi se, da priljubljenost Clickhouse eksponentno narašča, zlasti v rusko govoreči skupnosti. Lanskoletna konferenca High load 2018 (Moskva, 8.-9. november 2018) je pokazala, da takšne pošasti, kot sta vk.com in Badoo, uporabljajo Clickhouse, s katerim vnašajo podatke (na primer dnevnike) iz več deset tisoč strežnikov hkrati. V 40 minutnem videu . Kmalu bomo prepis objavili na Habru za lažje delo z gradivom.
Aplikacije
Po tem, ko sem porabil nekaj časa za raziskovanje, menim, da obstajajo področja, kjer bi ClickHouse lahko bil koristen ali bi lahko popolnoma nadomestil druge, bolj tradicionalne in priljubljene rešitve, kot so MySQL, PostgreSQL, ELK, Google Big Query, Amazon RedShift, TimescaleDB, Hadoop, MapReduce, Pinot in Druid. V nadaljevanju so opisane podrobnosti uporabe ClickHouse za posodobitev ali popolno zamenjavo zgornjega DBMS.
Razširitev zmogljivosti MySQL in PostgreSQL
Nedavno smo delno zamenjali MySQL s ClickHouse za našo platformo za glasila . Težava je bila v tem, da je MySQL zaradi slabe zasnove beležil vsako poslano e-pošto in vsako povezavo v tej e-pošti z zgoščeno vrednostjo base64, kar je ustvarilo ogromno tabelo MySQL (email_stats). Po pošiljanju samo 10 milijonov e-poštnih sporočil naročnikom storitev je ta tabela zasedla 150 GB prostora za datoteke in MySQL je začel biti "neumen" pri preprostih poizvedbah. Da bi odpravili težavo s prostorom za datoteke, smo uspešno uporabili stiskanje tabele InnoDB, ki ga je zmanjšalo za faktor 4. Vendar še vedno ni smiselno shranjevati več kot 20–30 milijonov e-poštnih sporočil v MySQL samo zaradi branja zgodovine, saj vsaka preprosta poizvedba, ki jo je treba iz nekega razloga opraviti v celoti, povzroči zamenjavo in veliko I /O obremenitev, glede katere smo redno prejemali opozorila Zabbixa.
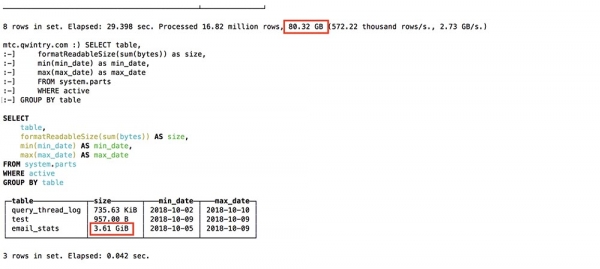
Clickhouse uporablja dva algoritma stiskanja, ki zmanjšata količino podatkov za približno , vendar so bili v tem konkretnem primeru podatki še posebej "stisljivi".

Zamenjava ELK
Na podlagi lastnih izkušenj sklad ELK (ElasticSearch, Logstash in Kibana, v tem posebnem primeru ElasticSearch) za izvajanje zahteva veliko več sredstev, kot je potrebno za shranjevanje dnevnikov. ElasticSearch je odličen mehanizem, če potrebujete dobro iskanje po dnevnikih po celotnem besedilu (kar mislim, da res ne potrebujete), vendar se sprašujem, zakaj je postal de facto standardni mehanizem za beleženje. Njegova zmogljivost vnosa v kombinaciji z Logstash nam je povzročala težave tudi pri dokaj majhnih obremenitvah in zahtevala, da dodajamo vedno več RAM-a in prostora na disku. Kot zbirka podatkov je Clickhouse boljši od ElasticSearch iz naslednjih razlogov:
- Podpora za narečje SQL;
- Najboljša stopnja stiskanja shranjenih podatkov;
- Podpora za iskanja regularnih izrazov namesto iskanja po celotnem besedilu;
- Izboljšano razporejanje poizvedb in večja splošna zmogljivost.
Trenutno največja težava, ki se pojavi pri primerjavi ClickHouse z ELK, je pomanjkanje rešitev za nalaganje dnevnikov, pa tudi pomanjkanje dokumentacije in vaj na to temo. Poleg tega lahko vsak uporabnik konfigurira ELK s pomočjo priročnika Digital Ocean, kar je zelo pomembno za hitro implementacijo tovrstnih tehnologij. Obstaja mehanizem baze podatkov, vendar Filebeat za ClickHouse še ni. Da, tam je in sistem za delo z dnevniki , obstaja orodje za vnos podatkov iz dnevniške datoteke v ClickHouse, vendar vse to traja več časa. Kljub temu je ClickHouse še vedno vodilni zaradi svoje preprostosti, tako da ga lahko tudi začetniki enostavno namestijo in začnejo uporabljati v celoti funkcionalno v samo 10 minutah.
Ker imam raje minimalistične rešitve, sem poskusil uporabiti FluentBit, orodje za pošiljanje dnevnikov z zelo malo pomnilnika, skupaj s ClickHouse, medtem ko sem se poskušal izogniti uporabi Kafke. Vendar je treba obravnavati manjše nezdružljivosti, kot je npr preden je to mogoče storiti brez posredniškega sloja, ki pretvori podatke iz FluentBit v ClickHouse.
Kot alternativo se lahko Kibana uporablja kot zaledje ClickHouse . Kolikor razumem, lahko to povzroči težave z zmogljivostjo pri upodabljanju velikega števila podatkovnih točk, zlasti pri starejših različicah Grafana. Pri Qwintryju tega še nismo preizkusili, vendar se pritožbe glede tega občasno pojavijo na podpornem kanalu ClickHouse v Telegramu.
Zamenjava Google Big Query in Amazon RedShift (rešitev za velika podjetja)
Idealen primer uporabe za BigQuery je nalaganje 1 TB podatkov JSON in izvajanje analitičnih poizvedb na njih. Big Query je odličen izdelek, katerega razširljivosti ni mogoče preceniti. To je veliko bolj kompleksna programska oprema kot ClickHouse, ki teče na notranji gruči, vendar ima z vidika naročnika veliko skupnega s ClickHouse. BigQuery lahko hitro postane drag, ko začnete plačevati na SELECT, zato je prava rešitev SaaS z vsemi prednostmi in slabostmi.
ClickHouse je najboljša izbira, ko izvajate veliko računsko dragih poizvedb. Več poizvedb SELECT izvajate vsak dan, bolj je smiselno zamenjati Big Query s ClickHouse, saj vam lahko taka zamenjava prihrani na tisoče dolarjev, ko gre za veliko terabajtov obdelanih podatkov. To ne velja za shranjene podatke, katerih obdelava v Big Queryju je precej poceni.
V članku soustanovitelja Altinityja Aleksandra Zaitseva govori o prednostih takšne migracije DBMS.
Zamenjava TimescaleDB
TimescaleDB je razširitev PostgreSQL, ki optimizira delo s časovnimi vrstami časovnih vrst v običajni bazi podatkov (, ).
Čeprav ClickHouse ni resen tekmec v niši časovnih vrst, temveč stolpčne strukture in izvajanja vektorskih poizvedb, je v večini primerov analitične obdelave poizvedb precej hitrejši od TimescaleDB. Hkrati je zmogljivost prejemanja paketnih podatkov iz ClickHouse približno 3-krat višja, uporablja pa tudi 20-krat manj prostora na disku, kar je zelo pomembno za obdelavo velikih količin zgodovinskih podatkov: .
Za razliko od ClickHouse je edini način za prihranek prostora na disku v TimescaleDB uporaba ZFS ali podobnih datotečnih sistemov.
Prihajajoče posodobitve ClickHouse bodo verjetno uvedle delta stiskanje, zaradi česar bo še bolj primeren za obdelavo in shranjevanje podatkov časovnih vrst. TimescaleDB je morda boljša izbira kot goli ClickHouse v naslednjih primerih:
- majhne namestitve z zelo malo RAM-a (<3 GB);
- veliko število majhnih INSERT-ov, ki jih ne želite medpomniti v velike fragmente;
- boljša doslednost, enotnost in zahteve glede KISLINE;
- Podpora za PostGIS;
- združevanje z obstoječimi tabelami PostgreSQL, saj je Timescale DB v bistvu PostgreSQL.
Konkurenca s sistemoma Hadoop in MapReduce
Hadoop in drugi izdelki MapReduce lahko izvedejo veliko zapletenih izračunov, vendar običajno delujejo z velikimi zakasnitvami. ClickHouse odpravi to težavo z obdelavo terabajtov podatkov in skoraj takojšnjim ustvarjanjem rezultatov. Tako je ClickHouse veliko bolj učinkovit pri izvajanju hitrih, interaktivnih analitičnih raziskav, ki bi morale biti zanimive za podatkovne znanstvenike.
Konkurenca s pinotom in druidom
Najbližja konkurenta ClickHouse sta stolpična, linearno razširljiva odprtokodna izdelka Pinot in Druid. V članku je objavljeno odlično delo o primerjavi teh sistemov z dne 1. februarja 2018
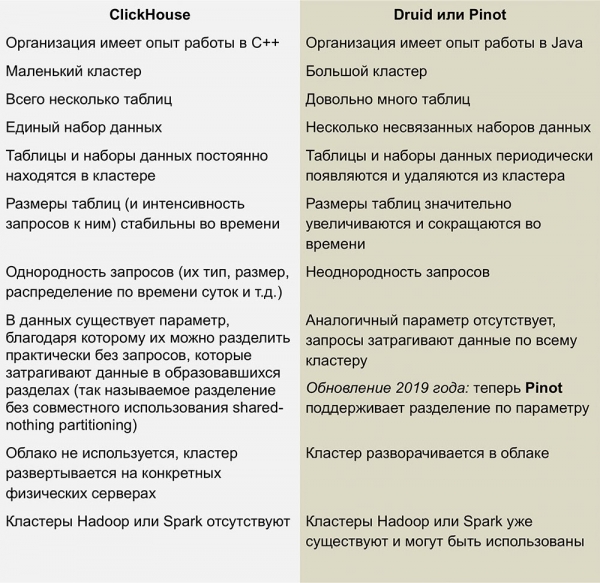
Ta članek je treba posodobiti - piše, da ClickHouse ne podpira operacij UPDATE in DELETE, kar za zadnje različice ne drži povsem.
S temi zbirkami podatkov nimamo veliko izkušenj, vendar mi ni ravno všeč kompleksnost infrastrukture, ki je potrebna za delovanje Druida in Pinota – gre za cel kup gibljivih delov, ki jih z vseh strani obdaja Java.
Druid in Pinot sta inkubatorska projekta Apache, katerih napredek podrobno opisuje Apache na svojih projektnih straneh GitHub. Pinot se je v inkubatorju pojavil oktobra 2018, Druid pa se je rodil 8 mesecev prej - februarja.
Pomanjkanje informacij o tem, kako deluje AFS, mi postavlja nekaj, morda neumnih, vprašanj. Zanima me, ali so avtorji Pinota opazili, da je fundacija Apache bolj naklonjena Druidu in ali je ta odnos do tekmeca povzročil občutek zavisti? Ali se bo razvoj Druida upočasnil in razvoj Pinota pospešil, če se bodo podporniki prvega nenadoma začeli zanimati za drugega?
Slabosti ClickHouse
Nezrelost: očitno to še vedno ni dolgočasna tehnologija, v vsakem primeru pa v drugih stolpčnih DBMS-jih ni opaziti ničesar takega.
Majhni vstavki pri visoki hitrosti ne delujejo dobro: vstavke je treba razdeliti na večje dele, ker se zmogljivost majhnih vstavkov slabša sorazmerno s številom stolpcev v vsaki vrstici. Tako ClickHouse shranjuje podatke na disk - vsak stolpec predstavlja 1 datoteko ali več, tako da morate za vstavljanje 1 vrstice s 100 stolpci odpreti in napisati vsaj 100 datotek. Zato vložki za medpomnjenje zahtevajo posrednika (razen če stranka sama zagotovi medpomnjenje) - običajno Kafka ali nekakšen sistem za upravljanje čakalne vrste. Mehanizem medpomnilniških tabel lahko uporabite tudi za poznejše kopiranje velikih kosov podatkov v tabele MergeTree.
Združevanja tabel so omejena z RAM-om strežnika, vendar so vsaj tam! Na primer, Druid in Pinot sploh nimata takih povezav, saj ju je težko implementirati neposredno v porazdeljene sisteme, ki ne podpirajo premikanja velikih kosov podatkov med vozlišči.
Ugotovitve
V prihodnjih letih načrtujemo široko uporabo ClickHouse v Qwintryju, saj ta DBMS zagotavlja odlično ravnotežje med zmogljivostjo, nizkimi stroški, razširljivostjo in preprostostjo. Skoraj prepričan sem, da se bo začel hitro širiti, ko bo skupnost ClickHouse pripravila več načinov za uporabo v majhnih do srednje velikih namestitvah.
Nekaj oglasov 🙂
Hvala, ker ste ostali z nami. So vam všeč naši članki? Želite videti več zanimivih vsebin? Podprite nas tako, da oddate naročilo ali priporočite prijateljem, , edinstven analog začetnih strežnikov, ki smo ga izumili za vas: (na voljo z RAID1 in RAID10, do 24 jeder in do 40 GB DDR4).
Dell R730xd dvakrat cenejši v podatkovnem centru Equinix Tier IV v Amsterdamu? Samo tukaj na Nizozemskem! Dell R420 - 2x E5-2430 2.2 Ghz 6C 128 GB DDR3 2x960 GB SSD 1 Gbps 100 TB - od 99 $! Preberite o
Vir: www.habr.com
