


Takole izgleda odvečnost
Redundančne kode* se pogosto uporabljajo v računalniških sistemih za povečanje zanesljivosti shranjevanja podatkov. V Yandexu se uporabljajo v številnih projektih. Na primer, uporaba redundantnih kod namesto replikacije v našem notranjem objektnem pomnilniku prihrani milijone brez žrtvovanja zanesljivosti. Toda kljub široki uporabi so jasni opisi delovanja redundantnih kod zelo redki. Tisti, ki želijo razumeti, se soočajo s približno naslednjim (iz ):

Moje ime je Vadim, pri Yandexu razvijam interno shranjevanje objektov MDS. V tem članku bom s preprostimi besedami opisal teoretične osnove redundantnih kod (Reed-Solomon in LRC kode). Povedal vam bom, kako deluje, brez zapletene matematike in redkih izrazov. Na koncu bom navedel primere uporabe redundantnih kod v Yandexu.
Ne bom podrobno obravnaval številnih matematičnih podrobnosti, vendar bom ponudil povezave za tiste, ki se želijo potopiti globlje. Opozoril bom tudi, da nekatere matematične definicije morda niso stroge, saj članek ni namenjen matematikom, temveč inženirjem, ki želijo razumeti bistvo vprašanja.
* V literaturi v angleškem jeziku se redundantne kode pogosto imenujejo kode za brisanje.
1. Bistvo redundantnih kod
Bistvo vseh redundantnih kod je izredno preprosto: shranjevati (ali prenašati) podatke tako, da se ob pojavu napak (odpovedi diska, napake pri prenosu podatkov ipd.) ne izgubijo.
V večini* redundantnih kod so podatki razdeljeni na n podatkovnih blokov, za katere se šteje m blokov redundantnih kod, kar ima za posledico skupno n + m blokov. Redundančne kode so sestavljene tako, da je mogoče obnoviti n blokov podatkov z uporabo samo dela n + m blokov. Nato bomo upoštevali samo blokovne redundantne kode, to je tiste, v katerih so podatki razdeljeni na bloke.
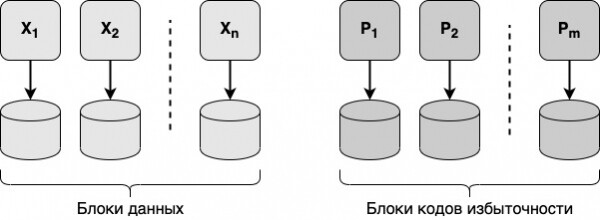
Če želite obnoviti vseh n blokov podatkov, morate imeti vsaj n od n + m blokov, saj ne morete pridobiti n blokov, če imate samo n-1 blok (v tem primeru bi morali vzeti 1 blok "iz tanke" zrak”). Ali je n naključnih blokov n + m blokov dovolj za obnovitev vseh podatkov? To je odvisno od vrste redundantnih kod, na primer Reed-Solomonove kode vam omogočajo obnovitev vseh podatkov z uporabo poljubnih n blokov, redundantne kode LRC pa ne vedno.
Shranjevanje podatkov
V sistemih za shranjevanje podatkov se praviloma vsak od podatkovnih blokov in blokov redundantne kode zapiše na ločen disk. Potem, če poljubni disk odpove, je originalne podatke še vedno mogoče obnoviti in prebrati. Podatke je mogoče obnoviti, tudi če odpove več diskov hkrati.
Prenos podatkov
Redundančne kode je mogoče uporabiti za zanesljiv prenos podatkov prek nezanesljivega omrežja. Preneseni podatki so razdeljeni na bloke, zanje pa se izračunajo redundantne kode. Po omrežju se prenašajo tako podatkovni bloki kot bloki redundantne kode. Če pride do napak v poljubnih blokih (do določenega števila blokov), se lahko podatki še vedno brez napak prenašajo po omrežju. Reed-Solomonove kode se na primer uporabljajo za prenos podatkov po optičnih komunikacijskih linijah in v satelitskih komunikacijah.
* Obstajajo tudi redundantne kode, v katerih podatki niso razdeljeni na bloke, kot so Hammingove kode in CRC kode, ki se pogosto uporabljajo za prenos podatkov v omrežjih Ethernet. To so kode za kodiranje s popravljanjem napak, namenjene so odkrivanju napak in ne njihovemu popravljanju (Hammingova koda omogoča tudi delno popravljanje napak).
2. Reed-Solomonove kode
Reed-Solomonove kode so ena najpogosteje uporabljenih redundantnih kod, izumljena v šestdesetih letih prejšnjega stoletja in prvič široko uporabljena v osemdesetih letih prejšnjega stoletja za množično proizvodnjo zgoščenk.
Obstajata dve ključni vprašanji za razumevanje Reed-Solomonovih kod: 1) kako ustvariti bloke redundantnih kod; 2) kako obnoviti podatke z uporabo redundantnih kodnih blokov. Poiščimo odgovore nanje.
Zaradi poenostavitve bomo nadalje predpostavili, da je n=6 in m=4. Druge sheme se obravnavajo po analogiji.
Kako ustvariti bloke redundantne kode
Vsak blok redundantnih kod se šteje neodvisno od drugih. Za štetje vsakega bloka se uporabi vseh n podatkovnih blokov. V spodnjem diagramu so X1-X6 podatkovni bloki, P1-P4 bloki redundantne kode.
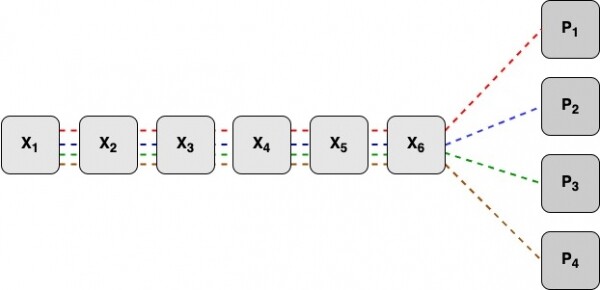
Vsi podatkovni bloki morajo biti enake velikosti, za poravnavo pa je mogoče uporabiti nič bitov. Nastali bloki redundantne kode bodo enake velikosti kot podatkovni bloki. Vsi podatkovni bloki so razdeljeni na besede (na primer 16 bitov). Recimo, da podatkovne bloke razdelimo na k besed. Nato bodo tudi vsi bloki redundantnih kod razdeljeni na k besed.
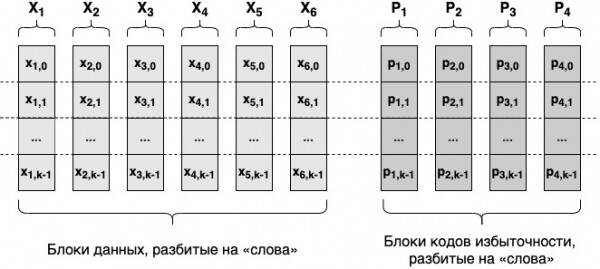
Za štetje i-te besede vsakega redundantnega bloka bodo uporabljene i-te besede vseh podatkovnih blokov. Izračunani bodo po naslednji formuli:
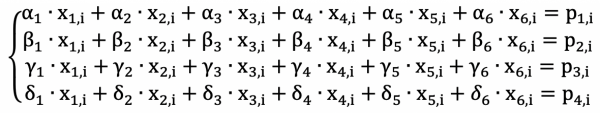
Tukaj so vrednosti x besede podatkovnih blokov, p so besede redundantnih kodnih blokov, vse alfa, beta, gama in delta so posebej izbrane številke, ki so enake za vse i. Takoj je treba povedati, da vse te vrednosti niso navadne številke, ampak elementi polja Galois; operacije +, -, *, / niso operacije, ki jih poznamo vsi, ampak posebne operacije, uvedene na elementih Galois polje.
Zakaj so potrebna Galoisova polja?

Zdi se, da je vse preprosto: podatke razdelimo na bloke, bloke na besede, z besedami podatkovnih blokov štejemo besede blokov redundantne kode - dobimo bloke redundantne kode. Na splošno to deluje tako, hudič pa je v podrobnostih:
- Kot je navedeno zgoraj, je velikost besede fiksna, v našem primeru 16 bitov. Zgornje formule za Reed-Solomonove kode so takšne, da pri uporabi navadnih celih števil rezultat izračuna p morda ne bo mogoče predstaviti z besedo veljavne velikosti.
- Pri obnavljanju podatkov bodo zgornje formule obravnavane kot sistem enačb, ki jih je treba rešiti, da obnovimo podatke. Med postopkom reševanja bo morda treba cela števila deliti eno z drugim, kar povzroči realno število, ki ga ni mogoče natančno predstaviti v računalniškem pomnilniku.
Te težave preprečujejo uporabo celih števil za Reed-Solomonove kode. Rešitev problema je izvirna, lahko jo opišemo na naslednji način: izmislimo posebna števila, ki jih je mogoče predstaviti z besedami zahtevane dolžine (na primer 16 bitov), in rezultat izvajanja vseh operacij, na katerih (seštevanje , odštevanje, množenje, deljenje) bodo predstavljene tudi v pomnilniku računalnika z besedami zahtevane dolžine.
Takšna "posebna" števila matematika preučuje že dolgo, imenujemo jih polja. Polje je niz elementov z definiranimi operacijami seštevanja, odštevanja, množenja in deljenja.
Polja Galois* so polja, za katera obstaja edinstven rezultat vsake operacije (+, -, *, /) za katera koli dva elementa polja. Galoisova polja je mogoče konstruirati za števila, ki so potence števila 2: 2, 4, 8, 16 itd. (pravzaprav potence katerega koli praštevila p, vendar nas v praksi zanimajo le potence 2). Na primer, za 16-bitne besede je to polje, ki vsebuje 65 elementov, za vsak par pa lahko najdete rezultat katere koli operacije (+, -, *, /). Vrednosti x, p, alfa, beta, gama, delta iz zgornjih enačb bodo za izračune obravnavane kot elementi Galoisovega polja.
Tako imamo sistem enačb, s katerim lahko s pisanjem ustreznega računalniškega programa sestavimo bloke redundantnih kod. Z istim sistemom enačb lahko izvedete obnovitev podatkov.
* To ni stroga definicija, temveč opis.
Kako obnoviti podatke
Obnova je potrebna, ko manjka nekaj blokov n + m. To so lahko tako podatkovni bloki kot bloki redundantne kode. Odsotnost podatkovnih blokov in/ali redundantnih kodnih blokov pomeni, da so ustrezne spremenljivke x in/ali p neznane v zgornjih enačbah.
Enačbe za Reed-Solomonove kode je mogoče obravnavati kot sistem enačb, v katerem so vse vrednosti alfa, beta, gama, delta konstante, vsi x in p, ki ustrezajo razpoložljivim blokom, so znane spremenljivke, preostali x in p so neznani.
Če na primer podatkovni bloki 1, 2, 3 in blok redundantne kode 2 niso na voljo, bo za i-to skupino besed obstajal naslednji sistem enačb (neznane so označene z rdečo):
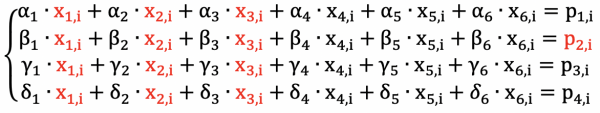
Imamo sistem 4 enačb s 4 neznankami, kar pomeni, da ga lahko rešimo in obnovimo podatke!
Iz tega sistema enačb sledijo številni sklepi o obnovitvi podatkov za Reed-Solomonove kode (n podatkovnih blokov, m redundantnih kodnih blokov):
- Podatke je mogoče obnoviti, če se izgubi kateri koli m blok ali manj. Če se izgubi m+1 ali več blokov, podatkov ni mogoče obnoviti: nemogoče je rešiti sistem m enačb z m + 1 neznankami.
- Če želite obnoviti vsaj en podatkovni blok, morate uporabiti kateri koli n od preostalih blokov in lahko uporabite katero koli od redundantnih kod.
Kaj še morate vedeti
V zgornjem opisu se izogibam številnim pomembnim vprašanjem, ki zahtevajo globlji potop v matematiko. Še posebej pa ne govorim o naslednjem:
- Sistem enačb za Reed-Solomonove kode mora imeti (edinstveno) rešitev za katero koli kombinacijo neznank (ne več kot m neznank). Na podlagi te zahteve so izbrane vrednosti alfa, beta, gama in delta.
- Sistem enačb mora biti zmožen samodejno sestaviti (odvisno od tega, kateri bloki niso na voljo) in rešiti.
- Zgraditi moramo Galoisovo polje: za določeno velikost besede moramo biti sposobni najti rezultat katere koli operacije (+, -, *, /) za katera koli dva elementa.
Na koncu članka so sklicevanja na literaturo o teh pomembnih vprašanjih.
Izbira n in m
Kako izbrati n in m v praksi? V praksi se v sistemih za shranjevanje podatkov uporabljajo redundantne kode za prihranek prostora, zato je m vedno izbrano manj kot n. Njihove posebne vrednosti so odvisne od številnih dejavnikov, vključno z:
- Zanesljivost shranjevanja podatkov. Večji kot je m, večje je število okvar diska, ki jih je mogoče preživeti, torej večja je zanesljivost.
- Odvečno shranjevanje. Višje kot je razmerje m/n, večja bo redundanca shranjevanja in dražji bo sistem.
- Čas obdelave zahteve. Večja kot je vsota n + m, daljši bo odzivni čas na zahteve. Ker branje podatkov (med obnovitvijo) zahteva branje n blokov, shranjenih na n različnih diskih, bo čas branja določil najpočasnejši disk.
Poleg tega shranjevanje podatkov v več DC nalaga dodatne omejitve pri izbiri n in m: če je 1 DC izklopljen, morajo biti podatki še vedno na voljo za branje. Na primer, pri shranjevanju podatkov v 3 DC-jih mora biti izpolnjen naslednji pogoj: m >= n/2, sicer lahko pride do situacije, ko podatki niso na voljo za branje, ko je 1 DC izklopljen.
3. LRC - Lokalni rekonstrukcijski kodeksi
Če želite obnoviti podatke z uporabo Reed-Solomonovih kod, morate uporabiti n poljubnih podatkovnih blokov. To je zelo pomembna pomanjkljivost za sisteme za porazdeljeno shranjevanje podatkov, saj boste morali za obnovitev podatkov na enem pokvarjenem disku prebrati podatke z večine drugih, kar bo povzročilo veliko dodatno obremenitev diskov in omrežja.
Najpogostejše napake so nedostopnost enega bloka podatkov zaradi okvare ali preobremenjenosti enega diska. Ali je mogoče v tem (najpogostejšem) primeru nekako zmanjšati prekomerno obremenitev za obnovitev podatkov? Izkazalo se je, da lahko: obstajajo redundantne kode LRC posebej za ta namen.
LRC (Local Reconstruction Codes) so redundantne kode, ki jih je razvil Microsoft za uporabo v Windows Azure Storage. Ideja LRC je zelo preprosta: vse podatkovne bloke razdelite v dve (ali več) skupin in za vsako skupino posebej izračunajte del blokov redundančne kode. Nato se nekateri bloki redundančne kode izračunajo z uporabo vseh podatkovnih blokov (v LRC se te imenujejo globalne redundančne kode), nekateri pa z uporabo ene od dveh skupin podatkovnih blokov (te se imenujejo lokalne redundančne kode).
LRC je označen s tremi številkami: nrl, kjer je n število podatkovnih blokov, r je število globalnih blokov redundance kode, l je število lokalnih blokov redundance kode. Za branje podatkov, ko en podatkovni blok ni na voljo, morate prebrati samo n/l blokov - to je l-krat manj kot pri Reed-Solomonovih kodah.
Na primer, upoštevajte shemo LRC 6-2-2. X1–X6 — 6 podatkovnih blokov, P1, P2 — 2 globalna redundancna bloka, P3, P4 — 2 lokalna redundancna bloka.
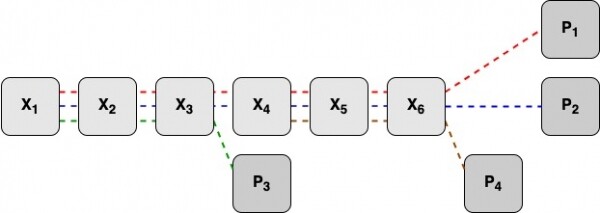
Redundančni kodni bloki P1, P2 se štejejo z uporabo vseh podatkovnih blokov. Redundančni kodni blok P3 - z uporabo podatkovnih blokov X1-X3, redundantni kodni blok P4 - z uporabo podatkovnih blokov X4-X6.
Ostalo je narejeno v LRC po analogiji z Reed-Solomon kodami. Enačbe za štetje besed redundantnih kodnih blokov bodo:
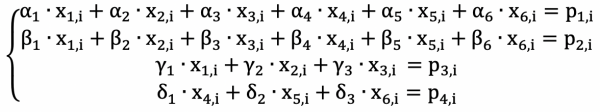
Za izbiro števil alfa, beta, gama, delta morajo biti izpolnjeni številni pogoji, ki zagotavljajo možnost obnovitve podatkov (torej reševanja sistema enačb). Več o njih si lahko preberete v .
Tudi v praksi se operacija XOR uporablja za izračun lokalnih redundantnih kod P3, P4.
Iz sistema enačb za LRC izhajajo številni sklepi:
- Za obnovitev katerega koli 1 podatkovnega bloka je dovolj, da preberete n/l blokov (n/2 v našem primeru).
- Če bloki r + l niso na voljo in so vsi bloki vključeni v eno skupino, podatkov ni mogoče obnoviti. To je enostavno razložiti s primerom. Naj bloka X1–X3 in P3 nista na voljo: to sta bloka r + l iz iste skupine, v našem primeru 4. Potem imamo sistem 3 enačb s 4 neznankami, ki jih ni mogoče rešiti.
- V vseh drugih primerih nedosegljivosti blokov r + l (ko je na voljo vsaj en blok iz vsake skupine) se podatki v LRC lahko obnovijo.
Tako LRC prekaša kode Reed-Solomon pri obnavljanju podatkov po posameznih napakah. V kodah Reed-Solomon morate za obnovitev celo enega bloka podatkov uporabiti n blokov, v LRC pa je za obnovitev enega bloka podatkov dovolj uporabiti n/l blokov (n/2 v našem primeru). Po drugi strani pa je LRC slabši od Reed-Solomonovih kod glede največjega števila dovoljenih napak. V zgornjih primerih lahko Reed-Solomonove kode obnovijo podatke za katere koli 4 napake, za LRC pa obstajata 2 kombinaciji 4 napak, ko podatkov ni mogoče obnoviti.
Kaj je pomembnejše, je odvisno od konkretne situacije, pogosto pa prihranki pri odvečni obremenitvi, ki jih zagotavlja LRC, odtehtajo nekoliko manj zanesljivo shranjevanje.
4. Druge kode redundance
Poleg kod Reed-Solomon in LRC obstaja še veliko drugih redundantnih kod. Različne kode redundance uporabljajo različno matematiko. Tukaj je nekaj drugih redundantnih kod:
- Koda redundance z uporabo operatorja XOR. Operacija XOR se izvede na n podatkovnih blokih in dobi se 1 blok redundantnih kod, to je shema n+1 (n podatkovnih blokov, 1 redundantna koda). Uporablja se v , kjer se bloki podatkov in redundantnih kod ciklično zapisujejo na vse diske polja.
- Algoritem sodo-liho, ki temelji na operaciji XOR. Omogoča izgradnjo 2 blokov redundantnih kod, to je sheme n+2.
- Algoritem STAR, ki temelji na operaciji XOR. Omogoča izgradnjo 3 blokov redundantnih kod, to je sheme n+3.
- Piramidne kode so še ena Microsoftova redundantna koda.
5. Uporabite v Yandex
Številni infrastrukturni projekti Yandex uporabljajo odvečne kode za zanesljivo shranjevanje podatkov. Tukaj je nekaj primerov:
- Notranji objektni pomnilnik MDS, o katerem sem pisal na začetku članka.
- — Sistem MapReduce Yandex.
- (Yandex DataBase) - porazdeljena baza podatkov newSQL.
MDS uporablja redundantne kode LRC, shemo 8-2-2. Podatki z odvečnimi kodami so zapisani na 12 različnih diskov v različnih strežnikih v 3 različnih DC: 4 strežniki v vsakem DC. Več o tem preberite v .
YT uporablja Reed-Solomonove kode (shema 6-3), ki so bile prve uvedene, in redundantne kode LRC (shema 12-2-2), pri čemer je LRC prednostna metoda shranjevanja.
YDB uporablja redundantne kode, ki temeljijo na sodo-liho (slika 4-2). O redundantnih kodah v YDB že .
Uporaba različnih shem redundantnih kod je posledica različnih zahtev za sisteme. Na primer, v MDS so podatki, shranjeni z uporabo LRC, postavljeni v 3 DC hkrati. Za nas je pomembno, da ostanejo podatki na voljo za branje, če 1 od katerega koli DC-ja odpove, zato morajo biti bloki porazdeljeni po DC-jih, tako da, če kateri koli DC ni na voljo, število nedostopnih blokov ni več kot dovoljeno. V shemi 8-2-2 lahko postavite 4 bloke v vsak DC, potem ko je kateri koli DC izklopljen, bodo 4 bloki nedosegljivi in podatke je mogoče prebrati. Ne glede na shemo, ki jo izberemo pri postavitvi v 3 DC, mora biti v vsakem primeru (r + l) / n >= 0,5, kar pomeni, da bo redundanca pomnilnika vsaj 50%.
V YT je situacija drugačna: vsaka gruča YT je v celoti locirana v 1 DC (različni grozdi v različnih DC), tako da te omejitve ni. Shema 12-2-2 zagotavlja 33% redundanco, to pomeni, da je shranjevanje podatkov cenejše, poleg tega lahko preživi do 4 hkratne izpade diska, tako kot shema MDS.
Obstaja veliko več funkcij uporabe redundantnih kod v sistemih za shranjevanje in obdelavo podatkov: nianse obnovitve podatkov, vpliv obnovitve na čas izvajanja poizvedbe, značilnosti snemanja podatkov itd. O teh in drugih funkcijah bom govoril posebej. uporabe redundantnih kod v praksi, če bo tema zanimiva.
6. Povezave
- Serija člankov o Reed-Solomonovih kodah in Galoisovih poljih:
V dostopnem jeziku se poglobijo v matematiko. - Microsoftov članek o LRC:
V 2. razdelku je na kratko razložena teorija in nato obravnavane izkušnje z LRC v praksi. - Sodo-neparna shema:
- Shema STAR:
- Piramidne kode:
- Odvečne kode v MDS:
- Odvečne kode v YT:
- Odvečne kode v YDB:
Vir: www.habr.com
