


Redno se srečujemo z bazo podatkov Apache Cassandra in potrebo po njenem upravljanju znotraj infrastrukture, ki temelji na Kubernetesu. V tem gradivu bomo delili svojo vizijo potrebnih korakov, meril in obstoječih rešitev (vključno s pregledom operaterjev) za selitev Cassandre na K8s.
"Kdor lahko vlada ženi, lahko vlada tudi državi"
Kdo je Cassandra? Je porazdeljen sistem za shranjevanje, zasnovan za upravljanje velikih količin podatkov, hkrati pa zagotavlja visoko razpoložljivost brez ene same točke okvare. Projekt skoraj ne potrebuje dolgega uvoda, zato bom navedel le glavne značilnosti Cassandre, ki bodo pomembne v kontekstu določenega članka:
- Cassandra je napisana v Javi.
- Topologija Cassandra vključuje več ravni:
- Vozlišče – ena nameščena instanca Cassandra;
- Rack je skupina primerkov Cassandra, združenih po nekaterih značilnostih, ki se nahajajo v istem podatkovnem centru;
- Podatkovno središče - zbirka vseh skupin instanc Cassandra, ki se nahajajo v enem podatkovnem središču;
- Grozd je skupek vseh podatkovnih centrov.
- Cassandra za identifikacijo vozlišča uporablja naslov IP.
- Za pospešitev pisanja in branja Cassandra nekatere podatke shrani v RAM.
Zdaj pa k dejanski potencialni selitvi na Kubernetes.
Kontrolni seznam za prenos
Ko govorimo o selitvi Cassandre na Kubernetes, upamo, da bo s selitvijo postalo bolj priročno za upravljanje. Kaj bo za to potrebno, kaj bo pri tem pomagalo?
1. Shranjevanje podatkov
Kot je bilo že pojasnjeno, Cassanda del podatkov shrani v RAM - v Memtable. Obstaja pa še en del podatkov, ki se shrani na disk – v obliki SSTable. Tem podatkom je dodana entiteta Dnevnik potrditve — evidence vseh transakcij, ki se tudi shranijo na disk.
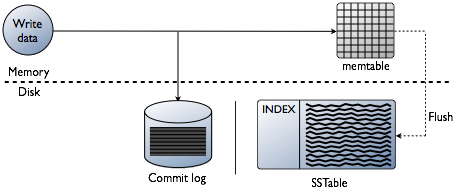
Napišite transakcijski diagram v Cassandri
V Kubernetesu lahko za shranjevanje podatkov uporabimo PersistentVolume. Zahvaljujoč preverjenim mehanizmom je delo s podatki v Kubernetesu vsako leto lažje.
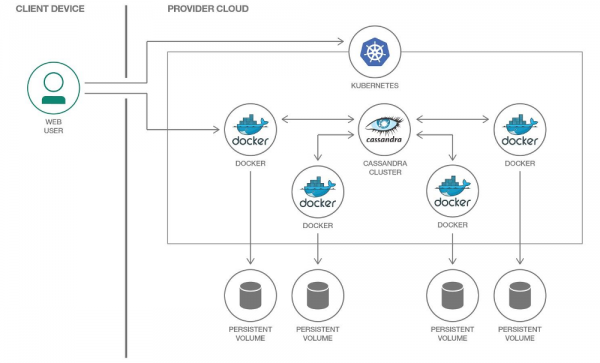
Vsakemu podu s Cassandro bomo dodelili lasten PersistentVolume
Pomembno je omeniti, da Cassandra sama po sebi pomeni replikacijo podatkov in za to ponuja vgrajene mehanizme. Če torej gradite gručo Cassandra iz velikega števila vozlišč, potem za shranjevanje podatkov ni treba uporabljati porazdeljenih sistemov, kot sta Ceph ali GlusterFS. V tem primeru bi bilo logično shranjevanje podatkov na gostiteljski disk z uporabo ali montažo hostPath.
Drugo vprašanje je, ali želite ustvariti ločeno okolje za razvijalce za vsako vejo funkcij. V tem primeru bi bil pravilen pristop dvig enega vozlišča Cassandra in shranjevanje podatkov v porazdeljeno shrambo, tj. omenjena Ceph in GlusterFS bosta vaši možnosti. Potem bo razvijalec prepričan, da ne bo izgubil testnih podatkov, tudi če se izgubi eno od vozlišč gruče Kuberntes.
2. Spremljanje
Skoraj nesporna izbira za izvajanje nadzora v Kubernetesu je Prometheus (o tem smo podrobno govorili v ). Kako gre Cassandri z izvozniki metrik za Prometheus? In kar je še bolj pomembno, z ujemajočimi se nadzornimi ploščami za Grafana?
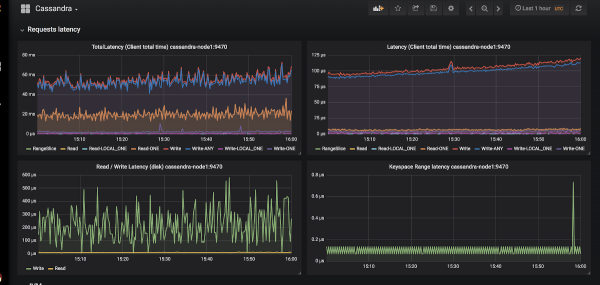
Primer videza grafov v Grafani za Cassandro
Obstajata samo dva izvoznika: и .
Zase smo izbrali prvega, ker:
- JMX Exporter raste in se razvija, medtem ko Cassandra Exporter ni mogel dobiti zadostne podpore skupnosti. Cassandra Exporter še vedno ne podpira večine različic Cassandre.
- Zaženete ga lahko kot javaagent z dodajanjem zastavice
-javaagent:<plugin-dir-name>/cassandra-exporter.jar=--listen=:9180. - Obstaja ena zanj , ki ni združljiv s programom Cassandra Exporter.
3. Izbira primitivov Kubernetes
V skladu z zgornjo strukturo grozda Cassandra poskusimo vse, kar je tam opisano, prevesti v terminologijo Kubernetes:
- Vozlišče Cassandra → Pod
- Cassandra Rack → StatefulSet
- Cassandra Datacenter → bazen iz StatefulSets
- Grozd Cassandra → ???
Izkazalo se je, da manjka neka dodatna entiteta za upravljanje celotne gruče Cassandra hkrati. Če pa nekaj ne obstaja, lahko ustvarimo! Kubernetes ima v ta namen mehanizem za definiranje lastnih virov – .
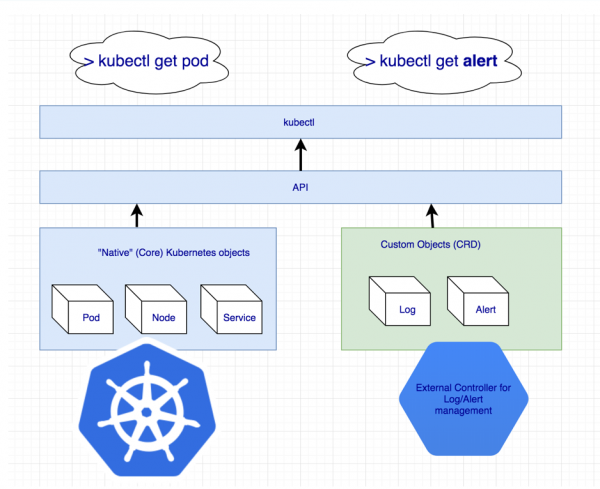
Najava dodatnih virov za dnevnike in opozorila
Toda Custom Resource sam po sebi ne pomeni ničesar: navsezadnje zahteva krmilnik. Morda boste morali poiskati pomoč ...
4. Identifikacija strokov
V zgornjem odstavku smo se dogovorili, da bo eno vozlišče Cassandra enako enemu podu v Kubernetesu. Toda naslovi IP sklopov bodo vsakič drugačni. In identifikacija vozlišča v Cassandri temelji na naslovu IP ... Izkazalo se je, da bo po vsaki odstranitvi poda grozd Cassandra dodal novo vozlišče.
Obstaja izhod in ne samo eden:
- Zapise lahko vodimo po identifikatorjih gostiteljev (UUID-ji, ki enolično identificirajo primerke Cassandra) ali po naslovih IP in vse shranimo v nekaterih strukturah/tabelah. Metoda ima dve glavni pomanjkljivosti:
- Tveganje, da pride do stanja tekmovanja, če padeta dve vozlišči hkrati. Po vzponu bodo vozlišča Cassandra hkrati zahtevala naslov IP iz tabele in tekmovala za isti vir.
- Če je vozlišče Cassandra izgubilo podatke, ga ne bomo mogli več identificirati.
- Druga rešitev se zdi kot majhen kramp, a kljub temu: ustvarimo lahko storitev s ClusterIP za vsako vozlišče Cassandra. Težave s to izvedbo:
- Če je v gruči Cassandra veliko vozlišč, bomo morali ustvariti veliko storitev.
- Funkcija ClusterIP je implementirana prek iptables. To lahko postane problem, če ima gruča Cassandra veliko (1000 ... ali celo 100?) vozlišč. čeprav lahko reši ta problem.
- Tretja rešitev je uporaba omrežja vozlišč za vozlišča Cassandra namesto namenskega omrežja podov z omogočanjem nastavitve
hostNetwork: true. Ta metoda nalaga določene omejitve:- Za zamenjavo enot. Nujno je, da mora imeti novo vozlišče enak naslov IP kot prejšnje (v oblakih kot je AWS, GCP je to skoraj nemogoče);
- Z uporabo omrežja vozlišč gruče začnemo tekmovati za omrežne vire. Zato bo postavitev več kot enega sklopa s Cassandro na eno vozlišče gruče problematična.
5. Varnostne kopije
Želimo shraniti polno različico podatkov posameznega vozlišča Cassandra na urniku. Kubernetes ponuja priročno uporabo funkcije , a tu nam palico v kolesa zabije sama Cassandra.
Naj vas spomnim, da Cassandra nekatere podatke shrani v pomnilnik. Za popolno varnostno kopijo potrebujete podatke iz pomnilnika (Memtables) premakni na disk (SSTables). Na tej točki vozlišče Cassandra preneha sprejemati povezave in se popolnoma izklopi iz gruče.
Po tem se varnostna kopija odstrani (Posnetek) in shema je shranjena (prostor za tipke). In potem se izkaže, da nam samo varnostna kopija ne daje ničesar: shraniti moramo identifikatorje podatkov, za katere je bilo odgovorno vozlišče Cassandra - to so posebni žetoni.
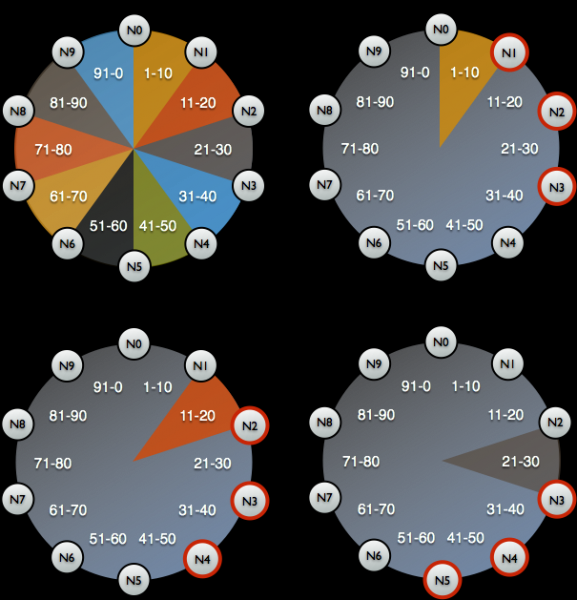
Porazdelitev žetonov za identifikacijo, za katere podatke so odgovorna vozlišča Cassandra
Primer skripta za ustvarjanje varnostne kopije Cassandra iz Googla v Kubernetes lahko najdete na . Edina točka, ki je skript ne upošteva, je ponastavitev podatkov v vozlišče pred snemanjem posnetka. To pomeni, da se varnostno kopiranje ne izvede za trenutno stanje, ampak za stanje malo prej. Toda to pomaga, da vozlišče ne preneha delovati, kar se zdi zelo logično.
set -eu
if [[ -z "$1" ]]; then
info "Please provide a keyspace"
exit 1
fi
KEYSPACE="$1"
result=$(nodetool snapshot "${KEYSPACE}")
if [[ $? -ne 0 ]]; then
echo "Error while making snapshot"
exit 1
fi
timestamp=$(echo "$result" | awk '/Snapshot directory: / { print $3 }')
mkdir -p /tmp/backup
for path in $(find "/var/lib/cassandra/data/${KEYSPACE}" -name $timestamp); do
table=$(echo "${path}" | awk -F "[/-]" '{print $7}')
mkdir /tmp/backup/$table
mv $path /tmp/backup/$table
done
tar -zcf /tmp/backup.tar.gz -C /tmp/backup .
nodetool clearsnapshot "${KEYSPACE}"Primer bash skripta za varnostno kopijo iz enega vozlišča Cassandra
Pripravljene rešitve za Cassandro v Kubernetesu
Kaj se trenutno uporablja za uvajanje Cassandre v Kubernetes in kateri od teh najbolj ustreza danim zahtevam?
1. Rešitve, ki temeljijo na grafikonih StatefulSet ali Helm
Uporaba osnovnih funkcij StatefulSets za zagon gruče Cassandra je dobra možnost. Z uporabo grafikona Helm in predlog Go lahko uporabniku zagotovite prilagodljiv vmesnik za uvajanje Cassandre.
To običajno dobro deluje ... dokler se ne zgodi nekaj nepričakovanega, na primer okvara vozlišča. Standardna orodja Kubernetes enostavno ne morejo upoštevati vseh zgoraj opisanih funkcij. Poleg tega je ta pristop zelo omejen glede tega, koliko ga je mogoče razširiti za bolj zapletene uporabe: zamenjava vozlišča, varnostno kopiranje, obnovitev, spremljanje itd.
Predstavniki:
- ;
- .
Oba grafikona sta enako dobra, vendar sta predmet zgoraj opisanih težav.
2. Rešitve, ki temeljijo na Kubernetes Operator
Takšne možnosti so bolj zanimive, ker ponujajo veliko možnosti za upravljanje grozda. Za načrtovanje operaterja Cassandra, tako kot za vsako drugo bazo podatkov, je dober vzorec videti kot Sidecar Controller CRD:
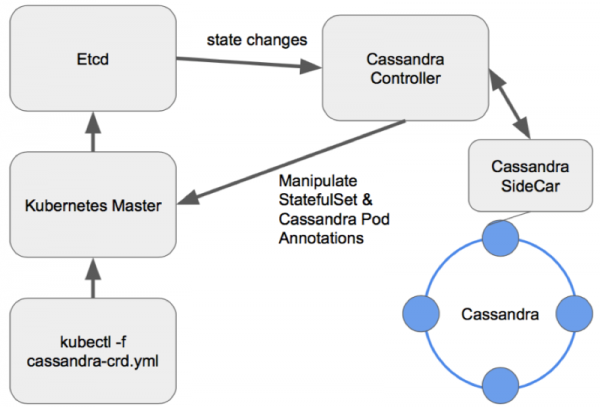
Shema upravljanja vozlišč v dobro zasnovanem operaterju Cassandra
Poglejmo obstoječe operaterje.
1. Operater Cassandra iz instaclustr
- Pripravljenost: Alfa
- Licenca: Apache 2.0
- Implementirano v: Java
To je res zelo obetaven in aktivno razvijajoč se projekt podjetja, ki ponuja upravljane uvedbe Cassandre. Kot je opisano zgoraj, uporablja vsebnik stranske prikolice, ki sprejema ukaze prek HTTP. Napisan v Javi, včasih nima naprednejše funkcionalnosti knjižnice client-go. Poleg tega operater ne podpira različnih omaric za en podatkovni center.
Toda operater ima takšne prednosti, kot so podpora za spremljanje, upravljanje grozdov na visoki ravni z uporabo CRD in celo dokumentacija za izdelavo varnostnih kopij.
2. Navigator iz Jetstacka
- Pripravljenost: Alfa
- Licenca: Apache 2.0
- Izvedeno v: Golang
Izjava, namenjena uvajanju DB-as-a-Service. Trenutno podpira dve bazi podatkov: Elasticsearch in Cassandra. Ima tako zanimive rešitve, kot je nadzor dostopa do baze podatkov prek RBAC (za to ima svoj ločen navigator-apiserver). Zanimiv projekt, ki bi se ga splačalo podrobneje pogledati, vendar je bil zadnji mit narejen pred letom in pol, kar očitno zmanjšuje njegov potencial.
3. Cassandra-operator avtorja vgkowskega
- Pripravljenost: Alfa
- Licenca: Apache 2.0
- Izvedeno v: Golang
Tega niso obravnavali "resno", saj je bila zadnja potrditev v repozitorij pred več kot enim letom. Razvoj operaterja je opuščen: zadnja različica Kubernetesa, ki je prijavljena kot podprta, je 1.9.
4. Cassandra-operator Rook
- Pripravljenost: Alfa
- Licenca: Apache 2.0
- Izvedeno v: Golang
Operater, katerega razvoj ne napreduje tako hitro, kot bi si želeli. Ima dobro premišljeno strukturo CRD za upravljanje gruče, rešuje problem prepoznavanja vozlišč z uporabo storitve s ClusterIP (isti “hack”) ... ampak to je zaenkrat vse. Trenutno ni nadzora ali varnostnih kopij takoj po namestitvi (mimogrede, mi smo za spremljanje ). Zanimiva točka je, da lahko s tem operaterjem tudi namestite ScyllaDB.
Opomba: Ta operater smo uporabili z manjšimi spremembami v enem od naših projektov. V celotnem obdobju delovanja (~4 mesece delovanja) pri delu operaterja ni bilo opaziti težav.
5. CassKop iz Orangea
- Pripravljenost: Alfa
- Licenca: Apache 2.0
- Izvedeno v: Golang
Najmlajši operater na seznamu: prva potrditev je bila izvedena 23. maja 2019. Že zdaj ima v svojem arzenalu veliko število funkcij z našega seznama, več podrobnosti o katerih lahko najdete v repozitoriju projekta. Operater je zgrajen na osnovi priljubljenega operaterja-sdk. Podpira spremljanje takoj po namestitvi. Glavna razlika od drugih operaterjev je uporaba , implementiran v Python in uporabljen za komunikacijo med vozlišči Cassandra.
Ugotovitve
Število pristopov in možnih možnosti za prenos Cassandre v Kubernetes govori zase: tema je v povpraševanju.
Na tej stopnji lahko poskusite kar koli od zgoraj naštetega na lastno odgovornost in tveganje: nobeden od razvijalcev ne jamči 100-odstotnega delovanja svoje rešitve v produkcijskem okolju. Toda že zdaj je veliko izdelkov videti obetavnih, da bi jih poskusili uporabiti v razvojnih mizah.
Mislim, da bo v prihodnosti ta ženska na ladji prišla prav!
PS
Preberite tudi na našem blogu:
- «»;
- «»;
- «»;
- «".
Vir: www.habr.com
