

Splošno znano je, da se kompetence tehničnega direktorja preverijo šele, ko vlogo prevzame drugič. Ena stvar je delati za podjetje več let, se skupaj z njim razvijati in, medtem ko je še vedno v istem kulturnem kontekstu, postopoma pridobivati večjo odgovornost. Povsem nekaj drugega pa je, da takoj stopite na mesto tehničnega direktorja v podjetju z zapuščino težav in kopico skrbno pometenih vprašanj.
V tem smislu je izkušnja Leona Fayerja, ki jo je delil na Ni ravno edinstveno, a v kombinaciji z njegovimi izkušnjami in številom različnih vlog, ki jih je prevzel v 20 letih, je zelo koristno. Spodaj je kronologija dogodkov v 90 dneh in številne anekdote, ki se jim je zabavno smejati, ko se zgodijo nekomu drugemu, vendar jih ni tako zabavno srečati v živo.
Leon zelo živo govori rusko, zato vam priporočam ogled videa, če imate 35–40 minut. Besedilna različica je spodaj, da prihranite čas.

Prva različica poročila je bila dobro strukturiran opis dela z ljudmi in procesi, ki je vseboval koristna priporočila. Vendar ni zajela vseh presenečenj, s katerimi sem se srečala na poti. Zato sem spremenil format in predstavil težave, ki so se pojavile v novem podjetju, kot bi se dogajalo v škatli, in metode za njihovo reševanje, v kronološkem vrstnem redu.
Mesec dni prej
Kot mnoge dobre zgodbe se je tudi ta začela z alkoholom. Sedeli smo v baru s prijatelji in kot je značilno v IT-krogih, so se vsi pritoževali nad svojimi težavami. Eden od njih je pravkar zamenjal službo in mi je pripovedoval o svojih težavah s tehnologijo, ljudmi in ekipo. Bolj ko sem poslušal, bolj sem spoznaval, da bi me moral preprosto zaposliti, saj so to točno takšne težave, ki jih rešujem zadnjih 15 let. To sem mu povedal in naslednji dan sva se srečala v delovnem okolju. Podjetje se je imenovalo Teaching Strategies.
Teaching Strategies je vodilni na trgu izobraževalne programske opreme za zelo majhne otroke – od rojstva do treh let. Tradicionalno podjetje, ki temelji na papirju, je staro 40 let, medtem ko je digitalna različica platforme SaaS stara 10 let. Proces prilagajanja digitalne tehnologije standardom podjetja se je začel relativno pred kratkim. »Nova« različica je bila predstavljena leta 2017 in je bila skoraj enaka stari, le manj funkcionalna.
Najbolj zanimivo je, da je promet tega podjetja zelo predvidljiv – iz dneva v dan, leto za letom, lahko natančno napovete, koliko ljudi bo prišlo in kdaj. Na primer, med 13. in 15. uro gredo vsi otroci v vrtcu spat, učitelji pa začnejo vnašati podatke. In to se dogaja vsak dan, razen ob vikendih, saj ob vikendih skoraj nihče ne dela.
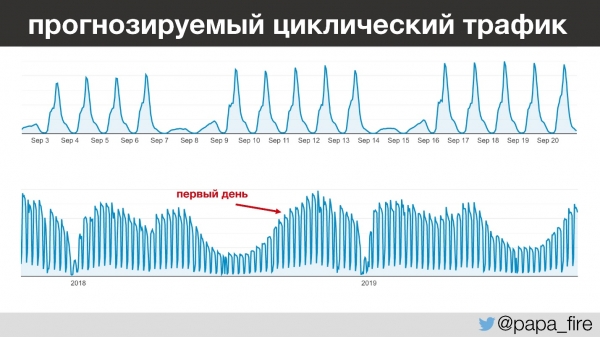
Če pogledamo malo naprej, bom omenil, da sem svoje delo začel v obdobju največjega letnega prometa, kar je zanimivo iz več razlogov.
Platforma, ki se je zdela stara komaj dve leti, je imela edinstven sklad: ColdFusion in SQL Server iz leta 2008. ColdFusion, če ne veste (in verjetno ne), je poslovni PHP jezik, ki je izšel sredi 90. let, in od takrat zanj sploh nisem slišal. Vseboval je tudi Ruby, MySQL, PostgreSQL, Javo, Go in Python. Toda osnovni monolit je deloval na ColdFusionu in SQL Serverju.
Težave
Bolj ko sem se z zaposlenimi v podjetju pogovarjal o njihovem delu in izzivih, s katerimi se soočajo, bolj sem spoznaval, da težave niso bile le tehnične. Pravzaprav je bila tehnologija stara – delovali so že s slabšo, vendar so bile težave z ekipo in procesi, in podjetje je to začelo razumeti.
Tradicionalno so njihovi tehniki sedeli v kotu in počeli svoje stvari. Vendar se je vse več poslovanja začelo premikati digitalno. Tako je podjetje v zadnjem letu, preden sem začel delati tam, dobilo nove člane: upravni odbor, tehničnega direktorja, finančnega direktorja in direktorja za zagotavljanje kakovosti. Z drugimi besedami, podjetje je začelo vlagati v tehnologijo.
Sledi težke zapuščine niso bile le v sistemih. Podjetje je imelo zastarele procese, zastarele ljudi in zastarelo kulturo. Vse to je bilo treba spremeniti. Mislil sem, da ne bo dolgočasno, zato sem se odločil, da poskusim.
Dva dni prej
Dva dni pred začetkom nove službe sem prišel v pisarno, izpolnil zadnje papirje, se srečal z ekipo in ugotovil, da se soočajo s težavo. Težava je bila v tem, da se je povprečni čas nalaganja strani podvojil in poskočil na 4 sekunde.
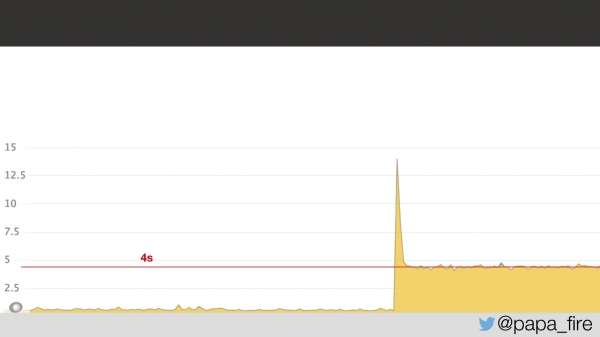
Sodeč po grafu je bilo očitno nekaj narobe, pa ni bilo jasno, kaj. Izkazalo se je, da gre za težavo z omrežno zakasnitvijo v podatkovnem centru: 5 ms zakasnitve v podatkovnem centru se je za uporabnike prevedlo v 2 sekundi. Nisem vedel, zakaj se je to zgodilo, ampak vsaj postalo je jasno, da je težava v podatkovnem centru.
Prvi dan
Minila sta dva dni in prvi dan v službi sem ugotovil, da težava ni izginila.
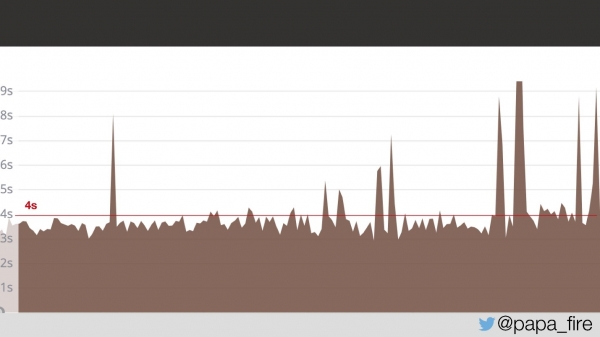
Dva dni so se strani uporabnikov nalagale v povprečju v 4 sekundah. Vprašal sem jih, ali so odkrili težavo.
- Da, odprli smo vozovnico.
- IN?
- No, še nam niso odgovorili.
Tu sem spoznal, da je vse, kar so mi povedali prej, le vrh ledene gore, proti kateremu se je bilo treba boriti.
Za ta primer je zelo primeren dober citat:
"Včasih je za spremembo tehnologije treba spremeniti organizacijo."
Ker pa sem začel delati v najbolj prometnem času leta, sem moral razmisliti tako o takojšnjih kot dolgoročnih rešitvah. In začeti sem moral s tistim, kar je bilo trenutno ključnega pomena.
Tretji dan
Torej, čas nalaganja je 4 sekunde, največji vrhovi pa so od 13 do 15.
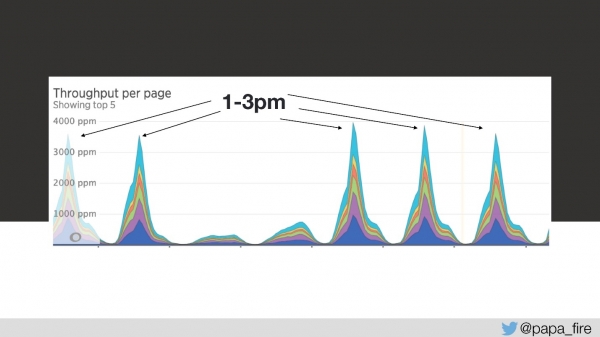
Tretji dan v tem obdobju je bila hitrost prenosa videti takole:
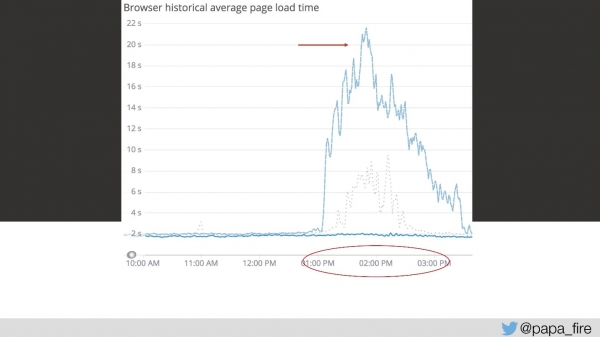
Z mojega vidika ni delovalo prav nič. Z vidika vseh ostalih je delovalo nekoliko počasneje kot običajno. Ampak to se ne zgodi kar tako – to je resen problem.
Poskušal sem prepričati ekipo, vendar so mi rekli, da preprosto potrebujejo več strežnikov. To je zagotovo rešitev, vendar še zdaleč ni edina ali najučinkovitejša. Vprašal sem, zakaj ni dovolj strežnikov in kolikšen je obseg prometa. Ekstrapoliral sem podatke in ugotovil, da imamo približno 150 zahtev na sekundo, kar je na splošno v razumnih mejah.
Vendar ne smemo pozabiti, da moramo preden dobimo pravi odgovor, postaviti pravo vprašanje. Moje naslednje vprašanje je bilo: koliko strežnikov za prednje stranke imamo? Odgovor me je malo "osupnil" – imeli smo 17 strežnikov za prednje stranke!
— Nerodno mi je vprašati, ampak 150 deljeno s 17 je enako približno 8? Ali pravite, da vsak strežnik obdela 8 zahtev na sekundo, in če bomo jutri imeli 160 zahtev na sekundo, bomo potrebovali še dva strežnika?
Seveda nismo potrebovali dodatnih strežnikov. Rešitev je bila v sami kodi, kar na prvi pogled:
var currentClass = classes.getCurrentClass();
return currentClass; Bila je funkcija getCurrentClass(), ker vse na spletnem mestu deluje v kontekstu razreda – pravilno. In za to eno funkcijo na vsaki strani, 200+ zahtev.
Rešitev je bila torej zelo preprosta, ni bilo treba ničesar prepisovati: preprosto ni bilo treba več zahtevati istih podatkov.
if ( !isDefined("REQUEST.currentClass") ) {
var classes = new api.private.classes.base();
REQUEST.currentClass = classes.getCurrentClass();
}
return REQUEST.currentClass;Bil sem presrečen, ker sem mislil, da sem glavno težavo odkril šele tretji dan. Kako naiven sem bil, saj je bila to le ena od mnogih težav.
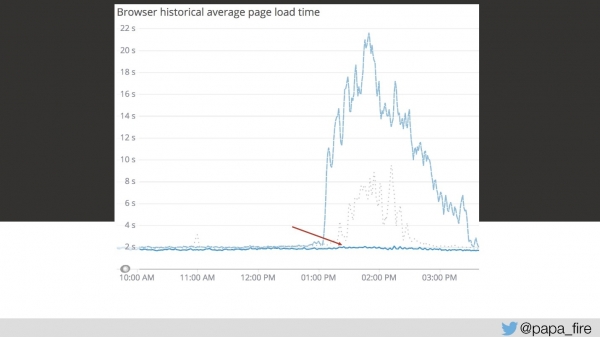
Toda rešitev te prve težave je graf spustila precej nižje.
Hkrati smo delali na drugih optimizacijah. Veliko stvari bi se dalo takoj popraviti. Na primer, tretji dan sem odkril, da ima sistem predpomnilnik (sprva sem mislil, da vse zahteve prihajajo neposredno iz baze podatkov). Ko pomislim na predpomnilnik, si predstavljam standardni Redis ali Memcached. Ampak to sem bil samo jaz, ker je predpomnjenje v tem sistemu uporabljalo MongoDB in SQL Server – istega, iz katerega smo pravkar brali podatke.
Deseti dan
Prvi teden sem se ukvarjal z vprašanji, ki jih je bilo treba obravnavati takoj. Približno v drugem tednu sem se prvič udeležil sestanka v stoje, da bi se pogovoril z ekipo, videl, kaj se dogaja in kako poteka celoten proces.
Spet se je pojavilo nekaj zanimivega. Ekipa je bila sestavljena iz: 18 razvijalcev; 8 preizkuševalcev; 3 menedžerjev; 2 arhitekta. In vsi so sodelovali v skupnih ritualih, kar je pomenilo, da je vsako jutro na sestanek prišlo več kot 30 ljudi in poročalo o tem, kaj počnejo. Jasno je, da sestanek ni trajal 5 ali 15 minut. Nihče ni poslušal nikogar drugega, ker je vsak delal na različnih sistemih. V tej obliki sta bila 2-3 vstopnice na uro med seanso nege že dober rezultat.
Najprej smo ekipo razdelili na več produktnih linij. Za različne oddelke in sisteme smo ustvarili ločene ekipe, vključno z razvijalci, preizkuševalci, produktnimi vodji in poslovnimi analitiki.
Rezultat je bil:
- Zmanjšanje števila stoječih protestov in shodov.
- Predmetno poznavanje izdelka.
- Občutek lastništva. Ko so ljudje nenehno menjavali sisteme, so vedeli, da bo njihove napake verjetno odpravljal nekdo drug, ne oni sami.
- Sodelovanje med ekipami. Ni treba posebej poudarjati, da QA in programerji prej niso veliko sodelovali; vodja produktov je počel svoje itd. Zdaj imajo skupno točko odgovornosti.
Naš glavni poudarek je bil na učinkovitosti, produktivnosti in kakovosti – to so bile težave, ki smo jih poskušali rešiti s preoblikovanjem ekipe.
Enajsti dan
Med spreminjanjem strukture ekipe sem odkril, kako izračunati ZgodbaTočke1 SP je bil enak enemu dnevu, vsaka zahteva pa je vsebovala SP tako za razvoj kot za zagotavljanje kakovosti, torej vsaj 2 SP.
Kako sem to odkril/a?
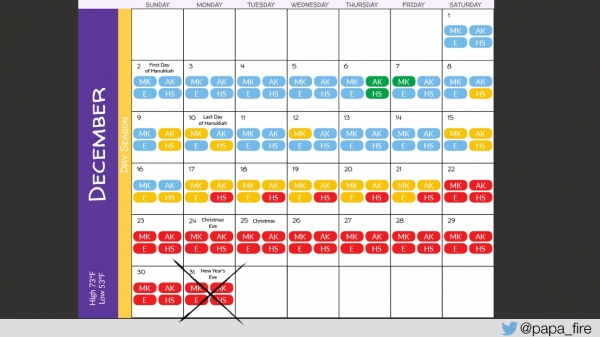
Našli smo napako: v enem od poročil, kjer vnesete začetni in končni datum obdobja, za katerega potrebujete poročilo, se zadnji dan ne upošteva. To pomeni, da nekje v poizvedbi ni bilo <=, ampak preprosto <. Rečeno mi je bilo, da gre za tri Story Points, kar pomeni 3 dni.
Po tem mi:
- Prenovili smo sistem zgodbenih točk. Zdaj manjši popravki napak, ki jih je mogoče hitro obdelati prek sistema, hitreje dosežejo uporabnike.
- Začeli smo z združevanjem povezanih razvojnih in testnih zahtevkov. Prej je bil vsak zahtevek, vsaka napaka, zaprt ekosistem, nepovezan z ničemer drugim. Sprememba treh gumbov na eni strani je lahko povzročila tri različne zahteve s tremi različnimi postopki zagotavljanja kakovosti namesto enega samega avtomatiziranega testa na stran.
- Z razvijalci smo začeli sodelovati pri pristopu k ocenjevanju stroškov dela. Tri dni za menjavo enega gumba ni smešno.
Dvajseti dan
Nekje sredi prvega meseca se je stanje nekoliko stabiliziralo, ugotovil sem, kaj se v bistvu dogaja, in začel sem gledati v prihodnost ter razmišljati o dolgoročnih rešitvah.
Dolgoročni cilji:
- Upravljana platforma. Na stotine poizvedb na vsaki strani ni resnih.
- Predvidljivi trendi. Občasno so se pojavljali prometni vrhunci, ki se na prvi pogled niso zdeli povezani z drugimi meritvami – razumeti smo morali, zakaj se je to zgodilo, in se naučiti to napovedati.
- Širitev platforme. Poslovanje nenehno raste, prihaja vedno več uporabnikov in promet se povečuje.
V preteklosti se je pogosto govorilo: "Prepišimo vse v [jezik/ogrodje], vse bo delovalo bolje!"
V večini primerov to ne deluje; dobro je, če prepis sploh deluje. Zato smo morali ustvariti načrt – konkretno strategijo, ki korak za korakom prikazuje, kako bomo dosegli svoje poslovne cilje (kaj bomo storili in zakaj), ki:
- odraža poslanstvo in cilje projekta;
- daje prednost ključnim ciljem;
- vsebuje urnik za njihovo doseganje.
Pred tem se nihče z ekipo ni pogovoril o namenu kakršnih koli sprememb. To zahteva ustrezne metrike uspeha. Prvič v zgodovini podjetja smo za tehnično ekipo določili ključne kazalnike uspešnosti in te metrike povezali z organizacijskimi.
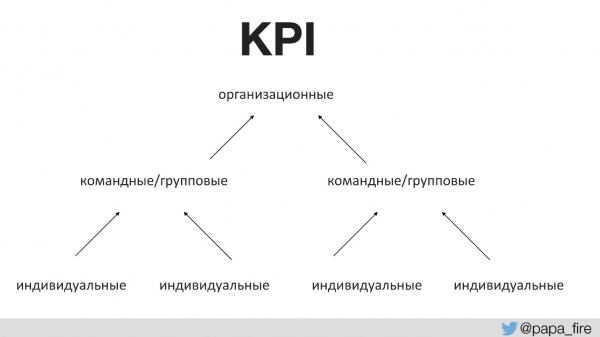
Z drugimi besedami, ključne kazalnike uspešnosti organizacije podpirajo ekipe, ključne kazalnike uspešnosti ekipe pa podpirajo posamezni ključni kazalniki uspešnosti. V nasprotnem primeru, če se ključni kazalniki uspešnosti procesa ne ujemajo s ključnimi kazalniki uspešnosti organizacije, bodo vsi ostali brez odgovornosti.
Na primer, eden od ključnih kazalnikov uspešnosti organizacije je povečanje tržnega deleža z novimi izdelki.
Kako lahko podpremo cilj, da imamo več novih izdelkov?
- Prvič, želimo porabiti več časa za razvoj novih izdelkov namesto za odpravljanje napak. To je logična odločitev, ki jo je mogoče enostavno izmeriti.
- Drugič, želimo podpreti rast obsega transakcij, saj večji kot je tržni delež, več je uporabnikov in posledično več prometa.
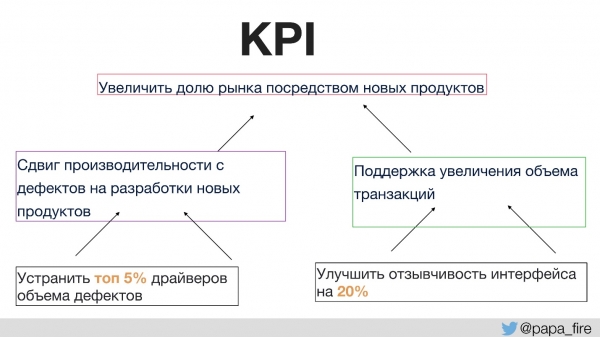
Nato bodo posamezni ključni kazalniki uspešnosti, ki jih je mogoče implementirati znotraj skupine, na primer locirani tam, kjer izvirajo glavne napake. Če se osredotočite posebej na ta del, lahko znatno zmanjšate število napak, povečate čas, porabljen za razvoj novih izdelkov, in s tem podprete ključne kazalnike uspešnosti organizacije.
Zato mora vsaka odločitev, vključno s prepisovanjem kode, podpirati specifične cilje, ki nam jih je podjetje zadalo (rast organizacije, nove funkcije, zaposlovanje).
Med tem postopkom se je pojavila zanimiva stvar, ki ni bila novost le za tehnično ekipo, temveč za celotno podjetje: vse zahteve se morajo osredotočati na vsaj en ključni kazalnik uspešnosti. Če torej vodja produkta reče, da želi zgraditi novo funkcijo, bi moralo biti prvo vprašanje: "Kateri ključni kazalnik uspešnosti podpira ta funkcija?" Če nobenega, potem oprostite – zdi se, da je funkcija nepotrebna.
Trideseti dan
Konec meseca sem odkril še eno nianso: nihče v moji operativni ekipi ni nikoli videl pogodb, ki jih podpisujemo s strankami. Morda se sprašujete, zakaj bi kdo želel videti stike?
- Prvič, ker so sporazumi o ravni storitev (SLA) določeni v pogodbah.
- Drugič, vsi sporazumi o ravni storitev (SLA) so različni. Vsaka stranka je prišla s svojimi zahtevami, prodajna ekipa pa jih je podpisala, ne da bi jih pregledala.
Še ena zanimiva podrobnost: pogodba z eno od naših največjih strank določa, da morajo biti vse različice programske opreme, ki jih platforma podpira, n-1, kar pomeni, da ne gre za najnovejšo različico, temveč za predzadnjo.
Jasno je, kako daleč smo bili od n-1, če je platforma temeljila na ColdFusionu in SQL Serverju 2008, ki julija sploh ni bil več podprt.
Petinštirideseti dan
Nekje sredi drugega meseca sem imel dovolj časa, da sem se usedel in naredil vrednosttokkartiranje Celoten postopek. To so potrebni koraki, ki jih je treba izvesti, od ustvarjanja izdelka do dostave potrošniku, in jih je treba opisati čim bolj podrobno.
Postopek razdelite na manjše dele in pogledate, kaj traja predolgo, kaj je mogoče optimizirati, izboljšati itd. Na primer, koliko časa traja, da se zahteva za izdelek pregleda, kdaj pride do zahteve, ki jo lahko obdela razvijalec, preverjanje kakovosti itd. Vsak korak podrobno pregledate in razmislite, kaj je mogoče optimizirati.
Med tem sta mi v oči padli dve stvari:
- visok odstotek zahtevkov, vrnjenih iz oddelka za kakovost (QA) nazaj razvijalcem;
- Pregledi zahtevkov za vlečenje so trajali predolgo.
Težava je bila v tem, da so bili to sklepi, kot je: zdi se, da traja dolgo, vendar nismo prepričani, koliko natančno.
"Ne moreš izboljšati tistega, česar ne moreš izmeriti."
Kako lahko upravičite resnost težave? Ali gre za izgubljanje dni ali ur?
Da bi to izmerili, smo procesu Jira dodali nekaj korakov: »pripravljeno za razvoj« in »pripravljeno za zagotavljanje kakovosti«, da bi izmerili, koliko časa vsaka zahteva čaka in kolikokrat se vrne na določen korak.
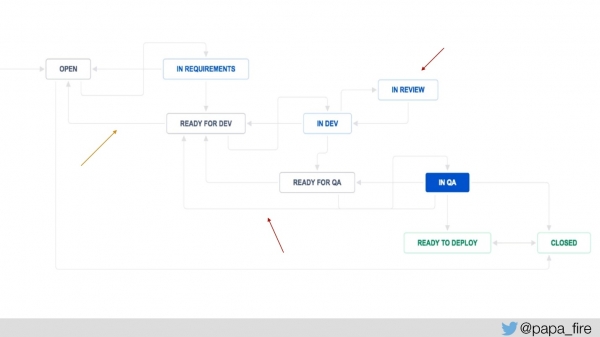
Dodali smo tudi možnost »v pregledu«, da bi spremljali povprečni čas, ko so zahteve v pregledu, nato pa lahko začnemo meriti stvari od tam naprej. Sistemske metrike smo že imeli, zdaj pa smo dodali nove in začeli meriti:
- Učinkovitost procesa: uspešnost in načrtovano/dostavljeno.
- Kakovost procesa: število napak, napake iz zagotavljanja kakovosti.
Resnično pomaga razumeti, kaj gre dobro in kaj slabo.
Petdeseti dan
Seveda je vse to lepo in zanimivo, toda proti koncu drugega meseca se je zgodilo nekaj, kar je bilo v osnovi predvidljivo, čeprav nisem pričakoval takšnega obsega. Ljudje so začeli odhajati, ker se je zamenjalo vodstvo. V vodstvo so prišli novi ljudje in začeli vse spreminjati, stari pa so odšli. In ponavadi so v podjetju, ki obstaja že nekaj let, vsi prijatelji in se vsi poznajo.
To je bilo pričakovano, vendar je bil obseg odpuščanj nepričakovan. Na primer, v enem tednu sta dva vodji ekip hkrati podala odpoved. Zato sem moral ne le pozabiti na druge zadeve, ampak se osredotočiti tudi na ustvarjanje ekipeTo je dolgotrajen in težaven problem, vendar smo se ga morali lotiti, ker smo želeli obdržati ljudi, ki so ostali (ali vsaj večino). Nekako smo se morali odzvati na ljudi, ki so odšli, da bi ohranili moralo v ekipi.
Teoretično je to dobro: nova oseba pride s popolnimi pooblastili, lahko oceni znanja ekipe in nadomesti obstoječe osebje. V resnici pa je iz različnih razlogov nemogoče preprosto pripeljati nove ljudi. Vedno je potrebno ravnovesje.
- Staro in novo. Obdržati moramo stare ljudi, ki lahko spremenijo in podprejo poslanstvo. Hkrati pa moramo pripeljati tudi novo kri, o čemer bomo govorili malo kasneje.
- Izkušnje. Veliko sem se pogovarjal z dobrimi mladinci, ki so se nam želeli pridružiti. Vendar jih nisem mogel zaposliti, ker ni bilo dovolj starejših, ki bi jih podpirali in mentorirali. Najprej smo morali zaposliti najboljše fante in šele nato mlade.
- Korenček in palica.
Nimam dobrega odgovora na vprašanje, kakšno je pravo ravnovesje, kako ga ohraniti, koliko ljudi obdržati in koliko pritiska izvajati. To je povsem individualen proces.
Enainpetdeseti dan
Začel sem si ogledovati ekipo, da bi videl, koga imam, in spet sem se spomnil:
"Večina težav so težave ljudi."
Ugotovil sem, da je imela ekipa kot celota, tako razvijalci kot operativni delavci, tri velike težave:
- Zadovoljstvo s trenutnim stanjem.
- Pomanjkanje odgovornosti — ker nihče še ni prevedel rezultatov dela izvajalcev v njihov vpliv na poslovanje.
- Strah pred spremembami.

Sprememba te vedno popelje iz cone udobja, in mlajši kot so ljudje, bolj jim spremembe niso všeč, ker ne razumejo, zakaj ali kako. Najpogostejši odgovor, ki sem ga slišal, je bil: "Tega še nikoli nismo počeli tako." To je doseglo točko popolnega absurda – tudi najmanjša sprememba ne bi šla skozi, ne da bi se kdo pritoževal. In ne glede na to, kako zelo je sprememba vplivala na njihovo delo, so ljudje rekli: "Ne, zakaj bi se trudili? Ne bo delovalo."
Ampak ne moreš postati boljši, ne da bi karkoli spremenil.
Imel sem popolnoma absurden pogovor z zaposlenim, povedal sem mu svoje ideje za optimizacijo, na kar je rekel:
- Ah, nisi videl, kaj smo imeli lani!
- Pa kaj?
— Zdaj je veliko bolje kot je bilo.
- Torej, ne more biti boljše?
- Kaj za?
Dobro vprašanje – zakaj? Kot da če so stvari zdaj boljše, kot so bile, potem je vse dovolj dobro. To vodi do pomanjkanja odgovornosti, kar je povsem normalno. Kot sem rekel, je bila tehnološka skupina nekoliko ob strani. Podjetje je menilo, da bi morali biti tam, ampak nihče ni nikoli postavil standardovTehnična podpora še nikoli ni videla sporazuma o ravni storitev (SLA), zato je bil za skupino popolnoma "sprejemljiv" (in to me je najbolj presenetilo):
- 12 sekund nalaganja;
- 5–10 minut izpada na izdajo;
- Reševanje kritičnih težav traja več dni in celo tednov;
- brez 24/7 dežurnega osebja.
Nihče se ni nikoli vprašal, zakaj tega ne bi mogli narediti bolje, in nihče se ni nikoli zavedel, da ne bi smelo biti tako.
Kot bonus je bila še ena težava: pomanjkanje izkušenjStarejši so odšli, preostala mlada ekipa pa je odraščala pod prejšnjim režimom in jo je ta zastrupil.
Poleg vsega tega so se ljudje bali tudi neuspeha in tega, da bi se zdeli nesposobni. To se je odražalo v dejstvu, da so se, prvič, pod nobenim pogojem ni prosil za pomočKolikokrat smo se že pogovarjali v skupinah in individualno in sem rekel: "Postavi vprašanje, če nečesa ne veš?" Sem samozavesten in vem, da lahko rešim vsak problem, vendar bo to trajalo nekaj časa. Če torej lahko vprašam nekoga, ki zna rešiti problem v 10 minutah, bom to storil. Manj izkušenj kot imaš, bolj se bojiš vprašati, ker misliš, da te bodo imeli za nesposobnega.
Ta strah pred postavljanjem vprašanj se kaže na zanimive načine. Na primer, vprašate: "Kako gre ta naloga?" in oni odgovorijo: "Samo nekaj ur je stran, skoraj sem končal." Naslednji dan vprašate znova in vam povedo, da je vse v redu, vendar obstaja samo ena težava, ki bo zagotovo rešena do konca dneva. Mine še en dan in dokler jih ne stisnete v kot in jih prisilite, da se z nekom pogovorijo, se stvari nadaljujejo tako. Problem želijo rešiti sami, saj verjamejo, da bo, če ga ne bodo rešili sami, velik neuspeh.
Zato Razvijalci so napihnili oceneBila je precejšnja šala: ko smo se pogovarjali o določeni nalogi, so mi dali številko, ki me je resnično presenetila. Povedali so mi, da razvijalec v svoje ocene vključi čas, ki bo potreben, da se zahtevek vrne iz oddelka za kakovost, ker najdejo napake, čas, ki bo potreben za odnose z javnostmi, in čas, ki ga bodo ljudje, ki naj bi ga pregledali, imeli zasedenost – z drugimi besedami, vse, kar je mogoče.
Drugič, ljudje, ki se bojijo, da bodo videti nesposobni, preveč analiziratiKo jim poveš, kaj točno je treba storiti, začnejo govoriti: "Ne, kaj če o tem razmislimo tukaj?" V tem smislu naše podjetje ni edinstveno; to je pogosta težava med mladimi.
V odgovor sem uvedel naslednje prakse:
- Pravilo 30 minut. Če težave ne morete rešiti v pol ure, prosite za pomoč nekoga drugega. To deluje z različnim uspehom, saj ljudje tako ali tako ne prosijo, ampak vsaj postopek se je začel.
- Odstranite vse razen bistva, pri ocenjevanju časa, potrebnega za dokončanje naloge, torej upoštevajte le, koliko časa bo trajalo pisanje kode.
- Nenehno učenje Za tiste, ki preveč analizirajo. Gre le za nenehno delo z ljudmi.
Šestdeseti dan
Medtem ko sem vse to počel, je bil čas, da uredim proračun. Seveda sem odkril veliko zanimivih stvari o tem, kako smo porabljali denar. Na primer, imeli smo celo omaro v ločenem podatkovnem centru, v kateri je bil en sam FTP strežnik, ki ga je uporabljala ena sama stranka. Izkazalo se je, da »...smo se preselili, a je ostal tam, nismo ga zamenjali.« To je bilo pred dvema letoma.
Še posebej zanimiv je bil račun za oblak. Prepričan sem, da je glavni razlog za visok račun za oblak ta, da imajo razvijalci prvič v življenju neomejen dostop do strežnikov. Ni jim treba prositi: "Prosim, dajte mi testni strežnik" – lahko ga prevzamejo sami. Poleg tega si razvijalci vedno želijo zgraditi tako kul sistem, da bi jim Facebook in Netflix zavidala.
Vendar razvijalcem primanjkuje izkušenj z nabavo strežnikov in znanj za določanje prave velikosti strežnika, ker jim tega prej ni bilo treba storiti. In pogosto ne razumejo v celoti razlike med skalabilnostjo in zmogljivostjo.
Rezultati popisa:
- Prihaja iz istega podatkovnega centra.
- Prekinili smo pogodbe s tremi storitvami sečnje. Ker smo jih imeli pet – vsak razvijalec, ki se je začel z nečim ukvarjati, je najel novega.
- Sedem sistemov AWS je bilo zaustavljenih. Tudi v tem primeru mrtvi projekti niso bili zaustavljeni; še naprej so delovali.
- Stroški programske opreme so se zmanjšali za 6-krat.
Petinsedemdeseti dan
Čas je mineval in čez dva meseca in pol sem se moral sestati z upravnim odborom. Naš upravni odbor ni nič boljši ali slabši od katerega koli drugega; tako kot vsi upravni odbori želi vedeti vse. Ljudje vlagajo denar in želijo razumeti, kako se naše delo ujema z našimi ključnimi kazalniki uspešnosti.
Upravni odbor vsak mesec prejme veliko informacij: število uporabnikov, njihovo rast, katere storitve uporabljajo in kako, učinkovitost delovanja in produktivnost ter končno povprečno hitrost nalaganja strani.
Edina težava je, da mislim, da je povprečje čisto zlo. Ampak to je zelo težko razložiti upravnemu odboru. Navajeni so delati z agregiranimi številkami, ne na primer z razponom časov nalaganja na sekundo.
V zvezi s tem je bilo nekaj zanimivih točk. Na primer, rekel sem, da bi moral biti promet razdeljen med ločene spletne strežnike glede na vrsto vsebine.

Torej, ColdFusion gre skozi Jetty in nginx ter zažene strani. Slike, JS in CSS pa gredo skozi ločen nginx s svojimi konfiguracijami. To je dokaj standardna praksa, o kateri govorim. Še pred nekaj leti. Posledično se slike nalagajo veliko hitreje in ... povprečna hitrost nalaganja se je povečala za 200 ms.
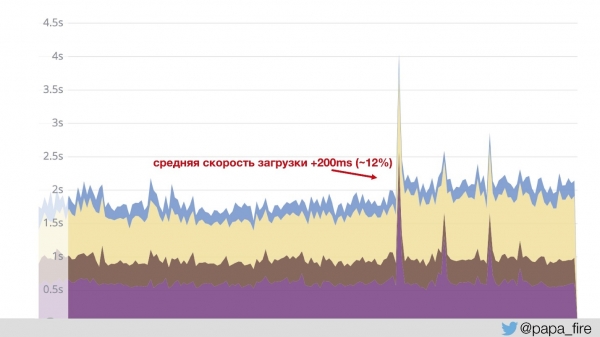
To se je zgodilo, ker graf temelji na podatkih, ki prihajajo iz Jettyja. To pomeni, da hitre vsebine niso vključene v izračun – povprečna številka je poskočila. To smo razumeli in se temu smejali, ampak kako bi lahko upravnemu odboru razložili, zakaj smo storili nekaj, kar je povzročilo 12-odstotni upad?
Petinosemdeseti dan
Do konca tretjega meseca sem spoznal, da na eno stvar sploh nisem računal: čas. Vse, o čemer sem govoril, zahteva čas.

To je moj dejanski tedenski koledar – preprost delovni teden, ne preveč natrpan. Ni dovolj časa za vse. Zato moram spet zaposliti ljudi, ki mi bodo pomagali pri reševanju težav.
Zaključek
To še ni vse. V tej zgodbi se sploh nisem dotaknil tega, kako smo delali z izdelkom in se poskušali uskladiti, kako smo integrirali tehnično podporo ali kako smo rešili druge tehnične težave. Na primer, čisto po naključju sem odkril, da ne uporabljamo SEQUENCEImamo funkcijo, ki smo jo napisali sami nextIDin se ne uporablja v transakciji.
O podobnih stvareh bi se dalo razpravljati na dolgo in široko. Najpomembnejša stvar, ki jo je vredno omeniti, pa je kultura.

Prav kultura, oziroma njeno pomanjkanje, vodi do vseh drugih težav. Trudimo se zgraditi kulturo, kjer ljudje:
- se ne bojijo neuspeha;
- učiti se iz napak;
- sodelovati z drugimi ekipami;
- pokažite pobudo;
- prevzeti odgovornost;
- pozdravite rezultat kot cilj;
- proslaviti uspeh.
S tem bo prišlo tudi vse ostalo.
Leon Fire , in .
Obstajata dve strategiji za spopadanje z zapuščino: za vsako ceno se ji izogniti ali pa pogumno premagati težave, ki jih prinaša. Mi Ubiramo drugo pot, spreminjamo procese in pristope. Pridružite se nam. , и in skupaj bomo implementirali kulturo DevOps.
Vir: www.habr.com
