


Moje dnevno delo je večinoma uvajanje programske opreme, kar pomeni, da veliko časa porabim za odgovarjanje na vprašanja, kot so:
- Ta programska oprema deluje za razvijalca, zame pa ne. Zakaj?
- Včeraj mi je ta program deloval, danes pa ne. Zakaj?
To je neke vrste odpravljanje napak, ki se nekoliko razlikuje od običajnega odpravljanja napak programske opreme. Pri rednem odpravljanju napak gre za logiko kode, pri uvajanju pa gre za interakcijo med kodo in okoljem. Tudi če je koren težave logična napaka, dejstvo, da vse deluje na enem računalniku in ne na drugem, pomeni, da je težava nekako v okolju.
Torej namesto običajnih orodij za odpravljanje napak, kot je gdb Imam drugačen nabor orodij za odpravljanje napak pri uvajanju. In moje najljubše orodje za reševanje težav, kot je "Zakaj ta programska oprema ne deluje zame?" klical strace.
Kaj je strace?
— je orodje za »sledenje sistemskim klicem«. Prvotno je bilo ustvarjeno v okviru Linux, vendar je mogoče iste trike za odpravljanje napak izvajati z orodji za druge sisteme ( ali ).
Osnovna aplikacija je zelo preprosta. Samo zagnati morate strace s poljubnim ukazom in izpustil bo vse sistemske klice (čeprav ga boste najprej morali verjetno sami namestiti strace):
$ strace echo Hello
...Snip lots of stuff...
write(1, "Hellon", 6) = 6
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++Kaj so ti sistemski klici? To je nekaj podobnega API-ju za jedro operacijskega sistema. Nekoč je imela programska oprema neposreden dostop do strojne opreme, na kateri je delovala. Če je na primer moral nekaj prikazati na zaslonu, se je igral z vrati ali pomnilniško preslikanimi registri za video naprave. Ko so postali priljubljeni večopravilni računalniški sistemi, je zavladal kaos, ko so se različne aplikacije borile za strojno opremo. Napake v eni aplikaciji lahko porušijo druge, če ne celotnega sistema. Nato so se v CPU pojavili načini privilegijev (ali "zaščita zvonjenja"). Jedro je postalo najbolj privilegirano: prejelo je popoln dostop do strojne opreme, kar je povzročilo manj privilegirane aplikacije, ki so že morale zahtevati dostop od jedra za interakcijo s strojno opremo prek sistemskih klicev.
Na binarni ravni se sistemski klic nekoliko razlikuje od preprostega funkcijskega klica, vendar večina programov uporablja ovoj v standardni knjižnici. Tisti. standardna knjižnica POSIX C vsebuje klic funkcije piši (), ki vsebuje vso kodo, specifično za arhitekturo za sistemski klic pisati.
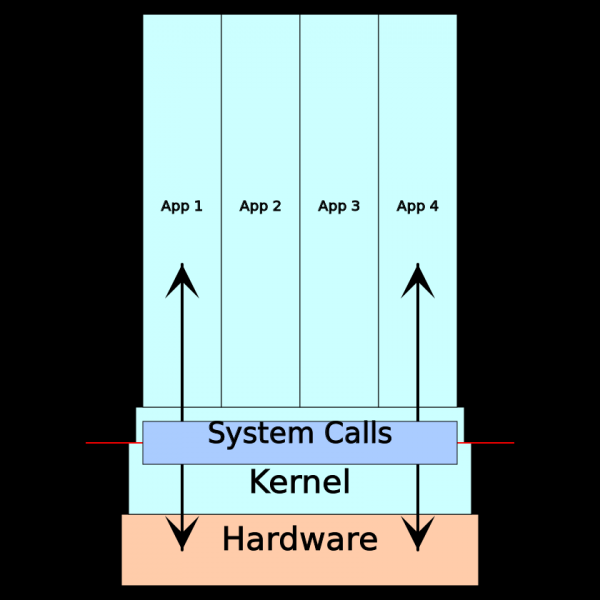
Skratka, kakršna koli interakcija med aplikacijo in njenim okoljem (računalniškimi sistemi) poteka prek sistemskih klicev. Če torej programska oprema deluje na enem računalniku, na drugem pa ne, bi bilo dobro pogledati rezultate sledenja sistemskim klicem. Natančneje, tukaj je seznam tipičnih točk, ki jih je mogoče analizirati s sledenjem sistemskega klica:
- V/I konzole
- Omrežni V/I
- Dostop do datotečnega sistema in V/I datotek
- Upravljanje življenjske dobe procesne niti
- Upravljanje pomnilnika na nizki ravni
- Dostop do določenih gonilnikov naprav
Kdaj uporabiti strace?
V teoriji, strace uporablja s katerim koli programom v uporabniškem prostoru, ker mora vsak program v uporabniškem prostoru izvajati sistemske klice. Deluje učinkoviteje s prevedenimi programi na nizki ravni, deluje pa tudi z jeziki na visoki ravni, kot je Python, če lahko presežete dodaten šum iz izvajalnega okolja in tolmača.
V vsem svojem sijaju strace se manifestira med razhroščevanjem programske opreme, ki dobro deluje na enem računalniku, vendar nenadoma preneha delovati na drugem, proizvaja nejasna sporočila o datotekah, dovoljenjih ali neuspešnih poskusih izvajanja nekaterih ukazov ali česa drugega ... Škoda, vendar ne tako dobro kombinirati s težavami na visoki ravni, kot so napake pri preverjanju potrdila. Običajno je za to potrebna kombinacija stracevčasih in orodja višje ravni (kot je orodje ukazne vrstice openssl za odpravljanje napak v potrdilu).
Kot primer bomo uporabili samostojni strežnik, vendar je sledenje sistemskim klicem pogosto mogoče izvesti na bolj zapletenih platformah za uvajanje. Izbrati morate le prava orodja.
Preprost primer odpravljanja napak
Recimo, da želite zagnati neverjetno strežniško aplikacijo foo in na koncu dobite tole:
$ foo
Error opening configuration file: No such file or directoryOčitno ni našel konfiguracijske datoteke, ki ste jo napisali. To se zgodi, ker včasih upravitelji paketov, ko sestavijo aplikacijo, preglasijo pričakovane lokacije datotek. In če sledite navodilom za namestitev za eno distribucijo, v drugi najdete datoteke, ki so popolnoma drugačne od tistih, kjer ste pričakovali. Težavo bi lahko rešili v nekaj sekundah, če bi sporočilo o napaki povedalo, kje iskati konfiguracijsko datoteko, vendar je ni. Kje torej iskati?
Če imate dostop do izvorne kode, jo lahko preberete in izveste vse. Dober rezervni načrt, vendar ne najhitrejša rešitev. Uporabite lahko razhroščevalnik po korakih, kot je gdb in poglejte, kaj program počne, vendar je veliko bolj učinkovito uporabiti orodje, ki je posebej zasnovano za prikaz interakcije z okoljem: strace.
Izhod strace morda se zdi odvečno, a dobra novica je, da je večino tega mogoče varno prezreti. Pogosto je koristno uporabiti operator -o za shranjevanje rezultatov sledenja v ločeno datoteko:
$ strace -o /tmp/trace foo
Error opening configuration file: No such file or directory
$ cat /tmp/trace
execve("foo", ["foo"], 0x7ffce98dc010 /* 16 vars */) = 0
brk(NULL) = 0x56363b3fb000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=25186, ...}) = 0
mmap(NULL, 25186, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f2f12cf1000
close(3) = 0
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "177ELF2113 3 > 1 260A2 "..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=1824496, ...}) = 0
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2f12cef000
mmap(NULL, 1837056, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f2f12b2e000
mprotect(0x7f2f12b50000, 1658880, PROT_NONE) = 0
mmap(0x7f2f12b50000, 1343488, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x22000) = 0x7f2f12b50000
mmap(0x7f2f12c98000, 311296, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x16a000) = 0x7f2f12c98000
mmap(0x7f2f12ce5000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1b6000) = 0x7f2f12ce5000
mmap(0x7f2f12ceb000, 14336, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f2f12ceb000
close(3) = 0
arch_prctl(ARCH_SET_FS, 0x7f2f12cf0500) = 0
mprotect(0x7f2f12ce5000, 16384, PROT_READ) = 0
mprotect(0x56363b08b000, 4096, PROT_READ) = 0
mprotect(0x7f2f12d1f000, 4096, PROT_READ) = 0
munmap(0x7f2f12cf1000, 25186) = 0
openat(AT_FDCWD, "/etc/foo/config.json", O_RDONLY) = -1 ENOENT (No such file or directory)
dup(2) = 3
fcntl(3, F_GETFL) = 0x2 (flags O_RDWR)
brk(NULL) = 0x56363b3fb000
brk(0x56363b41c000) = 0x56363b41c000
fstat(3, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x8), ...}) = 0
write(3, "Error opening configuration file"..., 60) = 60
close(3) = 0
exit_group(1) = ?
+++ exited with 1 +++Približno celotna prva stran izpisa strace - To je običajno priprava na nizki ravni za izstrelitev. (Veliko klicev mmap, mprotect, pero za stvari, kot je odkrivanje nizkonivojskega pomnilnika in prikazovanje dinamičnih knjižnic.) Pravzaprav med odpravljanjem napak izhod strace Bolje je brati od samega konca. Spodaj bo izziv pisati, ki prikaže sporočilo o napaki. Pogledamo zgoraj in vidimo prvi napačen sistemski klic - klic openat, ki povzroči napako ENOENT (»datoteke ali imenika ni bilo mogoče najti«) poskuša odpreti /etc/foo/config.json. Tukaj bi morala biti konfiguracijska datoteka.
To je bil samo primer, vendar bi rekel, da 90% časa, ki ga uporabljam strace, ni nič veliko težje narediti od tega. Spodaj je popoln vodnik za odpravljanje napak po korakih:
- Razburite se zaradi nejasnega sporočila programa o sistemski napaki
- Ponovno zaženite program z strace
- Poiščite sporočilo o napaki v rezultatih sledenja
- Pojdite višje, dokler ne dosežete prvega neuspelega sistemskega klica
Zelo verjetno bo sistemski klic v 4. koraku razkril, kaj je šlo narobe.
Nasveti
Preden vam pokažem primer bolj zapletenega odpravljanja napak, vam bom pokazal nekaj trikov za učinkovito uporabo strace:
človek je tvoj prijatelj
V mnogih sistemih *nix je mogoče z zagonom pridobiti celoten seznam sistemskih klicev jedra man sistemski klici. Videli boste stvari, kot so brk(2), kar pomeni, da lahko s tekom pridobite več informacij človek 2 brk.
Majhne grablje: človek 2 vilice mi pokaže stran za lupino vilice () в GNU libc, ki se, kot se je izkazalo, izvaja s klicanjem klon (). Semantika klica vilice ostane enako, če napišete program z uporabo vilice ()in zaženite sledenje - ne bom našel klicev vilice, namesto njih bo klon (). Takšne grablje te zmedejo le, če začneš primerjati vir z izhodom strace.
Uporabite -o, da shranite izhod v datoteko
strace lahko ustvari obsežen rezultat, zato je pogosto koristno shraniti rezultate sledenja v ločene datoteke (kot v zgornjem primeru). To tudi pomaga preprečiti zamenjavo izhoda programa z izhodom strace v konzoli.
Uporabite -s za ogled več podatkov argumentov
Morda ste opazili, da druga polovica sporočila o napaki ni prikazana v zgornjem primeru sledenja. To je zato, ker strace privzeto prikazuje le prvih 32 bajtov argumenta niza. Če želite videti več, dodajte nekaj podobnega -s 128 na klic strace.
-y olajša sledenje datotekam, vtičnicam itd.
"Vse je datoteka" pomeni, da sistemi *nix izvajajo vse V/I z deskriptorji datotek, ne glede na to, ali to velja za datoteko ali omrežje ali medprocesne cevi. To je priročno za programiranje, vendar je težko spremljati, kaj se v resnici dogaja, ko vidite skupno preberite и pisati v rezultatih sledenja sistemskega klica.
Z dodajanjem operaterja ja, boste prisilili strace označite vsak deskriptor datoteke v izhodu z opombo, na kaj kaže.
Pripni že delujoč proces z -p**
Kot boste videli v spodnjem primeru, morate včasih izslediti program, ki se že izvaja. Če je znano, da se izvaja kot proces 1337 (recimo iz izhoda ps), potem mu lahko sledite takole:
$ strace -p 1337
...system call trace output...Morda boste potrebovali korenske pravice.
Uporabite -f za spremljanje podrejenih procesov
strace Privzeto sledi le enemu procesu. Če ta proces ustvari podrejene procese, je mogoče videti sistemski klic za ustvarjanje podrejenega procesa, vendar sistemski klici podrejenega procesa ne bodo prikazani.
Če menite, da je napaka v podrejenem procesu, uporabite stavek -f, bo to omogočilo njegovo sledenje. Slaba stran tega je, da vas bo rezultat še bolj zmedel. Kdaj strace sledi enemu procesu ali eni niti, prikazuje en tok dogodkov klicev. Ko sledi več procesom hkrati, boste morda videli začetek klica, ki ga prekine sporočilo , nato - kup klicev za druge izvedbene veje in šele nato - konec prve <… foocall resumed>. Ali pa razdelite vse rezultate sledenja v različne datoteke, tudi z uporabo operatorja -ff (podrobnosti v o strace).
Filtrirajte sledi z -e
Kot lahko vidite, je rezultat sledenja pravi kup vseh možnih sistemskih klicev. Zastava -e Sled lahko filtrirate (glejte o strace). Glavna prednost je, da je hitreje zagnati filtrirano sled kot izvesti celotno sled in nato grep`pri. Če sem iskren, mi je skoraj vedno vseeno.
Niso vse napake slabe
Preprost in pogost primer je program, ki išče datoteko na več mestih hkrati, kot lupina, ki išče imenik, ki vsebuje izvršljivo datoteko:
$ strace sh -c uname
...
stat("/home/user/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory)
stat("/usr/local/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory)
stat("/usr/bin/uname", {st_mode=S_IFREG|0755, st_size=39584, ...}) = 0
...Hevristike, kot je "zadnja neuspela zahteva pred poročanjem o napaki", so dobre pri iskanju ustreznih napak. Kakor koli že, logično je, da začnemo od samega konca.
Vadnice za programiranje C vam lahko pomagajo razumeti sistemske klice.
Standardni klici v knjižnice C niso sistemski klici, temveč le tanka površinska plast. Torej, če vsaj malo razumete, kako in kaj narediti v C-ju, boste lažje razumeli rezultate sledenja sistemskega klica. Na primer, imate težave pri odpravljanju napak v omrežnih sistemih, poglejte isto klasiko .
Bolj zapleten primer odpravljanja napak
Rekel sem že, da je primer enostavnega odpravljanja napak primer, s čimer se moram večinoma ukvarjati pri delu strace. Vendar je včasih potrebna resnična preiskava, zato je tukaj resnični primer naprednejšega odpravljanja napak.
- razporejevalnik obdelave opravil, še ena izvedba demona *nix cron. Nameščen je na strežniku, a ko nekdo poskuša urediti urnik, se zgodi tole:
# crontab -e -u logs
bcrontab: Fatal: Could not create temporary fileV redu, to pomeni bcron poskušal napisati določeno datoteko, vendar ni šlo in noče priznati, zakaj. Razkrivanje strace:
# strace -o /tmp/trace crontab -e -u logs
bcrontab: Fatal: Could not create temporary file
# cat /tmp/trace
...
openat(AT_FDCWD, "bcrontab.14779.1573691864.847933", O_RDONLY) = 3
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000
read(3, "#Ansible: logsaggn20 14 * * * lo"..., 8192) = 150
read(3, "", 8192) = 0
munmap(0x7f82049b4000, 8192) = 0
close(3) = 0
socket(AF_UNIX, SOCK_STREAM, 0) = 3
connect(3, {sa_family=AF_UNIX, sun_path="/var/run/bcron-spool"}, 110) = 0
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000
write(3, "156:Slogs #Ansible: logsaggn20 1"..., 161) = 161
read(3, "32:ZCould not create temporary f"..., 8192) = 36
munmap(0x7f82049b4000, 8192) = 0
close(3) = 0
write(2, "bcrontab: Fatal: Could not creat"..., 49) = 49
unlink("bcrontab.14779.1573691864.847933") = 0
exit_group(111) = ?
+++ exited with 111 +++Čisto na koncu je sporočilo o napaki pisati, a tokrat je nekaj drugače. Prvič, ni ustrezne napake sistemskega klica, ki se običajno pojavi pred tem. Drugič, jasno je, da je nekje nekdo že prebral sporočilo o napaki. Videti je, da je pravi problem nekje drugje in bcrontab preprosto predvaja sporočilo.
Če pogledate moški 2 preberi, lahko vidite, da je prvi argument (3) deskriptor datoteke, ki ga *nix uporablja za vso V/I obdelavo. Kako ugotovim, kaj predstavlja deskriptor datoteke 3? V tem primeru lahko tečete strace z operaterjem ja (glejte zgoraj) in vam bo samodejno povedal, a če želite ugotoviti takšne stvari, je koristno vedeti, kako brati in razčleniti rezultate sledenja.
Izvor datotečnega deskriptorja je lahko eden od mnogih sistemskih klicev (vse je odvisno od tega, čemu je deskriptor namenjen – konzoli, omrežni vtičnici, sami datoteki ali čemu drugemu), a kakorkoli že, iščemo klice z vrnitvijo 3 (tj. v rezultatih sledenja iščemo »= 3«). V tem rezultatu sta 2 od njih: openat na samem vrhu in vtičnica V sredini. openat odpre datoteko, vendar Zapri(3) bo nato pokazalo, da se ponovno zapre. (Rake: deskriptorje datotek je mogoče ponovno uporabiti, ko jih odprete in zaprete). Pokliči vtičnica () primerna, ker je zadnja pred preberi (), in izkazalo se je, da bcrontab deluje z nečim prek vtičnice. Naslednja vrstica prikazuje, da je deskriptor datoteke povezan z vtičnica domene unix na poti /var/run/bcron-spool.
Torej moramo najti proces, povezan s vtičnica unix na drugi strani. V ta namen obstaja nekaj zvijačnih trikov, ki sta uporabna za odpravljanje napak pri uvajanju strežnikov. Prvi je uporaba NetStat ali novejši ss (stanje vtičnice). Oba ukaza prikažeta aktivne omrežne povezave sistema in sprejmeta izjavo -l za opis prisluškovalnih vtičnic in operaterja -p za prikaz programov, povezanih z vtičnico, kot odjemalca. (Obstaja veliko več uporabnih možnosti, vendar ti dve zadostujeta za to nalogo.)
# ss -pl | grep /var/run/bcron-spool
u_str LISTEN 0 128 /var/run/bcron-spool 1466637 * 0 users:(("unixserver",pid=20629,fd=3))To nakazuje, da je poslušalec ukaz inixserver, ki se izvaja z ID-jem procesa 20629. (In po naključju uporablja deskriptor datoteke 3 kot vtičnico.)
Drugo res uporabno orodje za iskanje istih informacij se imenuje tudi. Navaja vse odprte datoteke (ali deskriptorje datotek) v sistemu. Lahko pa dobite informacije o določeni datoteki:
# lsof /var/run/bcron-spool
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
unixserve 20629 cron 3u unix 0x000000005ac4bd83 0t0 1466637 /var/run/bcron-spool type=STREAMProces 20629 je dolgoživ strežnik, zato ga lahko priključite strace z uporabo nečesa podobnega strace -o /tmp/trace -p 20629. Če uredite opravilo cron v drugem terminalu, boste prejeli izhod sledenja z napako. In tukaj je rezultat:
accept(3, NULL, NULL) = 4
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21181
close(4) = 0
accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21181, si_uid=998, si_status=0, si_utime=0, si_stime=0} ---
wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 0}], WNOHANG|WSTOPPED, NULL) = 21181
wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes)
rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0
rt_sigreturn({mask=[]}) = 43
accept(3, NULL, NULL) = 4
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21200
close(4) = 0
accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21200, si_uid=998, si_status=111, si_utime=0, si_stime=0} ---
wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 111}], WNOHANG|WSTOPPED, NULL) = 21200
wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes)
rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0
rt_sigreturn({mask=[]}) = 43
accept(3, NULL, NULL(Zadnji sprejme () ne bo dokončan pri sledenju.) Tudi ta rezultat na žalost ne vsebuje napake, ki jo iščemo. Ne vidimo nobenih sporočil, ki jih bcrontag pošlje ali prejme iz vtičnice. Namesto tega popoln nadzor procesa (klon, počakaj 4, SIGCHLD itd.) Ta proces ustvari podrejeni proces, ki, kot morda ugibate, opravi pravo delo. In če ji morate ujeti sled, dodajte k klicu strace -f. To bomo našli, ko bomo iskali sporočilo o napaki v novem rezultatu s strace -f -o /tmp/sled -p 20629:
21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied)
21470 write(1, "32:ZCould not create temporary f"..., 36) = 36
21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84
21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory)
21470 exit_group(111) = ?
21470 +++ exited with 111 +++Zdaj, to je nekaj. Proces 21470 prejme napako "dostop zavrnjen", ko poskuša ustvariti datoteko na poti tmp/spool.21470.1573692319.854640 (v zvezi s trenutnim delovnim imenikom). Če bi poznali le trenutni delovni imenik, bi poznali tudi celotno pot in bi lahko ugotovili, zakaj proces v njem ne more ustvariti svoje začasne datoteke. Na žalost je postopek že zaključen, zato ne morete kar tako uporabiti lsof -p 21470 da bi našli trenutni imenik, vendar lahko delate v nasprotni smeri - poiščite sistemske klice PID 21470, ki spremenijo imenik. (Če jih ni, jih je PID 21470 moral podedovati od svojega starša, in to je že prek lsof -p ni mogoče najti.) Ta sistemski klic je chdir (kar je enostavno ugotoviti s pomočjo sodobnih spletnih iskalnikov). In tukaj je rezultat povratnega iskanja na podlagi rezultatov sledenja, vse do strežnika PID 20629:
20629 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21470
...
21470 execve("/usr/sbin/bcron-spool", ["bcron-spool"], 0x55d2460807e0 /* 27 vars */) = 0
...
21470 chdir("/var/spool/cron") = 0
...
21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied)
21470 write(1, "32:ZCould not create temporary f"..., 36) = 36
21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84
21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory)
21470 exit_group(111) = ?
21470 +++ exited with 111 +++(Če ste se izgubili, boste morda želeli prebrati mojo prejšnjo objavo .) Torej strežnik PID 20629 ni prejel dovoljenja za ustvarjanje datoteke na poti /var/spool/cron/tmp/spool.21470.1573692319.854640. Najverjetneje so razlog za to klasične nastavitve dovoljenj datotečnega sistema. Preverimo:
# ls -ld /var/spool/cron/tmp/
drwxr-xr-x 2 root root 4096 Nov 6 05:33 /var/spool/cron/tmp/
# ps u -p 20629
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
cron 20629 0.0 0.0 2276 752 ? Ss Nov14 0:00 unixserver -U /var/run/bcron-spool -- bcron-spoolTam je pes pokopan! Strežnik deluje kot uporabniški cron, vendar ima samo root dovoljenje za pisanje v imenik /var/spool/cron/tmp/. Preprost ukaz chown cron /var/spool/cron/tmp/ bo prisilil bcron deluje pravilno. (Če to ni bil vzrok težave, je naslednji najverjetnejši osumljenec varnostni modul jedra SE.)Linux ali AppArmor, zato bi preveril dnevnik sporočil jedra z dmesg.)
Skupno
Sledi sistemskim klicem so lahko za začetnika izjemne, vendar upam, da sem pokazal, da so hiter način za odpravljanje napak celotnega razreda pogostih težav pri uvajanju. Predstavljajte si, da poskušate odpraviti napake v večprocesnem procesu bcronz uporabo razhroščevalnika po korakih.
Razčlenjevanje rezultatov sledenja nazaj vzdolž verige sistemskega klica zahteva spretnost, a kot sem rekel, skoraj vedno z uporabo strace, samo dobim rezultat sledenja in iščem napake od konca. Kakorkoli, strace mi pomaga prihraniti veliko časa pri odpravljanju napak. Upam, da bo koristilo tudi vam.
Vir: www.habr.com
