

Danes vam bom povedal zgodbo. Zgodovina razvoja računalniške tehnologije in pojava oddaljenih služb od pradavnine do danes.
IT razvoj
Glavna stvar, ki se je lahko naučimo iz zgodovine IT, je ...

Ni treba posebej poudarjati, da se IT razvija spiralno. Iste rešitve in koncepti, ki so bili pred desetletji opuščeni, dobijo nov pomen in začnejo uspešno delovati v novih razmerah, z novimi nalogami in novimi zmogljivostmi. V tem se IT ne razlikuje od katerega koli drugega področja človeškega znanja in zgodovine Zemlje kot celote.

Dolgo nazaj, ko so bili računalniki veliki
"Mislim, da je na svetu trg za približno pet računalnikov," je leta 1943 generalni direktor IBM Thomas Watson.
Zgodnja računalniška tehnologija je bila velika. Ne, to je narobe, zgodnja tehnologija je bila pošastna, kiklopska. Popolnoma računalniško podprt stroj je zavzemal površino, primerljivo s telovadnico, in stal popolnoma nerealno denar. Primer komponent je RAM modul na feritnih obročih (1964).

Ta modul ima velikost 11 cm * 11 cm in kapaciteto 512 bajtov (4096 bitov). Omara, v celoti napolnjena s temi moduli, je komaj imela kapaciteto prastare 3,5” diskete (1.44 MB = 2950 modulov), medtem ko je porabila zelo občutno električno energijo in se segrevala kot parna lokomotiva.
Prav zaradi njegove enormne velikosti je angleško ime za razhroščevanje programske kode »debugging«. Ena prvih programerk v zgodovini, Grace Hopper (da, ženska), pomorska častnica, je leta 1945 napisala vnos v dnevnik, potem ko je raziskala težavo s programom.

Ker je molj (molj) na splošno hrošč (žuželka), je osebje o vseh nadaljnjih težavah in ukrepih za reševanje poročalo svojim nadrejenim kot o "odpravljanju napak" (dobesedno de-bug), potem je bilo ime hrošč trdno dodeljeno napaki programa in napaka v kodi in odpravljanje napak je postalo odpravljanje napak.
Z razvojem elektronike in zlasti polprevodniške elektronike se je fizična velikost strojev začela zmanjševati, računalniška moč pa se je, nasprotno, povečevala. Toda tudi v tem primeru je bilo nemogoče vsakogar osebno oskrbeti z računalnikom.
"Ni razloga, zakaj bi kdo želel imeti računalnik v svojem domu" - Ken Olsen, ustanovitelj DEC, 1977.
V 70. letih se je pojavil izraz mini računalnik. Spomnim se, da sem si, ko sem pred mnogimi leti prvič prebral ta izraz, predstavljal nekaj podobnega netbooku, skoraj dlančniku. Ne morem biti dlje od resnice.

Mini je le v primerjavi z ogromnimi strojnicami, vendar je to še vedno nekaj kabinetov z opremo, ki stane na stotine tisoče in milijone dolarjev. Vendar se je računalniška moč že toliko povečala, da ni bila vedno 100% obremenjena, hkrati pa so računalniki začeli biti na voljo tudi študentom in učiteljem.
In potem je prišel ON!

Malokdo razmišlja o latinskih koreninah v angleškem jeziku, a prav ta nam je prinesla dostop na daljavo, kot ga poznamo danes. Terminus (latinsko) - konec, meja, cilj. Namen Terminatorja T800 je bil končati življenje Johna Connorja. Vemo tudi, da se prometne postaje, kjer poteka vkrcavanje in izkrcavanje potnikov ali nakladanje in razkladanje blaga, imenujejo terminali – končni cilji poti.
V skladu s tem se je rodil koncept terminalskega dostopa in lahko vidite, da najbolj znan terminal na svetu še vedno živi v naših srcih.

DEC VT100 se imenuje terminal, ker zaključuje podatkovno linijo. Ima skoraj nič procesorske moči in njegova edina naloga je prikazovanje informacij, prejetih iz velikega stroja, in prenos vnosa s tipkovnice na stroj. In čeprav je VT100 fizično že dolgo mrtev, ga še vedno uporabljamo v polnem potencialu.
Naši dnevi
»Naše dni« bi začel šteti od začetka 80. let prejšnjega stoletja, od trenutka, ko so se pojavili prvi procesorji s kakršno koli pomembno računalniško močjo, dostopni širokemu krogu ljudi. Tradicionalno velja, da je bil glavni procesor tega obdobja Intel 8088 (družina x86) kot prednik zmagovalne arhitekture. Kakšna je temeljna razlika s konceptom 70-ih?
Prvič se pojavi težnja po prenosu obdelave informacij iz centra na periferijo. Vse naloge ne zahtevajo nore (v primerjavi s šibkim x86) moči velikega računalnika ali celo mini računalnika. Intel ne miruje, v 90. letih prejšnjega stoletja je izdal družino Pentium, ki je resnično postala prvi gospodinjski aparat množične proizvodnje v Rusiji. Ti procesorji zmorejo že marsikaj, ne samo pisanje pisem, ampak tudi večpredstavnost in delo z majhnimi bazami podatkov. Pravzaprav za mala podjetja strežniki sploh niso potrebni - vse je mogoče narediti na periferiji, na odjemalskih strojih. Procesorji so iz leta v leto zmogljivejši, razlika med strežniki in osebnimi računalniki pa je pri računalniški moči vse manjša in pogosto ostane le pri redundanci napajanja, podpori za zamenjavo med delovanjem in posebnih ohišjih za vgradnjo v stojala.
Če primerjate sodobne odjemalske procesorje, ki so bili "smešni" za skrbnike težkih strežnikov iz Intela v 90-ih s superračunalniki preteklosti, potem vam postane malo neprijetno.
Poglejmo starca, ki je tako rekoč mojih let. Cray X-MP/24 1984.

Ta stroj je bil med najboljšimi superračunalniki leta 1984, saj je imel 2 procesorja 105 MHz z največjo računalniško močjo 400 MFlops (milijoni operacij s plavajočo vejico). Določen stroj, prikazan na fotografiji, je stal v kriptografskem laboratoriju ameriške NSA in se ukvarjal z razbijanjem kod. Če pretvorite 15 milijonov dolarjev v dolarje iz leta 1984 v dolarje iz leta 2020, je strošek 37,4 milijona dolarjev ali 93 dolarjev/MFlops.

Stroj, na katerem pišem te vrstice, ima procesor Core i5–7400 letnik 2017, ki sploh ni nov in je bil že v letu izida najmlajši 4-jedrni izmed vseh namiznih procesorjev srednjega razreda. 4 jedra osnovne frekvence 3.0 GHz (3.5 s Turbo Boost) in podvojitve niti HyperThreading dajejo od 19 do 47 GFlops moči glede na različne teste po ceni 16 tisoč rubljev na procesor. Če sestavite celoten stroj, potem lahko vzamete njegovo ceno za 750 $ (po cenah in menjalnih tečajih od 1. marca 2020).
Na koncu dobimo 50--120-kratno premoč povsem povprečnega današnjega namiznega procesorja nad top 10 superračunalniki dogledne preteklosti, padec specifičnega stroška MFlops pa postane naravnost pošasten 93500 / 25 = 3700 krat.
Zakaj še vedno potrebujemo strežnike in centralizacijo računalništva s takšno močjo na periferiji, je popolnoma nerazumljivo!
Povratni skok - spirala je naredila obrat
Postaje brez diska
Prvi signal, da selitev računalništva na obrobje ne bo dokončna, je bil pojav tehnologije delovnih postaj brez diska. Z veliko porazdelitvijo delovnih postaj po celotnem podjetju, zlasti v onesnaženih prostorih, postane vprašanje upravljanja in podpore teh postaj zelo težavno.

Pojavi se koncept "časa na hodniku" - odstotek časa, ko je uslužbenec tehnične podpore na hodniku, na poti do zaposlenega s težavo. To je plačan čas, a popolnoma neproduktiven. Ne nazadnje pomembno vlogo, predvsem v onesnaženih prostorih, je imela okvara trdih diskov. Odstranimo disk iz delovne postaje in vse ostalo naredimo preko omrežja, vključno s prenosom. Omrežna kartica poleg naslova s strežnika DHCP prejme tudi dodatne informacije - naslov strežnika TFTP (simplified file service) in ime zagonske slike, jo naloži v RAM in zažene stroj.
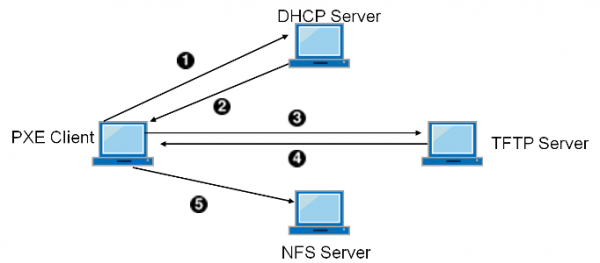
Poleg manj okvar in skrajšanega časa na hodniku vam zdaj ni treba odpravljati napak v stroju na mestu, ampak preprosto prinesite novega in odnesite starega na diagnostiko na opremljeno delovno mesto. A to še ni vse!
Postaja brez diska postane veliko varnejša - če nekdo nenadoma vdre v sobo in odnese vse računalnike, je to le izguba opreme. Na postajah brez diska se podatki ne shranjujejo.
Zapomnimo si to: informacijska varnost po "brezskrbnem otroštvu" informacijske tehnologije začenja igrati vse pomembnejšo vlogo. In strašne in pomembne 3 črke vse bolj vdirajo v IT - GRC (Governance, Risk, Compliance) ali v ruščini "Manageability, Risk, Compliance".
Terminalski strežniki
Široka distribucija vedno močnejših osebnih računalnikov na periferiji je močno prehitela razvoj javno dostopnih omrežij. Klasične aplikacije odjemalec-strežnik iz 90-ih in zgodnjih 00-ih niso dobro delovale prek tankega kanala, če je izmenjava podatkov dosegla pomembne vrednosti. To je bilo še posebej težko za oddaljene pisarne, povezane preko modema in telefonske linije, ki je občasno tudi zamrznila ali bila prekinjena. IN…
Spirala se je obrnila in se vrnila v terminalski način s konceptom terminalskih strežnikov.
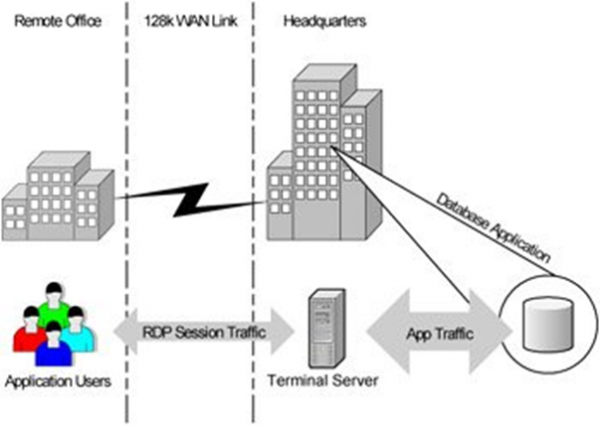
Pravzaprav smo se vrnili v 70. leta z njihovim nič strankami in centralizacijo računalniške moči. Hitro je postalo očitno, da terminalski dostop poleg čisto ekonomske utemeljitve kanalov ponuja ogromno možnosti za organizacijo varnega dostopa od zunaj, vključno z delom od doma za zaposlene ali izjemno omejen in nadzorovan dostop za izvajalce iz nezaupanja vrednih omrežij in nezaupanja vrednih/ nenadzorovane naprave.
Vendar so imeli terminalski strežniki z vsemi svojimi prednostmi in progresivnostjo tudi številne pomanjkljivosti - nizko fleksibilnost, problem hrupnega soseda, strogo strežniško Windows in tako naprej.
Rojstvo Proto VDI

Res je, da je bila v začetku in sredi leta 00 industrijska virtualizacija platforme x86 že v polnem teku. In nekdo je izrazil idejo, ki je preprosto visela v zraku: namesto centralizacije vseh odjemalcev na strežniških terminalskih farmah, dajmo vsakemu svoj osebni virtualni stroj s stranko. Windows in celo administratorski dostop?
Zavrnitev debelih strank
Vzporedno z virtualizacijo sej in OS je bil razvit pristop za olajšanje delovanja odjemalca na ravni aplikacije.
Logika za tem je bila precej preprosta, saj še vedno niso imeli vsi osebnih prenosnih računalnikov, vsi niso imeli interneta in mnogi so se lahko povezovali le iz internetne kavarne z zelo omejenimi, milo rečeno, pravicami. Pravzaprav je bilo mogoče zagnati le brskalnik. Brskalnik je postal nepogrešljiv atribut operacijskega sistema, internet je trdno vstopil v naša življenja.
Povedano drugače, vzporedno je potekal trend prenosa logike iz odjemalca v center v obliki spletnih aplikacij, za dostop do katerih potrebuješ le najpreprostejšega odjemalca, internet in brskalnik.
In nismo le končali tam, kjer smo začeli – z nič strankami in centralnimi strežniki. Do tja smo prišli po več neodvisnih poteh.

Infrastruktura navideznega namizja
posrednik
Leta 2007 je vodilni na trgu industrijske virtualizacije, VMware, izdal prvo različico svojega izdelka VDM (Virtual Desktop Manager), ki je postal pravzaprav prvi na nastajajočem trgu virtualnih namizij. Seveda nam ni bilo treba dolgo čakati na odgovor vodilnega terminalskega strežnika Citrixa in leta 2008 se je s prevzemom XenSource pojavil XenDesktop. Seveda so bili tudi drugi prodajalci s svojimi predlogi, a ne gremo preveč globoko v zgodovino in se oddaljimo od koncepta.
In koncept ostaja še danes. Ključna komponenta VDI je posrednik povezav.
To je srce infrastrukture virtualnega namizja.
Posrednik je odgovoren za najpomembnejše procese VDI:
- Določa vire (stroje/seje), ki so na voljo povezanemu odjemalcu;
- Po potrebi uravnoteži odjemalce v naborih strojev/sej;
- Posreduje stranko do izbranega vira.
Danes je odjemalec (terminal) za VDI lahko tako rekoč karkoli, kar ima zaslon – prenosnik, pametni telefon, tablica, kiosk, tanki ali ničelni odjemalec. In odzivni del, isti tisti, ki izvaja produktivno obremenitev - sejo terminalskega strežnika, fizični stroj, virtualni stroj. Sodobni zreli izdelki VDI so tesno povezani z virtualno infrastrukturo in jo neodvisno upravljajo v samodejnem načinu, nameščajo ali, nasprotno, brišejo virtualne stroje, ki niso več potrebni.
Malo ob strani, a za nekatere naročnike izjemno pomembna tehnologija VDI je podpora za strojno pospeševanje 3D grafike za delo oblikovalcev oz.
Protokol
Drugi izjemno pomemben del zrele rešitve VDI je protokol za dostop do virtualnih virov. Če govorimo o delu v lokalnem omrežju podjetja z odličnim, zanesljivim omrežjem 1 Gbps do delovnega mesta in zakasnitvijo 1 ms, potem lahko vzamete skoraj katero koli in sploh ne razmišljate.
Pomisliti morate, ko je povezava prek nenadzorovanega omrežja, kakovost tega omrežja pa je lahko popolnoma kakršna koli, do hitrosti več deset kilobitov in nepredvidljivih zakasnitev. Ti so ravno pravšnji za organizacijo pravega dela na daljavo, iz dač, od doma, z letališč in restavracij.
Terminalski strežniki proti odjemalcem VM
S prihodom VDI se je zdelo, da je prišel čas za slovo od terminalskih strežnikov. Zakaj so potrebni, če ima vsak svoj osebni VM?
Z vidika čiste ekonomije pa se je izkazalo, da za tipična masovna opravila, identična ad nauseum, še ni nič učinkovitejšega od terminalskih strežnikov glede razmerja cena/seja. Kljub vsem svojim prednostim pristop »1 uporabnik = 1 VM« porabi bistveno več sredstev za virtualno strojno opremo in polnopravni OS, kar poslabšuje ekonomiko tipičnih delovnih mest.
V primeru delovnih mest najvišjih menedžerjev, nestandardnih in obremenjenih delovnih mest, potrebe po visokih pravicah (do administratorja), ima namenski VM na uporabnika prednost. Znotraj tega VM lahko posamično dodelite vire, izdate pravice na kateri koli ravni in uravnotežite VM med gostitelji virtualizacije pod visoko obremenitvijo.
VDI in ekonomija
Že leta poslušam isto vprašanje - kako je VDI cenejši kot samo razdeljevanje prenosnikov vsem? In že leta moram odgovarjati popolnoma isto: v primeru navadnih pisarniških uslužbencev VDI ni cenejši, če upoštevamo neto stroške nabave opreme. Karkoli že lahko rečemo, prenosniki postajajo cenejši, vendar strežniki, sistemi za shranjevanje in sistemska programska oprema stanejo precej denarja. Če je prišel čas, da posodobite svoj vozni park in razmišljate o prihranku z VDI, ne, ne boste prihranili denarja.
Zgoraj sem navedel strašne tri črke GRC - torej VDI govori o GRC. Gre za obvladovanje tveganj, gre za varnost in udobje nadzorovanega dostopa do podatkov. In vse to običajno stane precej denarja za implementacijo na kup različnih vrst opreme. Z VDI je nadzor poenostavljen, varnost povečana, lasje pa postanejo mehki in svilnati.
Rešitve HPE za oddaljeno delo
Upravljanje na daljavo in v oblaku
iLO
HPE še zdaleč ni novinec pri upravljanju strežniške infrastrukture na daljavo, brez šale – marca je legendarni iLO (Integrated Lights Out) dopolnil 18 let. Ko se spomnim svojih dni kot skrbnik v 00-ih, osebno ne bi mogel biti srečnejši. Začetna namestitev v stojala in povezovalni kabli so bili vse, kar je bilo treba narediti v hrupnem in hladnem podatkovnem centru. Vso drugo konfiguracijo, vključno z nalaganjem operacijskega sistema, je mogoče izvesti z delovne postaje, dveh monitorjev in vrčka vroče kave. In to je pred 13 leti!

Strežniki HPE so danes z razlogom nesporen dolgoročni standard kakovosti – ne nazadnje pa pri tem igra zlati standard sistema za oddaljeno upravljanje – iLO.
Posebej bi rad izpostavil dejanja HPE pri ohranjanju nadzora človeštva nad koronavirusom. , da je do konca leta 2020 (vsaj) licenca iLO Advanced na voljo vsem brezplačno.
Infosight
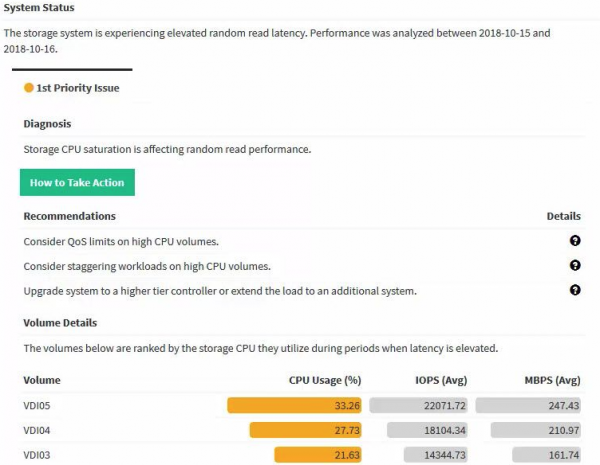
Če imate v svoji infrastrukturi več kot 10 strežnikov in administratorju ni dolgčas, bo seveda HPE Infosight oblačni sistem, ki temelji na umetni inteligenci, odličen dodatek standardnim orodjem za spremljanje. Sistem ne samo spremlja stanje in gradi grafe, temveč tudi samostojno priporoča nadaljnje ukrepe glede na trenutno stanje in trende.
Bodi pameten, , preizkusite Infosight!
OneView
Nenazadnje bi rad omenil HPE OneView – celoten portfelj izdelkov z ogromnimi zmogljivostmi za spremljanje in upravljanje celotne infrastrukture. In vse to, ne da bi vstali od svoje mize, ki jo morda imate v trenutni situaciji na vaši dachi.
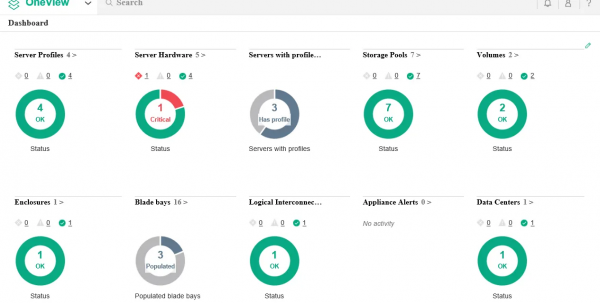
Tudi sistemi za shranjevanje niso slabi!
Seveda so vsi sistemi za shranjevanje vodeni in nadzorovani na daljavo – tako je bilo pred mnogimi leti. Zato želim danes govoriti o nečem drugem, in sicer o metro grozdih.
Metro grozdi niso novost na trgu, a ravno zato še vedno niso preveč priljubljeni - vplivata nanje inercija razmišljanja in prvi vtis. Seveda so obstajali že pred 10 leti, vendar stanejo kot litoželezni most. Leta, ki so minila od prvih metroclusterjev, so spremenila industrijo in dostopnost tehnologije širši javnosti.
Spomnim se projektov, kjer so bili deli sistemov za shranjevanje posebej razdeljeni - posebej za superkritične storitve v metro grozdu, posebej za sinhrono replikacijo (veliko ceneje).
Pravzaprav vas leta 2020 metrocluster nič ne stane, če lahko organizirate dve strani in kanale. Toda kanali, potrebni za sinhrono replikacijo, so popolnoma enaki kot za metroklastre. Licenciranje programske opreme se že dolgo izvaja v paketih - in sinhrona replikacija pride takoj kot paket z metro gručo, in edina stvar, ki doslej ohranja enosmerno replikacijo pri življenju, je potreba po organizaciji razširjenega omrežja L2. In tudi takrat L2 nad L3 že na vso moč vije po državi.
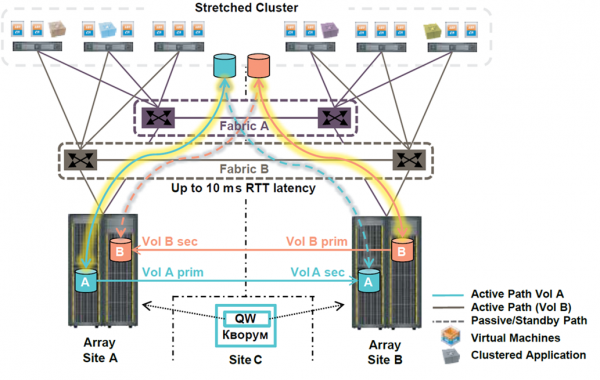
Kakšna je torej temeljna razlika med sinhrono replikacijo in metroclusterjem z vidika dela na daljavo?
Vse je zelo preprosto. Metrocluster deluje sam, samodejno, vedno, skoraj takoj.
Kako izgleda postopek preklapljanja obremenitve za sinhrono replikacijo na infrastrukturi z vsaj nekaj sto virtualnimi stroji?
- Sprejet je signal v sili.
- Dežurna izmena analizira situacijo - varno si lahko vzamete 10 do 30 minut samo za sprejem signala in odločitev.
- Če dežurni inženirji nimajo pooblastil za samostojen začetek preklopa, imajo še vedno 30 minut časa, da stopijo v stik s pristojnim in uradno potrdijo začetek preklopa.
- Pritisk na veliki rdeči gumb.
- 10-15 minut za časovne omejitve in ponovno namestitev glasnosti, ponovna registracija VM.
- 30 minut za spremembo naslova IP je optimistična ocena.
- In končno, začetek VM in lansiranje produktivnih storitev.
Skupni RTO (čas za obnovitev poslovnih procesov) lahko varno ocenimo na 4 ure.
Primerjajmo s stanjem na metroclustru.
- Sistem za shranjevanje razume, da je povezava z roko metroclustra izgubljena - 15-30 sekund.
- Virtualizacijski gostitelji razumejo, da je prvi podatkovni center izgubljen - 15-30 sekund (hkrati s točko 1).
- Samodejni ponovni zagon polovice do tretjine VM-jev v drugem podatkovnem centru - 10-15 minut pred nalaganjem storitev.
- Približno v tem času dežurna izmena ugotovi, kaj se je zgodilo.
Skupaj: RTO = 0 za posamezne storitve, 10-15 minut v splošnem primeru.
Zakaj se znova zažene samo polovica do tretjina navideznih strojev? Poglej kaj se dogaja:
- Vse narediš pametno in omogočiš samodejno uravnoteženje VM. Posledično v enem od podatkovnih centrov v povprečju deluje le polovica navideznih strojev. Navsezadnje je bistvo metroclusterja čim manjše izpade, zato je v vašem interesu zmanjšati število napadenih virtualnih strojev.
- Nekatere storitve je mogoče združiti v gruče na ravni aplikacije in porazdeliti po različnih VM. Skladno s tem so ti seznanjeni VM-ji prikovani enega za drugim ali s trakom povezani z različnimi podatkovnimi centri, tako da storitev ne čaka, da se VM v primeru nesreče znova zažene.
Z dobro zgrajeno infrastrukturo z razširjenimi metro grozdi poslovni uporabniki delajo z minimalnimi zamudami od koder koli, tudi v primeru nesreče na ravni podatkovnega centra. V najslabšem primeru bo zamuda čas ene skodelice kave.
In seveda metroclusterji odlično delujejo tako na HPE 3Par, ki se premika proti Valinorju, kot na čisto novi Primeri!

Infrastruktura oddaljenega delovnega mesta
Terminalski strežniki
Za terminalske strežnike ni treba izumiti ničesar novega, HPE jim že vrsto let dobavlja nekaj najboljših strežnikov na svetu. Brezčasna klasika - DL360 (1U) ali DL380 (2U) ali za ljubitelje AMD - DL385. Seveda so tu tudi blade strežniki, tako klasični C7000 kot nova sestavljiva platforma Synergy.

Za vsak okus, za vsako barvo, največ sej na strežnik!
“Klasična” preprostost VDI + HPE
V tem primeru, ko rečem »klasični VDI«, mislim na koncept 1 uporabnik = 1 VM z odjemalcem. WindowsIn seveda ni delovne obremenitve, ki bi bila bližje ali bolj znana hiperkonvergentnim sistemom kot VDI, zlasti z deduplikacijo in stiskanjem.

Tukaj lahko HPE ponudi lastno hiperkonvergirano platformo Simplivity in strežnike/certificirana vozlišča za partnerske rešitve, kot so VSAN Ready Nodes za gradnjo VDI na infrastrukturi VMware VSAN.
Pogovorimo se še o rešitvi podjetja Simplicity. Fokus, kot nam nežno namigne ime, je preprostost. Enostaven za uvajanje, enostaven za upravljanje, enostaven za prilagajanje.
Hiperkonvergirani sistemi so danes ena najbolj vročih tem v IT, število ponudnikov različnih ravni pa je okoli 40. Po Gartnerjevem magičnem kvadratu se HPE uvršča med Top5 na svetovni ravni in je uvrščen v kvadrat vodilnih – tistih, ki razumejo. kjer se industrija razvija, in so sposobni razumeti, da jo prevedejo v strojno opremo.
Arhitekturno je Simplivity klasičen hiperkonvergiran sistem s krmilnimi virtualnimi stroji, kar pomeni, da lahko podpira različne hipervizorje, v nasprotju s sistemi, integriranimi v hipervizorje. Dejansko sta od aprila 2020 podprta VMware vSphere in Microsoft Hyper-V, objavljeni pa so bili tudi načrti za podporo KVM. Ključna značilnost Simplivityja od njegovega pojava na trgu je strojno pospeševanje kompresije in deduplikacije s pomočjo posebne pospeševalne kartice.
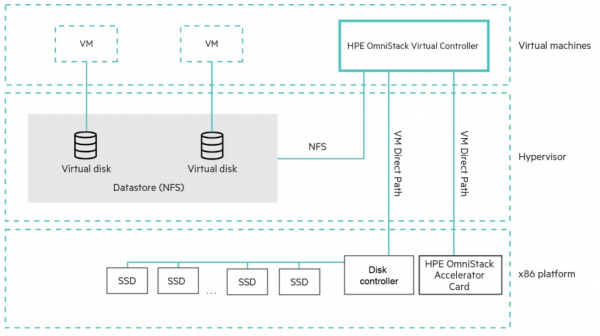
Upoštevati je treba, da sta stiskanje in deduplikacija globalni in vedno omogočeni; to ni izbirna funkcija, ampak arhitektura rešitve.
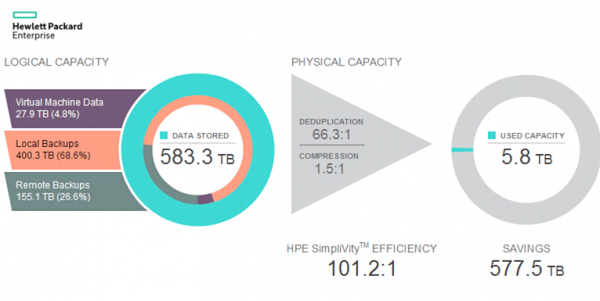
HPE je seveda nekoliko neiskren, saj trdi, da je izkoristek 100:1, pri čemer računa na poseben način, a izkoristek izrabe prostora je res zelo visok. Samo številka 100:1 je prelepa. Ugotovimo, kako je Simplivity tehnično implementiran za prikaz takih številk.
Posnetek. Posnetki so 100-odstotno pravilno implementirani kot RoW (Redirect-on-Write), zato se pojavijo takoj in ne povzročijo poslabšanja zmogljivosti. Kako se na primer razlikujejo od nekaterih drugih sistemov. Zakaj potrebujemo lokalne posnetke brez kazni? Da, zelo preprosto je zmanjšati RPO s 24 ur (povprečni RPO za varnostno kopiranje) na desetine ali celo enote minut.
backup. Posnetek se od varnostne kopije razlikuje le po tem, kako ga zaznava sistem za upravljanje navideznega stroja. Če se ob brisanju stroja izbriše vse ostalo, je bil to posnetek. Če je kaj ostalo, pomeni, da je rezerva. Tako lahko vsak posnetek štejemo za popolno varnostno kopijo, če je v sistemu označen in ni izbrisan.
Seveda bodo mnogi ugovarjali - kakšna varnostna kopija je to, če je shranjena v istem sistemu? In tukaj je zelo preprost odgovor v obliki nasprotnega vprašanja: povejte mi, ali imate formalni model groženj, ki določa pravila za shranjevanje varnostne kopije? To je popolnoma poštena varnostna kopija pred brisanjem datoteke v VM, to je varnostna kopija pred brisanjem samega VM. Če je treba varnostno kopijo shraniti izključno v ločenem sistemu, imate možnost izbire: replikacija tega posnetka v drugo gručo Simplivity ali v HPE StoreOnce.
In tu se izkaže, da je takšna arhitektura enostavno idealna za kakršen koli tip VDI. Navsezadnje VDI pomeni na stotine ali celo tisoče zelo podobnih strojev z enakim OS, z enakimi aplikacijami. Globalna deduplikacija bo vse to prežvečila in stisnila niti ne 100:1, ampak veliko bolje. Uvesti 1000 VM-jev iz ene predloge? Sploh ni problem, ti stroji bodo potrebovali več časa za registracijo v vCenter kot za kloniranje.
Linija Simplivity G je bila ustvarjena posebej za uporabnike s posebnimi zahtevami glede zmogljivosti in za tiste, ki potrebujejo 3D pospeševalnike.

Ta serija ne uporablja strojnega pospeševalnika deduplikacije in zato zmanjša število diskov na vozlišče, tako da krmilnik to obravnava v programski opremi. To sprosti reže PCIe za vse druge pospeševalnike. Količina razpoložljivega pomnilnika na vozlišče je bila tudi podvojena na 3TB za najzahtevnejše delovne obremenitve.

Preprostost je idealna za organiziranje geografsko porazdeljenih infrastruktur VDI s podvajanjem podatkov v osrednji podatkovni center.
Takšna arhitektura VDI (in ne samo VDI) je še posebej zanimiva v kontekstu ruske realnosti - ogromne razdalje (in s tem zamude) in daleč od idealnih kanalov. Ustvarjeni so regionalni centri (ali celo samo 1-2 vozlišči Simplivity v popolnoma oddaljeni pisarni), kjer se lokalni uporabniki povezujejo po hitrih kanalih, ohranja se popoln nadzor in upravljanje iz centra in le majhna količina resničnih, dragocenih in ne junk, se replicira v podatke centra.
Seveda je Simplivity v celoti povezan z OneView in InfoSight.
Tanki in ničelni odjemalci
Tanki odjemalci so specializirane rešitve za uporabo izključno kot terminali. Ker odjemalca razen vzdrževanja kanala in dekodiranja videa praktično ni obremenjenega, je skoraj vedno prisoten procesor s pasivnim hlajenjem, majhna zagonska disketa samo za zagon posebnega vgrajenega OS in to je v bistvu to. V njem praktično ni ničesar, kar bi lahko vlomili, in je neuporabno ukrasti. Cena je nizka in podatki se ne shranjujejo.
Obstaja posebna kategorija tankih odjemalcev, tako imenovani ničelni odjemalci. Njihova glavna razlika od tankih je odsotnost celo splošnega vgrajenega operacijskega sistema in delo izključno z mikročipom z vdelano programsko opremo. Pogosto vsebujejo posebne strojne pospeševalnike za dekodiranje video tokov v terminalskih protokolih, kot sta PCoIP ali HDX.
Kljub delitvi velikega Hewlett Packarda na ločena HPE in HP je nemogoče ne omeniti tankih odjemalcev, ki jih proizvaja HP.
Izbira je široka, za vsak okus in potrebe - do večmonitorskih delovnih postaj s strojnim pospeševanjem video toka.

Storitev HPE za vaše delo na daljavo
In nenazadnje želim omeniti storitev HPE. Predolgo bi bilo naštevati vse HPE-jeve ravni storitev in zmožnosti, vendar obstaja vsaj ena izjemno pomembna ponudba za delovna okolja na daljavo. In sicer serviser HPE/pooblaščeni servis. Še naprej delate na daljavo, iz vaše najljubše dače, poslušate čmrlje, medtem ko čebela iz HPE, ki prispe v podatkovni center, zamenja diske ali okvarjeno napajanje v vaših strežnikih.
HPE CallHome
V današnjih razmerah z omejitvami gibanja postaja funkcija Pokliči domov bolj pomembna kot kdaj koli prej. Vsak sistem HPE s to funkcijo lahko sam prijavi napako strojne ali programske opreme centru za podporo HPE. In verjetno bo nadomestni del in/ali servisni inženir prispel na vašo lokacijo veliko preden boste opazili kakršne koli okvare ali težave s produktivnimi storitvami.
Osebno toplo priporočam, da omogočite to funkcijo.
Vir: www.habr.com
