


Baza e të dhënave të serive kohore (TSDB) në Prometheus 2 është një shembull i shkëlqyer i një zgjidhjeje inxhinierike që ofron përmirësime të mëdha mbi ruajtjen v2 në Prometheus 1 për sa i përket shpejtësisë së grumbullimit të të dhënave, ekzekutimit të pyetjeve dhe efikasitetit të burimeve. Ne po zbatonim Prometheus 2 në Percona Monitoring and Management (PMM) dhe pata mundësinë të kuptoj performancën e Prometheus 2 TSDB. Në këtë artikull do të flas për rezultatet e këtyre vëzhgimeve.
Ngarkesa mesatare e punës Prometheus
Për ata që janë mësuar të merren me bazat e të dhënave për qëllime të përgjithshme, ngarkesa tipike e punës së Prometheus është mjaft interesante. Shkalla e akumulimit të të dhënave priret të jetë e qëndrueshme: zakonisht shërbimet që monitoroni dërgojnë afërsisht të njëjtin numër metrikash dhe infrastruktura ndryshon relativisht ngadalë.
Kërkesat për informacion mund të vijnë nga burime të ndryshme. Disa prej tyre, të tilla si alarmet, përpiqen gjithashtu për një vlerë të qëndrueshme dhe të parashikueshme. Të tjera, të tilla si kërkesat e përdoruesve, mund të shkaktojnë breshëri, megjithëse ky nuk është rasti për shumicën e ngarkesave të punës.
Testi i ngarkesës
Gjatë testimit, u fokusova në aftësinë për të grumbulluar të dhëna. Unë vendosa Prometheus 2.3.2 të përpiluar me Go 1.10.1 (si pjesë e PMM 1.14) në shërbimin Linode duke përdorur këtë skript: . Për gjenerimin më realist të ngarkesës, duke përdorur këtë Kam nisur disa nyje MySQL me një ngarkesë reale (Sysbench TPC-C Test), secila prej të cilave emuloi 10 nyje. Linux/MySQL.
Të gjitha testet e mëposhtme u kryen në një server Linode me tetë bërthama virtuale dhe 32 GB memorie, duke ekzekutuar 20 simulime ngarkese duke monitoruar dyqind shembuj MySQL. Ose, në termat e Prometeut, 800 objektiva, 440 gërvishtje në sekondë, 380 mijë regjistrime në sekondë dhe 1,7 milionë seri aktive kohore.
Dizajn
Qasja e zakonshme e bazave të të dhënave tradicionale, duke përfshirë atë të përdorur nga Prometheus 1.x, është që të . Nëse nuk është e mjaftueshme për të përballuar ngarkesën, do të përjetoni vonesa të larta dhe disa kërkesa do të dështojnë. Përdorimi i memories në Prometheus 2 mund të konfigurohet nëpërmjet çelësit storage.tsdb.min-block-duration, i cili përcakton se sa kohë do të mbahen regjistrimet në memorie përpara se të hidhen në disk (parazgjedhja është 2 orë). Sasia e memories së kërkuar do të varet nga numri i serive kohore, etiketave dhe gërvishtjeve të shtuara në transmetimin neto hyrës. Për sa i përket hapësirës në disk, Prometheus synon të përdorë 3 bajt për rekord (kampion). Nga ana tjetër, kërkesat për memorie janë shumë më të larta.
Megjithëse është e mundur të konfiguroni madhësinë e bllokut, nuk rekomandohet konfigurimi i tij manualisht, kështu që ju jeni të detyruar t'i jepni Prometheus aq memorie sa kërkon për ngarkesën tuaj të punës.
Nëse nuk ka memorie të mjaftueshme për të mbështetur rrjedhën hyrëse të metrikës, Prometheus do të humbasë memorien ose vrasësi OOM do të arrijë tek ajo.
Shtimi i shkëmbimit për të vonuar përplasjen kur Prometheus i mbaron memoria nuk ndihmon vërtet, sepse përdorimi i këtij funksioni shkakton konsum shpërthyes të kujtesës. Mendoj se ka të bëjë me Go, grumbulluesin e tij të plehrave dhe mënyrën se si merret me shkëmbimin.
Një qasje tjetër interesante është të konfiguroni bllokun e kokës që të shpërndahet në disk në një kohë të caktuar, në vend që ta numëroni atë që nga fillimi i procesit.
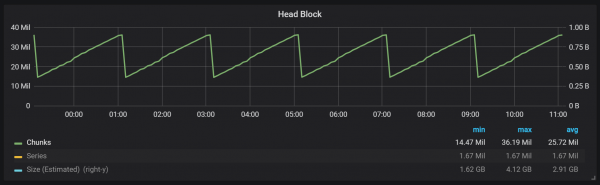
Siç mund ta shihni nga grafiku, ndezjet në disk ndodhin çdo dy orë. Nëse e ndryshoni parametrin min-blloku-kohëzgjatja në një orë, atëherë këto rivendosje do të ndodhin çdo orë, duke filluar pas gjysmë ore.
Nëse dëshironi të përdorni këtë dhe grafikë të tjerë në instalimin tuaj të Prometheus, mund ta përdorni këtë . Është projektuar për PMM, por, me modifikime të vogla, përshtatet në çdo instalim të Prometheus.
Kemi një bllok aktiv të quajtur head block i cili ruhet në memorie; blloqet me të dhëna më të vjetra janë të disponueshme nëpërmjet mmap(). Kjo eliminon nevojën për të konfiguruar cache-në veçmas, por gjithashtu do të thotë që ju duhet të lini hapësirë të mjaftueshme për cache-in e sistemit operativ nëse dëshironi të kërkoni të dhëna më të vjetra se ato që mund të strehojë blloku i kokës.
Kjo do të thotë gjithashtu se konsumi i memories virtuale Prometheus do të duket mjaft i lartë, gjë që nuk është diçka për t'u shqetësuar.
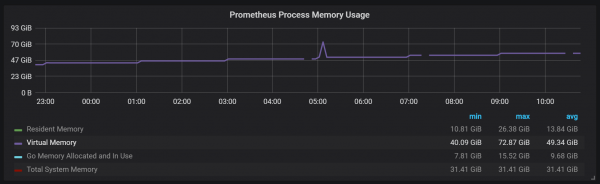
Një tjetër pikë interesante e projektimit është përdorimi i WAL (shkrimi përpara). Siç mund ta shihni nga dokumentacioni i ruajtjes, Prometheus përdor WAL për të shmangur përplasjet. Mekanizmat specifikë për garantimin e mbijetesës së të dhënave, për fat të keq, nuk janë të dokumentuara mirë. Versioni 2.3.2 i Prometheus lan WAL në disk çdo 10 sekonda dhe ky opsion nuk mund të konfigurohet nga përdoruesi.
Ngjeshjet
Prometheus TSDB është projektuar si një dyqan LSM (Log Structured Merge): blloku i kokës shpërlahet periodikisht në disk, ndërsa një mekanizëm ngjeshjeje kombinon blloqe të shumta së bashku për të shmangur skanimin e shumë blloqeve gjatë pyetjeve. Këtu mund të shihni numrin e blloqeve që kam vëzhguar në sistemin e testimit pas një dite ngarkese.
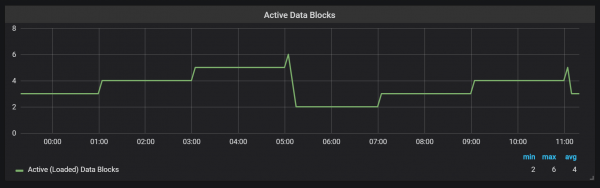
Nëse dëshironi të mësoni më shumë rreth dyqanit, mund të ekzaminoni skedarin meta.json, i cili ka informacione rreth blloqeve të disponueshme dhe se si u krijuan.
{
"ulid": "01CPZDPD1D9R019JS87TPV5MPE",
"minTime": 1536472800000,
"maxTime": 1536494400000,
"stats": {
"numSamples": 8292128378,
"numSeries": 1673622,
"numChunks": 69528220
},
"compaction": {
"level": 2,
"sources": [
"01CPYRY9MS465Y5ETM3SXFBV7X",
"01CPYZT0WRJ1JB1P0DP80VY5KJ",
"01CPZ6NR4Q3PDP3E57HEH760XS"
],
"parents": [
{
"ulid": "01CPYRY9MS465Y5ETM3SXFBV7X",
"minTime": 1536472800000,
"maxTime": 1536480000000
},
{
"ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ",
"minTime": 1536480000000,
"maxTime": 1536487200000
},
{
"ulid": "01CPZ6NR4Q3PDP3E57HEH760XS",
"minTime": 1536487200000,
"maxTime": 1536494400000
}
]
},
"version": 1
}Ngjeshjet në Prometheus janë të lidhura me kohën kur blloku i kokës është shpëlarë në disk. Në këtë pikë, mund të kryhen disa operacione të tilla.
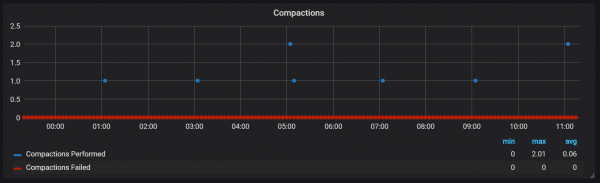
Duket se ngjeshjet nuk janë të kufizuara në asnjë mënyrë dhe mund të shkaktojnë pika të mëdha të hyrjes/daljes së diskut gjatë ekzekutimit.
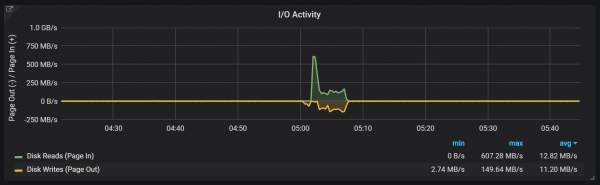
Shkallët e ngarkesës së CPU-së
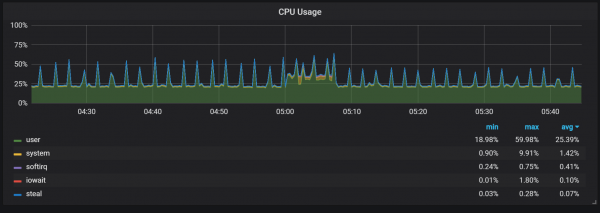
Sigurisht, kjo ka një ndikim mjaft negativ në shpejtësinë e sistemit, dhe gjithashtu paraqet një sfidë serioze për ruajtjen e LSM: si të bëhet ngjeshja për të mbështetur normat e larta të kërkesave pa shkaktuar shumë shpenzime?
Përdorimi i kujtesës në procesin e ngjeshjes gjithashtu duket mjaft interesant.
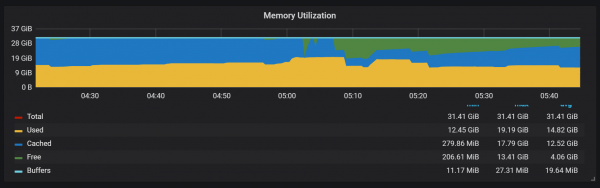
Ne mund të shohim se si, pas ngjeshjes, shumica e memories ndryshon gjendjen nga Cached në Falas: kjo do të thotë se informacioni potencialisht i vlefshëm është hequr prej andej. Kuriozë nëse përdoret këtu fadvice() ose ndonjë teknikë tjetër minimizimi, apo është për shkak se cache u çlirua nga blloqet e shkatërruara gjatë ngjeshjes?
Rimëkëmbja pas një dështimi
Rimëkëmbja nga dështimet kërkon kohë dhe për arsye të mirë. Për një rrymë hyrëse prej një milion regjistrimesh në sekondë, më duhej të prisja rreth 25 minuta ndërsa rikuperimi u krye duke marrë parasysh diskun SSD.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)"
level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)"
level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))"
level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)"
level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090
level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..."
level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R
level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus
level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM
level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0
level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q
level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB
level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363
level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started"
level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml
level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."Problemi kryesor i procesit të rikuperimit është konsumi i lartë i memories. Përkundër faktit se në një situatë normale serveri mund të funksionojë në mënyrë të qëndrueshme me të njëjtën sasi memorie, nëse prishet, mund të mos rikuperohet për shkak të OOM. Zgjidhja e vetme që gjeta ishte të çaktivizoja mbledhjen e të dhënave, të hapja serverin, ta lija të rikuperohej dhe të rindizja me mbledhjen e aktivizuar.
Nxemje
Një sjellje tjetër që duhet mbajtur parasysh gjatë ngrohjes është lidhja midis performancës së ulët dhe konsumit të lartë të burimeve menjëherë pas fillimit. Gjatë disa fillimeve, por jo të gjitha, vura re një ngarkesë serioze në CPU dhe memorie.
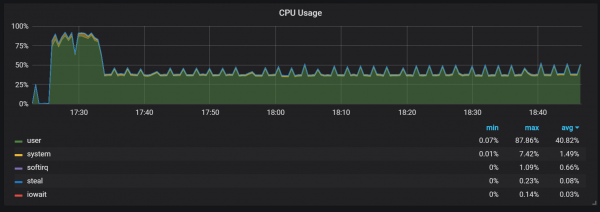
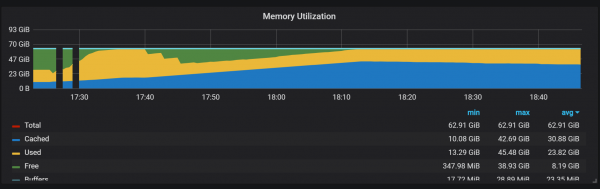
Boshllëqet në përdorimin e memories tregojnë se Prometheus nuk mund të konfigurojë të gjitha koleksionet që nga fillimi dhe disa informacione humbasin.
Nuk i kam kuptuar arsyet e sakta për ngarkesën e lartë të CPU dhe kujtesës. Dyshoj se kjo është për shkak të krijimit të serive të reja kohore në bllokun e kokës me frekuencë të lartë.
Ngarkesa e CPU-së rritet
Përveç ngjeshjeve, të cilat krijojnë një ngarkesë mjaft të lartë I/O, kam vërejtur rritje serioze në ngarkesën e CPU-së çdo dy minuta. Shpërthimet janë më të gjata kur fluksi i hyrjes është i lartë dhe duket se shkaktohen nga mbledhësi i mbeturinave të Go, me të paktën disa bërthama të ngarkuara plotësisht.
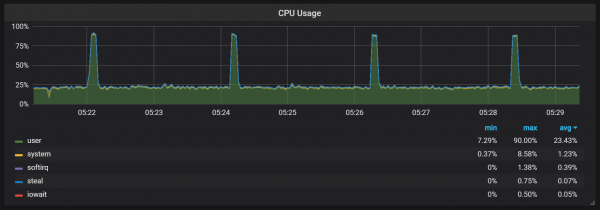
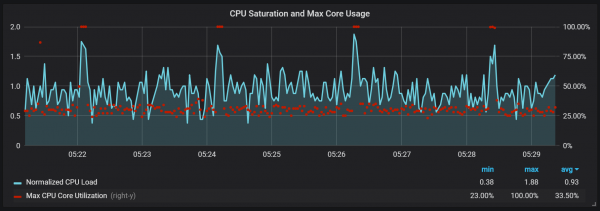
Këto kërcime nuk janë aq të parëndësishme. Duket se kur ndodhin këto, pika e brendshme e hyrjes dhe metrikat e Prometeut bëhen të padisponueshme, duke shkaktuar boshllëqe të dhënash gjatë të njëjtave periudha kohore.
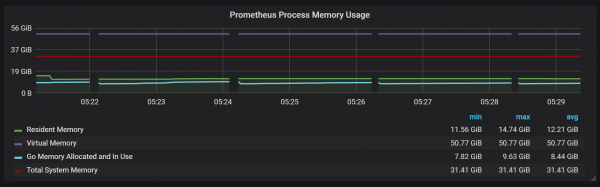
Ju gjithashtu mund të vini re se eksportuesi Prometheus mbyllet për një sekondë.
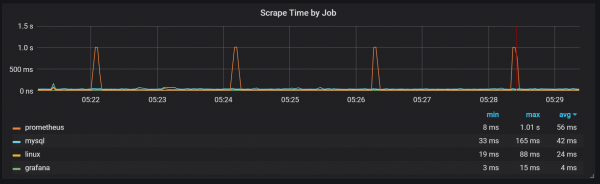
Mund të vërejmë korrelacione me mbledhjen e mbeturinave (GC).
Përfundim
TSDB në Prometheus 2 është i shpejtë, i aftë për të trajtuar miliona seri kohore dhe në të njëjtën kohë mijëra regjistrime në sekondë duke përdorur një pajisje mjaft modeste. Përdorimi i CPU dhe I/O i diskut është gjithashtu mbresëlënës. Shembulli im tregoi deri në 200 metrikë për sekondë për bërthamën e përdorur.
Për të planifikuar zgjerimin, duhet të mbani mend për sasi të mjaftueshme memorie, dhe kjo duhet të jetë memorie reale. Sasia e memories së përdorur që vura re ishte rreth 5 GB për 100 regjistrime për sekondë të rrymës hyrëse, e cila së bashku me cache të sistemit operativ jepte rreth 000 GB memorie të zënë.
Natyrisht, ka ende shumë punë për të bërë për të zbutur pikat e CPU dhe I/O të diskut, dhe kjo nuk është për t'u habitur duke marrë parasysh se sa i ri TSDB Prometheus 2 krahasohet me InnoDB, TokuDB, RocksDB, WiredTiger, por të gjithë kishin të ngjashme probleme në fillim të ciklit të tyre jetësor.
Burimi: www.habr.com
