

Përshëndetje, unë jam Dmitriy Logvinenko — Inxhinier i të Dhënave në departamentin e analizës së grupit të kompanive «Vezët».
Do t'ju tregoj për një mjet të shkëlqyer për zhvillimin e proceseve ETL — Apache Airflow. Por Airflow është aq universal dhe shumëfishtë, saqë ia vlen ta shqyrtoni edhe nëse nuk mereni me rrjedhat e të dhënave, por keni nevojë të filloni nganjëherë ndonjë proces dhe të ndihmoni në mbajtjen e tyre nën kontroll.
Po, nuk do të flas vetëm, por do të tregoj dhe: programi ka shumë kode, shkëmbime dhe rekomandime.
Çfarë zakonisht shihni kur kërkoni fjalën Airflow / Wikimedia Commons
Përmbajtja
Hyrje
Apache Airflow — është ashtu si Django:
- shkruar në Python,
- ka një admin të shkëlqyer,
- është pa kufij për zgjerim,
— vetëm më të mirat, dhe është krijuar për qëllime krejtësisht të tjera, përkatësisht (siç është shkruar deri në kaptinë):
- nisjen dhe monitorimin e detyrave në numër të pakufizuar makinash (sa do t'ju lejojë Celery/Kubernetes dhe ndërgjegjja juaj)
- me gjenerimin dinamik të flukseve të punës nga një kod shumë i lehtë për t'u shkruar dhe për t'u kuptuar në Python
- dhe me mundësinë për të lidhur çdo bazë të të dhënave dhe API me ndihmën e komponenteve të gatshme ose pluginëve të vetë-krijuar (gjë që bëhet jashtëzakonisht e lehtë).
Ne përdorim Apache Airflow në këtë mënyrë:
- mbledhim të dhëna nga burime të ndryshme (shumë instanca SQL Server dhe PostgreSQL, API të ndryshme me metrika të aplikacioneve, madje edhe 1C) në DWH dhe ODS (këtë e bëjmë me Vertica dhe Clickhouse).
- si një avanguardë
cron, i cili ekzekuton procese konsolidimi të të dhënave në ODS, si dhe monitoron shërbimin e tyre.
Derisa përpara pak kohësh ne e përmbushëm nevojën tonë me një server të vogël me 32 bërthama dhe 50 GB RAM. Në Airflow funksionon:
- më 200 DAG-ë (në thelb flukse pune, në të cilat kemi mbushur detyrat),
- në secilin në mesatarisht 70 detyra,
- kjo gjë ekzekutohet (po ashtu në mesatarisht) një herë në orë.
Dhe për mënyrën se si ne u zgjeruam, do të shkruaj më poshtë, por tani le të përcaktojmë über-detyrën që do të zgjidhim:
Ka janë tri servera SQL burimorë, të cilët kanë nga 50 baza të dhënash — instanca të një projekti, përkatësisht struktura e tyre është e njëjtë (në shumicën e rasteve, mwa-ha-ha), dhe për pasojë, çdo njëri ka një tabelë Orders (fatmirësisht, një tabelë me një emër të tillë mund të futet në çdo biznes). Ne marrim të dhënat duke shtuar fushat ndihmëse (serveri burim, baza burimore, identifikuesi i detyrës ETL) dhe naivisht do t'i hedhim ato në, të themi, Vertica.
Fillojmë!
Pjesa kryesore, praktike (edhe pak teorike)
Pse na duhet (dhe juve)
Kur pemët ishin të mëdha dhe unë isha një i thjeshtë SQL-çkuar në një shitje të madhe ruse, ne hidheshim në proceset ETL aka rrjedhat e të dhënave me dy mjete të disponueshme për ne:
- Informatica Power Center — një sistem ekstremisht kompleks, jashtëzakonisht produktiv, me pajisjet e veta dhe versionimin e saj. Kam përdorur ndoshta 1% të mundësive të saj. Pse? Epo, së pari, ky ndërfaqe ishte diku nga vitet '00 dhe na e shkaktonte presion psikologjik. Së dyti, kjo gjë është e mbyllur në procese tejet komplekse, riblerje intensive të komponenteve dhe shumë karakteristika të rëndësishme për ndërmarrjet. Për atë çmim që kushton, si fluturimi i një Airbus A380/një vit, do të heshtim.
Kujdes, screenshot mund t'i bëjë të rinjve nën 30 vjeç të ndihen disi keq

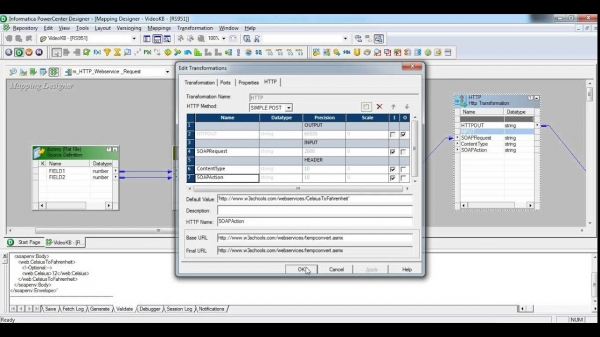
- SQL Server Integration Server — ne kemi përdorur këtë shok në proceset tona interne. Por në realitet: ne tashmë përdorim SQL Server, dhe do të ishte disi e paarsyeshme të mos i shfrytëzonim mjetet ETL të tij. Gjithçka në të është mirë: dhe ndërfaqja është e bukur, si dhe raportet e ekzekutimit... Por nuk për këtë e duam produktin software, oh jo për këtë. Të versiononi atë
dtsx(i cili është një XML me node të përzier gjatë ruajtjes) mund ta bëjmë, por çfarë do të thotë? Të bëjmë një paketë detyrash që do të transferonte njëqind tabela nga një server në tjetrin? Po çfarë njëqind, do t'ju bie gishti tregues pas njëzet copash, duke klikuar mbi butonin e mausit. Por duke parë, sigurisht duket më modern:
Kemi kërkuar pa dyshim zgjidhje. Punë madje gjysmë arritëm të krijojmë një gjenerator të vetë-ndërtuar për paketat SSIS...
... dhe pastaj më gjeti puna e re. Dhe aty më preku Apache Airflow.
Kur mësova se përshkrimet e proceseve ETL janë thjesht kod Python, pothuajse kërcen nga gëzimi. Kështu që rrjedhat e të dhënave u nënshtruan versionimit dhe difes, dhe grumbullimi i tabelave me një strukturë unike nga njëqind baza të dhënash në një target u bë një punë e kodit Python në një ekran 13” me një të dhjetë.
Po mblidhni një klaster
Le të mos organizojmë një kopësht të fëmijëve, dhe të mos flasim për gjëra të heltësisht të qarta, siç është instalimi i Airflow, baza e të dhënave që keni zgjedhur, Celery dhe punë të tjera të përshkruara në dokumente.
Që të mund të fillojmë menjëherë me eksperimentet, kam skicuar docker-compose.yml në të cilin:
- Le të ngrisim vetë Airflow: Scheduler, Webserver. Atje do të funksionojë gjithashtu Flower për monitorimin e detyrave të Celery (sepse është shtypur tashmë në
apache/airflow:1.10.10-python3.7, dhe ne nuk kemi asnjë problem me këtë); - PostgreSQL, në të cilin Airflow do të shkruajë informacionin e saj operativ (të dhënat e planifikuesit, statistikat e ekzekutimit etj.), ndërsa Celery do të shënojë detyrat e përfunduara;
- Redis, i cili do të veprojë si një broker detyrash për Celery;
- Celery worker, i cili do të merret me ekzekutimin e drejtpërdrejtë të detyrave.
- Në dosjen
./dagsne do të vendosim skedarët tanë me përshkrimin e dags. Ato do të kapen në flakë, prandaj nuk është e nevojshme të tërhiqni të gjithë stekun pas çdo shkurti.
Disa herë kodi në shembuj është dhënë jo plotësisht (për të mos e mbingarkuar tekstin), dhe diku ai modifikohet gjatë procesit. Shembujt e plotë funksionues të kodit mund të shihen në repositorium. .
docker-compose.yml
version: '3.4'
x-airflow-config: &airflow-config
AIRFLOW__CORE__DAGS_FOLDER: /dags
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__CORE__FERNET_KEY: MJNz36Q8222VOQhBOmBROFrmeSxNOgTCMaVp2_HOtE0=
AIRFLOW__CORE__HOSTNAME_CALLABLE: airflow.utils.net:get_host_ip_address
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgres+psycopg2://airflow:airflow@airflow-db:5432/airflow
AIRFLOW__CORE__PARALLELISM: 128
AIRFLOW__CORE__DAG_CONCURRENCY: 16
AIRFLOW__CORE__MAX_ACTIVE_RUNS_PER_DAG: 4
AIRFLOW__CORE__LOAD_EXAMPLES: 'False'
AIRFLOW__CORE__LOAD_DEFAULT_CONNECTIONS: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_RETRY: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_FAILURE: 'False'
AIRFLOW__CELERY__BROKER_URL: redis://broker:6379/0
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@airflow-db/airflow
x-airflow-base: &airflow-base
image: apache/airflow:1.10.10-python3.7
entrypoint: /bin/bash
restart: always
volumes:
- ./dags:/dags
- ./requirements.txt:/requirements.txt
services:
# Redis si Celery broker
broker:
image: redis:6.0.5-alpine
# DB për metadata e Airflow
airflow-db:
image: postgres:10.13-alpine
environment:
- POSTGRES_USER=airflow
- POSTGRES_PASSWORD=airflow
- POSTGRES_DB=airflow
volumes:
- ./db:/var/lib/postgresql/data
# Kontejner kryesor me Webserver, Scheduler, Celery Flower të Airflow
airflow:
<<: *airflow-base
environment:
<<: *airflow-config
AIRFLOW__SCHEDULER__DAG_DIR_LIST_INTERVAL: 30
AIRFLOW__SCHEDULER__CATCHUP_BY_DEFAULT: 'False'
AIRFLOW__SCHEDULER__MAX_THREADS: 8
AIRFLOW__WEBSERVER__LOG_FETCH_TIMEOUT_SEC: 10
depends_on:
- airflow-db
- broker
command: >
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint initdb &&
(/entrypoint webserver &) &&
(/entrypoint flower &) &&
/entrypoint scheduler"
ports:
# Celery Flower
- 5555:5555
# Webserver i Airflow
- 8080:8080
# Punëtori Celery, do të shkallëzohet duke përdorur `--scale=n`
worker:
<<: *airflow-base
environment:
<<: *airflow-config
command: >
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint worker"
depends_on:
- airflow
- airflow-db
- brokerShënime:
- Në ndërtimin e kompozitës kam mbështetur shumë në imazhin e njohur – patjetër shikoni. Ndoshta në jetën tuaj nuk keni nevojë për asgjë tjetër.
- Të gjitha konfigurimet e Airflow janë të disponueshme jo vetëm përmes
airflow.cfg, por edhe përmes variablave të ambientit (falë zhvilluesve), të cilat i përdora keq. - Natyrisht, ai nuk është gati për prodhim: qëllimisht nuk kam vendosur heartbeats në kontenierë, nuk u shqetësova për sigurinë. Megjithatë, bëra një minimum të përshtatshëm për eksperimentet tona.
- Vë re se:
- Folderi me DAG-at duhet të jetë i aksesueshëm si për planifikuesin ashtu edhe për punëtorët.
- E njëjta gjë vlen edhe për të gjitha bibliotekat e palëve të treta – ato duhet të jenë të gjitha të instaluara në makinat me planifikuesin dhe punëtorët.
Tani thjesht:
$ docker-compose up --scale worker=3Pas ngritjes, mund të shikoni ndërfaqet e internetit:
- Airflow:
- Flower:
Koncepte themelore
Nëse nuk keni kuptuar asgjë nga këto «DAG», ja një fjalor i shkurtër:
- Planifikuesi – دستşgŷ (djali më i rëndësishëm) në Airflow, që kontrollon që robotët të punojnë, jo njerëzit: monitoron orarin, përditëson DAG-at, nis detyrat.
Në versionet më të vjetra, ai kishte probleme me memorinë (jo, jo amnezia, por rrjedhje) dhe atje kishte mbetur një parametër legacy në konfigurime.
run_duration— intervali i rivendosjes së tij. Por tani gjithçka është në rregull. - DAG (edhe i njohur si «dag») — «grafik i orientuar jo-ciklik», por një përcaktim i tillë shumë pak njerëzve do t'u thotë diçka, dhe në thelb, është një kontejner për detyrat që ndërveprojnë me njëra-tjetrën (shih më poshtë) ose një analog i Paketës në SSIS dhe Workflow në Informatica.
Përveç dag-ve, gjithashtu mund të ketë sub-dag, por ndoshta nuk do të arrijmë atje.
- DAG Run — një dag i inicializuar, të cilit i është dhënë e tij
execution_date. DAGRAT e një dag-u mund të punojnë paralelisht (nëse, sigurisht, keni bërë detyrat tuaja idempotente). - Operator — këto janë copa kode që janë përgjegjëse për ekzekutimin e një veprimi të caktuar. Ka tre lloje operatorësh:
- veprim, si për shembull operatori ynë i preferuar
PythonOperator, i cili mund të ekzekutojë çdo (të vlefshëm) kod Python; - transfer, të cilët transportojnë të dhëna nga një vend në një tjetër, për shembull,
MsSqlToHiveTransfer; - sensor do të lejojë të reagoni ose të ngadalësoni ekzekutimin e dag-ut deri në ndodhjen e një eventi të caktuar.
HttpSensormund të tërheqë endpoint-in e caktuar dhe kur të presë përgjigjen e duhur, të fillojë transferiminGoogleCloudStorageToS3Operator. Një mendje kurioze do të pyesë: "përse? Sepse mund të bëjmë ripërsëritje direkt në operator!" Dhe pastaj, që të mos bllokojmë rezervuarin e detyrave me operatorë që janë pezull. Sensorët aktivizohen, kontrollojnë dhe vdesin deri në përpjekjen e ardhshme.
- veprim, si për shembull operatori ynë i preferuar
- Detyrë — operatorët e shpallur, pa marrë parasysh llojin, dhe të lidhur me dagun rriten në nivelin e detyrave.
- Instanca e detyrës — kur gjenerali-planifikues vendos se detyrat janë gati për t'u dërguar në luftë te punëtorët-ekzekutorë (në vend, nëse po përdorim
LocalExecutorose në një nod të largët në rastin eCeleryExecutor), ai u cakton atyre një kontekst (dmth. një grup variablesh - parametrash ekzekutimi), zhvillon modelet e komandave ose kërkesave dhe i vendos ato në rezervuar.
Drejtojmë detyrat
Së pari do të shënojmë skemën e përgjithshme të dagut tonë dhe pastaj do të thellojmë gjithnjë e më shumë në detaje, sepse përdorim disa zgjidhje jo triviale.
Pra, në formën më të thjeshtë, një dag i tillë do të dukej kështu:
nga datetime import timedelta, datetime
nga airflow import DAG
nga airflow.operators.python_operator import PythonOperator
nga commons.datasources import sql_server_ds
dag = DAG('orders',
schedule_interval=timedelta(hours=6),
start_date=datetime(2020, 7, 8, 0))
def workflow(**context):
print(context)
për conn_id, schema në sql_server_ds:
PythonOperator(
task_id=schema,
python_callable=workflow,
provide_context=True,
dag=dag)Le të kuptojmë:
- Së pari importojmë libraritë e nevojshme dhe disa gjëra të tjera;
sql_server_ds— kjo ështëList[namedtuple[str, str]]me emrat e lidhjeve nga Airflow Connections dhe bazat e të dhënave nga të cilat do të marrim tabelën tonë;dag— deklarata e DAG-ut tonë, e cila duhet të jetë nëglobals(), përndryshe Airflow nuk do ta gjente. DAG-ut i duhet gjithashtu të themi:- se quhet
orders— ky emër pastaj do të shfaqet në ndërfaqen e internetit, - se do të fillojë punën në mesnatë më 8 korrik,
- dhe duhet të ekzekutohet, afërsisht çdo 6 orë (për djemtë e mrekullueshëm këtu në vend të
timedelta()lejohetcron-linjë0 0 0/6 ? * * *, për ata më pak të mrekullueshëm — një shprehje si@daily);
- se quhet
workflow()do të bëjë punën kryesore, por jo tani. Tani ne thjesht do të hedhim kontekstin tonë në log.- Dhe tani magjia e thjeshtë e krijimit të detyrave:
- ecim përmes burimeve tona;
- inicjalizojmë
PythonOperator, i cili do të realizojë shoshin tonëworkflow(). Mos u harroni të tregoni një emër unik (brenda DAG-ut) për detyrën dhe të lidheni me vetë DAG-un. Flagsiguroni_kontekstnga ana e tij do të hedhë në funksion argumente shtesë, të cilat ne do t'i mbledhim me kujdes përmes**konteksti.
Derisa në këtë pikë, çfarë kemi marrë:
- një DAG të ri në ndërfaqen web,
- njëqind e pesëdhjetë detyra që do të ekzekutohen paralelisht (nëse lejojnë konfigurimet e Airflow, Celery dhe fuqia e serverëve).
Të paktën pothuajse e morëm.
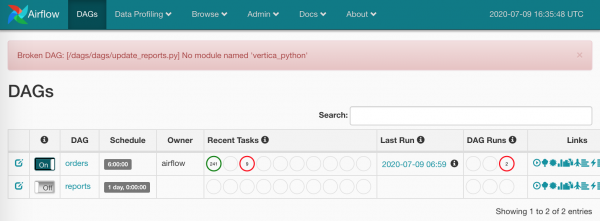
Kush do të instalohet varësitë?
Për ta thjeshtuar këtë, unë e kam ngjeshur në docker-compose.yml trajtim requirements.txt në të gjitha nodet.
Tani po fillon:
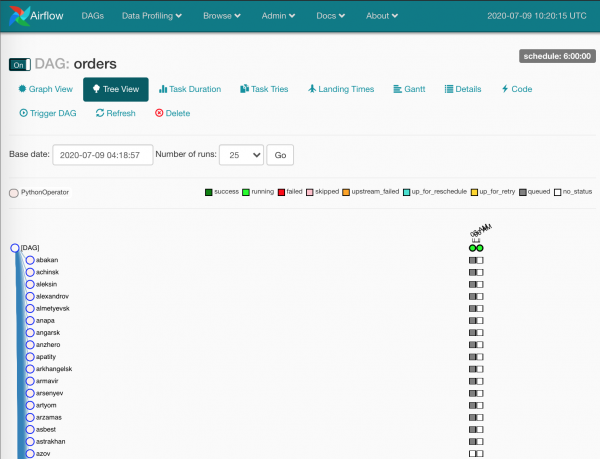
Kube gri — instanca të detyrave, të përpunuara nga planifikuesi.
Disa minuta pritje, detyrat i kapin punëtorët:
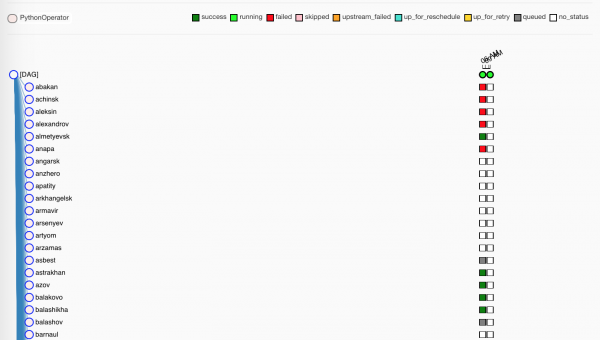
Të gjelbra, e qartë, — që kanë punuar me sukses. Të kuqe — jo shumë me sukses.
Meqenëse, në prodhim tonë nuk ka ndonjë dosje
./dags, e cila sinkronizohet midis makinave — të gjitha DAG-të ndodhen nëgitnë Gitlab tonë, dhe Gitlab CI shpërndani përditësimet në makina kur behet bashkimi nëmaster.
Pak për Flower
Ndërsa punëtorët po punojnë me detyrat tona boshe, kujtojmë një mjet tjetër, i cili mund të na tregojë diçka — Flower.
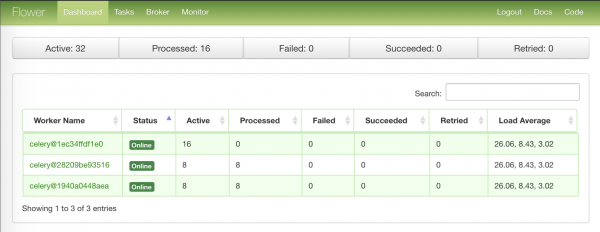
Faqja e parë me informacione përmbledhëse për nodet-punëtorë:
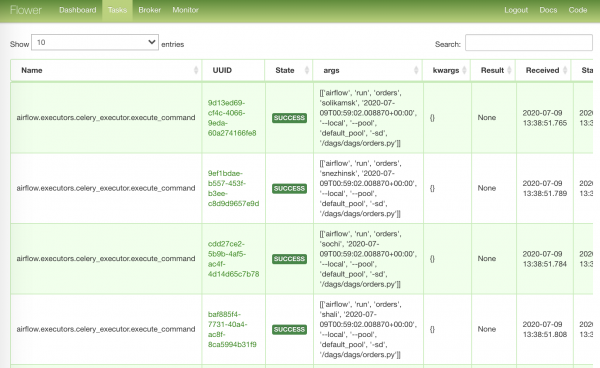
Faqja më e ngarkuar me detyra që kanë filluar punën:
Faqja më e mërzitshme me gjendjen e brokerit tonë:
Faqja më e ndritshme — me grafikat e gjendjes së detyrave dhe kohën e përfundimit të tyre:
Po ngarkojmë të ngarkuarin
Pra, të gjithë detyrat kanë përfunduar, mund të çojmë të plagosurit.
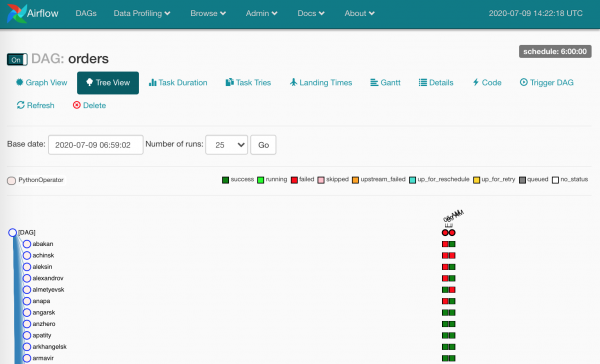
Dhe numri i të plagosurve ishte i konsiderueshëm — për arsye të ndryshme. Nëse përdoret siç duhet Airflow, këta katrorë tregojnë se të dhënat me siguri nuk arritën.
Duhet të shohim logun dhe të rilançojmë instancat e detyrave që kanë dështuar.
Duke klikuar në çdo katror, do të shohim veprimet që na janë në dispozicion:
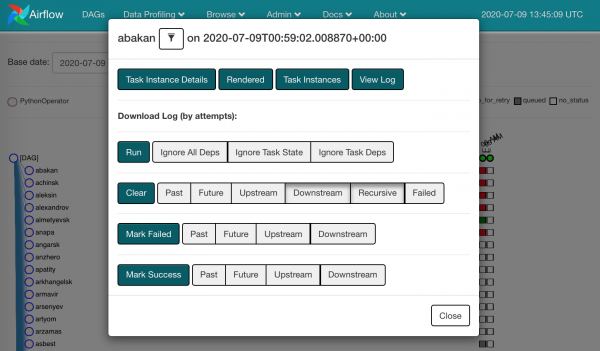
Mund të marrim dhe të bëjmë Clear për atë që ka dështuar. Pra, harrojmë se ka ndodhur diçka, dhe e njëjta instancë detyre do të shkojë te planifikuesi.

Natyrisht, nuk është shumë humane të bësh kështu me të gjitha katrorët e kuq — nuk është ky pritja jonë nga Airflow. Sigurisht, kemi armën e masave shkatërruese: Browse/Task Instances
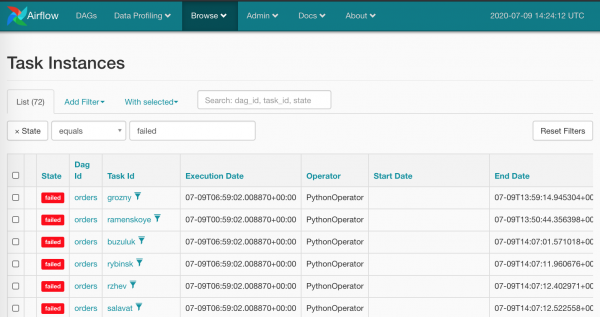
Do të zgjedhim gjithçka njëherësh dhe do të klikojmë opsionin e duhur për të kaluar në zero:
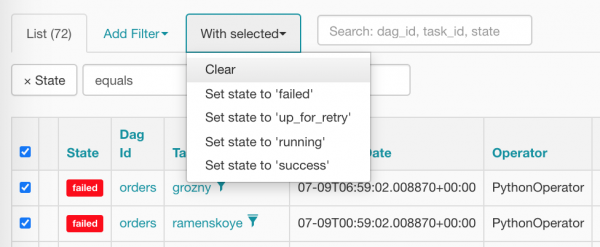
Pas pastrimit, taksitë tona duken kështu (ato tashmë po presin me padurim që planifikuesi t'i planifikojë):

Lidhje, likuj dhe variabla të tjerë
Koha më e mirë për të parë DAG-un tjetër, update_reports.py:
from collections import namedtuple
from datetime import datetime, timedelta
from textwrap import dedent
from airflow import DAG
from airflow.contrib.operators.vertica_operator import VerticaOperator
from airflow.operators.email_operator import EmailOperator
from airflow.utils.trigger_rule import TriggerRule
from commons.operators import TelegramBotSendMessage
dag = DAG('update_reports',
start_date=datetime(2020, 6, 7, 6),
schedule_interval=timedelta(days=1),
default_args={'retries': 3, 'retry_delay': timedelta(seconds=10)})
Report = namedtuple('Report', 'source target')
reports = [Report(f'{table}_view', table) for table in [
'reports.city_orders',
'reports.client_calls',
'reports.client_rates',
'reports.daily_orders',
'reports.order_duration']]
email = EmailOperator(
task_id='email_success', dag=dag,
to='{{ var.value.all_the_kings_men }}',
subject='Raportet DWH janë përditësuar',
html_content=dedent("""Të nderuar, raportet janë përditësuar"""),
trigger_rule=TriggerRule.ALL_SUCCESS)
tg = TelegramBotSendMessage(
task_id='telegram_fail', dag=dag,
tg_bot_conn_id='tg_main',
chat_id='{{ var.value.failures_chat }}',
message=dedent("""
Natasha, zgjohem, ne {{ dag.dag_id }} e hodhëm
"""),
trigger_rule=TriggerRule.ONE_FAILED)
for source, target in reports:
queries = [f"TRUNCATE TABLE {target}",
f"INSERT INTO {target} SELECT * FROM {source}"]
report_update = VerticaOperator(
task_id=target.replace('reports.', ''),
sql=queries, vertica_conn_id='dwh',
task_concurrency=1, dag=dag)
report_update >> [email, tg]Çdokush ka bërë ndonjëherë një raport azhurnimi, apo jo? Ja përsëri: ka një listë burimesh nga ku të marrim të dhënat; ka një listë ku t'i vendosim; mos harro të na lajmerosh kur ndodhi ndonjë gjë ose kur diçka dështoi (mirë, kjo nuk është për ne, jo).
Le të kalojmë përsëri në skedarin dhe të shikojmë gjërat e reja enigmatike:
from commons.operators import TelegramBotSendMessage— asgjë nuk na pengon të krijojmë operatorët tanë, siç e bëmë ne duke krijuar një mbështjellës të vogël për dërgimin e mesazheve në Razblokirovannyy. (Për këtë operator do të flasim më poshtë);default_args={}— dag-u mund të ndajë argumentet e njëjta me të gjithë operatorët e tij;to='{{ var.value.all_the_kings_men }}'— fushatonuk do të jetë e koduar, por do të formohet dinamikisht me anë të Jinja dhe një variabli me listën e email-eve që e kam vendosur me kujdes nëAdmin/Variables;trigger_rule=TriggerRule.ALL_SUCCESS— kushti për aktivizimin e operatorit. Në rastin tonë, letra do të shkojë te shefat vetëm nëse të gjitha varësitë përfunduan suksesshëm;tg_bot_conn_id='tg_main'— argumentetconn_idpranojnë identifikues të lidhjeve që krijojmë nëAdmin/Connections;trigger_rule=TriggerRule.ONE_FAILED— mesazhet në Telegram do të dërgohen vetëm në rast se ka detyra të dështuar;task_concurrency=1— ndalojmë ekzekutimin e shumë instanceve të njëjta të një detyre në të njëjtën kohë. Në të kundërt, do të kemi një ekzekutim të shumë instancaveVerticaOperator(të shikojnë një tabelë);report_update >> [email, tg]— të gjithaVerticaOperatordo të përfundojnë duke dërguar e-mail dhe mesazhe, kështu:

Por, pasi operatorët e njoftimeve kanë kushte të ndryshme për t'u ekzekutuar, do të punojë vetëm njëri. Në Pamjen e Dendrës duket pak më pak e qartë:

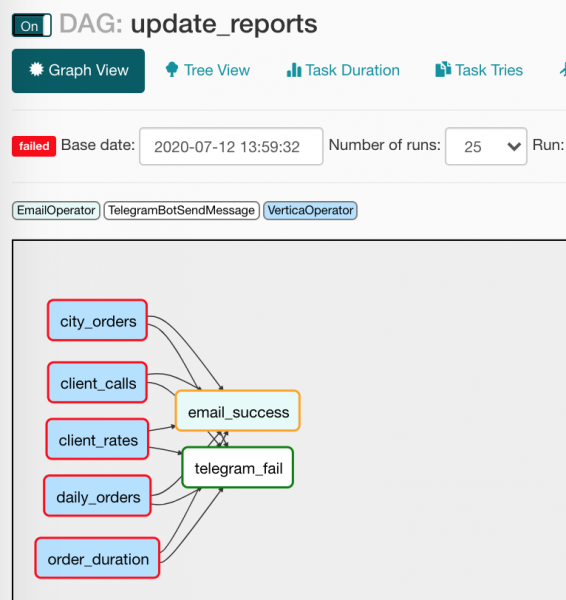

Do të them disa fjalë për makrotë dhe miqtë e tyre — variablat.
Makrotë janë placeholder-e Jinja, të cilat mund të vendosin informacion të ndryshëm të dobishëm në argumentet e operatorëve. Për shembull, kështu:
SELECT
id,
payment_dtm,
payment_type,
client_id
FROM orders.payments
WHERE
payment_dtm::DATE = '{{ ds }}'::DATE{{ ds }} do të zhvillohet në përmbajtjen e variablit të kontekstit execution_date në formatin YYYY-MM-DD: 2020-07-14. E bukura është se variablat e kontekstit lidhen fort me një instancë të caktuar të detyrës (katrorin në Pamjen e Dendrës), dhe kur bëhet një rinisje, placeholder-et do të zbulohen në të njëjtat vlera.
Vlerat e ndara mund të shikohen me butonin Rendered në çdo instancë të detyrës. Kështu është për detyrën me dërgimin e e-mailit:
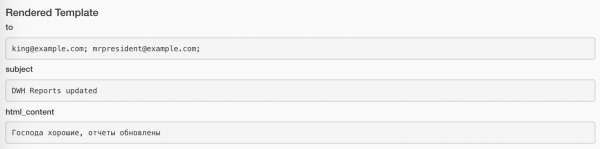
Dhe kështu është për detyrën me dërgimin e mesazhit:

Lista e plotë e makrosve të integruar për versionin më të fundit të disponueshëm është këtu:
Për më tepër, me ndihmën e plugin-eve, ne mund të shpallim makros tona të personalizuara, por kjo është një histori krejt tjetër.
Përveç gjërave të paracaktuar, ne mund të përdorim vlerat e variablave tanë (më sipër në kod unë e kam përdorur këtë). Le të krijojmë në Admin/Variables një çift gjërash:
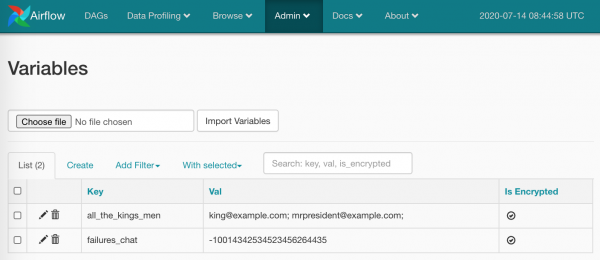
Gati për t’u përdorur:
TelegramBotSendMessage(chat_id='{{ var.value.failures_chat }}')Në vlerë mund të jetë skalar, ose mund të jetë edhe JSON. Në rastin e JSON-it:
bot_config
{
"bot": {
"token": 881hskdfASDA16641,
"name": "Verter"
},
"service": "TG"
}thjesht përdorim rrugën për çelësin e kërkuar: {{ var.json.bot_config.bot.token }}.
Do të them vetëm një fjalë dhe do të tregoj një skrin që ka të bëjë me lidhet. Këtu gjithçka është elementare: në faqe Admin/Connections krijojmë lidhjen, vendosim atje emrat e përdoruesve/fjalëkalimet dhe parametra më specifik. Ja kështu:
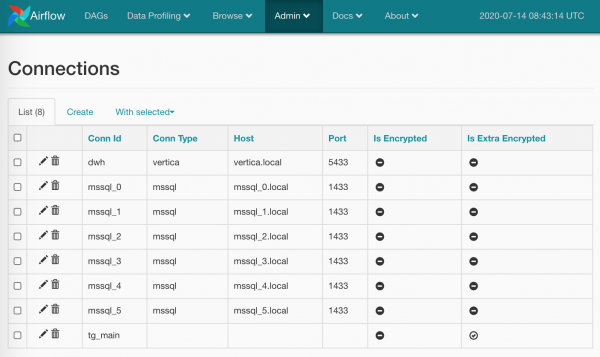
Fjalëkalimat mund të shkruhen (më me kujdes se në variantin e paracaktuar), ose mund të mos caktohet lloji i lidhjes (ashtu siç bëra për tg_main) — çështja është se lista e llojeve është e koduar në modelet Airflow dhe zgjerimi nuk lejon ndryshime në burim (nëse ndonjëherë nuk kam gjetur diçka — ju lutem më korrigjoni), por nuk ka asgjë që na ndalon të marrim kredencialet thjesht me emrin.
Gjithashtu, mund të bëni disa lidhje me një emër të vetëm: në këtë rast, metoda BaseHook.get_connection(), e cila na merr lidhjet sipas emrit, do të kthejë një rastësor nga disa të ngjashëm (do të ishte më logjike të bëhej Round Robin, por do ta lëmë këtë në ndërgjegjen e zhvilluesve të Airflow).
Variables dhe Connections, pa dyshim, janë mjete të shkëlqyera, por është e rëndësishme të mos humbasësh balancimin: cilat pjesë të rrjedhave tuaja i mbani në kodin tuaj dhe cilat — i jepni për ruajtje në Airflow. Nga njëra anë, ndërrimi i shpejtë i vlerës, për shembull, box-i i dërgesës, mund të jetë i lehtë përmes UI. Nga ana tjetër, kjo është në fund të fundit një kthim në klikimin me maus, nga i cili ne (unë) do doja të shpenzoja.
Puna me lidhjet — është një nga detyrat hook-esh. Në përgjithësi, hook-at e Airflow janë pika lidhëse me shërbime dhe biblioteka të jashtme. P.sh., JiraHook do të hapë për ne një klient për të bashkëpunuar me Jira (mund të lëvizim detyra këtu-këtu), dhe me ndihmën e SambaHook mund të dërgoni një skedar lokal në smb-pikë.
Analizojmë operatorin e personalizuar
Dhe ne u afruam ngushtësisht për të parë se si është bërë TelegramBotSendMessage
Kodi commons/operators.py me operatorin vetë:
from typing import Union
from airflow.operators import BaseOperator
from commons.hooks import TelegramBotHook, TelegramBot
class TelegramBotSendMessage(BaseOperator):
"""Dërgo mesazh në chat_id duke përdorur TelegramBotHook
Shembull:
>>> TelegramBotSendMessage(
... task_id='telegram_fail', dag=dag,
... tg_bot_conn_id='tg_bot_default',
... chat_id='{{ var.value.all_the_young_dudes_chat }}',
... message='{{ dag.dag_id }} dështoi :(',
... trigger_rule=TriggerRule.ONE_FAILED)
"""
template_fields = ['chat_id', 'message']
def __init__(self,
chat_id: Union[int, str],
message: str,
tg_bot_conn_id: str = 'tg_bot_default',
*args, **kwargs):
super().__init__(*args, **kwargs)
self._hook = TelegramBotHook(tg_bot_conn_id)
self.client: TelegramBot = self._hook.client
self.chat_id = chat_id
self.message = message
def execute(self, context):
print(f'Dërgo "{self.message}" në bisedën {self.chat_id}')
self.client.send_message(chat_id=self.chat_id,
message=self.message)Këtu, ashtu si gjithçka tjetër në Airflow, është shumë e thjeshtë:
- Trashëguam nga
BaseOperator, e cila implementon shumë gjëra specifike për Airflow (shikoni kur keni kohë) - Deklaruam fushat
template_fields, në të cilat Jinja do të kërkojë makro për përpunim. - Organizuam argumentet e duhura për
__init__(), vendosëm default-et atje ku duhet. - Nuk harrojmë as inicializimin e prindit.
- Hapëm hook-un përkatës
TelegramBotHook, morëm prej tij një objekt-klient. - E overrajduam (përkufizuam përsëri) metodën
BaseOperator.execute(), që Airflow do ta thërrasë kur është koha për të filluar operatorin — aty do të realizojmë veprimin kryesor, pa harruar të regjistrojmë. (Regjistrohemi, për shembull, direkt nëstdoutdhestderr— Airflow do ta kapë gjithçka, do ta mbështjellë bukur, do ta vendosë ku duhet.)
Të shikojmë çfarë kemi në commons/hooks.py. Pjesa e parë e skedarit, me vetë hook-un:
from typing import Union
from airflow.hooks.base_hook import BaseHook
from requests_toolbelt.sessions import BaseUrlSession
class TelegramBotHook(BaseHook):
"""Telegram Bot API hook
Shënim: shtoni një lidhje me Conn Type bosh dhe mos harroni
të plotësoni Extra:
{"bot_token": "YOuRAwEsomeBOtToKen"}
"""
def __init__(self,
tg_bot_conn_id='tg_bot_default'):
super().__init__(tg_bot_conn_id)
self.tg_bot_conn_id = tg_bot_conn_id
self.tg_bot_token = None
self.client = None
self.get_conn()
def get_conn(self):
extra = self.get_connection(self.tg_bot_conn_id).extra_dejson
self.tg_bot_token = extra['bot_token']
self.client = TelegramBot(self.tg_bot_token)
return self.clientS'di ashtë çfarë mund të shpjegohet këtu, thjesht do të theksoj disa pika të rëndësishme:
- Ne trashëgojmë, mendojmë për argumentet — në shumicën e rasteve do të jetë vetëm një:
conn_id; - Tejkalojmë metodat standarde: unë e kufizova
get_conn(), ku marrë parametrat e lidhjes sipas emrit dhe thjesht nxjerr seksioninextra(ky është një fushë për JSON), në të cilën unë (sipas udhëzimit tim!) vendosa tokenin e bosit Telegram:{"bot_token": "YOuRAwEsomeBOtToKen"}. - Krijoj një instancë të
TelegramBot, duke i dhënë gjithashtu tokenin e saktë.
Këtu është. Të marrë klientin nga huka mund të bëhet me TelegramBotHook().clent ose TelegramBotHook().get_conn().
Dhe pjesa e dytë e skedarit, ku bëj një mikro mbështjellje për Telegram REST API, për të mos sjellur të njëjtin për një metodë të vetme sendMessage.
class TelegramBot:
"""Telegram Bot API wrapper
Examples:
>>> TelegramBot('YOuRAwEsomeBOtToKen', '@myprettydebugchat').send_message('Hi, darling')
>>> TelegramBot('YOuRAwEsomeBOtToKen').send_message('Hi, darling', chat_id=-1762374628374)
"""
API_ENDPOINT = 'https://api.telegram.org/bot{}/'
def __init__(self, tg_bot_token: str, chat_id: Union[int, str] = None):
self._base_url = TelegramBot.API_ENDPOINT.format(tg_bot_token)
self.session = BaseUrlSession(self._base_url)
self.chat_id = chat_id
def send_message(self, message: str, chat_id: Union[int, str] = None):
method = 'sendMessage'
payload = {'chat_id': chat_id or self.chat_id,
'text': message,
'parse_mode': 'MarkdownV2'}
response = self.session.post(method, data=payload).json()
if not response.get('ok'):
raise TelegramBotException(response)
class TelegramBotException(Exception):
def __init__(self, *args, **kwargs):
super().__init__((args, kwargs))Qëllimi i duhur është të bashkosh të gjitha këto:
TelegramBotSendMessage,TelegramBotHook,TelegramBot— në plugin, ta vendosësh në një depo të hapur dhe ta ofrosh si Open Source.
Përderisa po e shqyrtonim gjithçka, përditësimet tona të raporteve arritën që të dërgojnë një mesazh gabimi në kanalin tim. Po shkoj të kontrolloj se çfarë është sërish gabim...
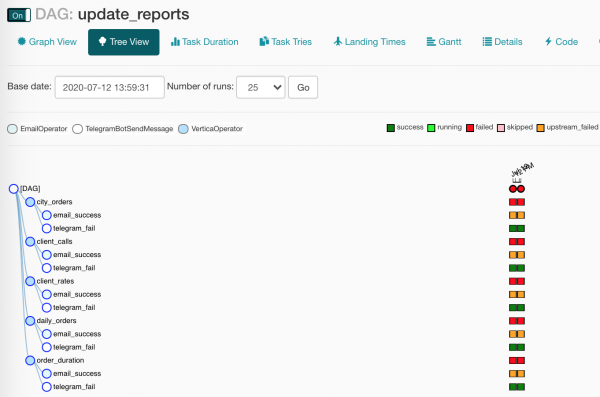
Diçka është prishur në dagun tonë! Po ashtu kjo është ajo që prisnim? Pikërisht!
A do të derdhësh?
Ndiheni se kam harruar diçka? Duket se premtova të transferoj të dhënat nga SQL Server në Vertica dhe këtu u largova nga tema, sa bezdisës!
Krimi ishte i qëllimtë, thjesht kisha detyrim të shpjegoja disa terminologji për ju. Tani mund të vazhdojmë.
Plani ynë ishte si më poshtë:
- Të bëjmë dag
- Të gjenerojmë detyra
- Të shohim si duket gjithçka
- Të caktojmë numrat e seancave për mbushjet
- Të marrim të dhënat nga SQL Server
- Të vendosim të dhënat në Vertica
- Të grumbullojmë statistikat
Pra, për të gjithë këtë, kam bërë një shtesë të vogël në docker-compose.yml:
docker-compose.db.yml
version: '3.4'
x-mssql-base: &mssql-base
image: mcr.microsoft.com/mssql/server:2017-CU21-ubuntu-16.04
restart: always
environment:
ACCEPT_EULA: Y
MSSQL_PID: Express
SA_PASSWORD: SayThanksToSatiaAt2020
MSSQL_MEMORY_LIMIT_MB: 1024
services:
dwh:
image: jbfavre/vertica:9.2.0-7_ubuntu-16.04
mssql_0:
<<: *mssql-base
mssql_1:
<<: *mssql-base
mssql_2:
<<: *mssql-base
mssql_init:
image: mio101/py3-sql-db-client-base
command: python3 ./mssql_init.py
depends_on:
- mssql_0
- mssql_1
- mssql_2
environment:
SA_PASSWORD: SayThanksToSatiaAt2020
volumes:
- ./mssql_init.py:/mssql_init.py
- ./dags/commons/datasources.py:/commons/datasources.pyAtje shohim:
- Vertica si host
dwhme cilësimet më të zakonshme, - tri instanca SQL Server,
- plotsojmë bazat me disa të dhëna të fundit (nuk duhet të shikoni në
mssql_init.py!)
E kemi nisur gjithçka me një komandë pak më të komplikuar se më parë:
$ docker-compose -f docker-compose.yml -f docker-compose.db.yml up --scale worker=3Çfarë ka gjeneruar rastësia jonë, mund të shikohet duke përdorur pikën Profilizimi i të Dhënave/Kërkesa Ad Hoc:
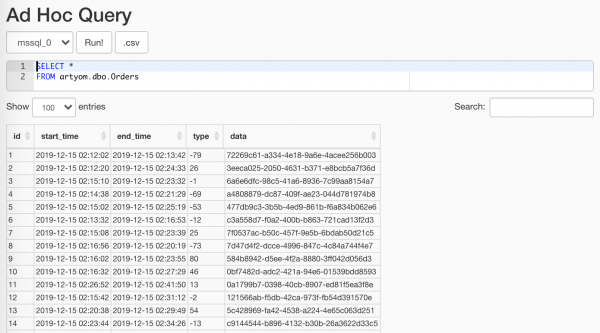
Kryesore, mos e tregoni këtë analistëve
Të ndalemi në detaje seancat ETL nuk do ta bëj, aty është gjithçka e thjeshtë: krijojmë një bazë, në të një tabelë, e mbështjellim gjithçka me menaxherin e kontekstit, dhe tani veprojmë kështu:
with Session(task_name) as session:
print('Load', session.id, 'started')
# Load worflow
...
session.successful = True
session.loaded_rows = 15session.py
nga sys import stderr
klasa Session:
"""Seanca e punës ETL
Example:
me Session(task_name) si sesion:
print(session.id)
session.successful = True
session.loaded_rows = 15
session.comment = 'Mirë
"""
def __init__(self, connection, task_name):
self.connection = connection
self.connection.autocommit = True
self._task_name = task_name
self._id = None
self.loaded_rows = None
self.successful = None
self.comment = None
def __enter__(self):
return self.open()
def __exit__(self, exc_type, exc_val, exc_tb):
if any(exc_type, exc_val, exc_tb):
self.successful = False
self.comment = f'{exc_type}: {exc_val}n{exc_tb}'
print(exc_type, exc_val, exc_tb, file=stderr)
self.close()
def __repr__(self):
return (f'')
@property
def task_name(self):
return self._task_name
@property
def id(self):
return self._id
def _execute(self, query, *args):
with self.connection.cursor() as cursor:
cursor.execute(query, args)
return cursor.fetchone()[0]
def _create(self):
query = """
KRIJO TABELË NËSE NUK EKZISTON sessions (
id SERIAL NUK NËN NORMËS
task_name VARCHAR(200) NUK NËN NORMËS,
started TIMESTAMPTZ NUK NËN NORMËS DEFAULT current_timestamp,
finished TIMESTAMPTZ DEFAULT current_timestamp,
successful BOOL,
loaded_rows INT,
comment VARCHAR(500)
);
"""
self._execute(query)
def open(self):
query = """
SHTO NË sessions (task_name, finished)
VLERAT (%s, NULL)
KTHIM id;
"""
self._id = self._execute(query, self.task_name)
print(self, 'hapur')
return self
def close(self):
if not self._id:
raise SessionClosedError('Seanca nuk është e hapur')
query = """
PËRMIKSO sessions
SET
finished = DEFAULT,
successful = %s,
loaded_rows = %s,
comment = %s
KU
id = %s
KTHIM id;
"""
self._execute(query, self.successful, self.loaded_rows,
self.comment, self.id)
print(self, 'mbyllur',
', e suksesshme: ', self.successful,
', Ngarkuar: ', self.loaded_rows,
', komenti:', self.comment)
klasa SessionError(Exception):
kalon
klasa SessionClosedError(SessionError):
kalonKa ardhur koha të marrim të dhënat tona nga pesëmbëdhjetë tabela tona. Do ta bëjmë këtë me disa rreshta të thjeshtë:
source_conn = MsSqlHook(mssql_conn_id=src_conn_id, schema=src_schema).get_conn()
query = f"""
SELECT
id, start_time, end_time, type, data
FROM dbo.Orders
WHERE
CONVERT(DATE, start_time) = '{dt}'
"""
df = pd.read_sql_query(query, source_conn)- Me anë të hook-ut do marrim nga Airflow
pymssql-konnekt - Në kërkesë do vendosim një kufizim në formën e datës — këtë do ta vendosë shabloni.
- Tërheqim kërkesën tonë
pandas, e cila do të sjellë për neDataFrame— do na nevojitet më vonë.
Unë përdor zëvendësimin
{dt}në vend të parametrave të kërkesës%sjo pse unë jam një Buratino i keq, por sepsepandasnuk mund të përballojë mepymssqldhe i ofron këtij të funditparams: List, ndonëse ai shumë dëshirontuple.
Gjithashtu, vini re se zhvilluesipymssqlvendosi të mos e mbështesë më, dhe është koha të kalojmë nëpyodbc.
Le të shohim çfarë i shtoi Airflow argumenteve tona:
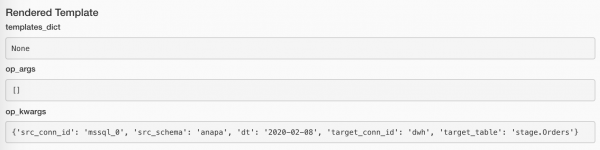
Nëse nuk ka të dhëna, nuk ka kuptim të vazhdojmë. Por gjithashtu është çuditshëm të quhet ngarkimi i suksesshëm. Po ashtu, nuk është një gabim. Ah, çfarë të bëjmë?! Ja çfarë:
if df.empty:
raise AirflowSkipException('Nuk ka rreshta për të ngarkuar')AirflowSkipException do të thotë Airflow se nuk ka gabime, por ne do ta kalojmë detyrën. Në ndërfaqe do të ketë një katror që nuk është gjelber dhe as i kuq, por me ngjyrë rozë.
Do t'i hedhim të dhënat tona për disa kolona:
df['etl_source'] = src_schema
df['etl_id'] = session.id
df['hash_id'] = hash_pandas_object(df[['etl_source', 'id']])Specifikisht:
- DB, nga e cila kemi marrë porositë,
- Identifikuesi i sesionit tonë të ngarkimit (do të jetë i ndryshëm për secilën detyrë),
- Hash nga burimi dhe identifikuesi i porosisë — që në bazën përfundimtare (ku gjithçka do të bashkohet në një tabelë) të kemi një identifikues unik për porosinë.
Ka mbetur hapi i parafundit: të ngarkohet gjithçka në Vertica. Dhe, siç është e çuditshme, një nga mënyrat më efektive për ta bërë këtë është përmes CSV!
# Export data to CSV buffer
buffer = StringIO()
df.to_csv(buffer,
index=False, sep='|', na_rep='NUL', quoting=csv.QUOTE_MINIMAL,
header=False, float_format='%.8f', doublequote=False, escapechar='\')
buffer.seek(0)
# Push CSV
target_conn = VerticaHook(vertica_conn_id=target_conn_id).get_conn()
copy_stmt = f"""
COPY {target_table}({df.columns.to_list()})
FROM STDIN
DELIMITER '|'
ENCLOSED '"'
ABORT ON ERROR
NULL 'NUL'
"""
cursor = target_conn.cursor()
cursor.copy(copy_stmt, buffer)- Ne bëjmë një marrëveshje speciale
StringIO. pandasdo të përfshijë në tëDataFramenë formën erreshtat CSV.Do të hapim një lidhje me Vertica-n tonë të dashur.- Dhe tani me ndihmën e
- copy()
do t'i dërgojmë të dhënat tona direkt në Vertica!do t'i dërgojmë të dhënat tona direkt në Vertica!
Do të marrim nga driver-i sa rreshta janë ngarkuar, dhe do t'i themi menaxherit të sesionit që gjithçka është OK:
session.loaded_rows = cursor.rowcount
session.successful = TrueKëtu është gjithçka.
Në prodhim krijojmë tabelën e synuar manualisht. Këtu le të lejoj vetes një automatizëm të vogël:
create_schema_query = f'CREATE SCHEMA IF NOT EXISTS {target_schema};'
create_table_query = f"""
CREATE TABLE IF NOT EXISTS {target_schema}.{target_table} (
id INT,
start_time TIMESTAMP,
end_time TIMESTAMP,
type INT,
data VARCHAR(32),
etl_source VARCHAR(200),
etl_id INT,
hash_id INT PRIMARY KEY
);"""
create_table = VerticaOperator(
task_id='create_target',
sql=[create_schema_query,
create_table_query],
vertica_conn_id=target_conn_id,
task_concurrency=1,
dag=dag)Unë me ndihmën e
VerticaOperator()krijoj skemën e DB-së dhe tabelën (nëse ato nuk ekzistojnë, sigurisht). E rëndësishme është të vendosësh drejt varësitë:
për conn_id, schema në sql_server_ds:
load = PythonOperator(
task_id=schema,
python_callable=workflow,
op_kwargs={
'src_conn_id': conn_id,
'src_schema': schema,
'dt': '{{ ds }}',
'target_conn_id': target_conn_id,
'target_table': f'{target_schema}.{target_table}'},
dag=dag)
create_table >> loadPërmbledhje
— Ja, — tha minusi, — a nuk është e vërtetë se tani
Ti e ke kuptuar që ndodhem unë si kafsha më e tmerrshme në pyll?
Julia Donaldson, «Gruffalo»
Mendoj se po të organizonim një garë mes kolegëve të mi: kush e përgatit dhe e nis më shpejt ETL-procesin nga fillimi: ata me SSIS dhe miniku, dhe unë me Airflow… Pastaj do të krahasonim edhe lehtësinë e mirëmbajtjes… Ehm, mendoj se do të pajtohesh se do t'i kaloj në çdo front!
Nëse flasim pak më seriozisht, atëherë Apache Airflow — përmes përshkrimit të proceseve në formën e kodit programues — e bëri punën time shumë më më të lehtë dhe më të këndshme.
Po ashtu, shkallëzueshmëria e tij e pakufizuar: si në aspektin e plugins, ashtu edhe prirja për të shkallëzuar — ju jep mundësinë të përdorni Airflow në pothuajse çdo fushë: qoftë në ciklin e plotë të mbledhjes, përgatitjes dhe përpunimit të të dhënave, qoftë në raketat që lëshohen (në Mars, sigurisht).
Pjesa përfundimtare, informative dhe reference
Gabimet që i kemi mbledhur për ju
start_date. Po, kjo është një meme lokale. Përmes argumentit kryesor të DAG-utstart_datekalojnë të gjitha. Shkurtimisht, nëse caktojmë nëstart_datedatën aktuale, dhe nëschedule_interval— një ditë, atëherë DAG-u do të nisë nesër, më herët se.start_date = datetime(2020, 7, 7, 0, 1, 2)Dhe më shumë asnjë problem.
Me të lidhet dhe një tjetër gabim në ekzekutim:
Task is missing the start_date parameter, që zakonisht tregon se e keni harruar të lidhni me operatorin e DAG-ut.- Të gjitha në një makinë. Po, si bazat (e vetë Airflow dhe mbulesës sonë), ashtu edhe serveri web, planifikuesi dhe punëtorët. Dhe madje punonte. Por me kalimin e kohës numri i detyrave në shërbime u rrit, dhe kur PostgreSQL filloi të jepte përgjigje nëpërmjet indekseve për 20 ms në vend të 5 ms, ne e morëm dhe e trezoruam.
- LocalExecutor. Po, ne kemi qenë ende në të, dhe tashmë kemi arritur në skajin e greminës. LocalExecutor ka qenë i mjaftueshëm për ne deri tani, por tani ka ardhur koha për të zgjeruar me të paktën një punëtor, dhe do të duhet të mundohemi të kalojmë në CeleryExecutor. Dhe duke marrë parasysh se mund të punosh me të edhe në një makinë, asgjë nuk na ndalon nga përdorimi i Celery edhe në serverin që "natyrisht, kurrë nuk do të shkojë në prodhim, të premtoj!"
- Përdorim i papërfshirë mjetet e ndërtuara:
- Connections për ruajtjen e të dhënave të identifikimit të shërbimeve,
- SLA Misses për të reaguar ndaj detyrave që nuk përfunduan në kohë,
- XCom për ndarjen e metadatat (thashë metatë dhënat!) midis detyrave të dagut.
- Abuzimi me postën. Çfarë të thuash këtu? Ishin krijuar njoftime për të gjitha përsëritjet e detyrave të rëna. Tani në Gmail-in tim të punës kam >90k letra nga Airflow, dhe ndërfaqja web e postës refuzon të marrë dhe të fshijë më shumë se 100 njësi për herë.
Më shumë pengesa:
Mjetet për automatizim më të madh
Për të punuar edhe më shumë me mendje dhe jo me duar, Airflow na përgatiti këtë:
- — ai ende ka status Experimental, që nuk e pengon të funksionojë. Me këtë, jo vetëm që mund të merrni informacion mbi dagat dhe detyrat, por mund të ndaloni/nisni dagun, të krijoni DAG Run ose grup.
- — përmes komandës në terminal janë të ndAvailable shumë mjete, të cilat jo vetëm që janë të pakëndshme për t'u përdorur përmes WebUI, por edhe nuk ekzistojnë fare. Për shembull:
backfillnevojiten për të rinisur instancat e detyrave.
Për shembull, vijnë analistët dhe thonë: «E keni, shoku, problem me të dhënat nga 1 deri më 13 janar! Rregulloni!». Dhe ti je si:airflow backfill -s '2020-01-01' -e '2020-01-13' orders- Mirëmbajtja e bazës:
initdb,resetdb,upgradedb,checkdb. run, i cili lejon të nisni një instancë të detyrës dhe t'i injoroni të gjitha varësitë. Për më tepër, mund ta nisni atë përmesLocalExecutor, madje edhe sikur të keni një klaster Celery.- Përgjithësisht, e njëjta gjë bënë
test, vetëm se nuk shkruan asgjë në bazë. connectionslejon krijimin masiv të lidhjeve nga shell.
- — një mënyrë mjaft hardcore për të bashkëvepruar, e cila është e destinuar për plugina, dhe jo për të grumbulluar me duar. Por kush na ndalon të shkojmë në
/home/airflow/dags, të nxjerrimipythondhe të fillojmë të bëjmë çfarë deshi? Mund, për shembull, të eksportoni të gjitha lidhjet me këtë kod:nga airflow import settings nga airflow.models import Connection fushat = 'conn_id conn_type host port schema login password extra'.split() session = settings.Session() per conn në session.query(Connection).order_by(Connection.conn_id): d = {field: getattr(conn, field) për fushat} print(conn.conn_id, '=', d) - Lidhja me bazën e të dhënave të metadatas Airflow. Nuk e rekomandoj të shkruani në të, por merrni statet e detyrave për metrika të ndryshme specifike shumë më shpejt dhe më lehtë se përmes ndonjë API.
Të themi, jo të gjitha detyrat tona janë idempotente, dhe ndonjëherë ato mund të dështojnë, dhe kjo është e pranueshme. Por disa dështime — kjo është tashmë e dyshimtë, dhe duhet të verifikohet.
Kujdes, SQL!
ME ekzekutimet e fundit SI ( SELECT task_id, dag_id, execution_date, state, row_number() PËR ( PARTITION BY task_id, dag_id ORDER BY execution_date DESC) SI rn FROM public.task_instance WHERE execution_date > now() - INTERVAL '2' DITË ), failed AS ( SELECT task_id, dag_id, execution_date, state, RAST CASE kur rn = row_number() PËR ( PARTITION BY task_id, dag_id ORDER BY execution_date DESC) THEN TRUE END SI last_fail_seq FROM last_executions WHERE state IN ('dështuar', 'në pritje për rikthim') ) SELECT task_id, dag_id, count(last_fail_seq) SI të pasuksesshëm, count(CASE KUR last_fail_seq DHE state = 'dështuar' ATËHERË 1 END) SI dështuar, count(CASE KUR last_fail_seq DHE state = 'në pritje për rikthim' ATËHERË 1 END) SI në pritje për rikthim FROM failed GRUPI PËR task_id, dag_id KUSH count(last_fail_seq) > 0
Linke
Natyrisht, dhjetë lidhjet e para nga rezultatet e Google përmbajnë dosjen e Airflow nga shënimet e mia.
- — natyrisht, duhet të filloni me dokumentacionin zyrtar, por kush i lexon udhëzimet?
- — të paktën lexoni rekomandimet nga krijuesit.
- — fillimi: ndërfaqja përdoruese në figura.
- — janë mirëshpjeguara bazat, nëse (rastësisht!) nuk e keni kuptuar diçka nga unë.
- — një udhëzues i shkurtër për konfigurimin e klasterit Airflow.
- — një artikel thuajse po aq interesant, përveç se ka më shumë formalizëm dhe më pak shembuj.
- — për funksionimin në bashkëpunim me Celery.
- — mbi idempotencën e detyrave, ngarkimin sipas ID-së në vend të datës, transformimet, strukturën e skedarëve dhe gjëra të tjera interesante.
- — varësitë e detyrave dhe Rregulli i Aktivizimit, të cilat i përmenda vetëm sipas rastit.
- — si të kaloni disa nga "punon siç është parashikuar" në planifikues, të ngarkoni të dhënat e humbura dhe të vendosni prioritetet e detyrave.
- — SQL pyetjet e dobishme për metadaten e Airflow.
- — ka një seksion të dobishëm për krijimin e sensorëve personalizues.
- — një shënim interesant mbi ndërtimin e infrastrukturës në AWS për Shkencën e të Dhënave.
- — gabime të zakonshme (kur dikush gjithsesi nuk lexon udhëzimet).
- — buzëqeshni, si njerëzit rregullojnë ruajtjen e fjalëkalimeve, kur mund të përdorin thjesht Connections.
- — kalimi i paqartë i DAG, kalimi i kontekstit në funksione, sërish për varësitë, dhe gjithashtu për humbjen e nisjeve të detyrave.
- — mbi përdorimin e
argumenteve standardedheparamsnë shabllonat, si dhe për Variables dhe Connections. - — një tregim mbi atë se si përgatitet planifikuesi për Airflow 2.0.
- — një artikull disi i vjetër mbi implementimin e grupit tonë në
docker-compose. - — detyra dinamike përmes shablloneve dhe kalimit të kontekstit.
- — njoftime standarde dhe të personalizuara përmes postës elektronike dhe Slack.
- — Degëtim i detyrave, makros dhe XCom.
Dhe lidhjet e përdorura në artikull:
- — plëhsitë që mund të përdoren në shabllon.
- — Gabime të zakonshme gjatë krijimit të DAG-ve.
- —
docker-composepër eksperimente, debuggim dhe më shumë. - — Mbështjellësi Python për Telegram REST API.
Burimi: habr.com
