


Më quajnë Denis Rojkov, unë jam drejtor i zhvillimit të software-it në kompaninë «Gazinformservice», në ekipin e produktit . Legjislacioni dhe normat e korporatave vendosin kërkesa të caktuara për sigurinë e ruajtjes së të dhënave. Askush nuk dëshiron që palë të treta të kenë qasje në informacionin konfidencial, prandaj për çdo projekt, pyetje të tilla janë të rëndësishme: identifikimi dhe autentikimi, menaxhimi i qasjes së të dhënave, sigurimi i integritetit të informacionit në sistem, regjistrimi i ngjarjeve të sigurisë. Prandaj, dua të flas për disa momente interesante që lidhen me sigurinë e SGBD.
Artikulli është përgatitur sipas një paraqitjeje në organizuar . Nëse nuk doni të lexoni, mund ta shihni:

Artikulli do të ketë tre pjesë:
- Si të mbrohet lidhjet.
- Çfarë është auditi i veprimeve dhe si të regjistrohet çfarë ndodh nga ana e bazës së të dhënave dhe lidhjes së saj.
- Si të mbrohen të dhënat në vetë bazën e të dhënave dhe cilat teknologji ekzistojnë për këtë.
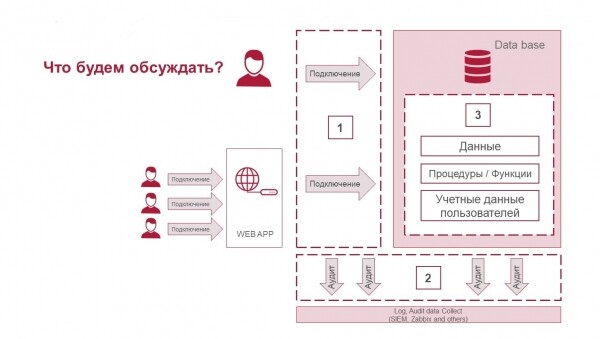
Tre komponentët e sigurisë së SGBD: mbrojtja e lidhjeve, auditi i veprimeve dhe mbrojtja e të dhënave
Mbrojtja e lidhjeve
Lidhja me bazën e të dhënave mund të bëhet si direkt ashtu edhe nëpërmjet aplikacioneve web. Në përgjithësi, përdoruesi nga ana e biznesit, domethënë një njeri që punon me SGBD, ndërvepron me të jo drejtpërdrejt.
Përpara se të flasim për mbrojtjen e lidhjeve, duhet të përgjigjemi në pyetje të rëndësishme, që do të determinojnë se si do të ndërtohen masat e sigurisë:
- a është ekuivalent një përdorues biznesi me një përdorues të SGBD;
- a sigurohet akses në të dhënat e SGBD vetëm përmes API-së, e cila ju kontrolloni, apo ka akses në tabela direkt;
- a është SGBD e ndarë në një segment të veçantë të mbrojtur, kush dhe si ndërvepron me të;
- a përdoret pooling/proxy dhe shtresa ndërmjetëse që mund të ndryshojnë informacionin për mënyrën se si është ndërtuar lidhja dhe kush përdor bazën e të dhënave.
Tani le të shohim se cilat mjete mund të aplikojmë për të mbrojtur lidhjet:
- Përdorni zgjidhje të klasës database firewall. Një shtresë e shtuar mbrojtjeje, të paktën do të rritë transparencën e asaj që ndodh në SGBD, maksimumi — do të mund të sigurosh mbrojtje të shtuar për të dhënat.
- Përdorni politikat e fjalëkalimeve. Zbatimi i tyre varet nga mënyra se si është ndërtuar arhitektura juaj. Në çdo rast, një fjalëkalim në skedarin e konfigurimit të aplikacionit web që lidhet me DBMS është i pamjaftueshëm për mbrojtje. Ekzistojnë një sërë mjetesh DBMS që lejojnë monitorimin e kërkesës për azhurnimin e përdoruesit dhe fjalëkalimit.
Lexoni më shumë rreth funksionaliteteve të vlerësimit të përdoruesve. , gjithashtu mund të mësoni për MS SQL Vulnerability Assessment. .
- Pasuroni kontekstin e sesionit me informacionin e nevojshëm. Nëse sesioni është i paqartë, nuk kuptoni se kush po punon brenda tij në DBMS, mund të shtoni informacion rreth asaj që bën, kush është dhe përse, gjatë operacionit të kryer. Ky informacion mund të shihet në audit.
- Konfiguroni SSL-në, nëse nuk keni ndarje rrjeti ndërmjet DBMS-së dhe përdoruesve të fundit, që nuk është në një VLAN të veçantë. Në këto raste, është domosdoshmërisht të mbroni kanalin ndërmjet konsumatorit dhe vetë DBMS-së. Ekzistojnë mjete mbrojtëse gjithashtu edhe në mes open source.
Si do të ndikojë kjo në performancën e DBMS-së?
Le të shohim shembujt e PostgreSQL, si SSL ndikon në ngarkesën e CPU, rritjen e kohëve dhe zvogëlimin e TPS, a do të harxhohen shumë burime nëse aktivizohet.
Ngarkohet PostgreSQL duke përdorur pgbench — kjo është një program i thjeshtë për të ekzekutuar teste performance. Ai përsërit një sekuencë komandash disa herë, ndoshta në seanca paralele të bazës së të dhënave, dhe më pas llogarit shpejtësinë mesatare të transaksioneve.
Test 1 pa SSL dhe duke përdorur SSL — lidhja vendoset në çdo transaksion:
pgbench.exe --connect -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres sslmode=require
sslrootcert=rootCA.crt sslcert=client.crt sslkey=client.key"ndaj
pgbench.exe --connect -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres"Test 2 pa SSL dhe duke përdorur SSL — të gjitha transaksionet kryhen në një lidhje:
pgbench.exe -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres sslmode=require
sslrootcert=rootCA.crt sslcert=client.crt sslkey=client.key"ndaj
pgbench.exe -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres"Cilësime të tjera:
scaling factor: 1
query mode: simple
number of clients: 10
number of threads: 1
number of transactions per client: 5000
number of transactions actually processed: 50000/50000Rezultatet e testimit:
PA SSL
SSL
Vendoset lidhja në çdo transaksion
mesatarja e vonesës
171.915 ms
187.695 ms
tps duke përfshirë vendosjen e lidhjeve
58.168112
53.278062
tps duke përjashtuar lidhjet e vendosura
64.084546
58.725846
CPU
24%
28%
Të gjitha transaksionet kryhen në një lidhje
mesatarja e vonesës
6.722 ms
6.342 ms
tps përfshirë vendosjen e lidhjeve
1587.657278
1576.792883
tps duke përjashtuar lidhjet e vendosura
1588.380574
1577.694766
CPU
17%
21%
Në ngarkesa të vogla, ndikimi i SSL është i krahasueshëm me gabimin e matjes. Nëse vëllimi i të dhënave të transferuara është shumë i madh, situata mund të jetë ndryshe. Nëse ne vendosim një lidhje për çdo transaksion (kjo ndodh rrallë, zakonisht lidhjet ndahen ndërmjet përdoruesve), keni një numër të madh lidhjesh/çlirimesh, ndikimi mund të jetë pak më i madh. Pra, ka rreziqe për një ulje të performancës, megjithatë, dallimi nuk është aq i madh sa të mos përdoret mbrojtja.
Kujdes — ka një dallim të madh nëse krahasohen modet e funksionimit: brenda një seance punoni ose në të ndryshme. Kjo është e qartë: krijimi i çdo lidhjeje kërkon burime.
Kemi një rast kur lidhëm Zabbix në modin besnik, domethënë nuk e kontrollonim md5, nuk kishte nevojë për autentifikim. Më pas, klienti kërkoi të aktivizohej modi i autentifikimit md5. Kjo shkaktoi një ngarkesë të madhe në CPU, performanca ra. Nisi një kërkim për mundësi optimizimi. Një nga zgjidhjet e mundshme për problemin — të zbatohet një kufizim rrjeti, të krijohen VLAN të veçanta për DBMS, të shtohen konfigurime për të bërë të qartë se kush dhe nga ku lidhet dhe të hiqet autentifikimi. Gjithashtu, mund të optimizohen parametrat e autentifikimit për të ulur kostot gjatë aktivizimit të autentifikimit, por në përgjithësi, përdorimi i metodave të ndryshme të autentifikimit ndikon në performancë dhe duhet të merret parasysh këto faktorë gjatë projektimit të kapaciteteve kompjuterike të serverëve (harduerit) për DBMS.
Përfundimi: në disa zgjidhje, madje edhe nuanca të vogla në autentifikim mund të ndikojnë ndjeshëm në projekt dhe është keq kur kjo kuptohet vetëm gjatë zbatimit në prodhim.
Auditi i veprimeve
Auditi nuk është vetëm për SGBD. Auditi është marrja e informacionit mbi atë që ndodh në segmente të ndryshme. Kjo mund të jetë edhe një firewall database, edhe sistemi operativ mbi të cilin është ndërtuar SGBD.
Në SGBD komerciale të nivelit Enterprise, auditi është i mirë, por në open source — jo gjithmonë. Këtu është çfarë ka në PostgreSQL:
- log default — logimi i ndërtuar;
- ekstensionet: pgaudit — nëse ju mungon logimi standard, mund të përdorni konfigurime të veçanta që zgjidhin disa probleme.
Shtesë për raportin në video:
«Regjistrimi fillestar i operatorëve mund të sigurohet nga një mjet standard i regjistrimit me log_statement = all.
Kjo është e pranueshme për monitorim dhe përdorime të tjera, por nuk siguron nivelin e detajeve që është zakonisht i nevojshëm për auditet.
Nuk mjafton të kesh një listë të të gjitha operacioneve që kryhen me bazën e të dhënave.
Duhet gjithashtu të ketë mundësinë për të gjetur afirmatat specifike që janë të rëndësishme për auditorin.
Mjeti i standardit të regjistrimit tregon atë që kërkoi përdoruesi, ndërsa pgAudit fokusohet në detajet e asaj që ndodhi kur baza e të dhënave kryente kërkesën.
Për shembull, një auditor mund të dëshirojë të sigurojë që një tavolinë specifike të jetë krijuar në një dritare shërbimi të dokumentuar.
Kjo mund të duket si një detyrë e thjeshtë për një audit të bazuar dhe grep, por çfarë nëse ju paraqitet diçka si ky shembull (me qëllim të ndërlikuar):
DO $$
FILLIM
EXECUTE ‘CREATE TABLE import’ || ‘ant_table (id INT)’;
END $$;
Mbajtja e standardit të regjistrit do t'ju japë këtë:
LOG: statement: DO $$
FILLIM
EXECUTE ‘CREATE TABLE import’ || ‘ant_table (id INT)’;
END $$;
Duket se për të gjetur tavolinën e interesit mund të kërkohet disa njohuri për kodin në raste kur tavolinat janë krijuar dinamikisht.
Kjo nuk është ideale, pasi do të ishte e preferueshme të kërkoni thjesht sipas emrit të tavolinës.
Këtu është ku do të jetë e dobishme pgAudit.
Për të njëjtën hyrje ai do të japë këtë dalje në regjistër:
AUDIT: SESSION,33,1,FUNCTION,DO,,,«DO $$
FILLIM
EXECUTE ‘CREATE TABLE import’ || ‘ant_table (id INT)’;
END $$;"
AUDIT: SESSION,33,2,DDL,CREATE TABLE,TABLE,public.important_table,CREATE TABLE important_table (id INT)
Regjistrohet jo vetëm blloku DO, por edhe teksti i plotë CREATE TABLE me llojin e operatorit, llojin e objektit dhe emrin e plotë, duke lehtësuar kërkimin.
Me regjistrimin e operatorëve SELECT dhe DML, pgAudit mund të konfiguroni për të regjistruar një hyrje të veçantë për çdo marrëdhënie që referohet në operator.
Nuk kërkohet një analizë sintaksore për të gjetur të gjithë operatorët që lidhen me një tabelë të caktuar,)».
Si do të ndikojë kjo në performancën e DBMS-së?
Le të kryejmë testime me përfshirjen e auditit të plotë dhe të shohim çfarë do të ndodhë me performancën e PostgreSQL. Do të aktivizojmë maksimalin e regjistrimit të DB sipas të gjitha parametrave.
Nuk bëjmë pothuajse asnjë ndryshim në skedarin e konfigurimit, nga të rëndësishmet — aktivizojmë rejimin debug5 për të marrë maksimumin e informacionit.
postgresql.conf
log_destination = ‘stderr’
logging_collector = on
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 10MB
log_min_messages = debug5
log_min_error_statement = debug5
log_min_duration_statement = 0
debug_print_parse = on
debug_print_rewritten = on
debug_print_plan = on
debug_pretty_print = on
log_checkpoints = on
log_connections = on
log_disconnections = on
log_duration = on
log_hostname = on
log_lock_waits = on
log_replication_commands = on
log_temp_files = 0
log_timezone = ‘Europe/Moscow’
Në SGBD PostgreSQL me parametrat 1 CPU, 2.8 GHz, 2 GB RAM, 40 GB HDD, realizojmë tre teste ngarkese, duke përdorur komandat:
$ pgbench -p 3389 -U postgres -i -s 150 benchmark
$ pgbench -p 3389 -U postgres -c 50 -j 2 -P 60 -T 600 benchmark
$ pgbench -p 3389 -U postgres -c 150 -j 2 -P 60 -T 600 benchmarkRezultatet e testimit:
Pa regjistrim
Me regjistrim
Koha totale e mbushjes së DB
43.74 sek
53.23 sek
RAM
24%
40%
CPU
72%
91%
Testi 1 (50 lidhje)
Numri i transaksioneve për 10 minuta
74169
32445
Transaksione/sek
123
54
Vonesa mesatare
405 ms
925 ms
Testi 2 (150 lidhje të mundshme 100)
Numri i transaksioneve për 10 minuta
81727
31429
Transaksione/sek
136
52
Vonesa mesatare
550 ms
1432 ms
Përmasat
Madhësia e DB
2251 MB
2262 MB
Madhësia e logjeve të DB
0 MB
4587 MB
Në fund: auditimi i plotë nuk është shumë i mirë. Të dhënat e auditimit do të jenë në vëllim si të dhënat në vetë bazën e të dhënave, madje edhe më shumë. Ky vëllim i regjistrimit, i cili gjenerohet në punën me DBMS, është një problem i zakonshëm në prodhim.
Shikojmë parametrat e tjerë:
- Shpejtësia nuk ndryshon shumë: pa regjistrim — 43,74 sek, me regjistrim — 53,23 sek.
- Performanca në RAM dhe CPU do të bjerë, pasi duhen krijuar skedarët me auditimin. Kjo është gjithashtu e dukshme në prodhim.
Me rritjen e numrit të lidhjeve, natyrisht, rezultatet do të përkeqësohen pak.
Në korporata me auditim është akoma më e komplikuar:
- të dhënat janë të shumta;
- auditimi nevojitet jo vetëm përmes syslog në SIEM, por edhe në skedarë: përndryshe nëse ndodhi diçka me syslog, duhet të ketë një skedar afër bazës, ku do të ruhen të dhënat;
- për auditimin nevojitet një raft i veçantë, për të mos rënë në I/O të disqeve, pasi ai zë shumë hapësirë;
- ka raste kur punonjësit e sigurisë kërkojnë mëkatësi, ato kërkojnë identifikim të akredituar.
Kufizimi i aksesit në të dhëna
Le të shohim teknologjitë që përdoren për të mbrojtur të dhënat dhe qasjen në to në sistemet komerciale të menaxhimit të të dhënave dhe open source.
Çfarë mund të përdoret në përgjithësi:
- Kriptimi dhe obfuskimi i procedurave dhe funksioneve (Wrapping) - pra, vegla dhe utilitetet të veçanta që e bëjnë kodin e lexueshëm të papërshkueshëm. Megjithatë, më vonë nuk mund ta ndryshosh ose ta riparosh përsëri. Ky qasje ndonjëherë kërkohet minimalisht në anën e DBMS - logjika e kufizimeve të licencës ose logjika e autorizimit është e koduar saktësisht në nivelin e procedurës dhe funksionit.
- Kufizimi i dukshmërisë së të dhënave sipas rreshtave (RLS) - është kur përdorues të ndryshëm shohin një tabelë, por përbërja e ndryshme e rreshtave në të, do të thotë se dikujt diçka nuk mund t'i tregohet në nivelin e rreshtave.
- Editimi i të dhënave të shfaqura (Masking) - është kur përdoruesit në një kolonë tabelar shohin ose të dhëna, ose vetëm yje, pra për disa përdorues informacioni do të jetë i mbyllur. Teknologjia përcakton se çfarë duhet t'i tregosh çdo përdoruesi duke marrë parasysh nivelin e aksesit.
- Ndara e qasjes Security DBA/Application DBA/DBA — në fakt, kjo lidhet me kufizimin e qasjes në vetë DBMS-në, dmth punonjësit e sigurisë mund të ndahen nga administratorët e database dhe administratorët e aplikacioneve. Në teknologjitë open source ka pak të tilla, ndërsa në DBMS-të komerciale ka mjaftueshëm. Ato janë të nevojshme kur ka shumë përdorues me qasje në vetë serverat.
- Kufizimi i qasjes në skedarë në nivele të sistemit të skedarëve. Mund të jepen të drejta, privilegje qasje në katalogë, në mënyrë që çdo administrator të ketë qasje vetëm në të dhënat e nevojshme.
- Qasja e mandatuar dhe pastrimi i memories — këto teknologji përdoren rrallë.
- Kriptimi end-to-end direkt në DBMS — kjo është kriptimi në anën e klientit me menaxhim të çelsave në anën e serverit.
- Kriptimi i të dhënave. Për shembull, kriptimi kolonash — kur përdorni mekanizmin që kripton një kolonë të veçantë të bazës.
Si ndikon kjo në performancën e DBMS?
Le të shohim një shembull të enkriptimit në kolona në PostgreSQL. Ka një modul pgcrypto, që lejon ruajtjen e fusha të zgjedhura në mënyrë të enkriptuar. Kjo është e dobishme kur vetëm disa të dhëna kanë vlerë. Për të lexuar fushat e enkriptuara, klienti kalon çelësin e dekriptimit, serveri dekriptojnë të dhënat dhe i kthen ato klientit. Pa çelësin, askush nuk mund të bëjë asgjë me të dhënat tuaja.
Le të bëjmë një test me pgcrypto. Do të krijojmë një tabelë me të dhëna të enkriptuara dhe me të dhëna të zakonshme. Më poshtë janë komandat për krijimin e tabelave, në rreshtin e parë është një komandë e dobishme — krijimi i vetë zgjerimit me regjistrimin e DBMS:
CREATE EXTENSION pgcrypto;
CREATE TABLE t1 (id integer, text1 text, text2 text);
CREATE TABLE t2 (id integer, text1 bytea, text2 bytea);
INSERT INTO t1 (id, text1, text2)
VALUES (generate_series(1,10000000), generate_series(1,10000000)::text, generate_series(1,10000000)::text);
INSERT INTO t2 (id, text1, text2) VALUES (
generate_series(1,10000000),
encrypt(cast(generate_series(1,10000000) AS text)::bytea, 'key'::bytea, 'bf'),
encrypt(cast(generate_series(1,10000000) AS text)::bytea, 'key'::bytea, 'bf'));Më pas, do të përpiqemi të marrim të dhëna nga secila tabelë dhe të shohim kohët e ekzekutimit.
Këtu është kërkesa nga tabela pa funksionin e enkriptimit:
psql -c "timing" -c "select * from t1 limit 1000;" "host=192.168.220.129 dbname=taskdb
user=postgres sslmode=disable" > 1.txtKronometri është aktivizuar.
id | teksti1 | teksti2
——+——-+——-
1 | 1 | 1
2 | 2 | 2
3 | 3 | 3
…
997 | 997 | 997
998 | 998 | 998
999 | 999 | 999
1000 | 1000 | 1000
(1000 rreshta)
Koha: 1.386 ms
Mostër nga tabela me funksionin e enkriptimit:
psql -c "timing" -c "select id, decrypt(text1, 'key'::bytea, 'bf'),
decrypt(text2, 'key'::bytea, 'bf') from t2 limit 1000;"
"host=192.168.220.129 dbname=taskdb user=postgres sslmode=disable" > 2.txtKronometri është aktivizuar.
id | dekryptim | dekryptim
——+—————+————
1 | x31 | x31
2 | x32 | x32
3 | x33 | x33
…
999 | x393939 | x393939
1000 | x31303030 | x31303030
(1000 rreshta)
Koha: 50.203 ms
Rezultatet e testimit:
Pa enkriptim
Pgcrypto (dekryptim)
Mostër 1000 rreshta
1.386 ms
50.203 ms
CPU
15%
35%
RAM
+5%
Enkriptimi ka një ndikim të fortë në performancë. Është e dukshme se koha është rritur, pasi operacionet e dekryptimit të të dhënave të enkriptuara (dhe dekryptimi zakonisht është i mbështjellë në logjikën tuaj) kërkojnë burime të konsiderueshme. Kështu, ideja për të enkriptuar të gjitha kolonat që përmbajnë disa të dhëna është e rrezikshme për uljen e performancës.
Megjithatë, enkriptimi nuk është një plumb argjendi që zgjidh të gjitha problemet. Të dhënat e dekryptuara dhe çelësi i dekryptimit gjatë procesit të dekryptimit dhe transmetimit të të dhënave ndodhen në server. Prandaj, çelësat mund të kapen nga ata që kanë qasje të plotë në serverin e bazës së të dhënave, siç janë administratorët e sistemit.
Kur për të gjithë përdoruesit është një çelës për tërë kolonën (edhe nëse jo për të gjithë, por për klientët e një grupi të kufizuar), — kjo nuk është gjithmonë e mirë dhe e saktë. Pikërisht për këtë arsye filluam të bëjmë enkriptim end-to-end, në DBMS po shqyrtojmë opsione për enkriptimin e të dhënave nga klienti dhe serveri, u shfaqën ato të famshme depozita të key-vault - produkte të veçanta që ofrojnë menaxhimin e çelësave në anën e DBMS.

Mjetet e sigurisë në DBMS komerciale dhe open source
Funksionet
Tipo
Politika e Fjalëkalimeve
Auditimi
Mbrojtja e kodit burimor të procedurave dhe funksioneve
RLS
Enkriptimi
Oracle
Komerciale
+
+
+
+
+
MsSql
Komerciale
+
+
+
+
+
Komerciale
+
+
+
+
zgjerimet
PostgreSQL
Falë
zgjerimet
zgjerimet
—
+
zgjerimet
MongoDb
Falë
—
+
—
—
I disponueshëm vetëm në MongoDB Enterprise
Tabela nuk është aspak e plotë, por situata është kështu: në produktet komerciale, detyrat e sigurisë janë zgjidhur prej kohësh, në open source, zakonisht përdoren ndonjë shtesë për sigurinë, shumë funksione mungojnë, ndonjëherë duhet të shtosh diçka vetë. Për shembull, politikat e fjalëkalimeve — në PostgreSQL ka shumë zgjerime të ndryshme (, , , , ), që realizojnë politikat e fjalëkalimeve, por nevojat e sektorit korporativ vendas, sipas mendimit tim, asnjë nuk i mbulon.
Çfarë të bëjmë nëse nuk ka asgjë që na nevojitet? Например, хочется использовать определенную СУБД, в которой нет функций, которые требует заказчик.
Atëherë mund të përdorni zgjidhje të jashtme që punojnë me sisteme të ndryshme DB, si "Kripto BD" ose "Garda BD". Nëse flasim për zgjidhje nga sektori vendas, atje dihet më shumë për standartet GOST se sa në open source.
Varianti i dytë është të shkruani vetë atë që ju nevojitet, të realizoni në nivelin e procedurave aksesin në të dhëna dhe enkriptimin në aplikacion. E vërteta është se me GOST-it do të jetë më e vështirë. Por në përgjithësi, ju mund të fshihni të dhënat siç duhet, t'i ruani në DB dhe pastaj t'i nxirrni dhe t'i dekriptoni siç duhet, direkt në nivelin e aplikacionit. Në të njëjtën kohë, mendoni se si do t'i mbroni këto algoritme në aplikacion. Sipas mendimit tonë, kjo duhet bërë në nivelin e DB, sepse do të funksionojë më shpejt.
Ky raport u shpërnda për herë të parë në nga Mail.ru Cloud Solutions. Shikoniprezantime të tjera dhe abonohuni për njoftimet mbi ngjarjet në Telegram .
Çfarë tjetër të lexoni në këtë temë:
- .
- .
Burimi: habr.com
