

Pra, ju mbledhni metrika. Dhe ne gjithashtu. Ne mbledhim edhe metrika. Sigurisht, ato që janë të rëndësishme për biznesin. Sot do t'ju tregojmë për lidhjen e parë në sistemin tonë të monitorimit - serverin e grumbullimit të pajtueshëm me statsd. , pse e shkruam dhe pse e braktisëm Brubeck-un.
Nga artikujt tanë të mëparshëm (, ) mund të zbuloni se deri pak kohë më parë ne mblidhnim etiketa duke përdorur Është shkruar në C. Është aq i thjeshtë sa një maus (gjë që është e rëndësishme kur doni të kontribuoni) dhe, më e rëndësishmja, trajton vëllimin tonë maksimal prej 2 milionë metrikash për sekondë (MPS) pa asnjë problem. Dokumentacioni pretendon mbështetje për 4 milionë MPS me një yll. Kjo do të thotë që do të merrni shifrën e deklaruar nëse e konfiguroni rrjetin saktë. Linux(Nuk e dimë se sa MPS mund të merrni nëse e lini rrjetin siç është.) Pavarësisht këtyre avantazheve, patëm disa ankesa serioze në lidhje me brubeck-un.
Kërkesa 1. Github, zhvilluesi i projektit, ndaloi së mbështeturi atë: duke publikuar patch-e dhe rregullime, duke pranuar kërkesat tona të klientit (dhe të të tjerëve). Aktiviteti ka rifilluar në muajt e fundit (diku rreth shkurtit-marsit 2018), por para kësaj pati pothuajse dy vjet heshtje të plotë. Për më tepër, projekti është në zhvillim e sipër. , gjë që mund të bëhet një pengesë serioze për zbatimin e veçorive të reja.
Kërkesa 2. Saktësia e llogaritjes. Brubeck mbledh vetëm 65536 vlera për agregim. Në rastin tonë, për disa metrika, periudha e agregimit (30 sekonda) mund të marrë vlera dukshëm më të larta (1,527,392 në kulmin). Si rezultat i kësaj mostrimi, vlerat maksimale dhe minimale duken të padobishme. Për shembull, si kjo:
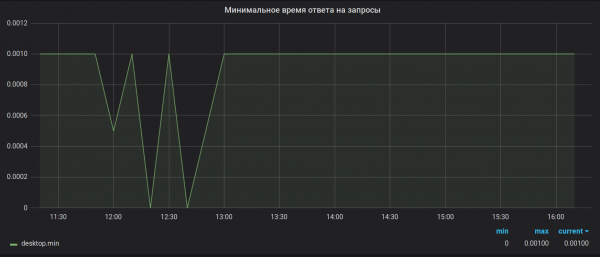
Siç ishte
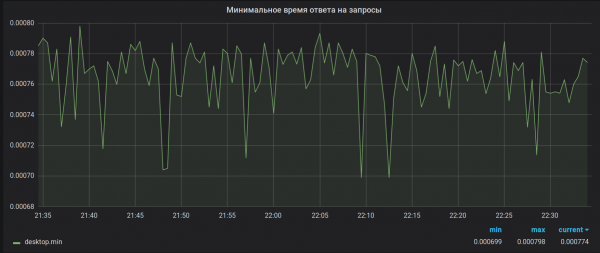
Si duhej të kishte qenë
Për të njëjtën arsye, shumat llogariten gabimisht. Shtojini kësaj një gabim me mbingarkesat e numrave të float-it 32-bit, i cili e dërgon serverin në një gabim segfault kur merr një metrikë në dukje të pafajshme, dhe gjithçka bëhet perfekte. Rastësisht, ky gabim nuk është rregulluar kurrë.
Dhe, së fundi, Kërkesa XNë kohën e shkrimit, jemi gati ta testojmë atë kundrejt të gjitha 14 implementimeve pak a shumë funksionale të statsd që kemi gjetur. Le të imagjinojmë se një infrastrukturë e caktuar është rritur aq shumë saqë gëlltitja e 4 milionë MPS nuk është më e mjaftueshme. Ose, edhe nëse nuk është rritur ende, metrikat janë aq të rëndësishme për ju saqë edhe uljet e shkurtra, 2-3-minutëshe në grafikë mund të bëhen kritike dhe të shkaktojnë periudha depresioni të pakapërcyeshëm tek menaxherët. Meqenëse trajtimi i depresionit është një detyrë e pafalshme, nevojiten zgjidhje teknike.
Së pari, toleranca ndaj defekteve, në mënyrë që një problem i papritur i serverit të mos shkaktojë një apokalips psikiatrik zombi në zyrë. Së dyti, shkallëzueshmëria, në mënyrë që të mund të përballojë mbi 4 milionë MPS pa pasur nevojë të gërmojë thellë në rrjet. Linux dhe rriten me qetësi "në gjerësi" në madhësinë e kërkuar.
Meqenëse kishim pak hapësirë për shkallëzueshmëri, vendosëm të fillonim me tolerancën ndaj gabimeve. "Oh! Tolerancë ndaj gabimeve! Është e thjeshtë, mund ta bëjmë", menduam, dhe lançuam dy servera, duke ekzekutuar një kopje të brubeck në secilin. Për ta bërë këtë, na u desh të kopjonim trafikun me metrika në të dy serverat dhe madje të shkruanim një fragment kodi për të. Ne e zgjidhëm problemin e tolerancës së defekteve në këtë mënyrë, por... jo shumë mirë. Në fillim, gjithçka dukej në rregull: çdo brubeck mbledh versionin e vet të agregimit, shkruan të dhëna në Graphite çdo 30 sekonda, duke mbishkruar intervalin e vjetër (kjo bëhet në anën e Graphite). Nëse një server dështon, ne gjithmonë kemi një të dytë me kopjen e vet të të dhënave të agreguara. Por ja ku qëndron problemi: nëse një server dështon, në grafikë shfaqet një model "sharrim-me-sharrim". Kjo për shkak të faktit se intervalet 30-sekondëshe të brubeck nuk janë të sinkronizuara, dhe kur njëri prej tyre dështon, ai nuk mbishkruan. E njëjta gjë ndodh kur serveri i dytë fillon. Është e tolerueshme, por ne duam më mirë! Problemi i shkallëzueshmërisë gjithashtu mbetet. Të gjitha metrikat ende shkojnë në një server të vetëm, dhe për këtë arsye ne jemi të kufizuar në të njëjtat 2-4 milionë MPS, varësisht nga performanca e rrjetit.
Nëse mendoni pak për problemin ndërsa pastroni borën, një ide e qartë mund t'ju lindë në mendje: ju nevojitet një statsd që mund të funksionojë në modalitetin e shpërndarë. Domethënë, një që zbaton sinkronizimin midis nyjeve sipas kohës dhe metrikave. "Me siguri një zgjidhje e tillë ndoshta ekziston tashmë," thamë ne, dhe shkuam të kërkonim në Google... Dhe nuk gjetëm asgjë. Pasi kërkuam në dokumentacion për statistika të ndryshme ( Që nga 11 dhjetori 2017, nuk gjetëm absolutisht asgjë. Me sa duket, as zhvilluesit dhe as përdoruesit e këtyre zgjidhjeve nuk kanë hasur ndonjëherë KAQ shumë metrika, përndryshe do të kishin gjetur diçka.
Dhe pastaj na u kujtua "lodra" statistikore, bioyino, të cilën e shkruam në hackathonin Just for Fun (emri i projektit u gjenerua nga një skript para hackathonit) dhe kuptuam se na duhej urgjentisht statistikat tona. Pse?
- sepse ka shumë pak klone të statsd në botë,
- sepse është e mundur të ofrohet toleranca e dëshiruar ose afër dëshiruar e gabimeve dhe shkallëzueshmëria (duke përfshirë sinkronizimin e metrikave të agreguara midis serverave dhe zgjidhjen e problemit të konflikteve gjatë dërgimit),
- sepse mund të llogaritni metrikat më saktë sesa Brubeck,
- sepse ne mund të mbledhim vetë statistika më të detajuara, të cilat Brubeck praktikisht nuk na i dha kurrë,
- sepse pata mundësinë të programoja aplikacionin tim në shkallë të shpërndarë me hiperperformancë, i cili nuk do ta përsëriste plotësisht arkitekturën e një tjetër hiperperformance të tillë... epo, e kuptoni.
Në çfarë të shkruaj? Në ndryshk, sigurisht. Pse?
- sepse tashmë ekzistonte një prototip i zgjidhjes,
- sepse autori i artikullit e njihte tashmë Rust-in në atë kohë dhe mezi priste të shkruante diçka në të për prodhim me mundësinë e publikimit të tij si burim të hapur,
- sepse gjuhët me GC nuk janë të përshtatshme për ne për shkak të natyrës së trafikut të marrë (pothuajse në kohë reale) dhe pauzat e GC janë praktikisht të papranueshme,
- sepse na duhet performancë maksimale e krahasueshme me C
- Sepse Rust na jep njëkohësi të patrembur, dhe nëse do të fillonim ta shkruanim në C/C++, do të merrnim edhe më shumë sesa brubeck, dobësi, tejmbushje të buffer-it, kushte race dhe fjalë të tjera të frikshme.
Pati edhe një argument kundër Rust. Kompania nuk kishte përvojë në krijimin e projekteve në Rust dhe ne nuk planifikonim ta përdornim atë në projektin tonë kryesor. Pra, kishte shqetësime serioze se nuk do të funksiononte, por vendosëm ta provonim.
Koha kaloi…
Më në fund, pas disa përpjekjeve të dështuara, versioni i parë funksional ishte gati. Çfarë ndodhi? Ja si dukej.
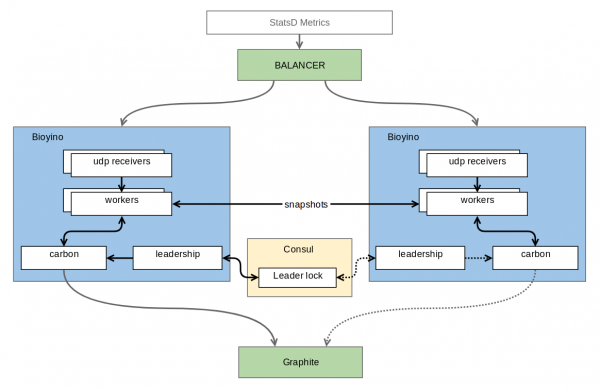
Çdo nyje merr grupin e vet të metrikave dhe i grumbullon ato, por nuk i grumbullon metrikat për ato lloje ku grupi i plotë do të kërkohej për grumbullimin përfundimtar. Nyjet janë të lidhura nëpërmjet një protokolli të kyçjes së shpërndarë, i cili u lejon atyre të zgjedhin atë (e thirrëm këtu) që ia vlen të dërgojë metrika te i Madhi. Ky problem aktualisht po adresohet nga , por në të ardhmen ambiciet e autorit shtrihen deri në Raft, ku nyja udhëheqëse e konsensusit është, sigurisht, më e denja. Përveç konsensusit, nyjet shpesh (si parazgjedhje, një herë në sekondë) u dërgojnë fqinjëve të tyre ato pjesë të metrikave të para-agreguara që kanë arritur të mbledhin gjatë asaj sekonde. Kjo ruan shkallëzueshmërinë dhe tolerancën ndaj gabimeve - çdo nyje ende mirëmban një grup të plotë metrikash, por metrikat dërgohen të agreguara, nëpërmjet TCP dhe të koduara në një protokoll binar, duke ulur ndjeshëm kostot e dublikimit krahasuar me UDP. Pavarësisht numrit relativisht të madh të metrikave hyrëse, akumulimi kërkon shumë pak memorie dhe madje edhe më pak CPU. Për metrikat tona të kompresuara mirë, kjo arrin vetëm në disa dhjetëra megabajt të dhënash. Një bonus shtesë është shmangia e rishkrimeve të panevojshme të të dhënave në Graphite, siç ishte rasti me burbeck.
Paketat UDP me metrika janë të pabalancuara midis nyjeve në pajisjet e rrjetit duke përdorur një round robin të thjeshtë. Natyrisht, hardueri i rrjetit nuk e analizon përmbajtjen e paketës dhe për këtë arsye mund të trajtojë shumë më tepër se 4 milion paketa në sekondë, për të mos përmendur metrikat për të cilat nuk di asgjë. Duke pasur parasysh që metrikat nuk merren individualisht në secilën paketë, ne nuk parashikojmë ndonjë problem të performancës këtu. Nëse një server rrëzohet, pajisja e rrjetit shpejt (brenda 1-2 sekondave) e zbulon këtë dhe e heq serverin e rënë nga rrotullimi. Si rezultat, nyjet pasive (domethënë, jo-udhëheqëse) mund të ndizen dhe fiken praktikisht pa asnjë rënie të dukshme në grafikë. Më së shumti që humbasim janë disa nga metrikat që mbërritën në sekondën e fundit. Një humbje/ndërrim i papritur i udhëheqësit do të krijojë ende një anomali të vogël (intervali 30-sekondësh është ende jashtë sinkronizimit), por nëse ka komunikim midis nyjeve, këto probleme mund të minimizohen, për shembull, duke dërguar paketa sinkronizimi.
Pak rreth pjesëve të brendshme. Aplikacioni është, sigurisht, me shumë fije, por arkitektura e fijeve ndryshon nga ajo e përdorur në brubeck. Fijet në brubeck janë identike - secila është përgjegjëse si për mbledhjen e të dhënave ashtu edhe për agregimin. Në bioyino, fijet e punëtorëve ndahen në dy grupe: ato përgjegjëse për përpunimin e rrjetit dhe ato përgjegjëse për agregimin. Kjo ndarje lejon një menaxhim më fleksibël të aplikacionit në varësi të llojit të metrikave: aty ku kërkohet agregim intensiv, mund të shtohen agregues, ndërsa aty ku ka shumë trafik rrjeti, mund të shtohen më shumë fije rrjeti. Aktualisht, ne operojmë me tetë fije rrjeti dhe katër fije agregimi në serverat tanë.
Pjesa llogaritëse (e grumbullimit) është mjaft e lodhshme. Buferat e mbushura me rrjedha rrjeti shpërndahen midis fijeve llogaritëse, ku më pas analizohen dhe grumbullohen. Me kërkesë, metrikat dërgohen në nyje të tjera. E gjithë kjo, duke përfshirë transferimin e të dhënave midis nyjeve dhe ndërveprimin me Consul, kryhet në mënyrë asinkrone dhe funksionon në kornizë. .
Komponenti i rrjetit përgjegjës për marrjen e metrikave paraqiti shumë më tepër sfida zhvillimi. Qëllimi kryesor i ndarjes së rrjedhave të rrjetit në entitete të ndara ishte zvogëlimi i kohës së shpenzuar për secilën rrjedhë. jo për të lexuar të dhëna nga një socket. Opsionet e përdorimit të UDP asinkron dhe recvmsg të rregullt shpejt u lanë jashtë përdorimit: e para konsumon shumë hapësirë CPU të përdoruesit për përpunimin e ngjarjeve, ndërsa e dyta konsumon shumë çelësa konteksti. Prandaj, qasja aktuale është Me buffer-a të mëdhenj (dhe buffer-at, zotërinj oficerë, nuk janë thjesht çdo gjë!). Mbështetja për UDP-në e rregullt është e rezervuar për rastet me ngarkesë të ulët kur recvmmsg nuk është i nevojshëm. Modaliteti shumëmesazhesh arrin qëllimin kryesor: fija e rrjetit kalon pjesën më të madhe të kohës duke pastruar radhën e sistemit operativ - duke lexuar të dhëna nga soketi dhe duke i transferuar ato në buffer-in e hapësirës së përdoruesit, vetëm herë pas here duke kaluar për t'ia dorëzuar buffer-in e plotë agreguesve. Radha e soketit praktikisht nuk grumbullohet kurrë dhe numri i paketave të humbura mezi rritet.
Shënim
Si parazgjedhje, madhësia e memorjes së përkohshme është vendosur mjaft e madhe. Nëse vendosni ta testoni vetë serverin, mund të zbuloni se pas dërgimit të një numri të vogël metrikash, ato nuk mbërrijnë në Graphite, duke mbetur në memorjen e transmetimit të rrjetit. Për të trajtuar një numër të vogël metrikash, duhet të vendosni vlera më të vogla në skedarët e konfigurimit bufsize dhe task-queue-size.
Më në fund, disa grafikë për dashamirësit e grafikëve.
Statistikat mbi numrin e metrikave hyrëse për secilin server: më shumë se 2 milion MPS.
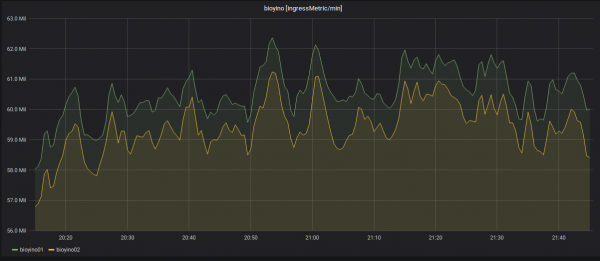
Çaktivizimi i njërës prej nyjeve dhe rishpërndarja e metrikave hyrëse.
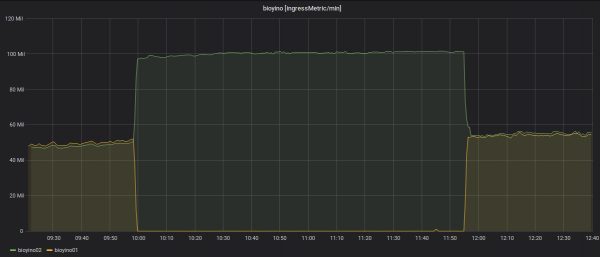
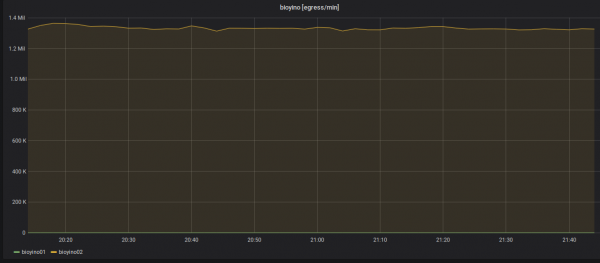
Statistikat mbi metrikat dalëse: vetëm një nyje dërgon ndonjëherë - shefi i bastisjes.
Statistikat e funksionimit të secilës nyje, duke marrë parasysh gabimet në module të ndryshme të sistemit.
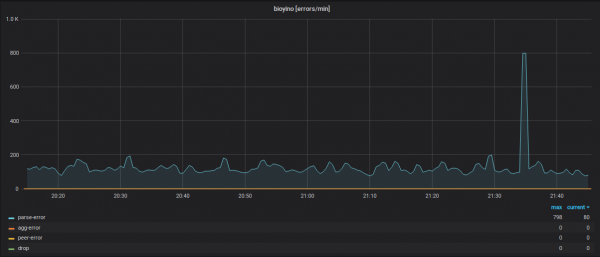
Detajet e metrikave hyrëse (emrat e metrikave janë të fshehura).
Çfarë planifikojmë të bëjmë me të gjitha këto më pas? Të shkruajmë kod të mallkuar, sigurisht! Projekti fillimisht ishte planifikuar si me burim të hapur dhe do të mbetet i tillë për gjithë jetën e tij. Planet tona të menjëhershme përfshijnë kalimin në versionin tonë të Raft, ndryshimin e protokollit të kolegëve në një më të lëvizshëm, shtimin e statistikave të brendshme shtesë, llojeve të reja metrike, rregullimeve të gabimeve dhe përmirësimeve të tjera.
Sigurisht, kushdo që është i gatshëm të ndihmojë në zhvillimin e projektit është i mirëpritur: të krijojë PR, probleme dhe ne do t'u përgjigjemi atyre sa herë që të jetë e mundur, t'i përmirësojmë ato, etj.
Kaq është e gjitha, njerëz, siç thonë, blini elefantët tanë!

Burimi: www.habr.com
