

В начале была технология и называлась она BPF. Мы посмотрели на нее в , ветхозаветной, статье этого цикла. В 2013 году усилиями Алексея Старовойтова (Alexei Starovoitov) и Даниэля Боркмана (Daniel Borkman) была разработана и включена в ядро Linux ее усовершенствованная версия, оптимизированная под современные 64-битные машины. Эта новая технология недолгое время носила название Internal BPF, затем была переименована в Extended BPF, а теперь, по прошествии нескольких лет, все ее называют просто BPF.
Грубо говоря, BPF позволяет запускать произвольный код, предоставляемый пользователем, в пространстве ядра Linux и новая архитектура оказалась настолько удачной, что нам потребуется еще с десяток статей, чтобы описать все ее применения. (Единственное с чем не справились разработчики, как вы можете видеть на кпдв ниже, это с созданием приличного логотипа.)
В этой статье описывается строение виртуальной машины BPF, интерфейсы ядра для работы с BPF, средства разработки, а также краткий, очень краткий, обзор существующих возможностей, т.е. всё то, что нам потребуется в дальнейшем для более глубокого изучения практических применений BPF.
Përmbledhje e shkurtër e artikullit
Вначале мы посмотрим на архитектуру BPF с высоты птичьего полета и обозначим основные компоненты.
Уже имея представление об архитектуре в целом, мы опишем строение виртуальной машины BPF.
В этом разделе мы более пристально посмотрим на жизненный цикл объектов BPF — программ и мапов.
Имея уже некоторое представление о системе мы, наконец, посмотрим на то, как создавать и управлять объектами из пространства пользователя при помощи специального системного вызова — bpf(2).
Писать программы при помощи системного вызова, конечно, можно. Но сложно. Для более реалистичного сценария ядерными программистами была разработана библиотека libbpf. Мы создадим простейший скелет приложения BPF, который мы будем использовать в последующих примерах.
Здесь мы узнаем как программы BPF могут обращаться к функциям-помощникам ядра — инструменту, который, наряду с мапами, принципиально расширяет возможности нового BPF по сравнению с классическим.
К этому моменту мы будем знать достаточно, чтобы понять как именно можно создавать программы, использующие мапы. И даже одним глазком заглянем в великий и могучий verifier.
Справочный раздел о том, как собрать требуемые утилиты и ядро для экспериментов.
В конце статьи те, кто дотуда дочитает, найдут мотивирующие слова и краткое описание того, что будет в следующих статьях. Мы также перечислим некоторое количество ссылок для самостоятельного изучения для тех, у кого нет желания или возможности ждать продолжения.
Введение в архитектуру BPF
Перед тем как начать рассматривать архитектуру BPF мы в последний раз (ой ли) сошлемся на , который был разработан как ответ на появление RISC машин и решал проблему эффективной фильтрации пакетов. Архитектура получилась настолько удачной, что, родившись в лихие девяностые в Berkeley UNIX, она была портирована на большинство существующих операционных систем, дожила до безумных двадцатых и до сих пор находит новые применения.
Новый BPF был разработан как ответ на повсеместное распространение 64-битных машин, облачных сервисов и возросших потребностей в инструментах для создания SDN (Software-defined networking). Разработанный сетевыми инженерами ядра как усовершенствованная замена классического BPF, новый BPF буквально через полгода нашел применения в нелегком деле трассировки Linux систем, а сейчас, через шесть лет после появления, нам потребуется целая, следующая, статья только для того, чтобы перечислить разные типы программ.
ВеСёЛыЕ КаРтИнКи
В своей основе BPF — это виртуальная машина-песочница, позволяющая запускать «произвольный» код в пространстве ядра без ущерба для безопасности. Программы BPF создаются в пространстве пользователя, загружаются в ядро и подсоединяются к какому-нибудь источнику событий. Событием может быть, например, доставка пакета на сетевой интерфейс, запуск какой-нибудь функции ядра, и т.п. В случае пакета программе BPF будут доступны данные и метаданные пакета (на чтение и, может, на запись, в зависимости от типа программы), в случае запуска функции ядра — аргументы функции, включая указатели на память ядра, и т.п.
Давайте посмотрим на этот процесс подробнее. Для начала расскажем про первое отличие от классического BPF, программы для которого писались на ассемблере. В новой версии архитектура была дополнена так, что программы стало можно писать на языках высокого уровня, в первую очередь, конечно, на C. Для этого был разработан бакенд для llvm, позволяющий генерировать байт-код для архитектуры BPF.

Архитектура BPF разрабатывалась, в частности, для того, чтобы эффективно выполняться на современных машинах. Для того, чтобы это работало на практике, байт-код BPF, после загрузки в ядро транслируется в нативный код при помощи компонента под названием JIT compiler (Just In Time). Далее, если вы помните, в классическом BPF программа загружалась в ядро и присоединялась к источнику событий атомарно — в контексте одного системного вызова. В новой архитектуре это происходит в два этапа — сначала код загружается в ядро при помощи системного вызова bpf(2), а затем, позднее, при помощи других механизмов, разных в зависимости от типа программы, программа подсоединяется (attaches) к источнику событий.
Тут у читателя может возникнуть вопрос: а что, так можно было? Каким образом гарантируется безопасность выполнения такого кода? Безопасность выполнения гарантируется нам этапом загрузки программ BPF под названием верификатор (по-английски этот этап называется verifier и я дальше буду использовать английское слово):

Verifier — это статический анализатор, который гарантирует, что программа не нарушит нормальный ход работы ядра. Это, кстати, не означает, что программа не может вмешаться в работу системы — программы BPF, в зависимости от типа, могут читать и переписывать участки памяти ядра, возвращаемые значения функций, обрезать, дополнять, переписывать и даже пересылать сетевые пакеты. Verifier гарантирует, что от запуска программы BPF ядро не свалится и что программа, которой по правилам доступны на запись, например, данные исходящего пакета, не сможет переписать память ядра вне пакета. Чуть более подробно мы посмотрим на verifier в соответствующем разделе, после того, как познакомимся со всеми остальными компонентами BPF.
Итак, что мы узнали к этому моменту? Пользователь пишет программу на языке C, загружает ее в ядро при помощи системного вызова bpf(2), где она проходит проверку на verifier и транслируется в нативный байткод. Затем тот же или другой пользователь подсоединяет программу к источнику событий и она начинает выполняться. Разделение загрузки и подсоединения нужно по нескольким причинам. Во-первых, запуск verifier — это относительно дорого и, загружая одну и ту же программу несколько раз, мы тратим компьютерное время впустую. Во-вторых, то, как именно подсоединяется программа, зависит от ее типа и один «универсальный» интерфейс, разработанный год назад может не подойти для новых типов программ. (Хотя сейчас, когда архитектура становится более зрелой, есть идея унифицировать этот интерфейс на уровне libbpf.)
Внимательный читатель может заметить, что мы еще не закончили с картинками. И правда, все сказанное выше не объясняет, чем BPF принципиально меняет картину по сравнению с классическим BPF. Два новшества, которые существенно расширяют границы применимости — это наличие возможности использовать разделяемую память и функции-помощники ядра (kernel helpers). В BPF разделяемая память реализована при помощи так называемых maps — разделяемых структур данных с определенным API. Такое название они получили, наверное, потому, что первым появившимся типом map была хэш-таблица. Дальше появились массивы, локальные (per-CPU) хэш-таблицы и локальные массивы, деревья поиска, мапы, содержащие указатели на программы BPF и многое другое. Нам сейчас интересен тот факт, что программы BPF получили возможность сохранять состояние между вызовами и разделять его с другими программами и с пространством пользователя.
Доступ к maps осуществляется из пользовательских процессов при помощи системного вызова bpf(2), а из программ BPF, работающих в ядре — при помощи функций-помощников. Более того, helpers существуют не только для работы с мапами, но и для доступа к другим возможностям ядра. Например, программы BPF могут использовать функции-помощники для перенаправления пакетов на другие интерфейсы, для генерации событий подсистемы perf, доступа к структурам ядра и т.п.

Итого, BPF предоставляет возможность загружать произвольный, т.е., прошедший проверку на verifier, код пользователя в пространство ядра. Этот код может сохранять состояние между вызовами и обмениваться данными с пространством пользователя, а также имеет доступ к разрешенным данному типу программ подсистемам ядра.
Это уже похоже на возможности, предоставляемые модулями ядра, по сравнению с которыми у BPF есть некоторые преимущества (конечно, сравнивать можно только похожие приложения, например, трассировку системы — на BPF нельзя написать произвольный драйвер). Можно отметить более низкий порог входа (некоторые утилиты, использующие BPF не предполагают у пользователя наличие навыков программирования ядра, да и вообще навыков программирования), безопасность времени выполнения (поднимите руку в комментариях те, кто не ломал систему при написании или тестировании модулей), атомарность — при перезагрузке модулей есть время простоя, а подсистема BPF гарантирует, что ни одно событие не будет пропущено (справедливости ради, это верно не для всех типов программ BPF).
Наличие таких возможностей и делает BPF универсальным инструментом для расширения ядра, что подтверждается на практике: все новые и новые типы программ добавляются в BPF, все больше крупных компаний используют BPF на боевых серверах 24×7, все больше стартапов строят свой бизнес на решениях, в основе которых лежит BPF. BPF используется везде: в защите от DDoS атак, создании SDN (например, реализации сетей для kubernetes), в качестве основного инструмента трассировки систем и сборщика статистики, в системах обнаружения вторжения и в системах-песочницах и т.п.
Давайте на этом закончим обзорную часть статьи и посмотрим на виртуальную машину и на экосистему BPF более подробно.
Отступление: утилиты
Для того, чтобы иметь возможность запускать примеры из последующих разделов, вам может потребоваться некоторое количество утилит, минимум llvm/clang с поддержкой bpf и bpftool. Në seksionin можно прочитать инструкции по сборке утилит, а также своего ядра. Этот раздел помещен ниже, чтобы не нарушать стройность нашего изложения.
Регистры и система команд виртуальной машины BPF
Архитектура и система команд BPF разрабатывалась с учетом того, что программы будут писаться на языке C и после загрузки в ядро транслироваться в нативный код. Поэтому количество регистров и множество команд выбиралось с оглядкой на пересечение, в математическом смысле, возможностей современных машин. Кроме этого, на программы налагались разного рода ограничения, например, до недавнего времени не было возможности писать циклы и подпрограммы, а количество инструкций было ограничено 4096 (сейчас привилегированным программам можно загружать до миллиона инструкций).
В BPF имеется одиннадцать доступных пользователю 64-битных регистров r0—r10 и счётчик команд (program counter). Регистр r10 содержит указатель на стек (frame pointer) и доступен только для чтения. Программам во время выполнения доступен стек в 512 байт и неограниченное количество разделяемой памяти в виде maps.
Программам BPF разрешается запускать определенный в зависимости от типа программы набор функций-помощников (kernel helpers) и, с недавних пор, и обычные функции. Каждая вызываемая функция может принимать до пяти аргументов, передаваемых в регистрах r1—r5, а возвращаемое значение передается в r0. Гарантируется, что после возврата из функции содержание регистров r6—r9 не изменится.
Для эффективной трансляции программ регистры r0—r11 для всех поддерживаемых архитектур однозначно отображаются на настоящие регистры с учетом особенностей ABI текущей архитектуры. Например, для x86_64 регистры r1—r5, использующиеся для передачи параметров функций, отображаются на rdi, rsi, rdx, rcx, r8, которые используются для передачи параметров в функции на x86_64. Например, код слева транслируется в код справа вот так:
1: (b7) r1 = 1 mov $0x1,%rdi
2: (b7) r2 = 2 mov $0x2,%rsi
3: (b7) r3 = 3 mov $0x3,%rdx
4: (b7) r4 = 4 mov $0x4,%rcx
5: (b7) r5 = 5 mov $0x5,%r8
6: (85) call pc+1 callq 0x0000000000001ee8Регистр r0 также используется для возврата результата выполнения программы, а в регистре r1 программе передается указатель на контекст — в зависимости от типа программы это может быть, например, структура (для XDP) или структура (для разных сетевых программ) или структура (для разных типов tracing программ) и т.п.
Итак, у нас был набор регистров, kernel helpers, стек, указатель на контекст и разделяемая память в виде maps. Не то, чтобы всё это было категорически необходимо в поездке, но…
Давайте продолжим описание и расскажем про систему команд для работы с этими объектами. Все () инструкции BPF имеют фиксированный 64-битный размер. Если вы посмотрите на одну инструкцию на 64-битной Big Endian машине, то вы увидите
![]()
Këtu Kodi — это кодировка инструкции, Dst/Src — это кодировки приемника и источника, соответственно, Off — 16-битный знаковый отступ, а Imm — это 32-битное знаковое целое число, используемое в некоторых командах (аналог константы K из cBPF). Кодировка Kodi имеет один из двух видов:
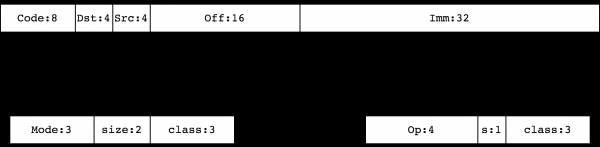
Классы инструкций 0, 1, 2, 3 определяют команды для работы с памятью. Они , BPF_LD, BPF_LDX, BPF_ST, BPF_STX, соответственно. Классы 4, 7 (BPF_ALU, BPF_ALU64) составляют набор ALU инструкций. Классы 5, 6 (BPF_JMP, BPF_JMP32) заключают в себе инструкции перехода.
Дальнейший план изучения системы команд BPF такой: вместо того, чтобы дотошно перечислять все инструкции и их параметры, мы разберем пару примеров в этом разделе и из них станет ясно, как устроены инструкции на самом деле и как вручную дизассемблировать любой бинарный файл для BPF. Для закрепления материала дальше в статье мы еще встретимся с индивидуальными инструкциями в разделах про Verifier, JIT компилятор, трансляцию классического BPF, а также при изучении maps, вызове функций и т.п.
Когда мы будем говорить об индивидуальных инструкциях, мы будем ссылаться на файлы ядра dhe , в которых определяются численные коды инструкций BPF. При самостоятельном изучении архитектуры и/или разборе бинарников, семантику вы можете найти в следующих, отсортированных в порядке сложности, источниках: , , и, конечно, в исходных кодах Linux — verifier, JIT, интерпретатор BPF.
Пример: дизассемблируем BPF в уме
Давайте разберем пример, в котором мы скомпилируем программу readelf-example.c и посмотрим на получившийся бинарник. Мы раскроем оригинальное содержимое readelf-example.c ниже, после того как восстановим его логику из бинарных кодов:
$ clang -target bpf -c readelf-example.c -o readelf-example.o -O2
$ llvm-readelf -x .text readelf-example.o
Hex dump of section '.text':
0x00000000 b7000000 01000000 15010100 00000000 ................
0x00000010 b7000000 02000000 95000000 00000000 ................Первый столбец в выводе readelf — это отступ и наша программа, таким образом, состоит из четырех команд:
Code Dst Src Off Imm
b7 0 0 0000 01000000
15 0 1 0100 00000000
b7 0 0 0000 02000000
95 0 0 0000 00000000Коды команд равны b7, 15, b7 dhe 95. Вспомним, что три младшие бита — это класс инструкции. В нашем случае четвертый бит у всех инструкций пустой, поэтому классы инструкций равны, соответственно, 7, 5, 7, 5. Класс 7 — это BPF_ALU64, а 5 — это BPF_JMP. Для обоих классов формат инструкции одинаковый (см. выше) и мы можем переписать нашу программу так (заодно перепишем остальные столбцы в человеческом виде):
Op S Class Dst Src Off Imm
b 0 ALU64 0 0 0 1
1 0 JMP 0 1 1 0
b 0 ALU64 0 0 0 2
9 0 JMP 0 0 0 0Operacioni b klasës ALU64 — kjo është . Она присваивает значение регистру-приемнику. Если установлен бит s (source), то значение берется из регистра-источника, а если, как в нашем случае, он не установлен, то значение берется из поля Imm. Таким образом, в первой и третьей инструкциях мы выполняем операцию r0 = Imm. Далее, операция 1 класса JMP — это (jump if equal). В нашем случае, так как бит S равен нулю, она сравнивает значение регистра-источника с полем Imm. Если значения совпадают, то переход происходит на PC + Off, ku PC, как водится, содержит адрес следующей инструкции. Наконец, операция 9 класса JMP — это . Эта инструкция завершает работу программы, возвращая ядру r0. Добавим новый столбец к нашей таблице:
Op S Class Dst Src Off Imm Disassm
MOV 0 ALU64 0 0 0 1 r0 = 1
JEQ 0 JMP 0 1 1 0 if (r1 == 0) goto pc+1
MOV 0 ALU64 0 0 0 2 r0 = 2
EXIT 0 JMP 0 0 0 0 exitМы можем переписать это в более удобном виде:
r0 = 1
if (r1 == 0) goto END
r0 = 2
END:
exitЕсли мы вспомним, что в регистре r1 программе передается указатель на контекст от ядра, а в регистре r0 в ядро возвращается значение, то мы можем увидеть, что если указатель на контекст равен нулю, то мы возвращаем 1, а в противном случае — 2. Проверим, что мы правы, посмотрев на исходник:
$ cat readelf-example.c
int foo(void *ctx)
{
return ctx ? 2 : 1;
}Да, это бессмысленная программа, но зато она транслируется всего в четыре простых инструкции.
Пример-исключение: 16-байтная инструкция
Ранее мы упомянули, что некоторые инструкции занимают больше, чем 64 бита. Это относится, например, к инструкции lddw (Code = 0x18 = | | ) — загрузить в регистр двойное слово из полей Imm. Дело в том, что Imm имеет размер 32, а двойное слово — 64 бита, поэтому загрузить в регистр 64-битное непосредственное значение в одной 64-битной инструкции не получится. Для этого две соседние инструкции используются для хранения второй части 64-битного значения в поле Imm. Shembull:
$ cat x64.c
long foo(void *ctx)
{
return 0x11223344aabbccdd;
}
$ clang -target bpf -c x64.c -o x64.o -O2
$ llvm-readelf -x .text x64.o
Hex dump of section '.text':
0x00000000 18000000 ddccbbaa 00000000 44332211 ............D3".
0x00000010 95000000 00000000 ........В бинарной программе всего две инструкции:
Binary Disassm
18000000 ddccbbaa 00000000 44332211 r0 = Imm[0]|Imm[1]
95000000 00000000 exitМы еще встретимся с инструкцией lddw, когда поговорим о релокациях и работе с maps.
Пример: дизассемблируем BPF стандартными средствами
Итак, мы научились читать бинарные коды BPF и готовы разобрать любую инструкцию, если потребуется. Однако, стоит сказать, что на практике удобнее и быстрее дизассемблировать программы при помощи стандартных средств, например:
$ llvm-objdump -d x64.o
Disassembly of section .text:
0000000000000000 <foo>:
0: 18 00 00 00 dd cc bb aa 00 00 00 00 44 33 22 11 r0 = 1234605617868164317 ll
2: 95 00 00 00 00 00 00 00 exitЖизненный цикл объектов BPF, файловая система bpffs
(Некоторые подробности, описываемые в этом подразделе, я впервые узнал из Alexei Starovoitov в .)
Объекты BPF — программы и мапы — создаются из пространства пользователя при помощи команд BPF_PROG_LOAD dhe BPF_MAP_CREATE системного вызова bpf(2), мы поговорим про то как именно это происходит в следующем разделе. При этом создаются структуры данных ядра и для каждой из них refcount (счетчик ссылок) устанавливается равным единице, а пользователю возвращается файловый дескриптор, указывающий на объект. После закрытия дескриптора refcount объекта уменьшается на единицу, и при достижении им нуля объект уничтожается.
Если программа использует мапы, то refcount этих мапов увеличивается на единицу после загрузки программы, т.е. их файловые дескрипторы можно закрыть из пользовательского процесса и при этом refcount не станет нулем:
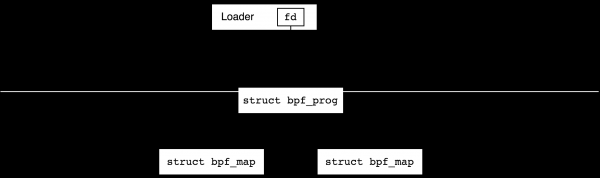
После успешной загрузки программы мы обычно присоединяем ее к какому-нибудь генератору событий. Например, мы можем посадить ее на сетевой интерфейс для обработки входящих пакетов или подключить ее к какой-нибудь tracepoint в ядре. В этот момент счетчик ссылок тоже увеличится на единицу и мы сможем закрыть файловый дескриптор в программе-загрузчике.
Что случится если мы теперь завершим работу загрузчика? Это зависит от типа генератора событий (hook). Все сетевые хуки будут существовать после завершения загрузчика, это, так называемые, глобальные хуки. А, например, программы трассировки будут освобождены после завершения процесса, создавшего их (и поэтому называются локальными, от «local to the process»). Технически, локальные хуки всегда имеют соответствующий файловый дескриптор в пространстве пользователя и поэтому закрываются с закрытием процесса, а глобальные — нет. На следующем рисунке я при помощи красных крестиков стараюсь показать как завершение программы-загрузчика влияет на время жизни объектов в случае локальных и глобальных хуков.
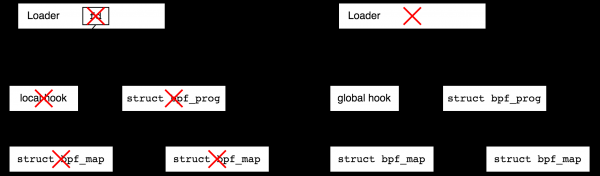
Зачем существует разделение на локальные и глобальные хуки? Запуск некоторых типов сетевых программ имеет смысл и без userspace, например, представьте защиту от DDoS — загрузчик прописывает правила и подключает BPF программу к сетевому интерфейсу, после чего загрузчик может пойти и убиться. С другой стороны, представьте себе отладочную программу трассировки, которую вы написали на коленке за десять минут — после ее завершения вам бы хотелось, чтобы в системе не оставалось мусора, и локальные хуки это гарантируют.
С другой стороны, представьте, что вы хотите подсоединиться к tracepoint в ядре и собирать статистику в течение многих лет. В этом случае вам бы хотелось завершить пользовательскую часть и возвращаться к статистике время от времени. Такую возможность предоставляет файловая система bpf. Это псевдо-файловая система, существующая только в памяти, которая позволяет создавать файлы, ссылающиеся на объекты BPF и, тем самым, увеличивающие refcount объектов. После этого загрузчик может завершить работу, а созданные им объекты останутся живы.
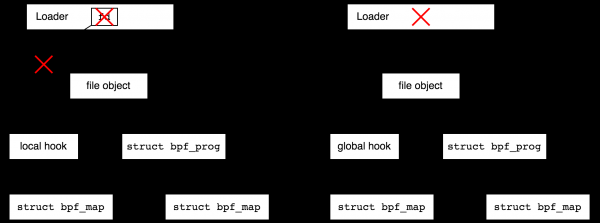
Создание файлов в bpffs, ссылающихся на объекты BPF называется «закрепление» («pin», как в следующей фразе: «process can pin a BPF program or map»). Создание файловых объектов для объектов BPF имеет смысл не только для продления жизни локальных объектов, но и для удобства использования глобальных объектов — возвращаясь к примеру с глобальной программой для защиты от DDoS, мы хотим иметь возможность время от времени приходить и смотреть на статистику.
Файловая система BPF обычно монтируется в /sys/fs/bpf, но ее можно смонтировать и локально, например, так:
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointИмена в файловой системе создаются при помощи команды BPF_OBJ_PIN системного вызова BPF. В качестве иллюстрации давайте возьмем какую-нибудь программу, скомпилируем, загрузим и закрепим ее в bpffs. Наша программа не делает ничего полезного, мы приводим ее код только для того, чтобы вы могли воспроизвести пример:
$ cat test.c
__attribute__((section("xdp"), used))
int test(void *ctx)
{
return 0;
}
char _license[] __attribute__((section("license"), used)) = "GPL";Скомпилируем эту программу и создадим локальную копию файловой системы bpffs:
$ clang -target bpf -c test.c -o test.o
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointТеперь загрузим нашу программу при помощи утилиты bpftool и посмотрим на сопутствующие системные вызовы bpf(2) (из вывода strace удалены некоторые не относящиеся к делу строки):
$ sudo strace -e bpf bpftool prog load ./test.o bpf-mountpoint/test
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="test", ...}, 120) = 3
bpf(BPF_OBJ_PIN, {pathname="bpf-mountpoint/test", bpf_fd=3}, 120) = 0Здесь мы загрузили программу при помощи BPF_PROG_LOAD, получили от ядра файловый дескриптор 3 и при помощи команды BPF_OBJ_PIN закрепили этот файловый дескриптор в виде файла "bpf-mountpoint/test". После этого программа-загрузчик bpftool закончила работу, но наша программа осталась в ядре, хотя мы и не прикрепляли ее ни к какому сетевому интерфейсу:
$ sudo bpftool prog | tail -3
783: xdp name test tag 5c8ba0cf164cb46c gpl
loaded_at 2020-05-05T13:27:08+0000 uid 0
xlated 24B jited 41B memlock 4096BМы можем удалить файловый объект обычным unlink(2) и после этого соответствующая программа будет удалена:
$ sudo rm ./bpf-mountpoint/test
$ sudo bpftool prog show id 783
Error: get by id (783): No such file or directoryУдаление объектов
Говоря об удалении объектов, необходимо уточнить, что после того, как мы отключили программу от хука (генератора событий), ни одно новое событие не повлечет ее запуск, однако, все текущие экземпляры программы будут завершены в нормальном порядке.
Некоторые виды BPF программ позволяют подменять программу на лету, т.е. предоставляют атомарность последовательности replace = detach old program, attach new program. При этом все активные экземпляры старой версии программы закончат свою работу, а новые обработчики событий будут создаваться уже из новой программы, и «атомарность» означает здесь, что ни одно событие не будет пропущено.
Присоединение программ к источникам событий
В этой статье мы не будем отдельно описывать подсоединение программ к источникам событий, так как это имеет смысл изучать в контексте конкретного типа программы. См. ниже, в котором мы показываем как подсоединяются программы типа XDP.
Управление объектами при помощи системного вызова bpf
Программы BPF
Все объекты BPF создаются и управляются из пространства пользователя при помощи системного вызова bpf, имеющего следующий прототип:
#include <linux/bpf.h>
int bpf(int cmd, union bpf_attr *attr, unsigned int size);Здесь команда cmd — это одно из значений типа , attr — указатель на параметры для конкретной программы и size — размер объекта по указателю, т.е. обычно это sizeof(*attr). В ядре 5.8 системный вызов bpf поддерживает 34 различных команды, а union bpf_attr занимает 200 строчек. Но нас не должно это пугать, так как мы будем знакомиться с командами и параметрами на протяжении нескольких статей.
Начнем мы с команды BPF_PROG_LOAD, которая создает программы BPF — берет набор инструкций BPF и загружает его в ядро. В момент загрузки запускается verifier, а потом JIT compiler и, после успешного выполнения, пользователю возвращается файловый дескриптор программы. Мы видели что с ним происходит дальше в предыдущем разделе .
Сейчас мы напишем пользовательскую программу, которая будет загружать простую программу BPF, но сначала нам нужно решить, что именно за программу мы хотим загрузить — нам придется выбрать и в рамках этого типа написать программу, которая пройдет проверку на verifier. Однако, чтобы не усложнять процесс, вот готовое решение: мы возьмем программу типа BPF_PROG_TYPE_XDP, которая будет возвращать значение XDP_PASS (пропустить все пакеты). На ассемблере BPF это выглядит очень просто:
r0 = 2
exitПосле того, как мы определились с тем, çfarë мы будем загружать, мы можем рассказать как мы это сделаем:
#define _GNU_SOURCE
#include <string.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/bpf.h>
static inline __u64 ptr_to_u64(const void *ptr)
{
return (__u64) (unsigned long) ptr;
}
int main(void)
{
struct bpf_insn insns[] = {
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_0,
.imm = XDP_PASS
},
{
.code = BPF_JMP | BPF_EXIT
},
};
union bpf_attr attr = {
.prog_type = BPF_PROG_TYPE_XDP,
.insns = ptr_to_u64(insns),
.insn_cnt = sizeof(insns)/sizeof(insns[0]),
.license = ptr_to_u64("GPL"),
};
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
for ( ;; )
pause();
}Интересные события в программе начинаются с определения массива insns — нашей программы BPF в машинных кодах. При этом каждая инструкция программы BPF упаковывается в структуру . Первый элемент insns соответствует инструкции r0 = 2, tjetri — exit.
Отступление. В ядре определены более удобные макросы для написания машинных кодов, и, используя ядерный заголовочный файл tools/include/linux/filter.h мы могли бы написать
struct bpf_insn insns[] = {
BPF_MOV64_IMM(BPF_REG_0, XDP_PASS),
BPF_EXIT_INSN()
};Но так как написание программ BPF в машинных кодах нужно только для написания тестов в ядре и статей про BPF, отсутствие этих макросов на самом деле не усложняет жизнь разработчика.
После определения программы BPF мы переходим к ее загрузке в ядро. Наш минималистский набор параметров attr включает в себя тип программы, набор и количество инструкций, обязательную лицензию, а также имя "woo", которое мы используем, чтобы найти нашу программу в системе после загрузки. Программа, как и было обещано, загружается в систему при помощи системного вызова bpf.
В конце программы мы попадаем в бесконечный цикл, который имитирует полезную нагрузку. Без него программа будет уничтожена ядром при закрытии файлового дескриптора, который возвратил нам системный вызов bpf, и мы не увидим ее в системе.
Ну что же, мы готовы к тестированию. Соберем и запустим программу под strace, чтобы проверить, что все работает как надо:
$ clang -g -O2 simple-prog.c -o simple-prog
$ sudo strace ./simple-prog
execve("./simple-prog", ["./simple-prog"], 0x7ffc7b553480 /* 13 vars */) = 0
...
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0x7ffe03c4ed50, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_V
ERSION(0, 0, 0), prog_flags=0, prog_name="woo", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS}, 72) = 3
pause(Все в порядке, bpf(2) вернул нам дескриптор 3 и мы отправились в бесконечный цикл с pause(). Давайте попробуем найти нашу программу в системе. Для этого мы пойдем в другой терминал и используем утилиту bpftool:
# bpftool prog | grep -A3 woo
390: xdp name woo tag 3b185187f1855c4c gpl
loaded_at 2020-08-31T24:66:44+0000 uid 0
xlated 16B jited 40B memlock 4096B
pids simple-prog(10381)Мы видим, что в системе имеется загруженная программа woo чей глобальный ID равен 390, и что в данный момент в процессе simple-prog имеется открытый файловый дескриптор, указывающий на программу (и если simple-prog завершит работу, то woo исчезнет). Как и ожидалось, программа woo занимает 16 байт — две инструкции — бинарных кодов в архитектуре BPF, но в нативном виде (x86_64) — это уже 40 байт. Давайте посмотрим на нашу программу в оригинальном виде:
# bpftool prog dump xlated id 390
0: (b7) r0 = 2
1: (95) exitбез сюрпризов. Теперь посмотрим на код, созданный JIT компилятором:
# bpftool prog dump jited id 390
bpf_prog_3b185187f1855c4c_woo:
0: nopl 0x0(%rax,%rax,1)
5: push %rbp
6: mov %rsp,%rbp
9: sub $0x0,%rsp
10: push %rbx
11: push %r13
13: push %r14
15: push %r15
17: pushq $0x0
19: mov $0x2,%eax
1e: pop %rbx
1f: pop %r15
21: pop %r14
23: pop %r13
25: pop %rbx
26: leaveq
27: retqне очень-то эффективно для exit(2), но справедливости ради, наша программа слишком уж проста, а для нетривиальных программ пролог и эпилог, добавленные JIT компилятором, конечно, нужны.
Maps
Программы BPF могут использовать структурированные области памяти, доступные как другим программам BPF, так и программам из пространства пользователя. Эти объекты называются maps и в этом разделе мы покажем как управлять ими при помощи системного вызова bpf.
Сразу скажем, что возможности maps не ограничиваются только доступом к общей памяти. Существуют мапы специального назначения, содержащие, например, указатели на программы BPF или указатели на сетевые интерфейсы, мапы для работы с perf events и т.п. Здесь мы о них говорить не будем, чтобы не путать читателя. Кроме этого, мы игнорируем проблемы синхронизации, так как это не важно для наших примеров. Полный список доступных типов мапов можно найти в , а в этом разделе мы в качестве примера возьмем исторически первый тип, хэш-таблицу BPF_MAP_TYPE_HASH.
Если вы создаете хэш-таблицу, скажем, в C++, вы скажете unordered_map<int,long> woo, что по-русски означает «мне нужна таблица woo неограниченного размера, у которой ключи имеют тип int, а значения — тип long». Для того, чтобы создать хэш-таблицу BPF мы должны сделать примерно то же самое, с поправкой на то, что нам придется указать максимальный размер таблицы, а вместо типов ключей и значений нам нужно указать их размеры в байтах. Для создания мапов используется команда BPF_MAP_CREATE системного вызова bpf. Давайте посмотрим на более-менее минимальную программу, которая создает map. После предыдущей программы, загружающей программы BPF, эта должна вам показаться простой:
$ cat simple-map.c
#define _GNU_SOURCE
#include <string.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/bpf.h>
int main(void)
{
union bpf_attr attr = {
.map_type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 4,
};
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
for ( ;; )
pause();
}Здесь мы определяем набор параметров attr, в котором говорим «мне нужна хэш-таблица с ключами и значениями размера sizeof(int), в которую я могу положить максимум четыре элемента». При создании BPF мапов можно указывать и другие параметры, например, так же, как и в примере с программой, мы указали название объекта как "woo".
Скомпилируем и запустим программу:
$ clang -g -O2 simple-map.c -o simple-map
$ sudo strace ./simple-map
execve("./simple-map", ["./simple-map"], 0x7ffd40a27070 /* 14 vars */) = 0
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=4, max_entries=4, map_name="woo", ...}, 72) = 3
pause(Здесь системный вызов bpf(2) вернул нам дескриптор мапа номер 3 и дальше программа, как и ожидалось, ждет дальнейших указаний в системном вызове pause(2).
Теперь отправим нашу программу в background или откроем другой терминал и посмотрим на наш объект при помощи утилиты bpftool (мы можем отличить наш map от других по его имени):
$ sudo bpftool map
...
114: hash name woo flags 0x0
key 4B value 4B max_entries 4 memlock 4096B
...Число 114 — это глобальный ID нашего объекта. Любая программа в системе может использовать этот ID, чтобы открыть уже существующий map при помощи команды BPF_MAP_GET_FD_BY_ID системного вызова bpf.
Теперь мы можем поиграться с нашей хэш-таблицей. Давайте посмотрим на ее содержимое:
$ sudo bpftool map dump id 114
Found 0 elementsПусто. Давайте положим в нее значение hash[1] = 1:
$ sudo bpftool map update id 114 key 1 0 0 0 value 1 0 0 0Посмотрим на таблицу еще раз:
$ sudo bpftool map dump id 114
key: 01 00 00 00 value: 01 00 00 00
Found 1 elementУра! У нас получилось добавить один элемент. Заметьте, что для этого нам приходится работать на уровне байтов, так как bptftool не знает какой тип имеют значения в хэш-таблице. (Ей можно передать это знание, используя BTF, но об этом не сейчас.)
Как именно bpftool читает и добавляет элементы? Давайте заглянем под капот:
$ sudo strace -e bpf bpftool map dump id 114
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL, next_key=0x55856ab65280}, 120) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0x55856ab65280, value=0x55856ab652a0}, 120) = 0
key: 01 00 00 00 value: 01 00 00 00
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0x55856ab65280, next_key=0x55856ab65280}, 120) = -1 ENOENTСначала мы открыли мап по его глобальному ID при помощи команды BPF_MAP_GET_FD_BY_ID dhe bpf(2) вернул нам дескриптор 3. Дальше при помощи команды BPF_MAP_GET_NEXT_KEY мы нашли первый ключ в таблице, передав NULL в качестве указателя на «предыдущий» ключ. При наличии ключа мы можем сделать BPF_MAP_LOOKUP_ELEM, который возвращает значение в указатель vlera. Следующий шаг — мы пытаемся найти следующий элемент, передавая указатель на текущий ключ, но наша таблица содержит только один элемент и команда BPF_MAP_GET_NEXT_KEY kthen ENOENT.
Хорошо, давайте поменяем значение по ключу 1, скажем, наша бизнес-логика требует прописать hash[1] = 2:
$ sudo strace -e bpf bpftool map update id 114 key 1 0 0 0 value 2 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x55dcd72be260, value=0x55dcd72be280, flags=BPF_ANY}, 120) = 0Как и ожидалось, это очень просто: команда BPF_MAP_GET_FD_BY_ID открывает наш мап по ID, а команда BPF_MAP_UPDATE_ELEM перезаписывает элемент.
Итого, после создания хэш-таблицы из одной программы мы можем читать и писать ее содержимое из другой. Заметьте, что если мы смогли это сделать из командной строки, то это может и любая другая программа в системе. Кроме команд, описанных выше, для работы с мапами из пространства пользователя доступны :
BPF_MAP_LOOKUP_ELEM: найти значение по ключуBPF_MAP_UPDATE_ELEM: обновить/создать значениеBPF_MAP_DELETE_ELEM: удалить ключBPF_MAP_GET_NEXT_KEY: найти следующий (или первый) ключBPF_MAP_GET_NEXT_ID: позволяет пройтись по всем существующим мапам, так работаетbpftool mapBPF_MAP_GET_FD_BY_ID: открыть существующий мап по его глобальному IDBPF_MAP_LOOKUP_AND_DELETE_ELEM: атомарно обновить значение объекта и вернуть староеBPF_MAP_FREEZE: сделать мап неизменяемым из userspace (эту операцию нельзя отменить)BPF_MAP_LOOKUP_BATCH,BPF_MAP_LOOKUP_AND_DELETE_BATCH,BPF_MAP_UPDATE_BATCH,BPF_MAP_DELETE_BATCH: массовые операции. Например,BPF_MAP_LOOKUP_AND_DELETE_BATCH— это единственный надежный способ прочитать и обнулить все значения из мапа
Не все из этих команд работают для всех типов мапов, но вообще работа с другими типами maps из пространства пользователя выглядит точно так же, как и работа с хэш-таблицами.
Для порядка, давайте завершим наши эксперименты с хэш-таблицей. Помните, что мы создали таблицу, в которой может содержаться до четырех ключей? Добавим еще несколько элементов:
$ sudo bpftool map update id 114 key 2 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 3 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 4 0 0 0 value 1 0 0 0Пока все хорошо:
$ sudo bpftool map dump id 114
key: 01 00 00 00 value: 01 00 00 00
key: 02 00 00 00 value: 01 00 00 00
key: 04 00 00 00 value: 01 00 00 00
key: 03 00 00 00 value: 01 00 00 00
Found 4 elementsПопробуем добавить еще один:
$ sudo bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
Error: update failed: Argument list too longКак и ожидалось, у нас не получилось. Посмотрим на ошибку подробнее:
$ sudo strace -e bpf bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3, info_len=80, info=0x7ffe6c626da0}}, 120) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x56049ded5260, value=0x56049ded5280, flags=BPF_ANY}, 120) = -1 E2BIG (Argument list too long)
Error: update failed: Argument list too long
+++ exited with 255 +++Все в порядке: как и ожидалось, команда BPF_MAP_UPDATE_ELEM пытается создать новый, пятый, ключ, но падает с E2BIG.
Итак, мы умеем создавать и загружать программы BPF, а также создавать и управлять мапами из пространства пользователя. Теперь логично посмотреть на то, как же мы можем использовать мапы из самих программ BPF. Мы могли бы рассказать об этом, на языке трудно-читаемых программ в машинных кодах-макросах, но на самом деле пришла пора показать, как пишутся и обслуживаются программы BPF на самом деле — при помощи libbpf.
(Для читателей, недовольных отсутствием низкоуровнего примера: мы подробно разберем программы, использующие мапы и функции-помощники, созданные при помощи libbpf и расскажем, что происходит на уровне инструкций. Для читателей, недовольных очень сильно, мы добавили в соответствующем месте статьи.)
Пишем программы BPF с помощью libbpf
Писать программы BPF при помощи машинных кодов может быть интересно только первое время, а потом наступает пресыщение. В этот момент нужно обратить свой взор на llvm, в котором есть бакенд для генерации кода для архитектуры BPF, а также на библиотеку libbpf, которая позволяет писать пользовательскую часть приложений BPF и загружать код программ BPF, сгенерированных при помощи llvm/clang.
На самом деле, как мы увидим в этой и последующих статьях, libbpf делает довольно много работы и без нее (или аналогичных инструментов — iproute2, libbcc, libbpf-go, и т.п.) жить невозможно. Одной из killer-фич проекта libbpf является BPF CO-RE (Compile Once, Run Everywhere) — проект, который позволяет писать программы BPF, переносимые с одного ядра на другое, с возможностью запуска на разных API (например, когда структура ядра меняется от версии к версии). Для того, чтобы иметь возможность работать с CO-RE, ваше ядро должно быть скомпилировано с поддержкой BTF (как это сделать мы рассказываем в разделе . Проверить, собрано ли ваше ядро с BTF или нет, можно очень просто — по наличию следующего файла:
$ ls -lh /sys/kernel/btf/vmlinux
-r--r--r-- 1 root root 2.6M Jul 29 15:30 /sys/kernel/btf/vmlinuxЭтот файл хранит в себе информацию обо всех типах данных, используемых в ядре и используется во всех наших примерах, использующих libbpf. Мы будем подробно говорить про CO-RE в следующей статье, а в этой — просто постройте себе ядро с CONFIG_DEBUG_INFO_BTF.
Biblioteka libbpf живет прямо в директории tools/lib/bpf ядра и ее разработка ведется через список рассылки bpf@vger.kernel.org. Однако для нужд приложений, живущих за пределами ядра, поддерживается отдельный репозиторий в котором ядерная библиотека зеркалируется для доступа на чтение более-менее как есть.
В данном разделе мы посмотрим на то, как можно создать проект, использующий libbpf, напишем несколько (более-менее бессмысленных) тестовых программ и подробно разберем как все это работает. Это позволит нам в следующих разделах проще объяснить, как именно программы BPF взаимодействуют с maps, kernel helpers, BTF, и т.п.
Обычно проекты, использующие libbpf добавляют гитхабовский репозиторий в качестве git submodule, сделаем это и мы:
$ mkdir /tmp/libbpf-example
$ cd /tmp/libbpf-example/
$ git init-db
Initialized empty Git repository in /tmp/libbpf-example/.git/
$ git submodule add https://github.com/libbpf/libbpf.git
Cloning into '/tmp/libbpf-example/libbpf'...
remote: Enumerating objects: 200, done.
remote: Counting objects: 100% (200/200), done.
remote: Compressing objects: 100% (103/103), done.
remote: Total 3354 (delta 101), reused 118 (delta 79), pack-reused 3154
Receiving objects: 100% (3354/3354), 2.05 MiB | 10.22 MiB/s, done.
Resolving deltas: 100% (2176/2176), done.Собирается libbpf очень просто:
$ cd libbpf/src
$ mkdir build
$ OBJDIR=build DESTDIR=root make -s install
$ find root
root
root/usr
root/usr/include
root/usr/include/bpf
root/usr/include/bpf/bpf_tracing.h
root/usr/include/bpf/xsk.h
root/usr/include/bpf/libbpf_common.h
root/usr/include/bpf/bpf_endian.h
root/usr/include/bpf/bpf_helpers.h
root/usr/include/bpf/btf.h
root/usr/include/bpf/bpf_helper_defs.h
root/usr/include/bpf/bpf.h
root/usr/include/bpf/libbpf_util.h
root/usr/include/bpf/libbpf.h
root/usr/include/bpf/bpf_core_read.h
root/usr/lib64
root/usr/lib64/libbpf.so.0.1.0
root/usr/lib64/libbpf.so.0
root/usr/lib64/libbpf.a
root/usr/lib64/libbpf.so
root/usr/lib64/pkgconfig
root/usr/lib64/pkgconfig/libbpf.pcНаш дальнейший план в этом разделе заключается в следующем: мы напишем программу BPF типа BPF_PROG_TYPE_XDP, ту же самую, что и в предыдущем примере, но на C, скомпилируем ее при помощи clang, и напишем программу-помощник, которая будет загружать ее в ядро. В следующих разделах мы расширим возможности как программы BPF, так и программы-помощника.
Пример: создаем полноценное приложение при помощи libbpf
Для начала мы используем файл /sys/kernel/btf/vmlinux, о котором говорилось выше, и создадим его эквивалент в виде заголовочного файла:
$ bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.hВ этом файле будут хранится все структуры данных, имеющиеся в нашем ядре, например, вот так в ядре определяется заголовок IPv4:
$ grep -A 12 'struct iphdr {' vmlinux.h
struct iphdr {
__u8 ihl: 4;
__u8 version: 4;
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
};Теперь мы напишем нашу программу BPF на языке C:
$ cat xdp-simple.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("xdp/simple")
int simple(void *ctx)
{
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Хоть программа у нас получилась очень простая, но все же мы должны обратить внимание на множество деталей. Во-первых, первым заголовочным файлом, который мы включаем является vmlinux.h, который мы только что сгенерировали при помощи bpftool btf dump — теперь нам не нужно устанавливать пакет kernel-headers, чтобы узнать, как выглядят структуры ядра. Следующий заголовочный файл приходит к нам из библиотеки libbpf. Сейчас он нам нужен только для того, чтобы определился макрос SEC, который отправляет символ в соответствующую секцию объектного файла ELF. Наша программа содержится в секции xdp/simple, где перед слэшем мы определяем тип программы BPF — это соглашение, используемое в libbpf, на основе названия секции она подставит правильный тип при запуске bpf(2). Сама программа BPF на C — очень простая и состоит из одной строчки return XDP_PASS. Наконец, отдельная секция "license" содержит название лицензии.
Мы можем скомпилировать нашу программу при помощи llvm/clang, версии >= 10.0.0, а лучше — больше (см. раздел ):
$ clang --version
clang version 11.0.0 (https://github.com/llvm/llvm-project.git afc287e0abec710398465ee1f86237513f2b5091)
...
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.oИз интересных особенностей: мы указываем целевую архитектуру -target bpf и путь к заголовкам libbpf, которые мы недавно установили. Также, не забывайте про -O2, без этой опции вас могут ожидать сюрпризы в дальнейшем. Посмотрим на наш код, получилось ли у нас написать программу, которую мы хотели?
$ llvm-objdump --section=xdp/simple --no-show-raw-insn -D xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: r0 = 2
1: exitДа, получилось! Теперь, у нас есть бинарный файл с программой, и мы хотим создать приложение, которое будет его загружать в ядро. Для этого библиотека libbpf предлагает нам два варианта — использовать более низкоуровневое API или более высокоуровневое API. Мы пойдем вторым путем, так как нам хочется научиться писать, загружать и подсоединять программы BPF минимальными усилиями для их последующего изучения.
Для начала, нам нужно сгенерировать «скелет» нашей программы из ее бинарника при помощи все той же утилиты bpftool — швейцарского ножа мира BPF (что можно понимать и буквально, так как Daniel Borkman — один из создателей и мантейнеров BPF — швейцарец):
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.hNë skedar xdp-simple.skel.h содержится бинарный код нашей программы и функции для управления — загрузки, присоединения, удаления нашего объекта. В нашем простом случае это выглядит как overkill, но это работает и в случае, когда объектный файл содержит множество программ BPF и мапов и для загрузки этого гигантского ELF нам достаточно лишь сгенерировать скелет и вызвать одну-две функции из пользовательского приложения, к написанию которого мы сейчас и перейдем.
Собственно говоря, наша программа-загрузчик — тривиальная:
#include <err.h>
#include <unistd.h>
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "failed to open and/or load BPF objectn");
pause();
xdp_simple_bpf__destroy(obj);
}Këtu struct xdp_simple_bpf определяется в файле xdp-simple.skel.h и описывает наш объектный файл:
struct xdp_simple_bpf {
struct bpf_object_skeleton *skeleton;
struct bpf_object *obj;
struct {
struct bpf_program *simple;
} progs;
struct {
struct bpf_link *simple;
} links;
};Мы можем заметить тут следы низкоуровнего API: структуру struct bpf_program *simple dhe struct bpf_link *simple. Первая структура описывает конкретно нашу программу, записанную в секции xdp/simple, а вторая — описывает то, как программа подсоединяется к источнику событий.
Funksioni xdp_simple_bpf__open_and_load, открывает объект ELF, парсит его, создает все структуры и подструктуры (кроме программы в ELF находятся и другие секции — data, readonly data, отладочная информация, лицензия и т.п.), а потом загружает в ядро посредством системного вызова bpf, что мы можем проверить, скомпилировав и запустив программу:
$ clang -O2 -I ./libbpf/src/root/usr/include/ xdp-simple.c -o xdp-simple ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_BTF_LOAD, 0x7ffdb8fd9670, 120) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0xdfd580, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(5, 8, 0), prog_flags=0, prog_name="simple", prog_ifindex=0, expected_attach_type=0x25 /* BPF_??? */, ...}, 120) = 4Давайте теперь посмотрим на нашу программу при помощи bpftool. Найдем ее ID:
# bpftool p | grep -A4 simple
463: xdp name simple tag 3b185187f1855c4c gpl
loaded_at 2020-08-01T01:59:49+0000 uid 0
xlated 16B jited 40B memlock 4096B
btf_id 185
pids xdp-simple(16498)и сдампим (мы используем сокращенный вид команды bpftool prog dump xlated):
# bpftool p d x id 463
int simple(void *ctx):
; return XDP_PASS;
0: (b7) r0 = 2
1: (95) exitЧто-то новое! Программа напечатала куски нашего исходного файла на языке C. Это было проделано библиотекой libbpf, которая нашла отладочную секцию в бинарнике, скомпилировала ее в объект BTF, загрузила его в ядро при помощи BPF_BTF_LOAD, а потом указала полученный файловый дескриптор при загрузке программы командой BPG_PROG_LOAD.
Kernel Helpers
Программы BPF могут запускать «внешние» функции — kernel helpers. Эти функции-помощники позволяют программам BPF получать доступ к структурам ядра, управлять maps, а также общаться с «реальным миром» — создавать perf events, управлять оборудованием (например, перенаправлять пакеты) и т.п.
Пример: bpf_get_smp_processor_id
В рамках парадигмы «учимся на примерах», рассмотрим одну из функций-помощников, bpf_get_smp_processor_id(), në skedarin kernel/bpf/helpers.c. Она возвращает номер процессора, на котором запускается вызвавшая ее программа BPF. Но нас не так интересует ее семантика, как то, что ее реализация занимает одну строчку:
BPF_CALL_0(bpf_get_smp_processor_id)
{
return smp_processor_id();
}Определения функций-помощников BPF похожи на определения системных вызовов Linux. Здесь, например, определяется функция, не имеющая аргументов. (Функция, принимающая, скажем, три аргумента, определяется при помощи макроса BPF_CALL_3. Максимальное количество аргументов равно пяти.) Однако, это только первая часть определения. Вторая часть заключается в определении структуры типа struct bpf_func_proto, которая содержит описание функции-помощника, понятное verifier:
const struct bpf_func_proto bpf_get_smp_processor_id_proto = {
.func = bpf_get_smp_processor_id,
.gpl_only = false,
.ret_type = RET_INTEGER,
};Регистрация функций-помощников
Для того, чтобы программы BPF определенного типа могли использовать эту функцию, они должны зарегистрировать ее, например, для типа BPF_PROG_TYPE_XDP в ядре определяется функция xdp_func_proto, которая по ID функции-помощника определяет, поддерживает ли XDP эту функцию или нет. Нашу функцию она :
static const struct bpf_func_proto *
xdp_func_proto(enum bpf_func_id func_id, const struct bpf_prog *prog)
{
switch (func_id) {
...
case BPF_FUNC_get_smp_processor_id:
return &bpf_get_smp_processor_id_proto;
...
}
}Новые типы программ BPF «определяются» в файле при помощи макроса BPF_PROG_TYPE. Определяются взято в кавычки, так как это логическое определение, а в терминах языка C определение целого набора конкретных структур происходит в других местах. В частности, в файле kernel/bpf/verifier.c все определения из файла bpf_types.h используются, чтобы создать массив структур bpf_verifier_ops[]:
static const struct bpf_verifier_ops *const bpf_verifier_ops[] = {
#define BPF_PROG_TYPE(_id, _name, prog_ctx_type, kern_ctx_type)
[_id] = & _name ## _verifier_ops,
#include <linux/bpf_types.h>
#undef BPF_PROG_TYPE
};То есть, для каждого типа программ BPF определяется указатель на структуру данных типа struct bpf_verifier_ops, который инициализируется значением _name ## _verifier_ops, т.е., xdp_verifier_ops për xdp. Структура xdp_verifier_ops në skedarin net/core/filter.c si nga:
const struct bpf_verifier_ops xdp_verifier_ops = {
.get_func_proto = xdp_func_proto,
.is_valid_access = xdp_is_valid_access,
.convert_ctx_access = xdp_convert_ctx_access,
.gen_prologue = bpf_noop_prologue,
};Здесь мы и видим нашу знакомую функцию xdp_func_proto, которая будет запускаться verifier каждый раз, как он встретит вызов какой-то функции внутри программы BPF, см. .
Посмотрим на то, как гипотетическая программа BPF использует функцию bpf_get_smp_processor_id. Для этого перепишем программу из нашего предыдущего раздела следующим образом:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("xdp/simple")
int simple(void *ctx)
{
if (bpf_get_smp_processor_id() != 0)
return XDP_DROP;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Simboli bpf_get_smp_processor_id në <bpf/bpf_helper_defs.h> библиотеки libbpf si
static u32 (*bpf_get_smp_processor_id)(void) = (void *) 8;то есть, bpf_get_smp_processor_id — это указатель на функцию, значение которого равно 8, где 8 — это значение BPF_FUNC_get_smp_processor_id типа enum bpf_fun_id, которое определяется для нас в файле vmlinux.h (файл bpf_helper_defs.h в ядре генерируется скриптом, поэтому «магические» числа — это ok). Эта функция не принимает аргументов и возвращает значение типа __u32. Когда мы запускаем ее в нашей программе, clang генерирует инструкцию BPF_CALL «правильного вида». Давайте скомпилируем программу и посмотрим на секцию xdp/simple:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ llvm-objdump -D --section=xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: bf 01 00 00 00 00 00 00 r1 = r0
2: 67 01 00 00 20 00 00 00 r1 <<= 32
3: 77 01 00 00 20 00 00 00 r1 >>= 32
4: b7 00 00 00 02 00 00 00 r0 = 2
5: 15 01 01 00 00 00 00 00 if r1 == 0 goto +1 <LBB0_2>
6: b7 00 00 00 01 00 00 00 r0 = 1
0000000000000038 <LBB0_2>:
7: 95 00 00 00 00 00 00 00 exitВ первой же строчке мы видим инструкцию call, параметр IMM которой равен 8, а SRC_REG — нулю. По ABI-соглашению, используемому verifier, это и есть вызов функции-помощника под номером восемь. После ее запуска логика простая. Возвращенное значение из регистра r0 копируется в r1 и на строчках 2,3 приводится к типу u32 — верхние 32 бита обнуляются. На строчках 4,5,6,7 мы возвращаем 2 (XDP_PASS) или 1 (XDP_DROP) в зависимости от того, вернула ли функция-помощник со строчки 0 нулевое или ненулевое значение.
Проверим себя: загрузим программу и посмотрим на вывод bpftool prog dump xlated:
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simple &
[2] 10914
$ sudo bpftool p | grep simple
523: xdp name simple tag 44c38a10c657e1b0 gpl
pids xdp-simple(10915)
$ sudo bpftool p d x id 523
int simple(void *ctx):
; if (bpf_get_smp_processor_id() != 0)
0: (85) call bpf_get_smp_processor_id#114128
1: (bf) r1 = r0
2: (67) r1 <<= 32
3: (77) r1 >>= 32
4: (b7) r0 = 2
; }
5: (15) if r1 == 0x0 goto pc+1
6: (b7) r0 = 1
7: (95) exitХорошо, verifier нашел правильный kernel-helper.
Пример: передаем аргументы и, наконец, запускаем программу!
Все функции-помощники на уровне выполнения имеют прототип
u64 fn(u64 r1, u64 r2, u64 r3, u64 r4, u64 r5)Параметры функциям-помощникам передаются в регистрах r1—r5, а значение возвращается в регистре r0. Функций, принимающих больше пяти аргументов — нет и добавлять их поддержку в будущем не предполагается.
Давайте посмотрим на новый kernel helper и то как BPF передает параметры. Перепишем xdp-simple.bpf.c следующим образом (остальные строки не изменились):
SEC("xdp/simple")
int simple(void *ctx)
{
bpf_printk("running on CPU%un", bpf_get_smp_processor_id());
return XDP_PASS;
}Наша программа печатает номер CPU, на котором она запущена. Скомпилируем ее и посмотрим на код:
$ llvm-objdump -D --section=xdp/simple --no-show-raw-insn xdp-simple.bpf.o
0000000000000000 <simple>:
0: r1 = 10
1: *(u16 *)(r10 - 8) = r1
2: r1 = 8441246879787806319 ll
4: *(u64 *)(r10 - 16) = r1
5: r1 = 2334956330918245746 ll
7: *(u64 *)(r10 - 24) = r1
8: call 8
9: r1 = r10
10: r1 += -24
11: r2 = 18
12: r3 = r0
13: call 6
14: r0 = 2
15: exitВ строках 0-7 мы записываем на стек строку running on CPU%un, а затем на строке 8 запускаем знакомый нам bpf_get_smp_processor_id. В строках 9-12 мы подготавливаем аргументы хелпера bpf_printk — регистры r1, r2, r3. Почему их три, а не два? Потому что bpf_printk — вокруг настоящего хелпера bpf_trace_printk, которому требуется передать размер форматной строки.
Давайте теперь добавим пару строчек к xdp-simple.c, чтобы наша программа подсоединялась к интерфейсу lo и по-настоящему запускалась!
$ cat xdp-simple.c
#include <linux/if_link.h>
#include <err.h>
#include <unistd.h>
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
__u32 flags = XDP_FLAGS_SKB_MODE;
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "failed to open and/or load BPF objectn");
bpf_set_link_xdp_fd(1, -1, flags);
bpf_set_link_xdp_fd(1, bpf_program__fd(obj->progs.simple), flags);
cleanup:
xdp_simple_bpf__destroy(obj);
}Здесь мы используем функцию bpf_set_link_xdp_fd, которая подсоединяет программы BPF типа XDP к сетевым интерфейсам. Мы захардкодили номер интерфейса lo, который всегда равен 1. Мы запускаем функцию два раза, чтобы сначала отсоединить старую программу, если она была присоединена. Заметьте, что теперь нам не нужен вызов pause или бесконечный цикл: наша программа-загрузчик завершит работу, но программа BPF не будет уничтожена, так как она подсоединена к источнику событий. После успешной загрузки и подсоединения, программа будет запускаться для каждого сетевого пакета, приходящего на lo.
Загрузим программу и посмотрим на интерфейс lo:
$ sudo ./xdp-simple
$ sudo bpftool p | grep simple
669: xdp name simple tag 4fca62e77ccb43d6 gpl
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 669Программа, которую мы загрузили имеет ID 669 и тот же ID мы видим на интерфейсе lo. Пошлем пару пакетов на 127.0.0.1 (request + reply):
$ ping -c1 localhostи теперь посмотрим на содержимое отладочного виртуального файла /sys/kernel/debug/tracing/trace_pipe, в который bpf_printk пишет свои сообщения:
# cat /sys/kernel/debug/tracing/trace_pipe
ping-13937 [000] d.s1 442015.377014: bpf_trace_printk: running on CPU0
ping-13937 [000] d.s1 442015.377027: bpf_trace_printk: running on CPU0Два пакета были замечены на lo и обработаны на CPU0 — наша первая полноценная бессмысленная программа BPF отработала!
Стоит заметить, что bpf_printk не даром пишет в отладочный файл: это не самый удачный хелпер для использования в production, но наша цель была показать что-то простое.
Доступ к maps из программ BPF
Пример: используем мап из программы BPF
В предыдущих разделах мы научились создавать и использовать мапы из пространства пользователя, а теперь посмотрим на ядерную часть. Начнем, как водится, с примера. Перепишем нашу программу xdp-simple.bpf.c si nga:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 8);
__type(key, u32);
__type(value, u64);
} woo SEC(".maps");
SEC("xdp/simple")
int simple(void *ctx)
{
u32 key = bpf_get_smp_processor_id();
u32 *val;
val = bpf_map_lookup_elem(&woo, &key);
if (!val)
return XDP_ABORTED;
*val += 1;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";В начало программы мы добавили определение мапа woo: это массив из 8 элементов, в котором хранятся значения типа u64 (на C мы определили бы такой массив как u64 woo[8]). В программе "xdp/simple" мы получаем номер текущего процессора в переменную key и затем при помощи функции-помощника bpf_map_lookup_element получаем указатель на соответствующую запись в массиве, которую увеличиваем на единицу. В переводе на русский: мы подсчитываем статистику того, на каком CPU были обработаны входящие пакеты. Попробуем запустить программу:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simpleПроверим, что она подцепилась к lo и пошлем немного пакетов:
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 108
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; doneТеперь посмотрим на содержимое массива:
$ sudo bpftool map dump name woo
[
{ "key": 0, "value": 0 },
{ "key": 1, "value": 400 },
{ "key": 2, "value": 0 },
{ "key": 3, "value": 0 },
{ "key": 4, "value": 0 },
{ "key": 5, "value": 0 },
{ "key": 6, "value": 0 },
{ "key": 7, "value": 46400 }
]Почти все процессы были обработаны на CPU7. Нам это не важно, главное, что программа работает и мы поняли как получить доступ к мапам из программ BPF — при помощи .
Мистический указатель
Итак, мы можем получать доступ из программы BPF к мапу при помощи вызовов вида
val = bpf_map_lookup_elem(&woo, &key);где функция-помощник выглядит как
void *bpf_map_lookup_elem(struct bpf_map *map, const void *key)но мы же передаем указатель &woo на безымянную структуру struct { ... }…
Если мы посмотрим на ассемблер программы, то увидим, что значение &woo на самом деле не определено (строчка 4):
llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
...и содержится в релокациях:
$ llvm-readelf -r xdp-simple.bpf.o | head -4
Relocation section '.relxdp/simple' at offset 0xe18 contains 1 entries:
Offset Info Type Symbol's Value Symbol's Name
0000000000000020 0000002700000001 R_BPF_64_64 0000000000000000 wooНо если мы посмотрим на уже загруженную программу, то увидим указатель на правильный map (строка 4):
$ sudo bpftool prog dump x name simple
int simple(void *ctx):
0: (85) call bpf_get_smp_processor_id#114128
1: (63) *(u32 *)(r10 -4) = r0
2: (bf) r2 = r10
3: (07) r2 += -4
4: (18) r1 = map[id:64]
...Таким образом, мы можем сделать вывод, что в момент запуска нашей программы-загрузчика ссылка на &woo была на что-то заменена библиотекой libbpf. Для начала мы посмотрим на вывод strace:
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, key_size=4, value_size=8, max_entries=8, map_name="woo", ...}, 120) = 4
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="simple", ...}, 120) = 5Мы видим, что libbpf создала мап woo и потом загрузила нашу программу simple. Посмотрим более пристально на то, как мы загружаем программу:
- вызываем
xdp_simple_bpf__open_and_loadиз файлаxdp-simple.skel.h - которая вызывает
xdp_simple_bpf__loadиз файлаxdp-simple.skel.h - которая вызывает
bpf_object__load_skeletonиз файлаlibbpf/src/libbpf.c - которая вызывает
bpf_object__load_xattrngalibbpf/src/libbpf.c
Последняя функция, кроме всего прочего, вызовет bpf_object__create_maps, которая создает или открывает существующие maps, превращая их в файловые дескрипторы. (Это то место, где мы видим BPF_MAP_CREATE в выводе strace.) Дальше вызывается функция bpf_object__relocate и именно она нас и интересует, так как мы помним, что мы видели woo в таблице релокаций. Исследуя ее, мы, в конце-концов попадаем в функцию bpf_program__relocate, которая и :
case RELO_LD64:
insn[0].src_reg = BPF_PSEUDO_MAP_FD;
insn[0].imm = obj->maps[relo->map_idx].fd;
break;Итак, мы берем нашу инструкцию
18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 llи заменяем в ней регистр-источник на BPF_PSEUDO_MAP_FD, а первый IMM на файловый дескриптор нашего мапа и, если он равен, например, 0xdeadbeef, то в результате мы получим инструкцию
18 11 00 00 ef eb ad de 00 00 00 00 00 00 00 00 r1 = 0 llИменно так информация о мапах передается в конкретную загруженную программу BPF. При этом мап может быть как создан при помощи BPF_MAP_CREATE, так и открыт по ID при помощи BPF_MAP_GET_FD_BY_ID.
Итого, при использовании libbpf алгоритм следующий:
- во время компиляции для ссылок на мапы создаются записи в таблице релокации
libbpfоткрывает объектник ELF, находит все используемые мапы и создает для них файловые дескрипторы- файловые дескрипторы загружаются в ядро как часть инструкции
LD64
Как вы понимаете, это еще не все, и нам придется заглянуть в ядро. К счастью, у нас есть зацепка — мы прописали значение BPF_PSEUDO_MAP_FD в регистр-источник и можем погрепать его, что приведет нас в святая всех святых — kernel/bpf/verifier.c, где функция с характерным названием заменяет файловый дескриптор на адрес структуры типа struct bpf_map:
static int replace_map_fd_with_map_ptr(struct bpf_verifier_env *env) {
...
f = fdget(insn[0].imm);
map = __bpf_map_get(f);
if (insn->src_reg == BPF_PSEUDO_MAP_FD) {
addr = (unsigned long)map;
}
insn[0].imm = (u32)addr;
insn[1].imm = addr >> 32;(полный код можно найти ). Так что мы можем дополнить наш алгоритм:
- во время загрузки программы verifier проверяет корректность использования мапа и прописывает адрес соответствующей структуры
struct bpf_map
При загрузке бинарника ELF при помощи libbpf происходит еще много событий, но мы обсудим это в рамках других статей.
Загружаем программы и мапы без libbpf
Как и обещалось, вот пример для читателей, которые хотят знать, как создать и загрузить программу, использующую мапы, без помощи libbpf. Это может быть полезно, когда вы работаете в окружении, для которого не можете собрать зависимости, или экономите каждый бит, или пишете программу типа , которая генерирует бинарный код BPF налету.
Для того, чтобы было проще следовать за логикой, мы для этих целей перепишем наш пример xdp-simple. Полный и немного расширенный код программы, рассматриваемой в этом примере, вы можете найти в этом .
Логика нашего приложения следующая:
- создать мап типа
BPF_MAP_TYPE_ARRAYпри помощи командыBPF_MAP_CREATE, - создать программу, использующую этот мап,
- подсоединить программу к интерфейсу
lo,
что переводится на человеческий как
int main(void)
{
int map_fd, prog_fd;
map_fd = map_create();
if (map_fd < 0)
err(1, "bpf: BPF_MAP_CREATE");
prog_fd = prog_load(map_fd);
if (prog_fd < 0)
err(1, "bpf: BPF_PROG_LOAD");
xdp_attach(1, prog_fd);
}Këtu map_create создает мап точно так же, как мы делали это в первом примере про системный вызов bpf — «ядро, пожалуйста, сделай мне новый мап в виде массива из 8 элементов типа __u64 и верни мне файловый дескриптор»:
static int map_create()
{
union bpf_attr attr;
memset(&attr, 0, sizeof(attr));
attr.map_type = BPF_MAP_TYPE_ARRAY,
attr.key_size = sizeof(__u32),
attr.value_size = sizeof(__u64),
attr.max_entries = 8,
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
return syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
}Программа тоже загружается просто:
static int prog_load(int map_fd)
{
union bpf_attr attr;
struct bpf_insn insns[] = {
...
};
memset(&attr, 0, sizeof(attr));
attr.prog_type = BPF_PROG_TYPE_XDP;
attr.insns = ptr_to_u64(insns);
attr.insn_cnt = sizeof(insns)/sizeof(insns[0]);
attr.license = ptr_to_u64("GPL");
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
return syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
}Сложная часть prog_load — это определение нашей программы BPF в виде массива структур struct bpf_insn insns[]. Но так как мы используем программу, которая у нас есть на C, то мы можем немного схитрить:
$ llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
7: b7 01 00 00 00 00 00 00 r1 = 0
8: 15 00 04 00 00 00 00 00 if r0 == 0 goto +4 <LBB0_2>
9: 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0)
10: 07 01 00 00 01 00 00 00 r1 += 1
11: 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1
12: b7 01 00 00 02 00 00 00 r1 = 2
0000000000000068 <LBB0_2>:
13: bf 10 00 00 00 00 00 00 r0 = r1
14: 95 00 00 00 00 00 00 00 exitИтого, нам нужно написать 14 инструкций в виде структур типа struct bpf_insn (совет: возьмите дамп сверху, перечитайте раздел про инструкции, откройте dhe и попробуйте определить struct bpf_insn insns[] самостоятельно):
struct bpf_insn insns[] = {
/* 85 00 00 00 08 00 00 00 call 8 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 8,
},
/* 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0 */
{
.code = BPF_MEM | BPF_STX,
.off = -4,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_10,
},
/* bf a2 00 00 00 00 00 00 r2 = r10 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_10,
.dst_reg = BPF_REG_2,
},
/* 07 02 00 00 fc ff ff ff r2 += -4 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_2,
.imm = -4,
},
/* 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll */
{
.code = BPF_LD | BPF_DW | BPF_IMM,
.src_reg = BPF_PSEUDO_MAP_FD,
.dst_reg = BPF_REG_1,
.imm = map_fd,
},
{ }, /* placeholder */
/* 85 00 00 00 01 00 00 00 call 1 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 1,
},
/* b7 01 00 00 00 00 00 00 r1 = 0 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 0,
},
/* 15 00 04 00 00 00 00 00 if r0 == 0 goto +4 <LBB0_2> */
{
.code = BPF_JMP | BPF_JEQ | BPF_K,
.off = 4,
.src_reg = BPF_REG_0,
.imm = 0,
},
/* 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0) */
{
.code = BPF_MEM | BPF_LDX,
.off = 0,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_1,
},
/* 07 01 00 00 01 00 00 00 r1 += 1 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 1,
},
/* 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1 */
{
.code = BPF_MEM | BPF_STX,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* b7 01 00 00 02 00 00 00 r1 = 2 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 2,
},
/* <LBB0_2>: bf 10 00 00 00 00 00 00 r0 = r1 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* 95 00 00 00 00 00 00 00 exit */
{
.code = BPF_JMP | BPF_EXIT
},
};Упражнение для тех, кто не стал писать это сам — найдите map_fd.
В нашей программе осталась еще одна нераскрытая часть — xdp_attach. К сожалению, программы типа XDP нельзя подсоединить при помощи системного вызова bpf. Люди, создававшие BPF и XDP были из сетевого сообщества Linux, а значит, они использовали самый привычный для них (но не для нормальных людей) интерфейс взаимодействия с ядром: , см. также . Самый простой способ реализации xdp_attach — это копирование кода из libbpf, а именно, из файла , что мы и проделали, немного укоротив его:
Добро пожаловать в мир netlink сокетов
Открываем netlink сокет типа NETLINK_ROUTE:
int netlink_open(__u32 *nl_pid)
{
struct sockaddr_nl sa;
socklen_t addrlen;
int one = 1, ret;
int sock;
memset(&sa, 0, sizeof(sa));
sa.nl_family = AF_NETLINK;
sock = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE);
if (sock < 0)
err(1, "socket");
if (setsockopt(sock, SOL_NETLINK, NETLINK_EXT_ACK, &one, sizeof(one)) < 0)
warnx("netlink error reporting not supported");
if (bind(sock, (struct sockaddr *)&sa, sizeof(sa)) < 0)
err(1, "bind");
addrlen = sizeof(sa);
if (getsockname(sock, (struct sockaddr *)&sa, &addrlen) < 0)
err(1, "getsockname");
*nl_pid = sa.nl_pid;
return sock;
}Читаем из такого сокета:
static int bpf_netlink_recv(int sock, __u32 nl_pid, int seq)
{
bool multipart = true;
struct nlmsgerr *errm;
struct nlmsghdr *nh;
char buf[4096];
int len, ret;
while (multipart) {
multipart = false;
len = recv(sock, buf, sizeof(buf), 0);
if (len < 0)
err(1, "recv");
if (len == 0)
break;
for (nh = (struct nlmsghdr *)buf; NLMSG_OK(nh, len);
nh = NLMSG_NEXT(nh, len)) {
if (nh->nlmsg_pid != nl_pid)
errx(1, "wrong pid");
if (nh->nlmsg_seq != seq)
errx(1, "INVSEQ");
if (nh->nlmsg_flags & NLM_F_MULTI)
multipart = true;
switch (nh->nlmsg_type) {
case NLMSG_ERROR:
errm = (struct nlmsgerr *)NLMSG_DATA(nh);
if (!errm->error)
continue;
ret = errm->error;
// libbpf_nla_dump_errormsg(nh); too many code to copy...
goto done;
case NLMSG_DONE:
return 0;
default:
break;
}
}
}
ret = 0;
done:
return ret;
}Наконец, вот наша функция, которая открывает сокет и посылает в него специальное сообщение, содержащее файловый дескриптор:
static int xdp_attach(int ifindex, int prog_fd)
{
int sock, seq = 0, ret;
struct nlattr *nla, *nla_xdp;
struct {
struct nlmsghdr nh;
struct ifinfomsg ifinfo;
char attrbuf[64];
} req;
__u32 nl_pid = 0;
sock = netlink_open(&nl_pid);
if (sock < 0)
return sock;
memset(&req, 0, sizeof(req));
req.nh.nlmsg_len = NLMSG_LENGTH(sizeof(struct ifinfomsg));
req.nh.nlmsg_flags = NLM_F_REQUEST | NLM_F_ACK;
req.nh.nlmsg_type = RTM_SETLINK;
req.nh.nlmsg_pid = 0;
req.nh.nlmsg_seq = ++seq;
req.ifinfo.ifi_family = AF_UNSPEC;
req.ifinfo.ifi_index = ifindex;
/* started nested attribute for XDP */
nla = (struct nlattr *)(((char *)&req)
+ NLMSG_ALIGN(req.nh.nlmsg_len));
nla->nla_type = NLA_F_NESTED | IFLA_XDP;
nla->nla_len = NLA_HDRLEN;
/* add XDP fd */
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FD;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(int);
memcpy((char *)nla_xdp + NLA_HDRLEN, &prog_fd, sizeof(prog_fd));
nla->nla_len += nla_xdp->nla_len;
/* if user passed in any flags, add those too */
__u32 flags = XDP_FLAGS_SKB_MODE;
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FLAGS;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(flags);
memcpy((char *)nla_xdp + NLA_HDRLEN, &flags, sizeof(flags));
nla->nla_len += nla_xdp->nla_len;
req.nh.nlmsg_len += NLA_ALIGN(nla->nla_len);
if (send(sock, &req, req.nh.nlmsg_len, 0) < 0)
err(1, "send");
ret = bpf_netlink_recv(sock, nl_pid, seq);
cleanup:
close(sock);
return ret;
}Итак, все готово к тестированию:
$ cc nolibbpf.c -o nolibbpf
$ sudo strace -e bpf ./nolibbpf
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, map_name="woo", ...}, 72) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=15, prog_name="woo", ...}, 72) = 4
+++ exited with 0 +++Посмотрим, подсоединилась ли наша программа к lo:
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 160Пошлем пинги и помотрим на map:
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; done
$ sudo bpftool m dump name woo
key: 00 00 00 00 value: 90 01 00 00 00 00 00 00
key: 01 00 00 00 value: 00 00 00 00 00 00 00 00
key: 02 00 00 00 value: 00 00 00 00 00 00 00 00
key: 03 00 00 00 value: 00 00 00 00 00 00 00 00
key: 04 00 00 00 value: 00 00 00 00 00 00 00 00
key: 05 00 00 00 value: 00 00 00 00 00 00 00 00
key: 06 00 00 00 value: 40 b5 00 00 00 00 00 00
key: 07 00 00 00 value: 00 00 00 00 00 00 00 00
Found 8 elementsУра, все работает. Заметьте, кстати, что наш map опять отображается в виде байтиков. Это проиходит из-за того, что, в отличие от libbpf мы не загружали информацию о типах (BTF). Но подробнее об этом мы поговорим в следующий раз.
Mjetet e zhvillimit
В этом разделе мы посмотрим на минимальный инструментальный набор разработчика BPF.
Вообще говоря, для разработки программ BPF не нужно ничего особенного — BPF работает на любом приличном дистрибутивном ядре, а программы собираются при помощи clang, который можно поставить из пакета. Однако, из-за того, что BPF находится в процессе разработки, ядро и инструменты постоянно меняются, если вы не хотите писать программы BPF дедовскими методами из 2019-х, то вам придется собрать
llvm/clangpahole- свое ядро
bpftool
(Для справки: этот раздел и все примеры в статье запускались на Debian 10.)
llvm/clang
BPF дружит с LLVM и, хотя с недавних пор программы для BPF можно компилировать и при помощи gcc, вся текущая разработка ведется для LLVM. Поэтому первым делом мы соберем текущую версию clang из git:
$ sudo apt install ninja-build
$ git clone --depth 1 https://github.com/llvm/llvm-project.git
$ mkdir -p llvm-project/llvm/build/install
$ cd llvm-project/llvm/build
$ cmake .. -G "Ninja" -DLLVM_TARGETS_TO_BUILD="BPF;X86"
-DLLVM_ENABLE_PROJECTS="clang"
-DBUILD_SHARED_LIBS=OFF
-DCMAKE_BUILD_TYPE=Release
-DLLVM_BUILD_RUNTIME=OFF
$ time ninja
... много времени спустя
$Теперь мы можем проверить, правильно ли все собралось:
$ ./bin/llc --version
LLVM (http://llvm.org/):
LLVM version 11.0.0git
Optimized build.
Default target: x86_64-unknown-linux-gnu
Host CPU: znver1
Registered Targets:
bpf - BPF (host endian)
bpfeb - BPF (big endian)
bpfel - BPF (little endian)
x86 - 32-bit X86: Pentium-Pro and above
x86-64 - 64-bit X86: EM64T and AMD64(Инструкция по сборке clang взята мной из .)
Мы не будем устанавливать только что собранные программы, а вместо этого просто добавим их в PATH, për shembull:
export PATH="`pwd`/bin:$PATH"(Это можно добавить в .bashrc или в отдельный файл. Лично я добавляю такие вещи в ~/bin/activate-llvm.sh и когда нужно делаю . activate-llvm.sh.)
Pahole и BTF
Utilitari pahole используется при сборке ядра для создания отладочной информации в формате BTF. Мы не будем в этой статье подробно останавливаться на деталях технологии BTF, кроме того факта, что это удобно и мы хотим его использовать. Поэтому, если вы собираетесь собирать свое ядро, соберите сначала pahole (без pahole вы не сможете собрать ядро с опцией CONFIG_DEBUG_INFO_BTF:
$ git clone https://git.kernel.org/pub/scm/devel/pahole/pahole.git
$ cd pahole/
$ sudo apt install cmake
$ mkdir build
$ cd build/
$ cmake -D__LIB=lib ..
$ make
$ sudo make install
$ which pahole
/usr/local/bin/paholeЯдра для экспериментов с BPF
При исследовании возможностей BPF хочется собрать свое ядро. Это, вообще говоря, не обязательно, так как вы сможете собирать и загружать программы BPF и на дистрибутивном ядре, однако, наличие своего ядра позволяет использовать самые новые возможности BPF, которые окажутся в вашем дистрибутиве в лучшем случае через месяцы или, как в случае с некоторыми отладочными инструментами, вообще не будут опакечены в обозримом будущем. Также свое ядро позволяет почувствовать себя важным экспериментировать с кодом.
Для того, чтобы построить ядро вам нужно, во-первых, само ядро, а во-вторых, файл конфигурации ядра. Для экспериментов с BPF мы можем использовать обычное ядро или одно из девелоперских ядер. Исторически разработка BPF происходит в рамках сетевого сообщества Linux и поэтому все изменения рано или поздно проходят через Дэвида Миллера (David Miller) — мантейнера сетевой части Linux. В зависимости от своей природы — правка или новые фичи — сетевые изменения попадают в одно из двух ядер — ose . Изменения для BPF таким же образом распределяются между dhe , которые потом пулятся в net и net-next, соответственно. Подробнее см. в dhe . Так что выбирайте ядро исходя из вашего вкуса и потребностей в стабильности системы, на которой вы тестируете (*-next ядра самые нестабильные из перечисленных).
В рамки данной статьи не входит рассказ о том, как управляться с файлами конфигурации ядра — предполагается, что вы либо уже умеете это делать, либо самостоятельно. Однако, следующих инструкций должно быть, более-менее, достаточно, чтобы у вас получилась работающая система с поддержкой BPF.
Скачать одно из вышеупомянутых ядер:
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git
$ cd bpf-nextСобрать минимальный работающий конфиг ядра:
$ cp /boot/config-`uname -r` .config
$ make localmodconfigВключить опции BPF в файле .config по своему выбору (скорее всего, сам CONFIG_BPF уже будет включен, так как его использует systemd). Вот список опций из ядра, которое использовалось для этой статьи:
CONFIG_CGROUP_BPF=y
CONFIG_BPF=y
CONFIG_BPF_LSM=y
CONFIG_BPF_SYSCALL=y
CONFIG_ARCH_WANT_DEFAULT_BPF_JIT=y
CONFIG_BPF_JIT_ALWAYS_ON=y
CONFIG_BPF_JIT_DEFAULT_ON=y
CONFIG_IPV6_SEG6_BPF=y
# CONFIG_NETFILTER_XT_MATCH_BPF is not set
# CONFIG_BPFILTER is not set
CONFIG_NET_CLS_BPF=y
CONFIG_NET_ACT_BPF=y
CONFIG_BPF_JIT=y
CONFIG_BPF_STREAM_PARSER=y
CONFIG_LWTUNNEL_BPF=y
CONFIG_HAVE_EBPF_JIT=y
CONFIG_BPF_EVENTS=y
CONFIG_BPF_KPROBE_OVERRIDE=y
CONFIG_DEBUG_INFO_BTF=yДальше мы можем легко собрать и установить модули и ядро (кстати, можно собрать ядро при помощи только что собранного clang, добавив CC=clang):
$ make -s -j $(getconf _NPROCESSORS_ONLN)
$ sudo make modules_install
$ sudo make installи перезагрузиться с новым ядром (я использую для этого kexec nga paketa kexec-tools):
v=5.8.0-rc6+ # если вы пересобираете текущее ядро, то можно делать v=`uname -r`
sudo kexec -l -t bzImage /boot/vmlinuz-$v --initrd=/boot/initrd.img-$v --reuse-cmdline &&
sudo kexec -ebpftool
Наиболее часто используемой утилитой в статье будет утилита bpftool, поставляемая в составе ядра Linux. Она написана и поддерживается разработчиками BPF для разработчиков BPF и с ее помощью можно управляться со всеми типами объектов BPF — загружать программы, создавать и изменять maps, исследовать жизнедеятельность экосистемы BPF, и т.п. Документацию в виде исходников к man pages можно найти или, уже скомпилированную, .
Në momentin e shkruar bpftool поставляется в готовом виде только для RHEL, Fedora и Ubuntu (см., например, , в котором рассказывается неоконченная история опакечивания bpftool в Debian). Но если вы уже собрали свое ядро, то собрать bpftool проще простого:
$ cd ${linux}/tools/bpf/bpftool
# ... пропишите пути к последнему clang, как рассказано выше
$ make -s
Auto-detecting system features:
... libbfd: [ on ]
... disassembler-four-args: [ on ]
... zlib: [ on ]
... libcap: [ on ]
... clang-bpf-co-re: [ on ]
Auto-detecting system features:
... libelf: [ on ]
... zlib: [ on ]
... bpf: [ on ]
$(здесь ${linux} — это ваша директория с ядром.) После выполнения этих команд bpftool будет собрана в директории ${linux}/tools/bpf/bpftool и ее можно будет прописать в путь (прежде всего пользователю root) или просто скопировать в /usr/local/sbin.
Собирать bpftool лучше всего при помощи последнего clang, собранного, как рассказано выше, а проверить, правильно ли она собралась — при помощи, например, команды
$ sudo bpftool feature probe kernel
Scanning system configuration...
bpf() syscall for unprivileged users is enabled
JIT compiler is enabled
JIT compiler hardening is disabled
JIT compiler kallsyms exports are enabled for root
...которая покажет, какие фичи BPF включены у вас в ядре.
Кстати, предыдущую команду можно запустить как
# bpftool f p kЭто сделано по аналогии с утилитами из пакета iproute2, где мы можем, например, сказать ip a s eth0 në vend të ip addr show dev eth0.
Përfundimi
BPF позволяет подковать блоху эффективно измерять и налету изменять функциональность ядра. Система получилась очень удачной, в лучших традициях UNIX: простой механизм, позволяющий (пере)программировать ядро, позволил огромному количеству людей и организаций экспериментировать. И, хотя эксперименты, так же как и развитие самой инфраструктуры BPF, еще далеко не закончены, система уже имеет стабильное ABI, позволяющее выстраивать надежную, а главное, эффективную бизнес-логику.
Хочется отметить, что по моему мнению технология получилась настолько популярной оттого, что с одной стороны, в нее можно играть (архитектуру машины можно понять более-менее за один вечер), а с другой — решать задачи, не решаемые (красиво) до ее появления. Две эти компоненты вместе заставляют людей экспериментировать и мечтать, что и приводит к появлению все новых и новых инновационных решений.
Данная статья, хоть и получилась не особо короткой, является только введением в мир BPF и не описывает «продвинутые» возможности и важные части архитектуры. Дальнейший план, примерно, такой: следующая статья будет обзором типов программ BPF (в ядре 5.8 поддерживается 30 типов программ), затем мы, наконец, посмотрим на то, как писать настоящие приложения на BPF на примере программ для трассировки ядра, затем придет время для более углубленного курса по архитектуре BPF, а затем — для примеров сетевых и security приложений BPF.
Предыдущие статьи этого цикла
Сылки
— документация по BPF от cilium, а точнее от Daniel Borkman, одного из создателей и мантейнеров BPF. Это одно из первых серьезных описаний, которое отлично от остальных тем, что Daniel точно знает о чем пишет и ляпов там не наблюдается. В частности, в этом документе рассказывается как работать с программами BPF типов XDP и TC при помощи известной утилиты
ipnga paketaiproute2.— оригинальный файл с документацией по классическому, а затем и по extended BPF. Полезно читать, если вы хотите покопаться в ассемблере и технических деталях архитектуры.
. Обновляется редко, но метко, так как пишут туда Alexei Starovoitov (автор eBPF) и Andrii Nakryiko — (мантейнер
libbpf).. Занимательный twitter-тред от Quentin Monnet с примерами и секретами использования bpftool.
. Гигантский (и до сих пор поддерживаемый) список ссылок на документацию по BPF от Quentin Monnet.
Burimi: habr.com
