


Çfarë parimesh krijon një Depo të Dëshiruar të Dhënash?
Fokusoni në vlerën e biznesit dhe analizën në mungesë të kodit boilerplate. Menaxhimi i DWH si një bazë kodi: versionimi, rishikimi, testimi automatik dhe CI. Modulariteti, zgjerueshmëria, kodi i hapur dhe komuniteti. Dokumentacioni i përdoruesit të miqësor dhe vizualizimi i varësive (Data Lineage).
Për më shumë detaje dhe mbi rolin e DBT në ekosistemin e Big Data & Analytics — mirëmëngjesi nën kat.
Përshëndetje të gjithëve
Këtu është Artemiy Kozyr. Për më shumë se 5 vjet punoj me depo të dhënash, ndihmoj në ndërtimin e ETL/ELT, si dhe analizën e të dhënave dhe vizualizimin. Aktualisht punoj në , dhe jap mësim në OTUS në kursin , dhe sot dua të ndaj me ju një artikull që kam shkruar përpara fillimit të grupit të ri në kursin.
Përmbledhje e shkurtër
Korniza DBT — është gjithçka për shkronjën T në akronimin ELT (Extract — Transform — Load).
Me shfaqjen e bazave të dhënash analitike aq të fuqishme dhe të Zgjeruara si BigQuery, Redshift, Snowflake, ka humbur tërë rëndësinë e kryerjes së transformimeve jashtë Depo të Dhënash.
DBT nuk e eksporton të dhënat nga burimet, por ofron mundësi të mëdha për të punuar me ato të dhëna që janë tashmë ngarkuar në Depo (në Internal ose External Storage).
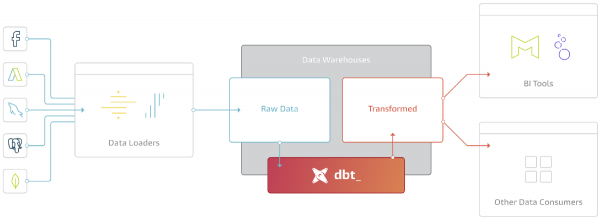
Qëllimi kryesor i DBT është të marrë kodin, ta kompiloje atë në SQL, dhe të ekzekutojë komandat në rendin e duhur në Depo.
Struktura e projektit DBT
Projekti përbëhet nga dy lloje direktorive dhe skedash:
- Modeli (.sql) — njësi transformimi e shprehur si një pyetje SELECT
- Skeda e konfigurimit (.yml) — parametra, cilësime, teste, dokumentacion
Në nivelin bazik, puna zhvillohet në këtë mënyrë:
- Përdoruesi përgatit kodin e modeleve në çdo IDE të përshtatshëm
- Me anë të CLI-s, thirret ekzekutimi i modeleve, DBT kompilon kodin e modeleve në SQL
- Kodsql i kompiliuar ekzekutohet në Depo në rendin e caktuar (graf)
Kështu mund të duket ekzekutimi nga CLI:
Gjithçka është SELECT
Kjo është karakteristika kryesore e kornizës Data Build Tool. Me fjalë të tjera, DBT abstragjon të gjithë kodin që lidhet me materializimin e pyetjeve tuaja në Depot (variacionet e komandave CREATE, INSERT, UPDATE, DELETE, ALTER, GRANT, …).
Çdo model supozon shkronjimin e një pyetje SELECT, e cila përcakton setin e të dhënave rezultuese.
Megjithatë, logjika e transformimeve mund të jetë shumënivélëshe dhe të konsolidojë të dhëna nga disa modele të tjera. Një shembull modeli që do të ndërtojë një vitrinë poroshish (f_orders):
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
me porosi si (
select * from {{ ref('stg_orders') }}
),
porosi_pages si (
select * from {{ ref('order_payments') }}
),
konte final si (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
porosi_pages.{{payment_method}}_amount,
{% endfor -%}
porosi_pages.total_amount as amount
from orders
left join porosi_pages using (order_id)
)
select * from final
Çfarë interesante mund të shohim këtu?
Së pari: Janë përdorur CTE (Common Table Expressions) — për organizimin dhe kuptimin e kodit që përmban shumë transformime dhe logjikë biznesi
Së dyti: Kodu i modelit — është një miks SQL dhe (gjuhë templating).
Në shembull është përdorur një cikël për për formimin e shumës sipas çdo metode pagese, të specifikuar në shprehje set. Po ashtu përdoret një funksion ref — mundësia për të referuar brenda kodit në modele të tjera:
- Gjatë kompilimit ref do të konvertohet në një tregues të synuar në tabelë ose pamje në Depo
- ref lejon ndërtimin e grafikëve të varësive të modeleve
Pikërisht shton në DBT mundësi pothuajse të pakufizuara. Më të përdorurat nga ato janë:
- Operatorët if / else — ndarës të rrugëve
- Ciklet for — cikle
- Variablat — variabla
- Makro — krijimi i makrove
Materializimi: Tabelë, Pamje, Inkremental
Strategjia e Materializimit — qasja sipas së cilës, rezultati i grupeve të dhënave të modelit do të ruhet në Depot.
Në një shqyrtim themelor, kjo është:
- Tabela — tabelë fizike në Depot
- Pamja — përfaqësim, tabelë virtuale në Depot
Ka dhe strategji më të ndërlikuara të materializimit:
- Inkremental — ngarkimi inkremental (i tabelave të mëdha të fakteve); rreshtat e rinj shtohen, ato të ndryshuara përditësohen, të fshirët hiqen
- Ephemeral — modeli nuk materializohet drejtpërdrejt, por merr pjesë si CTE në modele të tjera
- Çdo strategji tjetër që mund të shtoni vetë
Përveç strategjive të materializimit, hapen mundësi për optimizim për Depot specifike, për shembull:
- Snowflake: Tabela transiente, Sjellja e bashkimeve, Klasifikimi i tabelave, Kopjimi i të drejtave, Pamje të sigurta
- Redshift: Distkey, Sortkey (të ndërthurura, të ndara), Pamjet me lidhje të vonshme
- BigQuery: Ndarja dhe klasifikimi i tabelave, Sjellja e bashkimeve, Enkriptimi KMS, Etiketat & Të dhëna
- Spark: Formati i skedarit (parquet, csv, json, orc, delta), partition_by, clustered_by, buckets, incremental_strategy
Aktualisht mbështeten ruajtjet e mëposhtme:
- Postgres
- Redshift
- BigQuery
- Snowflake
- Presto (pjësërisht)
- Spark (pjësërisht)
- Microsoft SQL Server (adapter komuniteti)
Le të përmirësojmë modelin tonë:
- Të bëjmë plotësimin e tij inkremental (Incremental)
- Të shtojmë çelësat e segmentimit dhe renditjes për Redshift
-- Konfigurimi i modelit:
-- Plotësim inkremental, çelësi unik për përditësimin e shënimeve (unique_key)
-- Çelësi i segmentimit (dist), çelësi i renditjes (sort)
{{
config(
materialized='incremental',
unique_key='order_id',
dist="customer_id",
sort="order_date"
)
}}
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
me porosi si (
select * from {{ ref('stg_orders') }}
kujt 1=1
{% if is_incremental() -%}
-- Ky filtr do të aplikohet vetëm për nisjen inkrementale
and order_date >= (select max(order_date) from {{ this }})
{%- endif %}
),
porosi_pages as (
select * from {{ ref('order_payments') }}
),
fundore si (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
porosi_pages.{{payment_method}}_amount,
{% endfor -%}
porosi_pages.total_amount as amount
from orders
left join porosi_pages using (order_id)
)
select * from fundore
Grafi i varësisë së modeleve
I njëjti si pemë varësish. Po ashtu DAG (Grafi i Orientuar Aciiklik — Directed Acyclic Graph).
DBT krijon grafin bazuar në konfigurimin e të gjitha modeleve të projektit, përkatësisht lidhjet ref() brenda modeleve me modelet e tjera. Prania e grafit lejon realizimin e këtyre funksioneve:
- Ekzekutimin e modeleve në një rend të saktë
- Paralelizimin e formimit të vitrinave
- Ekzekutimin e një nëngrafi të rastit
Shembulli i vizualizimit të grafit:
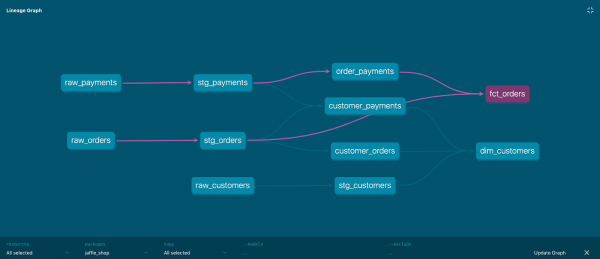
Çdo nyje e grafit është një model, brinjtë e grafit përcaktohen nga shprehja ref.
Cilësia e të dhënave dhe Dokumentacioni
Përveç formimit të vetë modeleve, DBT lejon testimin e një sërë supozimesh (assertions) mbi grupin e rezultateve të dhënave, të tilla si:
- Jo Null
- Unike
- Integriteti Referencial — integriteti referencor (p.sh., customer_id në tabelën e porosive përputhet me id në tabelën e klientëve)
- Përputhshmëria me listën e vlerave të lejuara
Është e mundur shtimi i testeve të veta (custom data tests), të tilla si, për shembull, % devijimi i të ardhurave me treguesit e ditës, javës, muajit të kaluar. Çdo supozim i formuluar në formën e një pyetje SQL mund të bëhet test.
Kështu mund të kapen devijimet dhe gabimet epadëshiruara në të dhëna në vitrinat e Depot.
Sa i dokumentacionit, DBT ofron mekanizma për shtimin, versionimin dhe shpërndarjen e metadatat dhe komentet në nivelin e modeleve dhe madje të atributeve.
Ja si duket shtimi i testeve dhe dokumentacionit në nivelin e skedarit të konfigurimit:
- emri: fct_orders
përshkrimi: Ky tabelë ka informacion bazik mbi porositë, si dhe disa fakte të deriva nga pagesat
kolonat:
- emri: order_id
teste:
- unik # kontrollimi i unikalitetit të vlerave
- jo_null # kontrollimi i pranisë së null
përshkrimi: Ky është një identifikues unik për një porosi
- emri: customer_id
përshkrimi: Çelësi i huaj në tabelën e klientëve
teste:
- jo_null
- marrëdhënie: # kontrollimi i integritetit referencial
në: ref('dim_customers')
fusha: customer_id
- emri: order_date
përshkrimi: Data (UTC) kur është bërë porosia
- emri: status
përshkrimi: '{{ doc("orders_status") }}'
teste:
- vlerat e pranuara: # kontrollimi i vlerave të pranuara
vlerat: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
Ja si duket ky dokumentacion tashmë në uebfaqen e gjeneruar:
Makrot dhe Modul
Qëllimi i DBT nuk është vetëm të bëhet një grup skenarësh SQL, por të ofrojë përdoruesve mjete të fuqishme dhe me mundësi të pasura për të ndërtuar transformime të veta dhe për të shpërndarë këto module.
Makroh janë grupe konstrukcionesh dhe shprehjesh që mund të thirren si funksione brenda modeleve. Makroh lejojnë ri-përdorimin e SQL midis modeleve dhe projekteve në përputhje me parimin inxhinierik DRY (Mos e Përsërit Vetveten).
Shembuj i makros:
{% macro rename_category(column_name) %}
case
when {{ column_name }} ilike '%osx%' then 'osx'
when {{ column_name }} ilike '%android%' then 'android'
when {{ column_name }} ilike '%ios%' then 'ios'
else 'other'
end as renamed_product
{% endmacro %}
Dhe përdorimi i tij:
{% set column_name = 'product' %}
select
product,
{{ rename_category(column_name) }} -- thirrje e makros
from my_table
DBT vjen me një menaxher paketa (packages), i cili lejon përdoruesit të publikojnë dhe ri-përdorin module dhe maqro të veçanta.
Kjo do të thotë mundësi për të shkarkuar dhe përdorur biblioteka si:
- : puna me Data/Koha, Çelësa Nënstitucionalë, teste të skemës, Pivot/Unpivot dhe të tjera
- Krijime të gatshme për shërbime si dhe
- Biblioteka për depozitë të veçanta të të dhënave, për shembull
- — Moduli për regjistrimin e funksionimit të DBT
Mund të shihni listën e plotë të pakove në .
Edhe më shumë mundësi
Këtu do të përshkruaj disa karakteristika dhe realizime të tjera interesante që unë dhe ekipi përdorim për ndërtimin e Depo të Dhënash në .
Ndarja e mjediseve të ekzekutimit DEV — TEST — PROD
Edhe brenda një klasteri DWH (në kuadrin e skemave të ndryshme). Për shembull, me shprehjen e mëposhtme:
me burim si (
zgjedh * nga {{ source('salesforce', 'users') }}
ku 1=1
{%- nëse target.name është në ['dev', 'test', 'ci'] -%}
ku timestamp >= dateadd(day, -3, current_date)
{%- përfundim -%}
)
Ky kod literally thotë: për mjediset dev, test, ci merri të dhënat vetëm për tre ditët e fundit dhe jo më shumë. Kështu, ekzekutimi në këto mite do të jetë shumë më i shpejtë dhe do të kërkojë më pak burime. Kur ekzekutohet në mjedisin prod kushti i filtrimit do të injorohet.
Materializimi me kodifikim alternativ të kolonave
Redshift — një DBMS kolonor që lejon përcaktimin e algoritmeve të kompresimit të të dhënave për çdo kolonë të veçantë. Zgjedhja e algoritmeve optimal mund të reduktojë volumën e zënë në disk nga 20-50%.
Makro do të ekzekutojë komandën ANALYZE COMPRESSION, do të krijojë një tabelë të re me algoritmet e kodimit të rekomanduara për kolonat, çelësat e segmentimit (dist_key) dhe renditjes (sort_key), do të transferojë të dhënat në të, dhe nëse është e nevojshme do të fshijë kopjen e vjetër.
Nënshkrimi i makros:
{{ compress_table(schema, table,
drop_backup=False,
comprows=none|Integer,
sort_style=none|compound|interleaved,
sort_keys=none|List,
dist_style=none|all|even,
dist_key=none|String) }}
Regjistrimi i ekzekutimeve të modeleve
Për çdo ekzekutim të modelit mund të lidhen hooks që do të ekzekutohen para fillimit ose menjëherë pas përfundimit të krijimit të modelit:
pre-hook: "{{ logging.log_model_start_event() }}"
post-hook: "{{ logging.log_model_end_event() }}"
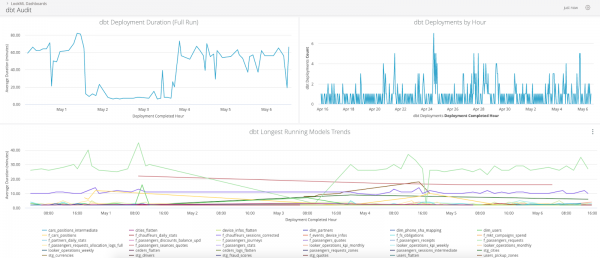
Moduli i regjistrimit do të lejojë regjistrimin e të gjitha metadatat e nevojshme në një tabelë të veçantë, mbi të cilën më vonë mund të bëhet auditi dhe analiza e vendeve problematike (bottlenecks).
Ja si duket paneli në të dhënat e regjistrimit në Looker:
Automatizimi i shërbimit të Depozitës
Nëse përdorni ndonjë zgjerim funksional të Ruhes, si UDF (Funksione të Definuara nga Përdoruesi), versionimi i këtyre funksioneve, menaxhimi i aksesit dhe nxjerrja e automatizuar e versioneve të reja janë shumë të lehta për t'u realizuar në DBT.
Ne përdorim UDF në Python, për llogaritjen e vlerave hash, domain-eve të adresave të postës, dekodimin e maskave me bit (bitmask).
shembulli i një makroje që krijon UDF në çdo mjedis ekzekutimi (dev, test, prod):
{% macro create_udf() -%}
{% set sql %}
CREATE OR REPLACE FUNCTION {{ target.schema }}.f_sha256(mes "varchar")
RETURNS varchar
LANGUAGE plpythonu
STABLE
AS $$
import hashlib
return hashlib.sha256(mes).hexdigest()
$$
;
{% endset %}
{% set table = run_query(sql) %}
{%- endmacro %}
Në Wheely përdorim Amazon Redshift, i cili bazohet në PostgreSQL. Për Redshift është e rëndësishme të mbledhim rregullisht statistika për tabelat dhe të lirojmë hapësirë në disk — komandat ANALYZE dhe VACUUM, përkatësisht.
Për këtë, çdo natë ekzekutohen komandat nga makroja redshift_maintenance:
{% macro redshift_maintenance() %}
{% set vacuumable_tables=run_query(vacuumable_tables_sql) %}
{% for row in vacuumable_tables %}
{% set message_prefix=loop.index ~ " of " ~ loop.length %}
{%- set relation_to_vacuum = adapter.get_relation(
database=row['table_database'],
schema=row['table_schema'],
identifier=row['table_name']
) -%}
{% do run_query("commit") %}
{% if relation_to_vacuum %}
{% set start=modules.datetime.datetime.now() %}
{{ dbt_utils.log_info(message_prefix ~ " Vacuuming " ~ relation_to_vacuum) }}
{% do run_query("VACUUM " ~ relation_to_vacuum ~ " BOOST") %}
{{ dbt_utils.log_info(message_prefix ~ " Analyzing " ~ relation_to_vacuum) }}
{% do run_query("ANALYZE " ~ relation_to_vacuum) %}
{% set end=modules.datetime.datetime.now() %}
{% set total_seconds = (end - start).total_seconds() | round(2) %}
{{ dbt_utils.log_info(message_prefix ~ " Finished " ~ relation_to_vacuum ~ " in " ~ total_seconds ~ "s") }}
{% else %}
{{ dbt_utils.log_info(message_prefix ~ ' Skipping relation "' ~ row.values() | join ('"."') ~ '" as it does not exist') }}
{% endif %}
{% endfor %}
{% endmacro %}
DBT Cloud
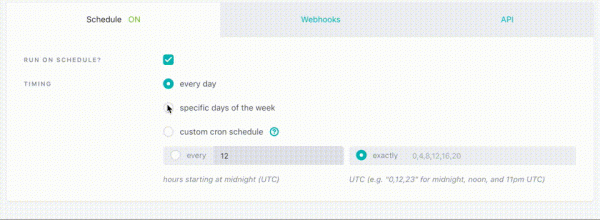
Ka një mundësi për të përdorur DBT si shërbim (Managed Service). Në paketë:
- Web IDE për zhvillimin e projekteve dhe modeleve
- Konfigurimi i punëve dhe vendosja në orar
- Qasje e thjeshtë dhe e convenient në logje
- Webfaqja me dokumentacionin e projektit tuaj
- Pjesa e vazhdueshme CI (Integrimi i Vazhdueshëm)
Përfundimi
Të përgatisësh dhe konsumosh DWH bëhet po aq e këndshme dhe e dobishme sa të pish një smoothie. DBT përbëhet nga Jinja, zgjerime të personalizuara (module), përpunues, motor (executor) dhe menaxher paketash. Duke i bashkuar këto elemente, merrni një mjedis të plotë pune për Depositet e Dhënash. Sot, është e vështirë të gjejmë një mënyrë më të mirë për menaxhimin e transformimeve brenda DWH.

Besimet që kanë ndjekur zhvilluesit e DBT janë formuluar kështu:
- Kød-i, dhe jo GUI, është abstraksioni më i mirë për të shprehur logjikën komplekse analitike
- Puna me të dhënat duhet të adaptohet sipas praktikave më të mira të zhvillimit të softuerit (Software Engineering)
- Infrastruktura më e rëndësishme për punën me të dhënat duhet të kontrollohet nga komuniteti i përdoruesve si softuer me burim të hapur
- Jo vetëm mjetet analitike, por edhe kodet gjithnjë e më shumë do të bëhen pronësi e komunitetit Open Source
Këto besime thelbësore prodhuan një produkt, i cili sot përdoret nga më shumë se 850 kompani, dhe përbëjnë bazën e shumë zgjerimeve interesante që do të krijohen në të ardhmen.
Për ata që janë të interesuar, ka një regjistrim video të një leksioni të hapur që kam mbajtur disa muaj më parë në kuadër të një leksioni të hapur në OTUS — .
Përveç DBT dhe Depozitave të Dhënash, në kuadër të kursit Data Engineer në platformën OTUS, unë dhe kolegët e mi udhëheqim mësime mbi një sërë temash të tjera aktuale dhe moderne:
- Konceptet arkitekturore të aplikacioneve të Dhënave të Mëdha
- Praktika me Spark dhe Spark Streaming
- Studimi i mënyrave dhe mjeteve për ngarkimin e burimeve të dhënash
- Ndërtimi i dritareve analitike në DWH
- Konceptet NoSQL: HBase, Cassandra, ElasticSearch
- Principet e organizimit të monitorimit dhe orkestrimit
- Projekti Final: mblidhen të gjitha aftësitë nën mbështetje mentorike
Linket:
- — Dokumentacioni zyrtar
- — Një artikull përmbledhës nga një nga autorët e DBT
- — YouTube, Regjistrimi i leksionit të hapur në OTUS
- — Leksioni i hapur më 15 maj 2020
- — OTUS
- — Pamja për të ardhmen e punës me të dhëna dhe analitikën
- — Evolucioni i analitikës dhe ndikimi i Burimit të Hapur
- — Parimet e ndërtimit të CI duke përdorur DBT
- — Praktike, Udhëzime hap pas hapi për punë të vetme
- — Github, kodi i projektit mësimor
Burimi: habr.com
