


SQL, çfarë mund të jetë më e thjeshtë? Secili prej nesh mund të shkruajë një kërkesë të thjeshtë - ne shtypim zgjidhni, listoni kolonat e kërkuara, më pas nga, emri i tabelës, disa kushte në ku dhe kjo është e gjitha - të dhëna të dobishme janë në xhepin tonë, dhe (pothuajse) pavarësisht se cila DBMS është nën kapuç në atë kohë (ose ndoshta ). Si rezultat, puna me pothuajse çdo burim të dhënash (relativ dhe jo aq) mund të konsiderohet nga pikëpamja e kodit të zakonshëm (me gjithçka që nënkupton - kontrolli i versionit, rishikimi i kodit, analiza statike, autotestet dhe kjo është e gjitha). Dhe kjo vlen jo vetëm për vetë të dhënat, skemat dhe migrimet, por në përgjithësi për të gjithë jetën e ruajtjes. Në këtë artikull do të flasim për detyrat e përditshme dhe problemet e punës me baza të të dhënave të ndryshme nën thjerrëzën e "bazës së të dhënave si kod".
Dhe le të fillojmë nga . Betejat e para të tipit "SQL vs ORM" u vunë re përsëri .
Harta objekt-relacionale
Mbështetësit e ORM tradicionalisht vlerësojnë shpejtësinë dhe lehtësinë e zhvillimit, pavarësinë nga DBMS dhe kodin e pastër. Për shumë prej nesh, kodi për të punuar me bazën e të dhënave (dhe shpesh vetë bazën e të dhënave)
zakonisht duket diçka si kjo ...
@Entity
@Table(name = "stock", catalog = "maindb", uniqueConstraints = {
@UniqueConstraint(columnNames = "STOCK_NAME"),
@UniqueConstraint(columnNames = "STOCK_CODE") })
public class Stock implements java.io.Serializable {
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "STOCK_ID", unique = true, nullable = false)
public Integer getStockId() {
return this.stockId;
}
...Modeli është i varur me shënime të zgjuara, dhe diku prapa skenave një ORM trim gjeneron dhe ekzekuton tonelata të disa kodeve SQL. Nga rruga, zhvilluesit po përpiqen të izolohen nga databaza e tyre me kilometra abstraksione, gjë që tregon disa .
Në anën tjetër të barrikadave, adhuruesit e SQL-së së pastër "të punuar me dorë" vërejnë aftësinë për të shtrydhur të gjithë lëngun nga DBMS-ja e tyre pa shtresa dhe abstraksione shtesë. Si rezultat, shfaqen projekte "të përqendruara në të dhënat", ku njerëz të trajnuar posaçërisht përfshihen në bazën e të dhënave (ata janë gjithashtu "bazikë", ata janë gjithashtu "bazikë", ata janë gjithashtu "bazdenues", etj.) dhe zhvilluesit mjafton të “tërheqësh” pamjet e gatshme dhe procedurat e ruajtura, pa hyrë në detaje.
Po sikur të kishim më të mirën nga të dyja botët? Si bëhet kjo në një mjet të mrekullueshëm me një emër që pohon jetën . Unë do të jap disa rreshta nga koncepti i përgjithshëm në përkthimin tim falas, dhe ju mund të njiheni më hollësisht me të .
Clojure është një gjuhë e lezetshme për krijimin e DSL-ve, por vetë SQL është një DSL e lezetshme, dhe ne nuk kemi nevojë për një tjetër. Shprehjet S janë të shkëlqyera, por nuk shtojnë asgjë të re këtu. Si rezultat, ne marrim kllapa për hir të kllapave. Nuk jeni dakord? Pastaj prisni momentin kur abstraksioni mbi bazën e të dhënave fillon të rrjedhë dhe ju filloni të luftoni me funksionin (raw-sql)
Pra, çfarë duhet të bëj? Le ta lëmë SQL si SQL të rregullt - një skedar për kërkesë:
-- name: users-by-country
select *
from users
where country_code = :country_code... dhe më pas lexoni këtë skedar, duke e kthyer atë në një funksion të rregullt Clojure:
(defqueries "some/where/users_by_country.sql"
{:connection db-spec})
;;; A function with the name `users-by-country` has been created.
;;; Let's use it:
(users-by-country {:country_code "GB"})
;=> ({:name "Kris" :country_code "GB" ...} ...)Duke iu përmbajtur parimit "SQL në vetvete, Clojure në vetvete", ju merrni:
- Asnjë surprizë sintaksore. Baza e të dhënave juaj (si çdo tjetër) nuk është 100% në përputhje me standardin SQL - por kjo nuk ka rëndësi për Yesql. Ju kurrë nuk do të humbni kohë duke kërkuar funksione me sintaksë ekuivalente SQL. Nuk do t'ju duhet kurrë të ktheheni në një funksion (raw-sql "disa('funky'::SYNTAX)")).
- Mbështetja më e mirë e redaktorit. Redaktori juaj tashmë ka mbështetje të shkëlqyer SQL. Duke ruajtur SQL si SQL, thjesht mund ta përdorni.
- Pajtueshmëria e ekipit. DBA-të tuaja mund të lexojnë dhe shkruajnë SQL që përdorni në projektin tuaj Clojure.
- Akordim më i lehtë i performancës. Keni nevojë për të ndërtuar një plan për një pyetje problematike? Ky nuk është problem kur pyetja juaj është SQL e rregullt.
- Ripërdorimi i pyetjeve. Tërhiqni dhe lëshoni të njëjtët skedarë SQL në projekte të tjera sepse është thjesht SQL e vjetër - thjesht ndajeni atë.
Për mendimin tim, ideja është shumë e lezetshme dhe në të njëjtën kohë shumë e thjeshtë, falë së cilës projekti ka fituar shumë në një sërë gjuhësh. Dhe më pas do të përpiqemi të aplikojmë një filozofi të ngjashme të ndarjes së kodit SQL nga çdo gjë tjetër përtej ORM-së.
Menaxherët e IDE dhe DB
Le të fillojmë me një detyrë të thjeshtë të përditshme. Shpesh duhet të kërkojmë disa objekte në bazën e të dhënave, për shembull, të gjejmë një tabelë në skemë dhe të studiojmë strukturën e saj (çfarë kolona, çelësa, indekse, kufizime, etj. janë përdorur). Dhe nga çdo IDE grafike ose një menaxher i vogël DB, para së gjithash, ne presim pikërisht këto aftësi. Në mënyrë që të jetë i shpejtë dhe të mos prisni gjysmë ore derisa të vizatohet një dritare me informacionin e nevojshëm (veçanërisht me një lidhje të ngadaltë me një bazë të dhënash në distancë), dhe në të njëjtën kohë, informacioni i marrë të jetë i freskët dhe i përshtatshëm, dhe jo junk të ruajtura në memorie. Për më tepër, sa më komplekse dhe më e madhe të jetë baza e të dhënave dhe sa më i madh të jetë numri i tyre, aq më e vështirë është ta bësh këtë.
Por zakonisht e hedh miun dhe thjesht shkruaj kodin. Le të themi se duhet të zbuloni se cilat tabela (dhe me cilat veti) përfshihen në skemën "HR". Në shumicën e DBMS-ve, rezultati i dëshiruar mund të arrihet me këtë pyetje të thjeshtë nga information_schema:
select table_name
, ...
from information_schema.tables
where schema = 'HR'Nga baza e të dhënave në bazën e të dhënave, përmbajtja e tabelave të tilla referente ndryshon në varësi të aftësive të çdo DBMS. Dhe, për shembull, për MySQL, nga i njëjti libër referencë mund të merrni parametrat e tabelës specifike për këtë DBMS:
select table_name
, storage_engine -- Используемый "движок" ("MyISAM", "InnoDB" etc)
, row_format -- Формат строки ("Fixed", "Dynamic" etc)
, ...
from information_schema.tables
where schema = 'HR'Oracle nuk e njeh Information_schema, por e njeh , dhe nuk lindin probleme të mëdha:
select table_name
, pct_free -- Минимум свободного места в блоке данных (%)
, pct_used -- Минимум используемого места в блоке данных (%)
, last_analyzed -- Дата последнего сбора статистики
, ...
from all_tables
where owner = 'HR'ClickHouse nuk bën përjashtim:
select name
, engine -- Используемый "движок" ("MergeTree", "Dictionary" etc)
, ...
from system.tables
where database = 'HR'Diçka e ngjashme mund të bëhet në Cassandra (e cila ka familje kolonash në vend të tabelave dhe hapësira kyçe në vend të skemave):
select columnfamily_name
, compaction_strategy_class -- Стратегия сборки мусора
, gc_grace_seconds -- Время жизни мусора
, ...
from system.schema_columnfamilies
where keyspace_name = 'HR'Për shumicën e bazave të të dhënave të tjera, ju gjithashtu mund të dilni me pyetje të ngjashme (madje edhe Mongo ka , i cili përmban informacion për të gjitha koleksionet në sistem).
Sigurisht, në këtë mënyrë mund të merrni informacion jo vetëm për tabelat, por për çdo objekt në përgjithësi. Herë pas here, njerëz të sjellshëm ndajnë një kod të tillë për baza të të dhënave të ndryshme, si, për shembull, në serinë e artikujve habra "Funksionet për dokumentimin e bazave të të dhënave PostgreSQL" (, , ). Sigurisht, mbajtja e gjithë këtij mali pyetjesh në kokën time dhe shtypja e tyre vazhdimisht është një kënaqësi e madhe, kështu që në IDE/redaktorin tim të preferuar kam një grup fragmentesh të përgatitura paraprakisht për pyetjet e përdorura shpesh, dhe gjithçka që mbetet është të shtypni emrat e objekteve në shabllon.
Si rezultat, kjo metodë e lundrimit dhe kërkimit të objekteve është shumë më fleksibël, kursen shumë kohë dhe ju lejon të merrni saktësisht informacionin në formën në të cilën është tani e nevojshme (si, për shembull, përshkruhet në postim ).
Operacionet me objekte
Pasi të kemi gjetur dhe studiuar objektet e nevojshme, është koha të bëjmë diçka të dobishme me to. Natyrisht, edhe pa hequr gishtat nga tastiera.
Nuk është sekret që thjesht fshirja e një tabele do të duket e njëjtë në pothuajse të gjitha bazat e të dhënave:
drop table hr.personsPor me krijimin e tabelës bëhet më interesante. Pothuajse çdo DBMS (duke përfshirë shumë NoSQL) mund të "krijojë tabelë" në një formë ose në një tjetër, dhe pjesa kryesore e saj madje do të ndryshojë pak (emri, lista e kolonave, llojet e të dhënave), por detajet e tjera mund të ndryshojnë në mënyrë dramatike dhe varen nga pajisje e brendshme dhe aftësitë e një DBMS specifike. Shembulli im i preferuar është se në dokumentacionin e Oracle ka vetëm BNF "të zhveshur" për sintaksën "krijo tabelën". . DBMS-të e tjera kanë aftësi më modeste, por secila prej tyre gjithashtu ka shumë karakteristika interesante dhe unike për krijimin e tabelave (, , , ). Nuk ka gjasa që ndonjë "magjistar" grafik nga një IDE tjetër (sidomos një universal) të jetë në gjendje t'i mbulojë plotësisht të gjitha këto aftësi, dhe edhe nëse mundet, nuk do të jetë një spektakël për njerëzit e dobët. Në të njëjtën kohë, një deklaratë e shkruar saktë dhe në kohë krijoni tabelën do t'ju lejojë t'i përdorni lehtësisht të gjitha, ta bëni ruajtjen dhe aksesin në të dhënat tuaja të besueshme, optimale dhe sa më komode.
Gjithashtu, shumë DBMS kanë llojet e tyre specifike të objekteve që nuk janë të disponueshme në DBMS të tjera. Për më tepër, ne mund të kryejmë operacione jo vetëm në objektet e bazës së të dhënave, por edhe në vetë DBMS, për shembull, "të vrasim" një proces, të çlirojmë një zonë memorie, të aktivizojmë gjurmimin, të kalojmë në modalitetin "vetëm lexim" dhe shumë më tepër.
Tani le të vizatojmë pak
Një nga detyrat më të zakonshme është të ndërtoni një diagram me objektet e bazës së të dhënave dhe të shihni objektet dhe lidhjet midis tyre në një pamje të bukur. Pothuajse çdo IDE grafike, shërbime të veçanta të "vijës së komandës", mjete të specializuara grafike dhe modelues mund ta bëjnë këtë. Ata do të vizatojnë diçka për ju "siç munden" dhe ju mund të ndikoni pak në këtë proces vetëm me ndihmën e disa parametrave në skedarin e konfigurimit ose kutitë e kontrollit në ndërfaqe.
Por ky problem mund të zgjidhet shumë më thjeshtë, më fleksibël dhe elegant, dhe sigurisht me ndihmën e kodit. Për të krijuar diagrame të çdo kompleksiteti, ne kemi disa gjuhë të specializuara markup (DOT, GraphML etj), dhe për to një shpërndarje të tërë aplikacionesh (GraphViz, PlantUML, Mermaid) që mund të lexojnë udhëzime të tilla dhe t'i vizualizojnë ato në një sërë formatesh. . Epo, ne tashmë dimë se si të marrim informacione për objektet dhe lidhjet midis tyre.
Këtu është një shembull i vogël se si mund të duket kjo, duke përdorur PlantUML dhe (në të majtë është një pyetje SQL që do të gjenerojë instruksionin e kërkuar për PlantUML, dhe në të djathtë është rezultati):
select '@startuml'||chr(10)||'hide methods'||chr(10)||'hide stereotypes' union all
select distinct ccu.table_name || ' --|> ' ||
tc.table_name as val
from table_constraints as tc
join key_column_usage as kcu
on tc.constraint_name = kcu.constraint_name
join constraint_column_usage as ccu
on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and tc.table_name ~ '.*' union all
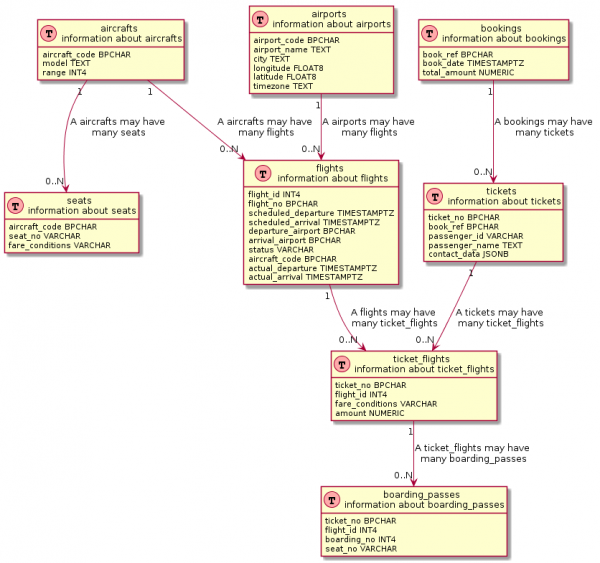
select '@enduml'Dhe nëse provoni pak, atëherë bazuar në ju mund të merrni diçka shumë të ngjashme me një diagram të vërtetë ER:
Pyetja SQL është pak më e komplikuar
-- Шапка
select '@startuml
!define Table(name,desc) class name as "desc" << (T,#FFAAAA) >>
!define primary_key(x) <b>x</b>
!define unique(x) <color:green>x</color>
!define not_null(x) <u>x</u>
hide methods
hide stereotypes'
union all
-- Таблицы
select format('Table(%s, "%s n information about %s") {'||chr(10), table_name, table_name, table_name) ||
(select string_agg(column_name || ' ' || upper(udt_name), chr(10))
from information_schema.columns
where table_schema = 'public'
and table_name = t.table_name) || chr(10) || '}'
from information_schema.tables t
where table_schema = 'public'
union all
-- Связи между таблицами
select distinct ccu.table_name || ' "1" --> "0..N" ' || tc.table_name || format(' : "A %s may haven many %s"', ccu.table_name, tc.table_name)
from information_schema.table_constraints as tc
join information_schema.key_column_usage as kcu on tc.constraint_name = kcu.constraint_name
join information_schema.constraint_column_usage as ccu on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and ccu.constraint_schema = 'public'
and tc.table_name ~ '.*'
union all
-- Подвал
select '@enduml'
Nëse shikoni nga afër, nën kapuç, shumë mjete vizualizimi përdorin gjithashtu pyetje të ngjashme. Vërtetë, këto kërkesa janë zakonisht të thella , për të mos përmendur ndonjë modifikim të tyre.
Metrika dhe monitorimi
Le të kalojmë te një temë tradicionalisht komplekse - monitorimi i performancës së bazës së të dhënave. Më kujtohet një histori e vogël e vërtetë që më tregoi "një nga miqtë e mi". Në një projekt tjetër jetonte një DBA e caktuar e fuqishme, dhe pak nga zhvilluesit e njihnin personalisht, ose e kishin parë ndonjëherë personalisht (pavarësisht nga fakti se, sipas thashethemeve, ai punonte diku në ndërtesën tjetër). Në orën "X", kur sistemi i prodhimit të një shitësi të madh filloi të "ndihej keq" edhe një herë, ai dërgoi në heshtje pamjet e grafikëve nga Oracle Enterprise Manager, në të cilat ai theksoi me kujdes vendet kritike me një shënues të kuq për "kuptueshmëri" ( kjo, për ta thënë butë, nuk ndihmoi shumë). Dhe bazuar në këtë "kartë fotografike" më duhej të trajtoja. Në të njëjtën kohë, askush nuk kishte qasje në menaxherin e çmuar (në të dy kuptimet e fjalës) të Ndërmarrjes, sepse sistemi është kompleks dhe i shtrenjtë, papritmas "zhvilluesit pengohen në diçka dhe thyejnë gjithçka". Prandaj, zhvilluesit "empirikisht" gjetën vendndodhjen dhe shkakun e frenave dhe lëshuan një copëz. Nëse letra kërcënuese nga DBA nuk do të mbërrinte përsëri në të ardhmen e afërt, atëherë të gjithë do të merrnin frymë të lehtësuar dhe do të ktheheshin në detyrat e tyre aktuale (deri në Letrën e re).
Por procesi i monitorimit mund të duket më argëtues dhe miqësor, dhe më e rëndësishmja, i aksesueshëm dhe transparent për të gjithë. Të paktën pjesa e tij bazë, si një shtesë në sistemet kryesore të monitorimit (të cilat sigurisht janë të dobishme dhe në shumë raste të pazëvendësueshme). Çdo DBMS është lirisht dhe absolutisht pa pagesë për të ndarë informacione rreth gjendjes dhe performancës së tij aktuale. Në të njëjtën Oracle DB "të përgjakshme", pothuajse çdo informacion rreth performancës mund të merret nga pamjet e sistemit, duke filluar nga proceset dhe sesionet deri te gjendja e cache-it të tamponit (për shembull, , seksioni "Monitorimi"). Postgresql gjithashtu ka një mori pamjesh të sistemit për , në veçanti ato që janë të domosdoshme në jetën e përditshme të çdo DBA, si p.sh , , . MySQL madje ka një skemë të veçantë për këtë. . Një In Mongo i integruar grumbullon të dhënat e performancës në një koleksion të sistemit .
Kështu, të armatosur me një lloj koleksionisti metrikë (Telegraf, Metricbeat, Collectd) që mund të kryejë pyetje të personalizuara sql, një ruajtje të këtyre metrikave (InfluxDB, Elasticsearch, Timescaledb) dhe një vizualizues (Grafana, Kibana), mund të merrni një dhe një sistem monitorimi fleksibël që do të integrohet ngushtë me metrika të tjera në të gjithë sistemin (të marra, për shembull, nga serveri i aplikacionit, nga OS, etj.). Si, për shembull, kjo bëhet në pgwatch2, e cila përdor kombinimin InfluxDB + Grafana dhe një grup pyetjesh për pamjet e sistemit, të cilat gjithashtu mund të aksesohen .
Në total
Dhe kjo është vetëm një listë e përafërt e asaj që mund të bëhet me bazën tonë të të dhënave duke përdorur kodin e rregullt SQL. Jam i sigurt se mund të gjeni shumë përdorime të tjera, shkruani në komente. Dhe ne do të flasim se si (dhe më e rëndësishmja pse) ta automatizojmë të gjithë këtë dhe ta përfshijmë atë në tubacionin tuaj CI/CD herën tjetër.
Burimi: www.habr.com
