

DataHub me burim të hapur: Platforma e kërkimit dhe zbulimit të meta të dhënave të LinkedIn
Gjetja e shpejtë e të dhënave që ju nevojiten është thelbësore për çdo kompani që mbështetet në sasi të mëdha të dhënash për të marrë vendime të bazuara në të dhëna. Kjo jo vetëm që ndikon në produktivitetin e përdoruesve të të dhënave (përfshirë analistët, zhvilluesit e mësimit të makinerive, shkencëtarët e të dhënave dhe inxhinierët e të dhënave), por gjithashtu ka një ndikim të drejtpërdrejtë në produktet përfundimtare që varen nga një tubacion cilësor i mësimit të makinerive (ML). Për më tepër, tendenca drejt zbatimit ose ndërtimit të platformave të mësimit të makinerive ngre natyrshëm pyetjen: cila është metoda juaj për zbulimin e brendshëm të veçorive, modeleve, metrikave, grupeve të të dhënave, etj.
Në këtë artikull do të flasim se si kemi publikuar një burim të dhënash nën një licencë të hapur në platformën tonë të kërkimit dhe zbulimit të meta të dhënave, duke filluar nga ditët e para të projektit . LinkedIn ruan versionin e vet të DataHub veçmas nga versioni me burim të hapur. Ne do të fillojmë duke shpjeguar pse na duhen dy mjedise të veçanta zhvillimi, më pas do të diskutojmë qasjet e hershme për përdorimin e burimit të hapur WhereHows dhe do të krahasojmë versionin tonë të brendshëm (prodhues) të DataHub me versionin në . Ne do të ndajmë gjithashtu detaje rreth zgjidhjes sonë të re të automatizuar për nxitjen dhe marrjen e përditësimeve me burim të hapur për t'i mbajtur të dy depot të sinkronizuara. Së fundi, ne do të ofrojmë udhëzime se si të filloni të përdorni DataHub me burim të hapur dhe të diskutojmë shkurtimisht arkitekturën e tij.

WhereHows është tani një DataHub!
Ekipi i meta të dhënave të LinkedIn u prezantua më parë (pasardhës i WhereHows), platforma e kërkimit dhe zbulimit të meta të dhënave të LinkedIn dhe planet e përbashkëta për ta hapur atë. Menjëherë pas këtij njoftimi, ne lëshuam një version alfa të DataHub dhe e ndamë atë me komunitetin. Që atëherë, ne kemi kontribuar vazhdimisht në depo dhe kemi punuar me përdoruesit e interesuar për të shtuar veçoritë më të kërkuara dhe për të zgjidhur problemet. Tani jemi të kënaqur të njoftojmë publikimin zyrtar .
Qasjet me burim të hapur
WhereHows, portali origjinal i LinkedIn për gjetjen e të dhënave dhe nga vijnë ato, filloi si një projekt i brendshëm; Ekipi i meta të dhënave e hapi atë . Që atëherë, ekipi ka mbajtur gjithmonë dy baza të ndryshme kodesh - një për burim të hapur dhe një për përdorim të brendshëm të LinkedIn - pasi jo të gjitha veçoritë e produktit të zhvilluara për rastet e përdorimit të LinkedIn ishin përgjithësisht të zbatueshme për audiencën më të gjerë. Për më tepër, WhereHows ka disa varësi të brendshme (infrastrukturë, biblioteka, etj.) që nuk janë me burim të hapur. Në vitet që pasuan, WhereHows kaloi nëpër shumë përsëritje dhe cikle zhvillimi, duke e bërë mbajtjen e dy bazave të kodeve në një sfidë të madhe. Ekipi i meta të dhënave ka provuar qasje të ndryshme gjatë viteve në përpjekje për të mbajtur të sinkronizuar zhvillimin e brendshëm dhe të burimit të hapur.
Provoni së pari: "Së pari me burim të hapur"
Fillimisht ndoqëm një model zhvillimi "së pari me burim të hapur", ku shumica e zhvillimit ndodh në një depo me burim të hapur dhe ndryshimet bëhen për vendosjen e brendshme. Problemi me këtë qasje është se kodi gjithmonë shtyhet fillimisht në GitHub përpara se të rishikohet plotësisht nga brenda. Derisa të bëhen ndryshime nga depoja me burim të hapur dhe të bëhet një vendosje e re e brendshme, nuk do të gjejmë asnjë problem prodhimi. Në rast të vendosjes së dobët, ishte gjithashtu shumë e vështirë për të përcaktuar fajtorin, sepse ndryshimet u bënë në grupe.
Për më tepër, ky model uli produktivitetin e ekipit kur zhvillonte veçori të reja që kërkonin përsëritje të shpejta, pasi detyroi të gjitha ndryshimet të shtyheshin fillimisht në një depo me burim të hapur dhe më pas të shtyheshin në një depo të brendshme. Për të reduktuar kohën e përpunimit, rregullimi ose ndryshimi i kërkuar mund të bëhej fillimisht në depon e brendshme, por ky u bë një problem i madh kur erdhi puna për bashkimin e atyre ndryshimeve përsëri në depo me burim të hapur, sepse të dy depot ishin jashtë sinkronizimit.
Ky model është shumë më i lehtë për t'u zbatuar për platforma të përbashkëta, biblioteka ose projekte infrastrukturore sesa për aplikacione të personalizuara në internet me funksione të plota. Për më tepër, ky model është ideal për projektet që fillojnë me burim të hapur që nga dita e parë, por WhereHows u ndërtua si një aplikacion plotësisht i brendshëm në internet. Ishte me të vërtetë e vështirë për të abstraktuar plotësisht të gjitha varësitë e brendshme, kështu që na duhej të ruanim pirunin e brendshëm, por mbajtja e pirunit të brendshëm dhe zhvillimi kryesisht i burimit të hapur nuk funksionoi fare.
Përpjekja e dytë: "E brendshme së pari"
**Si një përpjekje e dytë, ne kaluam në një model zhvillimi "të parë të brendshëm", ku shumica e zhvillimit ndodh brenda dhe ndryshimet bëhen rregullisht në kodin me burim të hapur. Megjithëse ky model është më i përshtatshmi për rastin tonë të përdorimit, ai ka probleme të qenësishme. Shtyrja e drejtpërdrejtë e të gjitha dallimeve në depo me burim të hapur dhe më pas përpjekja për të zgjidhur konfliktet e bashkimit më vonë është një opsion, por kërkon kohë. Zhvilluesit në shumicën e rasteve përpiqen të mos e bëjnë këtë sa herë që rishikojnë kodin e tyre. Si rezultat, kjo do të bëhet shumë më rrallë, në grupe, dhe kështu e bën më të vështirë zgjidhjen e konflikteve të bashkimit më vonë.
Herën e tretë funksionoi!
Dy përpjekjet e dështuara të përmendura më sipër rezultuan që depoja WhereHows GitHub të mbetet e vjetëruar për një kohë të gjatë. Ekipi vazhdoi të përmirësonte veçoritë dhe arkitekturën e produktit, në mënyrë që versioni i brendshëm i WhereHows për LinkedIn u bë më i avancuar se versioni me burim të hapur. Madje kishte një emër të ri - DataHub. Bazuar në përpjekjet e mëparshme të dështuara, ekipi vendosi të zhvillojë një zgjidhje të shkallëzuar dhe afatgjatë.
Për çdo projekt të ri me burim të hapur, ekipi i LinkedIn me burim të hapur këshillon dhe mbështet një model zhvillimi në të cilin modulet e projektit zhvillohen tërësisht në burim të hapur. Artefaktet e versionuara vendosen në një depo publike dhe më pas kontrollohen përsëri në artifaktin e brendshëm të LinkedIn duke përdorur . Ndjekja e këtij modeli zhvillimi nuk është vetëm e mirë për ata që përdorin burim të hapur, por gjithashtu rezulton në një arkitekturë më modulare, të zgjerueshme dhe të lidhshme.
Megjithatë, një aplikacion i pjekur në fund të fundit si DataHub do të kërkojë një kohë të konsiderueshme për të arritur këtë gjendje. Kjo gjithashtu përjashton mundësinë e një zbatimi plotësisht funksional me burim të hapur përpara se të gjitha varësitë e brendshme të jenë abstraguar plotësisht. Kjo është arsyeja pse ne kemi zhvilluar mjete që na ndihmojnë të bëjmë kontribute me burim të hapur më shpejt dhe me shumë më pak dhimbje. Kjo zgjidhje përfiton si ekipin e meta të dhënave (zhvilluesi i DataHub) ashtu edhe komunitetin me burim të hapur. Seksionet në vijim do të diskutojnë këtë qasje të re.
Automatizimi i botimit me burim të hapur
Qasja më e fundit e ekipit të Metadata ndaj DataHub me burim të hapur është të zhvillojë një mjet që sinkronizon automatikisht bazën e brendshme të kodeve dhe depon me burim të hapur. Karakteristikat e nivelit të lartë të kësaj pakete mjetesh përfshijnë:
- Sinkronizoni kodin LinkedIn me/nga burimi i hapur, i ngjashëm .
- Gjenerimi i titullit të licencës, i ngjashëm me .
- Krijoni automatikisht regjistrat e kryerjes me burim të hapur nga regjistrat e brendshëm të kryerjes.
- Parandaloni ndryshimet e brendshme që prishin ndërtimet me burim të hapur .
Nënseksionet e mëposhtme do të thellohen në funksionet e përmendura më sipër, të cilat kanë probleme interesante.
Sinkronizimi i kodit burimor
Ndryshe nga versioni me burim të hapur të DataHub, i cili është një depo e vetme GitHub, versioni LinkedIn i DataHub është një kombinim i depove të shumta (të quajtura brenda ). Ndërfaqja DataHub, biblioteka e modelit të meta të dhënave, shërbimi mbështetës i magazinës së meta të dhënave dhe punët e transmetimit qëndrojnë në depo të veçanta në LinkedIn. Megjithatë, për ta bërë më të lehtë për përdoruesit me burim të hapur, ne kemi një depo të vetme për versionin me burim të hapur të DataHub.
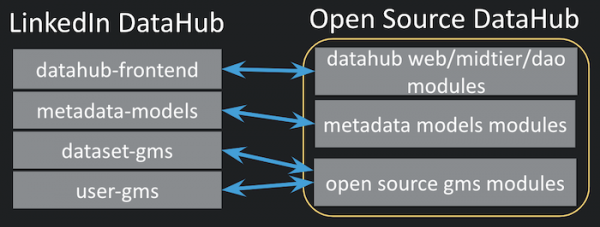
Figura 1: Sinkronizimi ndërmjet depove LinkedIn DataHub dhe një depo të vetme DataHub burim i hapur
Për të mbështetur flukset e automatizuara të ndërtimit, shtytjes dhe tërheqjes së punës, mjeti ynë i ri krijon automatikisht një hartë në nivel skedari që korrespondon me çdo skedar burimor. Megjithatë, paketa e veglave kërkon konfigurim fillestar dhe përdoruesit duhet të ofrojnë një hartë të modulit të nivelit të lartë siç tregohet më poshtë.
{
"datahub-dao": [
"${datahub-frontend}/datahub-dao"
],
"gms/impl": [
"${dataset-gms}/impl",
"${user-gms}/impl"
],
"metadata-dao": [
"${metadata-models}/metadata-dao"
],
"metadata-builders": [
"${metadata-models}/metadata-builders"
]
}Hartëzimi i nivelit të modulit është një JSON i thjeshtë, çelësat e të cilit janë modulet e synuara në depon me burim të hapur dhe vlerat janë lista e moduleve burimore në depot e LinkedIn. Çdo modul objektiv në një depo me burim të hapur mund të ushqehet nga çdo numër modulesh me burim. Për të treguar emrat e brendshëm të depove në modulet burimore, përdorni në stilin Bash. Duke përdorur një skedar të hartës së nivelit të modulit, mjetet krijojnë një skedar hartografie të nivelit të skedarit duke skanuar të gjithë skedarët në drejtoritë e lidhura.
{
"${metadata-models}/metadata-builders/src/main/java/com/linkedin/Foo.java":
"metadata-builders/src/main/java/com/linkedin/Foo.java",
"${metadata-models}/metadata-builders/src/main/java/com/linkedin/Bar.java":
"metadata-builders/src/main/java/com/linkedin/Bar.java",
"${metadata-models}/metadata-builders/build.gradle": null,
}Hartëzimi i nivelit të skedarit krijohet automatikisht nga mjetet; megjithatë, ai gjithashtu mund të përditësohet manualisht nga përdoruesi. Ky është një hartë 1:1 e një skedari burimor të LinkedIn në një skedar në depon me burim të hapur. Ekzistojnë disa rregulla që lidhen me këtë krijim automatik të lidhjeve të skedarëve:
- Në rastin e moduleve me burim të shumëfishtë për një modul të synuar në burim të hapur, mund të lindin konflikte, p.sh. , që ekziston në më shumë se një modul burimor. Si një strategji për zgjidhjen e konflikteve, veglat tona parazgjedhojnë opsionin "fiton i fundit".
- "null" do të thotë që skedari burim nuk është pjesë e depove me burim të hapur.
- Pas çdo paraqitjeje ose nxjerrjeje me burim të hapur, kjo hartë përditësohet automatikisht dhe krijohet një fotografi. Kjo është e nevojshme për të identifikuar shtesat dhe fshirjet nga kodi burimor që nga veprimi i fundit.
Krijimi i regjistrave të kryerjes
Regjistrat e kryerjes për kryerjet me burim të hapur gjenerohen gjithashtu automatikisht duke bashkuar regjistrat e kryerjes së depove të brendshme. Më poshtë është një mostër e regjistrit të kryerjes për të treguar strukturën e regjistrit të kryerjes së krijuar nga mjeti ynë. Një commit tregon qartë se cilat versione të depove burimore janë të paketuara në atë commit dhe ofron një përmbledhje të regjistrit të kryerjes. Kontrolloni këtë duke përdorur një shembull real të një regjistri të kryerjes së krijuar nga paketa jonë e veglave.
metadata-models 29.0.0 -> 30.0.0
Added aspect model foo
Fixed issue bar
dataset-gms 2.3.0 -> 2.3.4
Added rest.li API to serve foo aspect
MP_VERSION=dataset-gms:2.3.4
MP_VERSION=metadata-models:30.0.0Testimi i varësisë
LinkedIn ka , e cila ndihmon për të siguruar që ndryshimet në një shumëprodukt të brendshëm të mos prishin montimin e shumëprodukteve të varur. Depoja me burim të hapur DataHub nuk është me shumë produkte dhe nuk mund të jetë një varësi e drejtpërdrejtë e ndonjë produkti me shumë produkte, por me ndihmën e një mbështjellësi me shumë produkte që merr kodin burimor të burimit të hapur të DataHub, ne mund ta përdorim përsëri këtë testim varësie Kështu, çdo ndryshim (i cili mund të ekspozohet më vonë) në cilindo prej multiprodukteve që ushqejnë depon e DataHub me burim të hapur shkakton një ngjarje ndërtimi në multiproduktin e guaskës. Prandaj, çdo ndryshim që nuk arrin të ndërtojë një produkt mbështjellës dështon në testet përpara se të kryejë produktin origjinal dhe rikthehet.
Ky është një mekanizëm i dobishëm që ndihmon në parandalimin e çdo angazhimi të brendshëm që thyen ndërtimin me burim të hapur dhe e zbulon atë në kohën e kryerjes. Pa këtë, do të ishte mjaft e vështirë të përcaktohej se cili kryerje e brendshme shkaktoi dështimin e ndërtimit të depove me burim të hapur, sepse ne grumbullojmë ndryshime të brendshme në depon me burim të hapur DataHub.
Dallimet midis DataHub me burim të hapur dhe versionit tonë të prodhimit
Deri në këtë pikë, ne kemi diskutuar zgjidhjen tonë për sinkronizimin e dy versioneve të depove të DataHub, por ende nuk kemi përshkruar arsyet pse na duhen në radhë të parë dy rrjedha të ndryshme zhvillimi. Në këtë seksion, ne do të listojmë ndryshimet midis versionit publik të DataHub dhe versionit të prodhimit në serverët e LinkedIn dhe do të shpjegojmë arsyet e këtyre dallimeve.
Një burim mospërputhjesh buron nga fakti se versioni ynë i prodhimit ka varësi nga kodi që nuk është ende me burim të hapur, siç është LinkedIn's Offspring (korniza e brendshme e injektimit të varësisë së LinkedIn). Offspring përdoret gjerësisht në bazat e brendshme të kodeve sepse është metoda e preferuar për menaxhimin e konfigurimit dinamik. Por nuk është me burim të hapur; kështu që na duhej të gjenim alternativa me burim të hapur ndaj DataHub me burim të hapur.
Ka edhe arsye të tjera. Ndërsa krijojmë shtesa për modelin e meta të dhënave për nevojat e LinkedIn, këto shtesa janë zakonisht shumë specifike për LinkedIn dhe mund të mos zbatohen drejtpërdrejt në mjedise të tjera. Për shembull, ne kemi etiketa shumë specifike për ID-të e pjesëmarrësve dhe lloje të tjera të meta të dhënave që përputhen. Pra, tani i kemi përjashtuar këto shtesa nga modeli i meta të dhënave me burim të hapur të DataHub. Ndërsa angazhohemi me komunitetin dhe kuptojmë nevojat e tyre, ne do të punojmë në versionet e zakonshme me burim të hapur të këtyre shtesave aty ku nevojitet.
Lehtësia e përdorimit dhe përshtatja më e lehtë për komunitetin me burim të hapur frymëzuan gjithashtu disa nga ndryshimet midis dy versioneve të DataHub. Dallimet në infrastrukturën e përpunimit të rrjedhës janë një shembull i mirë për këtë. Megjithëse versioni ynë i brendshëm përdor një kornizë të përpunimit të transmetimit të menaxhuar, ne zgjodhëm të përdorim përpunimin e integruar (të pavarur) të transmetimit për versionin me burim të hapur, sepse shmang krijimin e një varësie tjetër të infrastrukturës.
Një shembull tjetër i ndryshimit është të kesh një GMS të vetme (Generalized Metadata Store) në një implementim me burim të hapur dhe jo në shumë GMS. GMA (Generalized Metadata Architecture) është emri i arkitekturës së fundit për DataHub dhe GMS është ruajtja e meta të dhënave në kontekstin e GMA. GMA është një arkitekturë shumë fleksibël që ju lejon të shpërndani çdo konstrukt të dhënash (p.sh. grupet e të dhënave, përdoruesit, etj.) në ruajtjen e tij të meta të dhënave, ose të ruani konstruksione të shumta të dhënash në një ruajtje të vetme të meta të dhënave për sa kohë që regjistri që përmban hartën e strukturës së të dhënave në GMS është përditësuar. Për lehtësinë e përdorimit, ne zgjodhëm një shembull të vetëm GMS që ruan të gjitha konstruksionet e ndryshme të të dhënave në DataHub me burim të hapur.
Një listë e plotë e dallimeve midis dy zbatimeve është dhënë në tabelën më poshtë.
Features produktit
LinkedIn DataHub
DataHub me burim të hapur
Konstruksionet e të dhënave të mbështetura
1) Grupet e të dhënave 2) Përdoruesit 3) Metrikat 4) Veçoritë e ML 5) Grafikët 6) Paneli
1) Grupet e të dhënave 2) Përdoruesit
Burimet e mbështetura të meta të dhënave për grupet e të dhënave
1) 2) Baza e divanit 3) 4) 5) HDFS 6) Hive 7) Kafka 8) MongoDB 9) MySQL 10) Oracle 11) 12) Presto 12) 13) Teradata 13) Vektori 14)
Hive Kafka RDBMS
Pub-nën
Kafka konfluente
Përpunimi i rrjedhës
Managed
I integruar (i pavarur)
Injeksioni i varësisë dhe konfigurimi dinamik
LinkedIn Pasardhësit
Ndërtimi i veglave
Ligradle (mbështjellësi i brendshëm Gradle i LinkedIn)
CI / CD
CRT (CI/CD e brendshme e LinkedIn)
Dyqane metadata
GMS të shumëfishta të shpërndara: 1) GMS e grupit të të dhënave 2) GMS e përdoruesit 3) GMS metrike 4) GMS e veçorive 5) GMS grafiku/paneli
GMS e vetme për: 1) grupet e të dhënave 2) përdoruesit
Mikroshërbime në kontejnerët Docker
thjeshton vendosjen dhe shpërndarjen e aplikacionit me . Çdo pjesë e shërbimit në DataHub është me burim të hapur, duke përfshirë komponentët e infrastrukturës si Kafka, , и , ka imazhin e vet Docker. Për të orkestruar kontejnerët Docker kemi përdorur .
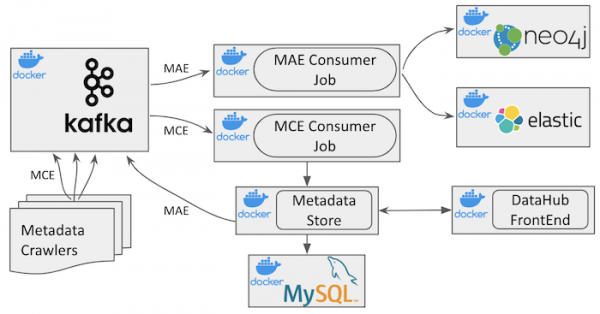
Figura 2: Arkitektura DataHub *burim i hapur**
Ju mund të shihni arkitekturën e nivelit të lartë të DataHub në imazhin e mësipërm. Përveç komponentëve të infrastrukturës, ai ka katër kontejnerë të ndryshëm Docker:
datahub-gms: shërbimi i ruajtjes së meta të dhënave
datahub-frontend: aplikacion , duke shërbyer ndërfaqen DataHub.
datahub-mce-consumer: aplikim , i cili përdor transmetimin e ngjarjes së ndryshimit të meta të dhënave (MCE) dhe përditëson ruajtjen e meta të dhënave.
datahub-mae-consumer: aplikim , i cili përdor një rrjedhë të ngjarjeve të auditimit të meta të dhënave (MAE) dhe krijon një indeks kërkimi dhe bazë të dhënash grafike.
Dokumentacioni i depove me burim të hapur dhe përmbajnë informacion më të detajuar në lidhje me funksionet e shërbimeve të ndryshme.
CI/CD në DataHub është me burim të hapur
Depoja me burim të hapur DataHub përdor për integrim të vazhdueshëm dhe për vendosje të vazhdueshme. Të dyja kanë integrim të mirë GitHub dhe janë të lehta për t'u konfiguruar. Për shumicën e infrastrukturës me kod të hapur të zhvilluar nga komuniteti ose kompanitë private (p.sh. ), Imazhet e Docker krijohen dhe vendosen në Docker Hub për lehtësinë e përdorimit nga komuniteti. Çdo imazh Docker i gjetur në Docker Hub mund të përdoret lehtësisht me një komandë të thjeshtë .
Me çdo angazhim në depon me burim të hapur DataHub, të gjitha imazhet e Docker ndërtohen automatikisht dhe vendosen në Docker Hub me etiketën "më të fundit". Nëse Docker Hub është konfiguruar me disa , të gjitha etiketat në depon me burim të hapur lëshohen gjithashtu me emrat përkatës të etiketave në Docker Hub.
Duke përdorur DataHub
është shumë e thjeshtë dhe përbëhet nga tre hapa të thjeshtë:
- Klononi depon me burim të hapur dhe ekzekutoni të gjithë kontejnerët Docker me docker-compose duke përdorur skriptin e dhënë docker-compose për një fillim të shpejtë.
- Shkarkoni mostrën e të dhënave të ofruara në depo duke përdorur mjetin e linjës së komandës që ofrohet gjithashtu.
- Shfletoni DataHub në shfletuesin tuaj.
Gjurmuar në mënyrë aktive konfiguruar gjithashtu për pyetje të shpejta. Përdoruesit gjithashtu mund të krijojnë probleme direkt në depon e GitHub. Më e rëndësishmja, ne mirëpresim dhe vlerësojmë të gjitha komentet dhe sugjerimet!
Planet për të ardhmen
Aktualisht, çdo infrastrukturë ose mikroshërbim për DataHub me burim të hapur është ndërtuar si një kontejner Docker dhe i gjithë sistemi është i orkestruar duke përdorur . Duke pasur parasysh popullaritetin dhe përhapjen , ne gjithashtu do të dëshironim të ofrojmë një zgjidhje të bazuar në Kubernetes në të ardhmen e afërt.
Ne gjithashtu planifikojmë të ofrojmë një zgjidhje me çelës në dorë për vendosjen e DataHub në një shërbim publik cloud, si p.sh , ose . Duke pasur parasysh njoftimin e fundit të migrimit të LinkedIn në Azure, kjo do të përputhet me prioritetet e brendshme të ekipit të meta të dhënave.
E fundit, por jo më pak e rëndësishme, falënderojmë të gjithë adoptuesit e hershëm të DataHub në komunitetin me burim të hapur, të cilët kanë vlerësuar alfat e DataHub dhe na kanë ndihmuar të identifikojmë problemet dhe të përmirësojmë dokumentacionin.
Burimi: www.habr.com
