


Duke qenë se ClickHouse është një sistem i specializuar, është e rëndësishme të merren parasysh karakteristikat e arkitekturës së tij gjatë përdorimit. Në këtë raport, Aleksej do të flasë për shembuj tipikë të gabimeve gjatë përdorimit të ClickHouse, të cilat mund të çojnë në punë të paefikase. Me shembuj nga praktika do të tregohen se si zgjedhja e një skeme të caktuar të përpunimit të të dhënave mund të ndryshojë ndjeshëm performancën.
Përshëndetje të gjithëve! Më quajnë Aleksej, unë merrem me ClickHouse.

Së pari, menjëherë dua t'ju gëzoj, nuk do t'ju tregoj sot se çfarë është ClickHouse. Me të vërtetë, më ka lodhur. Çdo herë e tregoj se çfarë është. Dhe, ndoshta, të gjithë tashmë e dinë.

Në vend të kësaj, do të flas për të gjitha grykat që mund të hasen, dmth se si mund të përdoret gabimisht ClickHouse. Në të vërtetë, nuk ka përse të keni frikë, sepse ne e zhvillojmë ClickHouse si një sistem që është i thjeshtë, i përshtatshëm, dhe funksionon menjëherë. E instalove dhe gjithçka shkon mirë, pa asnjë problem.
Megjithatë, është e rëndësishme të merret parasysh se kjo sistem është specializuar dhe mund të ndiheni lehtë në një skenar të pazakontë përdorimi, i cili do ta nxjerrë këtë sistem jashtë zonës së tij të komoditetit.
Pra, cilat janë pengesat? Në thelb, do të flas për gjëra të dukshme. Të gjithë e kuptojnë, të gjithë e dinë dhe mund të gëzohen që janë kaq të zgjuar, ndërsa ata që nuk kuptojnë, do të mësojnë diçka të re.

Një shembull shumë i thjeshtë, i cili, fatkeqësisht, ndodh shpesh, është numri i madh i insert-eve me batche të vogla, dmth. shumë insert-e të vogla.
Nëse shqyrtoni se si ClickHouse ekzekuton insert-in, mund të dërgoni një rrjedhë të dhënash deri në një terabajt në një kërkesë. Nuk është problem.
Le të shikojmë se cila do të jetë tipike performanca. Për shembull, ne kemi një tabelë me të dhënat e Yandex.Metrica. Hitet. 105 ndonjë kolonë. 700 byte në formë të pakompresuar. Dhe do të insertojmë, ashtu siç duhet, batche nga një milion rreshta.
Duke e futur në tabelën MergeTree, marrim gjysmë milioni rreshta në sekondë. Shumë mirë. Në tabelën e replikuar – do të jetë pak më e vogël, rreth 400,000 rreshta në sekondë.
Dhe nëse aktivizohet inserimi me kuorum, rezultati është pak më i ulët, por prapëseprapë një performancë e konsiderueshme, 250,000 në sekondë. Inserimi me kuorum – është një funksion i pa dokumentuar në ClickHouse*.
* sipas informacionit deri në vitin 2020, .

Çfarë ndodh nëse e bëjmë keq? Nëse futim një rresht në tabelën MergeTree, arrijmë 59 rreshta në sekondë. Kjo është 10,000 herë më e ngadaltë. Në ReplicatedMergeTree – 6 rreshta në sekondë. Dhe nëse aktivizohet kuorumi, arrijmë vetëm 2 rreshta në sekondë. Më duket se kjo është një situatë e papranueshme. Si mund të ngadalësohet kaq shumë? Edhe në bluzën time shkruan se ClickHouse nuk duhet të ngadalësojë. Por megjithatë, ndodhin ndonjëherë.

Në të vërtetë, kjo është një mangësi nga ana jonë. Ne mund ta kishim bërë që gjithçka të funksiononte mirë, por nuk e bëmë. Dhe nuk e bëmë sepse për skenarin tonë, kjo nuk ishte e nevojshme. Ne ishim ngjitur me grupe. Thjesht merrnim grupe dhe nuk kishim asnjë problem. I vendosim dhe gjithçka funksionon mirë. Por, natyrisht, mund të ndodhin një mori skenarësh. Për shembull, kur keni shumë serverë në të cilët krijohen të dhëna. Dhe ato vendosin të dhëna jo aq shpesh, por përsëri ndodhin vendosje të shpeshta. Duhen ndonjëherë të shmangen këto.
Nga një pikëpamje teknike, thelbi është se kur bën një insert në ClickHouse, të dhënat nuk shkojnë në ndonjë memtable. Nuk kemi as një MergeTree me strukturë log, por thjesht një MergeTree, sepse nuk ka asnjë log dhe as memTable. Ne thjesht shkruajmë të dhënat menjëherë në sistemin e skedarëve, të vendosura në kolona. Dhe nëse keni 100 kolona, do t'ju duhen më shumë se 200 skedarë për t'u shkruar në një drejtori të veçantë. E gjithë kjo është mjaft voluminoze.

Dhe lind pyetja: "Si të bëjmë drejt?", nëse ndodh një situatë që duhet si ndonjëherë të regjistrohen të dhënat në ClickHouse.
Metoda 1. Kjo është mënyra më e thjeshtë. Përdorni një radhë të shpërndarë. Për shembull, Kafka. Thjesht nxirrni të dhënat nga Kafka, gruponi çdo sekondë. Dhe gjithçka do të funksionojë normalisht, ju regjistroni, gjithçka punon mirë.
Disavantazhet janë se Kafka është edhe një sistem i madh i shpërndarë. E kuptoj nëse kompania juaj tashmë ka Kafka. Kjo është e mirë, është e përshtatshme. Por nëse nuk e keni, atëherë duhet të mendoni tri herë para se të sillni një sistem të tjetër shpërndarë në projektin tuaj. Prandaj, është e nevojshme të shqyrtoni alternativa.

Metoda 2. Një alternativë e tillë old-school dhe shumë e thjeshtë. Keni një server që gjeneron log-et tuaja. Ai thjesht regjistron log-et tuaja në një skedar. Dhe çdo sekondë, për shembull, e rinovojmë këtë skedar, hapim një të ri. Një skript i veçantë ose përmes cron-it, ose një daemon e merr skedarin më të vjetër dhe e regjistron në ClickHouse. Nëse regjistroni log-et çdo sekondë, gjithçka do të jetë e shkëlqyer.
Por disavantazhi i kësaj metode është se nëse serveri, ku krijohen log-et, zhduket diku, atëherë të dhënat do të zhduken gjithashtu.

Metoda 3. Ka një mënyrë tjetër interesante, që në të vërtetë nuk përdor skedarë temporal. Për shembull, keni ndonjë lloj reklame që rrotullohet ose ndonjë daemon interesante tjetër që gjeneron të dhëna. Dhe mund të grumbulloni një grup të dhënash direkt në memory, në buffer. Dhe kur kalon një sasi e mjaftueshme kohe, e ruani këtë buffer, krijoni një të ri dhe në një proces të veçantë, e vendosni atë që është grumbulluar në ClickHouse.
Nga ana tjetër, të dhënat gjithashtu shpërndahen kur përdorni kill -9. Nëse serveri juaj bie, atëherë do të humbni këto të dhëna. Një tjetër problem është se nëse nuk keni mundur ta shkruani në bazë, të dhënat do të grumbullohen në memory. Dhe ose do të mbaroni memory, ose thjesht do të humbni të dhënat.

Metoda 4. Një tjetër mënyrë interesante. Keni një proces serveri. Ai mund të dërgojë të dhëna në ClickHouse menjëherë, por të bëjë këtë në një lidhje. Për shembull, dërgoi një kërkesë http me transfer-encoding: chunked me insert. Dhe gjeneron chunks jo shumë shpesh, mund të dërgoni çdo rresht, ndonëse do të ketë overhead për framing të këtyre të dhënave.
Megjithatë, në këtë rast, të dhënat do të dërgohen në ClickHouse menjëherë. Dhe ClickHouse do t'i buferizojë vetë ato.
Por gjithashtu ndodhin probleme. Tani do të humbni të dhëna, përfshirë kur procesi juaj ndërpritet dhe, nëse procesi ClickHouse ndërpritet, sepse kjo do të jetë një insert i papërfunduar. Në ClickHouse, inserts janë atomare deri në një prag të caktuar të numrit të rreshtave. Në përgjithësi, kjo është një mënyrë interesante. Mund të përdoret gjithashtu.

Metoda 5. Ja një tjetër mënyrë interesante. Ky është një server i zhvilluar nga community për të grumbulluar të dhëna. Unë vetë nuk kam mbajtur shikimin e tij, kështu që nuk mund të garantoj asgjë. Megjithatë, as për ClickHouse nuk ofrohen ndonjë garancinë. Ky është gjithashtu open source, por nga ana tjetër, mund të keni zakonuar te një standard cilësie, të cilin ne mundohemi ta ofrojmë. Për këtë gjë – nuk e di, shkoni në GitHub, shikoni kodin. Ndoshta kanë shkruar diçka normale.
* në përputhje me gjendjen deri në vitin 2020, duhet gjithashtu të shtohet në shqyrtim .

Metoda 6. Një mënyrë tjetër është përdorimi i tabelave Buffer. Avantazhi i kësaj metode është se është shumë e thjeshtë për t'u filluar. Krijoni një tabelë Buffer dhe e vendosni atje.
Një disavantazh është se problemi nuk zgjidhet plotësisht. Nëse me insertimin e tipit MergeTree duhet të gruponi të dhënat në një grup çdo sekondë, kur e bëni këtë në tabelën buffer, duhet të gruponi të paktën deri në disa mijëra në sekondë. Nëse ka më shumë se 10,000 në sekondë, do të jetë ende problem. Dhe nëse bëni inserte në grupe, do të shihni se atëherë ka dhjetëra mijëra rreshta në sekondë. Dhe kjo ndodh me të dhëna mjaft të rënda.
Po ashtu, tabelat buffer nuk kanë log. Dhe nëse ka diçka të keqe me serverin tuaj, të dhënat do të humbasin.

Dhe si një bonus, recently kemi pasur mundësinë në ClickHouse për të marrë të dhëna nga Kafka. Ka një motor tabelash – Kafka. Thjesht krijoni një. Dhe mund të varni pamjet materializuese mbi të. Në këtë rast, ai do të nxjerrë në mënyrë të vetme të dhënat nga Kafka dhe do t'i vendosë në tabelat që ju nevojiten.
E ajo që na gëzon më së shumti në këtë mundësi është se nuk e bëmë ne. Kjo është një funksion i komunitetit. Dhe kur them "funksion i komunitetit", e them pa ndonjë përbuzje. Ne e lexuam kodin, bëmë rishikimin, dhe duhet të funksionojë normalisht.
* në gjendjen e vitit 2020, u shpall mbështetje e ngjashme për .

Çfarë mund të jetë e pakëndshme ose befasuese kur futni të dhëna? Nëse bëni një kërkesë insert values dhe në values shkruani ndonjë shprehje të llogaritur. Për shembull, now() – është gjithashtu një shprehje e llogaritur. Në këtë rast, ClickHouse detyrohet të ekzekutojë interpreterin e këtyre shprehjeve për çdo rresht, dhe performanca do të bjerë ndjeshëm. Është më mirë ta evitoni këtë.
* deri tani, problemi është zgjidhur plotësisht, dhe nuk ka më regresione të performancës kur përdoren shprehjet në VALUES.
Një shembull tjetër i kur mund të ketë disa probleme është kur të dhënat në një grup i përkasin shumë pjesëve. Në ClickHouse, pjesët janë në përmasa mujor. Nëse vendosni një grup prej një milioni rreshtash dhe të dhënat përfshijnë disa vite, do të keni disa dhjetëra pjesë. Kjo është ekuivalente me të pasur grupe që janë disa dhjetëra herë më të vogla në përmasë, sepse brenda, ato ndahen fillimisht sipas pjesëve.
* së fundmi në ClickHouse, në modalitetin eksperimental, është shtuar mbështetje për formatin kompakt të copave dhe copave në memorje me write-ahead log, që pothuajse zgjidh plotësisht problemin.

Tani le të shqyrtojmë llojin e dytë të problemit - tipizimin e të dhënave.
Tipizimi i të dhënave mund të jetë i rreptë, ose mund të jetë tekstual. Tekstual do të thotë se thjesht e deklaroni se të gjitha fushat janë të tipit tekst. Kjo është e papranueshme. Nuk duhet të bëni kështu.
Le të kuptojmë si të veprojmë drejt në rastet kur duam të themi se një fushë është tekst dhe le të kujdeset ClickHouse për këtë, pa u shqetësuar. Megjithatë, ende ia vlen të bëni disa përpjekje.

Për shembull, ne kemi një IP adresë. Në një rast e ruajmë si një varg. Për shembull, 192.168.1.1. Ndërsa në rastin tjetër - kjo do të jetë një numër i tipit UInt32*. 32 bit janë të mjaftueshme për një adresë IPv4.
Së pari, siç është e çuditshme, të dhënat do të kompresohen përafërsisht në të njëjtën mënyrë. Do të ketë dallime, sigurisht, por jo kaq të mëdha. Prandaj, nuk ka probleme të veçanta me hyrjen-daljen e disqeve.
Por ka një ndryshim të madh në kohën e procesorit dhe në kohën e ekzekutimit të kërkesës.
Le të llogarisim numrin e IP adresave unike, nëse ato ruhen si numra. Kështu del 137 milion rreshta në sekondë. Nëse e bëjmë të njëjtën gjë si vargje, atëherë 37 milion rreshta në sekondë. Nuk e di se pse ka ndodhur një përputhje e tillë. Unë vetë kam kryer këto kërkesa. Megjithatë, është përafërsisht katër herë më e ngadaltë.
Dhe nëse llogarisim ndryshimin në hapësirë në disk, ka një ndryshim gjithashtu. Dhe ndryshimi është diku rreth një të katërtës, pasi ka shumë adresa IP unike. Dhe nëse do të kishte këtu rreshta me një numër të vogël vlerash të ndryshme, ato do të kompresoheshin pa probleme në një volum përafërisht të njëjtë.
Dhe diferencia katërfish në kohë rrugore nuk është ndonjë gjë e zakonshme. Ndoshta për ju nuk ka rëndësi, por kur shoh një diferencë të tillë, në fillim më bën të ndihëm keq.

Le të shqyrtojmë raste të ndryshme.
1. Një rast është kur keni disa vlera unike. Në këtë rast, ne përdorim një praktikë të thjeshtë, që ndoshta e dini dhe mund ta përdorni për çdo DB. Kjo ka kuptim jo vetëm për ClickHouse. Thjesht regjistroni identifikuesit numerikë në bazë. Dhe mund të konvertoni në vargje dhe anasjelltas në anën e aplikacionit tuaj.
Ja për shembull, keni një rajon. Dhe po përpiqeni ta ruani atë si një varg. Do të shkruhet: Moskë dhe MO. Dhe kur shoh se aty shkruan "Moskë", atëherë kjo është akoma asgjë, por kur është dhe MO, atëherë bëhet siç duket shumë keq. Sa byte është kjo.
Në vend të kësaj, ne thjesht regjistrojmë numrin Ulnt32 dhe 250. Në Yandex kemi 250, ndoshta ju ndryshe. Për t'u siguruar, do të them se në ClickHouse ka një mundësi të ndërtuar për të punuar me bazën gjeografike. Thjesht regjistroni një listë me rajonet, përfshirë hierarkike, dmth, atje do të jetë dhe Moskë, dhe MO, dhe gjithçka që ju nevojitet. Dhe mund të konvertoni në nivelin e kërkesës.

Varianti i dytë është përafërsisht i njëjtë, por tashmë me mbështetje brenda ClickHouse. Ky është një lloj të dhënash Enum. Thjesht brenda Enum shkruani të gjitha vlerat që ju nevojiten. Për shembull, lloji i pajisjes dhe aty shkruani: desktop, mobil, tablet, televizor. Në total, 4 variante.
Disavantazhi është se duhet të bëni periodikisht një alter. Shtua vetëm një variant. Bëni alter table. Në të vërtetë, alter table në ClickHouse është falas. Sidomos është falas për Enum, sepse të dhënat në disk nuk ndryshojnë. Megjithatë, alter kap bllokimin* e tabelës dhe duhet të presë derisa të përfundojnë të gjitha select-et. Vetëm pas kësaj do të realizohet alter, pra disa përshtatje vazhdojnë të jenë të pranishme.
* në versionet e reja të ClickHouse, ALTER është bërë plotësisht pa bllokim.

Një variant tjetër mjaft unik për ClickHouse është lidhja e fjalorëve të jashtëm. Mund të shkruani numra në ClickHouse, ndërsa katalogët tuaj t’i mbani në çdo sistem që ju përshtatet. Për shembull, mund të përdorni: MySQL, Mongo, Postgres. Mund të krijoni edhe një mikroshërbim që do t’i dorëzojë këto të dhëna përmes http. Dhe në nivelin e ClickHouse shkruani një funksion që do t’i shndërrojë këto të dhëna nga numra në vargje.
Ky është një mënyrë e specializuar, por shumë efektive për të realizuar një bashkim me një tabelë të jashtme. Ka dy variante. Në një variant, këto të dhëna do të jenë plotësisht të ruajtura në cache, do të qëndrojnë plotësisht në memorjen e punës dhe do të përditësohen me një rregullsi të caktuar. Në variantin tjetër, nëse këto të dhëna nuk mund të ruhet në memorje, mund t'i ruajmë pjesërisht në cache.
Ja një shembull. Ka Yandex.Direct. Aty ka një fushatë reklamash dhe bannera. Numri i fushatave reklamash është ndoshta rreth dhjetë milion. Disa mund të ruhet në memorje. Ndërsa ka miliarda bannerash, ato nuk mund të ruhet. Dhe ne përdorim një fjalor të ruajtshëm në cache nga MySQL.
Problemi i vetëm është se fjalori i ruajtshëm në cache do të funksionojë normalisht, nëse raporti i goditjeve është afër 100%. Nëse është më i vogël, do të duhet të merrni çelësat e munguar dhe të merrni të dhënat nga MySQL për çdo grup të dhënash. Më shumë se ClickHouse, mund të sigurohem që – po, nuk ngadalëson, për sistemet e tjera nuk do flas.
Një bonus është se fjalorët janë një mënyrë shumë e thjeshtë për të azhurnuar të dhënat në ClickHouse me datë të kaluar. Kështu, nëse keni një raport për kampanjat reklamuese, përdoruesi thjesht ndërron kampanjën reklamuese dhe të gjitha të dhënat e mëparshme, në të gjithë raportet, gjithashtu ndryshojnë. Nëse shkruani rreshta direkt në tabelë, do të ishte e pamundur t'i azhurnoni ato.

Një mënyrë tjetër, kur nuk e dini nga ta merrni identifikuesit për rreshtat tuaj, është të përdorni thjesht një hash. Variantin më të thjeshtë është të merrni një hash 64-bitësh.
Problemi i vetëm është se, nëse hash-i është 64-bitësh, do të ketë patjetër kolizione. Sepse nëse ka një miliard rreshta, probabiliteti bëhet tashmë i ndjeshëm.
Dhe nuk do të ishte shumë mirë të hash-oni emrat e kampanjave reklamuese kështu. Nëse kampanjat reklamuese të kompanive të ndryshme ngatërrohen, do të ketë diçka që nuk ka kuptim.
Dhe ka një truĉ të thjeshtë. E vërteta, për të dhëna serioze nuk është shumë e përshtatshme, por nëse është diçka jo shumë serioze, thjesht shtoni një identifikues klienti në çelësin e fjalorëve. Dhe atëherë do të keni kolizione, por vetëm brenda një klienti. Ky metodë përdoret për mapën e lidhjeve në Yandex.Metrica. Atje kemi URL, ruajmë hashes. Dhe e dimë se kolizionet, natyrisht, ekzistojnë. Por kur shfaqet faqja, probabiliteti që në një faqe të vetme për një përdorues disa URL të përzihen dhe që kjo të vërehet është aq e ulët saqë mund të injorohet.
Si një bonus – për shumë operacione është e mjaftueshme të keni vetëm hashes dhe nuk është e nevojshme të ruani vetë stringjet asnjëherë.

Një shembull tjetër, nëse stringjet janë të shkurtra, për shembull, domenet e faqeve. Ato mund të ruhen ashtu si janë. Ose, për shembull, gjuha e shfletuesit ru – 2 byte. Sigurisht, më vjen shumë keq për byte-at, por mos u shqetësoni, 2 byte nuk janë një problem. Ju lutem, ruani ashtu si janë, mos e stresoni.

Një rast tjetër është kur, përkundrazi, ka shumë rreshta, dhe në to shumë unikë, për më tepër edhe një mori potencialisht të pakufizuar. Një shembull tipik është frazat e kërkimit ose URL-të. Frazat e kërkimit, përfshirë ato për shkak të gabimeve të shtypura. Le të shohim se sa fraza unike kërkohen brenda një dite. Dhe rezulton se pothuajse gjysma e të gjitha ngjarjeve janë të tilla. Në këtë rast, mund të mendoni se është e nevojshme të normalizoni të dhënat, të llogaritni identifikuesit, t’i grumbulloni në një tavëll të veçantë. Por kjo nuk është e rekomandueshme. Thjesht ruani këto rreshta ashtu siç janë.
Më mirë – mos krijoni asgjë të re, sepse nëse i ruani veçmas, do të nevojitet të bëni një bashkim (join). Dhe ky bashkim – në rastin më të mirë është një akses rastësor në memorie, nëse bie në mend. Nëse nuk mund të futet në memory, atëherë do të ketë probleme.
Nëse të dhënat ruhen në vend, ato thjesht lexohen në rendin e duhur nga sistemi i skedarëve dhe gjithçka shkon mirë.

Nëse keni URL-të ose ndonjë rresht të gjatë të komplikueshëm, ia vlen të mendoni se mund të llogariten ndonjë përmbledhje paraprakisht dhe të regjistrohet në një kolonë të veçantë.
Për URL-të, për shembull, mund të ruani veçmas domainin. Dhe nëse ju nevojitet me të vërtetë një domain, thjesht përdorni këtë kolumnë, ndërsa URL-të do të qëndrojnë dhe ju nuk do t'i prekni ato fare.
Le të shohim se çfarë diferencash ka. Në ClickHouse ekziston një funksion i specializuar që llogarit domainin. Ai është shumë i shpejtë, ne e kemi optimizuar atë. Dhe, për të qenë i sinqertë, ai madje nuk i përmbush RFC, por megjithatë llogarit gjithçka që na nevojitet.
Në një rast do të nxjerrim thjesht URL-të dhe do të llogarisim domainin. Kështu rezulton 166 milisekonda. Ndërsa nëse marrim një domain të gatshëm, atëherë rezulton vetëm 67 milisekonda, pra gati tre herë më shpejt. Dhe kjo është më e shpejtë jo për shkak se na nevojiten disa llogaritje, por për shkak se lexojmë më pak të dhëna.
Përveç kësaj, për një kërkesë që është më e ngadaltë, ndodhet më shumë shpejtësi gigabajtësh për sekondë. Sepse ajo lexon më shumë gigabajtë. Ky është informacion krejtësisht i tepërt. Kërkesa siç duket punon më shpejt, por ekzekutohet për një periudhë më të gjatë.
Por të parë volumin e të dhënave në disk, rezulton se URL-ja është 126 megabajt, ndërsa domeni është vetëm 5 megabajt. Kjo është 25 herë më e vogël. Megjithatë, kërkesa realizohet vetëm 4 herë më shpejt. Kjo është për shkak se të dhënat janë të nxehta. Nëse do të ishin të ftohta, do të ishte me siguri 25 herë më shpejt për shkak të hyrjes dhe daljes nga disku.
E cila, nëse vlerësojmë sa më i vogël është domeni krahasuar me URL-në, rezulton se është diku rreth 4 herë më i vogël. Por për arsyet e panjohura, të dhënat në disk zënë 25 herë më pak. Pse? Për shkak të kompresimit. Si URL-ja ashtu edhe domeni kompresohen. Por shpesh URL-ja përmban shumë mbeturina.

Sigurisht, është e rëndësishme të përdorni tipet e duhur të të dhënave, të cilat janë të destinuara posaçërisht për vlerat e nevojshme ose që përshtaten. Nëse jeni në IPv4, ruani UInt32*. Nëse jeni në IPv6, atëherë FixedString(16), sepse adresa IPv6 është 128 bit, dmth ruani ndershëm në formatin binar.
Çfarë të bëni nëse ndonjëherë keni adresa IPv4 dhe ndonjëherë IPv6? Po, mund të ruani të dyja. Një kolonë për IPv4, një tjetër për IPv6. Sigurisht, ka mundësinë për të shfaqur IPv4 në IPv6. Kjo do të funksionojë gjithashtu, por nëse ju nevojitet shpesh adresa IPv4 në kërkesa, atëherë do të ishte mirë ta vendosni në një kolonë të veçantë.
* tani në ClickHouse ka tipe të veçanta të dhënash IPv4, IPv6, të cilat ruajnë të dhënat po aq efikas sa numrat, por i paraqesin po aq lehtësisht sa vargjet.

Është gjithashtu e rëndësishme të theksohet se është e nevojshme të përpunohen të dhënat paraprakisht. Për shembull, ju vijnë disa logë të papërpunuara. Dhe ndoshta nuk është e mençur t'i fusni ato menjëherë në ClickHouse, edhe pse shumë joshëse është të mos bëni asgjë dhe gjithçka do të funksionojë. Por megjithatë, është më mirë të kryeni ato llogaritjet që mundeni.
Për shembull, versioni i shfletuesit. Në një departament fqinj, që nuk dua të tregoj me gisht, atje versioni i shfletuesit ruhet kështu, dmth. si një varg: 12.3. Pastaj, për të bërë një raport, ata e ndajnë këtë varg në një masiv, dhe më pas në elementin e parë të masivit. Natyrisht, gjithçka ngadalësohet. E pyesja, pse e bëjnë kështu. Më thanë se nuk i pëlqejnë optimizimet e parakohshme. Ndërsa unë nuk e pëlqej parakohshmërinë e pessimizimit.
Prandaj, në këtë rast, do të ishte më e saktë të ndaheshin në 4 kolona. Mos kini frikë, sepse kjo është ClickHouse. ClickHouse është një databazë kolonash. Dhe sa më shumë kolona të vogla e të rregullta, aq më mirë. Do të keni 5 BrowserVersion, bëni 5 kolona. Kjo është normale.

Tani le të shikojmë se çfarë të bëni nëse keni shumë rreshta shumë të gjatë, shumë arrays të gjatë. Nuk është nevoja t'i ruani ato në ClickHouse fare. Në vend të kësaj, mund të ruani vetëm një identifikues në ClickHouse. Dhe këto rreshta të gjatë i vendosni në një sistem tjetër.
Për shembull, në një nga shërbimet tona analitike, ka disa parametra të ngjarjeve. Dhe nëse për ngjarjet vijnë shumë parametra, ne thjesht ruajmë të parët 512 që hasim. Sepse 512 - nuk është problem.

Dhe nëse nuk mund të vendosni se cilat janë llojet tuaja të të dhënave, gjithashtu mund t'i shkruani të dhënat në ClickHouse, por në një tabelë përkohshme të tipit Log, e cila është speciale për të dhënat përkohshme. Pas kësaj, mund të analizoni se çfarë shpërndarje vlerash keni atje, çfarë ka në përgjithësi dhe të përbëni llojet e duhura.
* tani në ClickHouse ka një tip të dhënash i cili lejon ruajtjen efektive të rreshtave me më pak shpenzime punë.

Tani le të shqyrtojmë një rast tjetër interesant. Nd sometimes njerëzit kanë gjëra që ndodhin ndryshe. Hyj dhe shoh diçka të tillë. Dhe menjëherë mendja shkon tek një administrator shumë i përvojshëm dhe i mençur, që ka një përvojë të madhe në konfigurimin e MySQL versionit 3.23.
Këtu shohim mijëra tabela, në secilën prej të cilave është regjistruar mbetja nga ndarja e diçkaje të paqartë me mijë.
Në parim, e respektoj përvojën e dikujt tjetër, përfshirë këtu të kuptoj se çfarë vuajtjesh mund të ketë sjellë kjo përvojë.

Dhe arsyet janë më shumë se sa më pak të qarta. Këto janë stereotipet e vjetra që mund të kenë akumuluar gjatë punës me sisteme të tjera. Për shembull, në tabelat MyISAM s'ka çelës primar klaster. Dhe ky mënyrë ndarjeje të dhënash mund të jetë një përpjekje e dëshpëruar për të marrë të njëjtin funksionalitet.
Një arsye tjetër është se operacione të tilla si alter në tabela të mëdha janë të vështira për t'u realizuar. Të gjitha do të bllokohen. Megjithatë, në versionet moderne të MySQL kjo problematikë tashmë s’është aq serioze.
Ose, për shembull, mikroshardimi, por për këtë më vonë.

Në ClickHouse nuk është e nevojshme të veprohet kështu, sepse, së pari, çelësi primar është klaster, dhe të dhënat janë të renditura sipas çelësit primar.
Dhe ndonjëherë më pyesin: «Si ndryshon performanca e kërkesave për diapazone në ClickHouse nga madhësia e tabelës?». Unë them se ajo nuk ndryshon aspak. Për shembull, nëse keni një tabelë me një miliard rreshta dhe lexoni një diapazoni prej një milioni rreshtash, gjithçka shkon mirë. Nëse tabela ka një trilion rreshta dhe lexoni një milion rreshta, do të jetë pothuajse e njëjtë.
Dhe, për më tepër, nuk kërkohen gjëra si manualet e ndarjeve. Nëse hyni dhe shikoni se çfarë ka në sistemin e skedarëve, do të shihni që tabela është një gjë mjaft e rëndësishme. Dhe brenda saj ka diçka si ndarje. Kjo do të thotë që ClickHouse bën gjithçka për ju dhe nuk ka nevojë të vuani.

Alter në ClickHouse është falas, nëse bëni alter add/drop column.
Dhe nuk ka kuptim të krijoni tabela të vogla, sepse nëse keni 10 rreshta ose 10,000 rreshta në një tabelë, kjo është krejtësisht e parëndësishme. ClickHouse është një sistem që optimizon throughput, jo latency, kështu që nuk ka kuptim të përpunoni 10 rreshta.

Është e drejtë të përdorni një tabelë të madhe. Largohuni nga stereotype të vjetra, gjithçka do të shkojë mirë.
Si për bonus, në versionin tonë më të fundit është shtuar mundësia për të krijuar një çelës partitionimi të rastësishëm, në mënyrë që të kryhen operacione të ndryshme mirëmbajtjeje mbi parti të veçanta.
Për shembull, ju nevojiten shumë tabela të vogla, siç ndodh kur keni nevojë për të trajtuar disa të dhëna përkohshme, ju vijnë copëza dhe duhet të kryeni transformim mbi to para se t'i shkruani në tabelën përfundimtare. Për këtë rast, ekziston një motor i mrekullueshëm tabelash – StripeLog. Është pak si TinyLog, por më i mirë.
* tani në ClickHouse ka gjithashtu .

Një tjetër antipattern është mikro-shardimi. Për shembull, nëse ju nevojitet të shardoni të dhënat dhe keni 5 serverë, por nesër do të keni 6 serverë. Dhe mendoni se si të ristrukturoni këto të dhëna. Dhe në vend që t'i ndani në 5 sharda, i ndani në 1,000 sharda. Pastaj çdo një prej këtyre mikro-shardave e lidhni me një server të veçantë. Kështu do të keni për shembull, 200 ClickHouse në një server, me instance të veçanta në porta të veçanta ose në baza të dhënash të veçanta.

Por në ClickHouse kjo nuk është shumë mirë. Sepse edhe një instance ClickHouse përpiqet të përdorë të gjitha burimet e disponueshme të serverit për të përpunuar një kërkesë. Domethënë, nëse keni një server dhe aty, për shembull, 56 bërthama procesorësh. Ju ekzekutoni një kërkesë që zgjat një sekondë, dhe do të përdorë 56 bërthama. Nëse keni vendosur 200 ClickHouse në një server, atëherë do të keni 10,000 thirrje. Në përgjithësi, gjërat do të shkojnë shumë keq.
Arsyeja tjetër është se shpërndarja e punës ndërmjet këtyre instancave do të jetë e pabarabartë. Disa do ta përfundojnë më herët, disa më vonë. Po të ndodhte gjithçka në një instance, ClickHouse do të dinte si të shpërndajë të dhënat saktësisht mes rrjedhave.
Në një arsye tjetër është se do të keni ndërveprime ndërmjet proceseve përmes TCP. Të dhënat do të duhet të serializohen, deserializohen dhe do të ketë një numër të madh mikro-shardesh. Kështu, do të funksionojë thjesht në mënyrë joefikase.

Një tjetër antipattern, edhe pse është e vështirë ta quash një antipattern. Kjo është një sasi e madhe para-agregimi.
Në fakt, parashtrimi është shumë i mirë. Nëse kishit një miliard rreshta, e keni agreguar atë në 1,000 rreshta, dhe tani kërkesa e realizohet menjëherë. E gjithë kjo është në rregull. Kështu mund të veprohet. Dhe për këtë, madje në ClickHouse ka një tip të veçantë tabele AggregatingMergeTree, e cila kryen agregimin inkremental teksa futen të dhëna.
Por ndodhin raste kur mendoni se do të agregoni të dhënat kështu dhe po ashtu. Dhe në një departament fqinje, gjithashtu nuk dua të përmend emrin, përdorin tabela SummingMergeTree për të përmbledhur sipas çelësit kryesor, dhe si çelës kryesor përdorin rreth 20 kolona të ndryshme. Në çdo rast, e kam ndryshuar emrat e disa kolonave për konspiracion, por është kështu më pak më shumë.

Dhe ndodhin këto probleme. Së pari, volumi i të dhënave nuk zvogëlohet shumë. Për shembull, zvogëlohet tre herë. Tre herë – do të ishte një çmim i mirë për t'i lejuar vetes mundësi të pakufizuara për analizë, që ndodhin nëse të dhënat janë të paagreguara. Nëse të dhënat janë të agreguara, atëherë në vend të analizës merrni vetëm statistika të mjerueshme.
Dhe çfarë është veçanërisht frustrues? Sepse këta njerëz nga departamenti përballë vijnë dhe kërkojnë ndonjëherë të shtohet një kolonë tjetër në çelësin primar. Do të thotë, ne kemi aggreguar të dhënat kështu, dhe tani duam pak më shumë. Por në ClickHouse nuk ka mundësi për të modifikuar çelësin primar. Prandaj, duhet të shkruajmë ndonjë skript në C++. Dhe unë nuk i pëlqej skriptet, madje ndonjëherë edhe në C++.
Dhe nëse e shikoni përse u krijua ClickHouse, të dhënat jo të agreguara janë pikërisht skenari për të cilin ai është krijuar. Nëse e përdorni ClickHouse për të dhëna jo të agreguara, atëherë po bëni gjithçka siç duhet. Nëse po agregoni, atëherë ndonjëherë është e pranueshme.
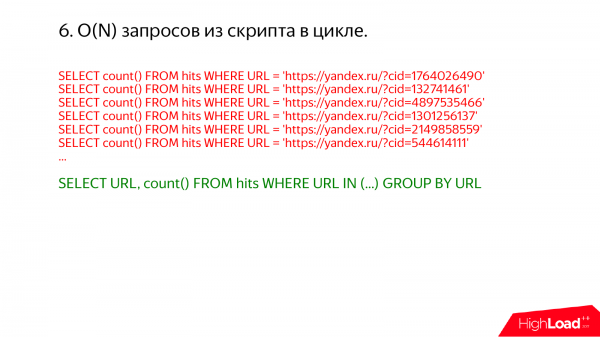
Një rast tjetër interesant është kërkesat në një cikël të pafund. Ndonjëherë, hyj në ndonjë server production dhe shikoj atje show processlist. Dhe çdo herë zbulloj se po ndodhin gjëra të tmerrshme.
Për shembull, diçka e tillë. Këtu është menjëherë e qartë se të gjitha mund të ishin ekzekutuar në një kërkesë. Thjesht shkruani atje url in dhe listën.

Pse ka shumë kërkesa të tilla në një cikël të pafund – kjo është e keqe? Nëse indeksi nuk përdoret, do të keni shumë kalime mbi të njëjtat të dhëna. Por nëse indeksi përdoret, për shembull, nëse keni një çelës primar mbi ru dhe shkruani url = diçka aty. Dhe mendoni se do të lexoni pikërisht një url nga tabela, do të jetë gjithçka në rregull. Por në fakt, jo. Sepse ClickHouse bën gjithçka sipas grupeve.
Kur i duhet të lexojë një interval të caktuar të të dhënave, ai lexon pak më shumë, sepse indeksi në ClickHouse është i hollë. Ky indeks nuk lejon të gjendet një rresht të veçantë në tabelë, vetëm një interval të caktuar. Dhe të dhënat kompresohen në blloqe. Për të lexuar një rresht, duhet të merrni një bllok të tërë dhe ta çkompresoni. Dhe nëse kryeni shumë kërkesa, do të keni shumë përputhje të tilla dhe shumë punë do t'ju përfundojë vazhdimisht.

Dhe si një bonus, mund të theksoj se në ClickHouse nuk duhet të keni frikë të dërgoni madje edhe megabajtë dhe madje qindra megabajtë në seksionin IN. E mbaj mend nga praktika jonë se nëse në MySQL dërgojmë një mori vlerash në seksionin IN, për shembull, dërgojmë aty 100 megabajtë ndonjë numri, atëherë MySQL konsumon 10 gigabajtë memorie dhe më shumë me këtë nuk ndodh asgjë, gjithçka punon keq.
Dhe e dyta – është se në ClickHouse, nëse kërkimet tuaja përdorin indeks, atëherë kjo është gjithmonë jo më e ngadaltë se skanimi i plotë, dmth. nëse duhet të lexoni pothuajse tërë tabelën, ai do të shkojë në mënyrë të vazhdueshme dhe do të lexojë tërë tabelën. Në përgjithësi, ai do të kuptojë vetë.
Por megjithatë ka disa vështirësi. Për shembull, ajo që IN me një nënkërkesë nuk përdor indeks. Por kjo është problemi ynë dhe duhet ta rregullojmë. Nuk ka asgjë të thellë këtu. Do ta rregullojmë*.
Dhe një gjë tjetër interesante – është se nëse keni një kërkesë shumë të gjatë dhe përpunimi i kërkesave është i shpërndarë, atëherë kjo kërkesë shumë e gjatë do të dërgohet në çdo server pa kompresim. Për shembull, 100 megabajtë dhe 500 serverë. Dhe, për rrjedhojë, do të dërgohen 50 gigabajtë përmes rrjetit. Do të dërgohen dhe pastaj gjithçka do të ekzekutohet me sukses.
* tashmë po përdoret; gjithçka është rregulluar, siç u premtua.

Dhe është një rast mjaft i zakonshëm nëse kërkesat vijnë nga API. Për shembull, keni krijuar ndonjë shërbim tuajin. Dhe nëse shërbimi juaj është i nevojshëm për dikë, atëherë e keni hapur API-në dhe pas dy ditësh vëreni se ndodhin gjëra të çuditshme. Të gjitha janë të ngarkuara dhe po vijnë disa kërkesa të tmerrshme, të cilat kurrë nuk duhej të ishin.
Dhe zgjidhja këtu është një. Nëse keni hapur API-në, do t'ju duhet ta kufizoni atë. Për shembull, të vendosni ndonjë kuotë. Nuk ka alternativa të tjera normale. Përndryshe, menjëherë do të shkruajnë një skript dhe do të kenë probleme.
Dhe në ClickHouse ka një mundësi speciale – kjo është llogaritja e kuotave. Gjithashtu, mund të transferoni çelësin tuaj të kuotës. Kjo, për shembull, është një identifikues i brendshëm i përdoruesit. Dhe kuotat do të llogariten pavarësisht për secilin prej tyre.

Tani, ka edhe një gjë interesante. Kjo është replikimi me dorë.
Di shumë raste kur, megjithëse ClickHouse ka mbështetje të integruar për replikimin, njerëzit e replikojnë ClickHouse me dorë.
Cili është principi? Ju keni një pipeline për përpunimin e të dhënave. Dhe ai funksionon në pavarësi, p.sh., në qendra të ndryshme të të dhënave. Ju regjistroni të dhëna të njëjta në një mënyrë të njëjtë në ClickHouse, siç është. Megjithatë, praktika tregon se të dhënat do të shkojnë në ndryshim për shkak të ndonjë veçorie në kodin tuaj. Shpresoj se në rastin tuaj ndodh kështu.
Dhe periodikisht do t'ju duhet gjithsesi të sinkronizoni me dorë. Për shembull, një herë në muaj, administratorët bëjnë rsync.
Në fakt, është shumë më e thjeshtë të përdorni replikimin e ndërtuar në ClickHouse. Por këtu mund të ketë disa kundërindikacione, sepse për këtë duhet të përdorni ZooKeeper. Nuk do të flas asgjë të keqe për ZooKeeper, në parim sistemi funksionon, por ndonjëherë ndodh që njerëzit nuk e përdorin atë për shkak të frikës nga java, sepse ClickHouse është një sistem i shkëlqyer, i shkruar në C++, që mund të përdoret dhe gjithçka do të shkojë mirë. Ndërsa ZooKeeper është në java. Dhe ndonjëherë nuk dëshiron as ta shohësh, por atëherë mund të përdorni replikimin me dorë.

ClickHouse – është një sistem praktik. Ai i merr parasysh nevojat tuaja. Nëse keni replikim në disqe manuale, mund të krijoni një tabelë të Distribuar, e cila shikon në replikat tuaja manuale dhe bën vetë kalimin midis tyre. Dhe ka madje një opsion të veçantë, i cili lejon shmangien e problemeve, edhe nëse replikat tuaja ndahen sistematikisht.

Më pas mund të hasni probleme nëse përdorni motorë tabelash primitivi. ClickHouse është një ndërtues i tillë, ku ka një mori motorësh tabelash të ndryshëm. Për të gjitha rastet serioze, siç shkruhet në dokumentacion, përdorni tabelat e familjes MergeTree. Të gjitha të tjerat janë për raste të veçanta ose për teste.
Në tabelën MergeTree nuk është e domosdoshme të keni ndonjë datë dhe kohë. Mund të përdorni gjithsesi. Nëse nuk ka datë dhe kohë, shkruani që default – viti 2000. Kjo do të funksionojë dhe nuk do të kërkojë burime.
Dhe në versionin e ri të serverit madje mund të tregoni që të keni një ndarjen të personalizuar pa çelësin e ndarjes. Kjo do të jetë e njëjtë.

Nga ana tjetër, mund të përdorni moteur primitive tabelash. Për shembull, ngarkoni të dhënat një herë dhe shikoni, rrotulloni dhe fshini. Mund të përdorni Log.
Ose mbani sasi të vogla për përpunim të ndërmjetëm - ky është StripeLog ose TinyLog.
Memory mund të përdoret, nëse keni një sasi të vogël të dhënash dhe thjesht të rrotulloni diçka në RAM.

ClickHouse nuk i pëlqen shumë të dhënat e tejnormizuara.
Ja një shembull tipik. Kjo është një sasi e madhe e URL-ve. I keni futur në një tabelë fqinje. Më pas vendosët të bëni JOIN me to, por kjo zakonisht nuk do të funksionojë, sepse ClickHouse mbështet vetëm Hash JOIN. Nëse RAM-i është i pamjaftueshëm për sasinë e të dhënave që duhen bashkuar, atëherë JOIN nuk do të mund të realizohet*.
Nëse të dhënat janë me kardinalitet të madh, mos e shqetësoni, ruani ato në formë denormale, URL-të direkt në tabelën kryesore.
* aktualisht në ClickHouse ekziston edhe merge join që funksionon kur të dhënat ndërmjetëse nuk i përshtaten RAM-it. Por kjo është e pasaktë dhe rekomandimi vazhdon të mbetet në fuqi.

Dy shembuj të tjerë, por tashmë dyshoj nëse ata janë antipatterns apo jo.
ClickHouse ka një mangësi të njohur. Ai nuk ka përditësime*. Në njëfarë mënyre, kjo është edhe e mirë. Nëse keni ndonjë të dhënë të rëndësishme, për shembull, llogarinë, askush s'do të mund ta dërgojë atë, sepse nuk ka përditësime.
* mbështetje për përditësime dhe fshirje është shtuar prej kohësh në modin grup.
Por ka disa mënyra të veçanta, të cilat lejojnë përditësime si për në sfond. Për shembull, tabelat e tipit ReplaceMergeTree. Ato bëjnë përditësime gjatë bashkimeve në sfond. Mund ta forconi këtë me optimizimin e tabelës. Por mos e bëni këtë shumë shpesh, sepse do të bëhet një riparim i plotë i pjesës.
JOIN të shpërndarë në ClickHouse – gjithashtu trajtohet keq nga planifikuesi i kërkesave.
Keq, por ndonjëherë është në rregull.
Përdorimi i ClickHouse vetëm për të lexuar të dhënat përsëri me select*.
Nuk do ta rekomandoja përdorimin e ClickHouse për llogaritje të ndërlikuara. Por nuk është krejtësisht kështu, sepse tashmë po largohemi nga kjo rekomandim. Dhe kohët e fundit kemi shtuar mundësinë e aplikimit të modeleve të mësimit të makinerive në ClickHouse – Catboost. Dhe kjo më shqetëson, sepse mendoj: "Sa katastrofike. Sa cikle në byte po na rezulton!". Më vjen shumë keq të harxhoj cikle për byte.

Por mos u frikës, vendosni ClickHouse, gjithçka do të shkojë mirë. Nëse keni ndonjë problem, ne kemi një komunitet. Për më tepër, komuniteti jeni ju. Nëse keni ndonjë problem, mund të hyni në bisedën tonë dhe shpresoj që do t'ju ndihmojnë.
Pyetje
Faleminderit për raportin! Ku mund të ankohesha për rënien e ClickHouse?
Mund të ankohem personalisht tani.
Këtë kohë kam filluar të përdor ClickHouse. Menjëherë e humba ndërfaqen cli.
Ju keni fat.
Pak më vonë e humba serverin me një select të vogël.
Keni talent.
Kam hapur një defekt në GitHub, por e injoruan.
Do ta shohim.
Aleksej më mashtroi për të ndarë një raport, duke premtuar se do të tregonte si e ngjeshni të dhënat brenda.
Shumë thjeshtë.
Këtë e kuptova dje. Më shumë për të saktë.
Nuk ka asnjë mashtrim të tmerrshëm. Thjesht është ngjeshje në blloqe. Në parazgjedhje përdoret LZ4, mund të aktivizoni ZSTD*. Blloqet janë nga 64 kilobajt deri në 1 megabajt.
* gjithashtu ka mbështetje për kodekët e specializuar të ngjeshjes, të cilat mund të përdoren në zinxhir me algorithmë të tjera.
A janë blloqet thjesht të dhëna të papërpunuara?
Jo krejtësisht të papërpunuara. Aty ka Arrays. Nëse keni një kolonë numerike, atje numrat janë radhitur në një array.
E kuptoj.
Aleks, një shembull që ishte me uniqExact mbi IP-të, dmth ajo që uniqExact llogaritet më gjatë sipas vargjeve sesa sipas numrave e kështu me radhë. Dhe nëse ne aplikojmë një truk dhe do të bëjmë casting në momentin e leximit? Dmth, duket se keni thënë që në disk nuk dallon shumë. Nëse lexojmë vargjet nga disku, bëjmë casting, a do të kemi më shpejt agregatët apo jo? Apo ne gjithsesi do të fitojmë pak këtu? Më duket se e keni testuar këtë, por për një arsye nuk e keni treguar në benchmark.
Mendoj se do të jetë më ngadalë sesa pa casting. Në këtë rast, adresa IP duhet të parserohet nga stringu. Sigurisht, në ClickHouse, parsing-u i adresave IP është gjithashtu i optimizuar. Ne u munduam shumë, por numrat janë shkruar në formën me dhjetë mijë. Shumë e papërshtatshme. Nga ana tjetër, funksioni uniqExact do të punojë ngadalë mbi vargjet jo vetëm sepse janë vargje, por gjithashtu sepse zgjidhet një specializim tjetër i algoritmit. Vargjet thjesht trajtohen ndryshe.
Po nëse marrim një tip më primitiv të dhënash? Për shembull, regjistrojmë user id, i cili është in, e regjistrojmë atë si një varg, dhe më pas e bëjmë casting, a do të jetë më argëtues apo jo?
Kam dyshoj. Mendoj se do të jetë edhe më trishtues, sepse në fund të fundit, analizimi i numrave është një problem serioz. Më duket se ky koleg kishte madje një prezantim mbi sa e vështirë është të analizosh numrat në formën e dhjetë-mijë, ose ndoshta jo.
Aleksej, faleminderit shumë për prezantimin! Dhe faleminderit për ClickHouse! Kam një pyetje për planet. A ka ndonjë plan për një veçori për të përditësuar fjalorët jo plotësisht?
Pra, një riciklim pjesor?
Po-po. Lloji që mund të shkruash ndonjë fushë MySQL, pra, të përditësosh pas, që të ngarkohen vetëm këta të dhëna, nëse fjalori është shumë i madh.
Një veçori shumë interesante. Dhe, më duket se ndonjë njeri e ka propozuar këtë në bisedën tonë. Ndoshta ky ishe ai vetë.
Nuk mendoj se kam qenë unë.
Shumë mirë, tani duket se janë dy kërkesa. Dhe mund të fillosh ngadalë ta realizosh. Por menjëherë dua t'ju paralajmëroj se kjo veçori është mjaft e thjeshtë për t'u realizuar. Që do të thotë, në thelb duhet thjesht të shkruajmë numrin e versionit në tabelë dhe më pas të shkruajmë: versioni është më i vogël se ky i tillë. Dhe kjo do të thotë se, shumë mundësisht, ne do ta propozojmë këtë për entuziastët. A jeni entuziast?
Po, por, për fat të keq, jo në C++.
A dinë kolegët tuaj të shkruajnë në C++?
Do të gjej dikë.
Shumë mirë.
* mundësia u shtua dy muaj pas raportit – krijuesi i saj e zhvilloi atë dhe e dërgoi vetë .
Faleminderit!
Përshëndetje! Faleminderit për raportin! Ju përmendët se ClickHouse konsumon shumë mirë të gjitha burimet që i janë ofruar. Dhe folësi fqinj me Luxoft tregoi për zgjidhjen e tij për Postën e Rusisë. Ai tha se ata e pëlqyen shumë ClickHouse, por nuk e përdorën atë në vend të konkurrentit të tyre kryesor pikërisht sepse ai konsumonte gjithë procesorin. Dhe ata nuk mundën ta inkorporonin në arkitekturën e tyre, në ZooKeeper-in e tyre me docker-at. A ka ndonjë mundësi për ta kufizuar ClickHouse, që të mos konsumojë gjithçka që i bëhet e aksesueshme?
Po, është shumë e lehtë. Nëse dëshironi që të konsumoni më pak bërthama, thjesht shkruani set max_threads = 1. Dhe kështu, do të ekzekutojë kërkesën në një bërthamë. Gjithashtu, mund t'i jepen konfigurime të ndryshme përdoruesve të ndryshëm. Prandaj nuk ka asnjë problem. Dhe për kolegët nga Luxoft, kaloni se nuk ishte mirë që ata nuk e gjetën këtë konfigurim në dokumentacion.
Alex, përshëndetje! Doja të pyesja për një çështje. Nuk është hera e parë që dëgjoj se shumë po fillojnë ta përdorin ClickHouse si një depo për logët. Në prezantimin tuaj thoshit se nuk duhet bërë kështu, pra nuk duhet të ruajmë vargje të gjata. Si e mendoni këtë?
Së pari, logët zakonisht nuk janë vargje të gjata. Sigurisht, ndodhin përjashtime. P.sh., ndonjë shërbim i shkruar në java hedh një exception që log-izohet. Dhe kështu në një cikël të pafund, dhe përfundojmë pa hap në hard disk. Zgjidhja është shumë e thjeshtë. Nëse vargjet janë shumë të gjata, prini ato. Dhe çfarë do të thotë të gjata? Dhjetëra kilobajt është e keqe.
* në versionet e fundit të ClickHouse, është përfshirë "granulacioni adaptiv i indeksit", i cili zgjidh problemin e ruajtjes së vargjeve të gjata në mënyrë të madhe.
Dhe kilobajt – a është e pranueshme?
E pranueshme.
Përshëndetje! Faleminderit për prezantimin! Unë tashmë kam pyetur për këtë në bisedë, por nuk e mbaj mend nëse kam marrë përgjigje. A planifikohet ndonjëherë të zgjerohet seksioni WITH, si CTE?
Për momentin jo. Seksioni WITH është disi jo serioz. Ai është si një tipar i vogël.
E kuptoj. Faleminderit!
Faleminderit për raportin! Shumë interesant! Një pyetje globale. A po planifikohet ndonjë modifikim për fshirjen e të dhënave, ndoshta në formën e ndonjë skeme?
Sigurisht. Kjo është detyra jonë e parë në radhën tonë. Tani kemi menduar aktivisht se si ta bëjmë gjithçka siç duhet. Dhe është koha të fillojmë të shtypim butonat në tastierë*.
* e kemi shtypur çdo buton në tastierë dhe gjithçka është bërë.
A do të ndikojë kjo ndonjëherë në performancën e sistemit apo jo? Do të jetë i njëjtë qëndrimi i sotëm për inserimin?
Mund të ndodhë që vetë deletimet, vetë azhurnimet, të jenë shumë të rënda, por kjo nuk do të ndikojë aspak në performancën e seleksioneve dhe performancën e inserimeve.
Dhe një pyetje e vogël. Në prezantim përmendët çelësin kryesor. Prandaj, ne kemi një ndarjen që është për default mujore, e saktë? Dhe kur vendosim një interval datash që përfshihet në muaj, atëherë vetëm ajo ndarje do të lexohet, e vërtetë?
Po.
Një pyetje. Nëse nuk mund të dalim me ndonjë çelës kryesor, a është e saktë ta bëjmë atë pikërisht sipas fushës 'Data', për të patur një ristrukturim më të vogël të këtyre të dhënave në sfond, në mënyrë që ato të jenë më të organizuara? Nëse nuk keni kërkesa diapazoni dhe madje nuk mund të zgjidhni asnjë çelës kryesor, a ka kuptim të vëmë datën në çelësin kryesor?
Po.
Ndoshta ka kuptim të vendosni një fushë në çelësin kryesor për të cilën të dhënat do të comprimohen më mirë, nëse ato janë të renditura sipas asaj fushe. Për shembull, identifikuesi i përdoruesit. Përdoruesi, për shembull, viziton të njëjtin faqe. Në këtë rast, vendosni ID-në e përdoruesit dhe kohën. Kështu, të dhënat tuaja do të comprimohen më mirë. Sa i përket datës, nëse me të vërtetë nuk keni dhe kurrë nuk keni kërkesa diapazoni për datat, atëherë nuk është e nevojshme ta vendosni datën në çelësin kryesor.
Mirë, faleminderit shumë!
Burimi: habr.com
