

Vazhdimi i temës së regjistrimit të rrjedhave të mëdha të të dhënave të ngritura nga , në këtë do të shikojmë mënyrat në të cilat mundeni zvogëloni madhësinë "fizike" të të ruajturit në PostgreSQL, dhe ndikimi i tyre në performancën e serverit.
Ne do të flasim për Cilësimet e TOAST dhe shtrirja e të dhënave. "Mesatarisht", këto metoda nuk do të kursejnë shumë burime, por pa modifikuar fare kodin e aplikacionit.

Sidoqoftë, përvoja jonë doli të jetë shumë produktive në këtë drejtim, pasi ruajtja e pothuajse çdo monitorimi nga natyra e tij është kryesisht vetëm për shtojca për sa i përket të dhënave të regjistruara. Dhe nëse po pyesni se si mund ta mësoni bazën e të dhënave të shkruajë në disk në vend të kësaj 200MB / s gjysma më shumë - ju lutem nën mace.
Sekretet e vogla të të dhënave të mëdha
Sipas profilit të punës , ata fluturojnë rregullisht tek ai nga strofullat paketat e tekstit.
Dhe qysh atëherë baza e të dhënave të të cilit ne monitorojmë është një produkt me shumë komponentë me struktura komplekse të dhënash, pastaj pyetje për performancë maksimale rezultojnë krejt kështu . Pra, vëllimi i çdo shembulli individual të një kërkese ose plani i ekzekutimit që rezulton në regjistrin që na vjen, rezulton të jetë "mesatarisht" mjaft i madh.
Le të shohim strukturën e njërës prej tabelave në të cilën shkruajmë të dhëna "të papërpunuara" - domethënë këtu është teksti origjinal nga hyrja e regjistrit:
CREATE TABLE rawdata_orig(
pack -- PK
uuid NOT NULL
, recno -- PK
smallint NOT NULL
, dt -- ключ секции
date
, data -- самое главное
text
, PRIMARY KEY(pack, recno)
);Një shenjë tipike (tashmë e ndarë, natyrisht, kështu që ky është një shabllon seksioni), ku gjëja më e rëndësishme është teksti. Ndonjëherë mjaft voluminoze.
Kujtoni se madhësia "fizike" e një regjistrimi në një PG nuk mund të zërë më shumë se një faqe të dhënash, por madhësia "logjike" është një çështje krejtësisht e ndryshme. Për të shkruar një vlerë vëllimore (varchar/tekst/bytea) në një fushë, përdorni :
PostgreSQL përdor një madhësi fikse faqeje (zakonisht 8 KB) dhe nuk lejon tuples të shtrihen në shumë faqe. Prandaj, është e pamundur të ruhen drejtpërdrejt vlera shumë të mëdha të fushës. Për të kapërcyer këtë kufizim, vlerat e mëdha të fushës kompresohen dhe/ose ndahen në linja të shumta fizike. Kjo ndodh pa u vënë re nga përdoruesi dhe ka pak ndikim në shumicën e kodeve të serverit. Kjo metodë njihet si TOAST...
Në fakt, për çdo tabelë me fusha "potencialisht të mëdha", automatikisht çdo rekord "i madh" në segmente 2 KB:
TOAST(
chunk_id
integer
, chunk_seq
integer
, chunk_data
bytea
, PRIMARY KEY(chunk_id, chunk_seq)
);
Kjo do të thotë, nëse duhet të shkruajmë një varg me një vlerë "të madhe". data, atëherë do të ndodhë regjistrimi i vërtetë jo vetëm në tryezën kryesore dhe PK-në e saj, por edhe në TOAST dhe PK-në e saj.
Reduktimi i ndikimit të TOAST
Por shumica e rekordeve tona nuk janë ende aq të mëdha, duhet të përshtatet në 8 KB - Si mund të kursej para për këtë?..
Këtu na vjen në ndihmë atributi në kolonën e tabelës:
- ZGJERUAR lejon kompresimin dhe ruajtjen e veçantë. Kjo opsion standard për shumicën e llojeve të të dhënave në përputhje me TOAST. Fillimisht përpiqet të kryejë kompresim, pastaj e ruan atë jashtë tabelës nëse rreshti është ende shumë i madh.
- KRYESORE lejon kompresim, por jo ruajtje të veçantë. (Në fakt, ruajtja e veçantë do të kryhet ende për kolona të tilla, por vetëm si mjet i fundit, kur nuk ka mënyrë tjetër për të tkurrur vargun në mënyrë që të përshtatet në faqe.)
Në fakt, kjo është pikërisht ajo që na duhet për tekstin - ngjeshni sa më shumë dhe nëse nuk përshtatet fare, vendoseni në TOAST. Kjo mund të bëhet drejtpërdrejt në fluturim, me një komandë:
ALTER TABLE rawdata_orig ALTER COLUMN data SET STORAGE MAIN;Si të vlerësoni efektin
Meqenëse fluksi i të dhënave ndryshon çdo ditë, ne nuk mund të krahasojmë numrat absolutë, por në terma relativë pjesë më të vogël E kemi shkruar në TOAST - aq më mirë. Por këtu ekziston një rrezik - sa më i madh të jetë vëllimi "fizik" i çdo regjistrimi individual, aq "më i gjerë" bëhet indeksi, sepse duhet të mbulojmë më shumë faqe të dhënash.
Seksioni para ndryshimeve:
heap = 37GB (39%)
TOAST = 54GB (57%)
PK = 4GB ( 4%)
Seksioni pas ndryshimeve:
heap = 37GB (67%)
TOAST = 16GB (29%)
PK = 2GB ( 4%)Në fakt, ne filloi të shkruante në TOAST 2 herë më rrallë, i cili shkarkoi jo vetëm diskun, por edhe CPU-në:
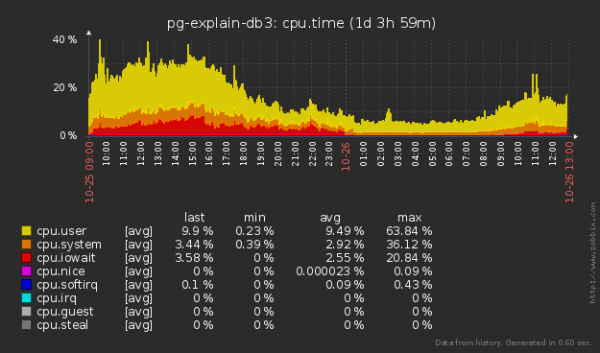
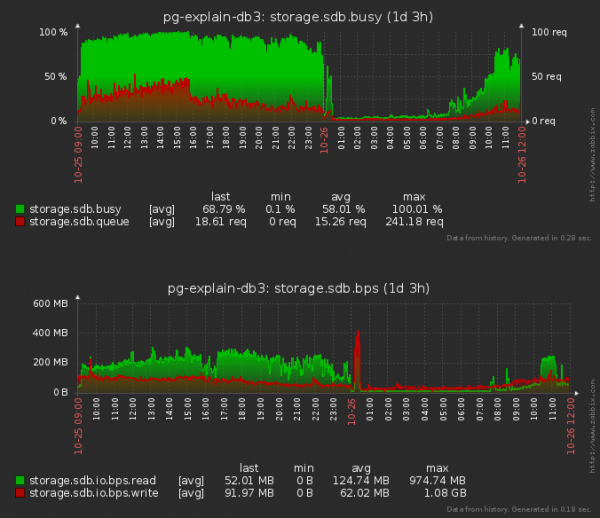
Do të vërej se ne gjithashtu jemi bërë më të vegjël në "leximin" e diskut, jo vetëm "shkrimin" - pasi kur futim një rekord në një tabelë, gjithashtu duhet të "lexojmë" një pjesë të pemës së secilit indeks për të përcaktuar pozicionin e ardhshëm në to.
Kush mund të jetojë mirë në PostgreSQL 11
Pas përditësimit në PG11, vendosëm të vazhdojmë të "akordojmë" TOAST dhe vumë re se duke filluar nga ky version parametri u bë i disponueshëm për akordim :
Kodi i përpunimit TOAST aktivizohet vetëm kur vlera e rreshtit që do të ruhet në tabelë është më e madhe se TOAST_TUPLE_THRESHOLD bajt (zakonisht 2 KB). Kodi TOAST do të ngjesh dhe/ose do të zhvendosë vlerat e fushës jashtë tabelës derisa vlera e rreshtit të bëhet më e vogël se TOAST_TUPLE_TARGET bajt (vlera e ndryshueshme, gjithashtu zakonisht 2 KB) ose madhësia nuk mund të zvogëlohet.
Ne vendosëm që të dhënat që kemi zakonisht janë ose "shumë të shkurtra" ose "shumë të gjata", kështu që vendosëm të kufizohemi në vlerën minimale të mundshme:
ALTER TABLE rawplan_orig SET (toast_tuple_target = 128);Le të shohim se si cilësimet e reja ndikuan në ngarkimin e diskut pas rikonfigurimit:

Jo keq! Mesatare radha në disk është zvogëluar afërsisht 1.5 herë, dhe disku "i zënë" është 20 përqind! Por ndoshta kjo ndikoi disi në CPU?

Të paktën nuk u përkeqësua. Megjithëse, është e vështirë të gjykohet nëse edhe vëllime të tilla ende nuk mund të rrisin ngarkesën mesatare të CPU-së 5%.
Duke ndryshuar vendet e termave, shuma...ndryshon!
Siç e dini, një qindarkë kursen një rubla, dhe me vëllimet tona të ruajtjes bëhet fjalë 10 TB/muaj edhe një optimizim i vogël mund të japë një fitim të mirë. Prandaj, i kushtuam vëmendje strukturës fizike të të dhënave tona - sa saktësisht Fushat e "stackuara" brenda rekordit secila nga tabelat.
Sepse për shkak të kjo është e drejtë përpara :
Shumë arkitektura ofrojnë përafrim të të dhënave në kufijtë e fjalëve të makinës. Për shembull, në një sistem 32-bit x86, numrat e plotë (lloji i numrit të plotë, 4 bajt) do të rreshtohen në një kufi fjalësh prej 4 bajtësh, ashtu si do të dyfishojnë numrat me pikë lundruese me saktësi (pika lundruese me saktësi të dyfishtë, 8 bajt). Dhe në një sistem 64-bitësh, vlerat e dyfishta do të rreshtohen në kufijtë e fjalëve 8-bajtë. Kjo është një arsye tjetër e papajtueshmërisë.
Për shkak të shtrirjes, madhësia e një rreshti tabele varet nga renditja e fushave. Zakonisht ky efekt nuk është shumë i dukshëm, por në disa raste mund të çojë në një rritje të konsiderueshme në madhësi. Për shembull, nëse përzieni fushat char (1) dhe numrat e plotë, zakonisht do të humbasin 3 bajt mes tyre.
Le të fillojmë me modelet sintetike:
SELECT pg_column_size(ROW(
'0000-0000-0000-0000-0000-0000-0000-0000'::uuid
, 0::smallint
, '2019-01-01'::date
));
-- 48 байт
SELECT pg_column_size(ROW(
'2019-01-01'::date
, '0000-0000-0000-0000-0000-0000-0000-0000'::uuid
, 0::smallint
));
-- 46 байтNga erdhën disa byte shtesë në rastin e parë? Është e thjeshtë - Linja e vogël 2-bajtë e rreshtuar në kufirin 4-bajtë përpara fushës tjetër, dhe kur është e fundit, nuk ka asgjë dhe nuk ka nevojë të rreshtohet.
Në teori, gjithçka është në rregull dhe ju mund t'i riorganizoni fushat sipas dëshirës tuaj. Le ta kontrollojmë atë në të dhëna reale duke përdorur shembullin e njërës prej tabelave, seksioni ditor i së cilës zë 10-15 GB.
Struktura fillestare:
CREATE TABLE public.plan_20190220
(
-- Унаследована from table plan: pack uuid NOT NULL,
-- Унаследована from table plan: recno smallint NOT NULL,
-- Унаследована from table plan: host uuid,
-- Унаследована from table plan: ts timestamp with time zone,
-- Унаследована from table plan: exectime numeric(32,3),
-- Унаследована from table plan: duration numeric(32,3),
-- Унаследована from table plan: bufint bigint,
-- Унаследована from table plan: bufmem bigint,
-- Унаследована from table plan: bufdsk bigint,
-- Унаследована from table plan: apn uuid,
-- Унаследована from table plan: ptr uuid,
-- Унаследована from table plan: dt date,
CONSTRAINT plan_20190220_pkey PRIMARY KEY (pack, recno),
CONSTRAINT chck_ptr CHECK (ptr IS NOT NULL),
CONSTRAINT plan_20190220_dt_check CHECK (dt = '2019-02-20'::date)
)
INHERITS (public.plan)Seksioni pas ndryshimit të rendit të kolonës - saktësisht fusha të njëjta, vetëm renditje të ndryshme:
CREATE TABLE public.plan_20190221
(
-- Унаследована from table plan: dt date NOT NULL,
-- Унаследована from table plan: ts timestamp with time zone,
-- Унаследована from table plan: pack uuid NOT NULL,
-- Унаследована from table plan: recno smallint NOT NULL,
-- Унаследована from table plan: host uuid,
-- Унаследована from table plan: apn uuid,
-- Унаследована from table plan: ptr uuid,
-- Унаследована from table plan: bufint bigint,
-- Унаследована from table plan: bufmem bigint,
-- Унаследована from table plan: bufdsk bigint,
-- Унаследована from table plan: exectime numeric(32,3),
-- Унаследована from table plan: duration numeric(32,3),
CONSTRAINT plan_20190221_pkey PRIMARY KEY (pack, recno),
CONSTRAINT chck_ptr CHECK (ptr IS NOT NULL),
CONSTRAINT plan_20190221_dt_check CHECK (dt = '2019-02-21'::date)
)
INHERITS (public.plan)
Vëllimi i përgjithshëm i seksionit përcaktohet nga numri i "fakteve" dhe varet vetëm nga proceset e jashtme, kështu që le të ndajmë madhësinë e grumbullit (pg_relation_size) nga numri i rekordeve në të - domethënë, marrim madhësia mesatare e regjistrimit aktual të ruajtur:
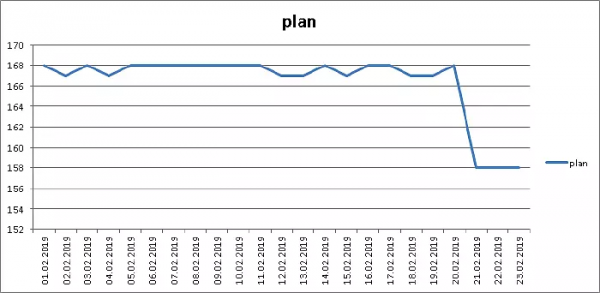
Minus 6% vëllim, E shkëlqyeshme!
Por gjithçka, natyrisht, nuk është aq rozë - në fund të fundit, në indekse nuk mund të ndryshojmë rendin e fushave, dhe për këtë arsye "në përgjithësi" (pg_total_relation_size) ...
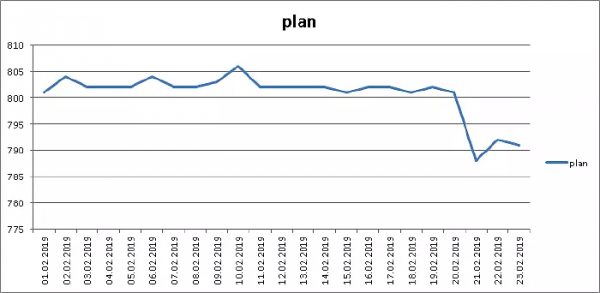
... edhe këtu kursyer 1.5%pa ndryshuar asnjë rresht të vetëm kodi. Po, po!

Vërej se opsioni i mësipërm për rregullimin e fushave nuk është fakti se është më optimali. Sepse ju nuk dëshironi të "shqyeni" disa blloqe fushash për arsye estetike - për shembull, një çift (pack, recno), e cila është PK për këtë tabelë.
Në përgjithësi, përcaktimi i renditjes "minimale" të fushave është një detyrë mjaft e thjeshtë e "forcës brutale". Prandaj, mund të merrni rezultate edhe më të mira nga të dhënat tuaja sesa tonat - provojeni!
Burimi: www.habr.com
