


Nga motivet e paraqitjeve të mia në Highload++ dhe DataFest Minsk 2019.
Për shumë njerëz sot, posta është një pjesë e pandashme e jetës në internet. Me ndihmën e saj, ne zhvillojmë korrespondencë biznesi, ruajmë të gjitha llojet e informacionit të rëndësishëm që lidhet me financat, rezervimin e hoteleve, porosinë e produkteve dhe shumë të tjera. Në mes të vitit 2018, formulua strategjia e zhvillimit të produktit të postës. Si duhet të jetë posta moderne?
Posta duhet të jetë inteligjente, domethënë të ndihmojë përdoruesit të orientohen në volumin në rritje të informacionit: të filtrojë, të strukturojë dhe të sigurojë atë në mënyrën më të përshtatshme. Ajo duhet të jetë e dobishme, duke lejuar që në kutinë postare të zgjidhen detyra të ndryshme, për shembull, të paguhen gjobat (funksion, të cilin, për fat të keq, e përdor). Dhe, natyrisht, posta duhet të sigurojë mbrojtje informacioni, duke filtruar spamin dhe duke mbrojtur nga thyerjet, dmth të jetë e sigurt.
Këto drejtime përcaktojnë një sërë detyrash kyçe, shumë prej të cilave mund të zgjidhen në mënyrë efektive me ndihmën e mësimdhënies të automatikës. Ja disa shembuj të funksionaliteteve që tashmë janë në punë, të zhvilluara si pjesë e strategjisë — nga një për çdo drejtim.
- Përgjigje e Mençur. Në postë ekziston funksioni i përgjigjes së mençur. Rrjeti nervor analizon tekstin e emailit, kupton kuptimin dhe qëllimin e tij, dhe si rezultat ofron tre opsione më të përshtatshme të përgjigjes: pozitive, negative dhe neutrale. Kjo ndihmon që të kursethni ndjeshëm kohë gjatë përgjigjeve të emaileve, si dhe shpesh ndihmon që të përgjigjeni në mënyrë kreative dhe argëtuese për veten.
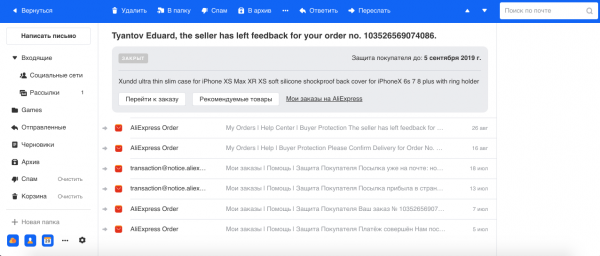
- Grupimi i emaileve, që lidhen me porositë në dyqanet online. Ne shpesh bëjmë blerje në internet, dhe zakonisht, dyqanet mund të dërgojnë disa letra për çdo porosi. Për shembull, nga AliExpress, shërbimi më i madh, vijnë shumë letra për një porosi të vetme, dhe ne llogaritëm se në rastin më ekstrem, numri i tyre mund të arrijë deri në 29. Prandaj, me modele të Njoftimit të Entiteteve, ne nxjerrim numrin e porosisë dhe informacion të tjera nga teksti dhe i grupojmë të gjitha letrat në një temë. Ne gjithashtu tregojmë informacionin kryesor mbi porosinë në një panel të veçantë, që lehtëson punën me këtë lloj letre.

- Antifishing. Phishing-u është një lloj mashtrimi veçanërisht i rrezikshëm, me të cilin keqbërësit përpiqen të marrin informacionin financiar (përfshirë kartat e bankës së përdoruesit) dhe emrat e përdoruesve. Këto letra imitojnë letra të vërteta, të dërguara nga shërbimi, duke përfshirë vizualisht. Prandaj, me ndihmën e Vizionit të Kompjuterit, ne njohim logot dhe stilin e dizajnit të letrave nga kompani të mëdha (për shembull, Mail.ru, Sber, Alfa) dhe e marrim këtë parasysh përveç tekstit dhe karakteristikave të tjera në klasifikatorët tanë të spam-it dhe phishing-ut.
Mësimi i makinerisë
Pak më shumë rreth mësimit të makinave në postë në përgjithësi. Posta është një sistem me ngarkesë të lartë: përmes serverëve tanë kalojnë, në mesatarisht, 1.5 miliard mesazhesh në ditë për 30 milion përdorues DAU. Ofrojnë të gjithë funksionet dhe karakteristikat e nevojshme rreth 30 sistemeve të mësimit të makinave.
Çdo mesazh kalon përmes një linje të plotë klasifikimi. Së pari, ne blokojmë spam-in dhe lëmë mesazhet e mira. Përdoruesit shpesh nuk e vërejnë punën e anti-spam-it, sepse 95-99% e spam-it nuk arrin as në dosjen përkatëse. Aftësia për të identifikuar spam-in është një pjesë shumë e rëndësishme e sistemit tonë dhe më e komplikuara, pasi në fushën e anti-spam-it ka një adaptim të vazhdueshëm midis sistemeve mbrojtëse dhe sulmuese, çka paraqet një sfidë inxhinierike të vazhdueshme për ekipin tonë.
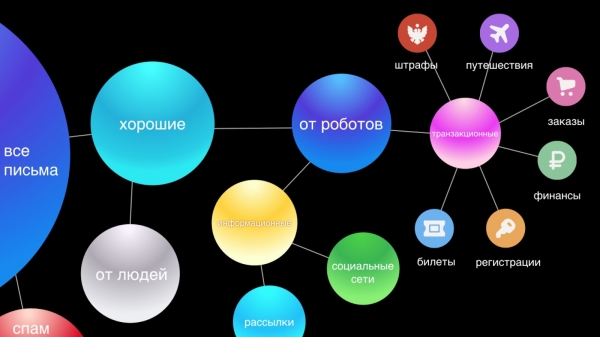
Më pas, ne ndarim mesazhet nga njerëzit dhe robotët. Mesazhet nga njerëzit janë më të rëndësishmet, ndaj për to ofrojmë funksione si Smart Reply. Mesazhet nga robotët ndahen në dy pjesë: ato transaksionale — që janë mesazhe të rëndësishme nga shërbimet, si për shembull, konfirmimet e blerjeve ose rezervimeve në hotel, financat, dhe ato informuese — që janë reklama biznesi, zbritje.
Ne mendojmë se letrat tregtare janë Po aq të rëndësishme sa korrespondenca personale. Ato duhet të jenë në dispozicion, pasi shpesh është e nevojshme të gjejmë shpejt informacion rreth porosisë ose rezervimeve të fluturimeve, ndërsa ne humbasim kohë duke kërkuar këto letra. Prandaj, për komfortin tonë, ne i ndajmë ato automatikisht në gjashtë kategori kryesore: udhëtimet, porositë, financat, biletat, regjistrimet dhe, përfundimisht, dënimet.
Letrat informacionale janë grupi më i madh dhe ndoshta më pak i rëndësishëm, që nuk kërkon një reagim të menjëhershëm, pasi asgjë thelbësore nuk do të ndryshojë në jetën e përdoruesit nëse ai nuk e lexon një letër të tillë. Në ndërfaqen tonë të re, ne i grumbullojmë ato në dy thread-e: rrjetet sociale dhe dërgesat, duke e pastruar vizualisht kutinë dhe lënë në dukje vetëm letrat e rëndësishme.
Ekspluatimi
Një numër i madh sistemesh sjell shumë vështirësi në funksionim. Modelet degradohen me kalimin e kohës, si çdo software tjetër: shfaqen defekte, makinat refuzojnë të funksionojnë, shkruhet kod i keq. Gjithashtu, të dhënat ndryshojnë vazhdimisht: shtohen të reja, transformohet modeli i sjelljes së përdoruesve etj., prandaj modelin pa mbështetje të duhur do të fillojë të funksionojë gjithnjë e më keq me kalimin e kohës.
Nuk duhet harruar se sa më shumë të thellohet mësimi i makinerive në jetën e përdoruesve, aq më shumë ndikim kanë ata në ekosistem, dhe, si pasojë, aq më shumë humbje financiare ose fitime mund të kenë lojtarët e tregut. Prandaj, në një numër gjithnjë e në rritje fushash, lojtarët adaptohen për të punuar me algoritmet e ML (shembuj klasikë — reklama, kërkimi dhe tashmë e përmendur anti-spam).
Gjithashtu, detyrat e mësimit të makinerive kanë një veçori: çdo ndryshim, madje edhe më i vogli, në sistem mund të sjellë shumë punë me modelin: punë me të dhënat, ri-trajnimi, vendosja, e cila mund të zgjasë për javë ose muaj. Prandaj, sa më shpejt të ndryshojë mjedisi në të cilin operojnë modelet tuaja, aq më shumë përpjekje kërkon mbështetje e tyre. Ekipa mund të krijojë shumë sisteme dhe të gëzohet për këtë, pastaj të shpenzojë pothuajse të gjitha burimet e saj për mbështetje, pa mundësi për të bërë diçka të re. Një situatë të tillë ne u përballëm një herë në ekipin tonë të anti-spamit. Dhe arritëm në përfundimin e qartë se mbështetje duhet të automatizohet.
Automatizimi
Çfarë mund të automatizohet? Në të vërtetë, pothuajse gjithçka. Kam përzgjidhur katër drejtime që përkufizojnë infrastrukturën e mësimit të makinerive:
- mbledhja e të dhënave;
- ri-trajnimi;
- vendosja;
- testimi & monitorimi.
Nëse ambienti është i paqëndrueshëm dhe vazhdimisht ndryshon, atëherë tërë infrastruktura rreth modelit bëhet shumë më e rëndësishme se vetë modeli. Mund të jetë një klasifikues i thjeshtë linear, por nëse e ushqeni si duhet me karakteristika dhe krijoni një feedback të mirë nga përdoruesit, atëherë ai do të funksionojë shumë më mirë se modelet më të avancuara me të gjitha pompimet.
Cikli i feedback-ut
Ky cikël përfshin mbledhjen e të dhënave, ri-trajnimin dhe përdorimin — në thelb, gjithë ciklin e përditësimit të modelit. Pse është e rëndësishme? Shikoni grafikun e regjistrimeve në postë:
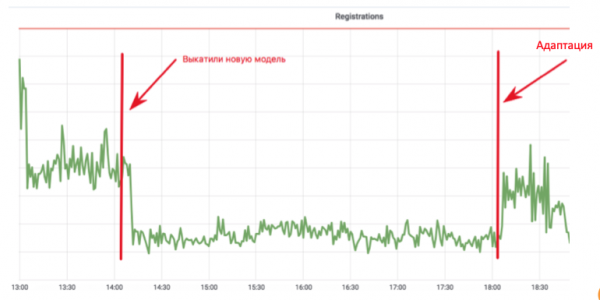
Programuesi i mësimit të makinave ka implementuar një model antibot, i cili nuk lejon që botët të regjistrohen në postë. Grafiku bie deri në një vlerë ku mbeten vetëm përdoruesit e vërtetë. E gjithë kjo është shkëlqyer! Por kalojnë katër orë, bot-kreatorët rregullojnë skenarët e tyre, dhe gjithçka kthehet në pikën e fillimit. Në këtë implementim, programuesi kaloi një muaj, duke shtuar karakteristika dhe ri-trajnuar modelin, por spameri arriti të adaptohej brenda katër orëve.
Për të mos qenë kaq painfully e vështirë dhe për të mos pasur nevojë të rregullojmë gjithçka më vonë, duhet të mendojmë fillimisht se si do të duket cikli i reagimit dhe çfarë do të bëjmë nëse ambienti ndryshon. Le të fillojmë me mbledhjen e të dhënave — ky është karburanti për algoritmet tona.
Mbledhja e të dhënave
E qartë se për rrjetet neurale moderne, sa më shumë të dhëna, aq më mirë, dhe këto janë, në thelb, të gjeneruara nga përdoruesit e produktit. Përdoruesit mund të na ndihmojnë duke etiketuar të dhënat, por nuk duhet keqpërdorur këtë, sepse përdoruesit në një moment do t'u mërzitet të mësojnë modelet tuaja dhe do të kalojnë në një produkt tjetër.
Një nga gabimet më të shpeshta (këtu po referohem tek Andrew Ng) — është një orientim tepër i fortë ndaj metrikave në datasetin e testimit, në vend të reagimeve nga përdoruesi, i cili në të vërtetë është masa kryesore e cilësisë, sepse ne krijojmë produktin për përdoruesin. Nëse përdoruesit nuk e kuptojnë ose nuk e pëlqejnë funksionimin e modelit, atëherë gjithçka është e kotë.
Prandaj, përdoruesi gjithmonë duhet të ketë mundësinë të votojë, prandaj duhet t’i ofrohet një mjet për feedback. Nëse ne mendojmë se në kuti ka ardhur një letër që i përket financave, duhet ta shënojmë atë si «financë» dhe të pozicionojmë një buton që përdoruesi mund të shtypë dhe të thotë se kjo nuk është financë.
Cilësia e feedback-ut
Le të flasim për cilësinë e feedback-ut të përdoruesve. Së pari, ju dhe përdoruesi mund të keni kuptime të ndryshme për një koncept të vetëm. Për shembull, ju dhe menaxherët e produktit mendoni se «financat» janë letra nga banka, ndërsa përdoruesi mendon se letra nga gjyshja për pensionin përbën gjithashtu financa. Së dyti, ka përdorues që pa menduar e duan të shtypin butona pa ndonjë logjikë. Së treti, përdoruesi mund të ketë keqkuptime të thella në përfundimet e tij. Një shembull i qartë nga praktika jonë është implementimi i klasifikuesit , një lloj shumë argëtues spami, kur përdoruesit i ofrohet të marrë disa miliona dollarë nga një kushëri i papritur që është gjetur në Afrikë. Pas implementimit të këtij klasifikuesi, ne kontrolluam klikimet 'Jo spam' në këto mesazhe, dhe doli se 80% e tyre ishin spama të shijshme nigeriane, që tregon se përdoruesit mund të jenë jashtëzakonisht besnikë.
Dhe nuk duhet të harrojmë se mbi butonat mund të klikojnë jo vetëm njerëzit, por edhe disa bota që bëjnë sikur janë shfletues. Kështu që feedbacku i papërpunuar nuk është i duhuri për trajnimin. Çfarë mund të bëjmë me këtë informacion?
Ne zbatojmë dy qasje:
- Feedback nga ML i lidhur. Për shembull, ne kemi një sistem online anti-bot dhe siç e përmenda më parë, ai merr një vendim të shpejtë në bazë të një numri të kufizuar karakteristikash. Dhe ka një sistem të dytë, të ngadalshëm, që punon post-faktum. Ai ka më shumë të dhëna për përdoruesin, për sjelljen e tij, etj. Si pasojë, merren vendime më të balancuara, ndaj ai ka saktësi dhe plotësi më të lartë. Diferenca në funksionimin e këtyre sistemëve mund të redirected në të parin si të dhëna për mësim. Në këtë mënyrë, sistemi më i thjeshtë do të përpiqet gjithmonë të afrohet me performancën e sistemit më kompleks.
- Klasifikimi i klikimeve. Mund të klasifikoni thjesht çdo klikim të përdoruesit, të vlerësoni vlefshmërinë e tij dhe mundësinë e përdorimit. Kështu veprojmë në anti-spamin e postës, duke përdorur karakteristikat e përdoruesit, historinë e tij, veçoritë e dërguesit, tekstin dhe rezultatet e klasifikuesve. Në fund marrim një sistem automatizues, që vlerëson feedback-un e përdoruesit. Dhe meqenëse ka nevojë për t'u trajnuar shumë më rrallë, puna e tij mund të bëhet themelore për të gjitha sistemet e tjera. Prioriteti kryesor në këtë model është preciziteti, sepse trajnimi i modelit me të dhëna të pasakta sjell pasoja.
Ndërsa ne pastrojmë të dhënat dhe mësojmë më tej sistemet tona ML, nuk duhet të harrojmë për përdoruesit, sepse për ne mijëra, miliona gabime në grafik janë statistika, ndërsa për përdoruesin çdo problem është një tragjedi. Përveç faktit që përdoruesi duhet të jetojë me gabimin tuaj në produkt, ai/ajo pas dhënies së feedback-ut pret që një situatë e tillë të mos përsëritet në të ardhmen. Prandaj, është gjithmonë e rëndësishme të ofroni përdoruesve jo vetëm mundësinë për të votuar, por edhe për të korrigjuar sjelljen e sistemeve ML, duke krijuar, për shembull, heuristika personale për çdo klikim feedback-u; në rastin e postës, kjo mund të jetë mundësia për të filtruar letra të tilla nga dërguesi dhe titulli për këtë përdorues.
Po ashtu, është e nevojshme që në bazë të disa raporteve ose ankesave në mbështetje të krijohet model në mënyrë semi-automatikisht ose manualisht, kështu që përdoruesit e tjerë mos të vuajnë nga probleme të ngjashme.
Heuristika për mësim
Me të dhënat e kësaj heuristike dhe shtrëngesave ka dy probleme. E para është se numri gjithnjë në rritje i shtrëngesave është e vështirë për t'u mbajtur, për të mos thënë për cilësinë dhe funksionimin e tyre në distancë të gjatë. Problemi i dytë është se gabimi mund të mos jetë i zakonshëm, dhe disa klikime për të mësuar më tej modelin do të ishin të pamjaftueshme. Ajo që duket si këto dy efekte të pa lidhura mund të kompensohet ndjeshëm nëse aplikohet qasja e mëposhtme.
- Krijojmë një shtrëngesë të përkohshme.
- Dërgojmë të dhënat nga ajo në model, i cili përditësohet rregullisht, përfshirë të dhënat e marra. Këtu, natyrisht, është e rëndësishme që heuristika të ketë një saktësi të lartë, që të mos ulin cilësinë e të dhënave në grupin e trajnim.
- Pastaj vendosim monitorim për aktivizimin e shtrëngesës, dhe nëse pas një periudhe shtrëngesa nuk aktivizohet më dhe mbulohet plotësisht nga modeli, atëherë mund ta heqim me siguri. Tani kjo problematikë është e pakët që do të përsëritet.
Pra, armata e shtrëngesave është shumë e dobishme. E rëndësishme është që shërbimi i tyre të jetë i përkohshëm, dhe jo të përhershëm.
Mësimi më tej
Ritraining është procesi i shtimit të të dhënave të reja, të marra si rezultat i feedback-ut nga përdoruesit ose nga sisteme të tjera, dhe mësimi i modelit ekzistues mbi to. Rreth ritrainimit mund të ketë disa probleme:
- Modeli mund të mos e mbështesë thjesht ritrainimin dhe të mësojë vetëm nga fillimi.
- Nuk ka asgjë në librin e natyrës që thotë se ritrainimi do të përmirësojë patjetër cilësinë e punës në prodhim. Ndodhin shpesh të kundërtat, pra është e mundur vetëm përkeqësimi.
- Ndryshimet mund të jenë të paparashikueshme. Ky është një çështje mjaft delikate që ne e kemi identifikuar për vete. Edhe nëse modeli i ri në A/B testim tregon rezultate të ngjashme krahasuar me aktualin, kjo nuk do të thotë aspak se do të punojë në të njëjtën mënyrë. Funksionimi i tyre mund të diferencojë në ndonjë përqindje që mund të sjellë gabime të reja ose të rikthejë ato të vjetra që janë korrigjuar. Me gabimet aktuale si ne, ashtu edhe përdoruesit, tashmë dimë të jetojmë, dhe kur ndodhin një numër i madh i gabimeve të reja, përdoruesi gjithashtu mund të mos e kuptojë se çfarë po ndodh, sepse ai pret një sjellje të parashikueshme.
Prandaj, e rëndësishme në rinovimin e modelit është të sigurojmë përmirësimin e tij, ose të paktën të mos e përkeqësojmë atë.
E para që na vjen në mendje kur flasim për rinovimin është qasja e Aktivës së Mësimit. Çfarë do të thotë kjo? Për shembull, një klasifikues përcakton nëse një letër i përket financave, dhe rreth kufijve të tij të vendosjes së vendimeve shtojmë një mostër të shembujve të etiketuar. Kjo funksionon mirë, për shembull, në reklamë, ku ka shumë reagime dhe mund të mësojmë modelin në mënyrë online. Por nëse ka pak reagime, atëherë marrim një mostër të konsiderueshme të përjashtuar në lidhje me shpërndarjen e dhënave në prodhim, mbi të cilën nuk mund të vlerësojmë sjelljen e modelit gjatë përdorimit.
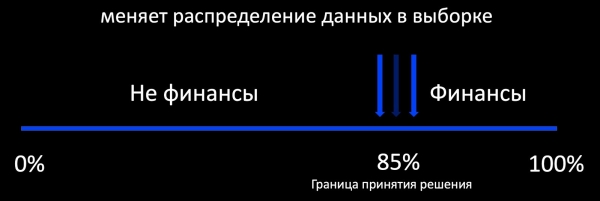
Në të vërtetë, qëllimi ynë është të ruajmë modelet e vjetra, të njohura për modelin, dhe të fitojmë të reja. Këtu vazhdimësia është e rëndësishme. Modeli, të cilin shpesh e hedhim me vështirësi, tashmë funksionon, prandaj mund të orientohemi mbi performancën e tij.
Në postë aplikohen modele të ndryshme: pemë, lineare, rrjete nervore. Për çdo një bëmë algoritmin tonë të ri-trajnimit. Në procesin e ri-trajnimit ne jo vetëm që marrim të dhëna të reja, por shpesh edhe karakteristika të reja, të cilat do të kemi parasysh në të gjithë algoritmët poshtë.
Modelet lineare
Le të marrim një regresion logjistik. E formojmë humbjen e modelit nga komponentët e mëposhtëm:
- LogLoss në të dhënat e reja;
- rregullojmë peshat e karakteristikave të reja (të vjetrat nuk i prekim);
- mësojmë edhe mbi të dhënat e vjetra për të ruajtur modelet e vjetra;
- dhe, ndoshta, më e rëndësishmja: vendosim Harmonic Regularization, e cila garanton që peshat e reja të mos ndryshojnë shumë në raport me modelin e vjetër në normë.
Duke qenë se çdo komponentë i humbjes ka koeficientë, ne mund të përcaktojmë vlerat optimale për detyrën tonë në kros-validim ose në përputhje me kërkesat produktive.
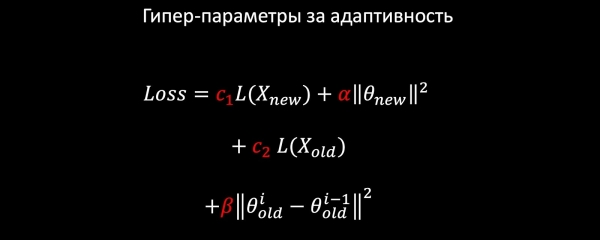
Pemët
Të kalojmë te pemët e vendimeve. Ne kemi realizuar algoritmin e mëposhtëm për ri-trajnim të pemëve:
- Në prodhim punon një pyll me 100—300 pemë, i cili është trajnuar në një dataset të vjetër.
- Ne eliminojmë në fund M = 5 copë dhe shtojmë 2M = 10 të reja, të stërvitur në të gjithë grupin e të dhënave, por me peshë të lartë për të dhënat e reja, që natyrshëm garanton një ndryshim inkremental të modelit.
Sigurisht, që me kalimin e kohës numri i pemëve rritet ndjeshëm, dhe ato duhet të reduktohen rregullisht për t'u përshtatur në kohë. Për këtë përdorim përhapjen e njohur tani Knowledge Distillation (KD). Më shkurt për parimin e tij të funksionimit.
- Ne kemi modelin aktual "të komplikuar". E nisim atë në grupin e të dhënave për trajnim dhe marrim shpërndarjen e probabiliteteve të klasave në daljen.
- Më pas e mësojmë modelin nxënës (në këtë rast, një model me më pak pemë) të përsërisë rezultatet e punës së modelit, duke përdorur shpërndarjen e klasave si variabël qëllimi.
- Është e rëndësishme të theksohet se ne nuk përdorim asnjë mënyrë markup të dataset-it dhe ndonjëherë mund të përdorim të dhëna rastësore. Sigurisht, ne përdorim një mostër të dhënash nga rrjedha live si një grup trajtimi për modelin e studentit. Kështu, grupi trening ofron saktësinë e modelit, ndërsa mostra e rrjedhës garanton performancë të ngjashme në shpërndarjen e prodhimit, duke kompensuar devijimin e grupit të trajtimit.
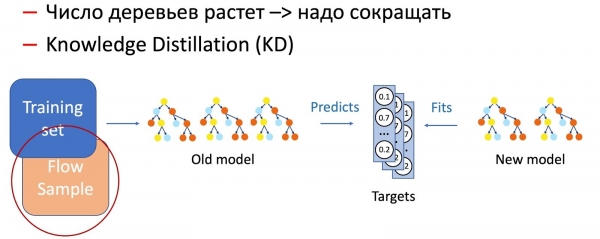
Kombinimi i këtyre dy metodave (shtimi i pemëve dhe reduktimi i rregullt i numrit të tyre nëpërmjet Knowledge Distillation) garanton hyrjen e modeleve të reja dhe vazhdimësinë e plotë.
Me KD, gjithashtu bëjmë dallimin e operacioneve me karakteristikat e modelit, siç është heqja e karakteristikave dhe funksionimi mbi mungesat. Në rastin tonë, kemi një sërë karakteristikash statistikore të rëndësishme (për dërguesit, hash-et tekstore, URL-të, etj.), të cilat ruhen në bazën e të dhënave, duke pasur një substancë që refuzon. Një zhvillim i tillë është, sigurisht, jashtë përgatitjes së modelit, pasi në setin e trajnimit nuk paraqiten situata refuzimi. Në raste të tilla, ne kombinojmë teknikat KD dhe augmentim: gjatë trajtimit për një pjesë të të dhënave, ne heqim ose zerojme karakteristikat e nevojshme, ndërsa etiketat (daljet e modelit aktual) i marrim origjinale, modeli nxënës mëson të përsërisë këtë shpërndarje.
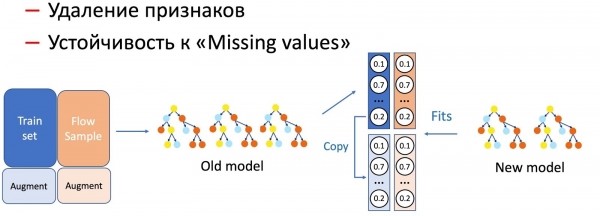
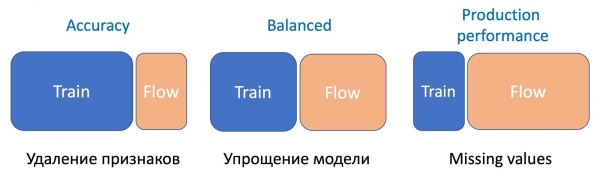
Kemi vënë re se sa më serioze të jetë manipulimi i modeleve, aq më shumë në proporcione kërkohet shtëpia e fluxit.
Për të hequr shenjat, operacioni më i thjeshtë kërkon vetëm një pjesë të vogël të rrjedhës, pasi ndryshohen vetëm disa shenja dhe modeli aktual ka mësuar mbi të njëjtin set — diferenca është minimale. Për të thjeshtuar modelin (reduktimin e numrit të pemëve disa herë), tashmë kërkohen 50 nga 50. Ndërsa për të humbur statistikat e rëndësishme që ndikojnë seriozisht në performancën e modelit, kërkohet më shumë rrjedhë për të balancuar funksionimin e modelit të ri që është i qëndrueshëm ndaj humbjeve në të gjitha llojet e shkresave.
FastText
Le të kalojmë te FastText. Kujtojmë se përfaqësimi (Embedding) i fjalës përbëhet nga shuma e embedding-ut të vetë fjalës dhe të gjitha N-gram e saj me shkronja, zakonisht trigramet. Duke qenë se mund të ketë mjaft trigrame, përdoret Bucket Hashing, pra transformimi i gjithë hapësirës në një harta të fixuar. Si rezultat, matrica e pesheve rezulton me dimensionin e sloj të brendshëm mbi numrin e fjalëve + bakete.
Kur trajnimi prishtisa shfaqen veçori të reja: fjalë dhe trigramë. Në trajtimin standard të modelit nga Facebook, nuk ndodhin ndryshime të rëndësishme. Trajtohen vetëm peshat e vjetra me entropi të kryqëzuar mbi të dhënat e reja. Në këtë mënyrë, veçoritë e reja nuk përdoren, natyrisht, ky qasje ka të gjitha mangësitë e përmendura më lart, që lidhen me paparashikueshmërinë e modelit në prodhim. Prandaj, ne kemi bërë disa përmirësime në FastText. Shtojmë të gjitha peshat e reja (fjalë dhe trigramë), trajtojmë të gjithë matricën me entropi të kryqëzuar dhe shtojmë rregullimin harmonik në përputhje me modelin linear, i cili garanton ndryshime të papërfillshme të peshave të vjetra.

CNN
Me rrjetet konvencionale është pak më e komplikuar. Nëse në CNN trajtohen katet e fundit, natyrisht, mund të aplikohet rregullimi harmonik dhe të sigurohet trashëgimia. Por në rastin kur kërkohet trajtimi i gjithë rrjetit, atëherë nuk mund të aplikoni një rregullim të tillë në të gjitha katet. Megjithatë, ka një mundësi me trajnimin e embedding-eve komplementarë përmes Triplet Loss ().
Triplet Loss
Në shembullin e detyrës së anti-fishing do të shqyrtojmë në përgjithësi Triplet Loss. Marrim logon tonë, si dhe shembuj pozitivë dhe negativë të logove të kompanive të tjera. Minimizohet distanca mes të parëve dhe maksimalizohet distanca mes të dytëve, duke e bërë këtë me një tolerancë të vogël për të siguruar një kompaktësi më të madhe të grupeve.
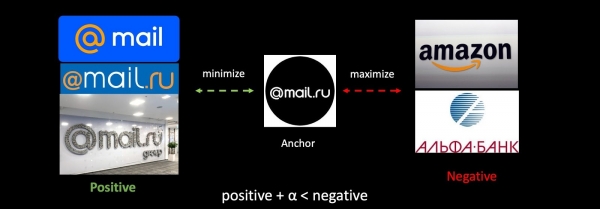
Nëse e ripërvojmë rrjetin, hapësira e matjes ndryshon plotësisht, dhe bëhet krejtësisht e papajtueshme me të mëparshmen. Kjo është një problem serioz në detyrat që përdorin vektorët. Për ta anashkaluar këtë problem, do të përziejmë ndërsa mësojmë embeddimet e vjetra.
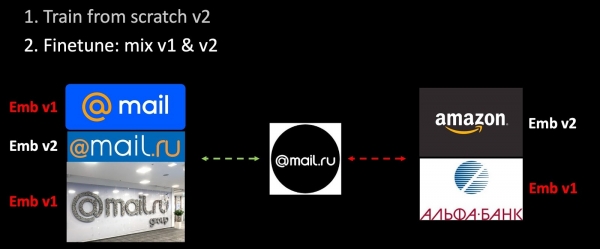
Ne kemi shtuar të dhëna të reja në setin e trajnimit dhe po mësojmë nga zero versionin e dytë të modelit. Në fazën e dytë, ne ripërvojmë rrjetin tonë (Finetuning): fillimisht, sa më shumë që përmirësohet, vetëm shtresa e fundit, pastaj zgjidhet e gjithë rrjeta. Në procesin e krijimit të trejve, vetëm një pjesë e embeddimeve llogaritet me modelin e mësuar, pjesa tjetër me të vjetrin. Kështu, gjatë ripërvojës sigurojmë pajtueshmërinë e hapësirave të matjes v1 dhe v2. Një version i veçantë i regularizimit harmonik.
Arkitektura e plotë
Nëse e shqyrtojmë sistemin si një tërë për shembullin e anti-spamit, atëherë modelet nuk janë të izoluara, por janë të shtrira njëra brenda tjetrës. Marrim figura, tekst dhe karakteristika të tjera, duke përdorur CNN dhe Fast Text për të marrë embedding. Më pas, mbi embedding aplikohet klasifikuesit, të cilët japin skora për klasa të ndryshme (llojet e mesazheve, spam, prania e logos). Skorët dhe karakteristikat tashmë në pikën e vendimmarrjes përmes një pylli drurësh. Klasifikuesit e ndarë në këtë skemë lejojnë një interpretim më të mirë të rezultateve të sistemit dhe të përmirësojnë më saktë komponentët në rast se shfaqen probleme, sesa t'i dorëzojmë të dhënat e plota në drunjtë e vendimmarrjes në formën e papërpunuar.
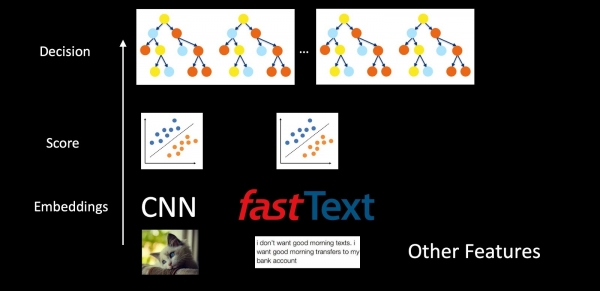
Si rezultat, ne garantojmë pasardhës të çdo niveli. Në nivelin e poshtëm në CNN dhe Fast Text përdorim rregullimin harmonik, për klasifikuesit në mes — gjithashtu rregullimin harmonik dhe kalibrimin e skores për përputhshmërinë e shpërndarjes së probabilitetit. Ndërsa boostimi i drurëve mësohet në mënyrë incrementale ose përmes Knowledge Distillation.
Në përgjithësi, mbështetje për një sistem të tillë të thelluar të mësimit të makinave zakonisht paraqet vështirësi, pasi çdo komponent në nivelin më të ulët çon në përditësimin e krejt sistemit më lart. Por duke qenë se në konfigurimin tonë çdo komponent ndryshon pak dhe është i pajtueshëm me atë të mëparshëm, e gjithë sistemi mund të përditësohet në pjesë pa pasur nevojë të ritrainojmë tërë strukturën, çka lejon mbështetje pa ndonjë ngarkesë serioze.
Dërgo
Kemi shqyrtuar mbledhjen e të dhënave dhe ritrainimin e llojeve të ndryshme të modeleve, prandaj po kalojmë në dërgimin e tyre në ambientin e prodhimit.
Testimi A/B
Si e thashë më parë, gjatë procesit të mbledhjes së të dhënave, zakonisht marrim një mostër me devijim, e cila nuk lejon të vlerësojmë performancën prodhuese të modelit. Prandaj, kur zbatohet modelin, është e domosdoshme të krahasohet me versionin e mëparshëm, për të kuptuar se si po shkojnë punët në të vërtetë, pra duhet të kryhen testet A/B. Në fakt, procesi i përgatitjes dhe analizës së shifrave është mjaft rutinë dhe i përshtatet automatikisht. Ne ia dalim të nxjerrim modelet tona gradualisht në 5%, 30%, 50% dhe 100% të përdoruesve, duke mbledhur të gjitha metrikat e disponueshme për përgjigjet e modelit dhe feedback-un e përdoruesve. Në rast të ndonjë devijimi të rëndësishëm, ne automatikisht e përshtasim modelin, ndërsa për rastet e tjera, pasi të kemi marrë një numër të mjaftueshëm klikimesh nga përdoruesit, marrim vendimin për rritjen e përqindjes. Si përfundim, e çojmë modelin e ri deri në 50% të përdoruesve plotësisht automatikisht, ndërsa shpërndarjen për të gjithë audiencën e miraton një njeri, edhe pse ky hap mund të automatizohet gjithashtu.
Megjithatë, proceset e testimeve A/B ofrojnë mundësi për optimizim. Problemi është se çdo test A/B zgjat mjaft gjatë (në rastin tonë, ai zgjat nga 6 deri në 24 orë në varësi të sasisë së feedback-ut), duke e bërë atë mjaft të shtrenjtë dhe me burime të kufizuara. Përveç kësaj, kërkohet një përqindje mjaft e lartë e fluksit për testin, për të përshpejtuar kohën totale të testit A/B (të grumbullosh një mostër statistikisht domethënëse për vlerësimin e matjeve në një përqindje të vogël mund të zgjasë shumë), që e bën numrin e vendeve për A/B teste jashtëzakonisht të kufizuar. Është e qartë se na nevojitet të nxjerrim në test vetëm modelet më premtuese, të cilat gjatë procesit të ristrukturohen ne merrim mjaft shumë.
Për të zgjidhur këtë problem, ne trajnuam një klasifikues të veçantë, i cili parashikon suksesin e testit A/B. Për këtë, si karakteristika marrim statistikën e marrjes së vendimeve, Precizionin, Rrethinë dhe metrika të tjera mbi grupin mësues, mbi atë të mbajtur dhe mbi një mostër nga fluksi. Gjithashtu krahasojmë modelin me atë aktual në prodhim, me heuristikët dhe marrim parasysh kompleksitetin e modelit. Duke përdorur të gjitha këto karakteristika, klasifikuesi i trajnuar mbi historinë e testeve vlerëson kandidatët e modeleve, në rastin tonë këto janë pyjet e pemëve, dhe merr një vendim se cilin prej tyre ta dërgojë në testin A/B.
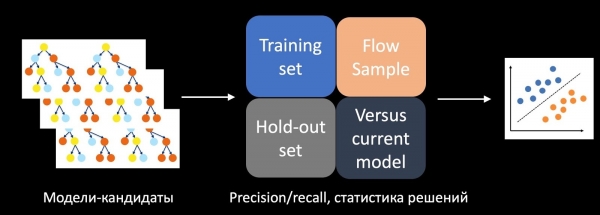
Në momentin e implementimit, ky qasje lejoj që numri i testeve A/B të suksesshme të rritet disa herë.
Testimi & monitorimi
Testimi dhe monitorimi, siç tregon çudi, nuk dëmtojnë shëndetin tonë, përkundrazi, përmirësojnë dhe na përshpejtojnë nga streset e tepruara. Testimi mund të parandalojë dështimin, ndërsa monitorimi — ta zbulojë atë në kohë, për të reduktuar ndikimin mbi përdoruesit.
Është e rëndësishme të kuptoni se herët a vonë sistemi juaj gjithmonë do të gabojë — kjo është e lidhur me ciklin e zhvillimit të çdo programi. Në fillim të zhvillimit të sistemit ka shumë defekte derisa gjithçka të stabilizohet dhe të përfundojë faza kryesore e risive. Por me kalimin e kohës, entropia bën të vetën, dhe gabimet shfaqen përsëri — për shkak të degradimit të komponentëve dhe ndryshimeve në të dhëna, siç e thashë më parë.
Këtu do të doja të theksoja se çdo sistem të mësuarit të makinerisë duhet të shihet nga këndvështrimi i përfitimit të tij gjatë gjithë ciklit të jetës. Më poshtë në grafik është një shembull i funksionimit të sistemit për kapjen e një specie të rrallë të spamit (në grafik linja është afër zeros). Njëherë për shkak të një karakteristike të gabuar të të dhënave, ai u çmend. Me fat, nuk kishte monitorim për përdorimin anormal, si rezultat sistemi filloi të ruante email-e në dosjen "spam" në kufirin e vendimit në një sasi të madhe. Pavarësisht nga rregullimi i pasojave, sistemi tashmë kishte gabuar aq shumë herë sa nuk do ta shlyejë kurrë kostot as për pesë vjet. Kjo është një dështim total nga këndvështrimi i ciklit të jetës së modelit.
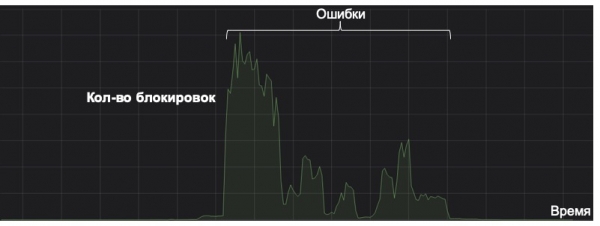
Prandaj, një gjë kaq e thjeshtë si monitorimi mund të bëhet thelbësore në jetën e modelit. Përveç metrikeve standarde dhe të dukshme, ne shqyrtojmë shpërndarjen e përgjigjeve dhe skorëve të modelit, si dhe shpërndarjen e vlerave të veçorive kyçe. Me anë të divergencës KL, ne mund të krahasojmë shpërndarjen aktuale me atë historike ose vlerat në testimin A/B me rrjedhën tjetër, që na lejon të vërejmë anomalitë në model dhe të kthehemi mbrapa me ndryshimet në kohë.
Në shumicën e rasteve, ne i lançojmë versionet tona të para të sistemeve me anë të heuristikave të thjeshta ose modeleve, të cilat më vonë i përdorim për monitorim. Për shembull, ne monitorojmë modelin NER në krahasim me regex për dyqane specifike online, dhe nëse mbulimi i klasifikuesit bie në krahasim me ato, atëherë shqyrtojmë arsyet. Një tjetër përdorim i dobishëm i heuristikave!
Përfundimet
Të kalojmë përsëri përmes mendimeve kryesore të artikullit.
- Fibdæk. Gjithmonë mendojmë për përdoruesin: si do të jetojë ai me gabimet tona dhe si do t’i raportojë ato. Nuk harrojmë se përdoruesit nuk janë një burim i pastër feedback-u për të mësuar modelet, dhe ky feedback duhet të filtrohet me ndihmën e sistemeve të asistuara ML. Nëse nuk ka mundësi për të mbledhur sinjale nga përdoruesi, ne kërkojmë burime alternative feedback-u, si sistemet e lidhura.
- Mësimi më tej. Këtu kryesorja është kontinuiteti, prandaj mbështetemi në modelin aktual në prodhim. Modelet e reja i trajnojmë në mënyrë që të mos diferencohen shumë nga të parat përmes rregullimit harmonik dhe trukeve të ngjashme.
- Dërgo. Autodeploy sipas metrikave redukton ndjeshëm kohën për implementimin e modeleve. Monitorimi i statistikave dhe shpërndarjes së vendimeve, numri i dështimeve nga përdoruesit është i domosdoshëm për gjumin tuaj të qetë dhe fundjavët produktive.
Shpresoj që ai që keni lexuar do t'ju ndihmojë të përmirësoni më shpejt sistemet tuaja ML, t'i nxirrni ato në treg më shpejt dhe t'i bëni ato më të besueshme, duke zvogëluar stresin nga puna.
Burimi: habr.com
