

Nëse jeni zhvillues dhe përballeni me detyrën e zgjedhjes së kodimit, pothuajse gjithmonë zgjidhja e duhur do të jetë Unicode. Mënyra specifike e paraqitjes varet nga konteksti, por shpesh ka një përgjigje universale — UTF-8. Ai është i mirë sepse lejon përdorimin e të gjitha simboleve Unicode, pa shpenzuar shumë byte në shumicën e rasteve. Megjithatë, për gjuhët që përdorin më shumë se vetëm alfabetin latinë, «jo shumë» do të thotë të paktën dy byte për simbol. A është e mundur të kemi më mirë, pa u rikthyer në kodimet parahistorike që na kufizojnë në vetëm 256 simbole të disponueshme?
Më poshtë propozoj të njihemi me përpjekjen time për të dhënë një përgjigje për këtë pyetje dhe realizimin e një algoritmi relativisht të thjeshtë, që lejon ruajtjen e stringjeve në shumicën e gjuhëve të botës, pa shtuar atë tepërsinë që ka UTF-8.
Diskleimer. Menjëherë do të bëj disa sqarime të rëndësishme: zgjidhja e përshkruar nuk ofrohet si një zëvendësim universale për UTF-8, është i përshtatshëm vetëm në një listë të ngushtë rastesh (për të cilat do të flas më poshtë), dhe në asnjë rast nuk duhet përdorur për ndërveprimin me API të jashtme (të cilat as nuk e dinë për të). Më së shpeshti, për ruajtjen kompakte të sasi të mëdha të të dhënave tekstuale, algoritmet e kompresimit të përdorura për qëllime të përgjithshme do të jenë të përshtatshme (p.sh., deflate). Për më tepër, gjatë procesit të krijimit të zgjidhjes sime, kam gjetur një standard ekzistues në vetë Unicode që zgjidh të njëjtën çështje — është pak më i komplikuar (dhe shpeshherë më i dobët), por gjithsesi është një standard i pranuar, dhe jo diçka e mbledhur nxitimthi. Për atë do të flas gjithashtu.
Për Unicode dhe UTF-8
Së pari — disa fjalë rreth asaj se çfarë është në të vërtetë Unicode dhe UTF-8.
Si e dimë, më parë ishin të njohura kodifikimet 8-bit. Me to gjithçka ishte e thjeshtë: 256 simbole mund të numëroheshin me numra nga 0 deri në 255, dhe numrat nga 0 deri në 255 paraqiten qartë si një bajt. Nëse kthehemi në origjinat më të hershme, kodifikimi ASCII është i kufizuar në 7 bit, prandaj biti më i lartë në përfaqësimin e saj në bajt është zero, dhe shumica e kodifikimeve 8-bit janë të përputhshme me të (ato ndryshojnë vetëm në pjesën e “sipërme”, ku biti më i lartë është një).
Çfarë e ndan Unicode nga ato kodifikime dhe pse lidhen me të shumë përfaqësime specifike — UTF-8, UTF-16 (BE dhe LE), UTF-32? Le të shqyrtojmë radhazi.
Standardi kryesor i Unicode përshkruan vetëm korrespondencën midis simboleve (dhe në disa raste — komponentëve të veçantë të simboleve) dhe numrat e tyre. Dhe numrat e mundshëm në këtë standard janë shumë të shumtë — nga 0x00 deri te 0x10FFFF (1 114 112 copje). Nëse do të donim të vendosnim një numër në një gamë të tillë në një variabël, as 1 as 2 byte nuk do të ishin të mjaftueshme. Dhe, duke qenë se procesorët tanë nuk janë shumë të adaptuar për punë me numra tre-byte, do të ishim të detyruar të përdorim plot 4 byte për një simbol! Ky është UTF-32, por pikërisht për këtë «shpenzim» ky format nuk është popullor.
Fatmirësisht, simbolët brenda Unicode-it nuk janë renditur rastësisht. Të gjithë numri i tyre është i ndarë në 17 «plane», secila prej të cilave përmban 65536 (0x10000) «pikë kodimi». Koncepti «pikë kodimi» këtu është thjesht numri i simbolit, i caktuar atij nga Unicode. Por, siç u tha më lart, në Unicode nuk janë numeruar vetëm simbolët e veçantë, por edhe komponentët e tyre dhe shënimet shërbimore (ndonjëherë as që i përputhen ndonjë numri — ndoshta për një periudhë të caktuar, por për ne nuk është kaq e rëndësishme), prandaj është më korrekte të flitet gjithmonë për numrin e numrave, e jo të simbolëve. Megjithatë, më poshtë për shkak të shkurtimit shpesh do të përdor fjalën «simbol», duke nënkuptuar termin «pikë kodimi».
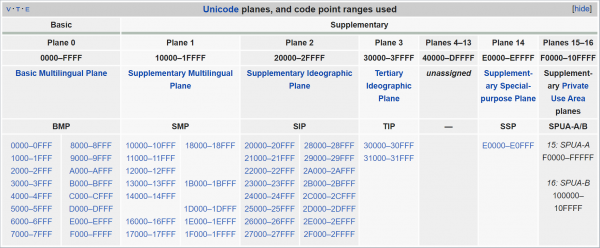
Plane të Unicode-it. Siç duket, pjesa më e madhe (planet nga 4 në 13) ende nuk është përdorur.
E mira është se e gjithë pjesa kryesore "mjaft" ndodhet në planin zero, i quajtur "Plani Multilinguistik Bazik". Nëse rreshti përmban tekst në një nga gjuhët moderne (përfshirë kinezishten), nuk do të dalësh jashtë këtij plani. Sidoqoftë, nuk mund të prerësh pjesën tjetër të Unicode gjithashtu — për shembull, emoji kryesisht ndodhen në fund të nivelit të ardhshëm, "Plani Multilinguistik Shtesë" (që shtrihet nga 0x10000 deri te 0x1FFFF). Prandaj, UTF-16 vepron kështu: të gjitha simbolet që bien në Plani Multilinguistik Bazik, kodifikohen "ashtu si janë", me numrin e tyre dy-bajtësh përkatës. Megjithatë, disa nga numrat në këtë gamë nuk tregojnë asnjë simbol të veçantë, por tregojnë se pas kësaj çifti bajt duhet të shqyrtohet një tjetër — duke kombinuar vlerat e këtyre katër bajtëve së bashku, ne do të kemi një numër që mbulon të gjithë gamën e lejueshme të Unicode. Ky paraqitje quhet "çiftet zëvendësuese" — ndoshta keni dëgjuar për to.
Kështu, UTF-16 kërkon dy ose (në raste shumë të rralla) katër byte për një "pikë kodimi". Kjo është më mirë se sa të përdorësh vazhdimisht katër byte, por latinishtja (dhe simbolet e tjera ASCII) në këtë kodim shpenzojnë gjysmën e hapësirës për zero. UTF-8 është krijuar për ta rregulluar këtë: ASCII në të zë, si më parë, vetëm një byte; kodet nga 0x80 deri te 0x7FF — dy byte; nga 0x800 deri te 0xFFFF — tre, dhe nga 0x10000 deri te 0x10FFFF — katër. Nga njëra anë, latinishtja ka përfituar: u rikthye kompatibiliteti me ASCII, dhe shpërndarja është më e shpërndarë "e shpërndarë" nga 1 deri në 4 byte. Por alfabetet e ndryshme nga latinishtja, fatkeqësisht, nuk përfitojnë asgjë krahasuar me UTF-16, dhe shumë tani kërkojnë në fakt tre byte në vend të dy — diapazoni i mbuluar nga regjistrimi dy-byte është ngushtuar 32 herë, nga 0xFFFF deri te 0x7FF, dhe tani nuk përfshin as kinez, as, për shembull, gjeorgjian. Kirilica dhe pesë alfabete të tjera — u ra fat — kanë fat, 2 byte për simbol.
Pse ndodh kështu? Le të shohim se si UTF-8 paraqet kodet e simboleve:

Për të paraqitur numrat këtu janë përdorur drejtpërdrejt bitët, të shënuar me simbolin x. Është e dukshme se në regjistrimin me dy byte ka vetëm 11 bitë (nga 16). Bitët udhëheqës këtu kanë vetëm funksion shërbimi. Në rastin e regjistrimit me katër byte, numri i pikës koduese merr 21 bitë nga 32 — duket se këtu do të mjaftonin tre byte (të cilat japin gjithsej 24 bitë), por markerat shërbimi konsumojnë shumë.
A është kjo një gjë e keqe? Në të vërtetë, jo shumë. Nga njëra anë — nëse na intereson shumë hapësira që zëmë, kemi algoritme kompresimi që lehtësisht do të eliminojnë gjithë entropinë dhe tepricën. Nga ana tjetër — qëllimi i Unicode është të ofrojë kodim sa më universale. Për shembull, një varg i koduar në UTF-8 mund t'i besohet një kodi që më parë punonte vetëm me ASCII, dhe nuk kemi frikë se ai do të shohë një karakter nga diapazoni ASCII që në të vërtetë nuk ekziston (sepse në UTF-8, të gjitha bajtat që fillojnë me bitin zero janë në të vërtetë ASCII). Dhe nëse do të donim të prisnim një bisht të vogël nga një varg të madh, pa e dekoduar atë nga fillimi (ose të rikuperonim disa informacione pas një pjese të dëmtuar) — nuk është e vështirë të gjendet duke filluar nga ndonjë simbol (mjafton të kalosh mbi bajtat që kanë prefiksin e bitit) 10).
Pse duhet të shpikim diçka të re?
Në të njëjtën kohë, ndonjëherë ndodhin situata kur algoritmet e kompresimit si deflate nuk janë shumë të aplikueshme, dhe dëshirojmë të arrijmë ruajtjen kompakte të vargjeve. Personal, kam përballur një detyrë të tillë, duke reflektuar mbi ndërtimin për një fjalor të madh, që përfshin fjalë në gjuhë të ndryshme. Nga njëra anë — çdo fjalë është shumë e shkurtër, kështu që shkrirja e saj do të ishte e pamjaftueshme. Nga ana tjetër — implementimi i pemës që kam shqyrtuar, ishte parashikuar që çdo bajt i vargut të ruajtur të krijonte një majë të veçantë të pemës, kështu që minimizimi i numrit të tyre ishte shumë i dobishëm. Në bibliotekën time (ashtu si në , në të cilën është e bazuar) një problem i tillë zgjidhet lehtësisht — vargjet e paketuar në -fjalor, ruhen atje në . Por, siç është e lehtë të kuptohet, kjo funksionon mirë vetëm për një alfabet të kufizuar — një varg në kinezisht nuk mund të ruhen në një fjalor të tillë.
Veçmas do të përmend një tjetër nuancë të pakëndshme që shfaqet kur përdoret UTF-8 në një strukturë të tillë të dhënash. Në figurën e mësipërme shihet se, kur regjistrohet simboli si dy bajta, bitët që i përkasin numrit të tij, nuk ndodhin të gjithë së bashku, por janë të ndara nga një çift bitësh 10 në mes: 110xxxxx 10xxxxxx. Për shkak të kësaj, kur në kodin e simbolit mbushen 6 bitët më të ulët të bajtëve të dytë (dmth. ndodh kalimi 10111111 → 10000000), atëherë ndërlikohet edhe bajti i parë. Si rezultat, letra «п» përfaqësohet nga bajtët 0xD0 0xBF, dhe e ardhshme pas saj "r" — tashmë 0xD1 0x80. Në pemën prefiks, kjo çon në shpërbërjen e majës prind në dy — një për prefiksin 0xD0, dhe një tjetër për 0xD1 (edhe pse e gjithë cirilika mund të kodifikohej vetëm me bajtin e dytë).
Çfarë kam arritur
Duke u përballur me këtë sfidë, vendosa të ushtrohem me lojra me bits, dhe gjithashtu të njoh pak më mirë strukturën e Unicode-it në përgjithësi. Rezultati ishte formati i kodimit UTF-C ("C" nga kompakt), që shpenzon jo më shumë se 3 bajta për një pikë kodimi, dhe shumë shpesh lejon që të shpenzojë vetëm një bajt shtesë për tërë rreshtin e koduar. Kjo bën që në shumë alfabetet jo-ASCII, ky kodim të jetë 30-60% më kompakt se UTF-8.
Kam organizuar shembuj të zbatimeve të algoritmeve të kodimit dhe dekodimit në formën , ju mund t'i përdorni ato lirshëm në kodin tuaj. Por unë ende do të theksoj që në një farë mënyre ky format mbetet "bicikletë", dhe nuk e rekomandoj ta përdorni pa kuptuar se përse ju nevojitet. Kjo është më shumë një eksperiment sesa një "përmirësim serioz i UTF-8". Megjithatë, kodi është shkruar me kujdes, me përmbledhje të qarta, komente të shumta dhe mbulimin me teste.
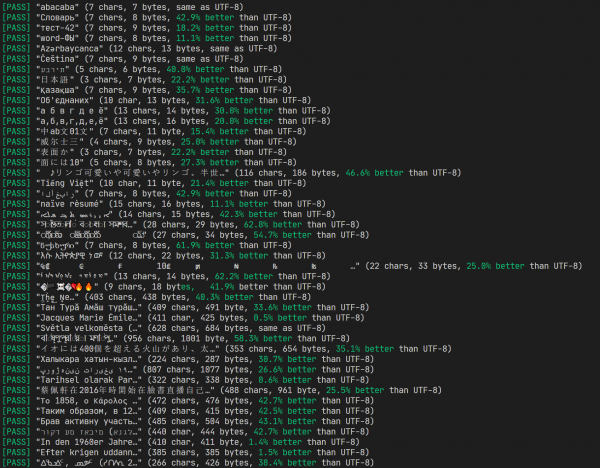
Rezultati i ekzekutimit të testeve dhe krahasimi me UTF-8
Gjithashtu kam bërë , ku mund të vlerësoni punën e algoritmit, dhe më pas do të flas për parimet dhe procesin e zhvillimit më në detaje.
Eliminimi i bitëve të tepërt
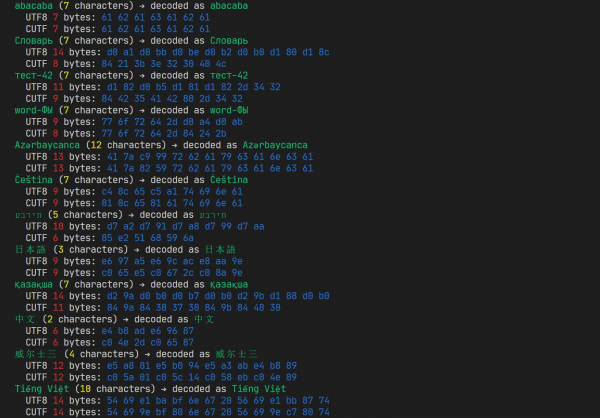
Për bazë kam marrë, sigurisht, UTF-8. E para dhe më e dukshme që mund të ndryshohet është - të reduktohet numri i bitëve ndihmës në çdo byte. Për shembull, byte i parë në UTF-8 gjithmonë fillon ose me 0, ose me 11 — dhe prefiksi 10 është vetëm në byte të ardhshëm. Do ta zëvendësojmë prefiksin 11 në 1, dhe do të heqim plotësisht prefikset në byte të ardhshëm. Çfarë do të nxjerrim?
0xxxxxxx — 1 byte
10xxxxxx xxxxxxxx — 2 byte
110xxxxx xxxxxxxx xxxxxxxx — 3 byte
Stop, ku është regjistrimi me katër byte? Nuk është më e nevojshme - me regjistrimin me tre byte tani kemi në dispozicion 21 bit dhe këtë e kemi mëse mjaftueshëm për të gjithë numrat deri në 0x10FFFF.
Çfarë ndihmuam këtu? E rëndësishmja është zb discoverimi i kufijve të simboleve nga një vend të rastësishëm në tampon. Nuk mund të gjuajmë në një bajt të rastësishëm dhe të gjejmë fillimin e simbolit tjetër. Ky është një kufizim i formatit tonë, por në praktikë nevoja për një gjë të tillë ndodh rrallë. Zakonisht, jemi në gjendje të kalojmë tamponin nga fillimi (sidomos kur bëhet fjalë për rreshta të shkurtër).
Situata me mbulimin e gjuhëve me 2 bajta gjithashtu është përmirësuar: tani formati dy-bajtësh ofron një gamë prej 14 bitësh, që do të thotë kode deri në 0x3FFF. Kinezët nuk kanë fat (hieroglifet e tyre kryesisht bien në gamën nga 0x4E00 deri te 0x9FFF), por georgianët dhe shumë popuj të tjerë kanë pasur më shumë gëzim — gjuhët e tyre gjithashtu ndodhen në 2 bajta për simbol.
Jemi duke futur gjendjen e koduesit
Le të mendojmë tani për vetitë e vetë rreshtave. Në fjalor zakonisht gjenden fjalë të shkruara me simbole të një alfabete, dhe kjo është e vërtetë për shumë tekste të tjera gjithashtu. Do të ishte mirë të përcaktonim një herë këtë alfabet, dhe pastaj të tregojmë vetëm numrin e shkronjës brenda tij. Le të shohim nëse na ndihmon vendosja e simboleve në tabelën Unicode.
Siç u tha më sipër, Unicode është ndarë në planesh me 65536 kodet për secilën. Por kjo ndarje nuk është shumë e dobishme (siç është thënë, më shpesh ne jemi në planin zero). Një ndarje më interesante është ajo në bloke. Këto intervale tani nuk kanë një gjatësi fikse dhe kanë më shumë kuptim — si rregull, secili bashkon simbole të një alfabeti.
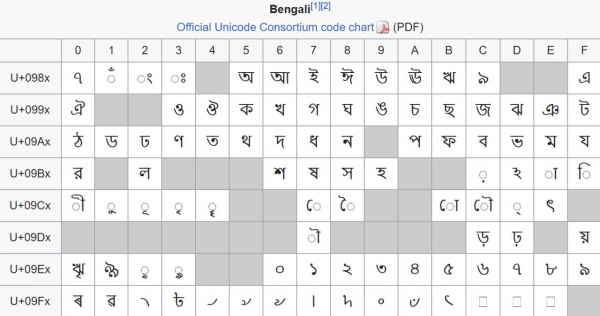
Blloku që përmban simbole të alfabetit bengali. Fatkeqësisht, për shkaqe historike, ky është një shembull i paketimit të ngjeshur jo shumë mirë — 96 simbole janë shpërndarë në mënyrë kaotike në 128 kodet e bllokut.
Fillimet e bllokut dhe përmasat e tyre gjithmonë janë shumëfish të 16 — kjo u bë vetëm për lehtësi. Për më tepër, shumë blloqe fillojnë dhe përfundohen në vlera shumëfish të 128 ose madje 256 — për shembull, kyrilika kryesore zë 256 byte nga 0x0400 deri te 0x04FF. Kjo është shumë e përshtatshme: nëse një herë ruajmë prefiksin 0x04, atëherë çdo simbol kyrilik mund të shkruhet me një byte. Megjithatë, kështu ne do të humbim mundësinë për të kthyer në ASCII (dhe çdo simbol tjetër në përgjithësi). Prandaj veprojmë kështu:
- Dy byte
10yyyyyy yxxxxxxxjo vetëm që tregojnë simbolin me numëryyyyyy yxxxxxxx, por gjithashtu ndryshojnë alfabetin aktual nëyyyyyy y0000000(dmth. mbajmë të gjithë bitët përveç atyre më të rinjve 7 bit); - Një byte
0xxxxxxxky është simboli i alfabetit aktual. Thjesht duhet ta shtojmë me atë zhvendosje që e mbajmë mend në hapin 1. Deri tani nuk e kemi ndryshuar alfabetin, prandaj zhvendosja është zero, kështu që kemi ruajtur përputhshmëri me ASCII.
Njësoj për kodet që kërkojnë 3 byte:
- Të tre byte
110yyyyy yxxxxxxx xxxxxxxxtregon simbolin me numëryyyyyy yxxxxxxx xxxxxxxx, ndryshon alfabetin aktual nëyyyyyy y0000000 00000000(mbajmë mend gjithçka, përveç më të riut 15 bit), dhe vendosim një flamur që tani jemi në modalitet të gjatë kjo do të thotë gjatë përdorimit të alfabetit të dyta byte do ta reshtojmë këtë flamur); - Dy byte
0xxxxxxx xxxxxxxxnë modalitetin e gjatë, ky është simboli i alfabetit aktual. Njësoj, ne e shtojmë atë me zhvendosjen nga hapi 1. E gjithë ndryshimi është se tani lexojmë dy byte (sepse kemi kaluar në këtë modalitet).
Dëgjon mirë: tani kur na nevojitet të kodojmë simbolet nga një gamë të njëjtë 7-bit të Unicode, ne harxhojmë 1 byte shtesë në fillim dhe vetëm një byte për çdo simbol.
Funksionimi i një versioni të hershëm. Tani shpesh kalon UTF-8, por ende ka hapësira për përmirësim.
Çfarë ka shkuar më keq? Së pari, kemi një gjendje, domethënë zhvendosjen e alfabetit aktual dhe flamurin modalitet të gjatë. Kjo na kufizon më tej: tani të njëjtat simbole mund të kodifikohen në mënyra të ndryshme në kontekste të ndryshme. Kërkimi i nënshkronjave, për shembull, do të duhet të bëhet duke marrë parasysh këtë, e jo thjesht duke krahasuar bajtët. Në të dytën, sapo ndërruam alfabetin, pati probleme me kodimin e simboleve ASCII (dhe kjo është jo vetëm latinisht, por edhe pikaturat bazë, duke përfshirë hapësirat) - ato kërkojnë një ndërrim të përsëritur të alfabetit në 0, pra përsëri një bajt të tepërt (dhe pastaj edhe një tjetër, për t'u kthyer te baza jonë).
Një alfabet është mirë, dy - më mirë
Le të provomë ta ndryshojmë pak prefiksin tonë të bajtëve, duke shtuar një tjetër përkatësisht tri që u përmendën më lart:
0xxxxxxx — 1 bajt në modin normal, 2 në atë të gjatë
11xxxxxx — 1 byte
100xxxxx xxxxxxxx — 2 byte
101xxxxx xxxxxxxx xxxxxxxx — 3 byte
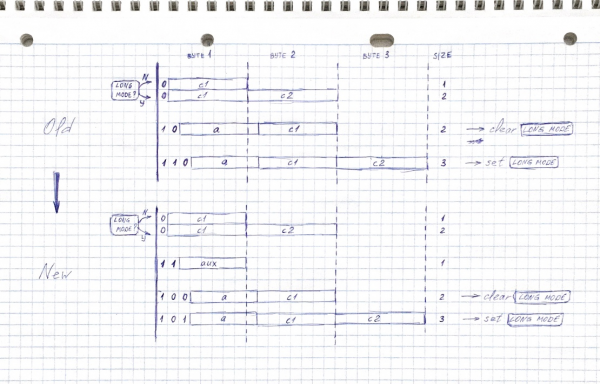
Tani, në regjistrimin me dy bajtë, kemi një bajt më të pakët të disponueshëm — kodohet deri te 0x1FFF, jo 0x3FFF. Megjithatë, është ende ndjeshëm më shumë se në kodet me dy bajtë të UTF-8, pjesa më e madhe e gjuhëve të zakonshme ende përfshihet, humbja më e dukshme — ra dhe , japonezët janë në trishtim.
Çfarë kod i ri 11xxxxxx? Это небольшой «загашник» размером в 64 символа, он дополняет наш основной алфавит, поэтому я назвал его вспомогательным (auxiliary) alfabeti. Kur ne kalojmë alfabetin aktual, një pjesë e vjetër e alfabetit bëhet ndihmës. Për shembull, kur kalojmë nga ASCII në cirilik — tani në "dajnik" kemi 64 simbole që përmbajnë latinisht, numra, hapësira dhe presje (inserton më të zakonshme në tekstet jo-ASCII). Kur kthehemi përsëri në ASCII — ndihmës do të bëhet pjesa kryesore e cirilikut.
Falë aksesit në dy alfabete, ne mund të përballojmë shumë tekste, duke pasur shpenzime minimale për kalimin e alfabeteve (pikërisht forma e shpesh do të çojë në kthimin në ASCII, por pas kësaj shumë simbole jo-ASCII do të nxirren nga alfabeti shtesë, pa nevojën për kalim të përsëritur).
Bonus: duke e shënuar alfabetin ndihmës me një prefiks 11xxxxxx dhe duke zgjedhur offset-in e tij fillestar të barabartë me 0xC0, ne marrim pajtim të pjesshëm me CP1252. Me fjalë të tjera, shumë (por jo të gjitha) tekste evropianë perëndimorë, të koduara në CP1252, do të duken ashtu si edhe në UTF-C.
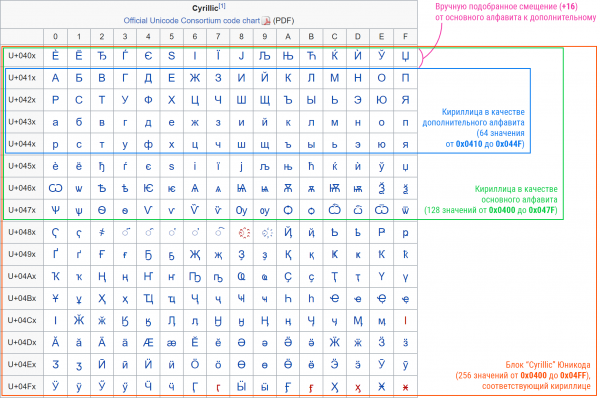
Këtu, megjithatë, shfaqet një vështirësi: si të merrni alfabetin ndihmës nga ai kryesor? Mund të lëmë të njëjtin zhvendosje, por — fatkeqësisht — struktura e Unicode tani punon kundër nesh. Shumë shpesh, pjesa kryesore e alfabetit nuk ndodhet në fillim të bllokut (për shembull, shkronja e madhe ruse «А» ka kod 0x0410, megjithatë blloku kyriliks fillon me 0x0400). Kështu, duke marrë në «dokument» 64 simbolat e para, ndoshta do të humbasim aksesin në pjesën e bishtit të alfabetit.
Për të zgjidhur këtë problem, kalova dorazi disa blloqe që përputhen me gjuhë të ndryshme, dhe tregova për to zhvendosjen e alfabetit ndihmës brenda atij kryesor. Latinishten, përjashtim, e riordnon si një base64.
Detajet përfundimtare
Le të mendojmë për fund se ku mund të përmirësojmë diçka tjetër.
Vërejmë se formati 101xxxxx xxxxxxxx xxxxxxxx lejon kodimin e numrave deri në 0x1FFFFF, ndërsa Unicode përfundon më herët, në 0x10FFFF. Me fjalë të tjera, pika e fundit e kodit do të përfaqësohet si 10110000 11111111 11111111. Pra, mund të themi se nëse byte-i i parë ka pamjen 1011xxxx (ku xxxx nëse është më shumë se 0), atëherë ai përfaqëson diçka tjetër. Për shembull, mund të shtojmë edhe 15 simbole, që janë vazhdimisht të disponueshme për kodim me një byte, por unë vendosa të veproj ndryshe.
Le të shohim ato blloqe të Unicode që kërkojnë tani tre byte. Kryesisht, siç u tha më parë, këto janë hieroglifet kineze — por me to është e vështirë të bësh diçka, ka 21 mijë. Por gjithashtu, aty fluturoi hiragana dhe katakana — dhe ato nuk janë aq shumë, më pak se dyqind. Dhe, duke qenë se përmendëm japonezët — aty ndodhen edhe emoji (në të vërtetë ata janë shpërndarë shumë kudo në Unicode, por blloqet kryesore janë në gamën 0x1F300 – 0x1FBFF). Nëse mendojmë për atë që tani ekzistojnë emoji që ndërtohen nga disa pika kodimi (për shembull, emoji përdor 7 kode!), është vërtet e trishtueshme të shpenzojmë për çdo një nga tre byte (7×3 = 21 byte për një simbol, është një makth).
Prandaj zgjedhim disa gamë të përzgjedhura, përkatëse për emoji, hiragana dhe katakana, i radhisim ato në një listë të vazhdueshme dhe i kodifikojmë në formë të dy byte në vend të tre:
1011xxxx xxxxxxxx
Shkëlqyeshëm: emoji i përmendur më parë , i cili përbëhet nga 7 pika kodimi, në UTF-8 zë 25 byte, ndërsa ne e përfshimë atë në 14 (pikërisht dy byte për çdo pikë kodi). Përveç kësaj, Habr refuzoi ta përballonte (si në redaktorin e vjetër ashtu edhe në atë të ri), kështu që u detyruam ta vendosim si imazh.
Do të përpiqemi të rregullojmë një problem tjetër. Siç e dimë, alfabeti kryesor është në thelb 6 bitët e lartë, të cilat i mbajmë mend, dhe i ngjisim me kodin e çdo simbole të dekoduara radhazi. Në rastin e karaktereve kineze, të cilat gjenden në bllokun 0x4E00 – 0x9FFF, janë ose bit 0, ose 1. Kjo nuk është shumë e rehatshme: do të na duhet vazhdimisht të kalojmë alfabetin midis këtyre dy vlerave (dmth. të shpenzojmë tre byte). Por le të vërejmë se në modin e gjatë nga vetë kodi mund të zbresim numrin e simboleve që kodojmë me modin e shkurtër (pas të gjitha trukeve të përshkruara më sipër, kjo është 10240) — atëherë diapazoni i karaktereve do të zhvendoset në 0x2600 – 0x77FF, dhe në këtë rast në të gjithë këtë diapazon 6 bitët e lartë (nga 21) do të jenë të barabarta me 0. Kështu, sekuencat e karaktereve do të përdorin dy byte për karakter (çfarë është optimal për një diapazon kaq të madh), pa shkaktuar kalime të alfabetit.
Zgjidhje alternative: SCSU, BOCU-1
Ekspertët e Unicode, vetëm duke lexuar titullin e artikullit, për siguri do të nxitojnë të kujtojnë se direkt në mesin e standarteve të Unicode ka (SCSU), i cili përshkruan një mënyrë kodimi, për të cilin është shumë e ngjashme me atë të përshkruar në artikull.
E pranoj sinqerisht: për ekzistencën e tij kam mësuar vetëm pasi u angazhova thellësisht në shkrimin e zgjidhjes së vet. Sikur ta kisha ditur që në fillim, ndoshta do të kisha provuar të shkruaja implementimin e tij në vend të shpikjes së një qasjeje të re.
E çuditshme, SCSU përdor ide që janë shumë të ngjashme me ato në të cilat kam arritur vetë (në vend të konceptit të "alfave" aty përdoren "dritaret", dhe ka më shumë se sa kam unë). Ndërkohë, ky format ka gjithashtu disavantazhe: është pak më afër algoritmeve të kompresimit, sesa kodimit. Sidomos, standardi ofron shumë mënyra për përfaqësim, por nuk thotë se si të zgjedhësh nga to optimalin — për këtë, encoder-i duhet të aplikojë disa heuristika. Prandaj, encoder-i SCSU që jep një paketim të mirë, do të jetë më i komplikuar dhe më i ngarkuar se algoritmi im.
Për krahasim, kam transferuar një implementim relativisht të thjeshtë të SCSU në JavaScript — nga volumi i kodit, ai doli të ishte i ngjashëm me UTF-C tim, por në disa raste tregoi rezultate deri në disa për qind më keq (ndonjëherë mund të kalojë atë, por jo shumë). Për shembull, tekstet në hebraisht dhe greqisht UTF-C i kodova madje 60% më mirë se SCSU (ndoshta për shkak të alfabetit të tyre të kompakt).
Veçmas do të shtoj se përveç SCSU ekziston gjithashtu një mënyrë tjetër për përfaqësimin kompakt të Unicode — , por ai synon kompatibilitetin me MIME (çfarë nuk më nevojitej), dhe përdor një qasje pak më të ndryshme për kodimin. Efektivitetin e tij nuk e kam vlerësuar, por mendoj se nuk do të jetë më i lartë se SCSU.
Përmirësimet e mundshme
Algoritmi që kam paraqitur nuk është universale nga dizajni (në këtë, ndoshta, qëllimet e mia ndahen më fort nga ato të konsorciumit Unicode). E përmenda tashmë se ai është zhvilluar kryesisht për një detyrë (ruajtjen e një fjalori shumëgjuhësh në një pemë prefiksesh), dhe disa karakteristika të tij mund të mos përshtaten mirë për detyra të tjera. Por fakti që ai nuk është standard mund të jetë gjithashtu një avantazh — mund t'i adaptoni lehtësisht sipas nevojave tuaja.
Për shembull, është qartë se mund të hiqni gjendjen, duke e bërë kodimin stateless — thjesht mos e azhurnoni variablin off, auxOffs dhe is21Bit në encoder dhe decoder. në këtë rast, nuk do të jepet mundësia për të paketa efektivisht sekuenca simbolesh të një alfabeti, por do të ketë garanci që një simbol i njëjtë do të kodifikohet gjithmonë me të njëjtat byte, pavarësisht nga konteksti.
Për më tepër, mund ta rregulloni koduesin për një gjuhë të veçantë, duke ndryshuar gjendjen e paracaktuar — për shembull, duke u bazuar në tekstet ruse, të vendosni në fillim të encoder dhe decoder offs = 0x0400 dhe auxOffs = 0. Kjo ka kuptim veçanërisht në rastin e modit stateless. Në përgjithësi, kjo do të ishte e ngjashme me përdorimin e kodimit të vjetër të tetë bitëve, vetëm se nuk e humbet mundësinë për të futur simbole nga e gjithë Unicode sipas nevojës.
Një tjetër mangësi, e përmendur më parë - në tekstin voluminoz të koduar në UTF-C, nuk ka një mënyrë të shpejtë për të gjetur kufirin e simbolit më të afërt me një byte të rastësishëm. Duke prerë nga bufferi i koduar, le të themi, 100 byte të fundit, rrezikoni të merrni plehra, të cilat nuk mund të bëni asgjë me to. Kodimi nuk është i përshtatur për ruajtjen e log-eve disa gigabajt, por përgjithësisht, kjo mund të korrigjohet. Byte 0xBF kurrë nuk duhet të ndodhë si byte i parë (por mund të jetë i dyti ose i tretë). Prandaj, gjatë kodimit, mund të futni një sekuencë 0xBF 0xBF 0xBF çdo 10 KB, le të themi - atëherë, nëse është e nevojshme, për të gjetur kufirin do të mjaftojë të skanoni copën e zgjedhur derisa të gjeni një marker të tillë. Pas të fundit 0xBF garantohet se do të jetë fillimi i simbolit. (Gjatë dekodimit, sigurisht që kjo sekuencë prej tre byteve do të injorohet.)
Në përfundim
Nëse keni lexuar deri këtu - urime! Shpresoj se, ashtu si unë, keni mësuar diçka të re (ose keni rifreskuar diçka të vjetër) rreth funksionit të Unicode.
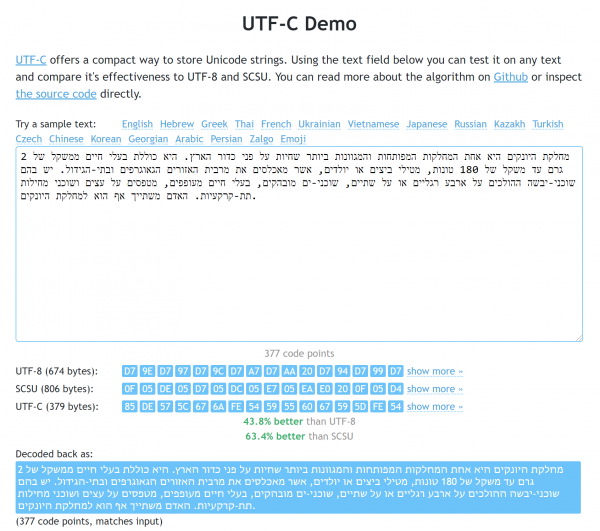
Faqja demonstruese. Në shembullin e hebraisht, shihen avantazhet si ndaj UTF-8, ashtu edhe ndaj SCSU.
Mos të shikoni hulumtimet e përmendura më sipër si një shqetësim për standardet. Megjithatë, në përgjithësi jam i kënaqur me rezultatet e punës sime, prandaj kam kënaqësi që i ndaj ato. : për shembull, biblioteka JS në formë të minimizuar peshon vetëm 1710 byte (pa varësi, sigurisht). Siç e përmenda më sipër, mund të njiheni me funksionimin e saj në (aty ka edhe një set tekstit me të cilin mund ta krahasoni me UTF-8 dhe SCSU).
Në fund, do të theksoj përsëri rastet e përdorimit të UTF-C. nuk duhet:
- Nëse rreshtat tuaj janë mjaft të gjatë (nga 100-200 karaktere). Në atë rast, ia vlen të mendoni për përdorimin e algoritmeve të kompresimit si deflate.
- Nëse ju nevojitet transparenca ASCII, domethënë ju është e rëndësishme që në sekuencat e koduara të mos shfaqen kode ASCII, të cilat nuk ishin në rreshtin origjinal. Nevojat për këtë mund të shmangen nëse gjatë interaksionit me API të tjera (për shembull, duke punuar me DB) e dërgoni rezultatin e kodimit si një koleksion abstrakt byte, jo si rreshta. Në të kundërt, rrezikoni të merrni dobësi të papritura.
- Nëse dëshironi të jeni në gjendje të gjeni shpejt kufijtë e karaktereve në një offset të caktuar (për shembull, gjatë dëmtimit të pjesës së një stringu). Kjo mund të bëhet, por vetëm duke skanuar stringun nga fillimi (ose duke zbatuar përmirësimin e përshkruar në seksionin e mëparshëm).
- Nëse ju nevojiten operacione të shpejta mbi përmbajtjen e stringjeve (të renditni ato, të kërkoni nënstringje, të konkatoni). Për këtë, stringjet duhet të dekodohen fillimisht, kështu që UTF-C do të jetë më i ngadalshëm se UTF-8 në këto raste (por më i shpejtë se algoritmet e kompresimit). Duke qenë se i njëjti string kodifikohet gjithmonë në të njëjtën mënyrë, krahasimi i saktë i dekodimit nuk kërkohet, ai mund të bëhet byte për byte.
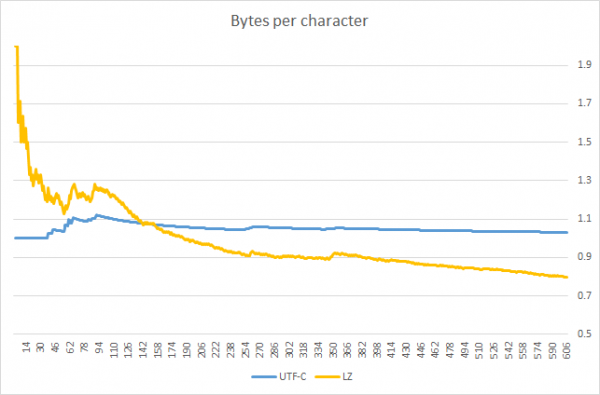
Përditësim: përdorues ka publikuar një grafik që thekson kufirin e aplikueshmërisë së UTF-C. Në të shikohet se UTF-C është më efektiv se algoritmi i kompresimit me qëllim të përgjithshëm (variacionet LZW) deri sa stringu i paketuar është më i shkurtër ~140 karaktere (në fakt, do të theksoja se krahasimi u bë mbi një tekst të vetëm; për gjuhë të tjera rezultati mund të ndryshojë).
Burimi: habr.com
