


Përshëndetje, lexues të Habrës. Me këtë artikull hapim një cikël që do të flasë për sistemin hiper-konvergjent AERODISK vAIR të zhvilluar nga ne. Fillimisht donim që me artikullin e parë të flisnim gjithçka rreth gjithçkaje, por sistemi është mjaft kompleks, kështu që do ta hamë elefantin për copa.
Le të fillojmë historinë me krijimin e sistemit, të thellohemi në sistemin e skedarëve ARDFS, i cili është baza e vAIR, dhe gjithashtu të diskutojmë pak mbi pozicionimin e këtij zgjidhjeje në tregun rus.
Në artikujt e mëvonshëm do të flasim më hollësisht për komponentët e ndryshëm arkitekturorë (klaster, hiperparalelizues, balancues ngarkese, sistem monitorimi etj.), procesin e konfigurimit, do të ngremë pyetje mbi licencimin, do të tregojmë ndarjen e testeve të dështimit dhe, natyrisht, do të shkruajmë për testimin e ngarkesës dhe dimensionimin. Po ashtu, do t’i dedikojmë një artikull veçmas versionit komunitar të vAIR.
A është AERODISK një lloj historie rreth sistemeve të ruajtjes? Apo pse kemi filluar të merremi me hiper-konvergjencën?
Fillimi i ideës për të krijuar një hiper-konsolidim na erdhi diku rreth vitit 2010. Atëherë nuk kishte as Aerodisk dhe as zgjidhje të ngjashme (sisteme komerciale hiper-konsolidimi) në treg. Detyra jonë ishte si vijon: nga një grup serverash me disqe lokale, të bashkuar me interkonnektin përmes protokollit Ethernet, duhej të krijonim një depot të shtrirë dhe të nisnim aty makinat virtuale dhe rrjetin e programit. Këto kërkesa duhej të realizoheshin pa SAN (sepse nuk kishte para për SAN dhe lidhjet e saja, dhe ne ende nuk e kishim shpikur SAN-në tonë).
Provova shumë zgjidhje open source dhe megjithatë e zgjidhëm këtë detyrë, por zgjidhja ishte shumë e ndërlikuar dhe e vështirë për t'u përsëritur. Për më tepër, kjo zgjidhje ishte një nga ato 'Punon? Mos e prek!'. Prandaj, pasi e zgjidhëm këtë detyrë, nuk vazhduam më me idenë për ta kthyer rezultatin e punës sonë në një produkt të plotë.
Pas atij rasti, ne u tërhoqëm nga kjo ide, por ndiheshim akoma se kjo detyrë ishte në të vërtetë e zgjidhshme dhe përfitimi nga një zgjidhje e tillë ishte më shumë se i dukshëm. Më pas, produktet HCI të kompanive ndërkombëtare e konfirmuan këtë ndjenjë.
Prandaj, në mes të vitit 2016, u rikthyem në këtë projekt si pjesë e krijimit të një produkti të plotë. Atëherë nuk kishim marrëdhënie me investitorët, kështu që na duhej të blinim stendën e zhvillimit me paratë tona të pakta. Duke renditur serverë dhe switch-e të përdorura në Avito, e nisa punën.

Detyra kryesore fillestare ishte krijimi i një sistemi të skedave, ndonëse të thjeshtë, por të vetin, që do të ishte në gjendje të shpërndante automatikisht dhe në mënyrë uniforme të dhënat në formën e blloqeve virtualë në një numër n-nodesh të klasterit, të cilat janë të lidhura me interkoneksionin përmes Ethernet-it. Po ashtu, Sistemi i Skedave duhet të ishte i shkallëzuar mirë dhe lehtësisht, dhe të ishte i pavarur nga sistemet përkatëse, pra të ishte i ndarë nga vAIR si 'thjesht një depo'.
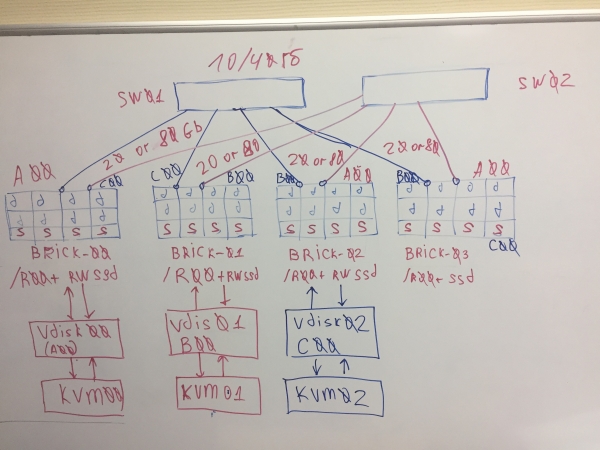
Koncepsioni i parë i vAIR

Ne vendosëm që të heqim dorë nga përdorimi i zgjidhjeve open source të gatshme për organizimin e një ruajtjeje të shpërndara (si ceph, gluster, lustre dhe të ngjashme) në favor të zhvillimit tonë, pasi kishim përvojë të konsiderueshme me to. Pa dyshim, këto zgjidhje vetë janë fantastike, dhe para punës mbi Aerodisk, kemi realizuar disa projekte integruese me to. Por është një gjë të realizosh një detyrë specifike për një klient, të trajnojosh staf dhe ndoshta të blesh mbështetje nga një ofrues i madh, dhe është një gjë krejt tjetër të krijosh një produkt të lehtë për t'u shpërndarë që do të përdoret për detyra të ndryshme, për të cilat si ofrues ndoshta as vetë nuk do të dimë. Për këtë qëllim të dytë, produktet ekzistuese open source nuk ishin të përshtatshme për ne, prandaj vendosëm ta zhvillojmë sistemin e skedarëve të shpërndarë vetë.
Pas dy vitesh, përmes disa zhvilluesve (të cilët kombinonin punën mbi vAIR me punën mbi sistemin klasik të ruajtjes Engine) arritëm një rezultat të caktuar.
Deri në vitin 2018, ne krijuam një sistem të thjeshtë skedarësh dhe e plotësuam atë me lidhjet e nevojshme. Sistemi bashkonte diskët fizikë (lokalë) nga serverë të ndryshëm në një rezervuar të sheshtë përmes interkonnektit të brendshëm dhe i ndante ata në blloqe virtuale, nga të cilat krijoheshin pajisje bllokues me një farë niveli të qëndrueshmërisë, në të cilat me ndihmën e hipervizorit KVM krijoheshin dhe ekzekutoheshin makinat virtuale.
Ne nuk u shqetësuam shumë për emrin e sistemit të skedarëve dhe e quajtëm thjesht ARDFS (merrni një guess se çfarë do të thotë))
Ky prototip duket i mirë (në sensin e performancës, jo në aspektin vizual, pasi ende nuk kishte paraqitje vizuale) dhe tregoi rezultate të mira në performancë dhe shkallëzim. Pas rezultatit të parë realist, ne e vazhduam këtë projekt, duke organizuar një mjedis të plotë zhvillimi dhe një ekip të veçantë që merrej vetëm me vAIR-in.
Ateherë, arkitektura e përgjithshme e zgjidhjes ishte pjekur, e cila ende nuk ka pësuar ndryshime të rëndësishme.
Të zhytim në sistemin e skedarëve ARDFS
ARDFS është themeli i vAIR, i cili siguron ruajtjen e shpërndarë dhe të qëndrueshme të të dhënave për të gjithë klasterin. Një nga (por jo e vetmja) veçori e dallueshme e ARDFS është se ai nuk përdor asnjë i serverëve të dedikuar nën menaxhim dhe kontroll. Kjo ishte menduar fillimisht për të thjeshtuar konfigurimin e zgjidhjes dhe për besueshmërinë e saj.
Struktura e ruajtjes
Në të gjitha nodet e klasterit, ARDFS organizon një rezervuar logjik nga të gjitha hapësirat e diskut të disponueshëm. Është e rëndësishme të kuptohet se rezervuari nuk janë ende të dhënat dhe as hapësira e formatizuar, por thjesht një shënim, pra çdo nod me vAIR të instaluar, kur shtohet në klaster, automatikisht shtohet në rezervuarin e përbashkët ARDFS dhe burimet e diskut automatizohen bëhen të përbashkëta për të gjithë klasterin (dhe të disponueshme për ruajtjen e të dhënave në të ardhmen). Ky qasje lejon që nodet të shtohen dhe hiqen në fluk të pa pasur ndonjë ndikim të rëndësishëm në sistemin që është duke funksionuar tashmë. Pra, sistemi është shumë i lehtë për t'u zgjeruar në mënyrë ”ndërtesash”, duke shtuar ose hequr nodet në klaster sipas nevojës.
Mbi grupin ARDFS shtohen disqet virtualë (objekte ruajtjeje për virtualizim), të cilat ndërtohen nga blloqe virtuale me madhësi 4 megabajt. Të dhënat ruhen drejtpërdrejt në disqet virtualë. Në nivelin e disqeve virtualë përcaktohet gjithashtu një skemë për qëndrueshmërinë ndaj dështimeve.
Siç mund të ishte kuptuar tashmë, për qëndrueshmërinë e nën-sistemit të disqeve ne nuk përdorim konceptin RAID (Grupi i disqeve të pavarur), por përdorim RAIN (Grupi i nënndeshkëve të pavarur). Këtu, qëndrueshmëria matet, automatizohet dhe menaxhohet duke u bazuar në nënndeshkë, jo në disqe. Disqet, pa dyshim, janë gjithashtu objekte ruajtjeje; ato, ashtu si gjithçka tjetër, monitorohen dhe mund të kryhen të gjitha operacionet standarde, përfshirë krijimin e një RAID lokal të harduerit, por klasteri menaxhon pikërisht nënndeshkë.
Në një situatë kur dëshira për RAID është shumë e madhe (p.sh., një skenar që mbështet dështime të shumta në klaster të vogla), asgjë nuk e pengon përdorimin e kontrolleve RAID lokale, ndërsa sipër mund të krijohet ruajtje e zgjatur dhe një arkitekturë RAIN. Ky skenar është plotësisht i vlefshëm dhe mbështetet nga ne, prandaj ne do ta diskutojmë atë në artikullin tonë mbi skenarët tipikë të përdorimit vAIR.
Skemat e qëndrueshmërisë së ruajtjes
Ka dy skema qëndrueshmërie për disqet virtuale në vAIR:
1) Faktor i replikimit ose thjesht replikimi – ky metod për qëndrueshmëri është i thjeshtë "si një shkop dhe një tel". Kryhet replikimi sinhron midis node-ve me faktor 2 (2 kopje në klaster) ose 3 (3 kopje, përkatësisht). RF-2 lejon diskun virtual të mbajë dështimin e një node në klaster, por "han" gjysmën e hapësirës së dobishme, ndërsa RF-3 mbijeton dështimin e 2-nodeve në klaster, por rezervon tashmë 2/3 të hapësirës së dobishme për nevojat e tij. Kjo skemë i ngjan shumë RAID-1, që do të thotë se disku virtual, i konfiguruar në RF-2, është i qëndrueshëm ndaj dështimit të çdo node në klaster. Në këtë rast, gjithçka do të jetë mirë me të dhënat dhe madje hyrja-dalja nuk do të ndalet. Kur node-ja e rëzuar të kthehet në punë, do të fillojë rikuperimi/sinhronizimi automatik i të dhënave.
Më poshtë janë shembuj të shpërndarjes së të dhënave RF-2 dhe RF-3 në modusin normal dhe në situata dështimi.
Kemi një makinë virtuale me kapacitet 8MB të dhënash unike (të dobishme), e cila funksionon në 4 nodet vAIR. Ndërsa në realitet është e vështirë të ketë një kapacitet kaq të vogël, për skemën që reflekton logjikën e funksionimit të ARDFS, ky shembull është më i kuptueshëm. AB përfaqëson blloqet virtuale prej 4MB, të cilat përmbajnë të dhënat unike të makinës virtuale. Me RF-2 krijohen dy kopje të këtyre blloqeve A1+A2 dhe B1+B2, përkatësisht. Këto blloqe shpërndahen në nodet, duke shmangur përputhjen e të njëjtave të dhëna në një nod, që do të thotë se kopja A1 nuk do të jetë në të njëjtin nod me kopjen A2. Me B1 dhe B2 është e ngjashme.
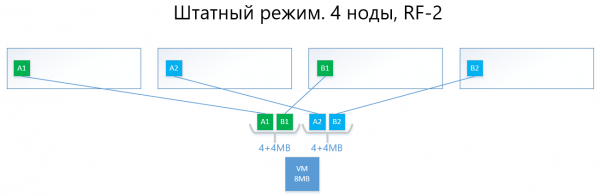
Në rastin e dështimit të njërit nga nodet (p.sh., nodi nr. 3, ku ndodhet kopja B1), kjo kopje aktivizohet automatikisht në nodin ku nuk ka kopjen e saj (pra kopjen B2).
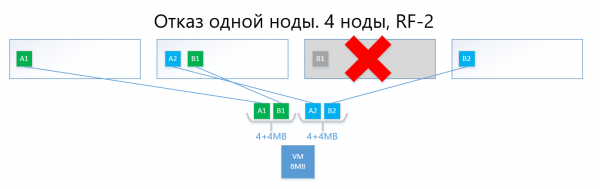
Kështu, disku virtual (dhe VM, përkatësisht) lehtë do të përballojnë dështimin e një nodi në skemën RF-2.
Skema me replikim, përkundër thjeshtësisë dhe besueshmërisë së saj, ka të njëjtin defekt si RAID1 – hapësira e dobishme është e vogël.
2) Kodimi i fshirjes ose kodimi eliminues (i njohur gjithashtu si "kodimi i tepricës") ka si qëllim zgjidhjen e problemit të përmendur më sipër. EC është një skemë tepricës që siguron një disponibilitet të lartë të dhënash me shpenzime më të ulëta në kapacitetin e diskut krahasuar me replikimin. Princi i funksionimit të këtij mekanizmi është i ngjashëm me RAID 5, 6, 6P.
Gjatë kodimit, procesi EC ndan një bllok virtual (në mënyrë default 4MB) në disa "copëza të dhënash" më të vogla në vartësi të skemës EC (për shembull, skema 2+1 e ndan çdo bllok 4 MB në 2 copëza prej 2MB). Më pas, ky proces gjeneron për "copëzat e dhënash" "copëza pariteti" që nuk kalojnë madhësinë e një prej pjesëve të ndara më parë. Gjatë dekodimit, EC gjeneron copëzat e munguar duke lexuar të dhënat "e mbijetuara" në të gjithë klasterin.
Për shembull, një diskut virtual me skemën EC 2 + 1, i realizuar në 4 node të klasterit, mund të përballojë një dështim të një node në klaster ashtu si RF-2. Në këtë mënyrë, shpenzimet e operimit do të jenë më të ulëta, konkretisht, koeficienti i dobishëm i kapacitetit kur RF-2 është 2, ndërsa me EC 2+1 do të jetë 1,5.
Për ta përshkruar thjesht, thelbi qëndron në atë se blloku virtual ndahet në 2-8 (pse nga 2 deri në 8, shih më poshtë) "copëza", dhe për këto copëza llogariten "copëza" pariteti me të njëjtin vëllim.
Në përfundim, të dhënat dhe pariteti shpërndahen njëtrajtësisht në të gjitha nodet e klasterit. Për më tepër, ashtu si në replikim, ARDFS në mënyrë automatike shpërndan të dhënat në nodet në një mënyrë që nuk lejon ruajtjen e të dhënave identike (kopjeve të të dhënave dhe paritetit të tyre) në një nodë, për të eliminuar mundësinë e humbjes së të dhënave në rast se të dhënat dhe pariteti i tyre papritur ndodhen në një nodë ruajtjeje që del jashtë funksionit.
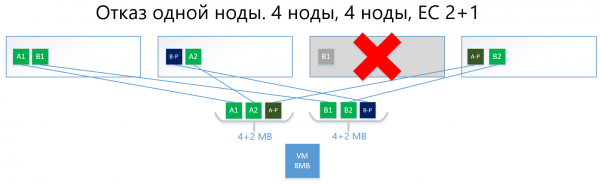
Më poshtë është një shembull, me të njëjtën virtualkë prej 8 MB dhe 4 nodet, por tashmë me skemën EC 2+1.
Blloqet A dhe B ndahen në dy pjesë secila prej 2 MB (në dy sepse 2+1), do të thotë se në A1+A2 dhe B1+B2. Ndryshe nga replika, A1 nuk është një kopje e A2, është një bllok virtual A, i ndarë në dy pjesë, ashtu si edhe blloku B. Kështu, kemi dy grupe prej 4 MB, në secilën prej të cilave janë dy pjesë prej dy megabajtësh. Më pas, për secilën nga këto grupe llogaritet pariteti me një volum jo më shumë se një pjesë (dmth. 2 MB), duke fituar gjithashtu + 2 pjesë pariteti (A-P dhe B-P). Pra, kemi 4×2 të dhëna + 2×2 paritet.
Më pas, pjesët "rregullohen" në nodet në mënyrë që të dhënat të mos kryqëzohen me paritetin e tyre. Pra, A1 dhe A2 nuk do të qëndrojnë në të njëjtën nodë me A-P.
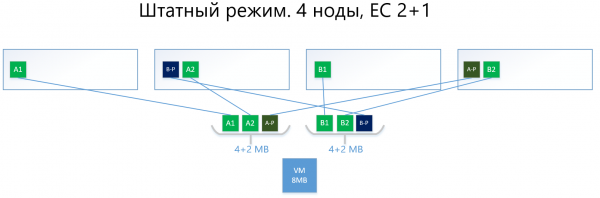
Në rast se dështojnë një nodet (le të supozojmë, po ashtu, edhe e treta) blloku i rënë B1 do të rikthehet automatikisht nga pariteti B-P, i cili ruhet në nodën nr. 2, dhe do të aktivizohet në nodën ku nuk ka B-paritet, dmth. pjesës B-P. Në këtë shembull – është nodë nr. 1.
Jam i sigurt se lexuesit kanë pyetje:
"Çdo gjë që keni përshkruar, është realizuar për një kohë të gjatë nga konkurentët, dhe në zgjidhjet open source, në çfarë ndryshimi është implementimi juaj EC në ARDFS?"
Më pas do të vijnë karakteristika interesante të funksionimit të ARDFS.
Kodimi i humbjes me fokus në fleksibilitet
Fillimisht, ne parashikuam një skemë mjaft të përshtatshme EC X+Y, ku X është një numër nga 2 deri në 8, dhe Y është një numër nga 1 në 8, por gjithmonë më i vogël ose i barabartë me X. Kjo skemë është e parashikuar për fleksibilitet. Rritja e numrit të copave të të dhënave (X), në të cilat ndahen blloket virtuale, lejon uljen e kostove të mbatjes, pra rritjen e hapësirës së dobishme.
Rritja e numrit të copave të paritetit (Y) rrit qëndrueshmërinë e disku virtual. Sa më i madh të jetë vlera e Y, aq më shumë nod të klasit mund të dalin jashtë funksionimit. Natyrisht, rritja e volumit të paritetit ulet kapacitetin e dobishëm, por kjo është një kosto për qëndrueshmëri.
Varësia e performancës nga skemat EC është pothuajse e drejtpërdrejtë: sa më shumë "copëza", aq më ulët është performanca, këtu, siç e kuptoni, është e nevojshme një qasje e balancuar.
Ky qasje lejon administratorët të konfigurojnë maksimalisht fleksibël magazinën e shtrirë. Brenda grumbullit ARDFS, mund të përdoren çdo skemë qëndrueshmërie dhe kombinimin e tyre, që gjithashtu, sipas mendimit tonë, është shumë e dobishme.
Më poshtë është një tabelë krahasuese e disa (jo të gjitha) skemave RF dhe EC.
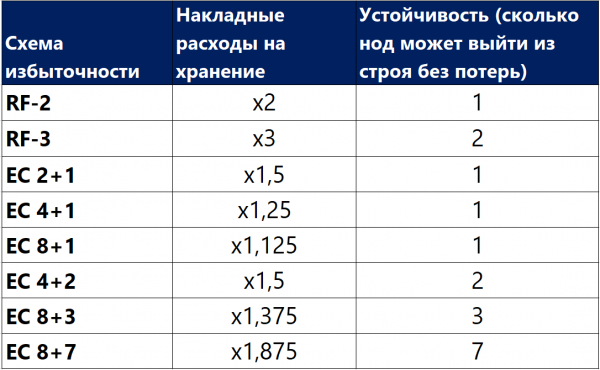
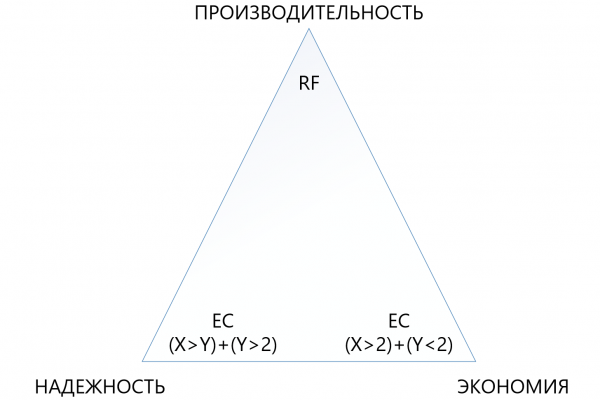
Nga tabela duket se edhe kombinimi më "i veçantë" EC 8+7, i cili lejon humbjen e deri në 7 nodëve njëkohësisht në klaster, "humb" hapësirë të dobishme më pak (1,875 përballë 2), se sa replikimi standard, dhe mbron 7 herë më mirë, çka e bën këtë mekanizëm mbrojtjeje, ndonëse më të ndërlikuar, shumë më tërheqës në situata kur nevojitet maksimalizimi i besueshmërisë në kushte të mungesës së hapësirës së diskut. Në të njëjtën kohë, është e rëndësishme të kuptohet se çdo "plus" në X ose Y do të sjellë një shpenzim shtesë në performancë, prandaj në triangle ndërmjet besueshmërisë, kursimit dhe performancës, duhen bërë zgjedhje shumë të kujdesshme. Për këtë arsye, do t'i kushtojmë një artikull të veçantë sizing-ut të kodimit që sillet larg.
Besueshmëria dhe autonomia e sistemit të skedarëve
ARDFS запускаhet lokalisht në të gjitha nodet e klasterit dhe sinkronizon mjetet e veta përmes ndërfaqeve të dedikuara Ethernet. Një pikë e rëndësishme është se ARDFS sinkronizon vetë jo vetëm të dhënat, por edhe metadatat që lidhen me ruajtjen. Gjatë punës në ARDFS, ne paralelisht studiuam një sërë zgjidhjesh ekzistuese dhe zbuluam se shumë prej tyre e bëjnë sinkronizimin e metadatave të sistemit të skedarëve duke përdorur një DB të shpërndarë të jashtme, e cila ne gjithashtu e përdorim për sinkronizimin, por vetëm të konfigurimeve, e jo të metadatave të FS (për këtë dhe sisteme të tjera përkatëse në artikullin e ardhshëm).
Sinkronizimi i metadatave të FS përmes një DB të jashtme është sigurisht një zgjidhje funksionale, por atëherë konsistencën e të dhënave të ruajtura në ARDFS do ta varej nga DB e jashtme dhe nga sjellja e saj (e cila, të them të drejtën — është një zonjë kapricioze), që në mendimin tonë është e keqe. Pse? Nëse metadat e FS dëmtohen, të dhënat e vetë FS gjithashtu mund të thonë «lamtumirë», prandaj ne vendosëm të ndiqnim një rrugë më të komplikuar, por më të besueshme.
Ne kemi zhvilluar nga vetë sistemin e sinkronizimit të të dhënave për ARDFS, dhe ai funksionon plotësisht në mënyrë të pavarur nga sistemet e tjera të ngjashme. Kjo do të thotë se asnjë sistem tjetër nuk mund ta dëmtojë të dhënat e ARDFS. Në mendimin tonë, ky është rruga më e sigurt dhe e duhur, por koha do të tregojë nëse është vërtet kështu. Përveç kësaj, ky qasje sjell një avantazh të shtuar. ARDFS mund të përdoret pavarësisht nga vAIR, thjesht si një depo e zgjeruar, dhe ne do të sigurohemi ta shfrytëzojmë ndjeshëm në produktet tona të ardhshme.
Në fund, duke krijuar ARDFS, ne fituam një sistem fleksibël dhe të besueshëm dosjesh, që ofron mundësinë për të kursyer hapësirë apo për të investuar të gjithë në performancë, ose për ta bërë depozita jashtëzakonisht të besueshme për një çmim të arsyeshëm, duke ulur kërkesat për performancë.
Së bashku me një politikë të thjeshtë licencimi dhe një model fleksibël të shpërndarjes (për të ardhmen, vAIR licencohet sipas node-ve dhe ofrohet si softuer ose si PAK), kjo lejon një përshtatje shumë të saktë të zgjidhjes sipas kërkesave të ndryshme të klientëve dhe më pas mbështetje të lehtë të këtij balansimi.
Kush ka nevojë për këtë mrekulli?
Nga njëra anë, mund të thuhet se në treg tashmë ka lojtarë me zgjidhje serioze në fushën e hiper-konvergjencës, dhe ku në të vërtetë po hyjmë. Duket se kjo deklaratë është e saktë, POR...
Nga ana tjetër, duke dalë "në terren" dhe duke biseduar me klientët, ne dhe partnerët tanë shohim se kjo nuk është aspak e vërtetë. Ka shumë detyra për hiper-konvergjencën, disa njerëz thjesht nuk e dinin se këto zgjidhje ekzistonin, disa mendonin se ishin të shtrenjta, disa kishin teste të dështuara me zgjidhje alternative, dhe disa madje ndalojnë blerjen për shkak të sanksioneve. Në përgjithësi, fusha u tregua e papërpunuar, prandaj shkuam për ta përmirësuar))).
Kur është ruja më e mirë se GKS?
Gjatë punës me tregun, shpesh na pyesin se kur është më mirë të aplikosh skemën klasike me ruja, dhe kur - hiper-konvergjencën? Shumë kompani - prodhues të GKS (sidomos ato që nuk kanë ruja në portofol) thonë: "Ruja po e humb rëndësinë, vetëm hiper-konvergjencë!". Kjo është një deklaratë guximtare, por nuk e pasqyron plotësisht realitetin.
Të them të vërtetën, tregu i ruja vërtet po kalon në drejtim të hiper-konvergjencës dhe zgjidhjeve të ngjashme, por gjithmonë ka një "por".
Së pari, qendrat e të dhënave dhe infrastrukturat IT të ndërtuara sipas një skeme klasike me sistemin e ruajtjes (SХД) nuk mund të riparohen kaq lehtë, prandaj modernizimi dhe zgjerimi i këtyre infrastrukturave është një trashëgimi e 5-7 viteve të fundit.
Së dyti, ato infrastrukturat që po ndërtohen aktualisht masivisht (në Rusi) ndërtohen sipas një skeme klasike për përdorimin e SХД, dhe nuk është se njerëzit nuk e dinë për hiper-konvergencën, por sepse tregu i hiper-konvergencës është i ri, zgjidhjet dhe standardet ende nuk janë stabilizuar, specialistët IT ende nuk janë të trajnuar, përvoja është e pakët, dhe qendrat e të dhënave duhet ndërtuar këtu dhe tani. Dhe kjo tendencë do të vazhdojë për 3-5 vite (pastaj edhe një trashëgimi, shih pikën 1).
Së treti, ka një kufizim teknik vetëm për disa vonesa të vogla prej 2 milisekondash gjatë regjistrimit (pa marrë parasysh cache-in lokal, sigurisht) që janë çmimi për ruajtjen e shpërndarë.
Dhe mos harrojmë përdorimin e serverëve fizikë të mëdhenj, të cilët preferojnë shkallëzimin vertical të sistemit të ruajtjes.
Ka shumë detyra të nevojshme dhe të njohura, ku storage back-end performon më mirë se hyper-converged. Sigurisht, prodhues që nuk kanë storage back-end në portofolin e produkteve të tyre nuk do të bien dakord me ne, por jemi të gatshëm të argumentojmë. Natyrisht, si zhvillues të të dy produkteve, në një nga publikimet e ardhshme do të bëjmë një krahasim midis storage back-end dhe hyper-converged, ku do të demonstrojmë qartë se në cilat kushte është më mirë.
Ku do të punojnë më mirë zgjidhjet hyper-converged se storage back-end?
Duke marrë parasysh pikat e mësipërme, mund të dalim në tri përfundime të qarta:
- Aty ku dy millisekonda vonesë në shkrim, që ndodhin në çdo produktivitet (në këtë moment nuk flasim për sintetik, një ditë sintetik mund të tregojnë edhe nanosekonda), janë të pranuara, hyper-converged do të përshtatet.
- Aty ku ngarkesa nga serverat fizikë të mëdhenj mund të shndërrohet në shumë të vogla virtual dhe të shpërndahen në node, aty hyper-converged gjithashtu do të funksionojë mirë.
- Aty ku shkallëzimi horizontal është më i rëndësishëm se ai vertikal, gjithashtu hyper-converged do të realizohet mrekullisht.
Cilat janë këto zgjidhje?
- Të gjithë shërbimet standarde të infrastrukturës (shërbimi i katalogëve, posta, SED, serverët e skedarëve, sistemet e vogla ose të mesme ERP dhe BI etj.). Ne i quajmë këto "llogaritje të zakonshme".
- Infrastruktura e ofruesve të cloud, ku është e nevojshme të zgjeroheni horizontalisht shpejt dhe standardizuar dhe të krijoni lehtësisht një numër të madh makinash virtuale për klientët.
- Infrastruktura tavolina virtuale (VDI), ku shumë virtuale të vogla të përdoruesve nisen dhe lundrojnë qetësisht brenda një klasteri të njëtrajtshëm.
- Rrjetet filiale, ku në çdo filial është e nevojshme të sigurohet një infrastrukturë standarde, me qëndrim të qëndrueshëm, por gjithashtu me kosto të ulët nga 15-20 makina virtuale.
- Çdo llogaritje të shpërndarë (shërbimet big data, për shembull). Atje ku ngarkesa nuk shkon "thellë", por "gjerë".
- Mjediset testuese, ku lejohet vonesa e vogël shtesë, por ka kufizime buxhetore, sepse janë teste.
Në këtë moment, për këto detyra ne kemi krijuar AERODISK vAIR dhe pikërisht mbi to po bëjmë përpjekje (deri tani me sukses). Mundësisht, kjo do të ndryshojë shpejt, pasi bota nuk qëndron në vend.
Dhe kështu…
Këtu përfundon pjesa e parë e një cikli të madh artikujsh; në artikullin e ardhshëm do të flasim për arkitekturën e zgjidhjes dhe komponentët e përdorur.
Do të jemi të lumtur për pyetje, propozime dhe debate konstruktive.
Burimi: habr.com
