

Ju ftoj të njihemi me përmbledhjen e raportit të fundit të vitit 2019 nga Aleksandër Valjalkin "Optimizimet Go në VictoriaMetrics"
— një DBMS e shpejtë dhe e shkallëzueshme për ruajtjen dhe përpunimin e të dhënave në formën e seri temporale (një rekord formon kohën dhe një grup vlerash përkatëse, për shembull, të marra përmes sondazhit periodic të gjendjes së sensorëve ose mbledhjes së metrikeve).

Ja një lidhje me videon e këtij raporti —

Do të flas pak për veten time. Unë jam Aleksandër Valjalkin. Ja . Më pëlqen Go dhe optimizimi i performancës. Kam shkruar shumë biblioteka të dobishme dhe ndonjëherë jo aq të dobishme. Ato fillojnë ose me fast, ose me quick prefiksin.
Aktualisht po punoj mbi VictoriaMetrics. Çfarë është kjo dhe çfarë po bëj atje? Për këtë do të flas në këtë prezantim.

Plani i raportit është si vijon:
- Fillimisht do t'ju tregoj se çfarë është VictoriaMetrics.
- Pastaj do të flas për seri temporale.
- Më pas do të tregoj si funksionon baza e të dhënave të seri temporale.
- Më tej do të flas për arkitekturën e bazës së të dhënave: çfarë përfshin ajo.
- Dhe pastaj do të kalojmë në optimizimet që ekzistojnë në VictoriaMetrics. Këto janë optimizimi i indeksit të invers dhe optimizimi për implementimin e bitset në Go.

Çfarë është VictoriaMetrics, a e di kush në audiencë? Ehh, shumë njerëz tashmë e dinë. Kjo është një lajm i mirë. Për ata që nuk e dinë – është një bazë të dhënash për seri kohore. Ajo bazohet në arkitekturën ClickHouse, duke përfshirë disa detaje të zbatimit të ClickHouse. Për shembull, disa nga ato janë: MergeTree, llogaritje paralele në të gjitha bërthamat e disponueshme të procesorit dhe optimizimi i performancës me punën mbi blloqet e të dhënave që vendosen në cache-in e procesorit.
VictoriaMetrics ofron kompresimin më të mirë të të dhënave krahasuar me bazat e tjera të të dhënave për seri kohore.
Ajo shkallëzohet në mënyrë vertikale — domethënë, mund të shtoni më shumë procesorë, më shumë memorie RAM në një kompjuter. VictoriaMetrics do të shfrytëzojë me sukses këto burime të disponueshme dhe do të rrisë performancën lineare.
Gjithashtu, VictoriaMetrics shkallëzohet horizontalisht — domethënë, mund të shtoni nën-produkte të tjera në klusterin VictoriaMetrics dhe performanca e saj do të rritet pothuajse linearisht.
Si e keni kuptuar, VictoriaMetrics është një bazë të dhënash e shpejtë, sepse nuk mund të flas për të tjerat. Po ashtu, është shkruar në Go, prandaj po flas për të në këtë mitap.

Kush e di se çfarë është një seri kohore? Shumë njerëz e dinë. Një seri kohore është një sërë çiftësh (timestamp, vlera), ku këto çifte janë të renditura sipas kohës. Vlera përfaqëson një numër me pikë të lëvizshme – float64.
Çdo seri kohore identifikohet në mënyrë unike nga një çelës. Çfarë përbën ky çelës? Ai përbëhet nga një grup i pandërprerë çiftësh çelës-vlerë.
Ja një shembull i një serie kohore. Çelësi i kësaj serie është një listë çiftësh: __name__="cpu_usage" – ky është emri i metrikës, instance="my-server" — ky është kompjuteri ku është mbledhur kjo metrikë, datacenter="us-east" — ky është qendra e të dhënave ku ndodhet ky kompjuter.
Kam marrë emrin e një serie kohore, e cila përbëhet nga tri çiftë çelës-vlerë. Ky çelës ka një listë çiftësh (timestamp, vlera). t1, t3, t3, ..., tN — këto janë timestamps, 10, 20, 12, ..., 15 — vlerat përkatëse. Kjo është përdorimi i CPU në këtë moment për këtë seri.

Ku mund të përdoren seritë kohore? Disa ide nga ndokush?
- Në DevOps mund të matni ngarkesën e CPU, RAM, rrjetit, rps, numrin e gabimeve etj.
- IoT – ne mund të masim temperaturën, presionin, koordinatat gjeografike, dhe ndonjë gjë tjetër.
- Po ashtu në financa – mund të monitorojmë çmimet e aksioneve dhe valutave të ndryshme.
- Për më tepër, seritë temporale mund të përdoren për monitorimin e proceseve prodhuese në fabrika. Kemi përdorues që përdorin VictoriaMetrics për monitorimin e turbina eolikë dhe robotëve.
- Gjithashtu, seritë temporale janë të dobishme për mbledhjen e informacionit nga sensorët e ndryshëm të pajisjeve. Për shembull, për motorin; për matjen e presionit në goma; për matjen e shpejtësisë, distancës; për matjen e konsumit të benzinës, etj.
- Gjithashtu, seritë temporale mund të përdoren për monitorimin e avionëve. Çdo avion ka një kutinë e zezë që mbledh seritë temporale sipas parametrave të ndryshëm të shëndetit të avionit. Serie temporale jepet gjithashtu në industrinë aviacione.
- Shëndetësia – janë presioni i gjakut, puls, etj.
Ndoshta ka edhe aplikime të tjera që kam harruar, por shpresoj që keni kuptuar se seritë temporale përdoren aktivisht në botën moderne. Dhe volumi i përdorimit të tyre po rritet çdo vit.

Për çfarë i nevojitet një bazë të dhënash për seritë e tyre? Pse nuk mund të përdoret një bazë e zakonshme relacionale për ruajtjen e serive të tyre?
Sepse në seritë e tyre zakonisht ka një volum të madh informacioni, që është e vështirë të ruhen dhe të procesohen në bazat e zakonshme të dhënash. Prandaj janë shfaqur BD të specializuara për seritë e dhënash. Këto baza ruajnë në mënyrë efektive pikat (timestamp, vlera) me një çelës të caktuar. Ato ofrojnë një API për të lexuar të dhënat e ruajtura sipas çelësit, me një çift çelës-vlerë, ose me disa të tilla, ose sipas regexp. Për shembull, nëse dëshironi të gjeni ngarkesën e procesorit të të gjithë shërbimeve tuaja në qendrën e të dhënave në Amerikë, duhet të përdorni një kërkesë të tillë.
Zakonisht bazat e dhënash për seritë e dhënash paraqesin gjuhë të specializuara kërkese, sepse SQL për seritë e dhënash nuk është shumë i përshtatshëm. Edhe pse ka baza të dhënash që mbështesin SQL, ai nuk është shumë i përshtatshëm. Më mirë i përshtaten gjuhët e kërkesave si , , , . Shpresoj që dikush të ketë dëgjuar për ndonjë prej këtyre gjuhëve. O PromQL, ndoshta, kanë dëgjuar shumë. Kjo është gjuhë kërkese e Prometheus.
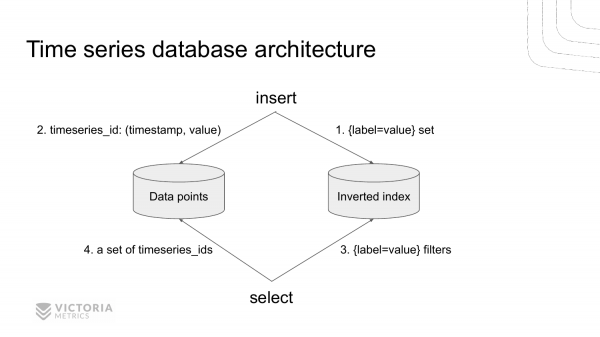
Ja si është ndërtimi i arkitekturës moderne të një baze të dhënash për seritë kohore në shembullin e VictoriaMetrics.
Ajo përbëhet nga dy pjesë. Kjo është një depo për indeksin e inverzuar dhe një depo për vlerat e serive kohore. Këto depove janë të ndara.
Kur një regjistrim i ri vjen në bazën e të dhënave, ne së pari referohemi në indeksin e inverzuar për të gjetur identifikuesin e serisë kohore sipas një grupi të caktuar label=value për këtë metrikë. E gjejmë këtë identifikues dhe ruajmë vlerën në depo.
Kur vjen ndonjë kërkesë për marrjen e të dhënave nga TSDB, ne në radhë të parë shkojmë në indeksin e inverzuar. Nxjerrim të gjitha timeseries_ids regjistrimet që korrespondojnë me këtë grup label=value. Dhe më pas e nxjerrim të gjitha të dhënat e nevojshme nga depon e të dhënave, e indeksuar sipas timeseries_ids.

Le të shqyrtojmë një shembull se si baza e të dhënave për seritë kohore trajton një kërkesë select të ardhshme.
- Së pari, ajo nxjerr të gjitha
timeseries_idsnga indeksi i inverzuar, të cilat përmbajnë çiftet e caktuaralabel=value, ose që i përgjigjen një shprehjeje rregullt të caktuar. - Më pas ajo nxjerr të gjitha pikat e të dhënave nga depoja e të dhënave në një interval të caktuar kohor për ato të gjetura.
timeseries_ids. - Pas kësaj, databaza kryen disa llogaritje mbi këto data points, sipas kërkesës së përdoruesit. Dhe pas kësaj, kthen një përgjigje.
Në këtë prezantim do t'ju tregoj për pjesën e parë. Kjo është kërkimi timeseries_ids në indeksin e invertuar. Për pjesën e dytë dhe të tretë mund të shikoni më vonë , ose të prisni deri sa të përgatis dokumente të tjera 🙂

Le t'ia fillojmë indeksit të invertuar. Disa mund të mendojnë se është e thjeshtë. Kush e di se çfarë është një indeks i invertuar dhe si funksionon? Oh, tashmë nuk ka shumë njerëz. Le t'ë përpiqemi të kuptojmë se çfarë është kjo.
Në të vërtetë, gjithçka është e thjeshtë. Ky është thjesht një fjalor që shfaq çelësin në vlerë. Çfarë është çelësi? Ky çift label=value, ku etiketë dhe vlera – janë strings. Dhe vlerat janë një grup timeseries_ids, i cili përfshin çiftin e caktuar label=value.
Indeksi i invertuar lejon të gjeni shpejt të gjitha timeseries_ids, të cilat kanë të caktuara label=value.
Po ashtu, ai lejon të gjeni shpejt timeseries_ids seritë e kohës për disa çifte label=value, ose për çifte label=regexp. Si ndodhi kjo? Përmes gjetjes së kryqëzimit të shumëllojshmërisë timeseries_ids për çdo çift label=value.

Le të shqyrtojmë realizime të ndryshme të indeksit të inkorporuar. Le të fillojmë me realizimin më të thjeshtë naiv. Ai duket kështu.
Funksioni getMetricIDs merr listën e rreshtave. Çdo rresht përmban label=value. Kjo funksion kthen një listë metricIDs.
Si funksionon kjo? Këtu kemi një variabël globale që quhet invertedIndex. Ky është një fjalor i zakonshëm (map), që shndërron rreshtin në një slice int-ësh. Rreshti përmban label=value.
Realizimi i funksionit: nxjerrim metricIDs për të parin label=value, pastaj kalojmë përmes gjithë të tjerëve label=value, nxjerrim metricIDs për ta. Dhe thërrasim funksionin intersectInts, për të cilin do të flitet më vonë. Dhe ky funksion kthen kryqëzimin e këtyre listave.

Siç e shihni, realizimi i indeksit të inkorporuar nuk është shumë i komplikuar. Por kjo është një realizim naiv. Çfarë të metash ka? Të metën kryesore të realizimit naiv është se ky indeks i inkorporuar ruhet në memorie. Pas ribllokimit të aplikacionit, ne e humbasim këtë indeks. Nuk ka ruajtje të këtij indeksi në disk. Për një bazë të dhënash, ky indeks i inkorporuar vështirë se do të përshtatet.
Këtu është një problem i dytë i lidhur me memorie. Indeksi i përmbysur duhet të ruhet në memorien operative. Nëse e kalon përmasën e memories operative, është e qartë se do të marrim një – gabim out of memory. Dhe programi nuk do të funksionojë.

Ky problem mund të zgjidhet me zgjidhje të gatshme siç janë , ose .
Në përmbledhje, na nevojitet një bazë të dhënash që lejon të bëjmë shpejt tre operacione.
- Operacioni i parë – është regjistrimi
çelës-vlerënë këtë bazë. Ajo e bën këtë shumë shpejt, kuçelës-vlerëjanë vargje të rastësishme. - Operacioni i dytë – është kërkimi i shpejtë i vlerës për një çelës të caktuar.
- Dhe operacioni i tretë – është kërkimi i shpejtë i të gjitha vlerave për një prefiks të caktuar.
LevelDB dhe RocksDB – këto baza janë zhvilluar në Google dhe Facebook. Fillimisht u shfaq LevelDB. Pjesa tjetër nga Facebook e mori LevelDB dhe filloi ta përmirësojë, duke krijuar RocksDB. Tani, në Facebook, pothuajse të gjitha bazat e të dhënave të brendshme punojnë me RocksDB, përfshirë MySQL që e kanë kaluar në RocksDB. Ata e quajtën .
Indeksi i përmbysur mund të realizohet me LevelDB. Si e bëjmë këtë? Ruajmë si çelës label=value. Dhe si vlerë – identifikuesin e serisë temporale, ku ndodhet çifti label=value.
Nëse kemi shumë seri temporale me këtë çift label=value, do të ketë shumë rreshta në këtë bazë të dhënash me të njëjtin çelës dhe të ndryshëm timeseries_ids. Për të marrë një listë të gjithë timeseries_ids, që fillojnë me këtë label=prefix, ne bëjmë një skanim të gamës, për të cilin është optimizuar kjo bazë e të dhënave. Domethënë, zgjedhim të gjithë rreshtat që fillojnë me label=prefix dhe marrim të nevojshmet timeseries_ids.

Ja implementimi i përafërt, si do të dukej në Go. Ne kemi një indeks të inversuar. Kjo është LevelDB.
Funksioni është i njëjtë, si për implementimin naive. Ajo pothuajse përsërit rresht në rresht implementimin naive. Vetëm momenti është, që në vend të aksesit te map ne i qasem indeksit të inversuar. Marrim të gjitha vlerat për të parën label=value. Pastaj kalojmë përmes të gjitha çiftëve të mbetur label=value dhe marrim grupet përkatëse të metricIDs për ta. Më pas gjejmë ndërprerjen.
Duket gjithçka mirë, por në këtë zgjidhje ka disavantazhe. VictoriaMetrics fillimisht implementoi indeksin e inversuar mbi bazën e LevelDB. Por në fund, iu desh të heqë dorë nga ai.
Pse? Sepse LevelDB është më i ngadalshëm se implementimi naive. Në implementimin naive, për çelësin e dhënë ne menjëherë marrim të gjithë slice-in metricIDs. Kjo është një operacion shumë i shpejtë — e gjithë slice është gati për përdorim.
Në LevelDB, gjatë çdo thirrjeje të funksionit GetValues duhet të kalosh përmes të gjitha rreshtave që fillojnë me label=value. Dhe për secilin rresht të nxjerrësh vlerën timeseries_ids. Nga të tillë timeseries_ids të grumbullosh një slice të këtyre timeseries_ids. është e qartë se kjo është shumë më e ngadalët se sa thjesht qasja në një map të zakonshëm sipas çelësit.
Mungesa e dytë është se LevelDB është shkruar në C. Qasja në funksionet C nga Go nuk është shumë e shpejtë. Kjo merr qindra nanosekonda. Kjo nuk është shumë e shpejtë, sepse në krahasim me një thirrje të zakonshme të funksionit të shkruar në Go, që zë 1-5 nanosekonda, diferenca në performancë është shumëfish më e madhe. Për VictoriaMetrics, ky ishte një disavantazh fatal 🙂

Prandaj, unë shkrova një implementim të vetin të indeksit të inversuar. Dhe e quajta .
Mergeset është e bazuar në strukturën e të dhënave MergeTree. Kjo strukturë të dhënash është marrë nga ClickHouse. E qartë është se mergeset duhet të jetë e optimizuar për kërkime të shpejta timeseries_ids për një çelës të caktuar. Mergeset është shkruar plotësisht në Go. Ju mund të shikoni . Implementimi i mergeset ndodhet në dosjen . Ju mund të provoni të kuptoni se çfarë ndodh atje.
API mergeset është shumë i ngjashëm me LevelDB dhe RocksDB. Kjo do të thotë se ai lejon ruajtjen e shpejtë të shënimeve të reja dhe shfrytëzimin e shpejtë të shënimeve sipas një prefiksi të caktuar.

Për disavantazhet e mergeset do të flasim më vonë. Tani do të diskutojmë për problemet që janë shfaqur me VictoriaMetrics në produksion gjatë implementimit të indeksit të invertuar.
Pse ndodhen ato?
Arsyeja e parë është shkalla e lartë e përmbysjes. Në përkthim në shqip – kjo do të thotë ndryshimi i shpeshtë i serive temporale. Kjo ndodh kur një seri temporale përfundon dhe fillon një tjetër, ose fillojnë shumë seria të reja. Dhe kjo ndodh shpesh.
Arsyeja e dytë është numri i madh i serive temporale. Në fillim, kur monitorimi po përhapej, numri i serive temporale ishte i vogël. Për shembull, për çdo kompjuter, duhet të monitoroni ngarkesën e procesorit, kujtesës, rrjetit dhe disqet. 4 seri temporale për çdo kompjuter. Keni, për shembull, 100 kompjuterë dhe 400 seria temporale. Kjo është shumë pak.
Me kohë, njerëzit shpikën mënyra për të matur informacion më të detajuar. Për shembull, të matësh ngarkesën jo të gjithë procesorit, por veç e veç të çdo bërthame procesori. Nëse keni 40 bërtha procesori, atëherë, sigurisht, keni 40 herë më shumë radhë të cilësuara për matjen e ngarkesës së procesorit.
Por kjo nuk është gjithçka. Çdo bërthamë procesori mund të ketë disa gjendje si idle, kur është në pritje. Gjithashtu, operimi në hapësirën e përdoruesit, operimi në hapësirën e bërthamës dhe gjendje të tjera. Dhe çdo gjendje e tillë gjithashtu mund të matet si një radhë e veçantë. Kjo shton për afro 7-8 herë numrin e radhëve.
Nga një metrikë, kemi marrë 40 x 8 = 320 metrika vetëm për një kompjuter. Po e shumëfishojmë me 100, dhe marrim 32,000 në vend të 400.
Më pas erdhi Kubernetes. Dhe ende nuk u përmirësua, sepse në Kubernetes mund të hostohen shumë shërbime të ndryshme. Çdo shërbim në Kubernetes përbëhet nga shumë podë. Të gjitha këto duhen monitoruar. Përveç kësaj, ne kemi një zhvillim të vazhdueshëm të versioneve të reja të shërbimeve tuaja. Për çdo version të ri, duhet të krijohen rreshta të rinj temporal. Si rezultat, numri i rreshtave temporal rritet në mënyrë eksponenciale dhe përballemi me problemin e një numri të madh rreshtash temporal, i njohur si high-cardinality. VictoriaMetrics e zgjidh këtë më me sukses krahasuar me bazat e tjera të të dhënave për rreshta temporal.

Le të shqyrtojmë më me hollësi high churn rate. Për çfarë arsye krijohet high churn rate në production? Sepse disa vlera etiketash dhe tagësh ndryshojnë vazhdimisht.
Për shembull, të marim Kubernetes, në të cilin ka një koncept deployment, dmth. kur lansohet një version i ri i aplikacionit tuaj. Zhvilluesit e Kubernetes vendosën të shtonin papritur id’shën e deployment’it në label.
Çfarë rezultoi nga kjo? Që në çdo deployment të ri, të gjitha rreshtat e vjetër temporal ndërpriten, dhe në vend të tyre nisin rreshta të rinj temporal me vlerë të re etike. deployment_id. Mund të ketë qindra mijëra dhe madje miliona të tilla.
Një karakteristikë e rëndësishme e gjithçkaje është se numri total i serive temporale po rritet, por numri i serive temporale që janë aktualisht aktive, për të cilat po vijnë të dhëna, mbetet konstant. Ky gjendje quhet – shkallë e lartë e ndryshueshmërisë.
Problemi kryesor i shkallës së lartë të ndryshueshmërisë është të sigurohet një shpejtësi e vazhdueshme e kërkimit për të gjitha seritë temporale sipas një grupi të caktuar etiketash për një interval të caktuar kohe. Zakonisht ky është një interval kohe për orën e fundit ose për ditën e fundit.
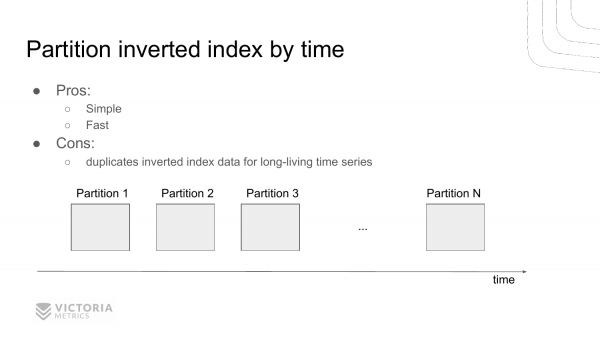
Si mund ta zgjidhim këtë problem? Kjo është një mundësi e parë. Të ndajmë indeksin e kthyer në pjesë të pavarura mbi bazë të kohës. Kjo do të thotë se kalon një interval kohe, përfundojmë punën me indeksin e kthyer aktual. Dhe krijojmë një indeks të ri të kthyer. Kalon një tjetër interval kohe, krijojmë një tjetër dhe një tjetër.
Dhe kur seleksionojmë nga këto indekse të kthyer, ne gjejmë një grup indekse të kthyer që bien brenda intervalit të caktuar. Dhe, për pasojë, përzgjedhim nga aty id-të e serive temporale.
Kjo lejon që të kursejmë burimet, sepse nuk na nevojitet të shqyrtojmë pjesë që nuk bien brenda intervalit të caktuar. Pra, zakonisht, nëse zgjedhim të dhënat për orën e fundit, ne i kalojmë kërkesat për intervalet e mëparshme të kohës.

Ka një mundësi tjetër për të zgjidhur këtë problem. Kjo është mbajtja e një liste të veçantë të identifikuesve të serive kohore për çdo ditë, të cilat janë hasur gjatë asaj dite.
Avantazhi i këtij zgjidhjeje në krahasim me zgjidhjen e mëparshme është se ne nuk e përsërisim informacionin mbi seritë kohore që nuk zhduken me kalimin e kohës. Ato janë vazhdimisht aty dhe nuk ndryshojnë.
Megjithatë, ky zgjidhje është më e komplikuar për t'u zbatuar dhe më sfiduese për tu debuguar. VictoriaMetrics ka zgjedhur këtë zgjidhje, e cila është formuar historikisht. Kjo zgjidhje gjithashtu tregon rezultate të mira krahasuar me të kaluarën. Për shkak se kjo zgjidhje nuk u implementua sepse duhej të dyfishoheshin të dhënat në çdo ndarje për seritë temporale që nuk ndryshojnë, pra që nuk zhduken me kalimin e kohës. VictoriaMetrics u optimizua kryesisht për konsumimin e hapësirës në disk, dhe implementimi i mëparshëm përkeqësoi konsumimin e saj. Kjo implementim tani është më i përshtatshëm për minimizimin e konsumit të hapësirës në disk, prandaj u zgjodh.
Kisha nevojë të përballesha me të. Lufta ishte se në këtë implementim duhet të zgjidhet një numër shumë më i madh timeseries_ids i të dhënave se sa kur indeksi i invertuar ndahet në kohë.

Si e zgjidhëm këtë problem? E zgjidhëm në një mënyrë origjinale - duke ruajtur disa identifikues të serive temporale në çdo regjistrim të indeksit të invertuar në vend të një identifikuesi. Pra, ne kemi një çelës label=value, i cila gjendet në çdo rresht temporal. Dhe tani ne ruajmë disa timeseries_ids në një regjistrim.
Këtu është një shembull. Më parë ne kishim N regjistrime, tani kemi një regjistrim, me prefiksin e njëjtë si të gjithë të tjerët. Një regjistrim të mëparshëm kishte një vlerë që përmban të gjithë id-et e rreshtave temporale.
Kjo ka lejuar të rritet shpejtësia e skanimit të këtij indeksi të përmbysur deri në 10 herë. Dhe ka lejuar të ulet konsumimi i memories për cache, sepse tani ruajmë rreshtin label=value vetëm një herë në cache së bashku me N herë. Dhe ky rresht mund të jetë i madh, nëse gjatë etiketimit dhe etiketave ruani rreshta të gjatë që i pëlqen të vendosë aty Kubernetes.
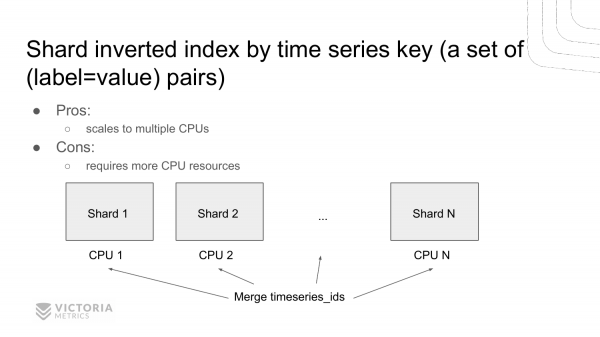
Një tjetër variant për shpejtësimin e kërkimeve në indekset e përmbysura është sharding. Krijimi i disa indekseve të përmbysura në vend të një dhe sharding të dhënave mes tyre sipas çelësit. Ky është një grup key=value Pra. Që do të thotë se ne kemi disa indekse të pavarura të përmbysura, të cilat mund t'i konsultojmë paralelisht në disa procesorë. Zbatimet e mëparshme lejonin funksionimin vetëm në modin me një procesor, pra, skanuar të dhënat vetëm në një bërthamë. Kjo zgjidhje lejon skanimin e të dhënave menjëherë në disa bërthama, ashtu siç bën ClickHouse. Këtë planifikojmë ta realizojmë.

Tani, le të kthehemi te dele tona – tek funksioni i ndërprerjes. timeseries_ids. Le të shqyrtojmë se çfarë zbatimesh mund të ekzistojnë. Ky funksion lejon të gjenden timeseries_ids për një grup të caktuar. label=value.

Varianti i parë – është zbatimi naive. Dy cikle të ngjitur. Këtu kemi në hyrje të funksionit intersectInts dy slices — a dhe b. Në dalje, duhet të na kthejë ndërprerjen e këtyre slices.
Zbatimi naive duket kështu. Ne kalojmë nëpër të gjitha vlerat nga slice a, brenda këtij cikli kalojmë nëpër të gjitha vlerat e slice b. Dhe i krahasojmë ato. Nëse ato përputhen, atëherë kemi gjetur ndërprerjen. Dhe e ruajmë në result.

Cilat janë disavantazhet? Kompleksiteti katror — ky është disavantazhi i saj kryesor. Për shembull, nëse keni dimensionet e slice a dhe b nëse ka një milion, atëherë kjo funksion nuk do të kthejë kurrë një përgjigje. Sepse do të duhet të kryejë një trilion iteracione, gjë që është shumë për komputatorët modernë.

Implementimi i dytë bazohet në map. Ne krijojmë një map. Vendosim në këtë map të gjitha vlerat nga slice. a. Pastaj kalojmë me një cikël të veçantë për slice. b. Dhe kontrollojmë – a ekziston kjo vlerë nga slice b në map. Nëse ekziston, atëherë e shtojmë atë në rezultat.

Cilat janë përfitimet? Avantazh është se këtu ekziston vetëm kompleksitet linear. Kështu që funksioni do të ekzekutohet shumë më shpejt për madhësi më të mëdha slice. Për një madhësi një milion të slice kjo funksion do të përfundojë për 2 milion iteracione, ndryshe nga trillioni i iteracioneve, si në funksionin e mëparshëm.
Cili është disavantazhi? Disavantazhi është se ky funksion kërkon më shumë memorie për të krijuar këtë map.
Disavantazhi i dytë është overhead-i i madh për hash-imin. Ky disavantazh nuk është shumë i dukshëm. Edhe për ne ai nuk ishte shumë i dukshëm, prandaj fillimisht në VictoriaMetrics implementimi i intersection ishte përmes map. Por më pas profilizimi tregoi se shumica e kohës së procesorit shpenzohet në shkrimin në map dhe në kontrollimin e ekzistencës së vlerës në këtë map.
Pse shpenzohet koha e procesorit në këto vende? Sepse në këto rreshta Go kryen operacionin e hash-it. Pra, ai llogarit hash-in nga çelësi, në mënyrë që më pas të referohet në indeksin e caktuar në HashMap. Operacioni i llogaritjes së hash-it realizohet për disa dhjetëra nanosekonda. Kjo është e ngadalshme për VictoriaMetrics.

Unë vendosa të realizoj një bitset, të optimizuar posaçërisht për këtë rast. Ja si duket tani ndërveprimi i dy slices. Këtu krijojmë bitset-in. Shtojmë në të elementët nga slice-i i parë. Pastaj kontrollojmë praninë e këtyre elementëve në slice-in e dytë. Dhe i shtojmë ata në rezultat. Pra, pothuajse nuk ndryshon nga shembulli i mëparshëm. E vetmja gjë është se këtu e zëvendësuam qasjen në map me funksione të personalizuara. shto dhe ka.

Në pamje të parë duket se kjo duhet të funksionojë më ngadalë, nëse më parë aty përdorej një map standard, dhe këtu thirren disa funksione, por profilizimi tregon se kjo gjë funksionon 10 herë më shpejt se map-i standard për rastin me VictoriaMetrics.
Përveç kësaj, ajo përdor shumë më pak memorie krahasuar me realizimin në map. Sepse ne ruajmë këtu bite në vend të vlerave tetëbyte.
Një e metë e këtij implementimi është se nuk është kaq e dukshme, nuk është triviale.
Një tjetër e metë, që shumë mund të mos e vërejnë, është se ky implementim mund të funksionojë keq në disa raste. Kjo do të thotë se është optimizuar për një rast specifik, për këtë rast të prerjes së ids të serive të kohës në VictoriaMetrics. Kjo nuk do të thotë se do të përshtatet për çdo rast. Nëse përdoret gabimisht, do të kemi jo një rritje të performancës, por një gabim out of memory dhe ngadalësimin e performancës.

Të shqyrtojmë implementimin e kësaj strukture. Nëse dëshironi ta shihni, ajo ndodhet në burimet e VictoriaMetrics, në dosjen . Ajo është optimizuar saktësisht për rastin e VictoriaMetrics, ku timeseries_id me përfaqëson një vlerë 64-bitore, ku 32 bitët e parë janë konstantë dhe ndyshojnë vetëm 32 bitët e fundit.
Kjo strukturë të dhënash nuk ruhet në disk, ajo funksionon vetëm në memorie.

Ja API i saj. Ai nuk është shumë i komplikuar. API është përshtatur saktësisht për shembujt specifikë të përdorimit në VictoriaMetrics. Kjo do të thotë se nuk ka funksione të panevojshme. Këtu janë funksionet që përdoren qartë nga VictoriaMetrics.
Ka funksione shto, që shton vlera të reja. Ka një funksion ka, e cila kontrollon vlerat e reja. Dhe ka një funksion fshij, e cila heq vlerat. Ka një funksion ndihmës len, e cila kthen madhësinë e grupit. Funksioni clone klonon grupin. Dhe funksioni appendto e shndërron këtë set në një slice timeseries_ids.

Ja si duket implementimi i kësaj strukture të dhënash. Në set ka dy elemente:
ItemsCount– kjo është një fushë ndihmëse, për të kthyer shpejt numrin e elementeve në set. Do të ishte e mundur pa këtë fushë ndihmëse, por ishte e nevojshme të shtohej këtu, pasi VictoriaMetrics shpesh pyet në algoritmet e saj për gjatësinë e bitset.Fusha e dytë – është
buckets. Ky është një slice i strukturësbucket32. Në çdo strukturë ruhethifusha. Këto janë 32 bitët e sipërm. Dhe dy slice —b16hisdhebucketsngabucket16strukturave.
Këtu ruhen 16 bitët e sipërm të pjesës së dytë të strukturës 64-bit. Dhe këtu ruhet bitsets për 16 bitët më të poshtëm të çdo byte.
Bucket64 është i përbërë nga një array uint64. Gjatësia llogaritet me ndihmën e këtyre konstantave. Në një bucket16 maksimumi mund të ruajë 2^16=65536 bit. Nëse e ndan këtë me 8, atëherë kemi 8 kilobyte. Nëse e ndan përsëri me 8, atëherë është 1000 uint64 vlerë. Pra, Bucket16 – kjo është një strukturë 8-kilobyte.

Le të shqyrtojmë se si është realizuar një nga metodologjitë e kësaj strukture për shtimin e një vlerë të re.
Çdo gjë fillon me uint64 vlerën. Llogarisim 32 bitët e sipërm, llogarisim 32 bitët e poshtëm. Shkruajmë në të gjitha buckets. Krahasojmë 32 bitët e sipërm në çdo bucket me vlerën që po shtojmë. Nëse ato përputhen, thërrasim funksionin shto në strukturën b32 buckets. Dhe shtojmë aty 32 bitët e poshtëm. Nëse ky është kthyer e vërtetë, atëherë kjo do të thotë se ne e kemi shtuar një vlerë të tillë dhe nuk e kemi pasur më parë. Nëse ai kthen false, atëherë një vlerë e tillë ka ekzistuar tashmë. Më pas rritim numrin e elementeve në strukturë.
Nëse nuk gjejmë bucket me vlerën hi-përkatëse, atëherë thërrasim funksionin addAlloc, i cili alokon një të re bucket, duke e shtuar atë në strukturën bucket.

Kjo është realizimi i funksionit b32.add. Ajo është e ngjashme me realizimin e mëparshëm. Ne llogarisim 16 bitët e lartë, 16 bitët e ulët.
Pastaj ne kalojmë në të gjitha 16 bitët e sipërm. Gjejmë përputhjet. Në rast përputhjeje, thërrasim metodën add, e cila do të shqyrtohet në faqen tjetër për bucket16.

Dhe tani niveli më i ulët, i cili duhet të jetë maksimalisht i optimizuar. Ne llogarisim për uint64 vlerën id në slice bit, si dhe bitmask. Ky është një maskë për këtë vlerë 64-bit, sipas së cilës mund të kontrolloni praninë e këtyre bitëve, ose t'i vendosni ato. Ne kontrollojmë praninë e këtyre bitëve, i vendosim ata, dhe kthejmë praninë. Kjo është implementimi ynë, i cili ka lejuar të shpejtojë operacionin e përputhjes së IDs së serive të kohës deri në 10 herë krahasuar me maps normale.

Në VictoriaMetrics, përveç kësaj optimizimi, ka shumë optimizime të tjera. Shumica e këtyre optimizimeve janë shtuar jo rastësisht, por pas profilizimit të kodit në production.
Kjo është rregulli kryesor i optimizimit – mos shtoni optimizimin duke supozuar se aty do të jetë një ngushticë, sepse mund të rezultojë që nuk do të ketë ngushticë. Optimizimi zakonisht keqëson cilësinë e kodit. Prandaj, është më mirë të optimizoni vetëm pas profilizimit dhe, idealisht, në production, në mënyrë që të jenë të dhëna reale. Ata që janë të interesuar, mund të shikoni burimet e VictoriaMetrics dhe të studioni optimizime të tjera që ka.

Kam një pyetje për bitset. Është shumë e ngjashme me implementimin e C++ vector bool, bitset i optimizuar. A e keni marrë implementimin nga aty?
Jo, jo nuk është nga aty. Kur realzoja këtë bitset, e shikoja ndihmën nga struktura e këtyre id-ëve të kohës, të cilat përdoren në VictoriaMetrics. Struktura e tyre është e tillë që 32 bitët e sipërm janë kryesisht të qëndrueshëm. 32 bitët e poshtëm mund të ndryshojnë. Sa më poshtë të jetë bit-i, aq më shpesh mund të ndryshojë. Prandaj, kjo realizim është optimizuar për këtë strukturë të dhënash. Realizimi në C++, sa di unë, është optimizuar për rastin e përgjithshëm. Nëse bëni optimizim për rastin e përgjithshëm, atëherë do të thotë se ajo nuk do të jetë më optimale për rastin specifik.
Ju rekomandoj gjithashtu të shikoni prezantimin e Aleksej Milovidit. Ai fliste diku para një muaji për optimizimet në ClickHouse për specializime të caktuara. Ai vërtet tregon se në rastin e përgjithshëm realizimi në C++ ose ndonjë realizim tjetër janë fokaluar për një punë të mirë në mes të gjithë. Ajo mund të punojë më keq se një realizim të specializuar për njohuritë specifike, siç është rasti ynë, kur ne e dimë se 32 bitët e sipërm janë kryesisht të qëndrueshëm.
Kam një pyetje të dytë. Cila është ndryshimi kardinal nga InfluxDB?
Ka shumë dallime drastike. Nëse flasim për performancën dhe konsumimin e memories, InfluxDB në testime tregon deri në 10 herë më shumë konsumim të memories për seritë me cardinalitet të lartë, kur i keni shumë, për shembull, miliona. Për shembull, VictoriaMetrics konsumon 1 GB për një milion serish aktive, ndërsa InfluxDB konsumon 10 GB. Dhe kjo është një diferencë e madhe.
Dallimi i dytë kardinal është se InfluxDB ka gjuhë të çuditshme pyetjesh – Flux dhe InfluxQL. Ato nuk janë shumë të përshtatshme për punën me seritë temporale në krahasim me , e cila mbështetet në VictoriaMetrics. PromQL është gjuha e pyetjeve nga Prometheus.
Dhe një dallim tjetër është se InfluxDB ka një model të dhënash pak të çuditshëm, ku në çdo rresht mund të ruhen disa fushë me grupe të ndryshme etiketash. Këto rreshta ndahen gjithashtu në tabela të ndryshme. Këto komplikime shtesë e bëjnë të vështirë punën e mëvonshme me këtë bazë. Ajo është e vështirë për t'u mbajtur dhe kuptuar.
Në VictoriaMetrics gjithçka është shumë më e thjeshtë. Çdo seri temporale përfaqëson një çelës-vlerë. Vlera është një grup pikash – (timestamp, vlera), ndërsa çelësi është një grup label=value. Nuk ka ndarje në fushat dhe matjet. Kjo ju lejon të zgjidhni çdo të dhënë dhe pastaj t'i kombinoni, shtoni, zbritni, shumëzoni, ndajeni ndryshe nga InfluxDB, ku llogaritjet midis radhëve të ndryshme ende nuk janë realizuar, sa di unë. Nëse janë realizuar, atëherë është e vështirë, duhet të shkruani shumë kod.
Kam një pyetje të saktësimit. E kuptova saktë që kishte një problem, për të cilin keni folur, që ky indeks i invertuar nuk fiton në memorie, prandaj bëhet particionim?
Në fillim, kam treguar një implementim naiv të indeksit të invertuar në map’in standard të Go. Kjo implementim nuk është e përshtatshme për databaza, sepse ky indeks i invertuar nuk ruhet në disk, ndërsa databaza duhet të ruajë në disk që të dhënat të mbeten të aksesueshme pas rinisjes. Në këtë implementim, pas rinisjes së aplikacionit, indeksi i invertuar do të humbasë. Dhe do të humbni qasje në të gjitha të dhënat sepse nuk do të jeni në gjendje t'i gjeni ato.
Përshëndetje! Faleminderit për raportin! Quhem Pavel. Jam nga kompania Wildberries. Kam disa pyetje për ju. Pyetja e parë. Si mendoni, nëse do të zgjidhnit një parim tjetër për ndërtimin e arkitekturës së aplikacionit tuaj dhe do të ndanit të dhënat sipas kohës, ndoshta do të kishit mundësi të bënte ndërprerje të të dhënave gjatë kërkimit, duke u bazuar vetëm në atë se në një ndarje ndodhen të dhënat për një periudhë kohe, pra për një interval kohor, dhe nuk do t'ju duhej të shqetësoheshit se copat janë të shpërndara ndryshe? Pyetja numër 2 — pasi realizoni një algoritëm të tillë me bitset dhe gjithçka tjetër, ndoshta keni provuar të përdorni instrukcionet e procesorit? Ndoshta keni provuar optimizime të tilla?
Për pyetjen e dytë do të përgjigjem menjëherë. Ne ende nuk kemi arritur aty. Por nëse do të nevojitet, do të arrijmë. Dhe pyetja e parë, cila ishte ajo?
Keni diskutuar dy skenarë. Dhe keni thënë se keni zgjedhur të dytin me një implementim më të komplikuar. Dhe nuk e preferuat të parin, ku të dhënat janë të ndara sipas kohës.
Po. Në rastin e parë, vëllimi total i indeksit do të ishte më i madh, sepse në çdo ndarje do të duhej të mbanim të dhëna të dyfishta për ato seri temporale që vazhdojnë përmes të gjitha ndarjeve. Dhe nëse ju keni një raport churn të ulët për seritë temporale, do të thotë se vazhdimisht përdoren të njëjtat seria, atëherë në rastin e parë ne do të humbnim shumë më tepër në hapësirën e diskut të përdorur krahasuar me rastin e dytë.
Po, ndarja sipas kohës është një opsion i mirë. Këtë e përdor Prometheus. Por në Prometheus ka një mangësi tjetër. Gjatë bashkimit të këtyre copave të dhënash, ai kërkon të mbajë në memorie metainformacionin për të gjitha etiketat dhe seritë temporale. Prandaj, nëse copat e dhënave janë të mëdha që ai po bashkon, konsumimi i memories rritet shumë gjatë bashkimit, në krahasim me VictoriaMetrics. Gjatë bashkimit, VictoriaMetrics në tërësi nuk konsumon memorie, disa kilobajt përdoren, pa marrë parasysh përmasat e copave të dhënash që po bashkohen.
Algoritmi, që përdorni, konsumon memorie. Në të shënohen etiketat e serisë temporale, ku ka vlera. Kështu kontrolloni praninë e çiftëzuar në një grumbull të dhënash dhe në tjetrin. Dhe kuptoni – a ka ndodhur ndërprerja apo jo. Zakonisht, në bazat e të dhënave implementohen kursore, itere, që mbajnë gjendjen e tyre aktuale dhe shkelen në të dhëna të renditura, për shkak se keni një kompleksitet të thjeshtë në këto operacione.
Pse nuk përdorim kursore për ndërprerjen e të dhënave?
Po.
Në LevelDB apo në mergeset kemi pikërisht rreshtat e renditur. Mund të kalojmë me kursor dhe të gjejmë ndërprerjen. Dhe pse nuk e përdorim? Sepse – është e ngadaltë. Sepse kursorët supozojnë se për çdo rresht duhet të thërrasësh një funksion. Thirrja e funksionit – është 5 nanosekonda. Dhe nëse keni 100,000,000 rreshta, atëherë rezulton se harxhojmë gjysmë sekonde vetëm për thirrjen e funksionit.
Po, ka një pyetje tjetër. Pyetja ndoshta do të tingëllojë pak e çuditshme. Pse në momentin e marrjes së të dhënave nuk mund të llogariten të gjithë aggregatët e nevojshëm dhe të ruhet forma e duhur e tyre? Pse të ruajmë volumet e mëdha në disa sisteme si VictoriaMetrics, ClickHouse, etj., vetëm për të shpenzuar shumë kohë më pas për to?
Do të jap një shembull për ta bërë më të qartë. Supozoni, si funksionon një speedometër i vogël lodër? Ai regjistron distancën që keni udhëtuar, duke e shtuar vazhdimisht atë në një matje, dhe në të dytën – kohën. Dhe e ndan. Dhe merr shpejtësinë mesatare. Mund të bëni diçka të ngjashme. Të mbledhni të gjitha faktet e nevojshme në fluturim.
Mirë, e kuptova pyetjen. Shembulli juaj ka vend për jetë. Nëse e dini se cilat agregate ju nevojiten, kjo është zgjidhja më e mirë. Por problemi është se njerëzit ruajnë këto metrika, disa të dhëna në ClickHouse dhe ata nuk dinë se si do t'i agregojnë apo filtrojnë ato në të ardhmen, prandaj duhet të ruajnë të gjitha të dhënat e papërpunuara. Po sikur të dini se çfarë duheni të llogarisni mesatare, pse të mos e llogarisni atë, në vend që të ruani një sasi të madhe të dhënash të papërpunuara? Por kjo është vetëm në rast se e dini saktësisht se çfarë ju nevojitet.
Për më tepër, bazat e të dhënave për ruajtjen e serive temporale mbështesin llogaritjen e agregateve. Për shembull, Prometheus mbështet . Pra, kjo mund të bëhet, nëse e dini se cilat agregate do t'ju nevojiten. Në VictoriaMetrics kjo nuk është ende e disponueshme, por zakonisht përpara saj vendoset Prometheus, në të cilin mund ta bëni atë në rregullat e regjistrimit.
Për shembull, në punën time të mëparshme, ishte e nevojshme të llogaritej numri i ngjarjeve në një dritare lëvizëse për orën e fundit. Problemi është se, për këtë, duhej të krijoja një implementim të personalizuar në Go, pra një shërbim për llogaritjen e këtij elementi. Ky shërbim përfundimisht nuk ishte i thjeshtë, sepse është e vështirë të llogaritet. Implementimi mund të jetë i thjeshtë nëse ju nevojitet të llogaritni disa aggragate në intervale fikse kohore. Nëse dëshoni të llogaritni ngjarjet në një dritare lëvizëse, atëherë nuk është aq e thjeshtë sa duket. Mendoj se kjo akoma nuk është realizuar në ClickHouse ose në bazat e të dhënave të kohës, sepse është e komplikuar për t'u zbatuar.
Dhe një pyetje tjetër. Tani po flisnim për average dhe më erdhi në mend se dikur kishte një gjë si Graphite me backend Carbon. Ai e kishte aftësinë të filtronte të dhënat e vjetra, pra të linte një pikë në minutë, një pikë në orë dhe kështu me radhë. Në parim, kjo është mjaft e përshtatshme nëse na duhen të dhëna të papërpunuara, gjysmë të thënë, për një muaj, dhe gjithë të tjerat mund të filtrohen. Por Prometheus dhe VictoriaMetrics nuk e mbështesin këtë funksionalitet. Është parashikuar të mbështetet? Nëse jo, pse?
Faleminderit për pyetjen. Përdoruesit tanë e bëjnë atë ndonjëherë. Ata pyesin kur do ta shtojmë mbështetjen për downsampling. Këtu ka disa probleme. Së pari, çdo përdorues e kupton nën downsampling diçka të tijën: dikush dëshiron të marrë çdo pikë të rastësishme në një interval të caktuar, dikush dëshiron vlerat maksimale, minimale, mesatare. Nëse shumë sisteme shkruajnë të dhëna në bazën tuaj, nuk mund t’i trajtoni ato të gjitha njësoj. Mund të dalë që për çdo sistem duhet të përdoret një downsampling i ndryshëm. Dhe kjo është e vështirë për t'u zbatuar.
Dhe e dyta është se VictoriaMetrics, ashtu si ClickHouse, është optimizuar për të punuar me një volum të madh të të dhënave të papërpunuara, prandaj ajo mund të përpunojë një miliard rreshta për më pak se një sekondë, nëse keni shumë bërthama në sistemin tuaj. Skandimi i pikave të serive temporale në VictoriaMetrics është 50,000,000 pika në sekondë për çdo bërthamë. Dhe këto performanca shkallëzohen në bërthamat ekzistuese. Pra, nëse keni 20 bërthama, për shembull, do të arrini të skanoni një miliard pikash në sekondë. Dhe kjo karakteristikë e VictoriaMetrics dhe ClickHouse zvogëlon nevojën për downsampling.
Një karakteristikë tjetër është se VictoriaMetrics comprimim këto të dhëna me efikasitet. Kompresimi mesatar në prodhim është nga 0.4 deri në 0.8 byte për pikë. Çdo pikë përfshin një timestamp + një vlerë. Dhe kjo kompresohet më pak se një byte në mesatare.
Sergei. Kam një pyetje. Cila është kuanti minimal i kohës për regjistrim?
Një milisekondë. Së fundmi, kishim një bisedë me zhvillues të tjerë të bazave të të dhënave për seritë e përkohshme. Kuanti minimal i kohës te ata është një sekondë. Edhe në Graphite, për shembull, është gjithashtu një sekondë. Në OpenTSDB gjithashtu është një sekondë. Në InfluxDB – saktësi nanosekondash. Në VictoriaMetrics – një milisekondë, sepse në Prometheus është një milisekondë. Dhe VictoriaMetrics është zhvilluar fillimisht si ruajtje e largët për Prometheus. Por tani ajo mund të ruajë të dhëna edhe nga sisteme të tjera.
Njeriu me të cilin kam biseduar thotë se ata kanë saktësi në sekonda - kjo është e mjaftueshme për ta, sepse varet nga lloji i të dhënave që ruhen në bazën e të dhënave të serive temporale. Nëse janë të dhëna DevOps ose të dhëna nga infrastruktura, ku i mbledhni ato me interval prej 30 sekondash deri në një minutë, atëherë saktësia në sekonda është e mjaftueshme; më pak nuk është e nevojshme. Por nëse po mbledhni këto të dhëna nga sistemet e tregtisë me frekuencë të lartë, atëherë saktësia në nanosekonda është e nevojshme.
Saktësia në milisekonda në VictoriaMetrics është e përshtatshme si për rastin DevOps, ashtu edhe për shumicën e rasteve që përmenda në fillim të raportit. E vetmja gjë për të cilën mund të mos jetë e përshtatshme është për sistemet e tregtisë me frekuencë të lartë.
Faleminderit! Dhe një pyetje tjetër. Çfarë përputhshmërie ka në PromQL?
Përputhje e plotë e anasjelltë. VictoriaMetrics mbështet plotësisht PromQL. Përveç kësaj ajo shton edhe funksionalitete të avancuara mbi PromQL, që quhet . Në lidhje me këtë funksionalitet të avancuar ka një raport në YouTube. Unë kam folur në Monitoring Meetup këtë pranverë në Shën Petersburg.
kanalin Telegram .
Vetëm përdoruesit e regjistruar mund të marrin pjesë në anketë. , ju lutemi.
Çfarë ju pengon të kaloni në VictoriaMetrics si një depo afatgjatë për Prometheus? (Shkruani në komentet, unë do të shtoj në anketë))
71,4%Nuk e përdor Prometheus5
28,6%Nuk dija për VictoriaMetrics2
7 përdorues kanë votuar. 12 përdorues janë abstenues.
Burimi: habr.com
