

Ju sugjeroj të lexoni transkriptin e ligjëratës "Hadoop. ZooKeeper" nga seria "Metodat për përpunimin e shpërndarë të vëllimeve të mëdha të të dhënave në Hadoop"
Çfarë është ZooKeeper, vendi i tij në ekosistemin Hadoop. Të pavërteta në lidhje me llogaritjen e shpërndarë. Diagrami i një sistemi standard të shpërndarë. Vështirësi në koordinimin e sistemeve të shpërndara. Probleme tipike të koordinimit. Parimet pas dizajnit të ZooKeeper. Modeli i të dhënave ZooKeeper. flamujt znode. Sesionet. API-ja e klientit. Primitivët (konfigurimi, anëtarësimi në grup, brava të thjeshta, zgjedhja e liderit, mbyllja pa efekt tufë). Arkitektura ZooKeeper. ZooKeeper DB. ZAB. Përpunuesi i kërkesave.


Sot do të flasim për ZooKeeper. Kjo gjë është shumë e dobishme. Ai, si çdo produkt Apache Hadoop, ka një logo. Ajo përshkruan një burrë.
Para kësaj, ne kryesisht folëm se si të dhënat mund të përpunohen atje, si t'i ruani ato, domethënë si t'i përdorni ato disi dhe të punoni me to disi. Dhe sot do të doja të flisja pak për ndërtimin e aplikacioneve të shpërndara. Dhe ZooKeeper është një nga ato gjëra që ju lejon të thjeshtoni këtë çështje. Ky është një lloj shërbimi që synon një lloj koordinimi të ndërveprimit të proceseve në sistemet e shpërndara, në aplikacionet e shpërndara.
Nevoja për aplikacione të tilla po bëhet çdo ditë e më shumë, kjo është ajo që ka të bëjë kursi ynë. Nga njëra anë, MapReduce dhe kjo kornizë e gatshme ju lejon të nivelizoni këtë kompleksitet dhe të lironi programuesin nga shkrimi i primitivëve si ndërveprimi dhe koordinimi i proceseve. Por nga ana tjetër, askush nuk garanton se kjo nuk do të duhet të bëhet gjithsesi. MapReduce ose korniza të tjera të gatshme jo gjithmonë zëvendësojnë plotësisht disa raste që nuk mund të zbatohen duke përdorur këtë. Përfshirë vetë MapReduce dhe një mori projektesh të tjera Apache; ato, në fakt, janë gjithashtu aplikacione të shpërndara. Dhe për ta bërë më të lehtë shkrimin, ata shkruan ZooKeeper.
Ashtu si të gjitha aplikacionet e lidhura me Hadoop, ai u zhvillua nga Yahoo! Tani është gjithashtu një aplikacion zyrtar Apache. Nuk është zhvilluar aq aktivisht sa HBase. Nëse shkoni te JIRA HBase, atëherë çdo ditë ka një mori raportesh të gabimeve, një mori propozimesh për të optimizuar diçka, d.m.th. jeta në projekt po vazhdon vazhdimisht. Dhe ZooKeeper, nga njëra anë, është një produkt relativisht i thjeshtë, dhe nga ana tjetër, kjo siguron besueshmërinë e tij. Dhe është mjaft e lehtë për t'u përdorur, kjo është arsyeja pse është bërë një standard në aplikimet brenda ekosistemit Hadoop. Kështu që mendova se do të ishte e dobishme ta rishikoja për të kuptuar se si funksionon dhe si ta përdor.
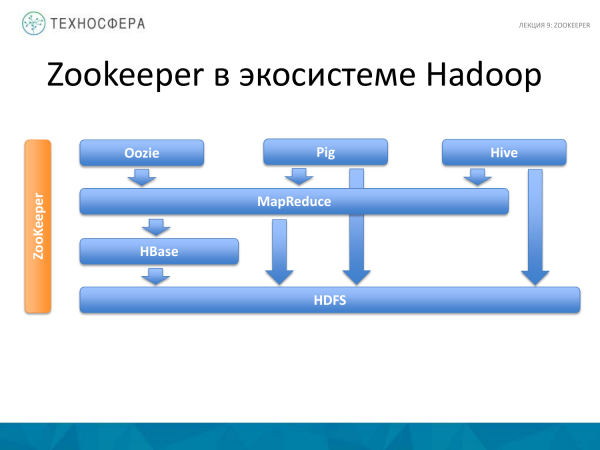
Kjo është një foto nga disa ligjërata që kemi pasur. Mund të themi se është ortogonale me gjithçka që kemi shqyrtuar deri më tani. Dhe gjithçka që tregohet këtu, në një shkallë ose në një tjetër, funksionon me ZooKeeper, d.m.th., është një shërbim që përdor të gjitha këto produkte. As HDFS dhe as MapReduce nuk shkruajnë shërbimet e tyre të ngjashme që do të funksiononin në mënyrë specifike për ta. Prandaj, përdoret ZooKeeper. Dhe kjo thjeshton zhvillimin dhe disa gjëra që lidhen me gabimet.

Nga vjen e gjithë kjo? Duket se kemi nisur dy aplikacione paralelisht në kompjuterë të ndryshëm, i kemi lidhur me një varg ose në një rrjetë, dhe gjithçka funksionon. Por problemi është se Rrjeti nuk është i besueshëm dhe nëse nuhatni trafikun ose shikoni se çfarë po ndodh atje në një nivel të ulët, si ndërveprojnë klientët në Rrjet, shpesh mund të shihni se disa pako humbasin ose ri-dërgohen. Nuk është më kot që u shpikën protokollet TCP, të cilat ju lejojnë të krijoni një seancë të caktuar dhe të garantoni dërgimin e mesazheve. Por në çdo rast, edhe TCP nuk mund t'ju shpëtojë gjithmonë. Çdo gjë ka një timeout. Rrjeti thjesht mund të bjerë për një kohë. Mund të vezullojë. Dhe e gjithë kjo çon në faktin se nuk mund të mbështeteni në besueshmërinë e Rrjetit. Ky është ndryshimi kryesor nga shkrimi i aplikacioneve paralele që funksionojnë në një kompjuter ose në një superkompjuter, ku nuk ka Rrjet, ku ka një autobus më të besueshëm të shkëmbimit të të dhënave në memorie. Dhe ky është një ndryshim thelbësor.
Ndër të tjera, kur përdorni Rrjetin, gjithmonë ekziston një vonesë e caktuar. Disku gjithashtu e ka atë, por Rrjeti ka më shumë prej tij. Vonesa është një kohë vonese, e cila mund të jetë ose e vogël ose mjaft domethënëse.
Topologjia e rrjetit po ndryshon. Çfarë është topologjia - kjo është vendosja e pajisjeve të rrjetit tonë. Ka qendra të dhënash, ka rafte që qëndrojnë atje, ka qirinj. E gjithë kjo mund të rilidhet, zhvendoset, etj. E gjithë kjo gjithashtu duhet të merret parasysh. Emrat e IP-ve ndryshojnë, ndryshon drejtimi përmes të cilit udhëton trafiku ynë. Kjo gjithashtu duhet të merret parasysh.
Rrjeti mund të ndryshojë edhe përsa i përket pajisjeve. Nga praktika, mund të them se inxhinierët tanë të rrjetit me të vërtetë pëlqejnë të përditësojnë periodikisht diçka në qirinj. Papritur doli një firmware i ri dhe ata nuk ishin veçanërisht të interesuar për ndonjë grup Hadoop. Ata kanë punën e tyre. Për ta, gjëja kryesore është që Rrjeti të funksionojë. Prandaj, ata duan të ringarkojnë diçka atje, të bëjnë një ndezje në harduerin e tyre dhe pajisja gjithashtu ndryshon periodikisht. E gjithë kjo disi duhet të merret parasysh. E gjithë kjo ndikon në aplikacionin tonë të shpërndarë.
Zakonisht njerëzit që fillojnë të punojnë me sasi të mëdha të dhënash për ndonjë arsye besojnë se interneti është i pakufishëm. Nëse ka një skedar prej disa terabajtësh atje, atëherë mund ta çoni në serverin ose kompjuterin tuaj dhe ta hapni duke përdorur mace dhe shiko. Një tjetër gabim është në vrull shikoni shkrimet. Mos e bëni kurrë këtë sepse është e keqe. Sepse Vim përpiqet të ruajë çdo gjë, të ngarkojë gjithçka në memorie, veçanërisht kur fillojmë të lëvizim nëpër këtë regjistër dhe të kërkojmë diçka. Këto janë gjëra që harrohen, por ia vlen të merren parasysh.

Është më e lehtë të shkruash një program që funksionon në një kompjuter me një procesor.
Kur sistemi ynë rritet, ne duam t'i paralelizojmë të gjitha, dhe ta paralelizojmë atë jo vetëm në një kompjuter, por edhe në një grup. Shtrohet pyetja: si ta koordinojmë këtë çështje? Aplikacionet tona mund të mos ndërveprojnë me njëri-tjetrin, por ne kemi drejtuar disa procese paralelisht në disa serverë. Dhe si të monitorohet që gjithçka po shkon mirë për ta? Për shembull, ata dërgojnë diçka përmes internetit. Ata duhet të shkruajnë për gjendjen e tyre diku, për shembull, në një lloj databaze ose regjistri, pastaj ta grumbullojnë këtë regjistër dhe më pas ta analizojnë atë diku. Plus, duhet të kemi parasysh që procesi po funksiononte dhe funksiononte, papritmas u shfaq një gabim në të ose u rrëzua, atëherë sa shpejt do ta zbulojmë?
Është e qartë se e gjithë kjo mund të monitorohet shpejt. Kjo është gjithashtu e mirë, por monitorimi është një gjë e kufizuar që të lejon të monitorosh disa gjëra në nivelin më të lartë.
Kur duam që proceset tona të fillojnë të ndërveprojnë me njëri-tjetrin, për shembull, t'i dërgojmë njëri-tjetrit disa të dhëna, atëherë lind edhe pyetja - si do të ndodhë kjo? A do të ketë një lloj kushti gare, a do të mbishkruajnë njëri-tjetrin, a do të arrijnë të dhënat si duhet, a do të humbasë ndonjë gjë gjatë rrugës? Duhet të zhvillojmë një lloj protokolli, etj.
Koordinimi i të gjitha këtyre proceseve nuk është një gjë e parëndësishme. Dhe kjo e detyron zhvilluesin të zbresë në një nivel edhe më të ulët, dhe të shkruajë sistemet ose nga e para, ose jo krejt nga e para, por kjo nuk është aq e thjeshtë.
Nëse keni dalë me një algoritëm kriptografik ose madje e zbatoni atë, atëherë hidheni menjëherë, sepse me shumë mundësi nuk do t'ju funksionojë. Me shumë mundësi do të përmbajë një mori gabimesh që keni harruar t'i jepni. Asnjëherë mos e përdorni për ndonjë gjë serioze sepse ka shumë të ngjarë të jetë e paqëndrueshme. Sepse të gjithë algoritmet që ekzistojnë janë testuar nga koha për një kohë shumë të gjatë. Është përgjuar nga komuniteti. Kjo është një temë më vete. Dhe këtu është e njëjta gjë. Nëse është e mundur të mos zbatoni vetë një lloj sinkronizimi të procesit, atëherë është më mirë të mos e bëni këtë, sepse është mjaft e ndërlikuar dhe ju çon në rrugën e lëkundur të kërkimit të vazhdueshëm të gabimeve.
Sot po flasim për ZooKeeper. Nga njëra anë, është një kornizë, nga ana tjetër, është një shërbim që ia lehtëson jetën zhvilluesit dhe thjeshton zbatimin e logjikës dhe koordinimin sa më shumë të proceseve tona.
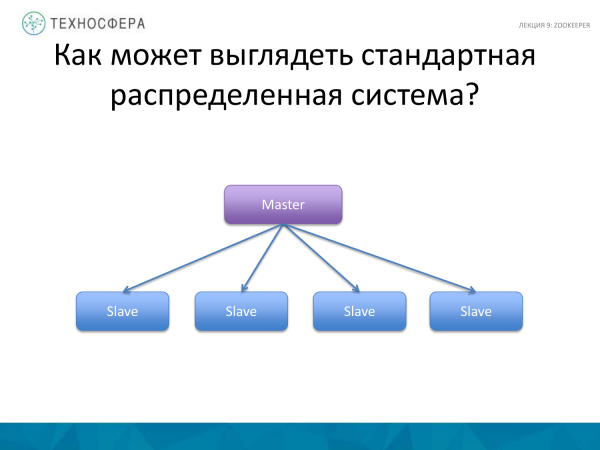
Le të kujtojmë se si mund të duket një sistem standard i shpërndarë. Kjo është ajo për të cilën folëm - HDFS, HBase. Ekziston një proces Master që menaxhon proceset e punëtorëve dhe skllevërve. Ai është përgjegjës për koordinimin dhe shpërndarjen e detyrave, rifillimin e punëtorëve, nisjen e të rejave dhe shpërndarjen e ngarkesës.
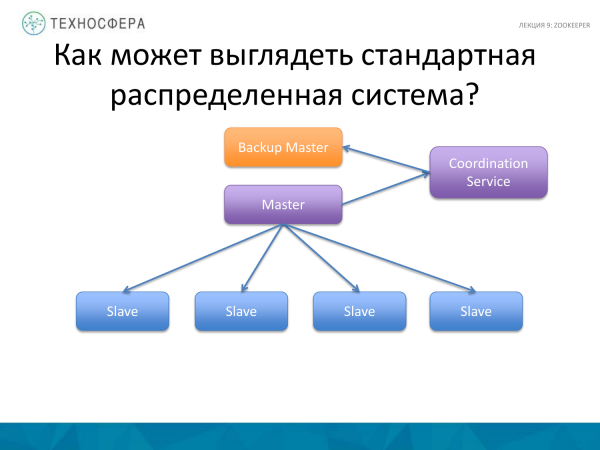
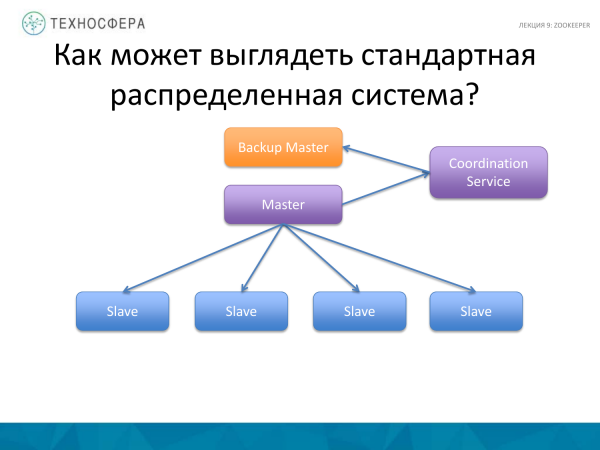
Një gjë më e avancuar është Shërbimi i Koordinimit, d.m.th., zhvendosni vetë detyrën e koordinimit në një proces të veçantë, plus ekzekutoni një lloj Masteri rezervë ose gatishmërie paralelisht, sepse Masteri mund të dështojë. Dhe nëse Master bie, atëherë sistemi ynë nuk do të funksionojë. Ne po ekzekutojmë kopje rezervë. Disa thonë se Masteri ka nevojë të kopjohet në kopje rezervë. Kjo mund t'i besohet edhe Shërbimit të Koordinimit. Por në këtë diagram, vetë Masteri është përgjegjës për koordinimin e punëtorëve; këtu shërbimi po koordinon aktivitetet e riprodhimit të të dhënave.
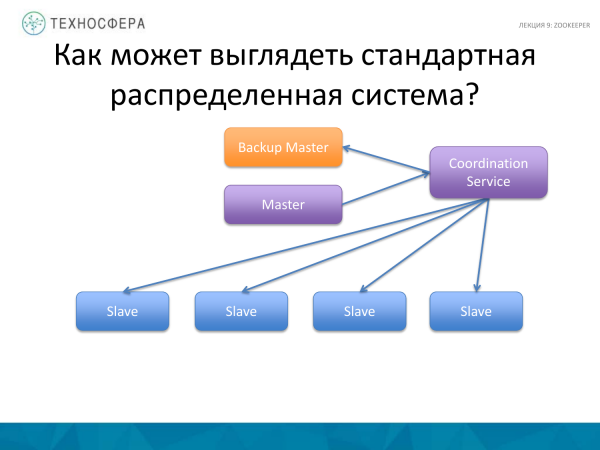
Një opsion më i avancuar është kur i gjithë koordinimi trajtohet nga shërbimi ynë, siç bëhet zakonisht. Ai merr përgjegjësinë për t'u siguruar që gjithçka funksionon. Dhe nëse diçka nuk funksionon, ne mësojmë për të dhe përpiqemi ta kapërcejmë këtë situatë. Sido që të jetë, na mbetet një Mjeshtër që në njëfarë mënyre ndërvepron me skllevër dhe mund të dërgojë të dhëna, informacione, mesazhe etj. përmes ndonjë shërbimi.
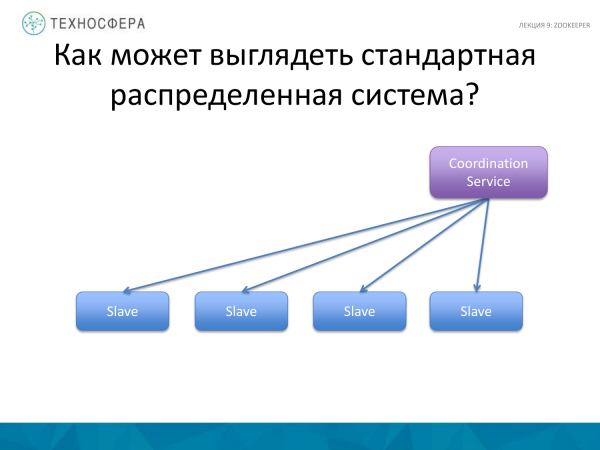
Ekziston një skemë edhe më e avancuar, kur nuk kemi Master, të gjitha nyjet janë skllevër master, të ndryshëm në sjelljen e tyre. Por ata ende duhet të ndërveprojnë me njëri-tjetrin, kështu që ka mbetur ende një shërbim për të koordinuar këto veprime. Ndoshta, Cassandra, e cila punon në këtë parim, i përshtatet kësaj skeme.
Është e vështirë të thuhet se cila nga këto skema funksionon më mirë. Secili ka të mirat dhe të këqijat e veta.
Dhe nuk ka nevojë të kesh frikë nga disa gjëra me Mjeshtrin, sepse, siç tregon praktika, ai nuk është aq i ndjeshëm për të shërbyer vazhdimisht. Gjëja kryesore këtu është të zgjidhni zgjidhjen e duhur për pritjen e këtij shërbimi në një nyje të veçantë të fuqishme, në mënyrë që të ketë burime të mjaftueshme, në mënyrë që nëse është e mundur, përdoruesit të mos kenë akses atje, në mënyrë që të mos e vrasin aksidentalisht këtë proces. Por në të njëjtën kohë, në një skemë të tillë është shumë më e lehtë të menaxhohen punëtorët nga procesi Master, pra kjo skemë është më e thjeshtë nga pikëpamja e zbatimit.
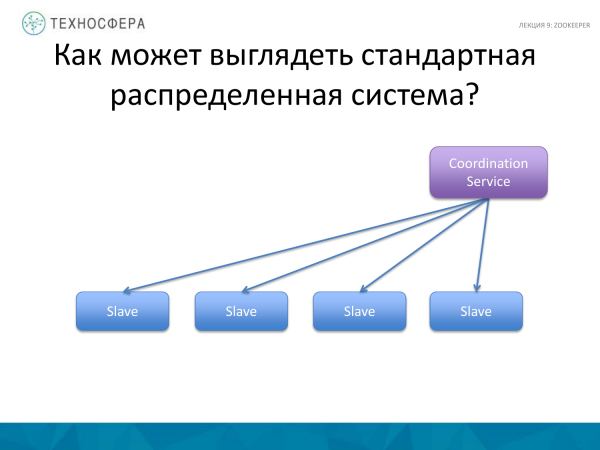
Dhe kjo skemë (sipër) është ndoshta më komplekse, por më e besueshme.

Problemi kryesor janë dështimet e pjesshme. Për shembull, kur dërgojmë një mesazh përmes rrjetit, ndodh një lloj aksidenti dhe ai që dërgoi mesazhin nuk do ta dijë nëse mesazhi i tij është marrë dhe çfarë ka ndodhur nga ana e marrësit, nuk do ta dijë nëse mesazhi është përpunuar saktë. , pra ai nuk do të marrë asnjë konfirmim.
Prandaj, ne duhet ta trajtojmë këtë situatë. Dhe gjëja më e thjeshtë është të ridërgojmë këtë mesazh dhe të presim derisa të marrim një përgjigje. Në këtë rast, nuk merret parasysh nëse gjendja e marrësit ka ndryshuar. Mund të dërgojmë një mesazh dhe të shtojmë të njëjtat të dhëna dy herë.
ZooKeeper ofron mënyra për t'u përballur me refuzime të tilla, gjë që e bën edhe jetën tonë më të lehtë.

Siç u përmend pak më herët, kjo është e ngjashme me shkrimin e programeve me shumë fije, por ndryshimi kryesor është se në aplikacionet e shpërndara që ndërtojmë në makina të ndryshme, mënyra e vetme për të komunikuar është Rrjeti. Në thelb, kjo është një arkitekturë e asgjës së përbashkët. Çdo proces ose shërbim që funksionon në një makinë ka memorien e vet, diskun e vet, procesorin e vet, të cilin nuk e ndan me askënd.
Nëse shkruajmë një program me shumë fije në një kompjuter, atëherë mund të përdorim memorien e përbashkët për të shkëmbyer të dhëna. Ne kemi një ndërprerës konteksti atje, proceset mund të ndryshojnë. Kjo ndikon në performancën. Nga njëra anë, nuk ka një gjë të tillë në program në një grup, por ka probleme me Rrjetin.

Prandaj, problemet kryesore që lindin gjatë shkrimit të sistemeve të shpërndara janë konfigurimi. Ne po shkruajmë një lloj aplikacioni. Nëse është e thjeshtë, atëherë ne kodojmë të gjitha llojet e numrave në kod, por kjo është e papërshtatshme, sepse nëse vendosim që në vend të një afati prej gjysmë sekonde duam një afat kohor prej një sekonde, atëherë duhet të rikompilojmë aplikacionin dhe hapni gjithçka përsëri. Është një gjë kur është në një makinë, kur thjesht mund ta rindizni, por kur kemi shumë makina, duhet të kopjojmë vazhdimisht gjithçka. Ne duhet të përpiqemi ta bëjmë aplikacionin të konfigurueshëm.
Këtu po flasim për konfigurimin statik për proceset e sistemit. Kjo nuk është plotësisht, mbase nga pikëpamja e sistemit operativ, mund të jetë një konfigurim statik për proceset tona, domethënë ky është një konfigurim që thjesht nuk mund të merret dhe përditësohet.
Ekziston edhe një konfigurim dinamik. Këto janë parametrat që duam t'i ndryshojmë menjëherë, në mënyrë që ato të merren atje.
Cili është problemi këtu? Ne përditësuam konfigurimin, e shpërndamë atë, pra çfarë? Problemi mund të jetë se nga njëra anë ne hapëm konfigurimin, por harruam gjënë e re, konfigurimi mbeti atje. Së dyti, ndërsa ne po dilnim, konfigurimi u përditësua në disa vende, por jo në të tjera. Dhe disa procese të aplikacionit tonë që funksionojnë në një makinë u rifilluan me një konfigurim të ri, dhe diku me një të vjetër. Kjo mund të rezultojë që aplikacioni ynë i shpërndarë të mos jetë në përputhje nga këndvështrimi i konfigurimit. Ky problem është i zakonshëm. Për një konfigurim dinamik, është më i rëndësishëm sepse nënkupton që mund të ndryshohet menjëherë.
Një problem tjetër është anëtarësimi në grup. Ne gjithmonë kemi një grup punëtorësh, gjithmonë duam të dimë se cili prej tyre është i gjallë, cili prej tyre ka vdekur. Nëse ka një Master, atëherë ai duhet të kuptojë se cilët punëtorë mund të ridrejtohen te klientët në mënyrë që ata të kryejnë llogaritjet ose të punojnë me të dhëna, dhe cilët jo. Një problem që lind vazhdimisht është se ne duhet të dimë se kush po punon në grupin tonë.
Një problem tjetër tipik janë zgjedhjet e liderëve, kur duam të dimë se kush është në krye. Një shembull është replikimi, kur kemi një proces që merr operacione shkrimi dhe më pas i përsërit ato midis proceseve të tjera. Ai do të jetë udhëheqësi, të gjithë të tjerët do t'i binden, do ta ndjekin. Është e nevojshme të zgjidhet një proces që të jetë i paqartë për të gjithë, në mënyrë që të mos rezultojë se zgjidhen dy drejtues.
Ekziston edhe akses ekskluziv reciprok. Problemi këtu është më kompleks. Ekziston një gjë e tillë si mutex, kur shkruani programe me shumë fije dhe dëshironi që qasja në disa burime, për shembull, një qelizë memorie, të kufizohet dhe kryhet vetëm nga një fije. Këtu burimi mund të jetë diçka më abstrakte. Dhe aplikacione të ndryshme nga nyje të ndryshme të Rrjetit tonë duhet të marrin vetëm akses ekskluziv në një burim të caktuar, dhe jo në mënyrë që të gjithë të mund ta ndryshojnë atë ose të shkruajnë diçka atje. Këto janë të ashtuquajturat bravë.
ZooKeeper ju lejon të zgjidhni të gjitha këto probleme në një shkallë ose në një tjetër. Dhe unë do të tregoj me shembuj se si ju lejon ta bëni këtë.

Nuk ka primitivë bllokues. Kur fillojmë të përdorim diçka, ky primitiv nuk do të presë që të ndodhë ndonjë ngjarje. Me shumë mundësi, kjo gjë do të funksionojë në mënyrë asinkrone, duke lejuar kështu që proceset të mos varen ndërsa presin diçka. Kjo është një gjë shumë e dobishme.
Të gjitha kërkesat e klientëve përpunohen sipas radhës së radhës së përgjithshme.
Dhe klientët kanë mundësinë të marrin njoftim për ndryshime në ndonjë gjendje, për ndryshime në të dhëna, përpara se klienti të shohë vetë të dhënat e ndryshuara.

ZooKeeper mund të funksionojë në dy mënyra. I pari është i pavarur, në një nyje të vetme. Kjo është e përshtatshme për testim. Mund të funksionojë gjithashtu në modalitetin e grumbullimit, në çdo numër nyjesh. serveratNëse kemi një grumbull me 100 makina, nuk është e thënë që të funksionojë në 100 makina. Mjafton të caktohen disa makina ku ZooKeeper mund të funksionojë. Dhe i përmbahet parimit të disponueshmërisë së lartë. ZooKeeper ruan një kopje të plotë të të dhënave në çdo instancë që funksionon. Do ta shpjegoj se si e bën këtë më vonë. Nuk i copëton ose nuk i ndan të dhënat. Nga njëra anë, ky është një disavantazh sepse nuk mund të ruajmë shumë, por nga ana tjetër, është i panevojshëm. Nuk është projektuar për këtë; nuk është një bazë të dhënash.
Të dhënat mund të ruhen nga ana e klientit. Ky është një parim standard në mënyrë që ne të mos e ndërpresim shërbimin dhe të mos e ngarkojmë atë me të njëjtat kërkesa. Një klient i zgjuar zakonisht e di për këtë dhe e ruan atë.
Për shembull, diçka ka ndryshuar këtu. Ekziston një lloj aplikimi. U zgjodh një drejtues i ri, i cili është përgjegjës, për shembull, për përpunimin e operacioneve të shkrimit. Dhe ne duam të përsërisim të dhënat. Një zgjidhje është ta vendosni në një lak. Dhe ne vazhdimisht pyesim shërbimin tonë - a ka ndryshuar ndonjë gjë? Opsioni i dytë është më optimal. Ky është një mekanizëm orësh që ju lejon të njoftoni klientët se diçka ka ndryshuar. Kjo është një metodë më pak e kushtueshme për sa i përket burimeve dhe më e përshtatshme për klientët.

Klienti është përdoruesi që përdor ZooKeeper.
Serveri është vetë procesi ZooKeeper.
Znode është gjëja kryesore në ZooKeeper. Të gjitha znodet ruhen në memorie nga ZooKeeper dhe organizohen në formën e një diagrami hierarkik, në formën e një peme.
Ka dy lloje operacionesh. E para është përditësimi/shkrimi, kur ndonjë operacion ndryshon gjendjen e pemës sonë. Pema është e zakonshme.
Dhe është e mundur që klienti të mos plotësojë një kërkesë dhe të shkëputet, por mund të krijojë një seancë përmes së cilës ndërvepron me ZooKeeper.

Modeli i të dhënave të ZooKeeper i ngjan një sistemi skedarësh. Ekziston një rrënjë standarde dhe më pas kaluam sikur nëpër drejtoritë që shkojnë nga rrënja. Dhe pastaj katalogu i nivelit të parë, nivelit të dytë. Kjo është e gjitha znodes.
Çdo znode mund të ruajë disa të dhëna, zakonisht jo shumë të mëdha, për shembull, 10 kilobajt. Dhe çdo znode mund të ketë një numër të caktuar fëmijësh.

Znodet vijnë në disa lloje. Ato mund të krijohen. Dhe kur krijojmë një znode, ne specifikojmë llojin të cilit duhet t'i përkasë.
Ka dy lloje. I pari është flamuri kalimtar. Znode jeton brenda një seance. Për shembull, klienti ka krijuar një seancë. Dhe sa të jetë gjallë kjo seancë, do të ekzistojë. Kjo është e nevojshme për të mos prodhuar diçka të panevojshme. Kjo është gjithashtu e përshtatshme për momentet kur është e rëndësishme për ne që të ruajmë primitivët e të dhënave brenda një sesioni.
Lloji i dytë është flamuri sekuencial. Ai rrit numëruesin në rrugën për në znode. Për shembull, ne kishim një direktori me aplikacionin 1_5. Dhe kur krijuam nyjen e parë, ajo mori p_1, e dyta - p_2. Dhe kur e thërrasim këtë metodë çdo herë, kalojmë shtegun e plotë, duke treguar vetëm një pjesë të shtegut, dhe ky numër rritet automatikisht sepse ne tregojmë llojin e nyjës - sekuencial.
Znode e rregullt. Ajo do të jetojë gjithmonë dhe do të ketë emrin që ne i themi.

Një tjetër gjë e dobishme është flamuri i orës. Nëse e instalojmë, atëherë klienti mund të regjistrohet në disa ngjarje për një nyje specifike. Unë do t'ju tregoj më vonë me një shembull se si bëhet kjo. Vetë ZooKeeper njofton klientin se të dhënat në nyje kanë ndryshuar. Megjithatë, njoftimet nuk garantojnë që disa të dhëna të reja kanë ardhur. Ata thjesht thonë se diçka ka ndryshuar, kështu që ju duhet të krahasoni të dhënat më vonë me thirrje të veçanta.
Dhe siç thashë tashmë, rendi i të dhënave përcaktohet nga kilobajt. Nuk ka nevojë të ruash të dhëna të mëdha teksti atje, sepse nuk është një bazë të dhënash, është një server i koordinimit të veprimeve.

Më lejoni t'ju tregoj pak për seancat. Nëse kemi disa servera, mund të kalojmë pa probleme nga një server në tjetrin. server, duke përdorur ID-në e sesionit. Kjo është mjaft e përshtatshme.
Çdo seancë ka një lloj kohore. Një seancë përcaktohet nga fakti nëse klienti dërgon ndonjë gjë te serveri gjatë atij sesioni. Nëse ai nuk ka transmetuar asgjë gjatë kohës së ndërprerjes, seanca bie, ose klienti mund ta mbyllë vetë.

Nuk ka aq shumë veçori, por ju mund të bëni gjëra të ndryshme me këtë API. Kjo thirrje që pamë të krijuar krijon një znode dhe merr tre parametra. Kjo është rruga për në znode, dhe duhet të specifikohet plotësisht nga rrënja. Dhe gjithashtu këto janë disa të dhëna që duam t'i transferojmë atje. Dhe lloji i flamurit. Dhe pas krijimit ai e kthen rrugën për në znode.
Së dyti, ju mund ta fshini atë. Truku këtu është se parametri i dytë, përveç shtegut për në znode, mund të specifikojë versionin. Prandaj, ai znode do të fshihet nëse versioni i tij që kemi transferuar është i barabartë me atë që ekziston në të vërtetë.
Nëse nuk duam ta kontrollojmë këtë version, atëherë thjesht kalojmë argumentin "-1".

Së treti, kontrollon ekzistencën e një znode. Kthen true nëse nyja ekziston, false ndryshe.
Dhe më pas shfaqet ora e flamurit, e cila ju lejon të monitoroni këtë nyje.
Ju mund ta vendosni këtë flamur edhe në një nyje që nuk ekziston dhe të merrni një njoftim kur të shfaqet. Kjo gjithashtu mund të jetë e dobishme.
Janë disa sfida të tjera merrni të Dhënat. Është e qartë se ne mund të marrim të dhëna përmes znode. Ju gjithashtu mund të përdorni orën e flamurit. Në këtë rast, nuk do të instalohet nëse nuk ka nyje. Prandaj, duhet të kuptoni se ekziston, dhe më pas të merrni të dhëna.

Ka edhe SetData. Këtu kalojmë versionin. Dhe nëse e kalojmë këtë, të dhënat në znode të një versioni të caktuar do të përditësohen.
Ju gjithashtu mund të specifikoni "-1" për të përjashtuar këtë kontroll.
Një metodë tjetër e dobishme është merrni Fëmijë. Mund të marrim gjithashtu një listë të të gjitha znodeve që i përkasin. Ne mund ta monitorojmë këtë duke vendosur orën e flamurit.
Dhe metodë sync lejon që të gjitha ndryshimet të dërgohen menjëherë, duke siguruar kështu që ato të ruhen dhe të gjitha të dhënat janë ndryshuar plotësisht.
Nëse nxjerrim analogji me programimin e rregullt, atëherë kur përdorni metoda të tilla si shkrimi, të cilat shkruajnë diçka në disk, dhe pasi ju kthen një përgjigje, nuk ka asnjë garanci që i keni shkruar të dhënat në disk. Dhe edhe kur sistemi operativ është i sigurt se gjithçka është shkruar, ka mekanizma në vetë disk ku procesi kalon nëpër shtresa të buferave dhe vetëm pas kësaj të dhënat vendosen në disk.

Kryesisht përdoren thirrje asinkrone. Kjo i mundëson klientit të punojë paralelisht me kërkesa të ndryshme. Mund të përdorni qasjen sinkrone, por është më pak produktive.
Dy operacionet për të cilat folëm janë përditësimi/shkrimi, të cilat ndryshojnë të dhënat. Këto janë krijimi, vendosja e të dhënave, sinkronizimi, fshirja. Dhe lexoni ekziston, getData, getChildren.
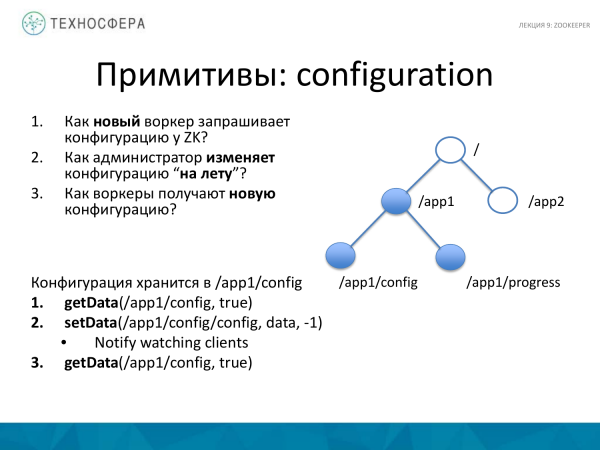
Tani disa shembuj se si mund të bëni primitivë për të punuar në një sistem të shpërndarë. Për shembull, lidhur me konfigurimin e diçkaje. Një punëtor i ri është shfaqur. Shtuam makinën dhe filluam procesin. Dhe janë tre pyetjet e mëposhtme. Si pyet ZooKeeper për konfigurim? Dhe nëse duam të ndryshojmë konfigurimin, si ta ndryshojmë atë? Dhe pasi e ndërruam, si e marrin ata punëtorët që kishim?
ZooKeeper e bën këtë relativisht të lehtë. Për shembull, ekziston pema jonë znode. Ekziston një nyje për aplikacionin tonë këtu, ne krijojmë një nyje shtesë në të, e cila përmban të dhëna nga konfigurimi. Këto mund të jenë ose jo parametra të veçantë. Meqenëse madhësia është e vogël, madhësia e konfigurimit zakonisht është gjithashtu e vogël, kështu që është mjaft e mundur ta ruani këtu.
Ju jeni duke përdorur metodën merrni të Dhënat për të marrë konfigurimin për punëtorin nga nyja. Caktuar në të vërtetë. Nëse për ndonjë arsye kjo nyje nuk ekziston, ne do të informohemi për të kur të shfaqet, ose kur të ndryshojë. Nëse duam të dimë se diçka ka ndryshuar, atëherë e vendosim në të vërtetë. Dhe nëse të dhënat në këtë nyje ndryshojnë, ne do të dimë për të.
SetData. Ne vendosim të dhënat, vendosim "-1", d.m.th. nuk e kontrollojmë versionin, supozojmë se kemi gjithmonë një konfigurim, nuk kemi nevojë të ruajmë shumë konfigurime. Nëse keni nevojë të ruani shumë, do t'ju duhet të shtoni një nivel tjetër. Këtu besojmë se ka vetëm një, kështu që përditësojmë vetëm atë më të fundit, në mënyrë që të mos kontrollojmë versionin. Në këtë moment, të gjithë klientët që janë abonuar më parë marrin një njoftim se diçka ka ndryshuar në këtë nyje. Dhe pasi ta kenë marrë duhet të kërkojnë sërish të dhënat. Njoftimi është se ata nuk marrin vetë të dhënat, por vetëm njoftimin e ndryshimeve. Pas kësaj ata duhet të kërkojnë të dhëna të reja.
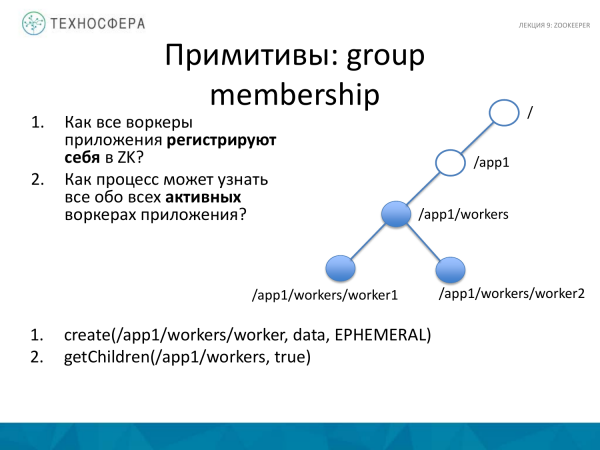
Opsioni i dytë për përdorimin e primitivit është anëtarësimi në grup. Kemi një aplikacion të shpërndarë, ka një bandë punëtorësh dhe duam të kuptojmë që janë të gjithë në vend. Prandaj, ata duhet të regjistrohen që punojnë në aplikacionin tonë. Dhe ne gjithashtu duam të mësojmë, ose nga procesi Master ose diku tjetër, për të gjithë punëtorët aktivë që kemi aktualisht.
Si ta bëjmë këtë? Për aplikacionin, ne krijojmë një nyje punëtorësh dhe shtojmë një nënnivel atje duke përdorur metodën e krijimit. Kam një gabim në rrëshqitje. Këtu ju duhet vijues specifikoni, atëherë të gjithë punëtorët do të krijohen një nga një. Dhe aplikacioni, duke kërkuar të gjitha të dhënat për fëmijët e kësaj nyje, merr të gjithë punonjësit aktivë që ekzistojnë.
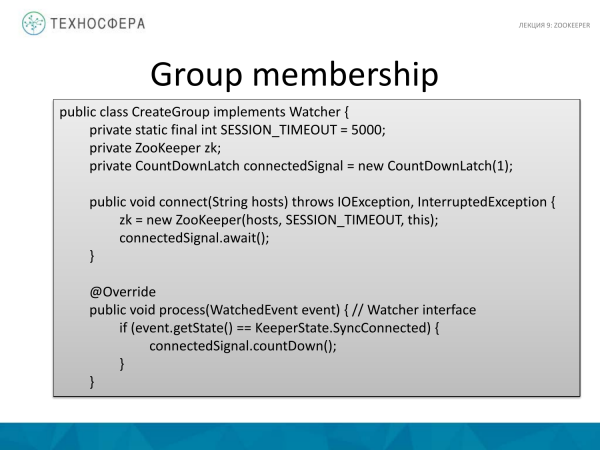

Ky është një zbatim kaq i tmerrshëm se si mund të bëhet kjo në kodin Java. Le të fillojmë nga fundi, me metodën kryesore. Kjo është klasa jonë, le të krijojmë metodën e saj. Si argumentin e parë përdorim hostin, ku po lidhemi, pra e vendosim si argument. Dhe argumenti i dytë është emri i grupit.
Si ndodh lidhja? Ky është një shembull i thjeshtë i API-së që përdoret. Gjithçka është relativisht e thjeshtë këtu. Ekziston një ZooKeeper i klasës standarde. Ne i kalojmë mikpritësit. Dhe caktoni kohëzgjatjen, për shembull, në 5 sekonda. Dhe ne kemi një anëtar të quajtur ConnectSignal. Në thelb, ne krijojmë një grup përgjatë rrugës së transmetuar. Ne nuk shkruajmë të dhëna atje, megjithëse diçka mund të ishte shkruar. Dhe nyja këtu është e tipit persistent. Në thelb, kjo është një nyje e zakonshme e zakonshme që do të ekzistojë gjatë gjithë kohës. Këtu krijohet seanca. Ky është zbatimi i vetë klientit. Klienti ynë do të dërgojë mesazhe periodike që tregojnë se seanca është e gjallë. Dhe kur e mbyllim seancën, thërrasim mbylljen dhe kaq, seanca bie. Kjo është në rast se diçka na bie, në mënyrë që ZooKeeper të mësojë për të dhe të ndërpresë seancën.
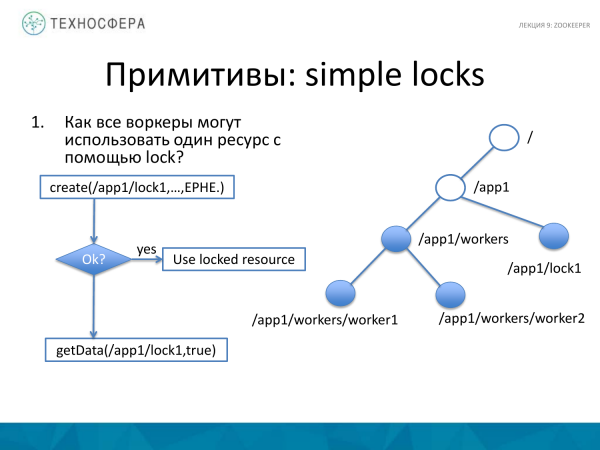
Si të mbyllni një burim? Këtu gjithçka është pak më e ndërlikuar. Ne kemi një grup punëtorësh, ka një burim që duam ta mbyllim. Për ta bërë këtë, ne krijojmë një nyje të veçantë, për shembull, të quajtur lock1. Nëse do të ishim në gjendje ta krijonim atë, atëherë do të kishim një bllokim këtu. Dhe nëse nuk ishim në gjendje ta krijonim atë, atëherë punëtori përpiqet të marrë getData nga këtu, dhe meqenëse nyja tashmë është krijuar, atëherë vendosim një vëzhgues këtu dhe në momentin që gjendja e kësaj nyje ndryshon, ne do të dimë për të. Dhe ne mund të përpiqemi të kemi kohë për ta rikrijuar atë. Nëse e kemi marrë këtë nyje, e kemi marrë këtë kyç, atëherë pasi të mos kemi më nevojë për kyçjen, do ta braktisim atë, pasi nyja ekziston vetëm brenda seancës. Prandaj, ajo do të zhduket. Dhe një klient tjetër, në kuadër të një sesioni tjetër, do të jetë në gjendje të marrë bllokimin në këtë nyje, ose më saktë, ai do të marrë një njoftim se diçka ka ndryshuar dhe ai mund të përpiqet ta bëjë atë në kohë.
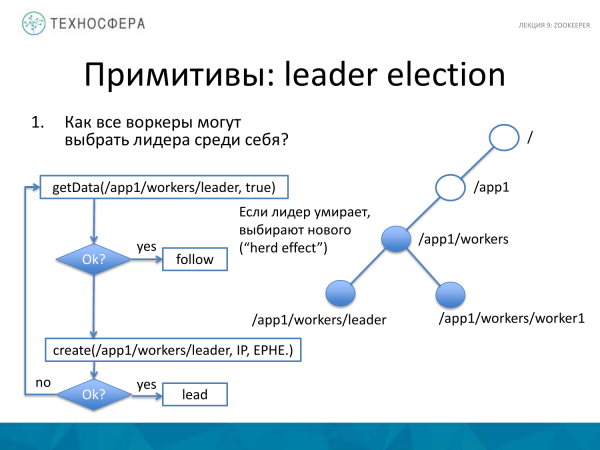
Një shembull tjetër se si mund të zgjidhni udhëheqësin kryesor. Kjo është pak më e ndërlikuar, por edhe relativisht e thjeshtë. Cfare po ndodh ketu? Ekziston një nyje kryesore që grumbullon të gjithë punëtorët. Ne po përpiqemi të marrim të dhëna për liderin. Nëse kjo ka ndodhur me sukses, pra kemi marrë disa të dhëna, atëherë punëtori ynë fillon ta ndjekë këtë udhëheqës. Ai beson se tashmë ka një lider.
Nëse udhëheqësi vdiq për ndonjë arsye, për shembull, ra, atëherë ne përpiqemi të krijojmë një udhëheqës të ri. Dhe nëse kemi sukses, atëherë punëtori ynë bëhet lider. Dhe nëse dikush në këtë moment arriti të krijojë një udhëheqës të ri, atëherë ne përpiqemi të kuptojmë se kush është dhe më pas ta ndjekim atë.
Këtu lind i ashtuquajturi efekt tufë, pra efekti i tufës, sepse kur një udhëheqës vdes, ai që është i pari në kohë do të bëhet udhëheqës.
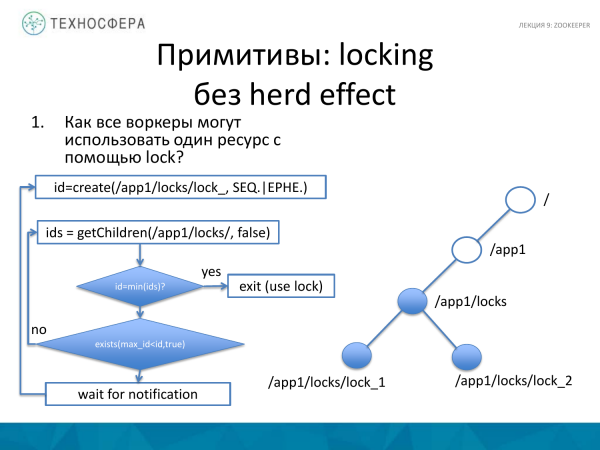
Kur kapni një burim, mund të përpiqeni të përdorni një qasje paksa të ndryshme, e cila është si më poshtë. Për shembull, ne duam të marrim një bravë, por pa efektin hert. Do të konsistojë në faktin që aplikacioni ynë kërkon lista të të gjitha ID-ve të nyjeve për një nyje tashmë ekzistuese me një bllokim. Dhe nëse para kësaj nyja për të cilën kemi krijuar një bllokim është më e vogla nga grupi që kemi marrë, atëherë kjo do të thotë se ne kemi kapur bllokimin. Ne kontrollojmë që kemi marrë një bllokim. Si kontroll, do të ketë një kusht që ID-ja që kemi marrë gjatë krijimit të një bllokimi të ri të jetë minimale. Dhe nëse e kemi marrë, atëherë punojmë më tej.
Nëse ka një ID të caktuar që është më e vogël se bllokimi ynë, atëherë vendosim një vëzhgues në këtë ngjarje dhe presim njoftimin derisa diçka të ndryshojë. Kjo do të thotë, ne e morëm këtë bravë. Dhe derisa të bjerë, ne nuk do të bëhemi ID minimale dhe nuk do të marrim bllokimin minimal, dhe kështu do të mund të identifikohemi. Dhe nëse ky kusht nuk plotësohet, atëherë ne menjëherë shkojmë këtu dhe përpiqemi ta marrim përsëri këtë bravë, sepse diçka mund të ketë ndryshuar gjatë kësaj kohe.
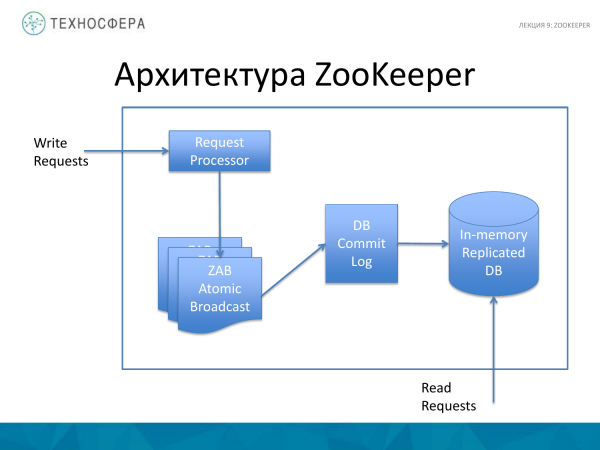
Nga çfarë përbëhet ZooKeeper? Janë 4 gjëra kryesore. Ky është procesi i përpunimit - Kërkesë. Dhe gjithashtu ZooKeeper Atomic Broadcast. Ekziston një regjistër i kryerjes ku regjistrohen të gjitha operacionet. Dhe vetë DB-ja e përsëritur në memorie, d.m.th vetë baza e të dhënave ku ruhet e gjithë kjo pemë.
Vlen të përmendet se të gjitha operacionet e shkrimit kalojnë përmes Përpunuesit të Kërkesave. Dhe operacionet e leximit shkojnë drejtpërdrejt në bazën e të dhënave në memorie.

Vetë baza e të dhënave është përsëritur plotësisht. Të gjitha rastet e ZooKeeper ruajnë një kopje të plotë të të dhënave.
Për të rivendosur bazën e të dhënave pas një përplasjeje, ekziston një regjistër Commit. Praktika standarde është që përpara se të dhënat të futen në memorie, ato shkruhet aty në mënyrë që nëse prishet, ky regjistër mund të luhet dhe gjendja e sistemit mund të rikthehet. Gjithashtu përdoren edhe fotografi periodike të bazës së të dhënave.

ZooKeeper Atomic Broadcast është një gjë që përdoret për të ruajtur të dhënat e përsëritura.
ZAB zgjedh brenda vetes një udhëheqës nga pikëpamja e nyjes ZooKeeper. Nyjet e tjera bëhen ndjekësit e saj dhe presin disa veprime prej saj. Nëse marrin hyrje, ata ia përcjellin të gjitha drejtuesit. Ai fillimisht kryen një operacion shkrimi dhe më pas u dërgon një mesazh ndjekësve të tij se çfarë ka ndryshuar. Kjo, në fakt, duhet të kryhet në mënyrë atomike, d.m.th., operacioni i regjistrimit dhe transmetimit të të gjithë sendit duhet të kryhet në mënyrë atomike, duke garantuar kështu konsistencën e të dhënave.
 Ai përpunon vetëm kërkesat për shkrim. Detyra e tij kryesore është që të transformojë operacionin në një përditësim transaksional. Kjo është një kërkesë e krijuar posaçërisht.
Ai përpunon vetëm kërkesat për shkrim. Detyra e tij kryesore është që të transformojë operacionin në një përditësim transaksional. Kjo është një kërkesë e krijuar posaçërisht.
Dhe këtu vlen të përmendet se idempotenca e përditësimeve për të njëjtin operacion është e garantuar. Cfare eshte? Kjo gjë, nëse ekzekutohet dy herë, do të ketë të njëjtën gjendje, pra vetë kërkesa nuk do të ndryshojë. Dhe kjo duhet të bëhet në mënyrë që në rast të një përplasjeje, të mund të rifilloni operacionin, duke rikthyer kështu ndryshimet që kanë rënë në këtë moment. Në këtë rast, gjendja e sistemit do të bëhet e njëjtë, d.m.th. nuk duhet të ndodhë që një seri e të njëjtave, për shembull, proceset e përditësimit, të çojnë në gjendje të ndryshme përfundimtare të sistemit.








Burimi: www.habr.com
