

В данной статье я представляю вам свои размышления на тему истории и перспектив развития интернета, централизованных и децентрализованных сетей и как итог — возможной архитектуры децентрализованной сети следующего поколения.
С интернетом что-то не так
Впервые я познакомился с Интернетом в 2000 году. Конечно, это далеко не самое начало — Сеть уже существовала до этого, но то время можно назвать как первый расцвет Интернета. Всемирная паутина — гениальное изобретение Тима Бернерса-Ли, web1.0 в его классической канонической форме. Множество сайтов и страничек, ссылающихся друг на друга гиперссылками. На первый взгляд — простая, как все гениальное, архитектура: децентрализованная и свободная. Хочу — путешествую по сайтам других людей, переходя по гиперссылкам; хочу — создаю свой сайт, на котором публикую то что мне интересно — например свои статьи, фотографии, программы, гиперссылки на интересные для меня сайты. А другие размещают ссылки на меня.
Казалось бы — идиллическая картина? Но вы уже знаете чем всё это закончилось.
Страничек стало слишком много, и поиск информации стал весьма нетривиальным делом. Прописанные авторами гиперссылки просто не могли структурировать этот огромный объем информации. Сначала появились каталоги, наполняемые вручную, а затем и гигантские поисковые системы, которые стали использовать хитроумные эвристические алгоритмы ранжирования. Сайты создавались и забрасывались, информация дублировалась и искажалась. Интернет стремительно коммерциализировался и уходил все дальше от идеальной академической сети. Язык разметки быстро превратился в язык форматирования. Появилась реклама, мерзкие надоедливые баннеры и технология раскрутки и обмана поисковиков — SEO. Сеть быстро засорялась информационным мусором. Гиперссылки перестали быть инструментом логической связи и превратились в инструмент раскрутки. Сайты закукливались, замыкались на себе, превращались из открытых «страничек» в герметичные «приложения», становились лишь средствами получения дохода.
Еще тогда у меня возникла некая мысль, что «что-то здесь не так». Куча разных сайтов, начиная от примитивных домашних страничек с вырвиглазным внешним видом, и заканчивая «мегапорталами», перегруженными мелькающими баннерами. Даже если сайты по одной теме — они совсем никак не связаны, у каждого свой дизайн, своя структура, надоедливые баннеры, плохо работающий поиск, проблемы со скачиванием (да, мне хотелось иметь информацию оффлайн). Уже тогда интернет начинал превращаться в какое-то подобие телевидения, где к полезному контенту гвоздями приколочена всяческая мишура.
Децентрализация превратилась в кошмар.
Что же хочется?
Парадоксально, но уже тогда, еще не зная ни о web 2.0, ни о p2p, мне как пользователю не нужна была децентрализация! Вспоминая свои незамутненные размышления тех времен, я прихожу к выводу что мне была нужна… единая база данных! Такая, запрос к которой выдавал бы все результаты, а не наиболее удачно подошедшие для алгоритма ранжирования. Такая, в которой все эти результаты были бы оформлены единообразно и стилизованы моим собственным единым оформлением, а не вырвиглазными самопальными дизайнами многочисленных Васей Пупкиных. Такая, которую можно было бы сохранять оффлайн и не бояться что завтра сайт исчезнет и информация пропадет навсегда. Такая, в которую я мог бы заносить свою информацию — например комментарии и теги. Такая, в которой я мог бы производить поиск, сортировку и фильтрацию своими личными алгоритмами.
Web 2.0 и социальные сети
Тем временем на арену вышла концепция Web 2.0. Сформулированная в 2005 году Тимом О’Рейли, как «методика проектирования систем, которые путём учёта сетевых взаимодействий становятся тем лучше, чем больше людей ими пользуются» — и подразумевающая активное вовлечение пользователей в коллективное создание и редактирование контента Сети. Без преувеличения, вершиной и триумфом этой концепции стали Социальные Сети. Гигантские платформы, объединяющие миллиарды пользователей и хранящие сотни петабайт данных.
Что же мы получили в соцсетях?
- унификация интерфейса; оказалось, что все возможности по созданию разнообразного вырвиглазного дизайна пользователям не нужны; все странички всех пользователей имеют одинаковый дизайн и это всех устраивает и даже удобно; отличается только контент.
- унификация функционала; все многообразие скриптов оказалось также ненужно. «Лента», друзья, альбомы… за время существования соцсетей их функционал более-менее стабилизировался и вряд ли изменится: ведь функционал определяется видами активности людей, а люди практически не меняются.
- единая БД; работать с такой БД оказалось гораздо удобнее, чем с множеством разрозненных сайтов; поиск стал гораздо проще. Вместо непрерывного сканирования разнообразных слабо связанных страничек, кэширования всего этого, ранжирования по сложнейшим эвристическим алгоритмам — относительно простой унифицированный запрос к единой базе с известной структурой.
- интерфейс обратной связи — лайки и репосты; в обычном вебе тот же Гугл никак не мог получить обратную связь от пользователей после перехода по ссылке в поисковой выдаче. В соцсетях эта связь оказалась простой и естественной.
Что мы потеряли? Мы потеряли децентрализацию, а значит — свободу. Считается, что теперь наши данные нам не принадлежат. Если раньше мы могли разместить домашнюю страничку хоть на собственном компьютере, то теперь мы отдаем все наши данные интернет-гигантам.
Кроме того, по мере развития Интернета им заинтересовались правительства и корпорации, в связи с чем возникли проблемы политической цензуры и копирайтных ограничений. Наши странички в соцсетях могут забанить и удалить, если контент не соответствует каким-то правилам соцсети; за неосторожный пост — привлечь к административной и даже уголовной ответственности.
И вот мы вновь задумываемся: а не вернуть ли нам децентрализацию? Но в другой форме, лишенной недостатков первой попытки?
Пиринговые сети
Первые p2p сети появились еще задолго до web 2.0 и развивались параллельно с развитием веба. Основное классическое применение p2p — файлообмен; первые сети разрабатывались для обмена музыкой. Первые сети (такие как Napster) были по сути централизованными, и потому их довольно быстро прикрыли правообладатели. Последователи пошли по пути децентрализации. В 2000 году появляются протоколы ED2K (первый клиент eDokney) и Gnutella, в 2001 — протокол FastTrack (клиент KaZaA). Постепенно степень децентрализации увеличивалась, технологии совершенствовались. На смену системам с «очередью закачки» пришли торренты, появилась концепция распределенных хеш-таблиц DHT. По мере закручивания гаек со стороны государств стала более востребованной анонимность участников. С 2000 года ведется разработка сети Freenet, c 2003 года — I2P, в 2006 стартовал проект RetroShare. Можно упомянуть многочисленные p2p сети, как существовавшие ранее и уже исчезнувшие — так и действующие сейчас: WASTE, MUTE, TurtleF2F, RShare, PerfectDark, ARES, Gnutella2, GNUNet, IPFS, ZeroNet, Tribbler и многие другие. Их много. Они разные. Очень разные — и по назначению, и по устройству… Наверное многим из вас даже не все эти названия знакомы. И ведь это далеко не всё.
Однако у p2p сетей есть масса недостатков. Помимо технических недостатков, присущих каждой конкретной реализации протокола и клиента, можно например отметить достаточно общий недостаток — сложность поиска (т.е. все то, с чем сталкивался Web 1.0, но в еще более сложном варианте). Здесь нет Гугла с его вездесущим и моментальным поиском. И если для файлоолбменных сетей еще можно воспользоваться поиском по имени файла или по метаинформации, то найти что-то, допустим, в оверлейных сетях onion или i2p, весьма непросто, если вообще возможно.
В общем и целом, если проводить аналогии с классическим интернетом, то большинство децентрализованных сетей застряли где-то на уровне FTP. Представьте себе интернет, в котором нет ничего, кроме FTP: ни современных сайтов, ни web2.0, ни Youtube… Вот примерно в таком состоянии и находятся децентрализованные сети. И несмотря на отдельные попытки что-то изменить, пока изменений немного.
Përmbajtje
Обратимся еще к одному важному кусочку этого паззла — контенту. Контент — главная проблема любого интернет-ресурса, и в особенности децентрализованного. Откуда его брать? Конечно, можно положиться на кучку энтузиастов (как это и происходит с существующими p2p сетями), но тогда развитие сети будет достаточно долгим, а контента там будет мало.
Работа с обычным интернетом — это поиск и изучение контента. Иногда — сохранение (если контент интересный и полезный, то многие, особенно пришедшие в Сеть во времена dial-up — в том числе и я — благоразумно сохраняют его оффлайн, чтобы не потерялся; ибо интернет — вещь нам неподконтрольная, сегодня сайт есть завтра нет, сегодня есть видеоролик на ютубе — завтра его удалили, и т.д.
А для торрентов (которые мы воспринимаем скорее как просто средство доставки, чем как p2p сеть) сохранение вообще подразумевается. И это, кстати, одна из проблем торрентов: скачанный один раз файл сложно переместить туда где им удобнее пользоваться (как правило, нужно вручную регенерировать раздачу) и совершенно нельзя переименовать (можно сделать хардлинк, но об этом совсем уж мало кто знает).
В общем, многие тем или иным способом сохраняют контент. Какова его дальнейшая судьба? Обычно сохраненные файлы оказываются где-то на диске, в папке типа Downloads, в общей куче, и лежат там вместе с многими тысячами других файлов. Это плохо — причем плохо для самого пользователя. Если интернет имеет поисковые машины, то локальный компьютер пользователя не имеет ничего подобного. Хорошо если пользователь аккуратный и привык сортировать «входящие» скачанные файлы. Но далеко не все такие…
На самом деле, сейчас немало и таких, кто ничего не сохраняет, а целиком полагается на онлайн. Но в p2p сетях предполагается, что контент хранится локально на устройстве пользователя и раздается другим участникам. Можно ли найти такое решение, которое позволит вовлечь обе категории пользователей в децентрализованную сеть, не меняя их привычек, и более того — облегчив им жизнь?
Идея достаточно простая: что, если сделать средство удобного и прозрачного для пользователя сохранения контента из обычного интернета, причем умного сохранения — с семантической метаинформацией, и не в общую кучу, а в определенную структуру с возможностью дальнейшего структурирования, и одновременно раздавать сохраненный контент в децентрализованную сеть?
Начнем с сохранения
Мы не будем рассматривать утилитарное использование интернета для просмотра прогнозов погоды или расписания самолетов. Нас больше интересуют самодостаточные и более-менее неизменяемые объекты — статьи (начиная от твитов/постов с соцсетях и заканчивая большими статьями, вот как здесь на Хабре), книги, изоборажения, программы, аудио и видео записи. Откуда в основном берется информация? Обычно это
- социальные сети (различные новости, небольшие заметки — «твиты», картинки, аудио и видео)
- статьи на тематических ресурсах (типа Хабра); хороших ресурсов не так много, обычно эти ресурсы также построены по принципу социальных сетей
- новостные сайты
Как правило, там есть стандартные функции: «лайк», «репост», «поделиться в социальных сетях» и т.п.
Представим себе некий плагин к браузеру, который будет специальным образом сохранять все то, под чем мы поставили лайк, сделали репост, сохранили в «избранном» (или нажали специальную кнопку плагина, выведенную в меню браузера — на случай, если у сайта нет функции лайка/репоста/добавления в закладки). Главная идея в том, что вы просто ставите лайк — как вы миллион раз делали до этого, а система сохраняет статью, картинку или видеоролик в специальное оффлайн-хранилище и эта статья или картинка становится доступной — и вам для оффлайн-просмтора через интерфейс децентрализованного клиента, так и в самой децентрализованной сети! Как по мне, очень удобно. Никаких лишних действий, и мы решаем сразу множество задач:
- сохранение ценного контента, который может потеряться или быть удален
- быстрое наполнение децентрализованной сети
- агрегация контента из разных источников (вы можете быть зарегистрированы в десятках интернет-ресурсов, и все лайки/репосты будут стекаться в единую локальную базу)
- структурирование интересного вам контента по вашим правилам
Очевидно, что плагин к браузеру должен быть настроен на структуру каждого сайта (это вполне реально — уже сейчас существуют плагины для сохранения контента из Youtube, Twitter, VK и т.д.). Сайтов, ради которых имеет смысл делать персональные плагины, не так уж и много. Как правило, это распространенные соцсети (их едва ли больше десятка) и еще некоторое количество высококачественных тематических сайтов типа Хабра (таких тоже немного). При открытом коде и спецификации, разработка нового плагина на основе шаблонной заготовки не должна занимать много времени. Для остальных сайтов можно задействовать универсальную кнопку сохранения, которая сохраняла бы всю страницу целиком в mhtml — возможно, предварительно очистив страницу от рекламы.
Теперь о структурировании
Под «умным» сохранением я понимаю как минимум сохранение с метаинформацией: источник контента (URL), набор ранее выставленных лайков, тегов, комментариев, их идентификаторы и т.д. Ведь при обычном сохранении эта информация теряется… Под источником может пониматься не только прямой URL, но и семантическая составляющая: например группа в соцсети или юзер, сделавший репост. Плагин может быть достаточно умным, чтобы использовать эту информацию для автоматического структурирования и тегирования. Также, следует понимать, что и сам пользователь всегда может добавить к сохраняемому контенту некую метаинформацию, для чего следует предусмотреть маскимально удобные средства интерфейса (идей как это сделать у меня достаточно много).
Таким образом, решается вопрос структурирования и организации локальных файлов пользователя. Это уже готовая польза, которой можно воспользоваться даже без всякого p2p. Просто некая оффлайновая база, которая знает что, откуда и в каком контексте мы сохранили, и позволяет проводить маленькие исследования. Например, найти пользователей внешней соцсети, которые больше всех ставили лайки под теми же постами что и вы. Многие ли соцсети это позволяют в явном виде?
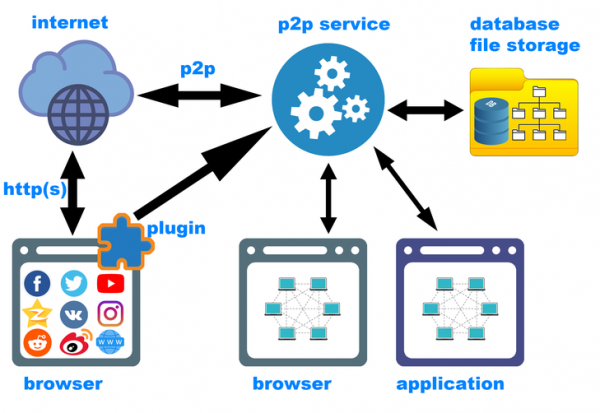
Здесь уже следует упомянуть о том, что одного плагина к браузеру разумеется недостаточно. Второй важнейший компонент системы — сервис децентрализованной сети, работающий в фоновом режиме и обслуживающий как саму p2p сеть (запросы из сети и запросы со стороны клиента), так и сохранение нового контента средствами плагина. Сервис, работая совместно с плагином, разместит контент в нужном месте, вычислит хеши (и возможно определит, что такой контент уже сохранен ранее), добавит в локальную базу данных нужную метаинформацию.
Что интересно — система была бы полезна уже в таком виде, без всяких p2p. Многие пользуются веб-клипперами, добавляющими интересный контент из веба например в Evernote. Предлагаемая архитектура является расширенным вариантом такого клиппера.
И наконец, p2p обмен
Самое приятное — то, что информацией и метаинформацией (как захваченной из веба, так и своей собственной) можно обмениваться. Концепция социальной сети прекрасно переносится на p2p архитектуру. Можно сказать, что социальная сеть и p2p словно созданы друг для друга. Любая децентрализовная сеть в идеале должна быть построена как социальная, только тогда это будет работать эффективно. «Друзья», «Группы» — это же те самые пиры, с которыми должны быть устойчивые связи, а таковые берутся из естественного источника — общих интересов пользователей.
Принципы сохранения и раздачи контента в децентрализованной сети полностью идентичны принципам сохранения (захвата) контента из обычного интернета. Если вы пользуетесь неким контентом из сети (а значит сохранили его), то кто угодно может пользоваться вашими ресурсами (диском и каналом), необходимыми для получения конкретно этого контента.
Лайки — самый простой инструмент сохранения и расшаривания. Если я поставил лайк — неважно, во внешнем интернете или внутри децентрализованной сети — значит контент мне нравится, а раз так — значит я готов держать его у себя локально и раздавать другим участникам децентрализованной сети.
- Контент не «потеряется»; он теперь сохранен у меня локально, я смогу вернуться к нему позже, в любое время, не беспокоясь о том что его кто-то удалит или заблокирует
- Я могу (сразу или позже) категоризировать его, тегировать, комментировать, ассоциировать с другим контентом, в общем сделать с ним что-то осмысленное — назовем это «формирование метаинформации»
- Я могу поделиться этой метаинформацией с другими участниками сети
- Я могу синхронизировать свою метаинформацию с метаинформацией других участников
Наверное, отказ от дизлайков тоже смотрится логично: если контент мне не нравится — то вполне логично, что я не хочу тратить свое место на диске для хранения и свой интернет — канал для раздачи этого контента. Поэтому дизлайки очень органично не вписываются в децентрализацию (хотя иногда это таки ).
Иногда нужно сохранить и то что «не нравится». Есть такое слово «надо»:)
«Закладки» (или «Избранное») — я не выражаю отношение к контенту, но сохраняю его в своей локальной базе закладок. Слово «избранное» (favorites) не вполне подходит по смыслу (для этого есть лайки и последующая их категоризация), а «закладки» (bookmarks) — вполне. Контент в «закладках» также раздается — если он вам «нужен» (т.е. вы так или иначе «пользуетесь» им), то логично что он может оказаться «нужен» и кому-то еще. Почему бы не воспользоваться вашими ресурсами для этого?
Достаточно очевидна функция «друзья«. Это пиры, люди со схожими интересами, а значит те, у которых скорее всего появится интересный контент. В децентрализованной сети это прежде всего означает подписку на ленту новостей от друзей и доступ к их каталогам (альбомам) с сохраненным ими контентом.
Аналогично функция «grupet» — некие коллективные ленты, или форумы, или что-то такое, на что тоже можно оформить подписку — и значит, принимать все материалы группы и раздавать их. Возможно, «группы», подобно большим форумам, должны быть иерархическими — это позволит лучше структурировать контент групп, а также ограничить поток информации и не принимать/не раздавать то, что не очень интересно вам.
Всё остальное
Следует отметить, что децентрализованная архитектура всегда сложнее централизованной. В централизованных ресурсах — жесткий диктат серверного кода. В децентрализованных — необходимость договариваться между множеством равных участников. Разумеется, тут не обойтись без криптографии, блокчейнов и прочих достижений, отработанных главным образом на криптовалютах.
Я предполагаю, что могут потребоваться некие криптографические взаимные рейтинги доверия, формируемые участниками сети друг для друга. Архитектура должна позволять эффективно бороться с ботнетами, которые, существуя в некоем облаке, могут например взаимонакручивать рейтинги сами себе. Очень хочется, чтобы корпорации и ботнет-фермы, при всем их технологическом превосходстве, не перехватили управление такой децентрализованной сетью; чтобы главным ее ресурсом были живые люди, способные производить и структурировать контент, интересный и полезный для других живых людей.
Еще хочется, чтобы такая сеть двигала цивилизацию к прогрессу. На этот счет у меня есть целая масса идей, которая впрочем не вписывается в рамки этой статьи. Скажу лишь, что определенным образом научный, технический, медицинский и т.п. контент должен иметь преимущество перед развлекательным, а это потребует таки некой модерации. Сама по себе модерация децентрализованной сети — задача нетривиальная, но решаемая (правда, слово «модерация» тут совершенно некорректное и совершенно не отражает сути процесса — ни внешне, ни внутренне… и я даже не придумал, как можно было бы назвать этот процесс).
Наверное, излишним будет упоминать о необходимости обеспечения анонимности — как встроенными средствами (как в i2p или Retroshare), так и пропусканием всего трафика через TOR или VPN.
Ну и наконец программная архитектура (схематично нарисованная на картинке к статье). Как уже было сказано, первый компонент системы — плагин для браузера, захватывающий контент с метаинформацией. Второй важнейший компонент — p2p сервис, работающий в фоновом режиме («backend»). Работа сети очевидно не должна зависеть от того, запущен ли браузер. Третьим компонентом является клиентское ПО — frontend. Это может быть и локальный веб-сервис (в этом случае пользователь сможет работать с децентрализованной сетью не выходя из любимого браузера), и отдельное GUI-приложение под конкретную ОС (Windows, Linux, MacOS, Andriod, iOS и т.д.). Мне нравится идея одновременного существования всех вариантов frontend’а. Заодно это обяжет к более строгой архитектуре backend’а.
Есть еще множество аспектов, которые в данную статью не вошли. Подключение к раздаче существующих файлохранилищ (т.е. когда у вас уже есть пара терабайт накачанного, и вы даете клиенту просканировать это, получить хеши, сопоставить их с тем что есть внутри Сети и присоединиться к раздаче, а заодно получить из Сети метаинформацию о своих собственных файлах — нормальные названия, описания, рейтинги, отзывы и т.п.), подключение внешних источников метаинформации (таких например, как базы Libgen), опциональное использование дискового пространства для хранения чужого зашифрованного контента (как во Freenet), архитектура интеграции с существующими децентрализованными сетями (тут вообще темный лес), идея медиахеширования (использование специальных перцептивных хешей для медиаконтента — картинок, аудио и видео, что позволит сопоставлять одинаковые по смыслу медиафайлы, отличающиеся размерами, разрешением и т.д.) и многое другое.
Краткое резюме статьи
1. В децентрализованных сетях нет Гугла с его поиском и ранжированием — но зато есть Сообщество реальных людей. Социальная сеть с ее механизмами обратной связи (лайками, репостами…) и социальным графом (друзьями, сообществами…) — идеальная модель прикладного уровня для децентрализованной сети
2. Основная идея, которую я привношу этой статьей — автоматическое сохранение интересного контента из обычного интернета при установке лайка/репоста; это может быть полезно и без p2p, просто ведение личного архива интересной информации
3. Этот контент заодно может автоматически наполнять децентрализованную сеть
4. Принцип автоматического сохранения интересного контента работает и при лайках/репостах в самой децентрализованной сети
Burimi: habr.com
