

Përshëndetje, Habr! Tani për tani në OTUS është hapur një grup për një raund të ri të kursit. . Me rastin e fillimit të kursit, ne tradicionalisht kemi përgatitur për ju një përkthim të materialeve interesante.
Çdo ditë më shumë se njëqind milion njerëz vizitojnë Twitter për të mësuar se çfarë po ndodh në botë dhe për ta diskutuar atë. Çdo tweet dhe çdo veprim tjetër i përdoruesve gjeneron një ngjarje që është e disponueshme për analizën e brendshme të të dhënave në Twitter. Qindra punonjës analizojnë dhe vizualizojnë këto të dhëna, dhe përmirësimi i përvojës së tyre është prioriteti kryesor për ekipin e Platformës së Të Dhënave të Twitter.
Ne besojmë se përdoruesit me një gamë të gjerë aftësish teknike duhet të kenë mundësi për të gjetur të dhëna dhe për të pasur qasje në mjete analize dhe vizualizimi të punojnë mirë mbi SQL. Kjo do t’i lejonte një grup të ri përdoruesish me më pak orientim teknik, duke përfshirë analistët e të dhënave dhe menaxherët e produkteve, të nxjerrin informacion nga të dhënat, duke i ndihmuar ata të kuptojnë më mirë dhe të përdorin mundësitë e Twitter. Kështu ne demokratizojmë analizën e të dhënave në Twitter.
Me përmirësimin e mjeteve tona dhe mundësive për analizën e brendshme të të dhënave, kemi parë përmirësime në shërbimin Twitter. Megjithatë, ka ende hapësirë për rritje. Mjetet aktuale, si Scalding, kërkojnë përvojë në programim. Mjetet e analizës bazuar në SQL, si Presto dhe Vertica, kanë probleme me performancën në shkallë të madhe. Ndërkohë, na shqetëson shpërndarja e të dhënave midis disa sistemeve pa qasje të vazhdueshme ndaj tyre.
Vit më parë shpallëm , në kuadër të cilit po transferojmë pjesë të në Google Cloud Platform (GCP). Kemi arritur në përfundimin se mjetet e Google Cloud mund të na ndihmojnë në iniciativat tona për demokratizimin e analizës, vizualizimit dhe mësimit të makinerisë në Twitter:
- : një magazinë të dhënash korporative me një motor SQL të bazuar në , i njohur për shpejtësinë e tij, lehtësinë dhe aftësinë për të përballuar .
- një mjet për vizualizimin e të dhënave të mëdha me funksione bashkëpunimi, si në Google Docs.
Nga ky artikull do të mësoni për përvojën tonë me këto mjete: çfarë kemi bërë, çfarë kemi mësuar dhe çfarë do të bëjmë më pas. Tani do të përqendrohemi në analitikën paketore dhe interaktive. Analitikën në kohë reale do ta diskutojmë në artikullin tjetër.
Historia e magazinave të të dhënave në Twitter
Para se të thellohemi në BigQuery, është e përshtatshme të japim një përmbledhje të shkurtër të historisë së magazinave të të dhënave në Twitter. Në vitin 2011, analiza e të dhënave në Twitter kryhej në Vertica dhe Hadoop. Për të krijuar MapReduce, ne përdorëm Pig. Në vitin 2012, e zëvendësuam Pig me Scalding, i cili kishte një API në Scala me avantazhe si mundësia për të krijuar konvejerë të ndërlikuar dhe lehtësinë në testim. Megjithatë, për shumë analistë të të dhënave dhe menaxherë produktesh, të cilët ishin më të rehatshëm të punonin me SQL, kjo ishte një kurbë mësimi mjaft e pjerrët. Diku në vitin 2016, filluam të përdornim Presto si ndërfaqen SQL për të dhënat në Hadoop. Spark ofronte një ndërfaqe Python, e cila e bën atë një zgjedhje të mirë për hulumtimet ad hoc të të dhënave dhe mësimin e makinave.
Që nga viti 2018, kemi përdorur këto mjete për analizën dhe vizualizimin e të dhënave:
- Scalding për linjat e prodhimit
- Scalding dhe Spark për analiza ad hoc të të dhënave dhe mësim makinor
- Vertica dhe Presto për analiza SQL ad hoc dhe interaktive
- Druid për qasje interaktive, kërkuese dhe me vonesë të ulët në metrikat e serive të kohës
- Tableau, Zeppelin dhe Pivot për vizualizimin e të dhënave
Kemi zbuluar se, megjithëse këto mjete ofrojnë mundësi shumë të fuqishme, kemi hasur vështirësi në realizimin e aksesit të këtyre mundësive për një audiencë më të gjerë në Twitter. Duke zgjeruar platformën tonë me ndihmën e Google Cloud, ne përqendrohemi në thjeshtimin e mjeteve tona analitike për të gjithë Twitter-in.
Depoja e të dhënave BigQuery nga Google
Disa ekipe në Twitter tashmë kanë përfshirë BigQuery në disa nga kanalet e tyre të prodhimit. Duke përdorur përvojën e tyre, filluam të vlerësojmë mundësitë e BigQuery për të gjitha skenarët e përdorimit të Twitter. Qëllimi ynë ishte të ofronim BigQuery për të gjithë kompaninë, si dhe të standardizonim dhe mbështesnim atë brenda paketës së veglave të Platformës së të Dhënave. Kjo ishte e vështirë për shumë arsye. Na nevojitej të zhvillonim një infrastrukturë për të pranuar sasi të mëdha të dhënash në mënyrë të besueshme, për të mbështetur menaxhimin e të dhënave në shkallë të plotë të kompanisë, për të siguruar kontrollin e duhur të qasjes dhe për të garantuar privatësinë e klientëve. Na duhej gjithashtu të krijonim sisteme për shpërndarjen e burimeve, monitorimin dhe kthimin e pagesave, në mënyrë që ekipet të mund të përdorin efektivisht BigQuery.
Në nëntor 2018, ne publikuam një version alfa të BigQuery dhe Data Studio për të gjithë kompaninë. Ne ofruam punonjësve të Twitter disa nga tabelat tona më të përdorura me të dhëna personale të pastra. Më shumë se 250 përdorues nga ekipet e ndryshme, duke përfshirë inxhinierinë, financat dhe marketingun, përdorën BigQuery. Së fundmi, ata bënin rreth 8,000 kërkesa, duke procesuar rreth 100 PB në muaj, përveç kërkesave të planifikuara. Pas marrjes së komenteve shumë pozitive, ne vendosëm të ecim përpara dhe të ofrojmë BigQuery si burimin kryesor për bashkëveprimin me të dhënat në Twitter.
Ja skema e arkitekturës së nivelit të lartë të depozitës sonë të të dhënave Google BigQuery.
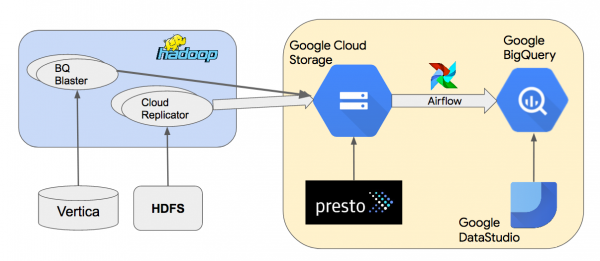
Ne kopjojmë të dhënat nga klasterët lokalë Hadoop në Google Cloud Storage (GCS), duke përdorur mjetin tonë të brendshëm Cloud Replicator. Më pas, ne përdorim Apache Airflow për të krijuar kanale, të cilat përdorin "" për të ngarkuar të dhënat nga GCS në BigQuery. Ne përdorim Presto për të pyetur grumbuj të dhënash Parquet ose Thrift-LZO në GCS. BQ Blaster është një mjet i brendshëm Scalding për ngarkimin e grumbujve të të dhënave HDFS Vertica dhe Thrift-LZO në BigQuery.
Në seksionet në vazhdim, ne do të diskutojmë qasjen dhe njohuritë tona për thjeshtësinë e përdorimit, performancën, menaxhimin e të dhënave, funksionalitetin e sistemit dhe kostot.
Thjeshtësia e përdorimit
Ne zbuluam se përdoruesit kishin lehtësi të madhe për t'u nisur me BigQuery, pasi nuk kërkonte instalim të softuerit dhe përdoruesit mund të hynin në të përmes një ndërfaqeje të kuptueshme në internet. Megjithatë, përdoruesit duhej të njiheshin me disa funksione të GCP dhe konceptet e tij, duke përfshirë burime si projektet, grumbujt e dhënash dhe tabelat. Ne zhvilluam materiale mësimore dhe udhëzues për të ndihmuar përdoruesit të fillojnë punën. Me një kuptim basal, përdoruesit mund të lëvizin lehtësisht nëpër grumbujt e dhënash, të shohin skemën dhe të dhënat e tabelave, të kryejnë kërkesa të thjeshta dhe të vizualizojnë rezultatet në Data Studio.
Qëllimi ynë për sa i përket futjes së të dhënave në BigQuery ishte të sigurojmë ngarkim të qetë të grumbujve të të dhënave HDFS ose GCS me një klikim të vetëm. Ne shqyrtuam (Airflow i menaxhuar), por nuk arritëm ta përdorim për shkak të modelit tonë të sigurisë "Domain Restricted Sharing" (më shumë për këtë në seksionin "Menaxhimi i të dhënave" më poshtë). Ne eksperimentuam me përdorimin e Shërbimit të Transferimit të të Dhënave Google (DTS) për organizimin e detyrave ngarkesë në BigQuery. Ndërkohë që DTS u konfigurua shpejt, nuk ishte fleksibël për ndërtimin e konvejerëve me varësi. Për versionin tonë alpha, krijuam një ambient të vetin Apache Airflow në GCE dhe e po përgatitim për të punuar në prodhim dhe për të mbështetur më shumë burime të dhënash, si Vertica.
Për të transformuar të dhënat në BigQuery, përdoruesit krijojnë konvejerë të thjeshtë të të dhënave SQL, duke përdorur kërkesa të planifikuara. Për konvejerët kompleksë me shumë hapa me varësi, planifikojmë të përdorim ose infrastrukturën tonë Airflow ose Cloud Composer së bashku me .
Performanca
BigQuery është krijuar për kërkesa SQL siç janë ato me qëllim të përgjithshëm, të cilat përpunojnë sasi të mëdha të dhënash. Ai nuk është i dizajnuar për kërkesa me vonesë të ulët, me kapacitet të lartë kalimi, të nevojshme për baza të dhënash transaksionale, ose për analizën e serive temporale me vonesë të ulët. . Për kërkesat analitike interaktive, përdoruesit tanë presin një kohë përgjigjeje më pak se një minutë. Duhej ta projektin përdorimin e BigQuery në mënyrë që të përmbushim këto pritshmëri. Për të siguruar një performancë të parashikueshme për përdoruesit tanë, ne përdorëm funksionalitetin e BigQuery, të disponueshëm për klientët me pagesë fikse, që lejon pronarët e projekteve të rezervojnë slotet minimale për kërkesat e tyre. BigQuery është një njësi fuqie llogaritëse e nevojshme për të ekzekutuar kërkesat SQL.
Kemi analizuar më shumë se 800 kërkesa, duke përpunuar rreth 1 TB të dhënash çdo, dhe zbuluam se koha mesatare e ekzekutimit ishte 30 sekonda. Mësuam gjithashtu se performanca varet fort nga përdorimi i slots tonë në projekte dhe detyra të ndryshme. Duhet të jemi të qartë në ndarjen e rezervave tona të slots për prodhim dhe ad hoc, për të mbajtur performancën për skenarët e përdorimit të prodhimit dhe analizën interaktive. Kjo ndikuar shumë në dizajnin tonë për rezervimin e slots dhe hierarkinë e projekteve.
Për menaxhimin e të dhënave, funksionalitetin dhe koston e sistemeve, do të flasim në ditët në vijim në pjesën e dytë të përkthimit, ndërsa tani ftojmë të gjithë të interesuarit për , ku do të jetë e mundur të informoheni në detaje rreth kursit dhe të bëni pyetje ekspertit tonë — Egor Mateshuk (Inxhinier i Dhënave Senior, MaximaTelecom).
Lexoni më shumë:
Burimi: habr.com
