


Nëse punoni me Kubernetes, ndoshta kubectl është një nga mjetet më të përdorura nga ju. Çdo herë që kaloni shumë kohë duke punuar me një mjet të caktuar, ia vlen të mësoni mirë atë dhe të përdorni në mënyrë efikase.
Ekipa përktheu artikulli i Daniel Veibel, ku do të gjeni këshilla dhe truka për një punë efikase me kubectl. Ai gjithashtu do t'ju ndihmojë të kuptoni më thellë funksionimin e Kubernetes.
Sipas autorit, qëllimi i artikullit është të bëjë që puna juaj e përditshme me Kubernetes të jetë jo vetëm më e efektshme, por edhe më e këndshme!
Hyrje: çfarë është kubectl
Para se të mësoni si të përdorni kubectl më efikas, është e nevojshme të keni një kuptim bazë të asaj që është dhe si funksionon.
Nga ana e përdoruesit, kubectl është një panel menaxhimi që lejon kryerjen e operacioneve Kubernetes.
Nga ana teknike, kubectl është klienti i API-së Kubernetes.
Kubernetes API — është një API HTTP REST. Ky API është ndërfaqja e vërtetë e përdoruesit të Kubernetes, përmes së cilës ai kontrollohet plotësisht. Kjo do të thotë se çdo operacion i Kubernetes paraqitet si një pikë fundore API dhe mund të ekzekutohet me një kërkesë HTTP në këtë pikë fundore.
Prandaj, detyra kryesore e kubectl është të ekzekutojë kërkesa HTTP ndaj API-së së Kubernetesit:
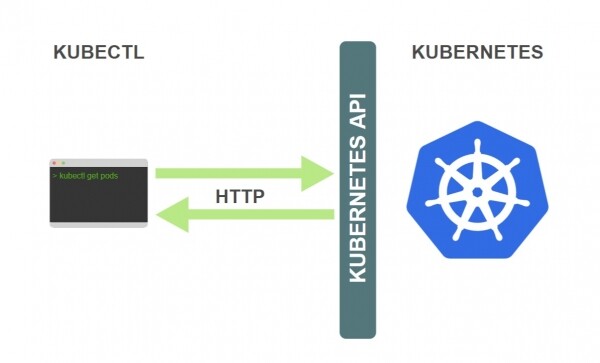
Kubernetes është një sistem krejtësisht të orientuar ndaj burimeve. Kjo do të thotë se ai mbështet gjendjen e brendshme të burimeve, dhe të gjitha operacionet e Kubernetesit janë operacione CRUD.
Ju keni kontroll të plotë mbi Kubernetes, duke menaxhuar këto burime, dhe Kubernetes zbulohet se çfarë të bëjë, duke u bazuar në gjendjen aktuale të burimeve. Për këtë arsye, referenca në API-në e Kubernetes është organizuar si një listë e tipeve të burimeve me operacionet e lidhura me to.
Le të shohim një shembull..
Supozoni se dëshironi të krijoni një burim ReplicaSet. Për ta bërë këtë, ju e përshkruani ReplicaSet-in në një skedar me emrin replicaset.yaml, pastaj ekzekutoni komandën:
$ kubectl create -f replicaset.yamlSi rezultat, do të krijohet një burim ReplicaSet. Por çfarë ndodh prapa skenave?
Në Kubernetes ka një operacion për krijimin e ReplicaSet. Siç është çdo operacion tjetër, ajo ofrohet si një pikë fundore API. Pika specifike e fundit API për këtë operacion duket kështu:
POST /apis/apps/v1/namespaces/{namespace}/replicasetsPikat fundore API të të gjitha operacioneve Kubernetes mund të gjenden në (duke përfshirë ). Për të bërë kërkesën reale në pikën e fundit, duhet të shtoni paraprakisht URL-në e serverit API në rrugët e pikave të fundit të renditura në dokumentacionin API.
Prandaj, kur ekzekutoni komandën e mësipërme, kubectl dërgon një kërkesë HTTP POST në pikën e lartpërmendur API. Definimi i ReplicaSet që keni specifikuar në skedarin replicaset.yaml, dërgohet në trupin e kërkesës.
Kështu funksionon kubectl për të gjitha komandat që ndërveprojnë me klasterin Kubernetes. Në të gjitha këto raste, kubectl thjesht dërgon kërkesa HTTP në pikat përkatëse të fundit API të Kubernetes.
Vini re se është e mundur të menaxhoni plotësisht Kubernetes me një mjet si curl, duke dërguar manualisht kërkesa HTTP në API-në e Kubernetes. Kubectl thjesht e simplifikon përdorimin e API-së Kubernetes.
Kjo është baza e asaj që është kubectl dhe si funksionon. Por ka diçka tjetër për API-në e Kubernetes që çdo përdorues i kubectl duhet ta dijë. Le të zhytim shkurtimisht në botën e brendshme të Kubernetes.
Bota e brendshme e Kubernetes
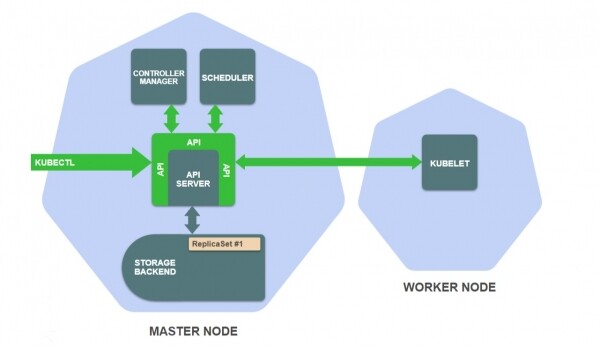
Kubernetes përbëhet nga një grup komponentesh të pavarura, të cilat ekzekutohen si procese të veçanta në nyjat e klasterit. Disa komponentë punojnë në nyjat kryesore, të tjerë në nyjat punuese, secili komponent ka detyrën e vet të veçantë.
Ja komponentët më të rëndësishëm në nyjat kryesore:
- Depoja — ruan definimet e burimeve ().
- Serveri API — ofron API-në dhe menaxhon depin.
- Menaxheri i kontrollit — garanton që statuset e burimeve përputhen me specifikimet.
- Planifikuesi — planifikon pods në nyjat punuese.
Dhe ja një nga komponentët më të rëndësishëm në nyjat punuese:
- Kubelet — menaxhon ekzekutimin e kontejnerëve në nyjën punuese.
Për të kuptuar si punojnë këto komponentë së bashku, le të marrim një shembull.
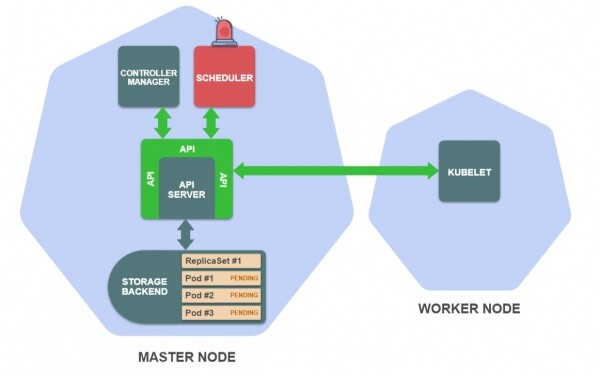
Supozoni se sapo keni ekzekutuar kubectl create -f replicaset.yaml, pas të cilit kubectl bën një kërkesë HTTP POST në (duke transmetuar definimin e burimit të ReplicaSet).
Çfarë ndodh në klaster?
- Pasi të përfundojë
kubectl create -f replicaset.yamlServeri API ruan definicionin e burimit tuaj ReplicaSet në depo:
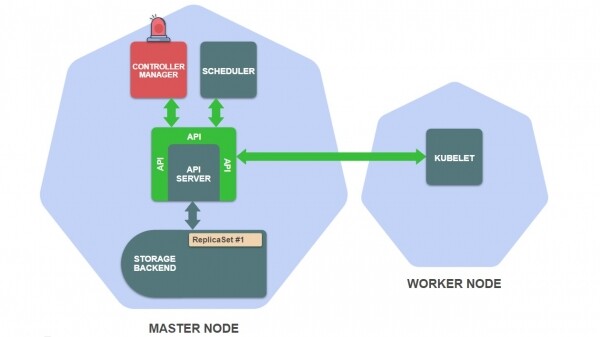
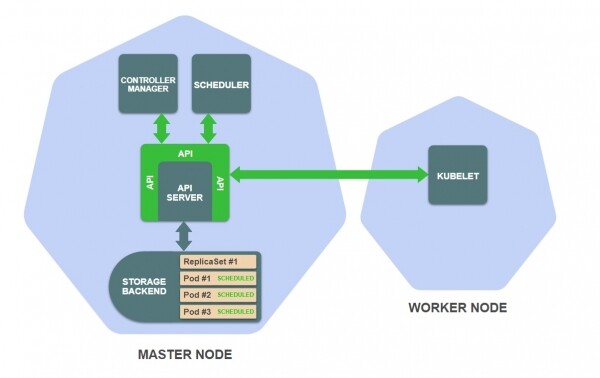
- Më pas, aktivizohet kontrolluesi i ReplicaSet në menaxherin e kontrolluesve, i cili merr përsipër krijimin, ndryshimin dhe fshirjen e burimeve të ReplicaSet:

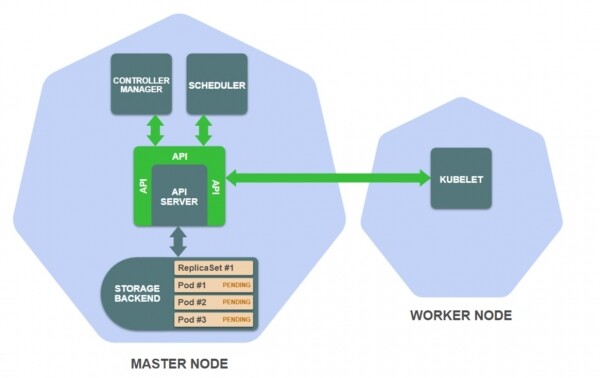
- Kontrolluesi i ReplicaSet krijon definicionin e pod-it për çdo kopje të ReplicaSet (përputhshëm me modelin e pod-it në definicionin e ReplicaSet) dhe i ruan ato në depo:

- Aktivizohet planifikuesi, i cili ndjek pod-et që ende nuk janë caktuar në asnjë nod pune:

- Planifikuesi zgjedh një nod të përshtatshëm pune për çdo pod dhe e shton këtë informacion në definicionin e pod-it në depo:
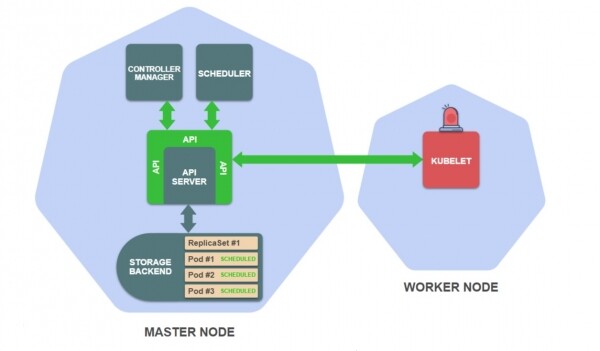
- Në nodin e punës, të cilit i është caktuar pod-i, aktivizohet Kubelet, i cili ndjek pod-et e caktuara në këtë nod:

- Kubelet lexon definicionin e pod-it nga depoja dhe jep komanda mjedisit të ekzekutimit të kontejnerëve, si p.sh. Docker, për të nisur kontejnerë në nod:

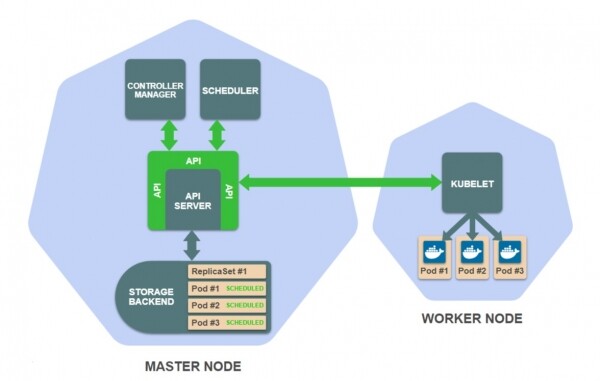
Më poshtë është varianti tekstual i këtij përshkrimi.
Kërkesa API për pikën e fundit të krijimit të ReplicaSet përpunoset nga serveri API. Serveri API autentifikon kërkesën dhe ruan definicionin e burimit ReplicaSet në depo.
Ky kyçje aktivizon kontrolluesin e ReplicaSet, i cili është një nënproces i menaxherit të kontrollit. Kontrolluesi i ReplicaSet ndjek krijimin, azhurnimin dhe fshirjen e burimeve të ReplicaSet në ruajtje dhe merr njoftim për ngjarjen kur ndodh kjo.
Detyra e kontrolluesit të ReplicaSet është të sigurojë që të ketë numrin e nevojshëm të pod-eve të ReplicaSet. Në shembulin tonë, për momentin nuk ka pod-e, kështu që kontrolluesi i ReplicaSet krijon këto përkufizime pod-i (në përputhje me modelin e pod-it në përcaktimin e ReplicaSet) dhe i ruan ato në ruajtje.
Krijimi i pod-eve të rinj nxit planifikuesin, që ndjek përkufizimet e pod-eve që ende nuk janë planifikuar për nodet punuese. Planifikuesi zgjidh një nod të përshtatshëm pune për secilin pod dhe azhurnon përkufizimet e pod-eve në ruajtje.
Vini re se deri në këtë pikë, askund në klaster nuk ka ekzekutuar kodin e ngarkesës së punës. E tërë ajo që është bërë deri tani, — është krijimi dhe azhurnimi i burimeve në ruajtje në nodin kryesor.
Ngjarja e fundit aktivizon Kubelet, e cila ndjek kontejnerët e programuar për nodet e saj të punës. Kubelet e nodës së punës, për të cilën janë vendosur kontejnerët tuaj të ReplicaSet, duhet t'i japë urdhër mjedisit të ekzekutimit të konteinerëve, si p.sh. Docker, për të shkarkuar imazhet e nevojshme të konteinerëve dhe për t'i nisur ato.
Në këtë moment, përfundimisht, aplikacioni juaj ReplicaSet është aktivizuar!
Roli i API-së Kubernetes
Siç e patë në shembullin e mëparshëm, komponentët e Kubernetes (përveç serverit API dhe magazinës) përcjellin ndryshimet në burimet në magazinë dhe ndryshojnë informacionin e burimeve në magazinë.
Sigurisht, këta komponentë nuk ndërveprojnë direkt me magazinën, vetëm përmes API-së së Kubernetes.
Le të shqyrtojmë shembujt e mëposhtëm:
- Kontrolluesi i ReplicaSet përdor pikën e fundit API me parametrin
watchpër të vëzhguar ndryshimet në burimet e ReplicaSet. - Kontrolluesi i ReplicaSet përdor pikën e fundit API (krijoni kontejner) për të krijuar kontejnerë.
- Planifikuesi përdor pikën e fundit API (ndrysho kontejner) për të azhurnuar kontejnerët me informacionin mbi nodën e punës të zgjedhur.
Siç e shihni, ky është e njëjta API, të cilës i referohet kubectl. Përdorimi i të njëjtës API për të ndihmuar komponentët e brendshëm dhe përdoruesit e jashtëm është një koncept themelor në dizajnin e Kubernetes.
Tani mund të përgjithësojmë se si funksionon Kubernetes:
- Depoja ruan gjendjen, domethënë burimet e Kubernetes.
- Serveri API ofron një ndërfaqe në depo në formën e API-së së Kubernetes.
- Të gjithë komponentët dhe përdoruesit e tjerë të Kubernetes lexojnë, monitorojnë dhe manipulojnë gjendjen (burimet) e Kubernetes përmes API-së.
Të kuptuarit e këtyre koncepteve do t'ju ndihmojë të kuptoni më mirë kubectl dhe ta përdorni atë në maksimum.
Tani le të shqyrtojmë një sërë këshillash dhe teknikash specifike që do të ndihmojnë në rritjen e produktivitetit me kubectl.
1. Rritja e shpejtësisë së inputit me ndihmën e plotësimit të komandave
Një nga teknikat më të dobishme, por shpesh të anashkaluara për të rritur produktivitetin me kubectl, është plotësimi i komandave.
Plotësimi i komandave lejon plotësimin automatik të pjesëve të veçanta të komandave kubectl me çelësin Tab. Kjo funksionon për nënkomandat, opsionet dhe argumentet, përfshirë ato komplekse si emrat e burimeve.
Shikoni se si funksionon shtesë e komandeve kubectl:

Shtesë e komandeve funksionon për shell-et Bash dhe Zsh.
përmban udhëzime të detajuara për konfigurimin e autocompletion-it, por më poshtë do të japim një përmbledhje të shkurtër.
Si funksionon shtesë e komandeve
Shtesë e komandeve është një funksion i shell-it që punon me një skenar shtese. Skripti i shtesës është një skenar i shell-it që përcakton sjelljen e shtesës për një komandë të veçantë.
Kubectl automatikisht gjeneron dhe nxjerr skenarët e shtesës për Bash dhe Zsh me komandat në vijim:
$ kubectl completion bashOse:
$ kubectl completion zshTeorikisht, mjafton të lidhni daljen e këtyre komandave në shell-in përkatës, në mënyrë që kubectl të mund të plotësojë komandat.
Në praktikë, mënyra e lidhjes ndryshon për Bash (duke përfshirë ndryshimet midis Linux dhe MacOS) dhe Zsh. Më poshtë do të shqyrtojmë të gjitha këto mundësi.
Bash në Linux
Skripti i shtesës për Bash varet nga paketa bash-completion, prandaj së pari duhet ta instaloni atë:
$ sudo apt-get install bash-completionOse:
$ yum install bash-completionMund ta testoni nëse paketa është instaluar me sukses duke përdorur komandën në vijim:
$ type _init_completion Nëse në këtë rast shfaqet kodi i funksionit të shell-it, atëherë bash-completion është instaluar siç duhet. Nëse komandën e jep një gabim 'Nuk u gjend', duhet të shtoni rreshtin e mëposhtëm në skedarin tuaj ~ / .bashrc:
$ burimi /usr/share/bash-completion/bash_completion Duhet të shtohet ky rresht në skedarin ~ / .bashrc apo jo, varet nga menaxheri i paketave që keni përdorur për të instaluar bash-completion. Për APT, kjo është e nevojshme, për YUM nuk është.
Pas instalimit të bash-completion, duhet të konfigurohet gjithçka që skripti i plotësimit të kubectl të përfshihet në të gjitha sesionet e shell-it.
Një mënyrë për ta bërë këtë është të shtoni rreshtin e mëposhtëm në skedarin ~ / .bashrc:
burim <(kubectl completion bash) Mënyra tjetër është të shtoni skriptin e plotësimit të kubectl në katalogun /etc/bash_completion.d (krijoni atë, nëse nuk ekziston):
$ kubectl completion bash >/etc/bash_completion.d/kubectl Të gjitha skriptet e plotësimit në katalog /etc/bash_completion.d aktualisht përfshihen në bash-completion.
Të dyja opsionet janë njësoj të aplikueshme.
Pas rinegjizimit të komandës së shell-it, autocompletion e komandave kubectl do të funksionojë.
Bash në MacOS
Në MacOS, konfigurimi është pak më i komplikuar. Kjo është për shkak se në MacOS nga default është Bash versioni 3.2, dhe skripti i autocompletion të kubectl kërkon një version Bash 4.1 ose më të lartë dhe nuk funksionon në Bash 3.2.
Përdorimi i një versioni të vjetër të Bash në MacOS lidhet me çështje licencimi. Versioni 4 i Bash shpërndahet nën licencën GPLv3, të cilën Apple nuk e mbështet.
Për të konfiguruar autocompletin e kubectl në MacOS, duhet të instaloni një version më të ri të Bash. Ju gjithashtu mund të vendosni Bash-në e përmirësuar si shellin e paracaktuar, e cila do t'ju kursejë shumë probleme në të ardhmen. Kjo nuk është e vështirë, detajet janë të dhëna në artikullin "».
Para se të vazhdoni, sigurohuni që po përdorni një version të fundit të Bash (kontrolloni daljen bash --version).
Skripta e autocompletit në Bash varet nga projekti , prandaj, së pari duhet ta instaloni atë.
Mund ta instaloni bash-completion përmes :
$ brew install bash-completion@2 Këtu @2 tregon bash-completion versioni 2. Autocompletimi i kubectl kërkon bash-completion v2, dhe bash-completion v2 kërkon versionin e Bash të paktën 4.1.
Dalja e komandës brew-install përmban seksionin Caveats, ku tregohet se duhet të shtoni në skedarin ~/.bash_profile:
export BASH_COMPLETION_COMPAT_DIR=/usr/local/etc/bash_completion.d
[[ -r "/usr/local/etc/profile.d/bash_completion.sh" ]] && .
"/usr/local/etc/profile.d/bash_completion.sh" Megjithatë, unë rekomandoj të shtoni këto rreshta jo në ~/.bash_profile, ndërsa në ~/.bashrc. Në këtë rast, autocompletion do të jetë i disponueshëm jo vetëm në shell-in kryesor, por edhe në nën-shell-et.
Pas rinisjes së shell-it, mund të kontrolloni saktësinë e instalimit duke përdorur komandën e mëposhtme:
$ type _init_completionNëse në daljen e komandës shihni një funksion shell, atëherë gjithçka është konfiguruar siç duhet.
Tani është e nevojshme që autocompletion për kubectl të aktivizohet në të gjitha seancat.
Një nga mënyrat është të shtoni rreshtin e mëposhtëm në ~/.bashrc:
burim <(kubectl completion bash) Mënyra e dytë është të shtoni skriptin e autocompletion në dosjen /usr/local/etc/bash_completion.d:
$ kubectl completion bash
/>/usr/local/etc/bash_completion.d/kubectlKjo mënyrë do të funksionojë vetëm nëse keni instaluar bash-completion me Homebrew. Në këtë rast, bash-completion ngarkon të gjitha skriptet nga kjo direktori.
Nëse keni instaluar , atëherë nuk është nevoja të kryeni hapin e mëparshëm, pasi skripti i autocompletion do të vendoset automatikisht në dosjen /usr/local/etc/bash_completion.d në momentin e instalimit. Në këtë rast, autocompletion për kubectl do të fillojë të funksionojë sapo të instaloni bash-completion.
Në përfundim, të gjitha këto opcione janë ekvivalentë.
Zsh
Skriptet e autocompletion për Zsh nuk kërkojnë asnjë varësi. E vetmja që duhet është t'i aktivizoni ato gjatë ngarkimit të shell-it.
Mund ta bëni këtë duke shtuar një rresht në ~/.zshrc fajl:
source <(kubectl completion zsh) Nëse morët një gabim not found: compdef pas rinisjes së shell-it tuaj, duhet të aktivizoni funksionin e ndërtuar compdef. Mund ta aktivizoni duke shtuar në fillim të fajlit tuaj ~/.zshrc këtë:
autoload -Uz compinit
compinit2. Shikoni specifikimet e burimeve
Kur krijoni definicionet e burimeve YAML, duhet të dini fushat dhe vlerat e tyre për këto burime. Një nga vendet për të kërkuar këtë informacion është në dokumentacionin e API, i cili përmban specifikime të plota për të gjithë burimet.
Megjithatë, ndërrimi në shfletuesin e uebit çdo herë që keni nevojë për të kërkuar diçka është e paprakët. Prandaj, kubectl ofron komandën kubectl shpjego, e cila tregon specifikimet e të gjitha burimeve drejtpërdrejt në terminalin tuaj.
Formati i komandës është si më poshtë:
$ kubectl explain resource[.field]...Komanda do të nxjerrë specifikimin e burimit ose fushës së kërkuar. Informacioni i nxjerrë është identik me atë që përmban udhëzimi i API.
Në mënyrë të paracaktuar kubectl shpjego tregon vetëm nivelin e parë të fushave të nxjerrjes.
Shikoni se si duket .
Mund të shfaqni të gjithë pemën nëse shtoni opsionin --recursive:
$ kubectl explain deployment.spec --recursiveNëse nuk e dini saktësisht se cilët burime ju nevojiten, mund t'i shihni të gjitha me komandën në vazhdim:
$ kubectl api-resources Kjo komandë shfaq emrat e burimeve në formën e shumësit, për shembull, dispozita në vend të deployment. Ajo gjithashtu shfaq emrin e shkurtër, për shembujt e atyre burimeve që e kanë. Mos u shqetësoni për këto dallime. Të gjitha këto variante emri janë ekuivalente për kubectl. Kështu që mund të përdorni cilin do prej tyre për deploy, для тех ресурсов, у которых оно есть. Не беспокойтесь об этих различиях. Все эти варианты имен эквивалентны для kubectl. То есть вы можете использовать любой из них для kubectl shpjego.
Të gjitha komandat e mëposhtme janë të barabarta:
$ kubectl explain deployments.spec
# ose
$ kubectl explain deployment.spec
# ose
$ kubectl explain deploy.spec3. Përdorni formatin e personalizuar të daljes së kolonave
Për default, formati i daljes së komandës kubectl get:
$ kubectl get pods
EMRI GATI STATUS RIFILLIMET MOSHAT
engine-544b6b6467-22qr6 1/1 Po punon 0 78d
engine-544b6b6467-lw5t8 1/1 Po punon 0 78d
engine-544b6b6467-tvgmg 1/1 Po punon 0 78d
web-ui-6db964458-8pdw4 1/1 Po punon 0 78dKy format është i përshtatshëm, por ai përmban një numër të kufizuar informacioni. Krahasuar me formatin e plotë të përcaktimit të burimit, këtu shfaqen vetëm disa fusha.
Në këtë rast, mund të përdorni formatin e personalizuar të daljes për kolonat. Ai lejon përcaktimin e të dhënave që do të shfaqen. Mund të shfaqni çdo fushë të burimit si një kolonë të veçantë.
Përdorimi i formatit të personalizuar përcaktohet nga opsionet:
-o custom-columns=:[,:]... Mund të përcaktoni çdo kolonë të daljes me një çift <jsonpath> — shprehja që përcakton fushën e burimit.
Le të shohim një shembull të thjeshtë:
$ kubectl get pods -o custom-columns='NAME:metadata.name'
NAME
engine-544b6b6467-22qr6
engine-544b6b6467-lw5t8
engine-544b6b6467-tvgmg
web-ui-6db964458-8pdw4Dalja përmban një kolonë me emrat e podeve.
Shprehja në opsion zgjedh emrat e podeve nga fusha metadata.name. Kjo për shkak se emri i podit përcaktohet në fushën fëmijë name të fushës metadata në përshkrimin e burimit të podit. Më shumë informacion mund të gjeni në ose mund të shkruani komandën kubectl explain pod.metadata.name.
Tani le të themi se dëshironi të shtoni një kolonë shtesë në dalje, për shembull, duke treguar nodin mbi të cilin punon çdo pod. Për këtë, thjesht mund të shtoni specifikimin përkatës të kolonës në opsionet e kolonave të personalizuara:
$ kubectl get pods
-o custom-columns='NAME:metadata.name,NODE:spec.nodeName'
EMRI NODE
engine-544b6b6467-22qr6 ip-10-0-80-67.ec2.internal
engine-544b6b6467-lw5t8 ip-10-0-36-80.ec2.internal
engine-544b6b6467-tvgmg ip-10-0-118-34.ec2.internal
web-ui-6db964458-8pdw4 ip-10-0-118-34.ec2.internal Shprehja zgjedh emrin e nodës nga spec.nodeName — kur një pod i caktohet një nodë, emri i saj shkruhet në fushën spec.nodeName e specifikimit të burimit të pod-it. Më shumë informacion mund të shihet në daljen kubectl explain pod.spec.nodeName.
Kruajeni se fushat e burimeve të Kubernetes janë të ndjeshme ndaj shkrimit.
Mund të shihni çdo fushë burimi në formën e një kolone. Thjesht shikoni specifikimin e burimit dhe provoni atë me çdo fushë që dëshironi.
Por së pari le të shqyrtojmë më në detaj shprehjet e zgjedhjes së fushave.
Shprehjet JSONPath
Shprehjet për zgjedhjen e fushave të burimeve bazohen në .
JSONPath është një gjuhë për nxjerrjen e të dhënave nga dokumentet JSON. Zgjedhja e një fushe është rastin më të thjeshtë të përdorimit të JSONPath. Ajo ka shumë , duke përfshirë selektorë, filtra dhe kështu me radhë.
Kubectl explain mbështet një numër të kufizuar mundësish JSONPath. Më poshtë janë përshkruar mundësitë dhe shembujt e përdorimit të tyre:
# Выбрать все элементы списка
$ kubectl get pods -o custom-columns='DATA:spec.containers[*].image'
# Выбрать специфический элемент списка
$ kubectl get pods -o custom-columns='DATA:spec.containers[0].image'
# Выбрать элементы списка, попадающие под фильтр
$ kubectl get pods -o custom-columns='DATA:spec.containers[?(@.image!="nginx")].image'
# Выбрать все поля по указанному пути, независимо от их имени
$ kubectl get pods -o custom-columns='DATA:metadata.*'
# Выбрать все поля с указанным именем, вне зависимости от их расположения
$ kubectl get pods -o custom-columns='DATA:..image'Operatori [] ka një rëndësi të veçantë. Shumica e fushave të burimeve Kubernetes janë lista, dhe ky operator lejon zgjedhjen e elementeve të këtyre listave. Ai përdoret shpesh me një wildcard si [*] për të zgjedhur të gjitha elementet e listës.
Shembuj të aplikimit
Mundësitë e përdorimit të formatit të daljes së kolonave të personalizuara janë të pakufizuara, pasi mund të shfaqni çfarëdo fushe ose kombinim fushash të burimit në dalje. Ja disa shembuj aplikimesh, por mos ngurroni të eksploroni dhe të gjeni aplikime të dobishme për ju.
- Shfaqja e imazheve të kontejnerëve për pod-at:
$ kubectl get pods -o custom-columns='NAME:metadata.name,IMAGES:spec.containers[*].image' NAME IMAGES engine-544b6b6467-22qr6 rabbitmq:3.7.8-management,nginx engine-544b6b6467-lw5t8 rabbitmq:3.7.8-management,nginx engine-544b6b6467-tvgmg rabbitmq:3.7.8-management,nginx web-ui-6db964458-8pdw4 wordpressKjo komandë shfaq emrat e imazheve të kontejnerëve për çdo pod.
Mbani mend se një pod mund të përmbajë disa kontejnerë, kështu që emrat e imazheve do të nxirren në një rresht, të ndarë me presje.
- Shfaqja e zonave të disponueshmërisë së nyjeve:
$ kubectl get nodes -o custom-columns='NAME:metadata.name,ZONE:metadata.labels.failure-domain.beta.kubernetes.io/zone' NAME ZONE ip-10-0-118-34.ec2.internal us-east-1b ip-10-0-36-80.ec2.internal us-east-1a ip-10-0-80-67.ec2.internal us-east-1bKy komandë është e dobishme nëse klustëri juaj është i vendosur në një cloud publik. Ajo tregon zonën e disponueshmërisë për çdo nod.
Zona e disponueshmërisë është një koncept cloud, që kufizon zonën e replikimit në një rajon gjeografik.
Zonat e disponueshmërisë për çdo nod merren përmes një etikete të veçantë — . Nëse klustëri është aktivizuar në një cloud publik, kjo etiketë krijohet automatikisht dhe plotësohet me emrat e zonave të disponueshmërisë për çdo nod.
Etiketat nuk janë pjesë e specifikimit të burimeve Kubernetes, kështu që nuk do të gjeni informacione për to në . Megjithatë, ato mund të shihen (ashtu si çdo etiketë tjetër) nëse kërkoni informacion mbi nodet në formatin YAML ose JSON:
$ kubectl get nodes -o yaml # ose $ kubectl get nodes -o jsonKy është një mënyrë e shkëlqyer për të mësuar më shumë rreth burimeve, përveç studimit të specifikimeve të burimeve.
4. Kalimi i lehtë midis klastrave dhe hapësirave të emrave
Kur kubectl bën një kërkesë në Kubernetes API, ai lexon skedarin kubeconfig për të marrë të gjitha parametrat e nevojshme për lidhjen.
Për default, skedari kubeconfig është ~/.kube/config. Në përgjithësi, ky skedar krijohet ose përditësohet me një komandë të veçantë.
Kur punoni me disa klasterë, skedari juaj kubeconfig përmban parametrat e lidhjes për të gjithë këta klasterë. Ju nevojitet një mënyrë për t'i treguar komandës kubectl se me cilin klaster po punoni.
Brenda klasterit mund të krijoni disa hapësira emri — një lloj klasteri virtual brenda klasterit fizik. Kubectl përcakton se cila hapësirë emri të përdorë gjithashtu në bazë të të dhënave nga skedari kubeconfig. Pra, ju nevojitet gjithashtu një mënyrë për t'i treguar komandës kubectl se me cilin hapësirë emri po punoni.
Në këtë kapitull do t'ju tregojmë se si funksionon dhe si ta arrini një punë efektive.
Kujdes, mund të keni disa skedarë kubeconfig të listuar në variablin e mjedisit KUBECONFIG. Në këtë rast, të gjithë këta skedarë do të bashkohen në një konfigurim të përgjithshëm gjatë ekzekutimit. Mund të ndryshoni gjithashtu skedarin kubeconfig të aplikuar si parazgjedhje duke e ekzekutuar kubectl me parametër --kubeconfig. Shikoni .
Skedar kubeconfig
Le të shohim se çfarë përmban skedari kubeconfig:
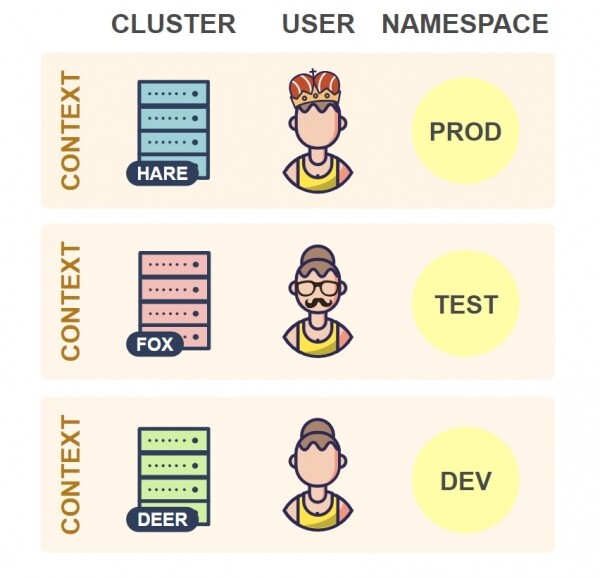
Siç e shihni, skedari kubeconfig përmban një grup kontekstesh. Një kontekst përbëhet nga tre elemente:
- Cluster — URL e API-së së serverit të klasterit.
- User — akreditetet e autentifikimit të përdoruesit në klaster.
- Namespace — hapësira e emrave e përdorur gjatë lidhjes me klasterin.
Në praktikë, zakonisht përdoret një kontekst për klaster në skedarin tuaj kubeconfig. Megjithatë, mund të keni disa kontekste për klaster, që ndryshojnë sipas përdoruesit ose hapësirës së emrave. Megjithatë, një konfigurim me disa kontekste është jo i zakonshëm, prandaj zakonisht ka një përputhje të qartë midis klasterëve dhe konteksteve.
Në çdo moment, një nga kontekstet është aktual:
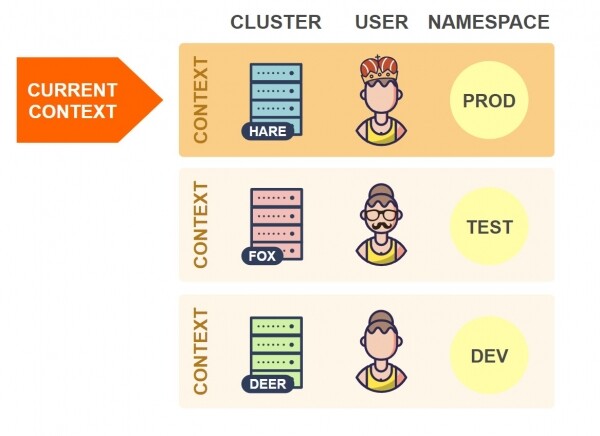
Kur kubectl lexon skedarin e konfigurimit, gjithmonë merret informacioni nga konteksti aktual. Në shembullin e mësipërm, kubectl do të lidhë me klasterin Hare.
Prandaj, për t'u kaluar në një klaster tjetër, duhet të ndryshoni kontekstin aktual në skedarin kubeconfig:
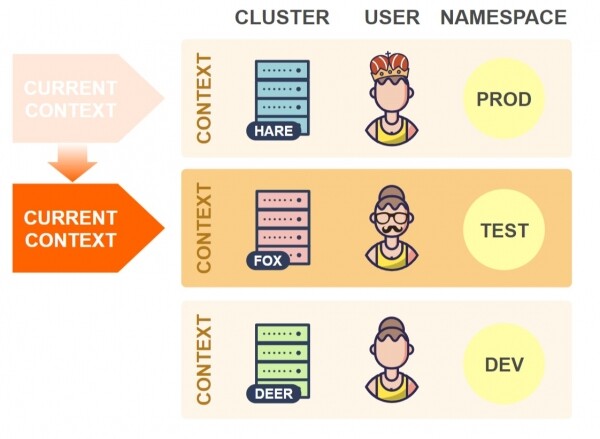
Tani kubectl do të lidhë me klasterin Fox.
Për të kaluar në një hapësirë tjetër emri në të njëjtin klaster, duhet të ndryshoni vlerën e elementit namespace për kontekstin aktual:
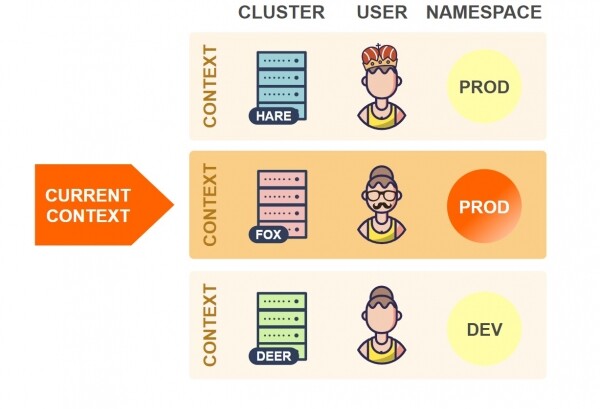
Në shembullin e mësipërm, kubectl do të përdorë hapësirën emri Prod të klasterit Fox (më parë ishte vendosur hapësira emri Test).
Merrni parasysh se kubectl gjithashtu ofron opsione --cluster, --user, --namespace dhe --context, të cilat lejojnë përmbysjen e elementeve të veçanta dhe të vetë kontekstit aktual, pavarësisht nga ato që janë vendosur në skedarin kubeconfig. Shihni opsionet kubectl.
Teorikisht, mund të ndryshoni manualisht parametrat në skedarin kubeconfig. Por kjo është e pakëndshme. Për të lehtësuar këto operacione, ekzistojnë një gamë e shërbimeve që lejojnë ndryshimin e parametrave në mënyrë automatike.
Përdorni kubectx
Një utilitar shumë i njohur për kalimin mes klasterëve dhe hapësirave emri.
Utilitari ofron komandat kubectx dhe kubens për të ndryshuar kontekstin dhe hapësirën emri aktualisht.
Siç u përmend, ndryshimi i kontekstit aktual do të thotë ndryshimi i klasterit, nëse keni vetëm një kontekst për klaster.
Ja një shembull i ekzekutimit të këtyre komandave:

Në thelb, këto komanda thjesht editojnë skedarin kubeconfig, siç u përshkrua më sipër.
Për të instaluar kubectx, ndiqni udhëzimet në
Të dy komandat mbështesin plotësimin automatik të emrave të konteksteve dhe hapësirave të emrave, duke lejuar që të mos i shkruani ato plotësisht. Udhëzimet për konfigurimin e plotësimit automatik .
Një funksion tjetër të dobishëm kubectx është . Ai funksionon në bashkëpunim me utilitarin , i cili duhet të instalohet veçmas. Instalimi i fzf e bën automatikisht të disponueshëm modin interaktiv në kubectx. Në modin interaktiv, mund të zgjidhni kontekstin dhe hapësirën e emrave përmes një ndërfaqe interaktive të kërkimit të lirë, të ofruar nga fzf.
Përdorimi i aliasave të komandës
Nuk keni nevojë për mjete të veçanta për të ndryshuar kontekstin dhe hapësirën e emrave aktuale, sepse kubectl gjithashtu ofron komanda për këtë. Pra, komanda kubectl config ofron nënkomanda për të redaktuar skedarët kubeconfig.
Ja disa prej tyre:
kubectl config get-contexts: shfaq të gjitha kontekstet;kubectl config current-context: merr kontekstin aktual;kubectl config use-context: ndrysho kontekstin aktual;kubectl config set-context: ndrysho elementin e kontekstit.
Megjithatë, përdorimi i këtyre komandave drejtpërdrejt nuk është shumë i përshtatshëm, sepse janë të gjata. Mund të krijoni alias për komandën që janë më të lehta për t'u ekzekutuar.
Kam krijuar një grup aliasesh bazuar në këto komanda, të cilat ofrojnë funksionalitet të ngjashëm me kubectx. Këtu mund të shihni veprimin e tyre:

Kujdes, aliaset përdorin fzf për të ofruar një ndërfaqe interaktive për kërkimin e lirë (si në mënyrën interaktive të kubectx). Kjo do të thotë se duhet , për të përdorur këto alias.
Këtu janë vetë përkufizimet e aliasëve:
# Получить текущий контекст
alias krc='kubectl config current-context'
# Список всех контекстов
alias klc='kubectl config get-contexts -o name | sed "s/^/ /;|^ $(krc)$|s/ /*/"'
# Изменить текущий контекст
alias kcc='kubectl config use-context "$(klc | fzf -e | sed "s/^..//")"'
# Получить текущее пространство имен
alias krn='kubectl config get-contexts --no-headers "$(krc)" | awk "{print $5}" | sed "s/^$/default/"'
# Список всех пространств имен
alias kln='kubectl get -o name ns | sed "s|^.*/| |;|^ $(krn)$|s/ /*/"'
# Изменить текущее пространство имен
alias kcn='kubectl config set-context --current --namespace "$(kln | fzf -e | sed "s/^..//")"' Për të instaluar këto alias, duhet të shtoni përkufizimet e mësipërme në skedarin tuaj ~/.bashrc ose ~/.zshrc dhe të rivendosni komandën tuaj.
Përdorimi i mjeteve shtesë
Kubectl lejon ngarkimin e mjeteve shtesë që ekzekutohen ashtu si komandat kryesore. Për shembull, mund të instaloni mjetin shtesë kubectl-foo dhe ta ekzekutoni duke përdorur komandën kubectl foo.
Do të ishte e përshtatshme të ndryshoni kontekstin dhe hapësirën e emrave në këtë mënyrë, për shembull, të ekzekutoni kubectl ctx për të ndërruar kontekstin dhe kubectl ns për të ndërruar hapësirën e emrave.
Kam shkruar dy mjete shtesë që bëjnë këtë:
Puna e plugjve bazohet në aliaset nga seksioni i mëparshëm.
Ja si funksionojnë:

Kujdes, plugjve përdorin fzf për të ofruar një ndërfaqe interaktive kërkimi të lirë (si në modin interaktiv kubectx). Kjo do të thotë se duhet, për të përdorur këto alias.
Për të instaluar plugjve, duhet të ngarkoni skripte shell me emra dhe në çdo katalog në variablin tuaj PATH dhe t'i bëni ata ekzekutues, për shembull, duke përdorur chmod +x. Menjëherë pas kësaj, do të jeni në gjendje të përdorni kubectl ctx dhe kubectl ns.
5. Shkurtimi i hyrjes me auto-aliaset
Aliaset e komandës së shell-it janë një mundësi e shkëlqyer për të përshpejtuar hyrjen. Projekti përmban rreth 800 shkurtime për komandat kryesore kubectl.
Mund të habiteni — si t'i mbani mend 800 aliaset? Por nuk keni nevojë t'i mbani mend të gjitha, sepse ato ndërtohen sipas një skeme të thjeshtë, e cila është e paraqitur më poshtë:

Për shembull:
- kgpooyaml — kubectl get pods oyaml
- ksysgsvcw — kubectl -n kube-system get svc w
- ksysrmcm — kubectl -n kube-system rm cm
- kgdepallsl — kubectl get deployment all sl
Siç e shihni, aliaset përbëhen nga komponentë, secili prej të cilëve përfaqëson një element të caktuar të komandës kubectl. Çdo alias mund të ketë një komponent për komandën bazë, veprimin dhe burimin dhe disa komponentë për parametrat. Ju thjesht 'plotësoni' këta komponentë nga majta në djathtë sipas skemës së mësipërme.
Skema e përditësuar detajale është në . Atje mund të gjeni gjithashtu.
Për shembull, aliasi kgpooyamlall është i barabartë me komandën kubectl get pods -o yaml --all-namespaces.
Rendi relativ i opsioneve nuk ka rëndësi: komanda kgpooyamlall është ekuivalente me komandën kgpoalloyaml.
Mund të mos përdorni të gjithë komponentët si aliasë. Për shembull k, kg, klo, ksys, kgpo mund të përdoren gjithashtu. Gjithashtu, në linjën e komandës mund të kombinoni aliasët dhe komandat ose opsionet e zakonshme:
Për shembull:
- Në vend të
kubectl proxymund të shkruhetk proxy. - Në vend të
kubectl get rolesmund të shkruhetkg roles(aktualisht nuk ka një alias për burimin Roles). - Për të marrë të dhënat për një pod të caktuar, mund të përdorni komandën
kgpo my-pod — kubectl get pod my-pod.
Kujtoni se disa alias kërkojnë argument në linjën e komandës. Për shembull, aliasi kgpol do të thotë kubectl get pods -l. Opcioni -l kërkon një argument — specifikimin e etiketës. Nëse përdorni një alias, do të duket si kgpol app=ui.
Për shkak se disa alias kërkojnë argumente, aliaset a, f dhe l duhet të përdoren në fund.
Në përgjithësi, sapo të zotëroni këtë skemë, do të jeni në gjendje të nxirrni intuitivisht aliaset nga komandat që dëshironi të ekzekutoni dhe të kurseni shumë kohë në shtypjen e tyre.
Instalimi
Për të instaluar kubectl-aliases, duhet të shkarkoni skedarin nga GitHub dhe ta përfshini në skedarin ~/.bashrc ose ~/.zshrc:
source ~/.kubectl_aliasesPlotësimi automatik
Siç kemi thënë më parë, shpesh shtoni fjalë shtesë në alias në linjën e komandës. Për shembull:
$ kgpooyaml test-pod-d4b77b989Nëse përdorni plotësimin automatik të komandës kubectl, është e mundshme që keni përdorur plotësimin automatik për gjëra si emrat e burimeve. Por, a është e mundur të bëni këtë kur përdoren aliaset?
Ky është një pyetje shumë e rëndësishme, sepse, nëse plotësimi automatik nuk funksionon, do të humbni një pjesë të përfitimeve nga aliaset.
Përgjigjja varet nga cila shell komandash po përdorni:
- Për Zsh, plotësimi automatik për aliaset funksionon 'nga kutia'.
- Për Bash, fatkeqësisht, disa veprime janë të nevojshme për të bërë që plotësimi automatik të punojë.
Aktivizimi i autocompletimit për aliaset në Bash
Problemi me Bash është se ai përpiqet të plotësojë (sa herë që klikoni Tab) aliasin, në vend të komandës që aliasi referon (siç bën Zsh). Duke pasur parasysh që nuk keni skripta plotësimi për të gjitha 800 aliaset, autocompletimi nuk funksionon.
Projekt ofron një zgjidhje gjithëpërfshirëse për këtë problem. Ai lidhet me mekanizmin e plotësimit për aliaset, brenda plotëson aliasin në komandë dhe kthen opsionet e plotësimit për komandën e plotësuar. Kjo do të thotë se plotësimi për aliasin sillet në të njëjtën mënyrë si për komandën e plotë.
Më pas do të shpjegoj së pari se si të instaloni complete-alias, dhe më pas si ta konfiguroni për të aktivizuar plotësimin për të gjitha aliaset kubectl.
Instalimi i complete-alias
Së pari, complete-alias kërkon . Prandaj, para se të instaloni complete-alias, duhet të siguroheni që bash-completion është instaluar. Udhëzimet për instalim janë dhënë më parë për Linux dhe MacOS.
Shënim i rëndësishëm për përdoruesit e MacOS: si skripti i autocompletimit kubectl, complete-alias nuk funksionon me Bash 3.2, i cili përdoret si parazgjedhje në MacOS. Në veçanti, complete-alias kërkon bash-completion v2 (brew install bash-completion@2), për të cilin kërkohet të paktën Bash 4.1. Kjo do të thotë se për të përdorur complete-alias në MacOS ju duhet të instaloni një version më të ri të Bash.
Ju nevojitet të shkarkoni skenarin nga dhe ta përfshini atë në skedarin tuaj ~/.bashrc:
source ~/bash_completion.shPasi të rikthehet terminali, complete-alias do të jetë instaluar plotësisht.
Aktivizimi i autofunksionim për aliaset kubectl
Në teknikë, complete-alias ofron funksionalitetin e shell-it _complete_alias. Ky funksion kontrollon aliasin dhe kthen sugjerime për autofunksionimin e komandës së aliasit.
Për të lidhur funksionin me një alias të caktuar, duhet të përdorni mekanizmin e integruar të Bash , për të vendosur _complete_alias si funksionin e autofunksionimit të aliasit.
Si shembull, le të marrim aliasin k, që përfaqëson komandën kubectl. Për të vendosur _complete_alias si funksionin e autofunksionimit për këtë alias, ju duhet të ekzekutoni komandën e mëposhtme:
$ complete -F _complete_alias k Rezultati i kësaj është se sa herë që të vendosni autofunksionimin për aliasin k, thirret funksioni _complete_alias, i cili kontrollon aliasin dhe kthen sugjerime për autofunksionimin e komandës kubectl.
Si një shembull të dytë, le të marrim aliasin kg, i cili përfaqëson kubectl get:
$ përfundimi -F _complete_alias kg Ashtu si në shembullin e mëparshëm, kur plotësoni automatikisht kg, merrni po ato sugjerime, që do të merrnit për kubectl get.
Vini re se mund të përdorni complete-alias për çdo alias në sistemin tuaj.
Prandaj, për të përfshirë plotësimin automatik për të gjitha aliaset e kubectl, duhet të ekzekutoni komandën e mësipërme për secilën prej tyre. Fragmenti i mëposhtëm bën këtë, nëse keni instaluar kubectl-aliases në ~/.kubectl-aliases:
për _a në $(sed '/^alias /!d;s/^alias //;s/=.*$//' ~/.kubectl_aliases);
do
complete -F _complete_alias "$_a"
done Ky copë kod duhet të vendoset në ~/.bashrc, të rindezësh shell-in dhe plotësimi automatik do të jetë në dispozicion për të gjithë 800 aliaset kubectl.
6. Zgjerimi i kubectl përmes tingujve
Duke filluar nga , kubectl mbështet , i cili lejon zgjerimin e funksioneve të tij me komanda shtesë.
Nëse jeni të njohur me , atëherë tingujt e kubectl janë ndërtuar në të njëjtin parim.
Në këtë kapitull ne do të tregojmë se si të instaloni tinguj, ku t'i kërkoni dhe si të krijoni tinguj tuaj.
Instalimi i tingujve
Plugins kubectl shpërndahen si skedarë ekzekutivë të thjeshtë me emrin e formatit kubectl-x. Prefiksi kubectl- është e domosdoshme, që më pas pason një komandë të re kubectl që lejon thirrjen e plugin-it.
Për shembull, plugin-i hello do të shpërndahet si skedari me emrin kubectl-hello.
Për të instaluar plugin-in, duhet ta kopjoni skedarin kubectl-x në çdo katalog në variablin tuaj PATH dhe ta bëni ekzekutiv, për shembull me chmod +x. Menjëherë pas kësaj, mund të thirrni plugin-in duke përdorur kubectl x.
Mund të përdorni komandën e mëposhtme për të dalë në listën e të gjithë plugin-ëve që aktualisht janë të instaluar në sistemin tuaj:
$ kubectl plugin listKjo komandë gjithashtu tregon paralajmërime nëse keni disa plugin-e me emra të njëjtë, ose nëse ka një skedar plugin-ësh që nuk është ekzekutiv.
Kërkimi dhe instalimi i plugin-eve përmes Krew
Plugin-et Kubectl janë të përshtatshme për përdorim të përbashkët ose përsëritës si paketat softuerike. Por ku mund të gjeni plugin-et që kanë ndarë të tjerët?
është i orientuar në ofrimin e një zgjidhjeje të unifikuar për ndarjen, kërkimin, instalimin dhe menaxhimin e moduleve kubectl. Projekti e quan veten "menaxherin e pakove për modulet kubectl" (Krew është si ).
Krew është një listë e moduleve kubectl që mund të zgjidhni dhe instaloni. Në të njëjtën kohë, Krew është gjithashtu një modul për kubectl.
Kjo do të thotë se instalimi i Krew funksionon në thelb si instalimi i çdo moduli tjetër kubectl. Mund të gjeni udhëzime të detajuara në .
Komandat më të rëndësishme Krew:
# Поиск в списке плагинов
$ kubectl krew search [<query>]
# Посмотреть информацию о плагине
$ kubectl krew info <plugin>
# Установить плагин
$ kubectl krew install <plugin>
# Обновить все плагины до последней версии
$ kubectl krew upgrade
# Посмотреть все плагины, установленные через Krew
$ kubectl krew list
# Деинсталлировать плагин
$ kubectl krew remove <plugin>Kujtoni se instalimi i moduleve përmes Krew nuk pengon instalimin e moduleve në mënyrën standarde siç përshkruhet më sipër.
Vini re se komanda kubectl krew list tregon vetëm ato module që janë instaluar me Krew, ndryshe nga komanda kubectl plugin list e cila rendit të gjitha modulet, pra ato që janë instaluar me Krew dhe ato që janë instaluar në mënyra të tjera.
Kërkimi i moduleve në vende të tjera
Krew është një projekt i ri, aktualisht në listën e tij Nëse nuk mund të gjeni atë që ju nevojitet, mund të gjeni module në vende të tjera, për shembull në GitHub.
Unë rekomandoj të shikoni seksionin GitHub . Aty do të gjeni disa dhjetëra plugins të disponueshëm që meritojnë të shihen.
Shkruani plugins tuaj
Ju mund të — nuk është e vështirë. Ju nevojitet të krijoni një skedar ekzekutiv që bën atë që nevojitet, ta emërtoni si kubectl-x dhe ta instaloni, siç ishte përshkruar më lart.
Skedari mund të jetë një skript bash, një skript python, ose një aplikacion i përpunuar go — kjo nuk ka rëndësi. Kushti i vetëm është që të mund të ekzekutohet drejtpërdrejt në sistemin operativ.
Le të krijojmë një shembull plugin tani. Në seksionin e mëparshëm keni përdorur komandën kubectl për të shfaqur listën e kontejnerëve për çdo pod. Mund ta kthejmë lehtësisht këtë komandë në një plugin që mund ta thërrisni, për shembull me kubectl img.
Krijoni një skedar kubectl-img përmbajtja e mëposhtme:
#!/bin/bash
kubectl get pods -o custom-columns='NAME:metadata.name,IMAGES:spec.containers[*].image' Tani bëni skedarin ekzekutiv me chmod +x kubectl-img dhe transferoni atë në çdo katalog në PATH tuaj. Menjëherë pas kësaj mund të përdorni plugin-in kubectl img.
Si e përmenda më parë, pluginet kubectl mund të shkruhen në çdo gjuhëprogramimi ose skriptimi. Nëse po përdorni skripte të komandës, përfitimi është se mund të thirrni lehtësisht kubectl nga plugini. Megjithatë, mund të shkruani plugina më të komplikuara në gjuhëprogramimi reale, duke përdorur . Nëse po përdorni Go, mund të përdorni gjithashtu , e cila ekziston veçanërisht për shkruarjen e pluginëve kubectl.
Si të ndani pluginët tuaj
Nëse mendoni se pluginët tuaj mund të jenë të dobishëm për të tjerët, mos ngurroni të ndani ata në GitHub. Sigurohuni që t'i shtoni ata në temën .
Mund të kërkoni gjithashtu që pluginët tuaj të shtohen në . Udhëzimet se si ta bëni këtë janë në .
Autocompletimi i komandave
Aktualisht, pluginët nuk mbështesin autocompletimin. Pra, duhet të shkruani emrin e plotë të pluginit dhe emrat e plotë të argumenteve.
Në repo GitHub kubectl për këtë funksion ka . Kështu, është e mundur që ky funksion të realizohet ndonjëherë në të ardhmen.
Suksese!!!
Çfarë tjetër të lexoni në këtë temë:
- .
- .
- .
Burimi: habr.com
