

Performanca e lartë është një nga kërkesat kryesore kur punojmë me të dhëna të mëdha. Ne në menaxhimin e ngarkesave të të dhënave në Sber punojmë për të rritur pothuajse të gjitha transaksionet në Cloudin Ton të Dhënave që bazohet në Hadoop dhe prandaj merremi me flukse të vërteta të mëdha informacioni. Natyrisht, ne gjithmonë jemi duke kërkuar mënyra për të përmirësuar performancën, dhe tani dëshirojmë të flasim se si arritëm të patch-ojmë RegionServer HBase dhe klientin HDFS, duke arritur kështu një rritje të konsiderueshme të shpejtësisë së operacioneve të leximit.
Megjithatë, përpara se të kalojmë në thelb të përmirësimeve, është e nevojshme të diskutojmë rreth kufizimeve, të cilat në thelb është e pamundur t'i shmangesh, nëse mbetesh me HDD.
Pse HDD dhe leximet e shpejta Random Access janë të papajtueshme
Siç dihet, HBase dhe shumë baze të tjera të dhënash ruajnë të dhënat në blloqe, me përmasa disa dhjetëra kilobajtë. Sipas parametrave default, kjo është rreth 64 KB. Tani imagjinoni se na nevojitet të nxjerrim vetëm 100 byte dhe kërkojmë nga HBase që të na japë këto të dhëna sipas një çelësi të caktuar. Duke qenë se madhësia e bllokut në HFiles është 64 KB, atëherë kërkesa do të jetë 640 herë më shumë (për një çast!) se sa na nevojitet.
Më pas, pasi kërkesa do kalojë përmes HDFS dhe mekanizmit të tij të memorizimit të të dhënave. ShortCircuitCache (që lejon aksesin direkt në skedarët), kjo shkakton leximin e vetëm 1 MB nga disku. Megjithatë, kjo mund të rregullohet përmes parametrave dfs.client.read.shortcircuit.buffer.size dhe në shumë raste ka kuptim ta zvogëlojmë këtë vlerë, për shembull deri në 126 KB.
Le të themi se ne e bëjmë këtë, por gjithashtu, kur fillojmë të lexojmë të dhënat përmes java api, funksione si FileChannel.read dhe kërkojmë nga sistemi operativ që të lexojë sasinë e caktuar të të dhënave, ai lexon "për çdo rast" dyfish më shumë, dmth në 256 KB në rastin tonë. Kjo ndodh sepse në java nuk ka një mundësi të thjeshtë për të vendosur flamurin FADV_RANDOM, që parandalon këtë sjellje.
Në përfundim, për të marrë 100 bajt, pas kulisave lexohen 2600 herë më shumë. Duket se zgjidhja është e qartë, le të zvogëlojmë madhësinë e bllokut në një kilobajt, të vendosim flamurin e përmendur dhe të arrijmë ndriçimin e madh të përshpejtimit. Por problemi është se, duke zvogëluar madhësinë e bllokut me 2 herë, ne gjithashtu zvogëlojmë numrin e bajtëve të lexuar në një njësi kohe po ashtu me 2 herë.
Disa një fitim nga vënia në dukje e flamurit FADV_RANDOM mund të arrihet, por vetëm në rast të multithreading të lartë dhe me një madhësi blloku prej 128 Kb, megjithatë, kjo është maksimumi i disa dhjetëra përqindësh.

Testet u kryen në 100 skedarë, secili me madhësinë prej 1 Gb dhe të vendosur në 10 disqe HDD.
Le të llogarisim se për çfarë mund të presim në këtë shpejtësi:
Supozoni se lexojmë nga 10 disqe me shpejtësinë 280 MB/sec, pra 3 milion herë nga 100 bite. Por siç e dimë, të dhënat që na duhen janë 2600 herë më të pakta se sa ato që janë lexuar. Prandaj 3 milion i ndajmë me 2600 dhe marrim 1100 regjistrime në sekondë.
Shpresëdhënëse, apo jo? Kjo është natyra Accessit të Rastësishëm të të dhënave në HDD — pavarësisht nga madhësia e bllokut. Kjo është një kufi fizik i aksesit rastësor dhe asnjë DB nuk mund të nxjerrë më shumë në këto kushte.
Si arrijnë atëherë bazat e të dhënave të arrijnë shpejtësi shumë më të larta? Për të përgjigjur në këtë pyetje, le të shohim se çfarë ndodh në figurën e ardhshme:
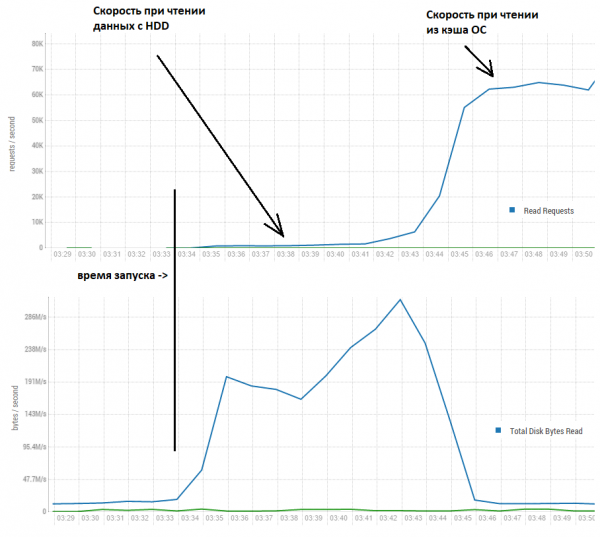
Këtu shohim se disa minuta të para shpejtësia është vërtet rreth një mijë regjistrimesh për sekondë. Megjithatë më pas, falë faktit se lexohen shumë më tepër sesa kërkohet, të dhënat vendosen në buff/cache të sistemit operativ (linux) dhe shpejtësia rritet deri në 60,000 për sekondë, që është më e pranueshme.
Kështu që më pas ne do të merremi me përshpejtimin e aksesit vetëm në ato të dhëna që janë në cache të OS-së ose ndodhen në depozita me shpejtësi të ngjashme me SSD/NVMe.
Në rastin tonë, ne do të kryejmë teste në një stand prej 4 serverësh, secili prej të cilëve është i ngarkuar si më poshtë:
CPU: Xeon E5-2680 v4 @ 2.40GHz 64 threads.
Memoria: 730 GB.
java version: 1.8.0_111
Dhe këtu, pikërisht, është momenti kyç — vëllimi i të dhënave në tabela që duhet të lexohen. E vërteta është se nëse lexohet të dhëna nga një tabelë që ngjitet krejtësisht në cache të HBase, atëherë procedura s’ka për të arritur në leximin nga buff/cache të operacionit. Sepse HBase në mënyrë të paracaktuar ndan 40% të memories për një strukturë të quajtur BlockCache. Në thelb, kjo është një ConcurrentHashMap, ku çelësi është emri i skedarit + offset i bllokut, ndërsa vlera përkatëse janë të dhënat për këtë offset.
Kështu, kur leximi bëhet vetëm nga kjo strukturë, ne , dukë si miliona kërkesa në sekondë. Por le të imagjinojmë se nuk mund të ndajmë qindra gigabajt memorie vetëm për nevojat e DB-së, sepse në këto serverë funksionon shumë gjëra të tjera të dobishme.
Për shembull, në rastin tonë, sasia e BlockCache në një RS është rreth 12 GB. Ne kemi vendosur dy RS në një nodë, pra nën BlockCache janë rezervuar 96 GB në të gjitha nodet. Ndërsa të dhënat janë shumë më të mëdha, për shembull, le të themi se janë 4 tabela, për 130 rajone, ku skedarët janë me përmasat 800 MB, të kompresuar me FAST_DIFF, pra në total 410 GB (kjo është vetëm të dhëna, pa marrë parasysh faktorë të replikimit).
Kështu, BlockCache përbën vetëm rreth 23% të gjithsej të dhënave dhe kjo është shumë më afër kushteve reale të asaj që quhet BigData. Dhe këtu fillon pjesa më interesante — sepse është e qartë, sa më pak goditje në cache, aq më keq është performanca. Sepse në rastin e një humbjeje do të duhet të kryejmë shumë punë — pra, të zbresim te thirrjet e funksioneve sistemore. Megjithatë, kjo nuk mund të shmanget dhe prandaj le të shqyrtojmë një aspekt tjetër — çfarë ndodh me të dhënat brenda cache-it?
Lehtësojmë situatën dhe le të supozojmë se kemi një cache që pranon vetëm 1 objekt. Ja një shembull se çfarë do ndodhte kur të përpiqemi të punojmë me një volum të dhënash që është 3 herë më i madh se cache, na duhet të:
1. Vendosni bllokun 1 në cache
2. Hiqni bllokun 1 nga cache
3. Vendosni bllokun 2 në cache
4. Hiqni bllokun 2 nga cache
5. Vendosni bllokun 3 në cache
Këto janë bërë 5 veprime! Megjithatë, nuk mund ta quajmë këtë situatë normale; për faktin se po e detyrojmë HBase të bëjë një sasi të madhe pune krejt të panevojshme. Ai vazhdimisht lexon të dhënat nga cache i sistemit operativ, i vendos ato në BlockCache, për t'i hequr thuajse menjëherë, sepse ka ardhur një grumbull i ri të dhënash. Animacioni në fillim të postimit tregon thelbin e problemit — Garbage Collector është në kulmin e tij, atmosfera ngrohet, Greta e vogël në Suedinë e largët dhe të nxehtë është e shqetësuar. Ne, IT-istët, nuk na pëlqen aspak kur fëmijët janë të trishtuar, prandaj fillojmë të mendojmë se çfarë mund të bëjmë për këtë.
Çfarë ndodh nëse vendosim në cache jo të gjithë blloqet, por vetëm një përqindje të caktuar të tyre, në mënyrë që cache të mos mbushet? Le të fillojmë thjesht duke shtuar disa rreshta kodi në fillim të funksionit për vendosjen e të dhënave në BlockCache:
public void cacheBlock(BlockCacheKey cacheKey, Cacheable buf, boolean inMemory) {
if (cacheDataBlockPercent != 100 && buf.getBlockType().isData()) {
if (cacheKey.getOffset() % 100 >= cacheDataBlockPercent) {
return;
}
}
...
Këtu ka kuptim që ofseti është pozita e blokut në skedarin dhe numrat e fundit shpërndahen rastësisht dhe në mënyrë të barabartë nga 00 në 99. Prandaj, do të kalojmë vetëm ata që bien në intervalin tonë të nevojshëm.
Për shembull, le të vendosim cacheDataBlockPercent = 20 dhe të shohim se çfarë do të ndodhë:
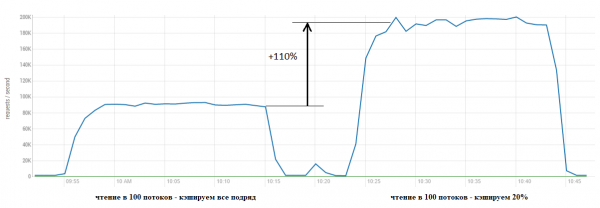
Rezultati është i dukshëm. Në grafiket më poshtë bëhet e qartë se përmes çfarë kjo përshpejtësim ndodhi — ne po kursejmë shumë burime GC duke mos u angazhuar në një punë të pafund për vendosjen e të dhënave në cache vetëm që ato të hidhen menjëherë në qenët marsianë poshtë bishtit:
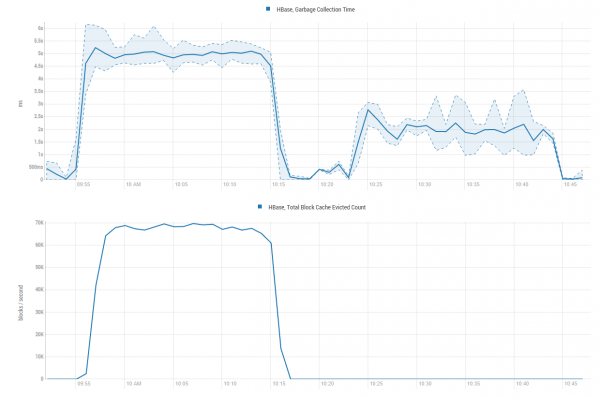
Shfrytëzimi i CPU në këtë rast po rritet, megjithatë ndjeshëm më pak se produktiviteti:
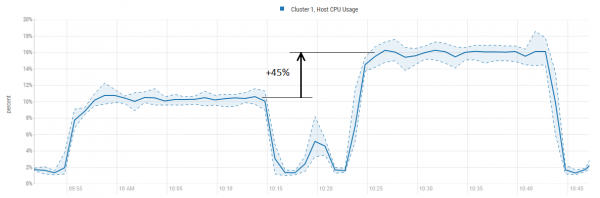
Këtu gjithashtu duhet të theksohet se blloqet që ruhen në BlockCache janë të ndryshme. Pjesa më e madhe, rreth 95%, janë të dhëna. Ndërsa e gjithë pjesa tjetër është metadatat, si filtra Bloom ose LEAF_INDEX dhe . Këto të dhëna janë të pakta, por shumë të dobishme, pasi para se të drejtohet drejtpërdrejt te të dhënat, HBase i referohet metes për të kuptuar nëse duhet të kërkojë më tej dhe, nëse po, ku ndodhet blloku që e intereson.
Prandaj, në kod shohim kushtin e kontrollit buf.getBlockType().isData() dhe për shkak të kësaj, ne do të lëmë metin në cache gjithsesi.
Tani le të rrisim ngarkesën dhe gjithashtu të rafinojmë disi funksionin. Në testin e parë, ne vendosëm përqindjen e prerjes = 20 dhe BlockCache ishte paksa nën ngarkesë. Tani do të vendosim 23% dhe do të shtojmë nga 100 rrjedha çdo 5 minuta për të parë në cilin moment ndodh saturimi:
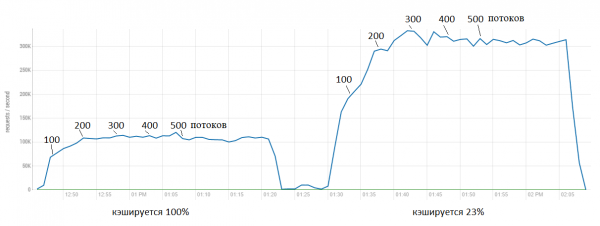
Këtu shohim se versioni origjinal pothuajse menjëherë arrin në plafon në nivelin rreth 100,000 kërkesa në sekondë. Ndërsa patch-i ofron një rritje deri në 300,000. Në të njëjtën kohë, është e qartë se rritja e mëtejshme nuk është aq "falas", pasi shfrytëzimi i CPU gjithashtu po rritet.
Megjithatë, kjo nuk është një zgjidhje shumë elegante, pasi ne nuk e dimë paraprakisht se sa përqind të blloqeve duhet të dërgohen në cache, pasi kjo varet nga profili i ngarkesës. Prandaj, është realizuar një mekanizëm automatik për përshtatjen e këtij parametri në varësi të aktiviteve të operacioneve të leximit.
Për të menaxhuar këtë, janë shtuar tre parametra:
hbase.lru.cache.heavy.eviction.count.limit — përcakton se sa herë duhet të nisë procesi i largimit të të dhënave nga cache, para se të fillojmë të përdorim optimizimin (dmth, të anashkalojmë blloqet). Me default, vlera është MAX_INT = 2147483647 dhe në fakt do të thotë se funksionaliteti nuk do të fillojë kurrë të funksionojë me një vlerë të tillë. Sepse procesi i largimit niset çdo 5 - 10 sekonda (kjo varet nga ngarkesa) dhe 2147483647 * 10 / 60 / 60 / 24 / 365 = 680 vjet. Megjithatë, ne mund ta vendosim këtë parametër në 0 dhe ta bëjmë funksionalitetin të funksionojë menjëherë pas fillimit.
Megjithatë, ka edhe një ngarkesë të dobishme në këtë parametër. Nëse kemi një ngarkesë të tillë që alternon vazhdimisht lexime afatshkurtra (të themi gjatë ditës) dhe lexime afatgjata (në mbrëmje), atëherë mund ta bëjmë që funksionaliteti të aktivizohet vetëm kur ka operacione të zgjatura leximore.
Për shembull, ne dimë se leximet afatshkurtra zakonisht zgjasin rreth 1 minutë. Prandaj, nuk duhet të fillojmë të përjashtojmë blloqet, sepse cache nuk do të ketë mundësi të skadojë dhe atëherë mund të vendosim këtë parametër të barabartë, për shembull, me 10. Kjo do të bëjë që optimizimi të fillojë të punojë vetëm kur ka filluar një lexim aktiv të gjatë, domethënë pas 100 sekondash. Kështu, nëse kemi një lexim afatshkurtër, të gjitha bllokat do të përfshihen në cache dhe do të jenë të disponueshme (përveç atyre që do të hiqen nga algoritmi standard). Ndërsa kur bëjmë lexime afatgjata, funksioni aktivizohet dhe do të kemi një performancë shumë më të lartë.
hbase.lru.cache.heavy.eviction.mb.size.limit — përcakton sa megabajt dëshirojmë të ruajmë në cache (dhe natyrisht të çlirojmë) brenda 10 sekondave. Funksionaliteti do të përpiqet të arrijë këtë vlerë dhe ta mbajë atë. Ideja është se nëse ngremë në cache gigabajt, atëherë do të duhet të çlirohen gjithashtu gigabajt, dhe kjo, siç e pamë më lart, është mjaft e shtrenjtë. Megjithatë, nuk duhet të përpiqeni ta vendosni atë shumë të vogël, pasi kjo do të çonte në daljen e parakohshme nga regjimi i kalimit të bllokimeve. Për serverët e fuqishëm (rreth 20-40 bërthama fizike) është optimal të vendosni rreth 300-400 MB. Për klasën mesatare (~10 bërthama) 200-300 MB. Për sistemet e dobëta (2-5 bërthama) mund të jetë e përshtatshme 50-100 MB (në ato nuk është testuar).
Le të shqyrtojmë si funksionon: le të themi se vendosëm hbase.lru.cache.heavy.eviction.mb.size.limit = 500, ka një ngarkesë të caktuar (lexime) dhe atëherë çdo ~10 sekonda llogarisim se sa byte është çliruar sipas formulës:
Overhead = Sumë e Çliruar e Bytes (MB) * 100 / Limit (MB) — 100;
Nëse në të vërtetë janë çliruar 2000 MB, atëherë Overhead është:
2000 * 100 / 500 — 100 = 300%
Algoritmet përpiqen të mbështesin jo më shumë se disa dhjetëra përqind, kështu që funksionaliteti do të zvogëlojë përqindjen e blloqeve të cache-uar, duke zbatuar kështu mekanizmin e auto-tuning.
Megjithatë, nëse ngarkesa ka rënë, le të supozojmë se janë liruar 200 MB dhe Overhead-i është bërë negativ (të ashtuquajturit overshooting):
200 * 100 / 500 — 100 = -60%
Atyreherë, funksionaliteti do të rrisë përqindjen e blloqeve të cache-uar deri sa Overhead-i të bëhet pozitiv.
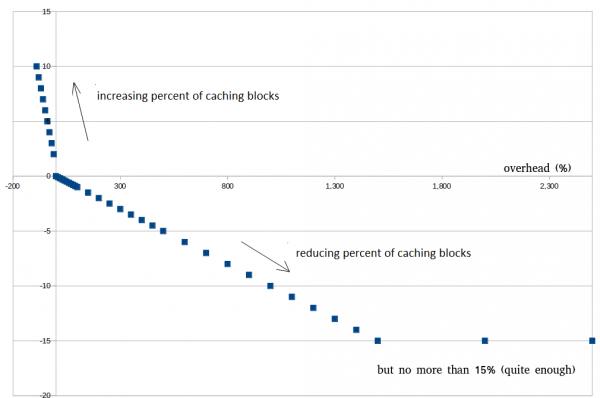
Më poshtë do të ketë një shembull se si duket kjo në të dhëna reale. Nuk është e nevojshme të përpiqeni të arrini 0%, kjo është e pamundur. Është mjaft mirë kur jeni rreth 30 — 100%, kjo ndihmon në shmangien e daljes premature nga moda e optimizimit gjatë shpërthimeve të shkurtra.
hbase.lru.cache.heavy.eviction.overhead.coefficient — vendos se sa shpejt dëshirojmë të marrim rezultatin. Nëse e dimë me siguri se leximet tona janë kryesisht të gjata dhe nuk duam të presim, mund të rrisim këtë koeficient dhe të arrijmë performancë të lartë më shpejt.
Shembuj, ne vendosëm këtë koeficient = 0.01. Kjo do të thotë që Overhead (shih më sipër) do të mnohet me këtë numër në rezultatin e marrë dhe do të ulet përqindja e bllokave të ruajtshme. Supozoni se Overhead = 300%, dhe koeficienti = 0.01, atëherë përqindja e bllokave të ruajtshme do të ulet me 3%.
Logjika e ngjashme e «Backpressure» është realizuar edhe për vlerat negative të Overhead (overshooting). Duke qenë se gjithmonë janë të mundshme luhatje a shkurtë të volumit të leximit-administrimit, ky mekanizëm lejon shmangien e daljes para kohe nga regjimi i optimizimit. Backpressure ka logjikë të përmbysur: sa më e fortë të jetë overshooting, aq më shumë bllokaj të ruhet.
Kodi i realizimit
LruBlockCache cache = this.cache.get();
if (cache == null) {
break;
}
freedSumMb += cache.evict() / 1024 / 1024;
/*
* Ndonëher ne po lexojmë më shumë të dhëna sesa mund të përfshihen në BlockCache
* dhe kjo është shkaku i një rate të lartë të eviktimit.
* Kjo nga ana tjetër çon në punë të rënda të Garbage Collector-it.
* Pra, shumë blloqe hyjnë në BlockCache por kurrë nuk lexohen,
* duke shpenzuar shumë burime CPU.
* Këtu do të analizojmë sa byte janë çliruar dhe do të vendosim
* ndoshta është koha për të ulur sasinë e blloqeve të caching.
* Kjo ndihmon për të shmangur vendosjen e shumë blloqeve në BlockCache
* kur evict() punon shumë aktivisht dhe kursen CPU për punë të tjera.
* Detaje të mëtejshme: https://issues.apache.org/jira/browse/HBASE-23887
*/
// Së pari, ne duam të kontrollojmë sa kohë
// ka kaluar që nga evict() i mëparshëm
// Kjo duhet të jetë pothuajse e njëjtë (+/- 10s)
// sepse marrim vëllime të krahasueshme të byte-eve të çliruara çdo herë.
// 10s sepse ky është periudha e paracaktuar për të ekzekutuar evict() (shih më lart this.wait)
long stopTime = System.currentTimeMillis();
if ((stopTime - startTime) > 1000 * 10 - 1) {
// Këtu ne duhet të llogarisim se cila është situata.
// Ne kemi kufirin "hbase.lru.cache.heavy.eviction.bytes.size.limit"
// dhe mund të llogarisim mbingarkimin mbi të.
// Ne do ta përdorim këtë informacion për të vendosur,
// si të ndryshojmë përqindjen e blloqeve të caching.
freedDataOverheadPercent =
(int) (freedSumMb * 100 / cache.heavyEvictionMbSizeLimit) - 100;
if (freedSumMb > cache.heavyEvictionMbSizeLimit) {
// Tani jemi në situatën kur jemi mbi kufirin
// Por ndoshta do ta injorojmë sepse kjo do të përfundojë shumë shpejt
heavyEvictionCount++;
if (heavyEvictionCount > cache.heavyEvictionCountLimit) {
// Po vazhdon për një kohë të gjatë dhe duhet të reduktojmë
// blloqet e caching tani. Pra, llogarisim këtu sa blloqe duam të anashkalojmë.
// Kjo varet nga:
// 1. Mbingarkimi - nëse mbingarkimi është i madh mund të jemi më agresiv
// në uljen e sasisë së blloqeve të caching.
// 2. Sa shpejt duam të arrijmë rezultatin. Nëse e dimë se
// leximet e rënda do të vazhdojnë për një kohë të gjatë, nuk duam të presim dhe mund
// të rrisim koeficientin dhe të arrijmë performancë të mirë shumë shpejt.
// Por nëse nuk jemi të sigurt mund ta bëjmë ngadalë dhe kjo mund të parandalojë
// daljen e parakohshme nga ky mod. Pra, kur koeficienti është
// më i lartë mund të arrijmë performancë më të mirë kur leximet e rënda janë të qëndrueshme.
// Por kur leximet ndryshojnë mund të përshtatim dhe të vendosim
// koeficientin në një nivel më të ulët.
int change =
(int) (freedDataOverheadPercent * cache.heavyEvictionOverheadCoefficient);
// Por praktika tregon se 15% ulje është mjaft e mjaftueshme.
// Ne nuk jemi lakmitarë (kjo mund të çojë në dalje të parakohshme).
change = Math.min(15, change);
change = Math.max(0, change); // Mendoj se kjo asnjëherë nuk do të ndodhte por kontrollo për siguri
// Pra, këtu është pika kyçe, ne po ulet % e blloqeve të caching
cache.cacheDataBlockPercent -= change;
// Nëse shkojmë shumë thellë duhet të ndalim këtu, në çdo rast duhet të jetë 1%.
cache.cacheDataBlockPercent = Math.max(1, cache.cacheDataBlockPercent);
}
} else {
// Mirë, kemi marrë shumë.
// Ndoshta është vetëm një fluctuation afatshkurtër dhe mund të qëndrojmë në këtë mod.
// Kjo ndihmon për të shmangur daljen e parakohshme gjatë fluctuationeve afatshkurtër.
// Nëse mbingarkimi është më pak se 90%, ne do të përpiqemi të rrisim përqindjen e
// blloqeve të caching dhe shpresojmë se është e mjaftueshme.
if (freedSumMb >= cache.heavyEvictionMbSizeLimit * 0.1) {
// Logjikë e thjeshtë: më shumë mbingarkim - më shumë blloqe caching (presion prapa)
int change = (int) (-freedDataOverheadPercent * 0.1 + 1);
cache.cacheDataBlockPercent += change;
// Por nuk mund të jetë më shumë se 100%, pra kontrollo atë.
cache.cacheDataBlockPercent = Math.min(100, cache.cacheDataBlockPercent);
} else {
// Duket se leximi i rëndë ka përfunduar.
// Thjesht dalim nga ky mod.
heavyEvictionCount = 0;
cache.cacheDataBlockPercent = 100;
}
}
LOG.info("BlockCache evicted (MB): {}, overhead (%): {}, " +
"heavy eviction counter: {}, " +
"current caching DataBlock (%): {}",
freedSumMb, freedDataOverheadPercent,
heavyEvictionCount, cache.cacheDataBlockPercent);
freedSumMb = 0;
startTime = stopTime;
}
Tani po të gjitha këto, le të shohim një shembull real. Kemi skenarin e mëposhtëm të testit:
- Fillojmë të bëjmë Scan (25 threads, batch = 100)
- Pas 5 minutash shtojmë multi-gets (25 threads, batch = 100)
- Pas 5 minutash e ndalojmë multi-gets (kthishemi përsëri vetëm në scan)
Bëjmë dy rrotullime, fillimisht hbase.lru.cache.heavy.eviction.count.limit = 10000 (e cila praktikisht e ndalon funksionin), dhe më pas vendosim limit = 0 (e aktivizon).
Në logët më poshtë ne shohim se si funksioni aktivizohet, duke e rikthyer Overshooting në 14-71%. Herë pas here ngarkesa ulet, e cila aktivizon Backpressure dhe HBase fillon të keqcache më shumë blloqe.
Logu i RegionServer
evicted (MB): 0, ratio 0.0, overhead (%): -100, heavy eviction counter: 0, current caching DataBlock (%): 100
evicted (MB): 0, ratio 0.0, overhead (%): -100, heavy eviction counter: 0, current caching DataBlock (%): 100
evicted (MB): 2170, ratio 1.09, overhead (%): 985, heavy eviction counter: 1, current caching DataBlock (%): 91 < start
evicted (MB): 3763, ratio 1.08, overhead (%): 1781, heavy eviction counter: 2, current caching DataBlock (%): 76
evicted (MB): 3306, ratio 1.07, overhead (%): 1553, heavy eviction counter: 3, current caching DataBlock (%): 61
evicted (MB): 2508, ratio 1.06, overhead (%): 1154, heavy eviction counter: 4, current caching DataBlock (%): 50
evicted (MB): 1824, ratio 1.04, overhead (%): 812, heavy eviction counter: 5, current caching DataBlock (%): 42
evicted (MB): 1482, ratio 1.03, overhead (%): 641, heavy eviction counter: 6, current caching DataBlock (%): 36
evicted (MB): 1140, ratio 1.01, overhead (%): 470, heavy eviction counter: 7, current caching DataBlock (%): 32
evicted (MB): 913, ratio 1.0, overhead (%): 356, heavy eviction counter: 8, current caching DataBlock (%): 29
kërkuar (MB): 912, raporti 0.89, overhead (%): 356, numri i lëshimeve të rënda: 9, blloku i të dhënave aktual i caching (%): 26
kërkuar (MB): 684, raporti 0.76, overhead (%): 242, numri i lëshimeve të rënda: 10, blloku i të dhënave aktual i caching (%): 24
kërkuar (MB): 684, raporti 0.61, overhead (%): 242, numri i lëshimeve të rënda: 11, blloku i të dhënave aktual i caching (%): 22
kërkuar (MB): 456, raporti 0.51, overhead (%): 128, numri i lëshimeve të rënda: 12, blloku i të dhënave aktual i caching (%): 21
kërkuar (MB): 456, raporti 0.42, overhead (%): 128, numri i lëshimeve të rënda: 13, blloku i të dhënave aktual i caching (%): 20
kërkuar (MB): 456, raporti 0.33, overhead (%): 128, numri i lëshimeve të rënda: 14, blloku i të dhënave aktual i caching (%): 19
kërkuar (MB): 342, raporti 0.33, overhead (%): 71, numri i lëshimeve të rënda: 15, blloku i të dhënave aktual i caching (%): 19
kërkuar (MB): 342, raporti 0.32, overhead (%): 71, numri i lëshimeve të rënda: 16, blloku i të dhënave aktual i caching (%): 19
kërkuar (MB): 342, raporti 0.31, overhead (%): 71, numri i lëshimeve të rënda: 17, blloku i të dhënave aktual i caching (%): 19
kërkuar (MB): 228, raporti 0.3, overhead (%): 14, numri i lëshimeve të rënda: 18, blloku i të dhënave aktual i caching (%): 19
kërkuar (MB): 228, raporti 0.29, overhead (%): 14, numri i lëshimeve të rënda: 19, blloku i të dhënave aktual i caching (%): 19
kërkuar (MB): 228, raporti 0.27, overhead (%): 14, numri i lëshimeve të rënda: 20, blloku i të dhënave aktual i caching (%): 19
kërkuar (MB): 228, raporti 0.25, overhead (%): 14, numri i lëshimeve të rënda: 21, blloku i të dhënave aktual i caching (%): 19
kërkuar (MB): 228, raporti 0.24, overhead (%): 14, numri i lëshimeve të rënda: 22, blloku i të dhënave aktual i caching (%): 19
kërkuar (MB): 228, raporti 0.22, overhead (%): 14, numri i lëshimeve të rënda: 23, blloku i të dhënave aktual i caching (%): 19
kërkuar (MB): 228, raporti 0.21, overhead (%): 14, numri i lëshimeve të rënda: 24, blloku i të dhënave aktual i caching (%): 19
kërkuar (MB): 228, raporti 0.2, overhead (%): 14, numri i lëshimeve të rënda: 25, blloku i të dhënave aktual i caching (%): 19
e dëbuar (MB): 228, raporti 0.17, overhead (%): 14, numri i lartë i dëbimeve: 26, përqindja e bllokut të të dhënave aktuale të ruajtjes: 19
e dëbuar (MB): 456, raporti 0.17, overhead (%): 128, numri i lartë i dëbimeve: 27, përqindja e bllokut të të dhënave aktuale të ruajtjes: 18 < shtesat e ndihmës (por tabela e njëjtë)
e dëbuar (MB): 456, raporti 0.15, overhead (%): 128, numri i lartë i dëbimeve: 28, përqindja e bllokut të të dhënave aktuale të ruajtjes: 17
e dëbuar (MB): 342, raporti 0.13, overhead (%): 71, numri i lartë i dëbimeve: 29, përqindja e bllokut të të dhënave aktuale të ruajtjes: 17
e dëbuar (MB): 342, raporti 0.11, overhead (%): 71, numri i lartë i dëbimeve: 30, përqindja e bllokut të të dhënave aktuale të ruajtjes: 17
e dëbuar (MB): 342, raporti 0.09, overhead (%): 71, numri i lartë i dëbimeve: 31, përqindja e bllokut të të dhënave aktuale të ruajtjes: 17
e dëbuar (MB): 228, raporti 0.08, overhead (%): 14, numri i lartë i dëbimeve: 32, përqindja e bllokut të të dhënave aktuale të ruajtjes: 17
e dëbuar (MB): 228, raporti 0.07, overhead (%): 14, numri i lartë i dëbimeve: 33, përqindja e bllokut të të dhënave aktuale të ruajtjes: 17
e dëbuar (MB): 228, raporti 0.06, overhead (%): 14, numri i lartë i dëbimeve: 34, përqindja e bllokut të të dhënave aktuale të ruajtjes: 17
e dëbuar (MB): 228, raporti 0.05, overhead (%): 14, numri i lartë i dëbimeve: 35, përqindja e bllokut të të dhënave aktuale të ruajtjes: 17
e dëbuar (MB): 228, raporti 0.05, overhead (%): 14, numri i lartë i dëbimeve: 36, përqindja e bllokut të të dhënave aktuale të ruajtjes: 17
e dëbuar (MB): 228, raporti 0.04, overhead (%): 14, numri i lartë i dëbimeve: 37, përqindja e bllokut të të dhënave aktuale të ruajtjes: 17
e dëbuar (MB): 109, raporti 0.04, overhead (%): -46, numri i lartë i dëbimeve: 37, përqindja e bllokut të të dhënave aktuale të ruajtjes: 22 < presioni i prapAmbush
e dëbuar (MB): 798, raporti 0.24, overhead (%): 299, numri i lartë i dëbimeve: 38, përqindja e bllokut të të dhënave aktuale të ruajtjes: 20
e dëbuar (MB): 798, raporti 0.29, overhead (%): 299, numri i lartë i dëbimeve: 39, përqindja e bllokut të të dhënave aktuale të ruajtjes: 18
e dëbuar (MB): 570, raporti 0.27, overhead (%): 185, numri i lartë i dëbimeve: 40, përqindja e bllokut të të dhënave aktuale të ruajtjes: 17
e dëbuar (MB): 456, raporti 0.22, overhead (%): 128, numri i lartë i dëbimeve: 41, përqindja e bllokut të të dhënave aktuale të ruajtjes: 16
e dëbuar (MB): 342, raporti 0.16, përshtatja (%): 71, numri i lëshimeve të rënda: 42, Bloku i të dhënave aktual të caching (%): 16
e dëbuar (MB): 342, raporti 0.11, përshtatja (%): 71, numri i lëshimeve të rënda: 43, Bloku i të dhënave aktual të caching (%): 16
e dëbuar (MB): 228, raporti 0.09, përshtatja (%): 14, numri i lëshimeve të rënda: 44, Bloku i të dhënave aktual të caching (%): 16
e dëbuar (MB): 228, raporti 0.07, përshtatja (%): 14, numri i lëshimeve të rënda: 45, Bloku i të dhënave aktual të caching (%): 16
e dëbuar (MB): 228, raporti 0.05, përshtatja (%): 14, numri i lëshimeve të rënda: 46, Bloku i të dhënave aktual të caching (%): 16
e dëbuar (MB): 222, raporti 0.04, përshtatja (%): 11, numri i lëshimeve të rënda: 47, Bloku i të dhënave aktual të caching (%): 16
e dëbuar (MB): 104, raporti 0.03, përshtatja (%): -48, numri i lëshimeve të rënda: 47, Bloku i të dhënave aktual të caching (%): 21 < interrupt gets
e dëbuar (MB): 684, raporti 0.2, përshtatja (%): 242, numri i lëshimeve të rënda: 48, Bloku i të dhënave aktual të caching (%): 19
e dëbuar (MB): 570, raporti 0.23, përshtatja (%): 185, numri i lëshimeve të rënda: 49, Bloku i të dhënave aktual të caching (%): 18
e dëbuar (MB): 342, raporti 0.22, përshtatja (%): 71, numri i lëshimeve të rënda: 50, Bloku i të dhënave aktual të caching (%): 18
e dëbuar (MB): 228, raporti 0.21, përshtatja (%): 14, numri i lëshimeve të rënda: 51, Bloku i të dhënave aktual të caching (%): 18
e dëbuar (MB): 228, raporti 0.2, përshtatja (%): 14, numri i lëshimeve të rënda: 52, Bloku i të dhënave aktual të caching (%): 18
e dëbuar (MB): 228, raporti 0.18, përshtatja (%): 14, numri i lëshimeve të rënda: 53, Bloku i të dhënave aktual të caching (%): 18
e dëbuar (MB): 228, raporti 0.16, përshtatja (%): 14, numri i lëshimeve të rënda: 54, Bloku i të dhënave aktual të caching (%): 18
e dëbuar (MB): 228, raporti 0.14, përshtatja (%): 14, numri i lëshimeve të rënda: 55, Bloku i të dhënave aktual të caching (%): 18
e dëbuar (MB): 112, raporti 0.14, përshtatja (%): -44, numri i lëshimeve të rënda: 55, Bloku i të dhënave aktual të caching (%): 23 < back pressure
e dëbuar (MB): 456, raporti 0.26, përshtatja (%): 128, numri i lëshimeve të rënda: 56, Bloku i të dhënave aktual të caching (%): 22
më është hequr (MB): 342, raporti 0.31, mbingarkesa (%): 71, numri i rëndë i heqjes: 57, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 58, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 59, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 60, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 61, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 62, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 63, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.32, mbingarkesa (%): 71, numri i rëndë i heqjes: 64, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 65, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 66, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.32, mbingarkesa (%): 71, numri i rëndë i heqjes: 67, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 68, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.32, mbingarkesa (%): 71, numri i rëndë i heqjes: 69, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.32, mbingarkesa (%): 71, numri i rëndë i heqjes: 70, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 71, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 72, blloku aktual i të dhënave në cache (%): 22
më është hequr (MB): 342, raporti 0.33, mbingarkesa (%): 71, numri i rëndë i heqjes: 73, blloku aktual i të dhënave në cache (%): 22
ejektuar (MB): 342, raporti 0.33, overhead (%): 71, numri i lartë i ejectimeve: 74, përqindja aktuale e DataBlock në caching (%): 22
ejektuar (MB): 342, raporti 0.33, overhead (%): 71, numri i lartë i ejectimeve: 75, përqindja aktuale e DataBlock në caching (%): 22
ejektuar (MB): 342, raporti 0.33, overhead (%): 71, numri i lartë i ejectimeve: 76, përqindja aktuale e DataBlock në caching (%): 22
ejektuar (MB): 21, raporti 0.33, overhead (%): -90, numri i lartë i ejectimeve: 76, përqindja aktuale e DataBlock në caching (%): 32
evicted (MB): 0, ratio 0.0, overhead (%): -100, heavy eviction counter: 0, current caching DataBlock (%): 100
evicted (MB): 0, ratio 0.0, overhead (%): -100, heavy eviction counter: 0, current caching DataBlock (%): 100
Skemat ishin të nevojshme për të treguar këtë proces në formë grafike të raportit midis dy seksioneve të caches - single (ku hyjnë blloqet që askush nuk i ka kërkuar ndonjëherë) dhe multi (këtu ruhen të dhënat 'të kërkuara' të paktën një herë):
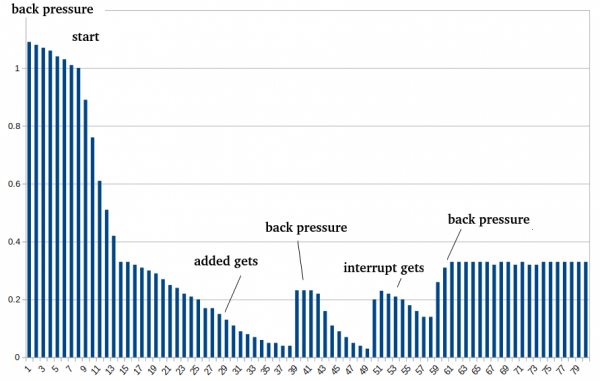
Dhe për fund, si duket funksionimi i parametrave në formën e një grafiku. Për krahasim, cache ishte plotësisht i ç aktivizuar në fillim, pastaj filloi HBase me caching dhe një vonesë në fillimin e optimizimit për 5 minuta (30 cikle ejectimi).
Kodi i plotë mund të gjendet në Pull Request në github.
Megjithatë, 300 mijë lexime në sekondë nuk janë gjithë ajo që mund të nxirret nga ky harduer në këto kushte. Arsyeja është se kur nevojitet akses në të dhëna nëpërmjet HDFS, përdoret mekanizmi ShortCircuitCache (SSC), i cili lejon aksesin direkt në të dhënat, duke shmangur ndërveprimet rrjet.
Profilimi tregoi se ky mekanizëm, megjithëse ofron një përfitim të madh, në një moment bëhet një ngushticë, pasi pothuajse të gjitha operacionet e rënda ndodhin brenda lock, që çon në bllokime për një kohë të gjatë.

Pasi e kuptuam këtë, kuptuam se problemi mund të shmanget duke krijuar një array SSC të pavarur:
private final ShortCircuitCache[] shortCircuitCache;
...
shortCircuitCache = new ShortCircuitCache[this.clientShortCircuitNum];
for (int i = 0; i < this.clientShortCircuitNum; i++)
this.shortCircuitCache[i] = new ShortCircuitCache(…);
Dhe pastaj të punojmë me to, duke përjashtuar ndërprerjet gjithashtu sipas numrit të fundit të ofsetit:
public ShortCircuitCache getShortCircuitCache(long idx) {
return shortCircuitCache[(int) (idx % clientShortCircuitNum)];
}
Tani mund të fillojmë testet. Për këtë, do të lexojmë skedarët nga HDFS me një aplikacion të thjeshtë multi-thread. Vendosim parametrat:
conf.set("dfs.client.read.shortcircuit", "true");
conf.set("dfs.client.read.shortcircuit.buffer.size", "65536"); // me defolt = 1 MB dhe kjo ngadalëson shumë leximin, prandaj është më mirë ta përshtatim me nevojat reale
conf.set("dfs.client.short.circuit.num", num); // nga 1 deri në 10
Dhe thjesht lexojmë skedarët:
FSDataInputStream in = fileSystem.open(path);
for (int i = 0; i 900000000)
position = 0L;
int res = in.read(position, byteBuffer, 0, 65536);
}
Ky kyç realizohet në threads të ndara dhe ne do të rrisim numrin e skedave që mund të lexohen njëkohësisht (nga 10 në 200 – aksisi horizontal) dhe numrin e cache-ve (nga 1 në 10 – grafikët). Aksisi vertikal tregon përshpejtimin që ofron rritja e SSC në krahasim me rastin kur cache është vetëm një.
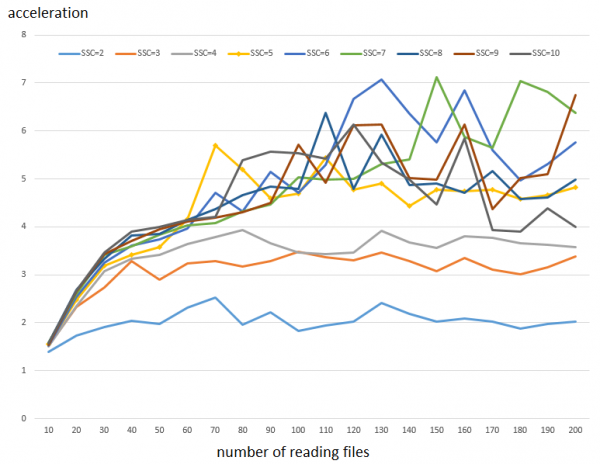
Si të lexoni grafikën: koha e ekzekutimit për 100 mijë lexime me blloqe prej 64 KB me një cache kërkon 78 sekonda. Ndërsa me 5 cache, kjo kryhet për 16 sekonda. Pra, ka një përshpejtim prej ~5 herësh. Siç duket në grafik, në një numër të vogël leximesh paralel efektet nuk janë shumë të dukshme, kjo fillon të luajë një rol të rëndësishëm kur leximet e thread-eve kalojnë 50. Gjithashtu bie në sy se rritja e numrit të SSC nga 6 e lart jep një rritje të dukshme më të vogël të performancës.
Shënim 1: pasi rezultatet e testimit janë mjaft të ndjeshme (shih më poshtë), janë kryer 3 funksionime dhe vlerat e marra janë mesatarizuar.
Shënim 2: Rritja e performancës nga konfigurimi për qasje të rastësishme është e njëjtë, megjithatë vetë qasja është pak më e ngadaltë.
Megjithatë, duhet të theksohet se ndryshe nga rasti me HBase, ky përmirësim nuk është gjithmonë falas. Këtu më shumë po "çlirojmë" mundësitë e CPU për të kryer punën, në vend që të ngrihet në bllokime.
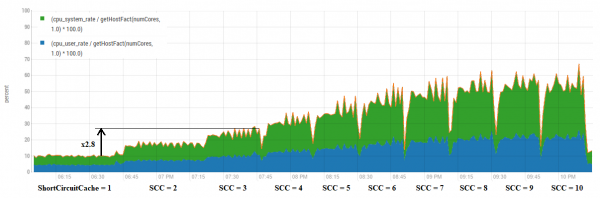
Këtu mund të vërehet se në përgjithësi rritja e numrit të cache-ve jep një rritje proporcionale të përdorimit të CPU. Megjithatë, ekzistojnë disa kombinime më fitimprurëse.
Për shembull, le të shikojmë më nga afër konfigurimin SSC = 3. Rritja e performancës në këtë diapazon është rreth 3.3 herë. Më poshtë janë rezultatet e të tri startimeve të veçanta.
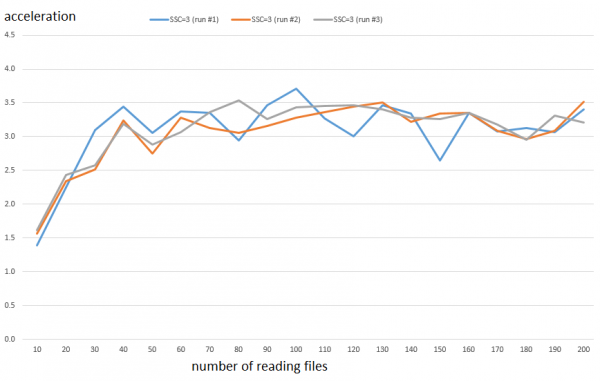
Ndërsa konsumimi i CPU rritet rreth 2.8 herë. Diferenca nuk është shumë e madhe, por Greta e vogël tashmë është e lumtur dhe ndoshta do të ketë kohë për të vizituar shkollën dhe mësimet.
Prandaj, kjo do të ketë një efekt pozitiv për çdo mjet që përdor qasje masive në HDFS (p.sh. Spark etj.), për sa kohë që kodi aplikativ është i lehtë (dmth. ngarkesa pikërisht në anën e klientit HDFS) dhe ka kapacitete të lirë CPU. Për ta provuar, le të testojmë se cilin efekt do të japë aplikimi i përbashkët i optimizimit të BlockCache dhe tuningut SSC për leximin nga HBase.
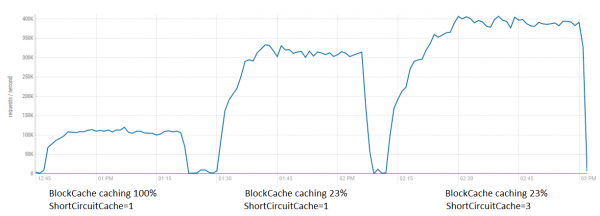
Këtu duket se në këto kushte efekti nuk është aq i madh sa në testet e rafinuara (lexim pa asnjë përpunim), megjithatë, është e mundur të nxirreni 80K të tjera. Së bashku, të dy optimizimet japin një përshpejtim deri në 4 herë.
Po ashtu, për këtë optimizim është bërë PR , i cili është integruar dhe kjo funksionalitet do të jetë i disponueshëm në versionet e ardhshme.
Dhe përfundimisht, ishte interesante të krahasohej performanca e leximit të një DB të tillë wide-column si Cassandra dhe HBase.
Për këtë, u lançuan instanca të utilitarit standard të testimit të ngarkesës YCSB nga dy hoste (800 threads në total). Në anën e serverit, ishin 4 instanca të RegionServer dhe Cassandra në 4 hoste (jo ato ku janë lansuar klientët, për të shmangur ndikimin e tyre). Leximet u bënë nga tabela me madhësi:
HBase — 300 GB on HDFS (100 GB të dhëna të pastra)
Cassandra — 250 GB (faktori i replikimit = 3)
Pra, volumi ishte afërsisht i njëjtë (në HBase pak më shumë).
Parametrat e HBase:
dfs.client.short.circuit.num = 5 (optimizimi i klientit HDFS)
hbase.lru.cache.heavy.eviction.count.limit = 30 — kjo do të thotë se patches do të fillojë të funksionojë pas 30 dëbimeve (~5 minuta)
hbase.lru.cache.heavy.eviction.mb.size.limit = 300 — vëllimi i synuar i caching dhe dëbimit
Logs YCSB u përpunuan dhe u përmbledhën në grafikë Excel:
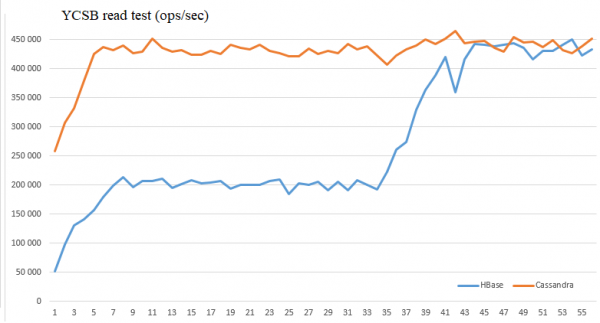
Siç shihet, të dhënat e optimizimit lejojnë të barazohen performancat e këtyre DB në këto kushte dhe të arrijnë 450 mijë lexime në sekondë.
Shpresojmë që kjo informacion mund të jetë e dobishme për dikë gjatë përpjekjeve emocionuese për performancën.
Burimi: habr.com
