

Përshëndetje, habrovçanë. Sot fillojnë mësimet në grupin e parë të kursit . Në lidhje me këtë, dëshirojmë t'ju tregojmë se si kaloi webinari i hapur mbi këtë kurs.

Në diskutuam se me cilat sfida ndodhen përballë databazat SQL në epokën e reve dhe Kubernetes. Gjithashtu shqyrtuam si databazat SQL përshtaten dhe mutojnë nën ndikimin e këtyre sfidave.
Webinarin e drejtoi , Menaxher i Dorëzimit në Praktikën e Re të Google në EPAM Systems.
Kur pemët ishin të vogla…
Për të filluar, le të kujtojmë se si filloi zgjedhja e SGBD-ve në fund të shekullit të 20-të. Megjithatë, kjo nuk do të jetë e vështirë, sepse zgjedhja e SGBD-ve në ato kohë fillonte dhe përfundonte Oracle.

Në fund të viteve '90 dhe fillimin e 2000-ve, nuk kishte shumë mundësi, nëse flasim për databazat industriale të shkallëzuara. Po, ekzistonin IBM DB2, Sybase dhe disa databaza të tjera që shfaqeshin dhe zhdukeshin, por mbi të gjitha ato nuk ishin aq të dukshme përballë Oracle. Si rezultat, aftësitë e inxhinierëve të atyre kohëve ishin lidhur në një mënyrë ose në tjetër me atë zgjedhje të vetme që ekzistonte.
Oracle DBA duhet të dinte:
- të instaloni Oracle Server nga distribuimi;
- të konfiguroni Oracle Server:
- init.ora;
- listener.ora;
— të krijoni:
- hapësira të tabelave;
- skemat;
- përdoruesit;
— të realizoni kopjim dhe rikuperim;
— të bëni monitorim;
— të luftoni me pyetje jo optimale.
Megjithatë, nga DBA e Oracle nuk pritej veçanërisht:
- të dinte të zgjidhte një DBMS optimal ose një teknologji tjetër për ruajtjen dhe përpunimin e të dhënave;
- të sigurojë disponueshmëri të lartë dhe shkallëzim horizontal (kjo nuk ishte gjithmonë çështje e DBA);
- të kishte njohuri të mira mbi fushën përkatëse, infrastrukturën, arkitekturën aplikative, OS;
- të realizonte ngarkimin dhe shkarkimin e të dhënave, migrimin e të dhënave midis DBMS-ve të ndryshme.
Në përgjithësi, nëse flasim për zgjedhjen në ato kohëra, ajo ngjasonte me zgjedhjen në një dyqan sovjetik në fund të viteve '80:

Koha jonë
Që atëherë, natyrisht, pemët janë rritur, bota ka ndryshuar, dhe ka ndodhur kështu:

Tregu i DBMS-ve ka ndryshuar gjithashtu, gjë që është e dukshme në raporin e fundit të kompanisë Gartner:
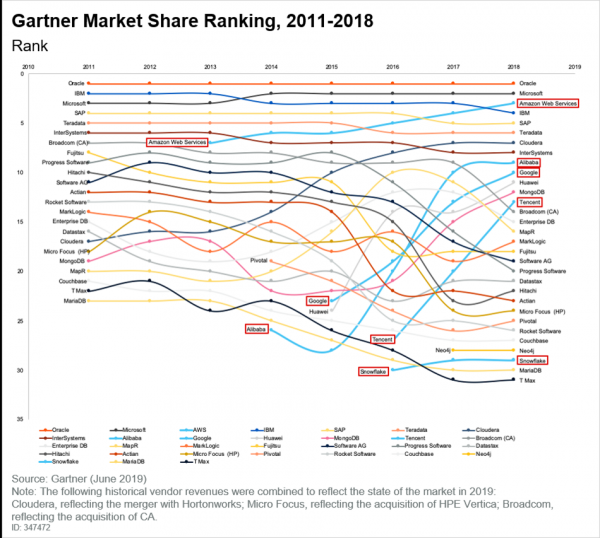
Dhe këtu është e pamundur të mos theksohet se rethana kanë zënë një vend, popullariteti i të cilave po rritet. Nëse lexoni atë raport të kompanisë Gartner, ne do të shohim konkluzionet e mëposhtme:
- Shumë klientë janë në rrugën e shndërrimit të aplikacioneve në cloud.
- Teknologjitë e reja shfaqen fillimisht në cloud dhe nuk ka garanci që ato ndonjëherë do të kalojnë në infrastrukturë jo-cloud.
- Modeli i çmimeve pay-as-you-go është bërë tashmë i zakonshëm. Të gjithë duan të paguajnë vetëm për atë që përdorin, dhe kjo tashmë nuk është një trend, por thjesht një konstatim i faktit.
Çfarë ndodh tani?
Sot të gjithë jemi në cloud. Çështjet që kemi, janë pyetje zgjedhjeje. Dhe ato janë të shumta, madje edhe kur flasim vetëm për zgjedhjen e teknologjive të bazave të të dhënave në formatin On-premises. Dhe kemi gjithashtu shërbime të menaxhuara dhe SaaS. Kështu, zgjedhja vetëm bëhet më e komplikuar çdo vit.
Përveç pyetjeve të zgjedhjes, veprojnë edhe faktorët kufizues:
- çmimi. Shumë teknologji ende kushtojnë para;
- aftësi. Nëse flasim për softin e lirë, atëherë lind pyetja e aftësive, pasi softi falas kërkon nga njerëzit që e implementojnë dhe e përdorin atë, kompetencë të mjaftueshme;
- funksionaliteti. Jo të gjitha shërbimet që janë në re dhe janë ndërtuar, le të themi, madje edhe në bazën e Postgres të njëjtë, kanë të njëjtat veçori si Postgres On-premises. Ky është një faktor thelbësor që duhet të dihet dhe kuptohet. Më shumë se kaq, ky faktor merr një rëndësi më të madhe se njohja e ndonjë mundësie të fshehtë të një SGBD specifike.
Çfarë pritet tani nga DA/DE:
- një kuptim të mirë të fushës së subjektit dhe arkitekturës aplikative;
- aftësinë për të zgjedhur teknologjinë e duhur SGBD në përputhje me detyrën e caktuar;
- aftësinë për të zgjedhur metodën optimale të zbatimit të teknologjisë së zgjedhur në kontekstin e kufizimeve ekzistuese;
- aftësinë për të realizuar transferimin dhe migrimin e të dhënave;
- aftësinë për të zbatuar dhe operuar zgjidhjet e zgjedhura.
Shembulli më poshtë në bazë të GCP tregon se si vendoset teknologjia e caktuar për punën me të dhëna në varësi të strukturës së tyre:
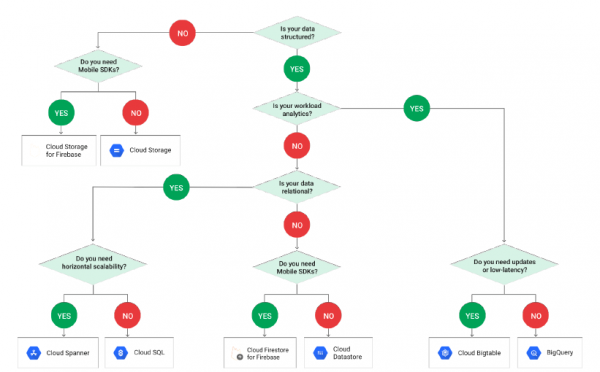
Vini re se në diagram nuk përfshihet PostgreSQL, dhe kjo për shkak se ai fshihet pas terminologjisë Cloud SQL. Dhe kur arrijmë në Cloud SQL, na nevojitet të bëjmë përsëri një zgjedhje:
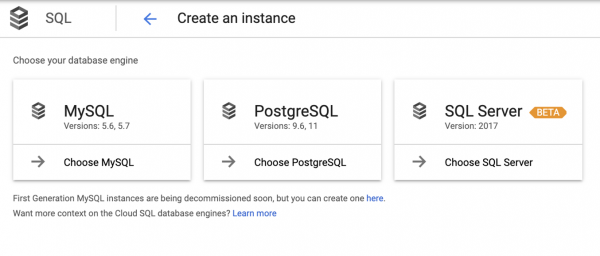
Duhet të theksohet se kjo zgjedhje nuk është gjithmonë e qartë, prandaj zhvilluesit e aplikacionit shpesh drejtohen nga intuita.
Në përmbledhje:
- Sa më shumë që kalon koha, aq më i rëndësishëm bëhet pyetja e zgjedhjes. Edhe nëse shohim vetëm GCP, shërbimet e menaxhuara dhe SaaS, përmendja e RDBMS shfaqet vetëm në hapin e 4-të (dhe atje është Spanner). Plus, zgjedhja e PostgreSQL shfaqet në të 5-in, kur janë gjithashtu MySQL dhe SQL Server, domethënë ka shumë, por duhet të zgjedhim.
- Nuk duhet harruar as kufizimet përballë tundimeve. Në shumicën e rasteve, të gjithë dëshirojnë Spanner, por ai është i shtrenjtë. Në përfundim, kërkesa tipike duket kështu: «Na bëni, ju lutem, Spanner por me çmimin e Cloud SQL, ju jeni profesionistë!»

Çfarë të bëjmë tani?
Pa pretenduar për të vërteta absolutiste, le të themi këtë:
Duhet të ndryshojmë qasjen në mësim:
- nuk ka kuptim të mësojmë siç i mësuam më parë DBA-të;
- dija e një produkti tani është e pamjaftueshme;
- dhe të dish dhjetëra në nivelin e njërit — është e pamundur.
Duhet të njohim jo vetëm produktin, por:
- rastin e përdorimit të tij;
- metoda të ndryshme të implementimit;
- përparësitë dhe disavantazhet e çdo metode;
- produkte të ngjashme dhe alternative për të bërë një zgjedhje të informuar dhe optimale, pa u mbështetur gjithmonë në produktin e njohur.
Përveç kësaj, duhet të jeni në gjendje të migroni të dhënat dhe të kuptoni parimet bazë të integrimit me ETL.
Rasti i vërtetë
Në të kaluarën e afërt, isha duke zhvilluar një backend për një aplikacion mobil. Në momentin që fillova punën, backend kishte përfunduar dhe ishte gati për t'u implementuar, dhe ekipi i zhvilluesve kishte kaluar rreth dy vjet në këtë projekt. Gjatë kësaj periudhe u vendosën detyrat e mëposhtme:
- të ndërtohet CI/CD;
- të bëhej review i arkitekturës;
- të ndizet gjithçka në funksion.
Aplikacioni vetë ishte mikroshtesë, dhe kodi në Python/Django ishte zhvilluar nga zero dhe menjëherë në GCP. Sa i përket audiencës synuese, supozohej se do të ishin dy rajone — SHBA dhe BE, dhe trafiku do të shpërndahej përmes Balancuesit Global të Ngarkesës. Të gjitha Workloads dhe ngarkesat Computation punonin në Google Kubernetes Engine.
Sa i përket të dhënave, ishin 3 struktura:
- Cloud Storage;
- Datastore;
- Cloud SQL (PostgreSQL).
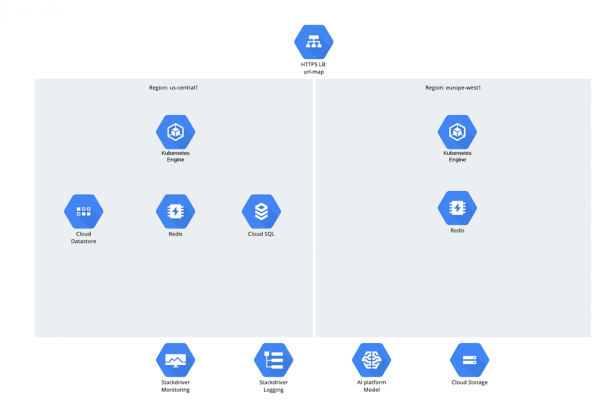
Mund të ngrihet një pyetje, pse u zgjodh Cloud SQL? Në të vërtetë, kjo pyetje ka shkaktuar një heshtje të çuditshme vitet e fundit - duket se njerëzit po ndihen të turpëruar nga bazat e të dhënave relacionale, megjithatë ata vazhdojnë t’i përdorin ato aktivisht ;-).
Sa i përket rastit tonë, Cloud SQL u zgjodh për arsyet e mëposhtme:
- Siç u përmend, aplikacioni u zhvillua me Django dhe përmban një model që shfaq të dhëna të qëndrueshme nga SQL në objekte Python (Django ORM).
- I vetmi framework mbështeti një listë mjaft të përfunduar të SGBD-ve:
- PostgreSQL;
- MariaDB;
- MySQL;
- Oracle;
- SQLite.
Prandaj, PostgreSQL u zgjodh nga ky listë më shumë intuitivisht (nuk mund të zgjidhje Oracle, në të vërtetë).
Çfarë mungonte:
- aplikacioni ishte deployuar vetëm në 2 rajone, dhe tani kishte një plan për një të tretë (Azia);
- Baza e të dhënave ndodhej në rajonin e Amerikës së Veriut (Iowa);
- nga ana e klientit kishte shqetësime për pengesat në qasje nga Evropa dhe Azia dhe ndërprerjet në shërbim në rast të ndërprerjes së SGBD-së.
Django mund të punojë me disa baza të të dhënash paralelisht dhe t'i ndajë ato për lexim dhe shkruaj, por në aplikacion nuk kishte shumë shënime (më shumë se 90% — lexim). Në përgjithësi, po të ishte e mundur të bëhej një replikë leximi të bazës kryesore në Evropë dhe Azi, do të ishte një zgjidhje kompromisi. Por çfarë është kaq e komplikuar këtu?
E komplikuar ishte se klienti nuk donte të hiqte dorë nga përdorimi i shërbimeve të menaxhuara dhe Cloud SQL. Dhe mundësitë që ofron Cloud SQL në këtë moment janë të kufizuara. Cloud SQL mbështet disponueshmërinë e lartë (HA) dhe Replikat për Lexim (RR), por edhe RR mbështetet vetëm në një rajon. Duke krijuar një bazë të dhënash në rajonin amerikan, nuk mund të bëhej një replikë leximi në rajonin evropian me mjete të Cloud SQL, ndonëse PostgreSQL vetë nuk e pengon këtë. Korrespondenca me punonjësit e Google nuk çoi në asgjë dhe u përfundua me premtime në stilin 'e dimë për problemin dhe po punojmë mbi të, një ditë do të zgjidhet problemi.'
Nëse rendisim mundësitë e Cloud SQL në mënyrë të thjeshtë, ato do të duken më pak kështu:
1. Disponueshmëri e Lartë (HA):
- brenda një rajoni;
- nëpërmjet replikimit të disqeve;
- nuk përdoren mekanizmat e PostgreSQL;
- mundësi për menaxhim automat dhe manual — failover/failback;
- në kalimin e DBMS nuk është i disponueshëm për disa minuta.
2. Read Replica (RR):
- brenda një rajoni;
- hot standby;
- replikimi streaming i PostgreSQL.
Përveç kësaj, siç është zakon, kur zgjedh teknologjinë përballesh gjithmonë me ndonjë kufizim:
- klienti nuk dëshironte të krijonte entitete dhe ta përdorte IaaS, përveç përmes GKE;
- klienti nuk do të donte të zbuste self service PostgreSQL/MySQL;
- po ashtu, Google Spanner do të ishte i përshtatshëm, nëse nuk do ishin çmimi i tij, e vërteta është se me të Django ORM nuk mund të funksionojë, por përndryshe është një gjë e mirë.
Duke marrë parasysh situatën, klienti bëri një pyetje të menjëhershme: "A mund të bëni diçka të ngjashme që të jetë si Google Spanner, por të punojë edhe me Django ORM?"
Zgjidhja e mundshme № 0
E para që më erdhi në mendje:
- të qëndrojmë brenda CloudSQL;
- nuk do të ketë replikim të integruar mes rajoneve në asnjë formë;
- të përpiqemi të lidhim një replikë me Cloud SQL ekzistues nga PostgreSQL;
- diku dhe si të nisim një instancë PostgreSQL, por të paktën të mos prekim masterin.
Fatkeqësisht, rezultoi se nuk mund të bëhej kështu, për shkak se nuk kam qasje në host (ai është krejt në një projekt tjetër) — pg_hba dhe kështu me radhë, dhe gjithashtu nuk ka qasje si superuser.
Zgjidhja e mundshme № 1
Pas disa reflektimeve dhe duke marrë parasysh rrethanat e mëparshme, mënyra e të menduarit ndryshoi disi:
- ende po përpiqemi të mbetemi brenda CloudSQL, por kalojmë në MySQL, sepse Cloud SQL nga MySQL ka një master të jashtëm, i cili:
— është proxy për MySQL-në e jashtme;
— duket si një instancë MySQL;
— është krijuar për migrimin e të dhënave nga re të tjera ose nga On-premises.
Duke qenë se konfigurimi i replikimit të MySQL-it nuk kërkon akses në host, në parim gjithçka funksiononte, por shumë pa stabilitet dhe e shqetësueshme. Dhe kur shkuam më tej, gjithçka u bë edhe më e frikshme, sepse ne po e zhvillonim tërë strukturën me terraform-in, dhe ndoshta ishte e vërtetë që master-i i jashtëm nuk mbështetet nga terraform-i. Po, Google ka CLI, por për një arsye, gjithçka funksiononte ndonjëherë — herë krijohet, herë nuk krijohet. Ndoshta, sepse CLI ishte i krijuar për migrimin e të dhënave nga jashtë, jo për replikat.
Në fakt, këtu u bë e qartë që Cloud SQL nuk është e përshtatshme fare. Siç thonë, ne bëmë gjithçka që mundëm.
Zgjidhja e mundshme № 2
Duke qenë se nuk arritëm të qëndrojmë brenda Cloud SQL, përpiqëm të formulojmë kërkesat për një zgjidhje kompromisi. Kërkesat rezultuan si më poshtë:
- punimi në Kubernetes, maksimalizimi i burimeve dhe mundësive të Kubernetes (DCS, …) dhe GCP (LB, …);
- mungesa e balastit nga një grumbull gjërash të panevojshme në re si HA proxy;
- mundësia për të nisur në rajonin kryesor HA PostgreSQL ose MySQL; në rajonet e tjera — HA nga RR e rajonit kryesor plus një kopje të saj (për besueshmëri);
- multi master (nuk doja ta lidhnim, por nuk ishte shumë e rëndësishme)
.
Si rezultat i këtyre kërkesave, në horizont përfundimisht dolën pmundësi të përshtatshme të DBMS dhe lidhjeve:
- MySQL Galera;
- CockroachDB;
- PostgreSQL tools
:
— pgpool-II;
— Patroni.
MySQL Galera
Teknologjia MySQL Galera është zhvilluar nga Codership dhe është një plugin për InnoDB. Karakteristikat:
- multi master;
- replikimi sinkron;
- leximi nga çdo nyje;
- shkrimi në çdo nyje;
- mekanizmi i integruar HA;
- ka Helm chart nga Bitnami.
CockroachDB
Sipas përshkrimit, kjo është një gjë plotësisht e shkëlqyer dhe përbën një projekt open source, e shkruar në Go. Pjesëmarrësi kryesor është Cockroach Labs (e themeluar nga ish-pjesëtarë të Google). Kjo DB relacional fillimisht është krijuar për t'u shpërndarë (me shkallëzim horizontal 'nga kuti') dhe për të qenë e qëndrueshme. Autorët e saj nga kompania kanë përcaktuar qëllimin 'të kombinojnë pasurinë e funksionalitetit SQL me disponueshmërinë horizontale, të zakonshme për zgjidhjet NoSQL'.
Si një bonus i këndshëm — mbështetje për protokollin e lidhjes PostgreSQL.
Pgpool
Kjo është një shtesë mbi PostgreSQL, në të vërtetë, një entitet i ri që merr të gjitha lidhjet dhe i përpunon ato. Ka balancuesin e vet të ngarkesës dhe parserin, licencohet sipas licencës BSD. Ofron mundësi të gjera, por duket disi shqetësuese, pasi ekzistenca e një entiteti të ri mund të jetë burim i ndonjë aventure shtesë.
Patroni
Ky është momenti i fundit që tërhoqi vëmendjen time, dhe siç u tregua, nuk ishte kot. Patroni është një mjet me kod të hapur që, në thelb, është një demon në Python, i cili lejon menaxhimin automatik të klashtave PostgreSQL me lloje të ndryshme replikimi dhe kalimin automatik të rolleve. Është një gjë shumë interesante, pasi integrohet mirë me Kubernetes dhe nuk sjell asnjë entitet të ri.
Çfarë u zgjodh në fund
Zgjedhja nuk ishte e lehtë:
- CockroachDB — zjarri, por i frikshëm;
- MySQL Galera — gjithashtu i mirë, përdoret shumë, por MySQL;
- Pgpool — shumë entitete ekstra, integrim i dobët me cloudin dhe K8s;
- Patroni — integrim të shkëlqyer me K8s, pa entitete të tepërta, integrohet mirë me GCP LB.
Prandaj, zgjedhja ra mbi Patroni.
Përfundimet
Është koha për të përmbledhur shkurtimisht. Po, bota e infrastrukturës IT ka ndryshuar ndjeshëm, dhe kjo është vetëm fillimi. Nëse më parë përmendjet ishin një lloj tjetër infrastrukture, tani është ndryshe. Për më tepër, inovacionet në cloud vazhdojnë të shfaqen vazhdimisht, do të vazhdojnë të shfaqen dhe, ndoshta, ato do të shfaqen fillimisht në cloud dhe më pas, falë startupeve, do të transferohen në On-premises.
Sa i përket SQL, SQL do të jetojë. Kjo do të thotë se duhet të njohim dhe të punojmë me PostgreSQL dhe MySQL, por është më e rëndësishme të dimë si t'i aplikojmë ato saktësisht.
Burimi: habr.com
