


С Elasticsearch сталкиваются многие. Но что происходит, когда хочешь с его помощью хранить логи «в особо крупном объёме»? Да ещё и безболезненно переживать отказ любого из нескольких дата-центров? Какой стоит делать архитектуру, и на какие подводные камни наткнёшься?
Мы в Одноклассниках решили при помощи elasticsearch решить вопрос лог-менеджмента, а теперь делимся с Хабром опытом: и про архитектуру, и про подводные камни.
Я — Пётр Зайцев, работаю системным администратором в Одноклассниках. До этого тоже был админом, работал с Manticore Search, Sphinx search, Elasticsearch. Возможно, если появится ещё какой-нибудь …search, вероятно буду работать и с ним. Также участвую в ряде опенсорсных проектов на добровольной основе.
Когда я пришёл в Одноклассники, то опрометчиво сказал на собеседовании, что умею работать с Elasticsearch. После того, как освоился и поделал какие-то простенькие задачи, мне подарили большую задачу по реформированию системы лог-менеджмента, существовавшую на тот момент.
Kërkesat
Требования к системе были сформулированы следующим образом:
- В качестве фронтенда должен был использоваться Graylog. Потому что в компании уже был опыт использования этого продукта, программисты и тестировщики его знали, он им был привычен и удобен.
- Объём данных: в среднем 50-80 тысяч сообщений в секунду, но если что-то ломается, то трафик ничем не ограничен, это может быть 2-3 миллиона строк в секунду
- Обсудив с заказчиками требования по скорости обработки поисковых запросов, мы поняли, что типичный паттерн использования подобной системы такой: люди ищут логи своего приложения за последние два дня и не хотят ждать результата на сформулированный запрос больше секунды.
- Админы настаивали на том, чтобы система при необходимости легко масштабировалась, не требуя от них глубокого вникания в то, как она устроена.
- Чтобы единственная задача по обслуживанию, которая этим системам требовалась периодически — это менять какое-то железо.
- Кроме того, в Одноклассниках есть прекрасная техническая традиция: любой сервис, который мы запускаем, должен переживать отказ дата-центра (внезапный, незапланированный и абсолютно в любое время).
Последнее требование в реализации этого проекта далось нам наибольшей кровью, о чём я ещё расскажу подробнее.
Среда
Мы работаем на четырёх дата-центрах, при этом дата-ноды Elasticsearch могут располагаться только в трёх (по ряду нетехнических причин).
В этих четырёх дата-центрах находятся примерно 18 тысяч различных источников логов — железки, контейнеры, виртуальные машины.
Важная особенность: запуск кластера происходит в контейнерах не на физических машинах, а на . Контейнерам гарантируется 2 ядра, аналогичных 2.0Ghz v4 с возможностью утилизации остальных ядер, в случае их простоя.
Иными словами:

Топология
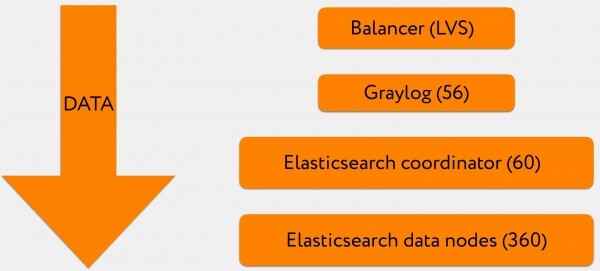
Общий вид решения мне изначально виделся следующим образом:
- 3-4 VIP стоят за А-рекордом домена Graylog, это адрес, на который отсылаются логи.
- каждый VIP представляет из себя балансировщик LVS.
- После него логи попадают на батарею Graylog, часть данных идёт в формате GELF, часть в формате syslog.
- Дальше всё это большими батчами пишется в батарею из координаторов Elasticsearch.
- А они, в свою очередь, отправляют запросы на запись и чтение на релевантные дата-ноды.
Termat
Возможно, не все подробно разбираются в терминологии, поэтому хотелось бы немного остановиться на ней.
В Elasticsearch есть несколько типов нод — master, coordinator, data node. Есть ещё два других типа для разных преобразований логов и связи разных кластеров между собой, но мы использовали только перечисленные.
Master
Пингует все присутствующие в кластере ноды, поддерживает актуальную карту кластера и распространяет её между нодами, обрабатывает событийную логику, занимается разного рода cluster wide housekeeping.
Coordinator
Выполняет одну-единственную задачу: принимает запросы от клиентов на чтение или запись и маршрутизирует этот трафик. В случае, если запрос на запись, скорее всего, он спросит master, в какой шард релевантного индекса ему это положить, и перенаправит запрос дальше.
Data node
Хранит данные, выполняет, прилетающие из вне, поисковые запросы и операции над расположенными на ней шардами.
Graylog
Это что-то вроде сплава Kibana с Logstash в ELK-стэке. Graylog совмещает в себе и UI и конвейер по обработке логов. Под капотом в Graylog работают Kafka и Zookeeper, которые обеспечивают связность Graylog как кластера. Graylog умеет кэшировать логи (Kafka) на случай недоступности Elasticsearch и повторять неудачные запросы на чтение и запись, группировать и маркировать по задаваемым правилам логи. Как и Logstash, Graylog имеет функциональность по модификации строк перед записью в Elasticsearch.
Кроме того, в Graylog есть встроенный service discovery, позволяющий на основе одной доступной ноды Elasticsearch получить всю карту кластера и отфильтровать её по определённому тегу, что даёт возможность направлять запросы на определённые контейнеры.
Визуально это выглядит примерно так:

Это скриншот с конкретного инстанса. Здесь мы по поисковому запросу выстраиваем гистограмму, выводим релевантные строки.
Indeksat
Возвращаясь к архитектуре системы, я бы хотел детальнее остановиться на том, как мы строили модель индексов, чтобы всё это работало корректно.
На приведённой ранее схеме это самый нижний уровень: Elasticsearch data nodes.
Индекс — это большая виртуальная сущность, состоящая из шардов Elasticsearch. Сам по себе каждый из шардов является ни чем иным, как Lucene index. А каждый Lucene index, в свою очередь, состоит и одного или более сегментов.
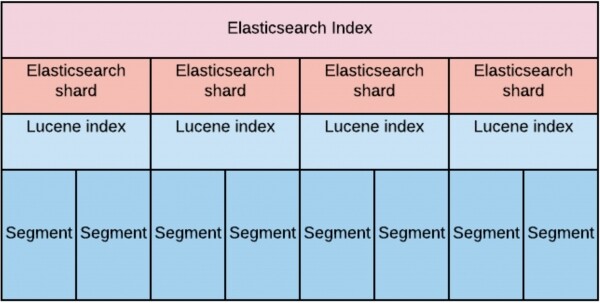
При проектировании мы прикидывали, что для обеспечения требования по скорости чтения на большом объёме данных нам необходимо равномерно «размазать» эти данные по дата-нодам.
Это вылилось в то, что количество шардов на индекс (с репликами) у нас должно быть строго равно количеству дата-нод. Во-первых, для того, чтобы обеспечить replication factor, равный двум (то есть мы можем потерять половину кластера). А, во-вторых, для того, чтобы запросы на чтение и запись обрабатывать, как минимум, на половине кластера.
Время хранения мы определили сперва как 30 дней.
Распределение шардов можно представить графически следующим образом:

Весь тёмно-серый прямоугольник целиком — это индекс. Левый красный квадрат в нём — это primary-шард, первый в индексе. А голубой квадрат — это replica-шард. Они находятся в разных дата-центрах.
Когда мы добавляем ещё один шард, он попадает в третий дата-центр. И, в конце концов, мы получаем вот такую структуру, которая обеспечивает возможность потери ДЦ без потери консистентности данных:

Ротацию индексов, т.е. создание нового индекса и удаление наиболее старого, мы сделали равной 48 часов (по паттерну использования индекса: по последним 48 часам ищут чаще всего).
Такой интервал ротации индексов связан со следующими причинами:
Когда на конкретную дата-ноду прилетает поисковый запрос, то, с точки зрения перформанса выгодней, когда опрашивается один шард, если его размер сопоставим с размером хипа ноды. Это позволяет держать “горячую” часть индекса в хипе и быстро к ней обращаться. Когда “горячих частей” становится много, то деградирует скорость поиска по индексу.
Когда нода начинает выполнять поисковой запрос на одном шарде, она выделяет кол-во тредов, равное количеству гипертрединговых ядер физической машины. Если поисковый запрос затрагивает большое кол-во шардов, то кол-во тредов растёт пропорционально. Это плохо отражается на скорости поиска и негативно сказывается на индексации новых данных.
Чтобы обеспечить необходимый latency поиска, мы решили использовать SSD. Для быстрой обработки запросов машины, на которых размещались эти контейнеры, должны были обладать по меньшей мере 56 ядрами. Цифра в 56 выбрана как условно-достаточная величина, определяющая количество тредов, которые будет порождать Elasticsearch в процессе работы. В Elasitcsearch многие параметры thread pool напрямую зависят от количества доступных ядер, что в свою очередь прямо влияет на необходимое кол-во нод в кластере по принципу "меньше ядер — больше нод".
В итоге у нас получилось, что в среднем шард весит где-то 20 гигабайт, и на 1 индекс приходится 360 шардов. Соответственно, если мы их ротируем раз в 48 часов, то у нас их 15 штук. Каждый индекс вмещает в себя данные за 2 дня.
Схемы записи и чтения данных
Давайте разберёмся, как в этой системе записываются данные.
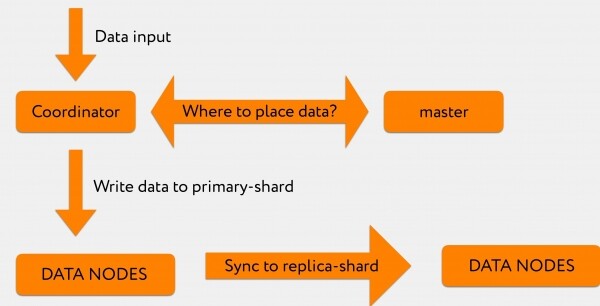
Допустим, у нас из Graylog прилетает в координатор какой-то запрос. Например, мы хотим проиндексировать 2-3 тысячи строк.
Координатор, получив от Graylog запрос, опрашивает мастер: «В запросе на индексацию у нас был конкретно указан индекс, но в который шард это писать — не указано».
Master отвечает: «Запиши эту информацию в шард номер 71», после чего она направляется непосредственно в релевантную дата-ноду, где находится primary-shard номер 71.
После чего лог транзакций реплицируется на replica-shard, который находится уже в другом дата-центре.
Из Graylog в координатор прилетает поисковый запрос. Координатор перенаправляет его по индексу, при этом Elasticsearch по принципу round-robin распределяет запросы между primary-shard и replica-shard.
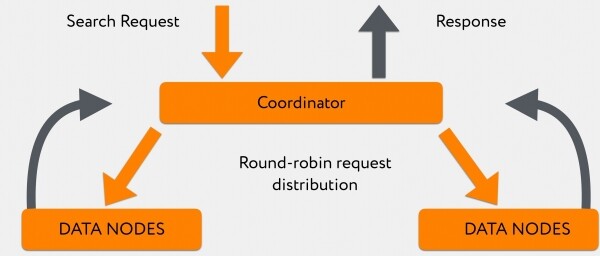
Ноды в количестве 180 штук отвечают неравномерно, и, пока они отвечают, координатор копит информацию, которую в него уже «выплюнули» более быстрые дата-ноды. После этого, когда либо вся информация пришла, либо по запросу достигнут таймаут, отдаёт всё непосредственно клиенту.
Вся эта система в среднем отрабатывает поисковые запросы по последним 48 часам за 300-400ms, исключая те запросы, которые с leading wildcard.
«Цветочки» с Elasticsearch: настройка Java

Чтобы всё это заработало так, как мы изначально хотели, мы очень долго отлаживали самые разнообразные вещи в кластере.
Первая часть обнаруженных проблем была связана с тем, как в Elasticsearch по дефолту преднастроена Java.
Problemi i parë
Мы наблюдали очень большое количество сообщений о том, что у нас на уровне Lucene, когда запущены background job’ы, мерджи сегментов Lucene завершаются с ошибкой. При этом в логах было видно, что это OutOfMemoryError-ошибка. По телеметрии мы видели, что хип свободен, и не было понятно, почему эта операция падает.
Выяснилось, что мерджи Lucene-индексов происходят вне хипа. А контейнеры довольно жёстко ограничены по потребляемым ресурсам. В эти ресурсы влезал только хип (значение heap.size было примерно равно RAM), а какие-то off-heap операции падали с ошибкой аллокации памяти, если по какой-то причине не укладывались в те ~500MB, что оставались до лимита.
Фикс был довольно тривиальным: доступный для контейнера объём RAM увеличили, после чего забыли о том, что такие проблемы у нас вообще были.
Problemi i dytë
Дня через 4-5 после запуска кластера мы заметили, что дата-ноды начинают периодически вываливаться из кластера и заходить в него секунд через 10-20.
Когда полезли разбираться, выяснилось, что эта самая off-heap память в Elasticsearch не контролируется практически никак. Когда мы контейнеру отдали больше памяти, мы получили возможность наполнять direct buffer pools различной информацией, и она очищалась только после того, как запускался explicit GC со стороны Elasticsearch.
В ряде случаев эта операция происходила довольно-таки долго, и за это время кластер успевал пометить эту ноду как уже вышедшую. Эта проблема хорошо описана .
Решение было следующим: мы ограничили Java возможность использовать основную часть памяти вне хипа под эти операции. Мы лимитировали её до 16 гигабайт (-XX:MaxDirectMemorySize=16g), добившись того, что explicit GC вызывался значительно чаще, а отрабатывал значительно быстрее, перестав тем самым дестабилизировать кластер.
Проблема третья
Если вы думаете, что проблемы с «нодами, покидающими кластер в самый непредвиденный момент» на этом кончились, вы ошибаетесь.
Когда мы конфигурировали работу с индексами, мы остановили свой выбор на mmapfs, чтобы по свежим шардам с большой сегментированностью. Это было довольно грубой ошибкой, потому что при использовании mmapfs файл маппится в оперативную память, а дальше мы работаем уже с mapped-файлом. Из-за этого получается, что при попытке GC остановить треды в приложении мы очень долго идём в safepoint, и по дороге к нему приложение перестает отвечать на запросы мастера о том, живое ли оно. Соответственно, master считает, что нода у нас больше в кластере не присутствует. После этого спустя секунд 5-10 отрабатывает garbage collector, нода оживает, снова заходит в кластер и начинает инициализацию шардов. Всё это сильно напоминало “продакшен, который мы заслужили” и не годилось для чего-либо серьёзного.
Чтобы избавиться от такого поведения, мы сперва перешли на стандартный niofs, а после, когда с пятых версий Elastic отмигрировались на шестые, попробовали hybridfs, где данная проблема не воспроизводилась. Подробней про типы стореджа можно почитать .
Проблема четвёртая
Потом была еще очень занимательная проблема, которую мы лечили рекордно долго. Мы ловили её 2-3 месяца, потому что был абсолютно непонятен её паттерн.
Иногда у нас координаторы уходили в Full GC, обычно где-то после обеда, и оттуда уже не возвращались. При этом при логировании задержки GC это выглядело так: у нас всё идет хорошо, хорошо, хорошо, а потом раз — и всё резко плохо.
Сперва мы думали, что у нас есть злой юзер, который запускает какой-то запрос, выбивающий координатор из рабочего режима. Очень долго логировали запросы, пытаясь выяснить, что происходит.
В итоге выяснилось, что в тот момент, когда какой-нибудь пользователь запускает большущий запрос, и он попадает на какой-то конкретный координатор Elasticsearch, некоторые ноды отвечают дольше, чем остальные.
И то время, пока координатор ждёт ответа всех нод, он копит в себе результаты, присланные с уже ответивших нод. Для GC это означает, что у нас очень быстро меняется паттерн использования хипа. И тот GC, который мы использовали, с этой задачей не справлялся.
Единственный фикс, который мы нашли для того, чтобы изменить поведение кластера в такой ситуации — миграция на JDK13 и использование сборщика мусора Shenandoah. Это решило проблему, координаторы у нас падать перестали.
На этом проблемы с Java закончились и начались проблемы с пропускной способностью.
«Ягодки» с Elasticsearch: пропускная способность

Проблемы с пропускной способностью означают, что наш кластер работает стабильно, но на пиках кол-ва индексируемых документов и в момент манёвров производительность недостаточная.
Первый встреченный симптом: при каких-то «взрывах» на продакшене, когда резко генерируется очень большое количество логов, в Graylog начинает часто мелькать ошибка индексации es_rejected_execution.
Это происходило из-за того, что thread_pool.write.queue на одной дата-ноде до момента, как Elasticsearch сумеет обработать запрос на индексацию и закинуть информацию в шард на диск, по дефолту умеет кэшировать только 200 запросов. И в об этом параметре говорится крайне мало. Указывается только предельное кол-во тредов и дефолтный размер.
Разумеется, мы пошли крутить это значение и выяснили следующее: конкретно в нашем сетапе довольно хорошо кешируется до 300 запросов, а большее значение чревато тем, что мы снова улетаем в Full GC.
Кроме того, поскольку это пачки сообщений, которые прилетают в рамках одного запроса, то надо было ещё подкрутить Graylog для того, чтобы он писал не часто и мелкими батчами, а огромными батчами или раз в 3 секунды, если батч всё ещё не полон. В таком случае получается, что информация, которую мы в Elasticsearch пишем, становится доступной не через две секунды, а через пять (что нас вполне устраивает), но уменьшается количество ретраев, которые приходится сделать, чтобы пропихнуть большую пачку информации.
Это особенно важно в те моменты, когда у нас что-то где-то упало и яростно об этом сообщает, чтобы не получать полностью заспамленный Elastic, а через какое-то время — неработоспособные из-за забившихся буферов ноды Graylog.
Кроме того, когда у нас происходили эти самые взрывы на продакшене, у нас приходили жалобы от программистов и тестировщиков: в тот момент, когда им очень нужны эти логи, они выдаются им очень медленно.
Стали разбираться. С одной стороны, было понятно, что и поисковые запросы, и запросы на индексацию отрабатывают, по сути, на одних и тех же физических машинах, и так или иначе определённые просадки будут.
Но это можно было частично обойти за счёт того, что в шестых версиях Elasticsearch появился алгоритм, позволяющий распределять запросы между релевантными дата-нодами не по случайному принципу round-robin (контейнер, который занимается индексацией и держит primary-shard, может быть очень занят, там не будет возможности ответить быстро), а направить этот запрос на менее загруженный контейнер с replica-shard, который ответит значительно быстрее. Иными словами, мы пришли к use_adaptive_replica_selection: true.
Картина чтения начинает выглядеть так:
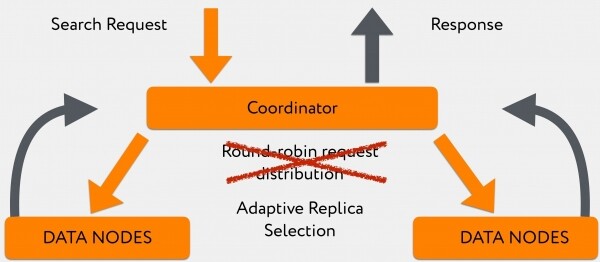
Переход на этот алгоритм позволил заметно улучшить query time в те моменты, когда у нас шёл большой поток логов на запись.
Наконец, основная проблема заключалась в безболезненном выведении дата-центра.
Чего мы хотели от кластера сразу после потери связи с одним ДЦ:
- Если у нас в отвалившемся дата-центре находится текущий master, то он будет перевыбран и переедет как роль на другую ноду в другом ДЦ.
- Мастер быстро выкинет из кластера все недоступные ноды.
- На основе оставшихся он поймет: в потерявшемся дата-центре у нас были такие-то primary-шарды, быстро запромоутит комплиментарные replica-шарды в оставшихся дата-центрах, и у нас продолжится индексация данных.
- В результате этого у нас будет плавно деградировать пропускная способность кластера на запись и чтение, однако в целом всё будет работать хоть и медленно, но стабильно.
Как выяснилось, хотели мы чего-то вот такого:

А получили следующее:

Как так получилось?
В момент падения дата-центра у нас узким местом стал мастер.
Pse?
Дело в том, что в мастере есть TaskBatcher, отвечающий за распространение в кластере определённых задач, ивентов. Любой выход ноды, любое продвижение шарда из replica в primary, любая задача на создание где-то какого-то шарда — всё это попадает сперва в TaskBatcher, где обрабатывается последовательно и в один поток.
В момент вывода одного дата-центра получалось, что все дата-ноды в выживших дата-центрах считали своим долгом сообщить мастеру «у нас потерялись такие-то шарды и такие-то дата-ноды».
При этом выжившие дата-ноды засылали всю эту информацию текущему мастеру и пытались дождаться подтверждения, что он её принял. Этого они не дожидались, так как мастер получал задачи быстрей, чем успел отвечать. Ноды по таймауту повторяли запросы, а мастер в это время уже даже не пытался отвечать на них, а был полностью поглощён задачей сортировки запросов по приоритетности.
В терминальном виде получалось, что дата-ноды спамили мастера до того, что он уходил в full GC. После этого у нас роль мастера переезжала на какую-то следующую ноду, с ней происходило абсолютно то же самое, и в итоге кластер разваливался полностью.
Мы делали измерения, и до версии 6.4.0, где это было пофикшено, нам было достаточно вывести одновременно вывести всего лишь 10 дата-нод из 360 для того, чтобы полностью положить кластер.
Выглядело это примерно вот так:

После версии 6.4.0, где починили этот стрёмный баг, дата-ноды перестали убивать мастера. Но «умнее» он от этого не стал. А именно: когда мы выводим 2, 3 или 10 (любое количество, отличное от единицы) дата-нод, мастер получает какое-то первое сообщение, которое говорит, что нода А вышла, и пытается рассказать об этом ноде B, ноде C, ноде D.
И на текущий момент с этим можно бороться только установкой тайм-аута на попытки кому-то о чём-то рассказать, равные где-то 20-30 секундам, и таким образом управлять скоростью вывода дата-центра из кластера.
В принципе, это укладывается в те требования, которые изначально были предъявлены к конечному продукту в рамках проекта, но с точки зрения «чистой науки» это баг. Который, кстати, был успешно пофикшен разработчиками в версии 7.2.
Причём, когда некая дата-нода выходила, получалось, что распространить информацию о её выходе важнее, чем рассказать всему кластеру, что на ней находились такие-то primary-shard (чтобы запромоутить replica-shard в другом дата-центре в primary, и в них можно было писать информацию).
Поэтому, когда уже всё «отгремело», вышедшие дата-ноды не маркируются как stale немедленно. Соответственно, мы вынуждены ждать, когда оттаймаутятся все пинги до вышедших дата-нод и только после этого наш кластер начинает рассказывать о том, что там-то, там-то и там-то надо продолжить запись информации. Более подробно можно почитать об этом .
В итоге операция вывода дата-центра у нас сегодня занимает около 5 минут в час пик. Для настолько большой и неповоротливой махины это довольно хороший результат.
В итоге мы пришли к следующему решению:
- У нас 360 дата-нод с дисками на 700 гигабайт.
- 60 координаторов для роутинга трафика по этим самым дата-нодам.
- 40 мастеров, которые у нас остались как некое наследие со времён версий до 6.4.0 — чтобы пережить вывод дата-центра, мы морально были готовы потерять несколько машин, чтобы гарантированно даже при худшем сценарии иметь кворум мастеров
- Любые попытки совмещения ролей на одном контейнере у нас упирались в то, что рано или поздно нода ломалось под нагрузкой.
- Во всём кластере используется heap.size, равный 31 гигабайту: все попытки уменьшить размер приводили к тому, что на тяжёлых поисковых запросах с leading wildcard либо убивал какие-то ноды, либо прибивался circuit breaker в самом Elasticsearch.
- Кроме того, для обеспечения производительности поиска мы старались держать количество объектов в кластере минимально возможным, чтобы обрабатывать как можно меньше событий в самом узком месте, которое у нас получилось в мастере.
Напоследок о мониторинге
Чтобы всё это работало так, как задумывалось, мы мониторим следующее:
- Каждая дата-нода сообщает в наше облако, что она есть, и на ней находятся такие-то шарды. Когда мы где-то что-то тушим, кластер через 2-3 секунды рапортует, что в центре А мы потушили ноду 2, 3, и 4 — это означает, что в других дата-центрах мы ни в коем случае не можем тушить те ноды, на которых остались шарды в единственном экземпляре.
- Зная характер поведения мастера, мы очень внимательно смотрим на количество pending-задач. Потому что даже одна зависшая задача, если вовремя не оттаймаутится, теоретически в какой-то экстренной ситуации способна стать той причиной, по которой у нас не отработает, допустим, промоушен replica-шарда в primary, из-за чего встанет индексация.
- Также мы очень пристально смотрим на задержки garbage collector, потому что у нас с этим уже были большие сложности при оптимизации.
- Реджекты по тредам, чтобы понимать заранее, где находится «бутылочное горло».
- Ну и стандартные метрики, типа heap, RAM и I/O.
При построении мониторинга обязательно надо учитывать особенности Thread Pool в Elasticsearch. описывает возможности настройки и дефолтные значения для поиска, индексации, но полностью умалчивает о thread_pool.management.Эти треды обрабатывают, в частности, запросы типа _cat/shards и другие аналогичные, которые удобно использовать при написании мониторинга. Чем больше кластер, тем больше таких запросов выполняется в единицу времени, а вышеупомянутый thread_pool.management мало того, что не представлен в официальной документации, так ещё и лимитирован по дефолту 5 тредами, что очень быстро утилизируется, после чего мониторинг перестаёт работать корректно.
Что хочется сказать в заключение: у нас получилось! Мы сумели дать нашим программистам и разработчикам инструмент, который практически в любой ситуации способен быстро и достоверно предоставить информацию о происходящем на продакшене.
Да, это получилось довольно-таки сложно, но, тем не менее, наши хотелки удалось уложить в уже существующие продукты, которые при этом не пришлось патчить и переписывать под себя.

Burimi: habr.com
