

Disa kohë më parë, ne u përballëm me pyetjen e zgjedhjes së një mjeti ETL për të punuar me Big Data. Zgjidhja e përdorur më parë Informatica BDM nuk na përshtatej për shkak të funksionalitetit të kufizuar. Përdorimi i tij është reduktuar në një kornizë për lëshimin e komandave me shkëndijë. Nuk kishte shumë analoge në treg që, në parim, ishin në gjendje të punonin me vëllimin e të dhënave me të cilat ne trajtojmë çdo ditë. Në fund zgjodhëm Ab Initio. Gjatë demonstrimeve pilot, produkti tregoi shpejtësi shumë të lartë të përpunimit të të dhënave. Nuk ka pothuajse asnjë informacion për Ab Initio në Rusisht, kështu që vendosëm të flasim për përvojën tonë në Habré.
Ab Initio ka shumë transformime klasike dhe të pazakonta, kodi i të cilave mund të zgjerohet duke përdorur gjuhën e tij PDL. Për një biznes të vogël, një mjet kaq i fuqishëm ka të ngjarë të jetë i tepërt dhe shumica e aftësive të tij mund të jenë të shtrenjta dhe të papërdorura. Por nëse shkalla juaj është afër Sberov, atëherë Ab Initio mund të jetë interesant për ju.
Ndihmon një biznes të grumbullojë njohuri globalisht dhe të zhvillojë një ekosistem, dhe një zhvillues të përmirësojë aftësitë e tij në ETL, të përmirësojë njohuritë e tij në guaskë, ofron mundësinë për të zotëruar gjuhën PDL, jep një pamje vizuale të proceseve të ngarkimit dhe thjeshton zhvillimin për shkak të bollëkut të komponentëve funksionalë.
Në këtë postim do të flas për aftësitë e Ab Initio dhe do të jap karakteristikat krahasuese të punës së tij me Hive dhe GreenPlum.
- Përshkrimi i kornizës MDW dhe puna për personalizimin e tij për GreenPlum
- Krahasimi i performancës Ab Initio midis Hive dhe GreenPlum
- Punoni Ab Initio me GreenPlum në modalitetin afër kohë reale
Funksionaliteti i këtij produkti është shumë i gjerë dhe kërkon shumë kohë për t'u studiuar. Megjithatë, me aftësitë e duhura të punës dhe cilësimet e duhura të performancës, rezultatet e përpunimit të të dhënave janë shumë mbresëlënëse. Përdorimi i Ab Initio për një zhvillues mund të sigurojë një përvojë interesante. Ky është një pamje e re e zhvillimit të ETL, një hibrid midis një mjedisi vizual dhe zhvillimit të shkarkimit në një gjuhë të ngjashme me skriptin.
Bizneset po zhvillojnë ekosistemet e tyre dhe ky mjet është i dobishëm më shumë se kurrë. Me Ab Initio, ju mund të grumbulloni njohuri për biznesin tuaj aktual dhe t'i përdorni këto njohuri për të zgjeruar dhe hapur biznese të reja. Alternativat për Ab Initio përfshijnë mjediset e zhvillimit vizual Informatica BDM dhe mjediset e zhvillimit jo-vizual Apache Spark.
Përshkrimi i Ab Initio
Ab Initio, si mjetet e tjera ETL, është një koleksion produktesh.

Ab Initio GDE (Graphical Development Environment) është një mjedis për zhvilluesin në të cilin ai konfiguron transformimet e të dhënave dhe i lidh ato me rrjedhat e të dhënave në formën e shigjetave. Në këtë rast, një grup i tillë transformimesh quhet grafik:
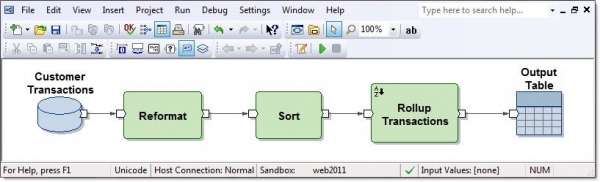
Lidhjet hyrëse dhe dalëse të komponentëve funksionalë janë porte dhe përmbajnë fusha të llogaritura brenda transformimeve. Disa grafikë të lidhur me rrjedha në formën e shigjetave në rendin e ekzekutimit të tyre quhen plan.
Ka disa qindra komponentë funksionalë, që është shumë. Shumë prej tyre janë shumë të specializuara. Aftësitë e transformimeve klasike në Ab Initio janë më të gjera se në mjetet e tjera ETL. Për shembull, Join ka dalje të shumta. Përveç rezultatit të lidhjes së grupeve të të dhënave, mund të merrni regjistrime dalëse të grupeve të të dhënave hyrëse, çelësat e të cilëve nuk mund të lidheshin. Ju gjithashtu mund të merrni refuzime, gabime dhe një regjistër të operacionit të transformimit, i cili mund të lexohet në të njëjtën kolonë si një skedar teksti dhe të përpunohet me transformime të tjera:
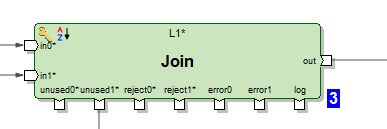
Ose, për shembull, mund të materializoni një marrës të dhënash në formën e një tabele dhe të lexoni të dhëna prej tij në të njëjtën kolonë.
Ka transformime origjinale. Për shembull, transformimi Scan ka funksionalitet të ngjashëm me funksionet analitike. Ka transformime me emra vetë-shpjegues: Krijo të dhëna, Lexo Excel, Normalizo, Rendit brenda grupeve, Ekzekuto programin, Ekzekuto SQL, Bashkohu me DB, etj. Grafikët mund të përdorin parametrat e kohës së ekzekutimit, duke përfshirë mundësinë e kalimit të parametrave nga ose në sistemi operativ. Skedarët me një grup të gatshëm parametrash të kaluar në grafik quhen grupe parametrash (pset).
Siç pritej, Ab Initio GDE ka depon e vet të quajtur EME (Enterprise Meta Environment). Zhvilluesit kanë mundësinë të punojnë me versionet lokale të kodit dhe të kontrollojnë zhvillimet e tyre në depon qendrore.
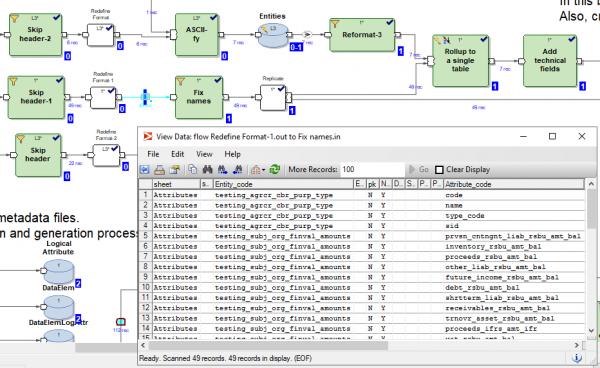
Është e mundur, gjatë ekzekutimit ose pas ekzekutimit të grafikut, të klikoni në çdo rrjedhë që lidh transformimin dhe të shikoni të dhënat që kaluan midis këtyre transformimeve:
Është gjithashtu e mundur të klikoni në çdo transmetim dhe të shihni detajet e gjurmimit - në sa paralele ka funksionuar transformimi, sa rreshta dhe bajt janë ngarkuar në cilën prej paraleleve:
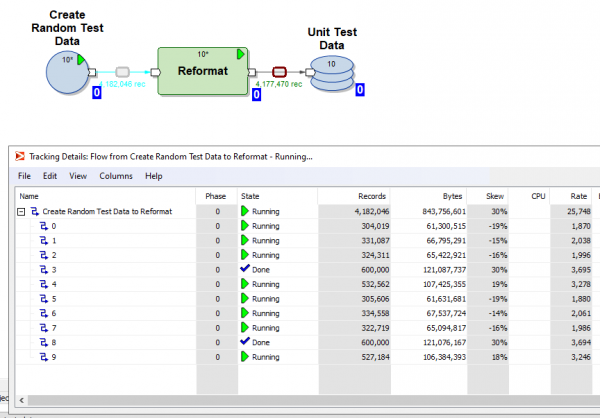
Është e mundur që ekzekutimi i grafikut të ndahet në faza dhe të shënohet se disa transformime duhet të kryhen fillimisht (në fazën zero), të tjerat në fazën e parë, të tjerat në fazën e dytë, etj.
Për secilin transformim, mund të zgjidhni paraqitjen (ku do të ekzekutohet): pa përpunim paralel ose në fije paralele, numri i të cilave mund të specifikohet. Skedarët e përkohshëm të krijuar nga Ab Initio gjatë ekzekutimit të transformimit mund të vendosen në sistemin e skedarëve. server, si dhe në HDFS.
Në çdo transformim, bazuar në shabllonin e paracaktuar, mund të krijoni skriptin tuaj në PDL, i cili është paksa si një guaskë.
Me PDL mund të zgjeroni funksionalitetin e transformimeve dhe, në veçanti, mund të gjeneroni në mënyrë dinamike (në kohën e ekzekutimit) fragmente të kodit arbitrar në varësi të parametrave të kohës së ekzekutimit.
Ab Initio gjithashtu ka një integrim të zhvilluar mirë me sistemin operativ përmes shell. Në mënyrë të veçantë, Sberbank përdor linux ksh. Ju mund të shkëmbeni variabla me shell dhe t'i përdorni ato si parametra të grafikut. Ju mund të telefononi ekzekutimin e grafikëve Ab Initio nga shell dhe të administroni Ab Initio.
Përveç Ab Initio GDE, shumë produkte të tjera janë të përfshira në dërgesë. Ekziston sistemi i tij i bashkëpunimit me pretendimin se quhet sistem operativ. Ekziston një Control>Center ku mund të planifikoni dhe monitoroni rrjedhat e shkarkimit. Ka produkte për të bërë zhvillim në një nivel më primitiv sesa lejon Ab Initio GDE.
Përshkrimi i kornizës MDW dhe puna për personalizimin e tij për GreenPlum
Së bashku me produktet e tij, shitësi furnizon produktin MDW (Metadata Driven Warehouse), i cili është një konfigurues grafiku i krijuar për të ndihmuar me detyrat tipike të popullimit të depove të të dhënave ose kasafortave të të dhënave.
Ai përmban analizues të meta të dhënave të personalizuara (specifik për projektin) dhe gjeneratorë të gatshëm të kodit jashtë kutisë.
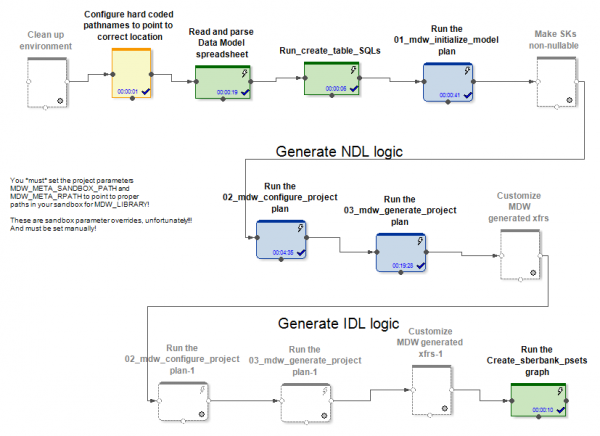
Si hyrje, MDW merr një model të dhënash, një skedar konfigurimi për vendosjen e një lidhjeje me një bazë të dhënash (Oracle, Teradata ose Hive) dhe disa cilësime të tjera. Pjesa specifike e projektit, për shembull, vendos modelin në një bazë të dhënash. Pjesa jashtë kutisë së produktit gjeneron grafikë dhe skedarë konfigurimi për ta duke ngarkuar të dhënat në tabelat e modeleve. Në këtë rast, grafikët (dhe psetet) krijohen për disa mënyra të fillimit dhe punës në rritje në përditësimin e entiteteve.
Në rastet e Hive dhe RDBMS, krijohen grafikë të ndryshëm për inicializimin dhe përditësimet në rritje të të dhënave.
Në rastin e Hive, të dhënat delta hyrëse lidhen përmes Ab Initio Join me të dhënat që ishin në tabelë përpara përditësimit. Ngarkuesit e të dhënave në MDW (si në Hive ashtu edhe në RDBMS) jo vetëm që futin të dhëna të reja nga delta, por gjithashtu mbyllin periudhat e rëndësisë së të dhënave, çelësat kryesorë të të cilëve morën deltën. Përveç kësaj, ju duhet të rishkruani pjesën e pandryshuar të të dhënave. Por kjo duhet bërë sepse Hive nuk ka operacione fshirjeje ose përditësimi.
Në rastin e RDBMS, grafikët për përditësimin në rritje të të dhënave duken më optimale, sepse RDBMS kanë aftësi reale të përditësimit.
Delta e marrë ngarkohet në një tabelë të ndërmjetme në bazën e të dhënave. Pas kësaj, delta lidhet me të dhënat që ishin në tabelë para përditësimit. Dhe kjo bëhet duke përdorur SQL duke përdorur një pyetje të krijuar SQL. Më pas, duke përdorur komandat SQL delete+insert, të dhënat e reja nga delta futen në tabelën e synuar dhe mbyllen periudhat e rëndësisë së të dhënave, çelësat kryesorë të të cilëve kanë marrë delta.
Nuk ka nevojë të rishkruhen të dhënat e pandryshuara.
Pra, arritëm në përfundimin se në rastin e Hive, MDW duhet të shkojë për të rishkruar të gjithë tabelën sepse Hive nuk ka një funksion përditësimi. Dhe asgjë më mirë se rishkrimi i plotë i të dhënave kur është shpikur përditësimi. Në rastin e RDBMS, përkundrazi, krijuesit e produktit e panë të nevojshme t'i besonin lidhjen dhe përditësimin e tabelave përdorimit të SQL.
Për një projekt në Sberbank, ne krijuam një zbatim të ri, të ripërdorshëm të një ngarkuesi të bazës së të dhënave për GreenPlum. Kjo është bërë në bazë të versionit që MDW gjeneron për Teradata. Ishte Teradata, dhe jo Oracle, ajo që iu afrua dhe më së miri për këtë, sepse... është gjithashtu një sistem MPP. Metodat e punës, si dhe sintaksa, e Teradata dhe GreenPlum rezultuan të jenë të ngjashme.
Shembuj të dallimeve kritike për MDW ndërmjet RDBMS-ve të ndryshme janë si më poshtë. Në GreenPlum, ndryshe nga Teradata, kur krijoni tabela duhet të shkruani një klauzolë
distributed byTeradata shkruan:
delete <table> all, dhe në GreenPlum ata shkruajnë
delete from <table>Në Oracle, për qëllime optimizimi ata shkruajnë
delete from t where rowid in (<соединение t с дельтой>), dhe Teradata dhe GreenPlum shkruajnë
delete from t where exists (select * from delta where delta.pk=t.pk)Vëmë re gjithashtu se që Ab Initio të punonte me GreenPlum, ishte e nevojshme të instalohej klienti GreenPlum në të gjitha nyjet e grupit Ab Initio. Kjo është për shkak se ne u lidhëm me GreenPlum njëkohësisht nga të gjitha nyjet në grupin tonë. Dhe në mënyrë që leximi nga GreenPlum të jetë paralel dhe çdo fill paralel Ab Initio të lexojë pjesën e vet të të dhënave nga GreenPlum, ne duhej të vendosnim një ndërtim të kuptuar nga Ab Initio në seksionin "where" të pyetjeve SQL.
where ABLOCAL()dhe përcaktoni vlerën e këtij konstruksioni duke specifikuar leximin e parametrave nga baza e të dhënave të transformimit
ablocal_expr=«string_concat("mod(t.", string_filter_out("{$TABLE_KEY}","{}"), ",", (decimal(3))(number_of_partitions()),")=", (decimal(3))(this_partition()))», e cila përpilohet në diçka si
mod(sk,10)=3, d.m.th. ju duhet të nxisni GreenPlum me një filtër të qartë për secilën ndarje. Për bazat e tjera të të dhënave (Teradata, Oracle), Ab Initio mund ta kryejë këtë paralelizim automatikisht.
Krahasimi i performancës Ab Initio midis Hive dhe GreenPlum
Sberbank kreu një eksperiment për të krahasuar performancën e grafikëve të krijuar nga MDW në lidhje me Hive dhe në lidhje me GreenPlum. Si pjesë e eksperimentit, në rastin e Hive kishte 5 nyje në të njëjtin grup si Ab Initio, dhe në rastin e GreenPlum kishte 4 nyje në një grup të veçantë. Ato. Hive kishte disa avantazhe harduerike ndaj GreenPlum.
Ne konsideruam dy palë grafikësh që kryejnë të njëjtën detyrë të përditësimit të të dhënave në Hive dhe GreenPlum. Në të njëjtën kohë, grafikët e gjeneruar nga konfiguruesi MDW u lansuan:
- ngarkesa fillestare + ngarkesa në rritje e të dhënave të krijuara rastësisht në një tabelë Hive
- ngarkesa fillestare + ngarkesa në rritje e të dhënave të krijuara rastësisht në të njëjtën tabelë GreenPlum
Në të dyja rastet (Hive dhe GreenPlum) ata kryen ngarkime në 10 fije paralele në të njëjtin grup Ab Initio. Ab Initio ruajti të dhëna të ndërmjetme për llogaritjet në HDFS (për sa i përket Ab Initio, u përdor faqosja e MFS duke përdorur HDFS). Një linjë e të dhënave të krijuara rastësisht zinte 200 bajt në të dyja rastet.
Rezultati ishte si ky:
Zgjua:
Ngarkimi fillestar në Hive
Rreshtat janë futur
6 000 000
60 000 000
600 000 000
Kohëzgjatja e inicializimit
shkarkime në sekonda
41
203
1 601
Ngarkimi në rritje në Hive
Numri i rreshtave të disponueshëm në
tabela e synuar në fillim të eksperimentit
6 000 000
60 000 000
600 000 000
Numri i linjave delta të aplikuara në
tabela e synuar gjatë eksperimentit
6 000 000
6 000 000
6 000 000
Kohëzgjatja e rritjes
shkarkime në sekonda
88
299
2 541
Kumbulla e gjelbër:
Ngarkimi fillestar në GreenPlum
Rreshtat janë futur
6 000 000
60 000 000
600 000 000
Kohëzgjatja e inicializimit
shkarkime në sekonda
72
360
3 631
Ngarkimi në rritje në GreenPlum
Numri i rreshtave të disponueshëm në
tabela e synuar në fillim të eksperimentit
6 000 000
60 000 000
600 000 000
Numri i linjave delta të aplikuara në
tabela e synuar gjatë eksperimentit
6 000 000
6 000 000
6 000 000
Kohëzgjatja e rritjes
shkarkime në sekonda
159
199
321
Ne shohim se shpejtësia e ngarkimit fillestar si në Hive ashtu edhe në GreenPlum varet linearisht nga sasia e të dhënave dhe, për arsye të harduerit më të mirë, është pak më e shpejtë për Hive sesa për GreenPlum.
Ngarkimi në rritje në Hive varet gjithashtu në mënyrë lineare nga vëllimi i të dhënave të ngarkuara më parë të disponueshme në tabelën e synuar dhe vazhdon mjaft ngadalë ndërsa vëllimi rritet. Kjo është shkaktuar nga nevoja për të rishkruar plotësisht tabelën e synuar. Kjo do të thotë që aplikimi i ndryshimeve të vogla në tabela të mëdha nuk është një rast i mirë përdorimi për Hive.
Ngarkimi në rritje në GreenPlum varet dobët nga vëllimi i të dhënave të ngarkuara më parë të disponueshme në tabelën e synuar dhe vazhdon mjaft shpejt. Kjo ndodhi falë SQL Joins dhe arkitekturës GreenPlum, e cila lejon funksionimin e fshirjes.
Pra, GreenPlum shton deltën duke përdorur metodën delete+insert, por Hive nuk ka operacione fshirjeje ose përditësimi, kështu që i gjithë grupi i të dhënave u detyrua të rishkruhet tërësisht gjatë një përditësimi në rritje. Krahasimi i qelizave të theksuara me shkronja të zeza është më zbulues, pasi korrespondon me opsionin më të zakonshëm për përdorimin e shkarkimeve me burime intensive. Ne shohim që GreenPlum mundi Hive në këtë test me 8 herë.
Punoni Ab Initio me GreenPlum në modalitetin afër kohë reale
Në këtë eksperiment, ne do të testojmë aftësinë e Ab Initio për të përditësuar tabelën GreenPlum me copa të dhënash të krijuara rastësisht në kohë pothuajse reale. Le të shqyrtojmë tabelën GreenPlum dev42_1_db_usl.TESTING_SUBJ_org_finval, me të cilën do të punojmë.
Ne do të përdorim tre grafikë Ab Initio për të punuar me të:
1) Graph Create_test_data.mp – krijon skedarë të dhënash në HDFS me 10 rreshta në 6 fije paralele. Të dhënat janë të rastësishme, struktura e tyre është e organizuar për t'u futur në tabelën tonë
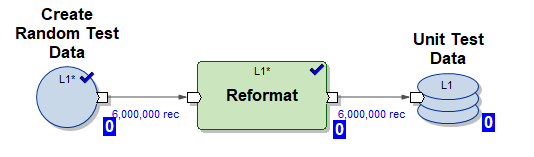

2) Grafiku mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset – grafiku i gjeneruar nga MDW duke inicializuar futjen e të dhënave në tabelën tonë në 10 fije paralele (përdoren të dhënat e testit të krijuara nga grafiku (1))

3) Grafiku mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset – një grafik i krijuar nga MDW për përditësimin në rritje të tabelës sonë në 10 fije paralele duke përdorur një pjesë të të dhënave të sapomarra (delta) të krijuara nga grafiku (1)
Le të ekzekutojmë skriptin e mëposhtëm në modalitetin NRT:
- gjenerojnë 6 linja testimi
- kryeni një ngarkesë fillestare, futni 6 rreshta testimi në një tabelë boshe
- përsëritni shkarkimin në rritje 5 herë
- gjenerojnë 6 linja testimi
- kryeni një futje shtesë prej 6 rreshtash testimi në tabelë (në këtë rast, koha e skadimit të valid_to_ts vendoset në të dhënat e vjetra dhe futen të dhëna më të fundit me të njëjtin çelës primar)
Ky skenar imiton mënyrën e funksionimit real të një sistemi të caktuar biznesi - një pjesë mjaft e madhe e të dhënave të reja shfaqen në kohë reale dhe derdhen menjëherë në GreenPlum.
Tani le të shohim regjistrin e skenarit:
Filloni Create_test_data.input.pset në 2020-06-04 11:49:11
Përfundo Create_test_data.input.pset në 2020-06-04 11:49:37
Filloni mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 11:49:37
Përfundo mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 11:50:42
Filloni Create_test_data.input.pset në 2020-06-04 11:50:42
Përfundo Create_test_data.input.pset në 2020-06-04 11:51:06
Filloni mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 11:51:06
Përfundo mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 11:53:41
Filloni Create_test_data.input.pset në 2020-06-04 11:53:41
Përfundo Create_test_data.input.pset në 2020-06-04 11:54:04
Filloni mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 11:54:04
Përfundo mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 11:56:51
Filloni Create_test_data.input.pset në 2020-06-04 11:56:51
Përfundo Create_test_data.input.pset në 2020-06-04 11:57:14
Filloni mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 11:57:14
Përfundo mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 11:59:55
Filloni Create_test_data.input.pset në 2020-06-04 11:59:55
Përfundo Create_test_data.input.pset në 2020-06-04 12:00:23
Filloni mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 12:00:23
Përfundo mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 12:03:23
Filloni Create_test_data.input.pset në 2020-06-04 12:03:23
Përfundo Create_test_data.input.pset në 2020-06-04 12:03:49
Filloni mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 12:03:49
Përfundo mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset në 2020-06-04 12:06:46
Rezulton kjo foto:
Grafik
Filloni kohë
Koha e mbarimit
Gjatësi
Create_test_data.input.pset
04.06.2020 11: 49: 11
04.06.2020 11: 49: 37
00:00:26
mdw_load.day_one.aktuale.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11: 49: 37
04.06.2020 11: 50: 42
00:01:05
Create_test_data.input.pset
04.06.2020 11: 50: 42
04.06.2020 11: 51: 06
00:00:24
mdw_load.i rregullt.aktual.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11: 51: 06
04.06.2020 11: 53: 41
00:02:35
Create_test_data.input.pset
04.06.2020 11: 53: 41
04.06.2020 11: 54: 04
00:00:23
mdw_load.i rregullt.aktual.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11: 54: 04
04.06.2020 11: 56: 51
00:02:47
Create_test_data.input.pset
04.06.2020 11: 56: 51
04.06.2020 11: 57: 14
00:00:23
mdw_load.i rregullt.aktual.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11: 57: 14
04.06.2020 11: 59: 55
00:02:41
Create_test_data.input.pset
04.06.2020 11: 59: 55
04.06.2020 12: 00: 23
00:00:28
mdw_load.i rregullt.aktual.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 12: 00: 23
04.06.2020 12: 03: 23
00:03:00
Create_test_data.input.pset
04.06.2020 12: 03: 23
04.06.2020 12: 03: 49
00:00:26
mdw_load.i rregullt.aktual.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 12: 03: 49
04.06.2020 12: 06: 46
00:02:57
Shohim që 6 linja rritëse përpunohen në 000 minuta, gjë që është mjaft e shpejtë.
Të dhënat në tabelën e synuar rezultuan të shpërndahen si më poshtë:
select valid_from_ts, valid_to_ts, count(1), min(sk), max(sk) from dev42_1_db_usl.TESTING_SUBJ_org_finval group by valid_from_ts, valid_to_ts order by 1,2; 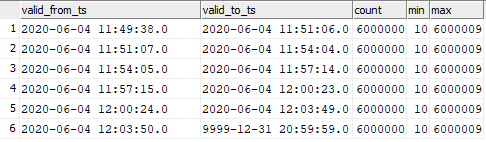
Ju mund të shihni korrespondencën e të dhënave të futura me kohën kur grafikët u hapën.
Kjo do të thotë që ju mund të ekzekutoni ngarkimin në rritje të të dhënave në GreenPlum në Ab Initio me një frekuencë shumë të lartë dhe të vëzhgoni një shpejtësi të lartë të futjes së këtyre të dhënave në GreenPlum. Sigurisht, nuk do të jetë e mundur të lëshohet një herë në sekondë, pasi Ab Initio, si çdo mjet ETL, kërkon kohë për të "filluar" kur të lansohet.
Përfundim
Ab Initio aktualisht përdoret në Sberbank për të ndërtuar një shtresë të unifikuar të të dhënave semantike (ESS). Ky projekt përfshin ndërtimin e një versioni të unifikuar të gjendjes së subjekteve të ndryshme të biznesit bankar. Informacioni vjen nga burime të ndryshme, kopjet e të cilave janë përgatitur në Hadoop. Bazuar në nevojat e biznesit, përgatitet një model i të dhënave dhe përshkruhen transformimet e të dhënave. Ab Initio ngarkon informacionin në ESN dhe të dhënat e shkarkuara nuk janë vetëm me interes për biznesin në vetvete, por gjithashtu shërbejnë si një burim për ndërtimin e të dhënave mars. Në të njëjtën kohë, funksionaliteti i produktit ju lejon të përdorni sisteme të ndryshme si marrës (Hive, Greenplum, Teradata, Oracle), gjë që bën të mundur përgatitjen e lehtë të të dhënave për një biznes në formatet e ndryshme që ai kërkon.
Aftësitë e Ab Initio janë të gjera; për shembull, korniza e përfshirë MDW bën të mundur krijimin e të dhënave historike teknike dhe të biznesit jashtë kutisë. Për zhvilluesit, Ab Initio bën të mundur që të mos rishpikni rrotën, por të përdorni shumë komponentë funksionalë ekzistues, të cilët në thelb janë biblioteka të nevojshme kur punoni me të dhëna.
Autori është ekspert në komunitetin profesional të Sberbank SberProfi DWH/BigData. Komuniteti profesional SberProfi DWH/BigData është përgjegjës për zhvillimin e kompetencave në fusha të tilla si ekosistemi Hadoop, Teradata, Oracle DB, GreenPlum, si dhe mjetet BI Qlik, SAP BO, Tableau, etj.
Burimi: www.habr.com
