

Ju keni shpenzuar muaj duke ridizajnuar monolitin tuaj në mikroshërbime dhe më në fund të gjithë janë mbledhur për të kthyer çelësin. Shkoni në faqen e parë të internetit... dhe asgjë nuk ndodh. Ju ringarkoni atë - dhe përsëri asgjë e mirë, faqja është aq e ngadaltë sa nuk përgjigjet për disa minuta. Cfare ndodhi?
Në fjalimin e tij, Jimmy Bogard do të kryejë një "post-mortem" mbi një fatkeqësi të vërtetë të mikroshërbimit. Ai do të tregojë problemet e modelimit, zhvillimit dhe prodhimit që zbuloi dhe sesi ekipi i tij e transformoi ngadalë monolitin e ri të shpërndarë në pamjen përfundimtare të mendjes së shëndoshë. Ndërsa është e pamundur të parandalohen plotësisht gabimet e projektimit, të paktën mund të identifikoni problemet në fillim të procesit të projektimit për të siguruar që produkti përfundimtar të bëhet një sistem i besueshëm i shpërndarë.

Përshëndetje të gjithëve, unë jam Jimmy dhe sot do të dëgjoni se si mund të shmangni mega fatkeqësitë kur ndërtoni mikroshërbime. Kjo është historia e një kompanie për të cilën punova për rreth një vit e gjysmë për të ndihmuar në parandalimin e përplasjes së anijes së tyre me një ajsberg. Për ta treguar siç duhet këtë histori, do të duhet të kthehemi pas në kohë dhe të flasim se ku filloi kjo kompani dhe si është rritur infrastruktura e saj IT me kalimin e kohës. Për të mbrojtur emrat e të pafajshmëve në këtë fatkeqësi, kam ndryshuar emrin e kësaj kompanie në Bell Computers. Sllajdi tjetër tregon se si dukej infrastruktura IT e kompanive të tilla në mesin e viteve '90. Kjo është një arkitekturë tipike e një serveri të madh universal HP Tandem Mainframe, tolerant ndaj gabimeve, për funksionimin e një dyqani harduerësh kompjuterik.

Ata duhej të ndërtonin një sistem për të menaxhuar të gjitha porositë, shitjet, kthimet, katalogët e produkteve dhe bazën e klientëve, kështu që ata zgjodhën zgjidhjen më të zakonshme të mainframe në atë kohë. Ky sistem gjigant përmbante çdo informacion për kompaninë, gjithçka të mundshme, dhe çdo transaksion kryhej përmes këtij mainframe. Ata mbanin të gjitha vezët e tyre në një shportë dhe menduan se kjo ishte normale. E vetmja gjë që nuk përfshihet këtu janë katalogët e porosive me postë dhe vendosja e porosive me telefon.
Me kalimin e kohës, sistemi u bë gjithnjë e më i madh dhe një sasi e madhe mbeturinash u grumbullua në të. Gjithashtu, COBOL nuk është gjuha më ekspresive në botë, kështu që sistemi përfundoi duke qenë një pjesë e madhe, monolit e mbeturinave. Në vitin 2000, ata panë se shumë kompani kishin faqe interneti përmes të cilave kryenin absolutisht të gjithë biznesin e tyre dhe vendosën të ndërtonin uebsajtin e tyre të parë komercial dot-com.
Dizajni fillestar dukej goxha i bukur dhe përbëhej nga një sajt i nivelit të lartë bell.com dhe një numër nëndimenesh për aplikacione individuale: catalog.bell.com, accounts.bell.com, orders.bell.com, kërkimi i produktit search.bell. com. Secili nëndomain përdori kornizën ASP.Net 1.0 dhe bazat e tij të të dhënave, dhe të gjithë folën me sistemin mbështetës. Megjithatë, të gjitha porositë vazhduan të përpunoheshin dhe të ekzekutoheshin brenda një rrjeti të vetëm të madh, në të cilin mbetën të gjitha mbeturinat, por pjesa e përparme ishin uebsajte të veçanta me aplikacione individuale dhe baza të dhënash të veçanta.
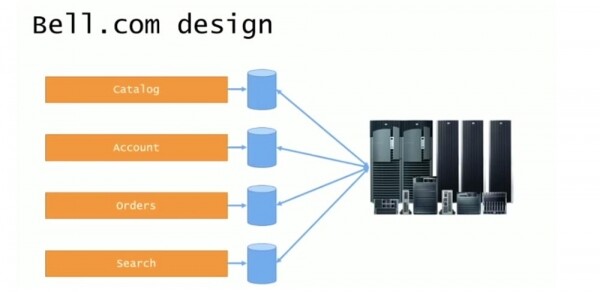
Pra, dizajni i sistemit dukej i rregullt dhe logjik, por sistemi aktual ishte siç tregohet në rrëshqitjen tjetër.
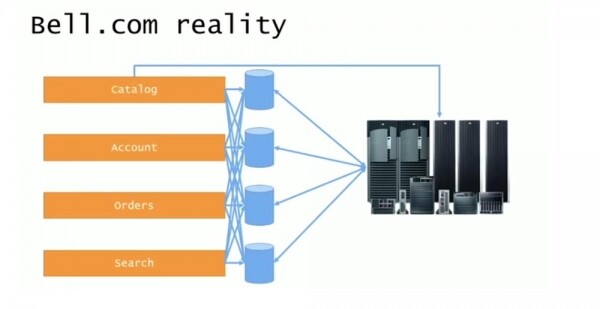
Të gjithë elementët i drejtonin thirrje njëri-tjetrit, kishin akses në API, dll të integruara të palëve të treta dhe të ngjashme. Shpesh ndodhte që sistemet e kontrollit të versionit të kapnin kodin e dikujt tjetër, ta fusnin brenda projektit dhe më pas gjithçka prishej. MS SQL Server 2005 përdori konceptin e serverëve të lidhjeve, dhe megjithëse nuk i tregova shigjetat në rrëshqitje, secila nga bazat e të dhënave foli gjithashtu me njëra-tjetrën, sepse nuk ka asgjë të keqe me ndërtimin e tabelave bazuar në të dhënat e marra nga disa baza të dhënash.
Meqenëse ata tani kishin një farë ndarjeje midis zonave të ndryshme logjike të sistemit, kjo u shndërrua në njolla papastërtie të shpërndara, me pjesën më të madhe të mbeturinave të mbetura ende në pjesën e pasme të mainframe.
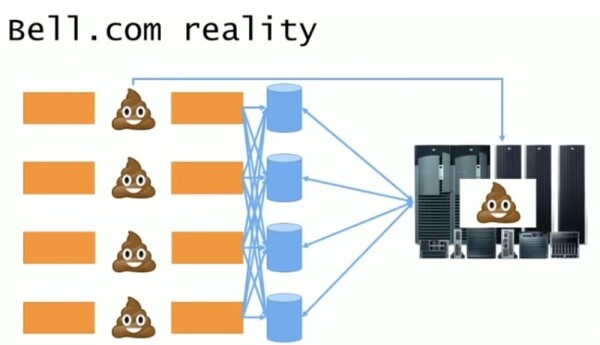
Gjëja qesharake ishte se ky mainframe ishte ndërtuar nga konkurrentët e Bell Computers dhe ende mirëmbahej nga konsulentët e tyre teknikë. E bindur për performancën e pakënaqshme të aplikacioneve të saj, kompania vendosi t'i heqë qafe ato dhe të ridizajnojë sistemin.
Aplikacioni ekzistues ishte në prodhim prej 15 vitesh, që është një rekord për aplikacionet e bazuara në ASP.Net. Shërbimi pranonte porosi nga e gjithë bota dhe të ardhurat vjetore nga ky aplikacion i vetëm arritën në një miliard dollarë. Një pjesë e konsiderueshme e fitimit u gjenerua nga faqja e internetit bell.com. Në të Premten e Zezë, numri i porosive të bëra përmes faqes arrinte në disa milionë. Sidoqoftë, arkitektura ekzistuese nuk lejonte asnjë zhvillim, pasi ndërlidhjet e ngurta të elementeve të sistemit praktikisht nuk lejuan që të bëhen ndryshime në shërbim.
Problemi më serioz ishte pamundësia për të bërë një porosi nga një vend, për të paguar në një tjetër dhe për ta dërguar në një të tretë, pavarësisht se një skemë e tillë tregtare është shumë e zakonshme në kompanitë globale. Faqja ekzistuese e internetit nuk e lejonte diçka të tillë, kështu që ata duhej të pranonin dhe bënin këto porosi përmes telefonit. Kjo bëri që kompania të mendonte gjithnjë e më shumë për ndryshimin e arkitekturës, veçanërisht për kalimin në mikroshërbime.
Ata bënë gjënë e zgjuar duke parë kompanitë e tjera për të parë se si e kishin zgjidhur një problem të ngjashëm. Një nga këto zgjidhje ishte arkitektura e shërbimit Netflix, e cila përbëhet nga mikroshërbime të lidhura nëpërmjet një API dhe një bazë të dhënash të jashtme.
Menaxhmenti i Bell Computers vendosi të ndërtojë pikërisht një arkitekturë të tillë, duke iu përmbajtur disa parimeve bazë. Së pari, ata eliminuan dyfishimin e të dhënave duke përdorur një qasje të përbashkët të bazës së të dhënave. Nuk u dërguan të dhëna, përkundrazi, të gjithë ata që kishin nevojë për to duhej të shkonin në një burim të centralizuar. Kjo u pasua nga izolimi dhe autonomia - çdo shërbim ishte i pavarur nga të tjerët. Ata vendosën të përdorin Web API për absolutisht çdo gjë - nëse dëshironi të merrni të dhëna ose të bëni ndryshime në një sistem tjetër, gjithçka bëhej përmes API-së së Uebit. Gjëja e fundit e madhe ishte një mainframe i ri i quajtur "Bell on Bell" në krahasim me mainframe "Bell" i bazuar në harduerin e konkurrentëve.
Kështu, gjatë 18 muajve, ata ndërtuan sistemin rreth këtyre parimeve thelbësore dhe e sollën atë në para-prodhim. Pas kthimit në punë pas fundjavës, zhvilluesit u mblodhën dhe ndezën të gjithë serverët me të cilët ishte lidhur sistemi i ri. 18 muaj punë, qindra zhvillues, pajisja më moderne Bell - dhe asnjë rezultat pozitiv! Kjo ka zhgënjyer shumë njerëz sepse ata e kanë përdorur këtë sistem në laptopët e tyre shumë herë dhe gjithçka ishte në rregull.
Ata ishin të zgjuar për të hedhur të gjitha paratë e tyre për zgjidhjen e këtij problemi. Ata instaluan raftet më moderne të serverëve me ndërprerës, përdorën fibra optike gigabit, harduerin më të fuqishëm të serverit me një sasi të çmendur RAM, i lidhën të gjitha, i konfiguruan - dhe përsëri, asgjë! Më pas ata filluan të dyshonin se arsyeja mund të ishte ndërprerjet e kohës, kështu që ata hynë në të gjitha cilësimet e uebit, të gjitha cilësimet e API dhe përditësuan të gjithë konfigurimin e afatit në vlerat maksimale, në mënyrë që gjithçka që mund të bënin ishte të uleshin dhe të prisnin që diçka të ndodhte. te siti. Ata pritën dhe pritën dhe pritën 9 minuta e gjysmë derisa uebfaqja të ngarkohej më në fund.
Pas kësaj, u kuptua se situata aktuale kishte nevojë për një analizë të thellë dhe na ftuan. Gjëja e parë që zbuluam ishte se gjatë të gjithë 18 muajve të zhvillimit, nuk u krijua asnjë "mikro" i vetëm i vërtetë - gjithçka vetëm u bë më e madhe. Pas kësaj, filluam të shkruanim një post-mortem, i njohur gjithashtu si një "regretrospektivë", ose "retrospektivë e trishtuar", e njohur edhe si "stuhi faji", e ngjashme me një "stuhi truri", për të kuptuar shkakun e katastrofës.
Ne kishim disa të dhëna, njëra prej të cilave ishte ngopja e plotë e trafikut në kohën e thirrjes API. Kur përdorni një arkitekturë shërbimi monolit, mund të kuptoni menjëherë se çfarë saktësisht shkoi keq, sepse keni një gjurmë të vetme të pirgut që raporton gjithçka që mund të ketë shkaktuar dështimin. Në rastin kur një grup shërbimesh hyjnë njëkohësisht në të njëjtin API, nuk ka asnjë mënyrë për të gjurmuar gjurmën përveç përdorimit të mjeteve shtesë të monitorimit të rrjetit si WireShark, falë të cilave mund të ekzaminoni një kërkesë të vetme dhe të zbuloni se çfarë ndodhi gjatë zbatimit të saj. Kështu, ne morëm një faqe interneti dhe kaluam pothuajse 2 javë duke bashkuar pjesët e enigmës, duke bërë një sërë thirrjesh në të dhe duke analizuar se çfarë çoi secila prej tyre.
Shikoni këtë foto. Tregon se një kërkesë e jashtme e shtyn shërbimin të kryejë shumë telefonata të brendshme që kthehen. Rezulton se çdo telefonatë e brendshme bën hop shtesë në mënyrë që të mund të shërbejë në mënyrë të pavarur këtë kërkesë, sepse nuk mund të kthehet askund tjetër për të marrë informacionin e nevojshëm. Kjo foto duket si një kaskadë e pakuptimtë thirrjesh, pasi kërkesa e jashtme thërret shërbime shtesë, të cilat thërrasin shërbime të tjera shtesë, e kështu me radhë, pothuajse pafundësisht.

Ngjyra e gjelbër në këtë diagram tregon një gjysmërreth në të cilin shërbimet thërrasin njëra-tjetrën - shërbimi A thërret shërbimin B, shërbimi B thërret shërbimin C dhe përsëri thërret shërbimin A. Si rezultat, ne marrim një "ngërç të shpërndarë". Një kërkesë e vetme krijoi një mijë thirrje API të rrjetit, dhe meqenëse sistemi nuk kishte tolerancë të integruar ndaj gabimeve dhe mbrojtje të lakut, kërkesa do të dështonte nëse edhe një nga këto thirrje API dështonte.
Bëmë pak matematikë. Çdo thirrje API kishte një SLA jo më shumë se 150 ms dhe 99,9% kohë pune. Një kërkesë shkaktoi 200 thirrje të ndryshme dhe në rastin më të mirë, faqja mund të shfaqej në 200 x 150 ms = 30 sekonda. Natyrisht, kjo nuk ishte e mirë. Duke shumëzuar 99,9% kohën e funksionimit me 200, kemi disponueshmërinë 0%. Rezulton se kjo arkitekturë ishte e dënuar me dështim që në fillim.
Ne pyetëm zhvilluesit se si nuk arritën ta dallonin këtë problem pas 18 muajsh punë? Doli që ata numëronin SLA-në vetëm për kodin që përdornin, por nëse shërbimi i tyre thërriste një shërbim tjetër, ata nuk e llogarisnin atë kohë në SLA-në e tyre. Gjithçka që nisej brenda një procesi i përmbahej vlerës 150 ms, por aksesi në proceset e tjera të shërbimit e rriti shumëfish vonesën totale. Mësimi i parë i mësuar ishte: "A jeni në kontroll të SLA-së tuaj, apo SLA po ju kontrollon?" Në rastin tonë, ishte kjo e fundit.
Gjëja tjetër që zbuluam ishte se ata dinin për konceptin e keqkuptimeve të llogaritjes së shpërndarë, të formuluar nga Peter Deitch dhe James Gosling, por ata injoruan pjesën e parë të tij. Ai thotë se thëniet "rrjeti është i besueshëm", "vonesa zero" dhe "përdorimi i pafund" janë koncepte të gabuara. Keqkuptime të tjera përfshijnë thëniet "rrjeti është i sigurt", "topologjia nuk ndryshon kurrë", "gjithmonë ka vetëm një administrator", "kostoja e transferimit të të dhënave është zero" dhe "rrjeti është homogjen".
Ata bënë një gabim sepse testuan shërbimin e tyre në makinat lokale dhe nuk u lidhën kurrë me shërbime të jashtme. Kur zhvilloheshin në nivel lokal dhe përdornin një memorie të fshehtë lokale, ata kurrë nuk hasën në kërcime në rrjet. Në të gjithë 18 muajt e zhvillimit, ata asnjëherë nuk e pyetën veten se çfarë mund të ndodhte nëse shërbimet e jashtme do të prekeshin.

Nëse shikoni kufijtë e shërbimit në foton e mëparshme, mund të shihni se të gjithë janë të pasaktë. Ka shumë burime që këshillojnë se si të përcaktohen kufijtë e shërbimit, dhe shumica e bëjnë atë gabim, si Microsoft në rrëshqitjen tjetër.

Kjo foto është nga blogu MS me temën "Si të ndërtojmë mikroshërbime". Kjo tregon një aplikacion të thjeshtë ueb, një bllok të logjikës së biznesit dhe një bazë të dhënash. Kërkesa vjen direkt, ndoshta ka një server për ueb, një server për biznesin dhe një për bazën e të dhënave. Nëse rrit trafikun, fotografia do të ndryshojë pak.
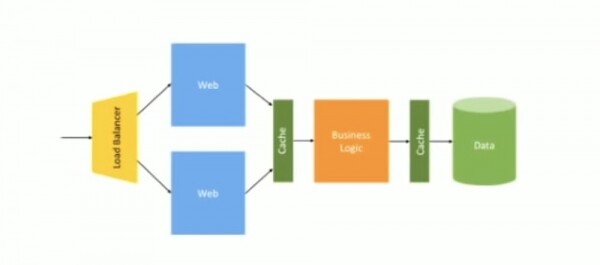
Këtu vjen një balancues i ngarkesës për të shpërndarë trafikun midis dy serverëve të uebit, një cache e vendosur midis shërbimit të uebit dhe logjikës së biznesit, dhe një cache tjetër midis logjikës së biznesit dhe bazës së të dhënave. Kjo është pikërisht arkitektura Bell e përdorur për balancimin e ngarkesës dhe aplikimin e vendosjes blu/jeshile në mesin e viteve 2000. Deri disa kohë gjithçka funksionoi mirë, pasi kjo skemë ishte menduar për një strukturë monolit.
Fotografia e mëposhtme tregon se si MS rekomandon kalimin nga një monolit në mikroshërbime - thjesht ndani secilin prej shërbimeve kryesore në mikroshërbime të veçanta. Pikërisht gjatë zbatimit të kësaj skeme Bell bëri një gabim.
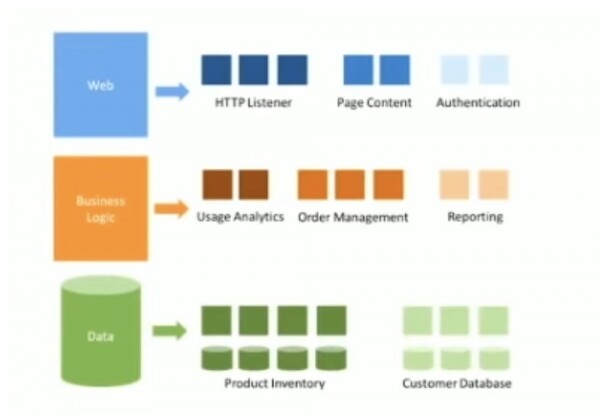
Ata i ndanë të gjitha shërbimet e tyre në nivele të ndryshme, secila prej të cilave përbëhej nga shumë shërbime individuale. Për shembull, shërbimi në internet përfshinte mikroshërbime për paraqitjen dhe vërtetimin e përmbajtjes, shërbimi i logjikës së biznesit përbëhej nga mikroshërbime për përpunimin e porosive dhe informacionit të llogarisë, baza e të dhënave ishte e ndarë në një grup mikroshërbimesh me të dhëna të specializuara. Si ueb-i, logjika e biznesit dhe baza e të dhënave ishin shërbime pa shtetësi.
Megjithatë, kjo pamje ishte krejtësisht e gabuar, sepse nuk kishte një hartë të ndonjë njësie biznesi jashtë grupit të IT të kompanisë. Kjo skemë nuk merrte parasysh asnjë lidhje me botën e jashtme, kështu që nuk ishte e qartë se si, për shembull, të merreshin analitikë biznesi të palëve të treta. Vërej se ata kishin gjithashtu disa shërbime të shpikura thjesht për të zhvilluar karrierën e punonjësve individualë, të cilët kërkuan të menaxhonin sa më shumë njerëz që të ishte e mundur në mënyrë që të merrnin më shumë para për të.
Ata besonin se kalimi në mikroshërbime ishte po aq i lehtë sa marrja e infrastrukturës së tyre të brendshme të shtresës fizike të nivelit N dhe ngjitja e Docker mbi të. Le të hedhim një vështrim se si duket arkitektura tradicionale e nivelit N.
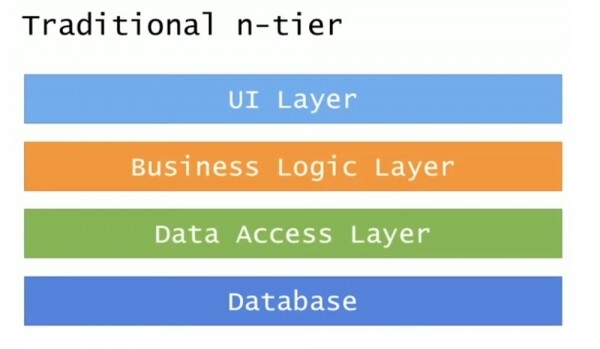
Ai përbëhet nga 4 nivele: niveli i ndërfaqes së përdoruesit të UI, niveli i logjikës së biznesit, niveli i aksesit të të dhënave dhe baza e të dhënave. Më progresive është DDD (Domain-Driven Design), ose arkitektura e orientuar drejt softuerit, ku dy nivelet e mesme janë objekte domeni dhe një depo.
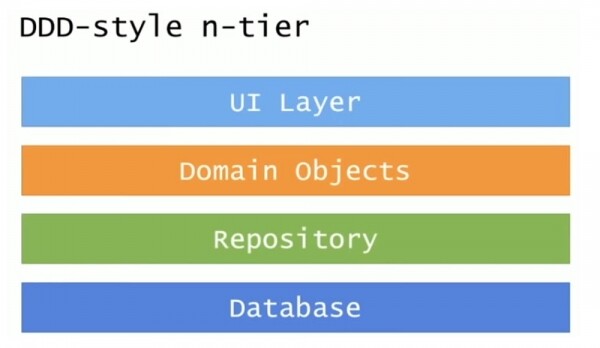
Jam përpjekur të shikoj fusha të ndryshme ndryshimi, fusha të ndryshme përgjegjësie në këtë arkitekturë. Në një aplikim tipik të nivelit N, klasifikohen zona të ndryshme ndryshimi që përshkojnë strukturën vertikalisht nga lart poshtë. Këto janë cilësimet e Katalogut, konfigurimit të kryera në kompjuterë individualë dhe kontrollet e Checkout, të cilat u trajtuan nga ekipi im.
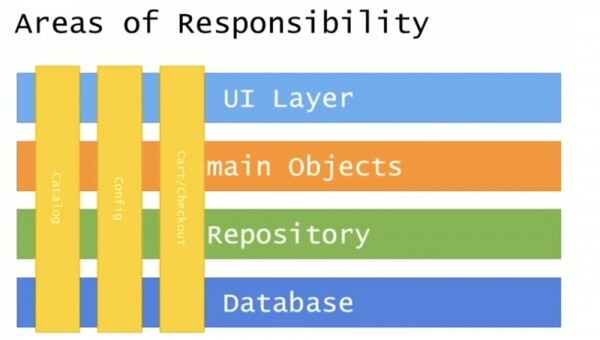
E veçanta e kësaj skeme është se kufijtë e këtyre zonave të ndryshimit ndikojnë jo vetëm në nivelin logjik të biznesit, por shtrihen edhe në bazën e të dhënave.
Le të shohim se çfarë do të thotë të jesh shërbim. Ekzistojnë 6 veti karakteristike të përkufizimit të një shërbimi - është softuer që:
- krijuar dhe përdorur nga një organizatë specifike;
- është përgjegjës për përmbajtjen, përpunimin dhe/ose dhënien e një lloji të caktuar informacioni brenda sistemit;
- mund të ndërtohet, vendoset dhe funksionon në mënyrë të pavarur për të përmbushur nevojat specifike operacionale;
- komunikon me konsumatorët dhe shërbime të tjera, duke ofruar informacion bazuar në marrëveshje ose garanci kontraktuale;
- mbron veten nga aksesi i paautorizuar dhe informacioni i tij nga humbja;
- trajton dështimet në mënyrë të tillë që të mos çojnë në dëmtim të informacionit.
Të gjitha këto veti mund të shprehen me një fjalë "autonomi". Shërbimet funksionojnë në mënyrë të pavarur nga njëri-tjetri, plotësojnë kufizime të caktuara dhe përcaktojnë kontrata mbi bazën e të cilave njerëzit mund të marrin informacionin që u nevojitet. Nuk përmenda teknologji specifike, përdorimi i të cilave është i vetëkuptueshëm.
Tani le të shohim përkufizimin e mikroshërbimeve:
- një mikroshërbim është me përmasa të vogla dhe i projektuar për të zgjidhur një problem specifik;
- Mikroshërbimi është autonom;
- Kur krijohet një arkitekturë mikroshërbimi, përdoret metafora e planifikimit të qytetit. Ky është përkufizimi nga libri i Sam Newman, Ndërtimi i Microservices.
Përkufizimi i kontekstit të kufizuar është marrë nga libri i Eric Evans-it, Dizajni i drejtuar nga Domain. Ky është një model thelbësor në DDD, një qendër e projektimit të arkitekturës që punon me modele arkitekturore vëllimore, duke i ndarë ato në kontekste të ndryshme të kufizuara dhe duke përcaktuar në mënyrë eksplicite ndërveprimet ndërmjet tyre.
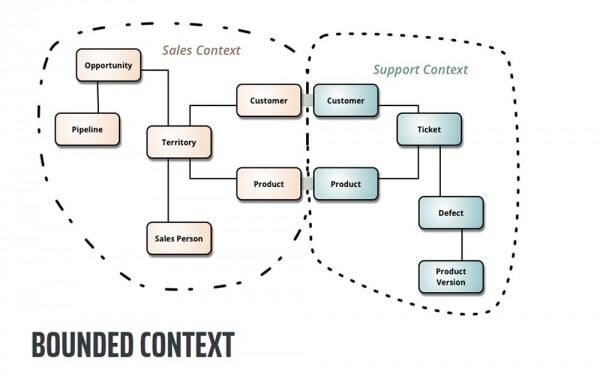
E thënë thjesht, një kontekst i kufizuar tregon shtrirjen në të cilën mund të përdoret një modul i veçantë. Brenda këtij konteksti është një model i unifikuar logjikisht që mund të shihet, për shembull, në domenin e biznesit tuaj. Nëse pyetni "kush është klient" personelit të përfshirë në porosi, do të merrni një përkufizim, nëse pyesni ata që janë të përfshirë në shitje, do të merrni një tjetër dhe interpretuesit do t'ju japin një përkufizim të tretë.
Pra, Bounded Context thotë se nëse nuk mund të japim një përkufizim të qartë se çfarë është një konsumator i shërbimeve tona, le të përcaktojmë kufijtë brenda të cilëve mund të flasim për kuptimin e këtij termi dhe më pas të përcaktojmë pikat e tranzicionit midis këtyre përkufizimeve të ndryshme. Kjo do të thotë, nëse flasim për një klient nga pikëpamja e vendosjes së porosive, kjo do të thotë kjo dhe ajo, dhe nëse nga pikëpamja e shitjeve, kjo do të thotë këtë dhe atë.
Përkufizimi tjetër i një mikroshërbimi është kapsulimi i çdo lloj operacioni të brendshëm, duke parandaluar "rrjedhjen" e përbërësve të procesit të punës në mjedis. Më pas vjen “përkufizimi i kontratave eksplicite për ndërveprimet e jashtme, ose komunikimet e jashtme”, i cili përfaqësohet nga ideja e kontratave që kthehen nga SLA. Përkufizimi i fundit është metafora e një qelize, ose qelize, që nënkupton kapsulimin e plotë të një grupi operacionesh brenda një mikroservice dhe praninë në të të receptorëve për komunikim me botën e jashtme.

Kështu, ne u thamë djemve në Bell Computers, “Ne nuk mund të rregullojmë asnjë nga kaosi që keni krijuar sepse thjesht nuk keni para për ta bërë atë, por ne do të rregullojmë vetëm një shërbim për t'i bërë të gjitha. kuptim.” Në këtë pikë, do të filloj duke ju treguar se si e rregulluam shërbimin tonë të vetëm në mënyrë që ai t'u përgjigjej kërkesave më shpejt se 9 minuta e gjysmë.
22:30 min
Vazhdon shume shpejt...

Pak reklamë
Faleminderit që qëndruat me ne. A ju pëlqejnë artikujt tanë? Dëshironi të shihni përmbajtje më interesante? Na mbështesni duke bërë një porosi ose duke rekomanduar miqve, , një analog unik i serverëve të nivelit të hyrjes, i cili u shpik nga ne për ju: (e disponueshme me RAID1 dhe RAID10, deri në 24 bërthama dhe deri në 40 GB DDR4).
Dell R730xd 2 herë më lirë në qendrën e të dhënave Equinix Tier IV në Amsterdam? Vetëm këtu në Holandë! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - nga 99 dollarë! Lexoni rreth
Burimi: www.habr.com
