

Shën. përk.: Ky artikull, i shkruar nga Galo Navarro, i cili mban pozitat e Inxhinierit Kryesor të Softuerit në kompaninë evropiane Adevinta, përbën një hetim tërheqës dhe edukues në fushën e shfrytëzimit të infrastrukturës. Titulli origjinal u pasua pak në përkthim për një arsye, që autori e shpjegon në fillim.
Vërejtje nga autori: Duket se ky publikim kërkon shumë më tepër vëmendje se sa pritej. Ende po marr komente të zemëruara për këtë që titulli i artikullit është mashtrues dhe disa lexues janë të trishtuar. E kuptoj arsyen për këtë, prandaj, pavarësisht rrezikut për të shkatërruar gjithë intrigën, dua ta them menjëherë se për çfarë është ky artikull. Kur kalojmë në Kubernetes, vëreja një gjë interesante: sa herë që lind një problem (për shembull, rritja e vonesave pas migrimit), shkaktohet gjithmonë akuza ndaj Kubernetes, por pastaj del që orkestratori në fakt nuk është fajtor. Ky artikull tregon për një nga këto raste. Titulli i tij përsërit një thirrje të njërit nga zhvilluesit tanë (do ta bëni të qartë se Kubernetes vërtet s'ka asnjë faj këtu). Në të nuk do të gjeni ndonjë zbulim të befasishëm për Kubernetes, por mund të prisni disa mësime të mira rreth sistemeve të komplikuara.
Para disa javësh, ekipi im po merte pjesë në migrimin e një mikroshërbimi në platformën kryesore, që përfshin CI/CD, një mjedis të bazuar në Kubernetes, metrika dhe mjete të tjera të dobishme. Ky transfer kishte karakter provues: ne planifikonim të merrnim këtë si bazë dhe të transferonim rreth 150 shërbime të tjera në muajt në vijim. Të gjitha ato janë përgjegjëse për funksionimin e disa nga platformat më të mëdha online në Spanjë (Infojobs, Fotocasa, etj.).
Pas lançimit të aplikacionit në Kubernetes dhe ridrejtimit të një pjese të trafikut në të, na priste një surprizë shqetësuese. Vonesa (latencë) e kërkesave në Kubernetes ishte 10 herë më e lartë se në EC2. Në përgjithësi, duhet të gjenim një zgjidhje për këtë problem ose të heqim dorë nga migrimi i mikroshërbimit (dhe ndoshta nga e gjithë projekti).
Pse vonesa në Kubernetes është kaq e lartë krahasuar me EC2?
Për të gjetur ngushticën, mblodhëm metrika në të gjithë rrugën e kërkesës. Arkitektura jonë është e thjeshtë: portali API (Zuul) proxy të kërkesave në instancat e mikroshërbimit në EC2 ose Kubernetes. Në Kubernetes përdorim NGINX Ingress Controller, ndërsa backendet përbëhen nga objekte të zakonshme të tipit me aplikacione JVM në platformën Spring.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Duket se problemi ishte lidhur me vonesën në fazën fillestare të punës në backend (e kam shënuar seksionin problematik në grafik si «xx»). Në EC2, përgjigjja e aplikacionit zgjaste rreth 20 ms. Në Kubernetes, vonesa rritej deri në 100—200 ms.
Ne shpejt eliminuam të dyshuarit e mundshëm që lidheshin me ndërrimin e mjedisit të ekzekutimit. Versioni i JVM mbeti i njëjtë. Problemet e konteinerizimit gjithashtu nuk ishin në lojë: aplikacioni tashmë punonte me sukses në konteinerat në EC2. Ngarkesa? Por ne vëzhguam vonesa të larta edhe me 1 kërkesë në sekondë. Pauzat për mbledhjen e plehrave gjithashtu mund të injoroheshin.
Një nga administratorët tanë të Kubernetes pyeti nëse aplikacioni kishte varësi të jashtme, pasi në të kaluarën kërkesat për DNS kishin shkaktuar probleme të ngjashme.
Hipoteza 1: zgjidhja e emrave DNS
Me çdo kërkesë, aplikacioni ynë bën një deri në tre kërkesa në një instancë të AWS Elasticsearch në një domene si elastic.spain.adevinta.com. Brenda konteinerëve, ne , prandaj ne mund ta kontrollojmë nëse kërkimi i emrit të domenit është me të vërtetë i gjatë.
Kërkesat DNS nga konteineri:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecKërkesa të ngjashme nga një nga instancat EC2, ku funksionon aplikacioni:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecDuke marrë parasysh se kërkimi zgjat rreth 30 msec, u bë e qartë se zgjidhja DNS kur kontaktimi me Elasticsearch me të vërtetë kontribuon në rritjen e vonesës.
Megjithatë, kjo ishte e çuditshme për dy arsye:
- Kemi tashmë shumë aplikacione në Kubernetes që ndërveprojnë me burimet AWS, por nuk kanë vonesa të mëdha. Çfarëdo qe të jetë arsyeja, ajo lidhet konkretisht me këtë rast.
- E dimë që JVM bën caching në memorie për DNS. Në imazhet tona, vlera TTL është e caktuar në
$JAVA_HOME/jre/lib/security/java.securitydhe është e vendosur në 10 sekonda:networkaddress.cache.ttl = 10. Në fjalë të tjera, JVM duhet të ruajë të gjitha kërkesat DNS për 10 sekonda.
Për të konfirmuar hipotezën e parë, vendosëm për një kohë të heqim dorë nga kërkesat për DNS dhe të shohim nëse problemi do të zhdukej. Fillimisht, vendosëm të përshtatim aplikacionin që të lidhet me Elasticsearch direkt përmes adresës IP, jo përmes emrit të domain-it. Kjo do të kërkonte ndryshime në kod dhe një ri-distribuim të ri, prandaj ne thjesht e lidhëm domain-in me adresën IP të tij në /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comTani kontejneri merrte IP-në thuajse menjëherë. Kjo çoi në disa përmirësime, por ne përfundimisht ishim akoma larg nivelit të pritshëm të vonesës. Megjithëse zgjidhja e DNS merrte shumë kohë, arsyet e vërteta vazhdonin të na shpëtonin.
Diagnoza përmes rrjetit
Ne vendosëm të analizojmë trafikun nga kontejneri me ndihmën e tcpdump, për të ndjekur se çfarë ndodhi në rrjet:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Pasyre, dërguam disa kërkesa dhe i shkarkuam kapjet e tyre (kubectl cp my-service:/capture.pcap capture.pcap) për analiza të mëtejshme në .
Në kërkesat DNS nuk kishte asgjë të dyshimtë (përveç një detaji të vogël, për të cilin do flas më vonë). Por kishte disa çuditëri në mënyrën se si shërbimi ynë trajtonte çdo kërkesë. Më poshtë është një screenshot i kapjes, që tregon pranimin e kërkesës para fillimit të përgjigjes:
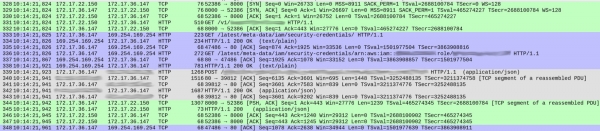
Numrat e paketave janë të dhëna në kolonën e parë. Për qartësi, kam theksuar me ngjyra rrjedhat e ndryshme TCP.
Rrjedha jeshile, që fillon me paketën 328, tregon se si klienti (172.17.22.150) nguli një lidhje TCP me kontejnerin (172.17.36.147). Pasi u krye dorëzimi fillestar (328-330), paketa 331 solli HTTP GET /v1/.. — kërkesa hyrëse për shërbimin tonë. Tërë procesi zuri 1 ms.
Rrjedha gri (nga paketa 339) tregon se shërbimi ynë dërgoi një kërkesë HTTP te instanca Elasticsearch (dorëzimi TCP mungon, pasi përdoret një lidhje ekzistuese). Kjo mori 18 ms.
Deri tani gjithçka është në rregull, dhe koha është përkatësisht në përputhje me vonesat e pritura (20-30 ms në matjet nga klienti).
Megjithatë, seksioni blu zë 86 ms. Çfarë po ndodh atje? Me paketën 333 shërbimi ynë dërgoi një kërkesë HTTP GET në /latest/meta-data/iam/security-credentials, dhe menjëherë pas saj, përmes të njëjtës lidhje TCP, një tjetër kërkesë GET në /latest/meta-data/iam/security-credentials/arn:...
Kemi zbuluar se kjo përsëritet me çdo kërkesë në të gjithë gjurmimin. Zgjidhja DNS është ndjeshëm më e ngadaltë në konteinerët tanë (shpjegimi i këtij fenomeni është mjaft interesant, por do ta mbaj për një artikull të veçantë). Doli që shkaku i vonesave të mëdha janë thirrjet në shërbimin AWS Instance Metadata me çdo kërkesë.
Hipoteza 2: thirrje të panevojshme në AWS
Të dy endpoint-at i përkasin . Mikrosherbimi ynë e përdor këtë shërbim gjatë punës me Elasticsearch. Të dy thirrjet janë pjesë e procesit bazë të autorizimit. Endpoint-i, i cili kontaktohet gjatë kërkesës së parë, jep rolin IAM të lidhur me instancën.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleKërkesa e dytë kontakton endpoint-in e dytë për autorizatat e përkohshme për këtë instancë:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Klienti mund të përdorin ato për një periudhë të shkurtër kohe dhe herë pas here duhet të marrin certifikata të reja (deri në Skadimi). Modeli është i thjeshtë: AWS kryen rotacion të shpeshtë të çelësave për shkak të arsyeve të sigurisë, por klientët mund t'i ruajnë ato për disa minuta, duke kompesuar rënien e performancës të lidhur me marrjen e certifikatave të reja.
AWS Java SDK duhet të marrë përsipër detyrat për organizimin e këtij procesi, megjithatë për ndonjë arsye kjo nuk ndodh.
Pas kërkimit të problemeve në GitHub, u nënshtruam një problemi . Kjo na ndihmoi të përcaktonim drejtimin në të cilin duhet të "gërmojmë" më tej.
AWS SDK përmbush certifikatat kur ndodh një nga kushtet e mëposhtme:
- Skadimi i tyre (
Skadimi) përputhet meEXPIRATION_THRESHOLD, i vendosur në kod në 15 minuta. - Ka kaluar më shumë kohë nga përpjekja e fundit për të azhurnuar certifikatat se sa
REFRESH_THRESHOLD, i ‘hardcode’ në 60 minuta.
Për të parë afatin real të skadencës së sertifikatave që ne marrim, ne ekzekutuam komandat e cURL të mësipërme nga kontejneri dhe nga një instancë EC2. Koha e vlefshmërisë së sertifikatës, e cila u mor nga kontejneri, rezultoi të ishte shumë më e shkurtër: pikërisht 15 minuta.
Tani gjithçka është e qartë: për kërkesën e parë, shërbimi ynë mori sertifikata të përkohshme. Pasi afati i tyre të vlefshmërisë nuk kalonte 15 minuta, në kërkesën e mëparshme AWS SDK vendosi t'i rinovonte ato. Dhe kjo ndodhte me çdo kërkesë.
Pse afati i vlefshmërisë së sertifikatave u bë më i shkurtër?
Shërbimi AWS Instance Metadata është menduar për të punuar me instancat EC2, dhe jo me Kubernetes. Në anën tjetër, ne nuk dëshironim të ndryshonim ndërfaqen e aplikacioneve. Për këtë ne përdorëm — një mjet, i cili me ndihmën e agenëve në çdo nyje Kubernetes lejon përdoruesit (inxhinierët që despletojnë aplikacione në grup) të caktojnë role IAM konteinerëve në pod’ët sikur ata janë instanca EC2. KIAM kap thirrjet për shërbimin AWS Instance Metadata dhe i përpunon ato nga cache e tij, pasi i ka marrë nga AWS. Nga pikëpamja e aplikacionit, asgjë nuk ndryshon.
KIAM ofron certifikata afatshkurtra për pod. Kjo ka kuptim, duke pasur parasysh se mesatarja e jetës së një pod-i është më e shkurtër se ajo e një instance EC2. Në mënyrë të paracaktuar, afati i vlefshmërisë së certifikatave .
Si rezultat, nëse vendosen të dy vlerat e paracaktuara një mbi tjetrën, lind një problem. Çdo certifikatë që i ofrohet aplikacionit skadon pas 15 minutash. Në të njëjtën kohë, AWS Java SDK e rinovon çdo certifikatë me pak se 15 minuta kohë deri në skadim.
Si pasojë, certifikata e përkohshme rinovohet me çdo kërkesë, e cila sjell disa thirrje në API-në e AWS dhe çon në një rritje të konsiderueshme të vonesave. Në AWS Java SDK gjetëm , ku përmendet një problem i ngjashëm.
Zgjidhja doli të ishte e thjeshtë. Ne thjesht e konfiguram KIAM për të kërkuar certifikata me një afat më të gjatë vlefshmërie. Pas kësaj, kërkesat filluan të kalonin pa ndihmën e shërbimit AWS Metadata, dhe vonesa ra edhe më poshtë se në EC2.
Përfundimet
Sipas përvojës sonë me migrimet, mund të themi se një nga burimet më të zakonshme të problemeve nuk janë gabimet në Kubernetes ose në elementët e tjerë të platformës. Gjithashtu, nuk lidhet me ndonjë defekt themelor në mikroshërbimet që ne po transferojmë. Problemet shpesh ndodhin thjesht sepse ne kombinojmë elementë të ndryshëm së bashku.
Ne po përziejmë sisteme të komplikuara që kurrë më parë nuk kanë ndërvepruar me njëri-tjetrin, duke pritur që së bashku ato të krijojnë një sistem më të madh, më të integruar. Fatkeqësisht, sa më shumë elementë të jenë, aq më shumë hapësirë ka për gabime dhe aq më e lartë është entropia.
Në rastin tonë, vonesa e lartë nuk ishte rezultat i gabimeve ose zgjidhjeve të këqija në Kubernetes, KIAM, AWS Java SDK, ose mikroshërbimin tonë. Ajo rezultoi nga kombinimi i dy parametrave të pavarur, të caktuar si parazgjedhje: një në KIAM dhe tjetri në AWS Java SDK. Secili prej tyre ka kuptim kur shqyrtohet veçmas: si politika aktive e rinovimit të certifikatave në AWS Java SDK, ashtu edhe afati i shkurtër i vlefshmërisë së certifikatave në KAIM. Por, kur i bashkojmë ato së bashku, rezultatet bëhen të paparashikueshme. Dy zgjidhje të pavarura dhe logjike nuk kanë nevojë të kenë kuptim kur mblidhen së bashku.
P.S. nga përkthyesi
Mësoni më shumë rreth arkitekturës së mjetit KIAM për integrimin e AWS IAM me Kubernetes në nga krijuesit e saj.
Në blogun tonë lexoni gjithashtu:
- «»;
- «»;
- «»;
- «».
Burimi: habr.com
