

Klasifikimi i të dhënave në bazë të përmbajtjes është një detyrë e hapur. Sistemet tradicionale të parandalimit të humbjes së të dhënave (DLP) e zgjidhin këtë problem duke marrë shtypje nga të dhënat përkatëse dhe duke monitoruar piketat për të marrë shtypjet. Duke marrë parasysh numrin e madh të burimeve të dhënash që ndryshojnë vazhdimisht në Facebook, ky qasje jo vetëm që nuk është e shkallëzueshme, por është edhe e paefektshme për të përcaktuar se ku ndodhen të dhënat. Ky artikull është i dedikuar një sistemi tërësor, i ndërtuar për të zbuluar lloje të ndjeshme semantike në Facebook në shkallë dhe për të siguruar automatikisht ruajtjen e të dhënave dhe kontrollin e qasjes.
Qasja e përshkruar këtu është sistemi ynë i parë i përfunduar i privatësisë, i cili përpiqet të zgjidhë këtë problem duke përfshirë sinjale të dhënash, mësim në makinë dhe metoda tradicionale të identifikimit për të shfaqur dhe klasifikuar të dhënat në Facebook. Sistemi i përshkruar eksploatohet në një ambient të prodhimit, duke arritur një rezultat mesatar F2 mbi 0.9 në kategoritë e ndryshme të privatësisë duke trajtuar një sasi të madhe të burimeve të dhënash në dhjetëra depo. Paraqesim përkthimin e publikimit të Facebook në ArXiv mbi klasifikimin e shkallëzueshëm të të dhënave për sigurimin dhe privatësinë e bazuar në mësimin në makinë.
Hyrje
Sotëria po mbledh dhe ruan sasi të mëdha të të dhënave në formate dhe vende të ndryshme [1], pastaj të dhënat konsumohen në shumë vende, ndonjëherë kopjohen ose ruajnë disa herë, duke bërë që informacioni i çmuar dhe konfidencial i biznesit të shpërndahet në shumë depo të dhënash korporative. Kur kërkohet që një organizatë të përmbushë kushte të caktuara ligjore ose rregullatore, si për të përmbushur rregullat gjatë procedurave civile, lind nevoja për të mbledhur të dhëna mbi vendndodhjen e të dhënave të nevojshme. Kur një urdhër për privatësi thotë se organizata duhet të maskojë të gjitha numrat e sigurimeve shoqërore (SSN) kur transmeton informacion personal tek subjekte të paautorizuara, hapi i parë natyror është të kërkojë të gjitha SSN në depozitë e të dhënave të tërë organizatës. Në këto rrethana, klasifikimi i të dhënave bëhet kritik [1]. Një sistem klasifikimi do të lejojë organizatat të sigurojnë automatikisht përputhshmërinë me privatësinë dhe politikat e sigurisë, siç është përfshirja e politikave të menaxhimit të aksesit dhe ruajtja e të dhënave. Facebook ofron një sistem të ndërtuar nga ne në Facebook, i cili përdor shumë sinjale të dhënash, një arkitekturë të sistemit të shkallëzueshëm dhe mësimautomatik për të zbuluar lloje të ndjeshme semantike të të dhënave.
Identifikimi dhe klasifikimi i të dhënave është procesi i gjetjes dhe etiketimit të tyre në një mënyrë që informacioni i duhur të mund të nxirret shpejt dhe efikasitet kur është e nevojshme. Procesi aktual është kryesisht manual dhe përfshin studimin e ligjeve ose rregulloreve përkatëse, përcaktimin e cilat tipe informacioni duhet të konsiderohen të ndjeshëm dhe cila është shkalla e ndryshme e ndjeshmërisë, dhe më pas ndërtimin përkatës të klasave dhe politikave të klasifikimit [1]. Pasi që sistemet e mbrojtjes nga humbja e të dhënave (DLP) marrin gjurmët e të dhënave dhe ndjekin pikëfundet poshtë rrjedhës për të marrë gjurmët. Duke punuar me një depo të madhe me aktive dhe petabajtë të të dhënave, ky qasje thjesht nuk është e qëndrueshme në shkallë.
Qëllimi ynë është të ndërtojmë një sistem klasifikimi të të dhënave që është në shkallë si për të dhënat e qëndrueshme ashtu edhe për ato të paqëndrueshme, pa ndonjë kufizim të shtuar mbi tipin apo formatin e të dhënave. Kjo është një qëllim ambicioz dhe natyrisht sjell sfida. Një regjistrim ndonjëherë mund të jetë mijëra karaktere i gjatë.
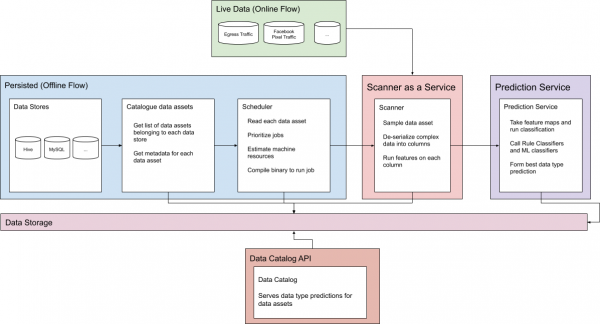
Figura 1. Flukset e parashikimeve online dhe offline
Prandaj, ne duhet ta paraqesim atë në mënyrë efektive duke përdorur një grup të përbashkët veçorish, të cilat më vonë mund të kombinohen dhe të zhvendosen lehtësisht. Këto veçori duhet të sigurojnë jo vetëm klasifikim të saktë, por gjithashtu të sigurojnë fleksibilitet dhe zgjerueshmëri për të lejuar shtimin dhe zbulimin e llojeve të reja të të dhënave në të ardhmen. Përveç kësaj, është e nevojshme të merret me tabela të mëdha autonome. Të dhënat e qëndrueshme mund të ruhen në tabela me madhësi shumë petabayti. Kjo mund të çojë në ulje të shpejtësisë së skanimit. Për më tepër, ne duhet të respektojmë një klasifikim të rreptë SLA për të dhënat e paqëndrueshme. Kjo e bën sistemin shumë efikas, të shpejtë dhe të saktë. Së fundmi, ne duhet të sigurojmë klasifikimin e të dhënave me vonesë të ulët për të dhënat e paqëndrueshme, për të realizuar klasifikimin në kohë reale, si dhe për rastet e përdorimit në internet.
Ky artikull përshkruan se si e trajtuam problemin e mësipërm dhe paraqet një sistem klasifikimi të shpejtë dhe të shkallëzuar, i cili klasifikon elementët e të dhënave të të gjitha llojeve, formateve dhe burimeve mbi një grup të përbashkët veçorish. Ne zgjeruam arkitekturën e sistemit dhe krijuam një model të veçantë të mësimit të makinerisë për klasifikimin e shpejtë të të dhënave offline dhe online. Ky artikull është organizuar si më poshtë: në Seksionin 2 paraqitet dizajni i përgjithshëm i sistemit. Në Seksionin 3 diskutojmë pjesët e sistemit të mësimit të makinerisë. Në Seksionet 4 dhe 5 flitet për punën e lidhur dhe për të ardhmen e punës.
Arkitektura
Për të përballuar problemet e të dhënave të qëndrueshme dhe të dhënave online në shkallën e Facebook-ut, sistemi i klasifikimit ka dy rrjedha të ndara, të cilat do t'i diskutojmë në detaje.
Të dhëna të qëndrueshme
Së pari, sistemi duhet të njohë një shumëllojshmëri aktivash informativë në Facebook. Për çdo depo, mblidhet ndonjë informacion bazë, siç është qendra e të dhënave që përmban këto të dhëna, sistemi që ka këto të dhëna dhe aktivet e ndodhura në depo specifike të dhënash. Kjo formon një katalog të të dhënave metadatatike, duke lejuar sistemin të nxjerrë informacionin në mënyrë efikase pa e ngarkuar klientin dhe burimet e përdorura nga inxhinierët e tjerë.
Ky katalog i të dhënave metadatatike siguron një burim të besueshëm për të gjithë aktivet e skanuara dhe lejon monitorimin e gjendjes së aktivave të ndryshme. Me këtë informacion, vendoset përparësia e planifikimit në bazë të të dhënave të mbledhura dhe informacionit të brendshëm nga sistemin, siç është koha e fundit e skanimit të suksesshëm të aktivës dhe koha e krijimit të saj, si dhe kërkesat e kaluara për kujtesë dhe procesor për këtë aktiv, nëse është skanuar më parë. Pastaj, për çdo burim të dhënash (ndërsa burimet bëhen të disponueshme), thirret detyra e skanimit aktual të burimit.
Çdo detyrë është një skedar i kompiluar binar që kryen një mostër Beras të fundit të dhënash që janë të disponueshme për çdo aktiv. Aktiviteti ndahet në kolona të veçanta, ku rezultati i klasifikimit për çdo kolonë përpunohen në mënyrë të pavarur. Për më tepër, sistemi skanon çdo të dhënë të përmbledhur brenda kolonave. JSON, arrays, struktura të koduara, URL-të, të dhënat e serialize të base 64 dhe shumë të tjera – të gjitha këto skanohen. Kjo mund të rrisë ndjeshëm kohën e ekzekutimit të skanimit, pasi një tabelë mund të përmbajë mijëra kolona të ngulitura në një objekt të madh binaire. json.
Për çdo rresht që përzgjidhet në aktivin e dhënave, sistemi i klasifikimit nxjerr objektet e lundrueshme dhe tekstet nga përmbajtja dhe lidh secilin objekt mbrapsht me kolonën nga e cila është marrë. Rezultati i fazës së nxjerrjes së objekteve është një hartë e të gjithë objekteve për çdo kolonë të gjetur në aktivin e dhënave.
Për çfarë nevojiten karakteristikat?
Koncepti i karakteristikave është një çështje kyçe. Në vend të karakteristikave float dhe text, ne mund të dërgojmë mostra të papërpunuara të rreshtave, të cilat janë nxjerrë direkt nga çdo burim të dhënash. Për më tepër, modelet e mësimit të makinerisë mund të trajnohen direkt me çdo mostër, në vend të qindra llogaritjeve të karakteristikave që vetëm përpiqen të afrojë mostrën. Këtij fenomeni i japin disa arsye:
- Privatësia para së gjithash: e rëndësishme, koncepti i karakteristikave na lejon të mbajmë në kujtesë vetëm ato mostra që nxjerrim. Kjo garanton që ne ruajmë mostrat për një qëllim të vetëm dhe asnjëherë nuk i regjistrojmë ato me përpjekjet tona. Kjo është veçanërisht e rëndësishme për të dhënat e paqëndrueshme, pasi shërbimi duhet të mbajë një gjendje klasifikimi para se të ofrojë parashikimin.
- Kujtesa: disa mostra mund të kenë gjatësi në mijëra karaktere. Ruajtja e të dhënave të tilla dhe transmetimi i tyre në disa pjesë të sistemit pa nevojë konsumon shumë bajte shtesë. Dy faktorë mund të kombinohen me kalimin e kohës, duke marrë parasysh se ka shumë burime të dhënash me mijëra kolona.
- Agregimi i karakteristikave: me anë të karakteristikave, rezultatet e çdo skanimi paraqiten qartë përmes grupit të tyre, duke lejuar sistemin të bashkojë rezultatet e skanimeve të mëparshme të të njëjtit burim të dhënash në një mënyrë të përshtatshme. Kjo mund të jetë e dobishme për të agreguar rezultatet e skanimit të një burimi të dhënash në disa execucione.
Më pas, karakteristikat dërgohen në shërbimin e parashikimit, ku ne përdorim klasifikimin e bazuar në rregulla dhe mësimin e automatik për të parashikuar etiketat e të dhënave për çdo kolonë. Shërbimi mbështetet si në klasifikuesit e rregullave ashtu edhe në mësimin e automatik dhe zgjedh parashikimin më të mirë të dhënë nga çdo objekt parashikimi.
Klasifikuesit e rregullave janë një heuristik manual, ata përdorin llogaritje dhe koeficientë për të normalizuar objektin në një gamë nga 0 deri në 100. Pasi që një pikë fillestare krijohet për çdo lloj të dhënash dhe emri i kolonës përkatës, që nuk përfshihet në asnjë 'listë të ndaluar', klasifikuesi i rregullave zgjedh pikën më të lartë të normalizuar mes të gjitha llojeve të të dhënave.
Për shkak të kompleksitetit të klasifikimit, përdorimi ekskluzivisht i heuristikës manuale çon në saktësi të ulët në klasifikim, veçanërisht për të dhënat e pa strukturuara. Për këtë arsye, ne kemi zhvilluar një sistem të mësimit të makinerive për të punuar me klasifikimin e të dhënave të pa strukturuara, siç janë përmbajtjet e përdoruesve dhe adresat. Mësimi i makinave na ka lejuar të fillojmë të largohemi nga heuristika manuale dhe të aplikojmë sinjale të tjera të dhënash (p.sh., emrat e kolonave, origjina e të dhënave), duke rritur ndjeshëm saktësinë e identifikimit. Ne do të thellohemi më tej në arkitekturën tonë të mësimit të makinave më vonë.
Shërbimi i parashikimit ruan rezultatet për çdo kolonë së bashku me metadata që lidhen me kohën dhe gjendjen e skanimit. Çdo konsumator dhe proceset e poshtme që varen nga këto të dhëna, mund t'i lexojnë ato nga sërë të dhënash që publikohen çdo ditë. Ky set agregon rezultatet e të gjitha këtyre detyrave të skanimit, ose API-në e kohës reale të katalogut të të dhënave. Parashikimet e publikuara janë themeli i automatikisht aplikimit të politikës së privatësisë dhe sigurisë.
Në fund, pasi shërbimi i parashikimit të regjistrojë të gjithë të dhënat dhe të gjitha parashikimet të ruajten, API i katelogut tonë të të dhënave mund të kthejë të gjitha parashikimet e tipave të të dhënave për burimin në kohë reale. Çdo ditë, sistemi publikoon një grup të dhënash që përmban të gjitha parashikimet më të fundit për çdo aktiv.
Të dhënat e pasigurta
Megjithëse procesi i përshkruar më sipër është krijuar për aktivet që ruhen, trafiku që nuk ruhet gjithashtu merret parasysh si një pjesë e të dhënave të organizatës dhe mund të jetë i rëndësishëm. Për këtë arsye, sistemi ofron një API online për gjenerimin e parashikimeve të klasifikimit në kohë reale për çdo trafik të pasigurt. Sistemi i parashikimit në kohë reale përdoret gjerësisht në klasifikimin e trafikut të daljës, trafikut të hyrjes në modelet e mësimit të makinerive dhe të dhënat e reklamuesve.
Këtu API pranon dy argumente kryesore: çelësi i grumbullimit dhe të dhënat e papërpunuara që duhet të parashikohen. Shërbimi kryen të njëjtin nxjerrje objektesh siç është përshkruar më sipër dhe grupin objektesh së bashku për të njëjtin çelës. Këto karakteristika gjithashtu mbështeten në cache-in e ruajtur për rikuperim pas dështimit. Për çdo çelës grumbullimi, shërbimi garanton se para thirrjes së shërbimit të parashikimit, ai ka parë mjaft muestra në përputhje me procesin e përshkruar më lart.
Optimizimi
Për skanimin e disa depozitave, ne përdorim biblioteka dhe metoda optimizimi në leximin nga depozita e nxehtë [2] dhe garantojmë se nuk ka asnjë dështim nga përdorues të tjerë që kanë akses në të njëjtën depozitë.
Për tabela jashtëzakonisht të mëdha (50+ petabajt), pavarësisht optimizimeve të shumta dhe efikasitetit të memories, sistemi punon për skanimin dhe llogaritjen e gjithçkaje para se të përfundojë memoria. Në fund, skanimi llogaritet plotësisht në memorie dhe nuk ruhet gjatë skanimit. Nëse tabelat e mëdha përmbajnë mijëra kolona me grumbuj të dhënash të pa strukturuar, detyra mund të dështojë për shkak të mungesës së burimeve të memories gjatë kryerjes së parashikimeve për të gjithë tabelën. Kjo do të çojë në reduktimin e mbulimit. Për të luftuar këtë, ne e kemi optimizuar sistemin për të përdorur shpejtësinë e skanimit si një ndërmjetës përsa i përket sasisë sa mirë sistemi përballon ngarkesën aktuale. Ne e përdorim shpejtësinë si një mekanizëm parashikimi, për të parë problemet me memorien dhe në llogaritjen parashikuese të harta objekteve. Në këtë mënyrë, ne përdorim më pak të dhëna se zakonisht.
Sinjalet e të dhënave
Sistemi i klasifikimit është i mirë aq sa janë sinjalet nga të dhënat. Këtu do të shqyrtojmë të gjitha sinjalet që përdoren nga sistemi i klasifikimit.
- Bazuar në përmbajtje: sigurisht, sinjali i parë dhe më i rëndësishëm është përmbajtja. Kryhet një përzgjedhje Bernulli për çdo aset të dhënash që skanojmë dhe nxjerrim karakteristika nga përmbajtja e të dhënave. Shumë karakteristika rrjedhin nga përmbajtja. Mund të ketë çdo numër objektesh të lëvizshëm që përfaqësojnë llogaritjet e numrit të herëve që është vërejtur një tip specifik pattern. Për shembull, mund të kemi karakteristika të numrit të email-ëve që janë parë në përzgjedhje, ose karakteristika të numrit të smiley-ve që janë vërejtur në përzgjedhje. Këto llogaritje karakteristikash mund të normalizohen dhe agregohen për skanime të ndryshme.
- Origjinat e të dhënave: një sinjal i rëndësishëm që mund të ndihmojë kur përmbajtja ka ndryshuar nga tabela prind. Një shembull i zakonshëm është të dhënat e hash-it. Kur të dhënat në tabelën fëmijë hash-ohen, ato shpesh vijnë nga tabela prind, ku qëndrojnë në formë të hapur. Të dhënat mbi origjinën ndihmojnë në klasifikimin e tipeve të caktuara të të dhënave kur ato nuk lexohen qartë ose janë transformuar nga tabela lart në rrjedhë.
- Annotimet: një tjetër sinjal me cilësi të lartë që ndihmon në identifikimin e të dhënave të pa strukturuara. Në fakt, annotimet dhe të dhënat e origjinës mund të punojnë së bashku për të shpërndarë atribute midis aktiveve të ndryshme të të dhënave. Annotimet ndihmojnë në identifikimin e burimit të të dhënave të pa strukturuara, ndërsa të dhënat e origjinës mund të ndihmojnë në gjurmimin e flukseve të këtyre të dhënave në të gjithë ruajtjen.
- Injeksioni i të dhënave është një metodë në të cilën simbole speciale, të lexueshme, gënjehen në burime të njohura me lloje të njohura të të dhënave. Pastaj, sa herë që ne skanojmë përmbajtjen me një sekuencë të njëjtë të simboleve të padukshme, mund të konkludohet se përmbajtja buron nga ky lloj i njohur i të dhënave. Ky është një tjetër sinjal cilësor i të dhënave, i ngjashëm me annotimet. Përveç asaj, zbulimi mbi përmbajtjen ndihmon në zbuluar të dhënat e futur.
Metrika e matjes
Një komponent i rëndësishëm është metodologjia rigoroze e matjes së metriku. Metrikat kryesore të iteracionit për përmirësimin e klasifikimit janë saktësia dhe rikthimi i çdo etikete, me vlerësimin F2 që është më i rëndësishmi.
Për të llogaritur këto tregues, është e nevojshme një metodologji e pavarur e etiketimit të të dhënave që nuk varet nga sistemi vetë, por mund të përdoret për krahasim të drejtpërdrejtë me të. Më poshtë do të përshkruajmë se si e mbledhim të vërtetën kryesore nga Facebook dhe e përdorim atë për të trajnuar sistemin tonë të klasifikimit.
Grumbullimi i të dhënave të sakta
Ne grumbullojmë të dhëna të sakta nga çdo burim të listuar më poshtë, në tabelën e tij të vetme. Çdo tabelë është përgjegjëse për agregimin e vlerave më të fundit të vëzhguara nga ky burim specifik. Çdo burim ka një kontroll të cilësisë së të dhënave për të garantuar që vlerat e vëzhguara për çdo burim janë të larta dhe përmbajnë etiketat më të fundit të llojeve të të dhënave.
- Konfigurimet e platformës së regjistrimit: disa fusha në tabelat e ultrave mbushen me të dhëna që i përkasin një tipi të caktuar. Përdorimi dhe shpërndarja e këtyre të dhënave shërbejnë si një burim i besueshëm i të dhënave të sakta.
- Shënjimi manual: zhvilluesit që mbështesin sistemin, si dhe shënjuesit e jashtëm, janë të trajnuar për të shënjuar kolonat. Kjo zakonisht funksionon mirë për të gjitha llojet e të dhënave në depo, dhe mund të jetë burimi kryesor i besueshmërisë për disa të dhëna të pa-strukturuara, si të dhënat e mesazheve ose përmbajtjen e përdoruesve.
- Kolonat nga tabelat prind mund të shënohen ose të anotohen si që përmbajnë të dhëna të caktuara, dhe ne mund të ndjekim këto të dhëna në tabelat e poshtme.
- Selekcioni i rrjedhave të ekzekutimit: rrjedhat e ekzekutimit në Facebook mbajnë të dhëna të një tipi të caktuar. Duke përdorur skanerin tonë si një arkitekturë shërbimi, ne mund të selektojmë rrjedhat që kanë lloje të njohura të të dhënave dhe t'i dërgojmë ato nëpërmjet sistemit. Sistemi premton të mos ruajë këto të dhëna.
- Tabela e seleksionimit: tabela të mëdha, të njohura për përmbajtjen e të dhënave të plota, mund të përdoren gjithashtu si të dhëna stërvitore dhe të transmetohen përmes një skaner si shërbim. Kjo është ideale për tabelat me një gamë të plotë tipesh të dhënash, duke bërë që seleksioni i kolonave në mënyrë rastësore të jetë ekuivalent me seleksionimin e tërë grupit të këtij lloj të dhënash.
- Të dhëna sintetike: ne mund të përdorim madje biblioteka që gjenerojnë të dhëna në kohë reale. Kjo funksionon mirë për tregues të thjeshtë dhe publikë, si adresa ose GPS.
- Menaxherët e të dhënave: programet e privatësisë zakonisht përdorin menaxherë të të dhënave për të lidhur manuelisht politikat me pjesët e të dhënave. Kjo ofron një burim shumë të saktë të besueshmërisë.
Ne nevojitet pranishmëri e çdo burimi kryesor të dhënash të besueshme në një njësi me të gjitha këto të dhëna. Problemi më i madh me besueshmërinë është të sigurohemi që ajo është përfaqësuese për magazinën e të dhënave. Përndryshe, motorët e klasifikimit mund të stërviten keq. Për të luftuar këtë, të gjithë burimet e mësipërme përdoren për të siguruar një balancë gjatë trajnimit të modeleve ose llogaritjes së metrikeve. Për më tepër, njerëzit e etiketimit zgjedhin në mënyrë të barabartë kolona të ndryshme në magazinën e të dhënave dhe i etiketohet të dhënat në përputhje, që grumbullimi i vlerave të besueshme të mbetet i paanshëm.
Integrimi i vazhdueshëm
Për të siguruar iterim të shpejtë dhe përmirësim, është thelbësore të masim gjithmonë performancën e sistemit në kohë reale. Ne mund të masim çdo përmirësim të klasifikimit në krahasim me sistemin sot, në mënyrë që taktikisht të mund të orientojmë të dhënat në përmirësimet në vazhdim. Këtu do të shqyrtojmë se si sistemi e përfundon ciklin e rikthimit, i cili sigurohet nga të dhënat e besueshme.
Kur sistemi i planifikimit përballet me një aset që ka një etiketë nga një burim të besueshëm, ne planifikojmë dy detyra. E para përdor skanerët tanë të prodhimit dhe, kështu, kapacitetet tona të prodhimit. Detyra e dytë përdor skanerin e mbledhjes më të fundit me veçoritë më të reja. Çdo detyrë shkruan daljen e saj në tabelën e saj të veçantë, duke shënuar versionet së bashku me rezultatet e klasifikimit.
Kështu ne krahasojmë rezultatet e klasifikimit të versionit kandidatë për lëshim dhe modelit të prodhimit në kohë reale.
Ndërsa grupe të dhënash krahasojnë veçoritë RC dhe PROD, logohen shumë variacione të motorit të klasifikimit të shërbimit të parashikimit. Modeli më i fundit i ndërtuar i mësimit të makinerisë, modeli aktual në prodhim dhe çdo model eksperimental. Të njëjtin qasje na lejon "të presim" versionet e ndryshme të modelit (agnostik të klasifikuesve tanë të rregullave) dhe të krahasojmë metrikat në kohë reale. Kështu është e lehtë të përcaktohet kur eksperimenti me ML është gati për t'u implementuar në prodhim.
Çdo natë, shenjat RC të llogaritura për këtë ditë dërgohen në konvejerin e trajnimit ML, ku modeli trajnohet mbi shenjat më të fundit të RC dhe vlerëson performancën e tij në krahasim me një set të dhënash të besueshëm.
Çdo mëngjes modeli përfundon trajnimin dhe automatikisht publikohet si eksperimentale. Ai automatikisht përfshihet në listën e eksperimentaleve.
Disa rezultate
Më shumë se 100 lloje të ndryshme të të dhënave etiketohen me saktësi të lartë. Llojet e strukturuara mirë, si email-et dhe numrat e telefonit, klasifikohen me një vlerësim f2 më shumë se 0,95. Llojet e lirë të të dhënave, si përmbajtja e përdoruesve dhe emrat, gjithashtu funksionojnë shumë mirë, me gola F2 më shumë se 0,85.
Një numër i madh kolonash të qëndrueshme dhe të paqëndrueshme të dhënash klasifikohen çdo ditë në të gjitha depozitë. Më shumë se 500 terabajt skanojnë çdo ditë në më shumë se 10 depo të të dhënash. Mb coveri i shumicës së këtyre depozita është më shumë se 98%.
Me gjatë kohës, klasifikimi është bërë shumë efektiv, pasi detyrat e klasifikimit në rrjedhën autonome të ruajtur zgjatin mesatarisht 35 sekonda nga skanimi i aktivizimit deri në llogaritjen e parashikimeve për çdo kolonë.
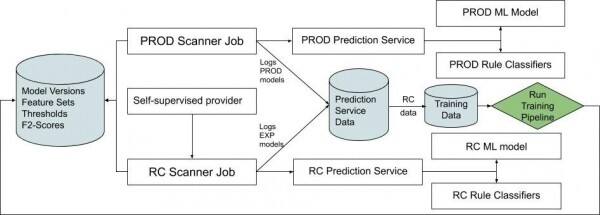
Fig. 2. Diagrami që përshkruan rrjedhën e vazhdueshme të integrimit për të kuptuar se si gjërat RC generohet dhe dërgohet në model.
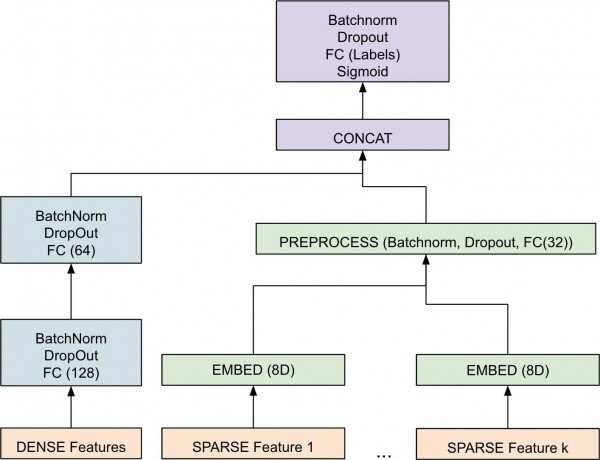
Figura 3. Diagrami në nivel të lartë i komponentës së mësimit të makinerive.
Komponenti i sistemit të mësimit të makinerive
Në seksionin e kaluar ne thellë hulumtuam arkitekturën e tërë sistemit, duke theksuar shkallën, optimizimin dhe rrjedhat e të dhënave në modin autonom dhe online. Në këtë seksion do të shqyrtojmë shërbimin e parashikimit dhe do të përshkruajmë sistemin e mësimit të makinerive që siguron funksionimin e shërbimit të parashikimit.
Me më shumë se 100 lloje të të dhënave dhe disa përmbajtje të pa-strukturuar, si të dhënat e mesazheve dhe përmbajtja e përdoruesve, përdorimi ekskluziv i heuristikës manuale rezulton në saktësi klasifikimi subparare, veçanërisht për të dhënat e pa-strukturuar. Për këtë arsye, ne gjithashtu zhvilluam një sistem mësimi makina për të adresuar kompleksitetet e të dhënave të pa-strukturuar. Përdorimi i mësimit të makinave lejon fillimin e një shkëputjeje nga heuristika manuale dhe punën me tiparet dhe sinjalet shtesë të të dhënave (p.sh. emrat e kolonave, origjina e të dhënave) për të përmirësuar saktësinë.
Modeli i realizuar studioja përfaqësimet vektoriale [3] për objekte të dendura dhe të shpërndara veçmas. Më pas, ato bashkohen për të formuar një vektor që kalon përmes një serie fazash të normalizimit të paketave [4] dhe nonlineariteteve për të arritur rezultatin përfundimtar. Rezultati përfundimtar është një numër me presje lëvizëse ndërmjet [0-1] për çdo etiketë, që tregon probabilitetin se shembulli i përket këtij lloji ndjeshmërie. Përdorimi i PyTorch për modelin na lehtësoi të lëvizim më shpejt, duke mundësuar zhvilluesve jashtë ekipit të bëjnë shpejt dhe të testojnë ndryshimet.
Në projektimin e arkitekturës, ishte e rëndësishme të modeloheshin veçmas objekte të shpërndara (p.sh., tekst) dhe të dendura (p.sh., numra) për shkak të dallimeve të tyre të brendshme. Po ashtu, për arkitekturën përfundimtare ishte e rëndësishme të realizohej shpërndarja e parametrave, për të gjetur vlerën optimale të shpejtësisë së të mësuarit, madhësisë së paketës dhe hiperparametrave të tjerë. Zgjedhja e optimizuesit ishte gjithashtu një hiperparametër i rëndësishëm. Zbuluam se optimizuesi popullor Adamshpesh çon në mbingarkesë, ndërsa modeli me SGD më të qëndrueshme. Ishin disa nuanca shtesë që duhej t’i përfshinin në modelin vetë. Për shembull, rregullat statike që garantonin që modeli bënte një parashikim deterministik kur një karakteristikë kishte një vlerë të caktuar. Këto rregulla statike janë të përcaktuara nga klientët tanë. Ne zbuluam se përfshirja e tyre në model çoi në krijimin e një arkitekture më të pavarur dhe të besueshme, për dallim nga implementimi i një faze post-procesimi për të trajtuar këto raste speciale të kufizimeve. Gjithashtu, vini re se gjatë trajnimit këto rregulla janë të çkyçura për të mos penguar procesin e trajnimit të gradientit.
Problemet
Një nga problemet ishte mbledhja e të dhënave të besueshme dhe cilësore. Modeli ka nevojë për besueshmëri për çdo kategori, që të mund të studiojë asocimet midis objekteve dhe etiketave. Në seksionin e mëparshëm diskutuam për metodat e mbledhjes së të dhënave si për matjen e sistemit ashtu edhe për trajnimin e modeleve. Analiza tregoi se kategori të dhënash si numrat e kartave të kreditit dhe llogaritë bankare nuk janë shumë të përhapura në depozitat tona. Kjo e bën të vështirë mbledhjen e një sasi të madhe të dhënash të besueshme për trajnimin e modeleve. Për të zgjidhur këtë problem, kemi zhvilluar procese për fitimin e të dhënave sintetike të besueshme për këto kategori. Ne gjenerojmë të dhëna të tilla për lloje të ndjeshme, duke përfshirë SSN, numrat e kartave të kreditit dhe IBAN-numrat për të cilat modeli nuk ka mundur të parashikojë më parë. Ky qasje lejon trajtimin e llojeve të dhënash konfidenciale pa rrezikun e privacisë që lidhet me fshehjen e të dhënave reale konfidenciale.
Përveç problemeve të besueshmërisë së të dhënave, ekzistojnë probleme të hapura të arkitekturës mbi të cilat po punojmë, siç janë izolimi i ndryshimeve dhe ndalimi i hershëm. Izolimi i ndryshimeve është i rëndësishëm për të siguruar që kur bëhen ndryshime të ndryshme në pjesë të ndryshme të rrjetit, ndikimi të izolohet nga klasat specifike dhe të mos ketë një ndikim të gjerë në performancën e përgjithshme të parashikimit. Përmirësimi i kritereve të ndaljes së hershme gjithashtu ka rëndësi thelbësore, në mënyrë që të mund të ndalojmë procesin e trajnim në një pikë të qëndrueshme për të gjitha klasat, dhe jo në atë pikë ku disa klasa përshtaten shumë, ndërsa të tjera jo.
Rëndësia e veçorisë
Kur një veçori e re prezantohet në model, ne duam të dimë ndikimin e saj të përgjithshëm në model. Ne gjithashtu duam të sigurohemi që parashikimet janë interpretuese nga njeriu, për të kuptuar saktësisht se cilat veçori përdoren për çdo tip të të dhënave. Për këtë, ne kemi zhvilluar dhe introduktuar për klasat rëndësia e veçorive për modelin PyTorch. Vini re se kjo është ndryshe nga rëndësia e përgjithshme e veçorisë, e cila zakonisht mbështetet, sepse ajo nuk na tregon se cilat janë veçoritë e rëndësishme për një klasë të caktuar. Ne e masim rëndësinë e objektit duke llogaritur rritjen e gabimit të parashikimit pas riorganizimit të objektit. Një veçori është "e rëndësishme" kur riorganizimi i vlerave rrit gabimin e modelit, pasi në këtë rast modeli mbështetet në veçorinë për parashikimin. Një veçori është "e parëndësishme" kur riorganizimi i vlerave të saj e lë gabimin e modelit të pandryshuar, pasi në këtë rast modeli e injoron atë [5].
Rëndësia e veçorisë për çdo klasë lejon që modeli të jetë i interpretuar, në mënyrë që ne të mund të shohim se në çfarë i kushton vëmendje modeli gjatë parashikimit të etiketës. Për shembull, kur analizojmë ADDR, sigurojmë që veçoria e lidhur me adresën, si AddressLinesCount, të jetë në vend të lartë në tabelën e rëndësisë së veçorive për çdo klasë, për t'u siguruar që intuicioni ynë njerëzor të përputhet mirë me atë që është mësuar nga modeli.
Vlerësimi
Është e rëndësishme të përcaktohet një metrikë e vetme suksesi. Ne zgjodhëm F2 — balancë midis reagimit dhe saktësisë (devijimi i reagimit është pak më i madh). Reagimi është më i rëndësishëm për rastin e përdorimit të privatësisë sesa saktësia, pasi është thelbësore për ekipin të mos humbasë asnjë të dhënë konfidenciale (duke siguruar një saktësi të arsyeshme). Të dhënat faktike të vlerësimit të performancës F2 të modelit tonë kalojnë përtej këtij artikulli. Megjithatë, me konfigurim të kujdesshëm mund të arrijmë një rezultat të lartë (0.9+) F2 për klasat më të ndjeshme.
Puna e lidhur
Ekzistojnë shumë algoritme të klasifikimit automatik të dokumenteve të pa strukturuara duke përdorur metoda të ndryshme, të tilla si përputhja e shablloneve, kërkimi i ngjashmërisë së dokumenteve dhe metoda të ndryshme të mësimit mesin (bayesian, pemë vendimesh, k-afërsia e afërt dhe shumë të tjera) [6]. Cdo prej tyre mund të përdoret si pjesë e klasifikimit. Megjithatë, problemi qëndron te shkallëzueshmëria. Qasja e klasifikimit në këtë artikull është e orientuar drejt fleksibilitetit dhe performancës. Kjo na lejon të mbështesim klasat e reja në të ardhmen dhe të ruajmë vonesë të ulët.
Ekziston gjithashtu një numër i madh punësh për heqjen e gjurmëve nga të dhënat. Për shembull, autorët në [7] përshkruajnë një zgjidhje që përqendrohet në problemin e kapjes së rrjedhjeve të të dhënave të ndjeshme. Supozimi kryesor është mundësia e gjurmës për të krahasuar atë me një grup të njohur të të dhënave të ndjeshme. Autorët në [8] përshkruajnë një problem të ngjashëm të rrjedhjes së privatësisë, por zgjidhja e tyre bazohet në një arkitekturë specifike Android dhe klasifikohet vetëm në rast se veprimet e përdoruesit çuan në dërgimin e informacionit personal ose nëse një aplikacion bazë rrjedh të dhënat e përdoruesit. Situata këtu është ndonjëherë ndryshe, pasi të dhënat e përdoruesit gjithashtu mund të jenë shumë të strukturuara. Prandaj, na nevojitet një teknikë më e sofistikuar sesa heqja e gjurmëve.
Më në fund, për të përballuar mungesën e të dhënave për disa lloje të dhënash të ndjeshme, ne prezantuam të dhëna sintetike. Ekziston një volum i madh literaturë mbi augmentimin e të dhënave, për shembull, autorët në [9] studiuan rolin e injeksionit të zhurmës gjatë trajnimit dhe vunë re rezultate pozitive në mësimin e kontrolluar. Qasja jonë ndaj privatësisë është ndryshe, sepse introduktimi i të dhënave të zhurmshme mund të jetë kunderproduktiv, dhe në vend të kësaj përqendrohemi në të dhëna sintetike të cilësisë së lartë.
Përfundimi
Në këtë artikull, ne prezantuam një sistem që mund të klasifikojë një fragment të dhënash. Kjo na lejon të krijojmë sisteme për të siguruar përputhshmërinë me politikat e privatësisë dhe sigurisë. Ne treguam se infrastruktura e shkallëzuar, integrimi i vazhdueshëm, mësimi me makinë dhe të dhënat cilësore mbi besueshmërinë e të dhënave luajnë një rol kyç në suksesin e shumë iniciativave tona në fushën e privatësisë.
Ekzistojnë shumë drejtime për punën e ardhshme. Ajo mund të përfshijë ofrimin e mbështetjes për të dhënat jo të strukturuara (skedarët), klasifikimin jo vetëm të tipeve të të dhënave, por edhe të nivelit të ndjeshmërisë, si dhe përdorimin e mësimit të vetëkryer në mënyrë të drejtpërdrejtë gjatë mësimit përmes gjenerimit të shembujve të saktë sintetikë. Këta shembuj do të ndihmojnë modelin të zvogëlojë humbjet në masën më të madhe. Puna e ardhshme mund të përqendrohet gjithashtu në procesin e hetimit, ku ne dalim përtej zbulesës dhe ofrojmë një analizë të shkakut rrënor të shkeljeve të ndryshme të privatësisë. Kjo do të ndihmojë në raste të tilla si analiza e ndjeshmërisë (p.sh., a është ndjeshmëria e privatësisë së tipi të dhënave e lartë (p.sh., IP e përdoruesit) apo e ulët (p.sh., IP e brendshme e Facebook-ut)).
Bibliografia
- David Ben-David, Tamar Domany, dhe Abigail Tarem. Klasifikimi i të dhënave në ndërmarrje duke përdorur teknologjitë e web-it semantik. Në Peter F.Ï Patel-Schneider, Yue Pan, Pascal Hitzler, Peter Mika, Lei Zhang, Jeff Z. Pan, Ian Horrocks, dhe Birte Glimm, redaktorë, Webi Semantik – ISWC 2010, fq. 66–81, Berlin, Heidelberg, 2010. Springer Berlin Heidelberg.
- Subramanian Muralidhar, Wyatt Lloyd, Sabyasachi Roy, Cory Hill, Ernest Lin, Weiwen Liu, Satadru Pan, Shiva Shankar, Viswanath Sivakumar, Linpeng Tang, dhe Sanjeev Kumar. f4: Sistemi i ngrohtë i ruajtjes BLOB të Facebook. Simpoziumi i 11-të USENIX mbi Dizajnin dhe Zbatimin e Sistemeve Operative (OSDI 14), fq. 383–398, Broomfield, CO, Tetor 2014. Shoqata USENIX.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, dhe Jeff Dean. Përfaqësimet e shpërndara të fjalëve dhe frazave dhe përbërshmëria e tyre. Në C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, dhe K. Q. Weinberger, redaktues, Përparimet në Sistemet e Informacionit Neural 26, fq. 3111–3119. Curran Associates, Inc., 2013.
- Sergey Ioffe dhe Christian Szegedy. Normalizimi i grupeve: Accelerating trajnimi i rrjetit të thellë duke reduktuar ndryshimin e brendshëm të variablave. Në Francis Bach dhe David Blei, redaktues, Aktet e Konferencës Ndërkombëtare të 32-të mbi Mësimin e Makinerive, vëllimi 37 i Aktet e Kërkimeve mbi Mësimin e Makinerive, fq. 448–456, Lille, Francë, 07–09 Korrik 2015. PMLR.
- Leo Breiman. Pyjet e rastësishme. Mach. Learn., 45(1):5–32, Tetor 2001.
- Thair Nu Phyu. Anketë mbi teknikat e klasifikimit në minierat e të dhënave.
- X. Shu, D. Yao, dhe E. Bertino. Zbulimi që ruan privatësinë të ekspozimit të të dhënave të ndjeshme. Transaksionet IEEE mbi Forensikën dhe Sigurinë e Informacionit, 10(5):1092–1103, 2015.
- Zhemin Yang, Min Yang, Yuan Zhang, Guofei Gu, Peng Ning, dhe Xiaoyang Wang. Appintent: Duke analizuar transmetimin e të dhënave të ndjeshme në android për zbulimin e rrjedhjes së privatësisë. fq. 1043–1054, 11 2013.
- Qizhe Xie, Zihang Dai, Eduard H. Hovy, Minh-Thang Luong, dhe Quoc V. Le. Rritja e të dhënave pa mbikëqyrje.
Merrni detaje se si të fitoni një profesion të kërkuar nga e para ose të përmirësoni aftësitë dhe pagat përmes kurseve online SkillFactory:
- (12 muaj)
- (12 javë)
- (20 javë)
- (20 javë)
E tjera kurse
- (9 muaj)
- (8 muaj)
- (9 muaj)
- (12 muaj)
- (18 muaj)
- (12 muaj)
- (9 muaj)
- (7 muaj)

Burimi: habr.com
