

Përshëndetje.
Решил поделится своей находкой — плодом раздумий, проб и ошибок.
По большому счёту: это никакая не находка, конечно же — всё это должно быть давно известно, тем кто занимается прикладной стат-обработкой данных и оптимизацией каких либо систем, не обязательно именно СУБД.
И: да знают, пишут занятные статьи по своим ресерчам, (UPD.: в комментариях указали на очень интересный проект: )
С другой стороны: навскидку не усматриваю широкого упоминания, распространения такого подхода, в интернете, среди ит-специалистов, ДБА.
Итак, к сути.
Предположим что вот у нас задача: настроить некую сервисную систему, на обслуживание какой то работы.
Про эту работу — известно: какая она, в чём измеряется качество этой работы и какой критерий показатель замеров этого качества.
Также допустим что, более-менее известно-понятно: как именно выполняется работа в (или с) этой сервисной системой.
"Более-менее" — это значит что есть возможность подготовить (или где то взять) некий тулз, утилиту, сервис которым можно синтезировать и подать на систему тестовую нагрузку достаточно адекватную к тому что будет в проде, в достаточно адекватных к работе в проде условиях.
Ну и допустим что известен набор регулировочных параметров этой сервисной системы, которыми можно настраивать эту систему, в смысле продуктивности её работы.
И, в чём проблема — нет достаточно полного понимания этой сервисной системы, такого который позволяет экспертно выставить настройку этой системы, под будущую нагрузку, на данной платформе и получить нужно продуктивность работы системы.
Ну. Так, почти всегда и бывает.
Что тут можно сделать.
Ну первое, что приходит в голову: заглянуть в доку по этой системе. Понять — какие там допустимые диапазоны на значения регулировочных параметров. И, например, методом координатного спуска, подбирать значения для параметров системы, в тестах.
Т.е. задавать системе какую то конфигурацию, в виде конкретного набора значений её настроечных пар-ров.
Подавать на неё тестовую нагрузку, вот этой самой тулзой-утилитой, лоад-генератором.
И смотреть величину — отклик, ну или метрику качества работы системы.
Второй мыслью может быть заключение такое что — это же очень долго.
Ну т.е.: если настроечных параметров — много, если пробегаемые диапазоны их значений — большие, если каждый отдельный нагрузочный тест — выполняется много времени, то: да, это всё может занять не приемлемо много времени.
Ну и тут что можно понять и вспомнить.
Можно узнать, в наборе значений настроечных параметров сервисной системы — вектор, как последовательность каких то значений.
Каждому такому вектору, при прочих равных (в том что этим вектором не затрагивается) соответствует вполне себе определённое значение метрики — показателя качества работы системы, под тестовой нагрузкой.
Т.е.
Вот обозначим вектор конфигурации системы, как  , ku
, ku  ; Где
; Где  — кол-во параметров конфигурации системы, сколько их, этих параметров.
— кол-во параметров конфигурации системы, сколько их, этих параметров.
А значение метрики, соответствующей данному  обозначим как
обозначим как
 , то, у нас получается функция:
, то, у нас получается функция: 
Ну и, тогда: всё немедленно сводится к, в моём случае: почти забытым со студенческой скамьи, алгоритмам поиска экстремума функции.
Хорошо, но тут возникает организационно-прикладной вопрос: а какой именно алгоритм использовать.
- В смысле — чтобы самому поменьше руками кодить.
- И чтобы работало, т.е. находило экстремум (если он есть), ну, по крайней мере — быстрее координатного спуска.
Первый момент намекает что надо посмотреть в сторону каких то сред, в которых такие алгоритмы — уже реализованы, и есть, в каком то виде, готовом к использованию в коде.
Ну, мне известны python dhe cran-r
Второй момент обозначает что надо почитать про собственно алгоритмы, какие они есть, какие у них требования, особенности в работе.
И что они дают, могут быть полезные побочные эффекты-результаты, либо впрямую, от самого алгоритма.
Либо их можно получить на итогах работы алгоритма.
Тут многое зависит от входных условий.
Например если, по каким то причинам, нужно быстрее получить результат, ну, нужно смотреть в сторону алгоритмов градиентного спуска, выбирать какой то из них.
Или, если не так важно время, можно например попользоваться методами стохастической оптимизации, например генетическим алгоритмом.
Предлагаю рассмотреть работу такого подхода, по подбору конфигурации системы, с использованием генетического алгоритма, на следующей, так сказать: лабораторной работе.
Исходные:
- Пусть есть, в качестве сервисной системы:
oracle xe 18c - Пусть она — обслуживает транзакционную активность и цель: получить возможно большую пропускную способность субд, по транзакциям/сек.
- Транзакции — бывают сильно разные, по своему характеру работы с данными и контексту работы.
Условимся так что это транзакции которые не обрабатывают большое кол-во табличных данных.
В том смысле что не генерируют ундо-данных больше чем редо и не обрабатывают большие проценты строк, больших таблиц.
Это транзакции которые меняют одну строку в более-менее большой таблице, с небольшим кол-вом индексов над этой таблицей.
В таком раскладе: продуктивность субд по обработке транзакций будет, с оговоркой, определяться качеством обработки базой редо-данных.
Оговорка — если говорить именно про настройках субд.
Потому что, в общем случае, могут быть, например, транзакционные блокировки, между скл-сессиями, из-за, дизайна пользовательской работы с табличными данными и/или табличной модели.
Которые, конечно же, будут угнетающе сказываться на tps-метрике и это будет экзогенный, относительно субд, фактор: ну вот так задизайнили табличную модель и работу с данными в ней что возникают блокировки.
Поэтому, для чистоты эксперимента, исключим этот фактор, ниже уточню как именно.
- Предположим, для определённости, что 100% подаваемых в субд sql-команд: это dml-команды.
Пусть характеристики пользовательской работы с субд: одни и те же, в тестах.
А именно: кол-во скл-сессий, табличные данные, то как с ними работают скл-сессии. - Субд работает в
FORCE LOGGING,ARCHIVELOGмодах. Флешбак-датабейс режим выключен, на уровне субд. - Редо-логи: расположены в отдельной файловой системе, на отдельном "диске";
Вся остальная часть физической компоненты бд: в другой, отдельной фс, на отдельном "диске":
Подробнее, про устройство физ. компоненты лабораторной бд
SQL> select status||' '||name from v$controlfile;
/db/u14/oradata/XE/control01.ctl
SQL> select GROUP#||' '||MEMBER from v$logfile;
1 /db/u02/oradata/XE/redo01_01.log
2 /db/u02/oradata/XE/redo02_01.log
SQL> select FILE_ID||' '||TABLESPACE_NAME||' '||round(BYTES/1024/1024,2)||' '||FILE_NAME as col from dba_data_files;
4 UNDOTBS1 2208 /db/u14/oradata/XE/undotbs1_01.dbf
2 SLOB 128 /db/u14/oradata/XE/slob01.dbf
7 USERS 5 /db/u14/oradata/XE/users01.dbf
1 SYSTEM 860 /db/u14/oradata/XE/system01.dbf
3 SYSAUX 550 /db/u14/oradata/XE/sysaux01.dbf
5 MONITOR 128 /db/u14/oradata/XE/monitor.dbf
SQL> !cat /proc/mounts | egrep "/db/u[0-2]"
/dev/vda1 /db/u14 ext4 rw,noatime,nodiratime,data=ordered 0 0
/dev/mapper/vgsys-ora_redo /db/u02 xfs rw,noatime,nodiratime,attr2,nobarrier,inode64,logbsize=256k,noquota 0 0Изначально под эти условия нагрузки субд транзакциями хотел использовать
У неё есть такая замечательная особенность, процитирую автора:
At the heart of SLOB is the “SLOB method.” The SLOB Method aims to test platforms
without application contention. One cannot drive maximum hardware performance
using application code that is, for example, bound by application locking or even
sharing Oracle Database blocks. That’s right—there is overhead when sharing data
in data blocks! But SLOB—in its default deployment—is immune to such contention.
Эта декларация: соответствует, так и есть.
Удобно регулировать степень параллелизма скл-сессий, это ключ -t запуска утилиты runit.sh из состава SLOB-а
Регулируется процент дмл-команд, в том кол-ве скл-ей которые отправляет в субд, каждая скл-сессия, параметр UPDATE_PCT
Отдельно и очень удобно: SLOB сам, перед и после сессии нагрузки — готовит статспак, или awr-снапшоты (что задано готовить).
Однако выяснилось что SLOB не поддерживает работу скл-сессий с продолжительностью менее 30 секунд.
Поэтому, сначала накодировал свой, рабоче-крестьянский вариант нагрузчика, а потом он так и остался в работе.
Уточню по нагрузчику — что и как он делает, для ясности.
По существу нагрузчик выглядит так:
Код воркера
function dotx()
{
local v_period="$2"
[ -z "v_period" ] && v_period="0"
source "/home/oracle/testingredotracе/config.conf"
$ORACLE_HOME/bin/sqlplus -S system/${v_system_pwd} << __EOF__
whenever sqlerror exit failure
set verify off
set echo off
set feedback off
define wnum="$1"
define period="$v_period"
set appinfo worker_&&wnum
declare
v_upto number;
v_key number;
v_tots number;
v_cts number;
begin
select max(col1) into v_upto from system.testtab_&&wnum;
SELECT (( SYSDATE - DATE '1970-01-01' ) * 86400 ) into v_cts FROM DUAL;
v_tots := &&period + v_cts;
while v_cts <= v_tots
loop
v_key:=abs(mod(dbms_random.random,v_upto));
if v_key=0 then
v_key:=1;
end if;
update system.testtab_&&wnum t
set t.object_name=translate(dbms_random.string('a', 120), 'abcXYZ', '158249')
where t.col1=v_key
;
commit;
SELECT (( SYSDATE - DATE '1970-01-01' ) * 86400 ) into v_cts FROM DUAL;
end loop;
end;
/
exit
__EOF__
}
export -f dotxЗапускаются воркеры таким образом:
Запуск воркеров
echo "starting test, duration: ${TEST_DURATION}" >> "$v_logfile"
for((i=1;i<="$SQLSESS_COUNT";i++))
do
echo "sql-session: ${i}" >> "$v_logfile"
dotx "$i" "${TEST_DURATION}" &
done
echo "waiting..." >> "$v_logfile"
waitА таблицы для воркеров готовятся так:
Создание таблиц
function createtable() {
source "/home/oracle/testingredotracе/config.conf"
$ORACLE_HOME/bin/sqlplus -S system/${v_system_pwd} << __EOF__
whenever sqlerror continue
set verify off
set echo off
set feedback off
define wnum="$1"
define ts_name="slob"
begin
execute immediate 'drop table system.testtab_&&wnum';
exception when others then null;
end;
/
create table system.testtab_&&wnum tablespace &&ts_name as
select rownum as col1, t.*
from sys.dba_objects t
where rownum<1000
;
create index testtab_&&wnum._idx on system.testtab_&&wnum (col1);
--alter table system.testtab_&&wnum nologging;
--alter index system.testtab_&&wnum._idx nologging;
exit
__EOF__
}
export -f createtable
seq 1 1 "$SQLSESS_COUNT" | xargs -n 1 -P 4 -I {} -t bash -c "createtable "{}"" | tee -a "$v_logfile"
echo "createtable done" >> "$v_logfile"Т.е. под каждый воркер (практически: отдельная скл-сессия в субд) создаётся отдельная таблица, с которой и работает воркер.
Этим достигается отсутствие транзакционных блокировок, между скл-сессиями воркеров.
Каждый воркер: делает одно и тоже, со своей таблицей, таблицы все одинаковые.
Воркеры все — выполняют работу в течении одного и того же кол-ва времени.
Причём — достаточно долгого времени, чтобы, например, точно произошёл, и не один раз лог-свичинг.
Ну и соответственно возникали, с этим связанные, затраты и эффекты.
В моём случае — продолжительность работы воркеров накофигуривал в 8 минут.
Кусок статспак-отчёта, с описанием работы субд под нагрузкой
Database DB Id Instance Inst Num Startup Time Release RAC
~~~~~~~~ ----------- ------------ -------- --------------- ----------- ---
2929910313 XE 1 07-Sep-20 23:12 18.0.0.0.0 NO
Host Name Platform CPUs Cores Sockets Memory (G)
~~~~ ---------------- ---------------------- ----- ----- ------- ------------
billing.izhevsk1 Linux x86 64-bit 2 2 1 15.6
Snapshot Snap Id Snap Time Sessions Curs/Sess Comment
~~~~~~~~ ---------- ------------------ -------- --------- ------------------
Begin Snap: 1630 07-Sep-20 23:12:27 55 .7
End Snap: 1631 07-Sep-20 23:20:29 62 .6
Elapsed: 8.03 (mins) Av Act Sess: 8.4
DB time: 67.31 (mins) DB CPU: 15.01 (mins)
Cache Sizes Begin End
~~~~~~~~~~~ ---------- ----------
Buffer Cache: 1,392M Std Block Size: 8K
Shared Pool: 288M Log Buffer: 103,424K
Load Profile Per Second Per Transaction Per Exec Per Call
~~~~~~~~~~~~ ------------------ ----------------- ----------- -----------
DB time(s): 8.4 0.0 0.00 0.20
DB CPU(s): 1.9 0.0 0.00 0.04
Redo size: 7,685,765.6 978.4
Logical reads: 60,447.0 7.7
Block changes: 47,167.3 6.0
Physical reads: 8.3 0.0
Physical writes: 253.4 0.0
User calls: 42.6 0.0
Parses: 23.2 0.0
Hard parses: 1.2 0.0
W/A MB processed: 1.0 0.0
Logons: 0.5 0.0
Executes: 15,756.5 2.0
Rollbacks: 0.0 0.0
Transactions: 7,855.1Возвращаясь к постановке лабораторной работы.
Будем, при прочих равных, варьировать значения таких параметров лабораторной субд:
- Размер журнальных групп бд. диапазон значений: [32, 1024] Мбайт;
- Кол-во журнальных групп бд. диапазон значений: [2,32];
log_archive_max_processesдиапазон значений: [1,8];commit_loggingдопускается два значения:batch|immediate;commit_waitдопускается два значения:wait|nowait;log_bufferдиапазаон значений: [2,128] Мбайт.log_checkpoint_timeoutдиапазаон значений: [60,1200] секундdb_writer_processesдиапазаон значений: [1,4]undo_retentionдиапазаон значений: [30;300] секундtransactions_per_rollback_segmentдиапазаон значений: [1,8]disk_asynch_ioдопускается два значения:true|false;filesystemio_optionsдопускаются такие значения:none|setall|directIO|asynch;db_block_checkingдопускаются такие значения:OFF|LOW|MEDIUM|FULL;db_block_checksumдопускаются такие значения:OFF|TYPICAL|FULL;
Человек, с опытом сопровождения oracle-баз данных, безусловно, уже сейчас может сказать — что и в какие значения нужно выставлять, из указанных параметров и их допустимых значений, чтобы получить большую продуктивность субд, под ту работу с данными, которая обозначена, прикладным кодом, здесь, выше.
Но.
Смысл лабораторной работы показать что оптимизационный алгоритм, сам и относительно быстро это нам уточнит.
Нам же: остаётся только заглянуть в доку, по настраиваемой системе, ровно настолько, насколько нужно чтобы выяснить: какие параметры и в каких диапазонах изменять.
А так же: накодировать код, которым будет реализована работа с настраиваемой системой выбранного алгоритма оптимизации.
Т.о., теперь о коде.
Выше говорил о cran-r, т.е.: все манипуляции, с настраиваемой системой — оркестрируются в виде R-скрипта.
Собственно задание, анализ, подбор по значению метрики, векторов состояния системы: это пакет GA ()
Пакет, в данном случае, не очень подходит, в смысле того что он ожидает задания векторов (хромосом, если в терминах пакета) в виде пос-тей чисел с дробной частью.
А мой вектор, из значений настроечных параметров: это 14-ть величин — целые числа и строковые значения.
Проблема, конечно легко обходится, назначением строковым величинам — каких то определённых чисел.
Т.о., в итоге, основной кусок R-скрипта выглядит так:
Вызов GA::ga
cat( "", file=v_logfile, sep="n", append=F)
pSize = 10
elitism_value=1
pmutation_coef=0.8
pcrossover_coef=0.1
iterations=50
gam=GA::ga(type="real-valued", fitness=evaluate,
lower=c(32,2, 1,1,1,2,60,1,30,1,0,0, 0,0), upper=c(1024,32, 8,10,10,128,800,4,300,8,10,40, 40,30),
popSize=pSize,
pcrossover = pcrossover_coef,
pmutation = pmutation_coef,
maxiter=iterations,
run=4,
keepBest=T)
cat( "GA-session is done" , file=v_logfile, sep="n", append=T)
gam@solutionТут, с помощью lower dhe upper атрибутов подпрограммы ga задаётся, по сути, область поискового пространства, внутри которого будет выполнятся поиск такого вектора (или векторов) для которых будет получено максимальное значение фитнесс-функции.
ga-подпограмма выполняет поиск максимизируя фитнесс-функцию.
Ну, т.о., получается что, в данном случае, надо чтобы фитнесс-функция, понимая вектор как набор значений для определённых параметров субд, получала метрику, от субд.
Т.е.: сколько, при данной настройке субд и данной нагрузке на субд: субд обрабатывает транзакций в секунду.
Т.е., разворачивая, нужно чтобы внутри фитнесс-функции выполнялась такая многоходовка:
- Обработка входного вектора чисел — преобразование его в значения для параметров субд.
- Попытка создания заданного кол-ва редо-групп, заданного размера. Причём попытка: может быть неудачной.
Уже существовавшие в субд журнальные группы, в каком то кол-ве и какого то размера, для чистоты эксперимента — д.б. удалены. - При успехе предыдущего пункта: задание базе значений конфигурационных параметров (опять же: может быть сбой)
- При успехе предыдущего пункта: остановка субд, запуск субд для того чтобы вновь заданные значения параметров — вступили в силу. (опять же: может быть сбой)
- При успехе предыдущего пункта: выполнить нагрузочный тест. получить метрику от субд.
- Вернуть субд к исходному состоянию, т.е. удалить дополнительные журнальные группы, вернуть в работу исходную конфигурацию субд.
Код фитнесс-функции
evaluate=function(p_par) {
v_module="evaluate"
v_metric=0
opn=NULL
opn$rg_size=round(p_par[1],digit=0)
opn$rg_count=round(p_par[2],digit=0)
opn$log_archive_max_processes=round(p_par[3],digit=0)
opn$commit_logging="BATCH"
if ( round(p_par[4],digit=0) > 5 ) {
opn$commit_logging="IMMEDIATE"
}
opn$commit_logging=paste("'", opn$commit_logging, "'",sep="")
opn$commit_wait="WAIT"
if ( round(p_par[5],digit=0) > 5 ) {
opn$commit_wait="NOWAIT"
}
opn$commit_wait=paste("'", opn$commit_wait, "'",sep="")
opn$log_buffer=paste(round(p_par[6],digit=0),"m",sep="")
opn$log_checkpoint_timeout=round(p_par[7],digit=0)
opn$db_writer_processes=round(p_par[8],digit=0)
opn$undo_retention=round(p_par[9],digit=0)
opn$transactions_per_rollback_segment=round(p_par[10],digit=0)
opn$disk_asynch_io="true"
if ( round(p_par[11],digit=0) > 5 ) {
opn$disk_asynch_io="false"
}
opn$filesystemio_options="none"
if ( round(p_par[12],digit=0) > 10 && round(p_par[12],digit=0) <= 20 ) {
opn$filesystemio_options="setall"
}
if ( round(p_par[12],digit=0) > 20 && round(p_par[12],digit=0) <= 30 ) {
opn$filesystemio_options="directIO"
}
if ( round(p_par[12],digit=0) > 30 ) {
opn$filesystemio_options="asynch"
}
opn$db_block_checking="OFF"
if ( round(p_par[13],digit=0) > 10 && round(p_par[13],digit=0) <= 20 ) {
opn$db_block_checking="LOW"
}
if ( round(p_par[13],digit=0) > 20 && round(p_par[13],digit=0) <= 30 ) {
opn$db_block_checking="MEDIUM"
}
if ( round(p_par[13],digit=0) > 30 ) {
opn$db_block_checking="FULL"
}
opn$db_block_checksum="OFF"
if ( round(p_par[14],digit=0) > 10 && round(p_par[14],digit=0) <= 20 ) {
opn$db_block_checksum="TYPICAL"
}
if ( round(p_par[14],digit=0) > 20 ) {
opn$db_block_checksum="FULL"
}
v_vector=paste(round(p_par[1],digit=0),round(p_par[2],digit=0),round(p_par[3],digit=0),round(p_par[4],digit=0),round(p_par[5],digit=0),round(p_par[6],digit=0),round(p_par[7],digit=0),round(p_par[8],digit=0),round(p_par[9],digit=0),round(p_par[10],digit=0),round(p_par[11],digit=0),round(p_par[12],digit=0),round(p_par[13],digit=0),round(p_par[14],digit=0),sep=";")
cat( paste(v_module," try to evaluate vector: ", v_vector,sep="") , file=v_logfile, sep="n", append=T)
rc=make_additional_rgroups(opn)
if ( rc!=0 ) {
cat( paste(v_module,"make_additional_rgroups failed",sep="") , file=v_logfile, sep="n", append=T)
return (0)
}
v_rc=0
rc=set_db_parameter("log_archive_max_processes", opn$log_archive_max_processes)
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("commit_logging", opn$commit_logging )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("commit_wait", opn$commit_wait )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("log_buffer", opn$log_buffer )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("log_checkpoint_timeout", opn$log_checkpoint_timeout )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("db_writer_processes", opn$db_writer_processes )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("undo_retention", opn$undo_retention )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("transactions_per_rollback_segment", opn$transactions_per_rollback_segment )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("disk_asynch_io", opn$disk_asynch_io )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("filesystemio_options", opn$filesystemio_options )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("db_block_checking", opn$db_block_checking )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("db_block_checksum", opn$db_block_checksum )
if ( rc != 0 ) { v_rc=1 }
if ( rc!=0 ) {
cat( paste(v_module," can not startup db with that vector of settings",sep="") , file=v_logfile, sep="n", append=T)
rc=stop_db("immediate")
rc=create_spfile()
rc=start_db("")
rc=remove_additional_rgroups(opn)
return (0)
}
rc=stop_db("immediate")
rc=start_db("")
if ( rc!=0 ) {
cat( paste(v_module," can not startup db with that vector of settings",sep="") , file=v_logfile, sep="n", append=T)
rc=stop_db("abort")
rc=create_spfile()
rc=start_db("")
rc=remove_additional_rgroups(opn)
return (0)
}
rc=run_test()
v_metric=getmetric()
rc=stop_db("immediate")
rc=create_spfile()
rc=start_db("")
rc=remove_additional_rgroups(opn)
cat( paste("result: ",v_metric," ",v_vector,sep="") , file=v_logfile, sep="n", append=T)
return (v_metric)
}Т.о. вся работа: выполняется в фитнесс-функции.
ga-подпрограмма, выполняет обработку векторов, ну или, правильнее говорить — хромосом.
В которой, нам больше всего важна: селекция хромосом с такими генами, при которых фитнесс-функция выдаёт большие значения.
Это, по сути и есть процесс поиска оптимального набора хромосом вектором, в N-мерном пространстве поиска.
Очень внятное, подробное , с примерами R-кода, работы генетического алгоритма.
Отдельно отмечу два технических момента.
Вспомогательные вызовы, из ф-ции evaluate, например остановка-запуск, задание значения параметра субд, выполняются на основе cran-r ф-ции system2
С помощью которой: вызывается уже какой то баш-скрипт, или команда.
Për shembull:
set_db_parameter
set_db_parameter=function(p1, p2) {
v_module="set_db_parameter"
v_cmd="/home/oracle/testingredotracе/set_db_parameter.sh"
v_args=paste(p1," ",p2,sep="")
x=system2(v_cmd, args=v_args, stdout=T, stderr=T, wait=T)
if ( length(attributes(x)) > 0 ) {
cat(paste(v_module," failed with: ",attributes(x)$status," ",v_cmd," ",v_args,sep=""), file=v_logfile, sep="n", append=T)
return (attributes(x)$status)
}
else {
cat(paste(v_module," ok: ",v_cmd," ",v_args,sep=""), file=v_logfile, sep="n", append=T)
return (0)
}
}Второй момент — строка, evaluate ф-ции, с сохранением конкретного значения метрики и ей соответствующего настроечного вектора, в лог-файл:
cat( paste("result: ",v_metric," ",v_vector,sep="") , file=v_logfile, sep="n", append=T)Это важно, т.к., из этого массива данных, можно будет получить дополнительную информацию о том какой из компонентов настроечного вектора больше, или меньше влияет на значение метрики.
Т.е.: можно будет провести attribute-importamce анализ.
Итак, что может получится.
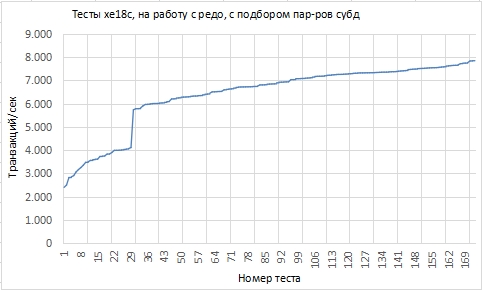
В виде графика, если упорядочить тесты по возрастанию метрики, картина такая:
Некоторые данные, соответствующие крайним значениям метрики:

Тут, на скриншоте с результатами, уточню: значения настроечного вектора — даны в терминах кода фитнес-функции, не в терминах намбер-списка параметров/диапазонов значений параметров, который формулировал выше по тексту.
Ну. Много это, или мало, ~8тыс tps: вопрос отдельный.
В рамках лабораторной работы — не суть важна эта цифра, важна динамика, как это значение меняется.
Динамика тут хорошая.
Очевидно, что, как минимум один фактор, значимо влияющий на значение метрики, ga-алгоритм, перебирая вектора-хромосомы: накрыл.
Судя по достаточно бодрой динамике значений кривой — есть ещё как минимум один фактор, который, хотя и значительно меньше, но влияет.
Вот тут нужен attribute-importance анализ, чтобы понять: какие атрибуты (ну, в данном случае — компоненты настроечного вектора) и как сильно влияют на значение метрики.
А от этой информации: понять — какие факторы затрагивались изменениями значимых атрибутов.
Kryej attribute-importance можно разными способами.
Мне, для этих целей, нравится алгоритм randomForest одноименного R-пакета ()
randomForest, как я понимаю его работу вообще и его подход к оценке важности атрибутов в частности, строит некую модель зависимости переменной-отклика, от атрибутов.
В нашем случае переменная отклика — это метрика получаемая от субд, в нагрузочных тестах: tps;
А атрибуты это — компоненты настроечного вектора.
Так вот randomForest оценивает важность каждого атрибута модели двумя числами: %IncMSE — как наличие/отсутсвие данного атрибута, в модели, изменяет MSE-качество этой модели (Mean Squared Error);
И IncNodePurity — это число, которое отображает насколько качественно, по значениям данного атрибута, можно разделить датасет с наблюдениями, так чтобы в одной части оказались данные, с каким то одним значением объясняемой метрики, а в другой с другим значением метрики.
Ну т.е.: насколько это классифицирующий атрибут (наиболее внятное, рускояз-е пояснение по рандомфорест-у видел ).
Рабоче-крестьянский R-код, для обработки датасета с итогами нагрузочных тестов:
x=NULL
v_data_file=paste('/tmp/data1.dat',sep="")
x=read.table(v_data_file, header = TRUE, sep = ";", dec=",", quote = ""'", stringsAsFactors=FALSE)
colnames(x)=c('metric','rgsize','rgcount','lamp','cmtl','cmtw','lgbffr','lct','dbwrp','undo_retention','tprs','disk_async_io','filesystemio_options','db_block_checking','db_block_checksum')
idxTrain=sample(nrow(x),as.integer(nrow(x)*0.7))
idxNotTrain=which(! 1:nrow(x) %in% idxTrain )
TrainDS=x[idxTrain,]
ValidateDS=x[idxNotTrain,]
library(randomForest)
#mtry=as.integer( sqrt(dim(x)[2]-1) )
rf=randomForest(metric ~ ., data=TrainDS, ntree=40, mtry=3, replace=T, nodesize=2, importance=T, do.trace=10, localImp=F)
ValidateDS$predicted=predict(rf, newdata=ValidateDS[,colnames(ValidateDS)!="metric"], type="response")
sum((ValidateDS$metric-ValidateDS$predicted)^2)
rf$importanceМожно прямо руками поподбирать гиперпараметры алгорима и, ориентируясь на качество модели, выбрать модель поточнее выполняющую предсказания на валидационном датасете.
Можно написать какую то функцию для этой работы (кстати — опять же, на каком то оптимизационном алгоритме).
Можно воспользоваться R-пакетом caret, не суть важно.
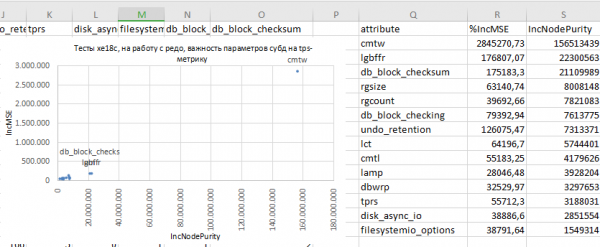
В итоге, в данном случае, получается такой результат, для оценки степени важности атрибутов:
Ну. Т.о., можно приступать к глобальным осмыслениям:
- Получается так что наиболее значимым, в данных условиях тестирования, оказался параметр
commit_wait
Технически, он задаёт режим выполнения io-операции записи редо-данных, из лог-буфера субд, в current-журнальную группу: синхронный, или асинхронный.
Vleranowaitпри котором получается практически вертикальный, кратный прирост значения tps-метрики: это включение асинк-моды io в редо-группы.
Отдельный вопрос — надо, или не надо так делать в продовой бд. Тут я ограничиваюсь только констатацией: это значимый фактор. - Логично что размер лог-буффера субд: оказывается значимым фактором.
Чем меньше размер лог-буфера, тем меньше его буферизующая способность, тем чаще случаются его переполнения и/или не возможность выделить в нём свободную область под порцию новых редо-данных.
А значит: задержки связанные с аллоцированием пространства в лог-буффере и/или сбросом редо-данных из него в редо-группы.
Эти задержки, конечно же должны влиять и влияют на пропускную способность субд по транзакциям. - Parametri
db_block_checksum: ну, тоже, в общем то понятно — обработка транзакций приводит к образованию дарти-блоков в буферном кеше субд.
Которые, при включенной проверке чексумм датаблоков, базе приходится обрабатывать — вычислять эти чексуммы от тела датаблока, сверять их с тем что написано в хидере датаблока: совпадает/не совпадает.
Такая работа, опять же, не может не затягивать обработку данных, ну и соответственно, параметр и механизм который этот параметр задаёт — оказываются значащими.
Поэтому же вендор предлагает, в документации на этот параметр, разные его (параметра) значения и отмечает что — да, импакт будет, но, вот, разные значения, вплоть до "выключено" и разный импакт, можете выбрать.
Ну и глобальный вывод.
Подход, в общем то: оказывается вполне рабочим.
Он вполне себе позволяет, на ранних этапах нагрузочного тестирования некоей сервисной системы, для выбора её (системы) оптимальной конфигурации под нагрузку не особо сильно вникать в особенности настройки системы под нагрузку.
Но не исключает совсем — хотя бы на уровне понимания: "регулировочных ручек" и допустимых диапазонов вращения этих ручек систему знать надо.
Далее подход относительно быстро может найти оптимальную конфигурацию системы.
И можно, по итогам тестирования, получить информацию, про природу взаимосвязи метрики качества работы системы и значений настроечных параметров системы.
Что, конечно, должно способствовать возникновению вот этого самого глубокого понимания системы, её работы, по крайней мере — под данной нагрузкой.
Практически это: размен затрат на вникание в настраиваемую систему, на затраты по подготовке вот такого тестирования работы системы.
Отдельно отмечу: в этом подходе — критично важна степень адекватности тестирования системы к тем условиям её работы которые у неё будут в продовой эксплуатации.
Спасибо за ваше внимание, время.
Burimi: habr.com
