

Sot, përveç kodit monolit, projekti ynë përfshin dhjetëra mikroshërbime. Secila prej tyre kërkon monitorim. Bërja e kësaj në një shkallë të tillë duke përdorur inxhinierët DevOps është problematike. Ne kemi zhvilluar një sistem monitorimi që funksionon si një shërbim për zhvilluesit. Ata mund të shkruajnë në mënyrë të pavarur metrika në sistemin e monitorimit, t'i përdorin ato, të ndërtojnë panele në bazë të tyre dhe t'u bashkëngjisin sinjalizime që do të aktivizohen kur të arrihen vlerat e pragut. Për inxhinierët DevOps, vetëm infrastrukturë dhe dokumentacion.
Ky postim është një transkript i fjalimit tim me tonën në RIT++. Shumë njerëz na kërkuan të bënim versione tekstuale të raporteve nga atje. Nëse keni qenë në konferencë ose keni parë videon, nuk do të gjeni asgjë të re. Dhe të gjithë të tjerët - mirë se vini në mace. Unë do t'ju tregoj se si arritëm në një sistem të tillë, si funksionon dhe si planifikojmë ta përditësojmë atë.

E kaluara: skema dhe plane
Si arritëm te sistemi aktual i monitorimit? Për t'iu përgjigjur kësaj pyetjeje, duhet të shkoni në 2015. Kështu dukej atëherë:
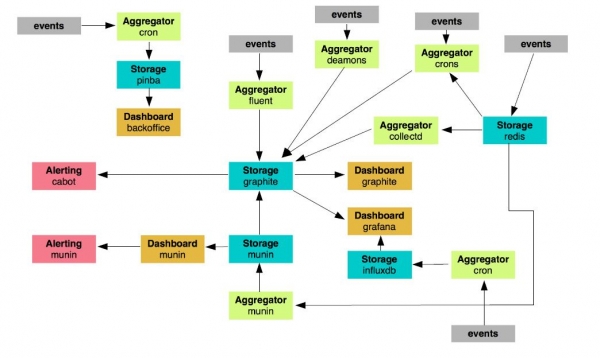
Kishim rreth 24 nyje që ishin përgjegjëse për monitorimin. Ekziston një paketë e tërë kurorash, skriptesh, demonësh të ndryshëm që monitorojnë disi diçka, dërgojnë mesazhe dhe kryejnë funksione. Menduam se sa më tej të shkonim, aq më pak i zbatueshëm do të ishte një sistem i tillë. Nuk ka kuptim ta zhvillojmë atë: është shumë e rëndë.
Ne vendosëm të zgjedhim ata elementë monitorues që do të mbajmë dhe zhvillojmë dhe ata që do të braktisim. Ishin 19. Kanë mbetur vetëm grafitë, agregatët dhe Grafana si pult. Por si do të duket sistemi i ri? Si kjo:
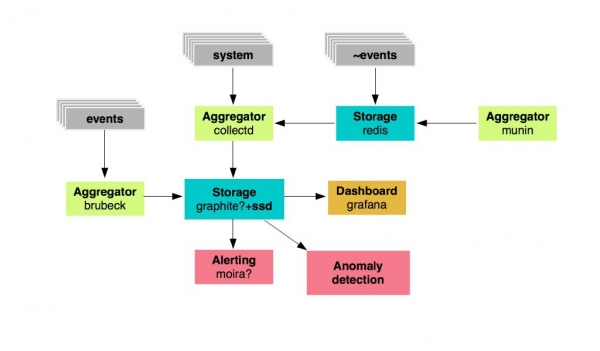
Ne kemi një ruajtje metrike: këto janë grafite, të cilat do të bazohen në disqet e shpejtë SSD, këta janë grumbullues të caktuar për metrikë. Tjetra - Grafana për shfaqjen e tabelave dhe Moira për sinjalizimin. Ne gjithashtu donim të zhvillonim një sistem për kërkimin e anomalive.
Standardi: Monitorimi 2.0
Kështu dukeshin planet në vitin 2015. Por duhej të përgatisnim jo vetëm infrastrukturën dhe vetë shërbimin, por edhe dokumentacionin për të. Ne kemi zhvilluar një standard të korporatës për veten tonë, të cilin e quajmë monitorim 2.0. Cilat ishin kërkesat për sistemin?
- disponueshmëri e vazhdueshme;
- intervali i ruajtjes së metrikës = 10 sekonda;
- ruajtja e strukturuar e metrikave dhe tabelave;
- SLA > 99,99%
- mbledhja e matjeve të ngjarjeve përmes UDP (!).
Na duhej UDP sepse kemi një fluks të madh trafiku dhe ngjarjesh që gjenerojnë metrikë. Nëse i shkruani të gjitha në grafit menjëherë, ruajtja do të shembet. Ne gjithashtu zgjodhëm prefikset e nivelit të parë për të gjitha metrikat.
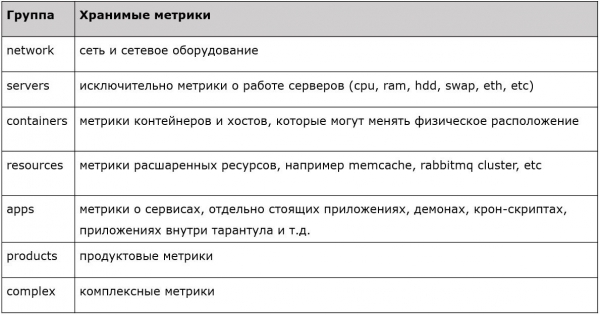
Secila prej parashtesave ka disa veti. Ekzistojnë metrikë për serverët, rrjetet, kontejnerët, burimet, aplikacionet, etj. Është zbatuar filtrim i qartë, i rreptë dhe i shtypur, ku ne pranojmë metrikë të nivelit të parë dhe thjesht hedhim pjesën tjetër. Kështu e kemi planifikuar këtë sistem në vitin 2015. Çfarë ka në të tashmen?
I pranishëm: diagrami i ndërveprimit të komponentëve të monitorimit
Para së gjithash, ne monitorojmë aplikacionet: kodin tonë PHP, aplikacionet dhe mikroshërbimet - me pak fjalë, gjithçka që shkruajnë zhvilluesit tanë. Të gjitha aplikacionet dërgojnë metrikë nëpërmjet UDP në grumbulluesin Brubeck (statsd, rishkruar në C). Doli të ishte më i shpejti në testet sintetike. Dhe dërgon matjet tashmë të grumbulluara në Graphite përmes TCP.
Ai ka një lloj metrikë të quajtur kohëmatës. Kjo është një gjë shumë e përshtatshme. Për shembull, për çdo lidhje përdoruesi me shërbimin, ju dërgoni një metrikë me kohën e përgjigjes në Brubeck. Një milion përgjigje erdhën, por grumbulluesi ktheu vetëm 10 metrikë. Ju keni numrin e njerëzve që kanë ardhur, kohën maksimale, minimale dhe mesatare të përgjigjes, mesataren dhe 4 përqindjet. Më pas të dhënat transferohen në Graphite dhe ne i shohim të gjitha drejtpërdrejt.
Ne kemi gjithashtu një grumbullim për metrikat në harduer, softuer, metrikë të sistemit dhe sistemin tonë të vjetër të monitorimit Munin (ai ka funksionuar për ne deri në 2015). Ne i mbledhim të gjitha këto përmes demonit të C's CollectD (ai ka një grup të tërë shtojcash të ndryshme të integruara në të, mund të anketojë të gjitha burimet e sistemit pritës në të cilin është instaluar, thjesht specifikoni në konfigurim se ku të shkruani të dhënat) dhe shkruani të dhënat në Graphite përmes tij. Ai gjithashtu mbështet shtojcat python dhe skriptet e guaskës, kështu që ju mund të shkruani zgjidhjet tuaja të personalizuara: CollectD do t'i mbledhë këto të dhëna nga një host lokal ose i largët (duke supozuar Curl) dhe do t'i dërgojë në Graphite.
Pastaj ne dërgojmë të gjitha metrikat që kemi mbledhur në Carbon-c-relay. Kjo është zgjidhja Carbon Relay nga Graphite, e modifikuar në C. Ky është një ruter që mbledh të gjitha metrikat që ne dërgojmë nga grumbulluesit tanë dhe i drejton ato në nyje. Gjithashtu në fazën e rrugëzimit, ai kontrollon vlefshmërinë e metrikës. Së pari, ato duhet të korrespondojnë me skemën e prefiksit që tregova më herët dhe, së dyti, ato janë të vlefshme për grafitin. Përndryshe ata do të bien.
Releja e karbonit-c më pas dërgon matjet në grupin e grafitit. Ne përdorim cache-in e karbonit, të rishkruar në Go, si magazinimin kryesor të metrikës. Go-carbon, për shkak të multithreading-ut, është shumë më i mirë se karbon-cache. Ai merr të dhëna dhe i shkruan ato në disqe duke përdorur paketën whisper (standarde, e shkruar në python). Për të lexuar të dhënat nga depozitat tona, ne përdorim Graphite API. Është shumë më i shpejtë se standardi Graphite WEB. Çfarë ndodh më pas me të dhënat?
Shkojnë në Grafanë. Ne përdorim grupimet tona të grafitit si burimin kryesor të të dhënave, plus ne kemi Grafana si një ndërfaqe në internet për shfaqjen e metrikës dhe ndërtimin e paneleve. Për secilin prej shërbimeve të tyre, zhvilluesit krijojnë pultin e tyre. Më pas ata ndërtojnë grafikë bazuar në to, të cilët shfaqin metrikat që shkruajnë nga aplikacionet e tyre. Përveç Grafanës kemi edhe SLAM. Ky është një demon python që llogarit SLA bazuar në të dhënat nga grafiti. Siç thashë tashmë, ne kemi disa dhjetëra mikroshërbime, secila prej të cilave ka kërkesat e veta. Duke përdorur SLAM, ne shkojmë te dokumentacioni dhe e krahasojmë atë me atë që është në Graphite dhe krahasojmë se sa mirë përputhen kërkesat me disponueshmërinë e shërbimeve tona.
Le të shkojmë më tej: alarmues. Organizohet duke përdorur një sistem të fortë - Moira. Është i pavarur sepse ka Grafitin e tij nën kapuç. Zhvilluar nga djemtë nga SKB "Kontur", shkruar në python dhe Go, plotësisht me burim të hapur. Moira merr të njëjtën rrjedhë që shkon në grafit. Nëse për ndonjë arsye ruajtja juaj vdes, sinjalizimi juaj do të vazhdojë të funksionojë.
Ne vendosëm Moira në Kubernetes; ai përdor një grup serverësh Redis si bazën e të dhënave kryesore. Rezultati ishte një sistem tolerant ndaj gabimeve. Ai krahason rrjedhën e metrikës me listën e nxitësve: nëse nuk ka përmendje në të, atëherë e heq metrikën. Pra, është në gjendje të tresë gigabajt metrikë në minutë.
Ne i bashkëngjitëm gjithashtu një LDAP të korporatës, me ndihmën e të cilit çdo përdorues i sistemit të korporatës mund të krijojë njoftime për veten e tij bazuar në shkaktarët ekzistues (ose të krijuar rishtazi). Meqenëse Moira përmban Grafit, ai mbështet të gjitha veçoritë e tij. Pra, së pari merrni rreshtin dhe kopjoni atë në Grafana. Shihni se si shfaqen të dhënat në grafikë. Dhe pastaj ju merrni të njëjtën linjë dhe kopjoni atë në Moira. E varni me kufizime dhe merrni një alarm në dalje. Për të bërë të gjitha këto, nuk keni nevojë për ndonjë njohuri specifike. Moira mund të sinjalizojë me SMS, email, Jira, Slack... Gjithashtu mbështet ekzekutimin e skripteve të personalizuara. Kur i ndodh një shkaktar dhe ajo është e abonuar në një skript të personalizuar ose binar, ajo e ekzekuton atë dhe dërgon JSON në stdin për këtë binar. Prandaj, programi juaj duhet ta analizojë atë. Çfarë do të bëni me këtë JSON varet nga ju. Nëse dëshironi, dërgoni në Telegram, nëse dëshironi, hapni detyrat në Jira, bëni çfarëdo.
Ne gjithashtu përdorim zhvillimin tonë për alarmim - Imagotag. Ne përshtatëm panelin, i cili zakonisht përdoret për etiketat elektronike të çmimeve në dyqane, për t'iu përshtatur nevojave tona. Ne sollëm këmbëza nga Moira në të. Ai tregon se në çfarë gjendje janë dhe kur kanë ndodhur. Disa nga djemtë e zhvillimit braktisën njoftimet në Slack dhe email në favor të këtij paneli.

Epo, duke qenë se ne jemi një kompani progresive, ne monitoruam edhe Kubernetes në këtë sistem. Ne e përfshimë atë në sistem duke përdorur Heapster, të cilin e instaluam në grup, ai mbledh të dhëna dhe i dërgon në Graphite. Si rezultat, diagrami duket si ky:
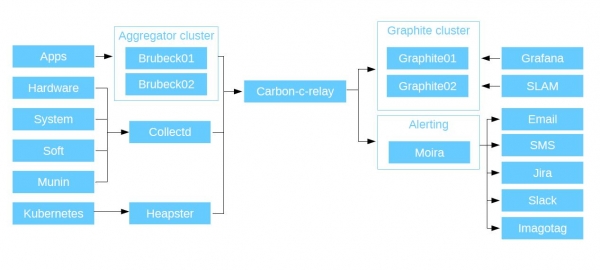
Komponentët e Monitorimit
Këtu është një listë e lidhjeve me komponentët që kemi përdorur për këtë detyrë. Të gjithë ata janë me burim të hapur.
Grafit:
- go-karbon:
- pëshpërit:
- grafit-api:
Rele karboni-c:
Brubeck:
Të mbledhura:
Moira:
Grafana:
Heapster:
Statistikë
Dhe këtu janë disa numra se si funksionon sistemi për ne.
Agregator (brubeck)
Numri i metrikës: ~300/sek
Intervali për dërgimin e metrikës në Graphite: 30 sek
Përdorimi i burimeve të serverit: ~ 6% CPU (po flasim për serverë të plotë); ~ 1 GB RAM; ~ 3 Mbps LAN
Grafit (go-karbon)
Numri i metrikës: ~ 1 / min
Intervali i përditësimit të metrikës: 30 sek
Skema e ruajtjes së metrikës: 30 sekonda 35d, 5min 90d, 10min 365d (ju jep një kuptim të asaj që ndodh me shërbimin për një periudhë të gjatë kohore)
Përdorimi i burimeve të serverit: ~10% CPU; ~ 20 Gb RAM; ~30 Mbps LAN
Lakueshmëri
Ne në Avito e vlerësojmë vërtet fleksibilitetin në shërbimin tonë të monitorimit. Pse në fakt ai doli kështu? Së pari, përbërësit e tij janë të këmbyeshëm: si vetë komponentët ashtu edhe versionet e tyre. Së dyti, mbështetshmëria. Meqenëse i gjithë projekti është me burim të hapur, ju mund ta modifikoni vetë kodin, të bëni ndryshime dhe të zbatoni funksione që nuk janë të disponueshme jashtë kutisë. Përdoren rafte mjaft të zakonshme, kryesisht Go dhe Python, kështu që kjo bëhet mjaft thjesht.
Ja një shembull i një problemi të vërtetë. Një metrikë në Graphite është një skedar. Ajo ka një emër. Emri i skedarit është emri i metrikës. Dhe ka një rrugë për në të. Emrat e skedarëve në Linux Ato janë të kufizuara në 255 karaktere. Dhe ne kemi (si "klientë të brendshëm") djemtë nga departamenti i bazës së të dhënave. Ata na thonë: "Ne duam të monitorojmë pyetjet tona SQL. Dhe ato nuk janë 255 karaktere të gjata, por 8 MB secila. Ne duam t'i shfaqim ato në Grafana, të shohim parametrat për këtë pyetje, dhe akoma më mirë, duam të shohim pyetjet e tilla kryesore. Do të ishte mirë nëse do të shfaqeshin në kohë reale. Dhe do të ishte edhe më interesante t'i fusnim në një alarm."
Shembulli i pyetjes SQL është marrë si shembull nga
Ne vendosim një server Redis dhe përdorim shtojcat tona të mbledhura, të cilat shkojnë në Postgres dhe marrin të gjitha të dhënat prej andej, duke dërguar metrikë në Graphite. Por ne e zëvendësojmë emrin metrikë me hash. Në të njëjtën kohë, ne dërgojmë të njëjtin hash në Redis si çelës dhe të gjithë pyetjen SQL si vlerë. Gjithçka që duhet të bëjmë është të sigurohemi që Grafana të shkojë në Redis dhe të marrë këtë informacion. Ne po hapim API-në Graphite sepse... kjo është ndërfaqja kryesore për ndërveprimin e të gjithë komponentëve të monitorimit me grafitin, dhe ne futim një funksion të ri atje të quajtur aliasByHash() - nga Grafana marrim emrin e metrikës dhe e përdorim atë në një kërkesë për Redis si çelës, në përgjigje ne marrim vlerën e çelësit, që është "kërkesa jonë SQL" " Kështu, ne shfaqëm në Grafana një shfaqje të një pyetjeje SQL, e cila teorikisht ishte e pamundur të shfaqej atje, së bashku me statistikat mbi të (telefonat, rreshtat, total_koha, ...).
Rezultatet e
Disponueshmëria. Shërbimi ynë i monitorimit është i disponueshëm 24/7 nga çdo aplikacion dhe çdo kod. Nëse keni akses në objektet e ruajtjes, mund të shkruani të dhëna në shërbim. Nuk ka rëndësi gjuha, nuk kanë rëndësi vendimet. Ju vetëm duhet të dini se si të hapni një prizë, të vendosni një metrikë atje dhe të mbyllni prizën.
Besueshmëria. Të gjithë komponentët janë tolerantë ndaj defekteve dhe i trajtojnë mirë ngarkesat tona.
Barrierë e ulët për hyrje. Për të përdorur këtë sistem, nuk keni nevojë të mësoni gjuhë programimi dhe pyetje në Grafana. Thjesht hapni aplikacionin tuaj, futni një prizë në të që do të dërgojë metrikë në Graphite, mbylleni atë, hapni Grafana, krijoni panele kontrolli atje dhe shikoni sjelljen e matjeve tuaja, duke marrë njoftime përmes Moira.
Pavarësia. Ju mund t'i bëni të gjitha këto vetë, pa ndihmën e inxhinierëve DevOps. Dhe ky është një avantazh, sepse ju mund të monitoroni projektin tuaj tani, nuk keni pse të kërkoni askënd - ose të filloni punën ose të bëni ndryshime.
Çfarë synojmë ne?
Gjithçka e renditur më poshtë nuk është thjesht mendime abstrakte, por diçka drejt së cilës janë hedhur të paktën hapat e parë.
- Detektor i anomalive. Ne duam të krijojmë një shërbim që do të shkojë në magazinat tona Graphite dhe do të kontrollojë çdo metrikë duke përdorur algoritme të ndryshme. Tashmë ka algoritme që duam t'i shohim, ka të dhëna, ne dimë të punojmë me to.
- Metadatat. Ne kemi shumë shërbime, ato ndryshojnë me kalimin e kohës, ashtu si njerëzit që punojnë me ta. Ruajtja e vazhdueshme e dokumentacionit manualisht nuk është një opsion. Kjo është arsyeja pse ne tani po fusim meta të dhënat në mikroshërbimet tona. Ai tregon se kush e ka zhvilluar atë, gjuhët me të cilat ndërvepron, kërkesat SLA, ku dhe kujt duhet t'i dërgohen njoftimet. Kur vendoset një shërbim, të gjitha të dhënat e entitetit krijohen në mënyrë të pavarur. Si rezultat, ju merrni dy lidhje - njëra për aktivizuesit, tjetra për panelet në Grafana.
- Monitorimi në çdo shtëpi. Ne besojmë se të gjithë zhvilluesit duhet të përdorin një sistem të tillë. Në këtë rast, ju gjithmonë kuptoni se ku është trafiku juaj, çfarë ndodh me të, ku bie, ku janë dobësitë e tij. Nëse, për shembull, diçka vjen dhe rrëzon shërbimin tuaj, atëherë do të mësoni për të jo gjatë një telefonate nga menaxheri, por nga një alarm, dhe mund të hapni menjëherë regjistrat më të fundit dhe të shihni se çfarë ndodhi atje.
- Performancë e lartë. Projekti ynë po rritet vazhdimisht dhe sot përpunon rreth 2 vlera metrike në minutë. Një vit më parë, kjo shifër ishte 000 000. Dhe rritja vazhdon, dhe kjo do të thotë se pas njëfarë kohe Grafiti (pëshpëritja) do të fillojë të ngarkojë shumë nënsistemin e diskut. Siç thashë tashmë, ky sistem monitorimi është mjaft universal për shkak të këmbyeshmërisë së komponentëve. Dikush mirëmban dhe zgjeron vazhdimisht infrastrukturën e tij posaçërisht për Graphite, por ne vendosëm të shkojmë në një rrugë tjetër: përdorim si një depo për metrikat tona. Ky tranzicion është pothuajse i përfunduar dhe shumë shpejt do t'ju tregoj më në detaje se si u bë kjo: çfarë vështirësish kishte dhe si u tejkaluan, si shkoi procesi i migrimit, do të përshkruaj komponentët e zgjedhur si detyrues dhe konfigurimet e tyre.
Faleminderit per vemendjen! Bëni pyetjet tuaja mbi temën, do të përpiqem t'ju përgjigjem këtu ose në postimet e mëposhtme. Ndoshta dikush ka përvojë në ndërtimin e një sistemi të ngjashëm monitorimi ose kalimin në Clickhouse në një situatë të ngjashme - ndajeni atë në komente.
Burimi: www.habr.com
