

Le të shqyrtojmë konceptin e monitorimit të Kubernetes, të njohim mjetin Prometheus dhe të flasim për alarmin.
Tema e monitorimit është e gjërë, dhe nuk mund të përmbahet në një artikull të vetëm. Qëllimi i këtij teksti është të japë një përmbledhje mbi veglat, konceptet dhe qasje.
Materiali i këtij artikulli është një përmbledhje nga . Nëse dëshironi të ndiqni një trajnim të plotë — regjistrohuni në kursin mbi .

Çfarë monitorohet në grupin Kubernetes
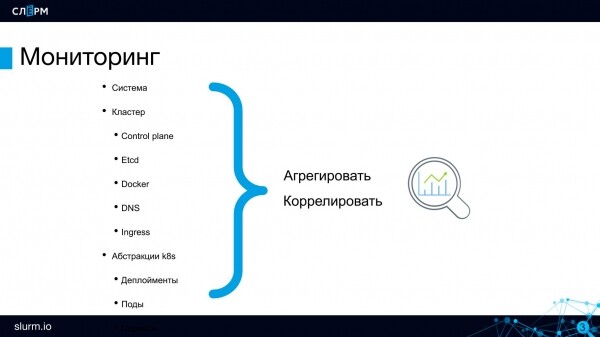
Serverët fizikë. Nëse grupi Kubernetes është vendosur në serverët tuaj, duhet të monitoroni shëndetin e tyre. Këtë detyrë e kryen Zabbix; nëse punoni me të, nuk është nevoja të hiqni dorë, nuk do të ketë konflikte. Zabbix monitoron gjendjen e serverëve tanë.
Të kalojmë në monitorimin në nivelin e grupit.
Komponentët e Planit të Kontrollit: API, Scheduler dhe të tjerë. Të paktën duhet të monitoroni që numri i serverëve API apo etcd të jetë më i madh se 0. Etcd mund të ofrojë shumë metrika: mbi diskët mbi të cilët operon, mbi shëndetin e grupit të tij etcd dhe të tjerë.
Docker ka kaq është njohur prej kohësh dhe të gjithë e dinë për problemet e tij: numri i madh i kontejnerëve shkakton ngadalësime dhe probleme të tjera. Prandaj, edhe Docker-in si sistem duhet ta kontrolloni, të paktën për aksesueshmërinë.
DNS. Nëse DNS në klaster dështon, atëherë do të dështojë edhe i gjithë shërbimi Discovery, dhe thirrjet nga podët te podët do të ndalen të funksionojnë. Në praktikën time nuk kam pasur probleme të tilla, por kjo nuk do të thotë se nuk duhet të ndiqni gjendjen e DNS-it. Mund të monitoroni vonesat në kërkesa dhe disa metrika të tjera në CoreDNS.
Ingress. Duhet të kontrolloni disponueshmërinë e ingreseve (përfshirë edhe Ingress Controller) si pika hyrjeje në projekt.
Tani që kemi shqyrtuar komponentët kryesorë të klasterit, le të zbresim poshtë, në nivelin e abstraksioneve.
Duket se aplikacionet funksionojnë në pods, kështu që duhet t’i kontrollojmë ato, por në të vërtetë nuk është kështu. Pods janë efemerë: sot funksionojnë në një server, nesër në një tjetër; sot ka 10, nesër 2. Prandaj, thjesht nuk monitorohen pods. Në kuadër të arkitekturës mikroshërbimit, është më e rëndësishme të kontrollohet disponueshmëria e aplikacionit në tërësi. Veçanërisht, duhet të kontrollohet disponueshmëria e endpoint-eve të shërbimit: a funksionon ndonjë gjë? Nëse aplikacioni është në dispozicion, atëherë çfarë ndodh pas tij, sa replikë ka tani — këto janë pyetje të rendit të dytë. Nuk ka nevojë të mbahen nën kontroll instancat e veçanta.
Në nivelin e fundit, duhet të kontrollohet funksionimi i aplikacionit vetë, për të marrë metrikat e biznesit: numri i porosive, sjellja e përdoruesve dhe më shumë.
Prometheus
Sistemi më i mirë për monitorimin e klashtërës është . Nuk di asnjë mjet që mund të krahasohet me Prometheus për cilësinë dhe lehtësinë e përdorimit. Ai është i shkëlqyer për infrastrukturën fleksibël, prandaj kur flitet për 'monitorimin e Kubernetes', zakonisht nënkuptohet pikërisht Prometheus.
Ka disa mundësi si të filloni të punoni me Prometheus: me ndihmën e Helm-it mund të instaloni Prometheus normal ose Prometheus Operator.
- Prometheus i zakonshëm. Është në rregull, por nevojitet të konfigurojmë ConfigMap — në thelb, të shkruajmë skedarë konfigurimi tekstorë, siç bënim më parë, para arkitekturës mikroservis.
- Prometheus Operator është pak më kompleks, me logjikë të brendshme më të komplikuar, por është më e lehtë për t'u punuar me të: ka objekte të veçanta, abstraksionet shtohen në klaster, kështu që kontrollimi dhe konfigurimi është shumë më i lehtë.
Për të kuptuar produktin, rekomandoj fillimisht të instaloni Prometheus-in e zakonshëm. Do të duhet të gjitha t'i konfiguroni përmes skedarit, por kjo do t'ju ndihmojë: do të kuptoni se çfarë i përket çfarë dhe si konfigurohet. Në Prometheus Operator, ju menjëherë shqiptoni në një nivel më të lartë të abstraksionit, edhe pse nëse dëshironi të hulumtoni thellë, do të mundeni.
Prometheus është shumë i integruar me Kubernetes: mund të hyjë në API Server dhe të ndërveprojë me të.
Prometheus është i popullarizuar, andaj mbështetet nga shumë aplikacione dhe gjuhë programimi. Mbështetje është e nevojshme, pasi që Prometheus ka formatin e tij të metrikave, dhe për ta dërguar këtë format kërkohet ose një bibliotekë brenda aplikacionit, ose një eksportues i gatshëm. Dhe ka mjaft eksportues të tillë. Për shembull, ekziston PostgreSQL Exporter: ai merr të dhënat nga PostgreSQL dhe i konverton ato në formatin Prometheus, që Prometheus të mund të punojë me to.
Arkitektura e Prometheus
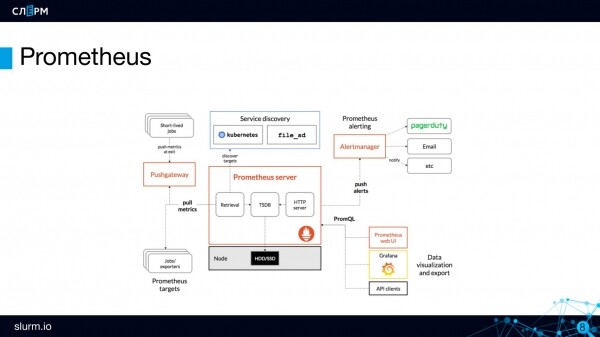
Prometheus Server — kjo është pjesa server, truri i Prometheus. Këtu ruhen dhe përpunohen metrikat.
Metrikat ruhen në një databazë të serive të kohës (TSDB). TSDB nuk është një databazë e veçantë, por një paketë në gjuhën Go, e cila është e integruar në Prometheus. Në terma të thjeshtë, gjithçka ndodhet në një binar.
Mos i ruani të dhënat në TSDB për një kohë të gjatë
Infrastruktura e Prometheus nuk është e përshtatshme për ruajtjen afatgjatë të metrikave. Si parazgjedhje, periudha e ruajtjes është 15 ditë. Ky kufi mund të tejkalohet, por duhet të keni parasysh: sa më shumë të dhëna të ruani në TSDB dhe sa më gjatë ta bëni këtë, aq më shumë resurse do të konsumojë. Ruajtja e të dhënave historike në Prometheus konsiderohet praktikë e keqe.
Nëse keni një trafik të madh, numri i metrikave shkon në qindra mijëra në sekondë, është më mirë të kufizoni ruajtjen e tyre në bazë të hapësirës së diskut ose afatit. Zakonisht në TSDB ruhen "të dhënat e nxehta", metrikat për të cilat ruhen vetëm për disa orë. Për ruajtje më të gjatë përdoren ruajtje të jashtme në ato baza të të dhënave që vërtet janë të përshtatshme për këtë, si InfluxDB, ClickHouse dhe të tjera. Kam parë më shumë komente pozitive për ClickHouse.
Prometheus Server funksionon sipas modelit pull: ai vetë shkon për metrikat në ato endpoint-e që ne i kemi dhënë atij. I thamë: "shko në API Server", dhe ai shkon aty çdo n-ë sasi sekondash dhe merr metrikat.
Për objektet me një jetëgjatësi të shkurtër (job ose cron job), të cilat mund të shfaqen ndërmjet periudhave të scraping, ka një komponent Pushgateway. Metrikat nga objektet afatshkurtra dërgohen aty: job-i ngrihet, ekzekuton veprimin, dërgon metrikat në Pushgateway dhe mbaron. Pas një kohe, Prometheus në ritmin e vet shkon dhe merr këto metrika nga Pushgateway.
Për konfigurimin e njoftimeve në Prometheus ka një komponent të veçantë — Alertmanager. Dhe rregullat e alërtimit — alerting rules. Për shembull, është e nevojshme të krijoni një alërt në rast se API serverët janë 0. Kur ndodhi ngjarja, alërti dërgohet te menaxheri i alerteve për dërgesë të mëtejshme. Menaxheri i alerteve ka konfigurime të mjaftueshme fleksibile të rrugëtimit: një grup aleresh mund të dërgohet në grupin Telegram të administratorëve, një tjetër në grupin e zhvilluesve, një të tretë në grupin e infrastrukturës. Njoftimet mund të vijnë në Slack, Telegram, në email dhe në kanale të tjera.
Dhe në fund do të flas për karakteristikën e killer-it të Prometheus — Zbulimi. Gjatë punës me Prometheus, nuk është e nevojshme të përcaktoni adresat specifike të objekteve për monitorim, është e mjaftueshme të vendosni llojin e tyre. Kështu që nuk është nevoja të shkruani 'ja IP-adresa, ja porta — monitoro', përkundrazi, duhet të përcaktoni se sipas cilave parime të gjenden këto objekte (objektet ). Prometheus vetë, në varësi të objekteve që janë aktive aktualisht, tërheq ato të nevojshme dhe i shton në monitorim.
Ky qasje është shumë e përshtatshme për strukturën e Kubernetes, ku gjithçka është gjithashtu në lëvizje: sot 10 serverë, nesër 3. Për të mos e përcaktuar çdo herë IP-adresën e serverit, shkruani një herë se si të gjendet — dhe Zbulimi do ta bëjë këtë.
Gjuha e Prometheus quhet PromQL. Me këtë gjuhë mund të nxirrni vlerat e metrikeve të caktuara dhe pastaj t'i transformoni ato, duke ndërtuar raportime analitike mbi to.
https://prometheus.io/docs/prometheus/latest/querying/basics/
Kërkesa e thjeshtë
container_memory_usage_bytes
Operacione matematikore
container_memory_usage_bytes / 1024 / 1024
Funksionet e integruara
sum(container_memory_usage_bytes) / 1024 / 1024
Sqarimi i kërkesës
100 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]) * 100)Ndërfaqja në internet e Prometheus
Prometheus ka një ndërfaqe mjaft minimaliste. Ajo është e përshtatshme vetëm për depurim ose demonstrim.
Në fushën e Shprehjes, mund të shkruani kërkesa në gjuhën PromQL.
Në seksionin e Alarmeve gjenden rregullat e alarmeve — rregullat e alarmin dhe ato kanë tre statuset:
- inactive — nëse në këtë moment alarma nuk është aktive, domethënë gjithçka është në rregull, dhe ajo nuk ka kaluar;
- pending — kjo ndodh kur alarma ka aktivizuar, por dërgimi ende nuk ka kaluar. Vonesat caktohen për të kompensuar ndërlikimet e rrjetit: nëse shërbimi i caktuar është rikuperuar brenda një minute, alarmi nuk duhet të ndizet për momentin;
- firing — ky është statusi i tretë, kur alarmi ndizet dhe dërgon mesazhe.
Në menunë Status do të gjeni informacion në lidhje me atë se çfarë përfaqëson Prometheus. Aty ka dhe një kalim në qëllimet (targets) që përmendëm më parë.
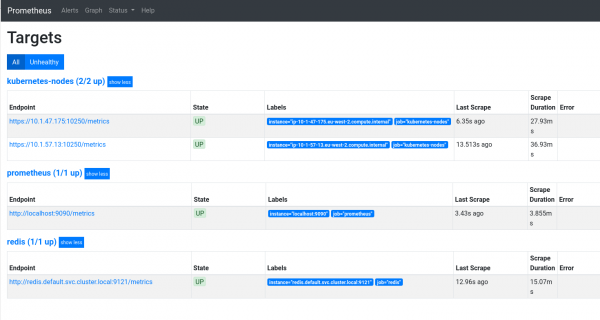
Për një shqyrtim më të detajuar të ndërfaqes së Prometheus, shihni .
Integrimi me Grafana.
Në ndërfaqen web të Prometheus nuk do të gjeni grafikë të bukur dhe të kuptueshëm, nga të cilat mund të nxirrni përfundime për gjendjen e klasterit. Për t'i ndërtuar ato, Prometheus integrohet me Grafana. Përftohen kështu këto dashboard-e.
Të konfiguroni integrimin e Prometheus me Grafana është krejtësisht e thjeshtë, instrukcione do të gjeni në dokumentacion: , dhe unë do ta përfundoj këtu.
Në artikujt e ardhshëm do të vazhdojmë temën e monitorimit: do të flasim për mbledhjen dhe analizën e logjeve me Grafana Loki dhe mjete alternative.
Autori: Marsel Ibraev, administrator i çertifikuar i Kubernetes, inxhinier praktik në kompaninë , folës dhe zhvillues kurseve të Slyrm.
Burimi: habr.com
