


Që nga viti 2008, kompania jonë është përqendruar kryesisht në menaxhimin e infrastrukturës dhe mbështetjen teknike 24/7 për projektet web. Ne kemi mbi 400 klientë, që përfaqësojnë afërsisht 15% të tregut të tregtisë elektronike në Rusi. Si pasojë, ne mbështesim një arkitekturë shumë të larmishme. Nëse diçka nuk funksionon, jemi të detyruar ta rregullojmë brenda 15 minutash. Por për të kuptuar vërtet se ka ndodhur një problem, duhet të monitorojmë projektin dhe t'u përgjigjemi incidenteve. Por si ta bëjmë këtë?
Unë besoj se ka një problem me krijimin e një sistemi të duhur monitorimi. Nëse nuk do të kishte problem, propozimi im do të ishte një deklaratë e thjeshtë: "Ju lutem instaloni Prometheus + Grafana dhe plugin-et 1, 2, 3." Fatkeqësisht, nuk funksionon më kështu. Dhe problemi kryesor është se të gjithë ende besojnë në diçka që ekzistonte në vitin 2008, për sa i përket komponentëve të softuerit.
Lidhur me organizimin e sistemit të monitorimit, do të guxoja të thoja se... projektet me monitorim të duhur nuk ekzistojnë. Dhe situata është aq e keqe saqë nëse diçka shkon keq, ekziston rreziku që të kalojë pa u vënë re - në fund të fundit, të gjithë janë të bindur se "gjithçka monitorohet".
Ndoshta gjithçka monitorohet. Por si?
Të gjithëve na ka ndodhur të hasim një histori si kjo: një anëtar i ekipit DevOps dhe një administrator po punojnë mbi diçka, dhe një ekip zhvilluesish u vjen dhe u thotë: "E kemi publikuar, tani monitorojeni". Çfarë do të thuash me monitorojeni? Si funksionon?
Në rregull. Po e monitorojmë mënyrën e vjetër. Por kjo tashmë po ndryshon, dhe rezulton se ju po monitoronit shërbimin A, i cili është bërë shërbimi B, i cili bashkëvepron me shërbimin C. Por ekipi i zhvillimit ju thotë: "Instaloni programin; ai duhet të monitorojë gjithçka!"
Pra, çfarë ka ndryshuar? - Gjithçka ka ndryshuar!
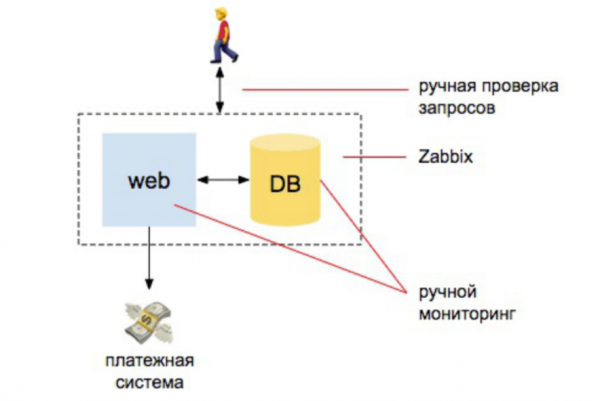
2008. Gjithçka është në rregull.
Janë disa zhvillues, një server, një server baze të dhënash. Këtu fillon gjithçka. Ne kemi disa informacione, instalojmë Zabbix, Nagios dhe Cacti. Pastaj konfigurojmë alarme të qarta për CPU-në, aktivitetin e diskut dhe hapësirën e diskut. Gjithashtu bëjmë disa kontrolle manuale për t'u siguruar që faqja e internetit po përgjigjet dhe që porositë po merren në bazën e të dhënave. Dhe kaq është - jemi pak a shumë të mbrojtur.
Krahasuar me sasinë e punës që bënte administratori në atë kohë për të siguruar monitorimin, 98% e saj ishte e automatizuar: personi që monitoronte duhej të kuptonte se si ta instalonte Zabbix-in, ta konfiguronte dhe të vendoste alarmet. Dhe 2% ishte për kontrolle të jashtme: duke u siguruar që faqja po përgjigjej dhe po kërkonte në bazën e të dhënave, si dhe duke u siguruar që kishin mbërritur porosi të reja.
2010. Ngarkesa e punës është duke u rritur.
Po fillojmë të zgjerojmë uebin dhe të shtojmë një motor kërkimi. Duam të sigurohemi që katalogu i produkteve të përmbajë të gjitha produktet dhe që kërkimi i produkteve të funksionojë. Që baza e të dhënave të funksionojë, që porositë të përpunohen, që faqja të përgjigjet nga jashtë dhe në të dyja drejtimet. serverat dhe përdoruesi nuk përjashtohet nga faqja ndërsa ajo po ribalancohet në një server tjetër, etj. Numri i entiteteve rritet.
Për më tepër, çështja që lidhet me infrastrukturën mbetet më e madhja në mendjen e menaxherit. Ideja që personi përgjegjës për monitorimin është ai që instalon Zabbix dhe e konfiguron atë ende ekziston.
Por në të njëjtën kohë, po punohet për të kryer kontrolle të jashtme, për të krijuar një sërë skriptesh pyetjesh të indeksuesit të kërkimit, një sërë skriptesh për të kontrolluar nëse kërkimi ndryshon gjatë procesit të indeksimit, një sërë skriptesh që kontrollojnë nëse mallrat transferohen në shërbimin e dorëzimit, e kështu me radhë.
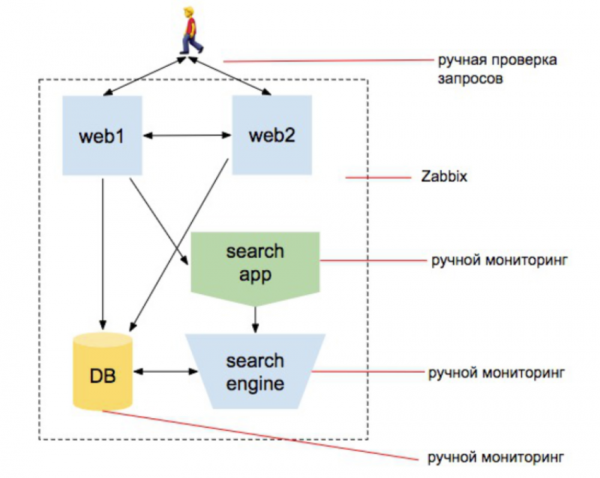
Shënim: E kam shkruar "grup skriptesh" tri herë. Kjo do të thotë që personi përgjegjës për monitorimin nuk është më ai që thjesht instalon Zabbix. Ata janë ata që fillojnë kodimin. Por asgjë nuk ka ndryshuar ende në mendjet e ekipit.
Por bota po ndryshon, duke u bërë gjithnjë e më komplekse. Shtohet një shtresë virtualizimi dhe disa sisteme të reja. Ato fillojnë të bashkëveprojnë me njëra-tjetrën. Kush tha "mban erë mikroshërbimesh?" Por çdo shërbim, i marrë veçmas, ende duket si një faqe interneti. Ne mund t'i qasemi asaj dhe të kuptojmë se ajo ofron informacionin dhe funksionet e nevojshme në mënyrë të pavarur. Dhe nëse jeni administrator, duke punuar vazhdimisht në një projekt që është zhvilluar për 5-7-10 vjet, ju grumbulloni këtë njohuri: shfaqet një nivel i ri - ju e njihni atë, shfaqet një nivel tjetër - ju e njihni atë...
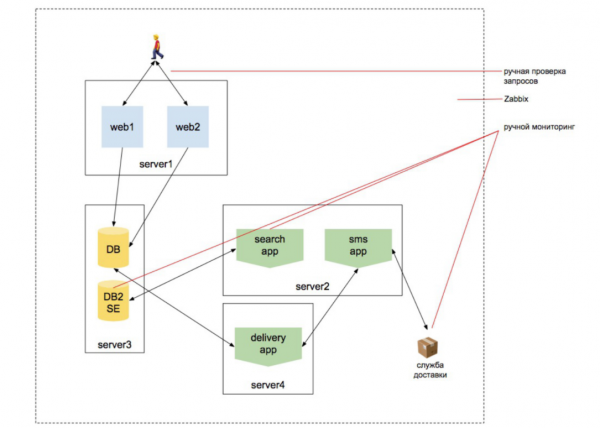
Por është e rrallë që dikush ta ndjekë një projekt për 10 vjet.
Monitorimi i CV-së së një burri
Le të themi se ju jeni bashkuar me një startup të ri që punësoi menjëherë 20 zhvillues, shkroi 15 mikroshërbime dhe ju jeni administratori, dhe ata ju thonë, "Ndërtoni CI/CD. Ju lutem." Ju keni ndërtuar CI/CD, dhe papritmas dëgjoni, "Po kemi probleme të punojmë me prodhimin në një 'kub' pa e kuptuar se si do të funksionojë aplikacioni në të. Ndërtoni për ne një sandbox në të njëjtin 'kub'."
Ti krijon një sandbox në këtë kub. Ata menjëherë të thonë: "Ne duam një bazë të dhënash skene që përditësohet çdo ditë nga prodhimi, në mënyrë që të shohim se çfarë funksionon në bazën e të dhënave, por pa e prishur bazën e të dhënave të prodhimit."
Ju jetoni në të gjitha këto. Dy javë para publikimit, ju thuhet: "Tani më duhet vetëm të monitoroj të gjitha këto..." Domethënë, të monitoroj infrastrukturën e klasterit, të monitoroj arkitekturën e mikroshërbimeve, të monitoroj punën me shërbimet e jashtme...
Dhe kolegët e mi nxjerrin këtë skemë të njohur nga kokat e tyre dhe thonë: "Gjithçka është e qartë këtu! Instaloni një program që do të monitorojë të gjitha këto." Po, po: Prometheus + Grafana + plugins.
Dhe ata shtojnë: “Keni dy javë kohë, sigurohuni që gjithçka është e sigurt.”
Në shumë projekte që shohim, monitorimi i caktohet një personi të vetëm. Imagjinoni sikur duam të punësojmë dikë për dy javë për të trajtuar monitorimin dhe po hartojmë një CV. Çfarë aftësish duhet të ketë ky person, duke pasur parasysh gjithçka që kemi diskutuar deri më tani?
- Ai duhet të kuptojë monitorimin dhe specifikat e funksionimit të infrastrukturës së hekurit.
- Ai duhet të kuptojë specifikat e monitorimit të Kubernetes (dhe të gjithë duan të jenë në "kub" sepse mund të abstraktojnë veten nga gjithçka, të fshihen, sepse administratori do të merret me pjesën tjetër) - veten, infrastrukturën e tij dhe të kuptojë se si të monitorojë aplikacionet brenda.
- Ata duhet të kuptojnë që shërbimet komunikojnë me njëra-tjetrën në mënyra specifike dhe të jenë të njohur me specifikat e mënyrës se si ato bashkëveprojnë. Është plotësisht e mundur të shihet një projekt ku disa shërbime komunikojnë në mënyrë sinkrone, sepse nuk ka mënyrë tjetër. Për shembull, backend përdor REST, gRPC për të hyrë në shërbimin e katalogut, merr një listë produktesh dhe i kthen ato. Nuk ka pritje këtu. Dhe me shërbime të tjera, funksionon në mënyrë asinkrone. Dërgimi i një porosie në një shërbim shpërndarjeje, dërgimi i një email-i e kështu me radhë.
Ndoshta po ndiheni pak të mbingarkuar nga e gjithë kjo? Dhe administratori që supozohet ta monitorojë është edhe më shumë i mbingarkuar. - Ai duhet të jetë në gjendje të planifikojë dhe planifikojë saktë - sepse puna po bëhet gjithnjë e më shumë.
- Prandaj, ata duhet të krijojnë një strategji nga shërbimi që kanë krijuar për të kuptuar se si ta monitorojnë atë në mënyrë specifike. Ata kanë nevojë për një kuptim të arkitekturës së projektit dhe zhvillimit të tij, si dhe një kuptim të teknologjive të përdorura në zhvillim.
Le të kujtojmë një rast krejtësisht normal: disa shërbime janë shkruar në PHP, disa në Go dhe disa në JS. Ato në një farë mënyre bashkëveprojnë me njëra-tjetrën. Këtu vjen termi "mikroshërbim": ka kaq shumë sisteme të ndara sa zhvilluesit nuk mund ta kuptojnë projektin në tërësi. Një pjesë e ekipit shkruan shërbime në JS që funksionojnë në mënyrë të pavarur dhe nuk janë të vetëdijshme se si funksionon pjesa tjetër e sistemit. Një pjesë tjetër shkruan shërbime në Python dhe nuk ndërhyn në mënyrën se si funksionojnë shërbimet e tjera; ato janë të izoluara në domenin e tyre. Një pjesë e tretë shkruan shërbime në PHP ose diçka tjetër.
Të 20 këta persona janë të ndarë në 15 shërbime, dhe ka vetëm një administrator që duhet ta kuptojë të gjithën. Prit! Ne thjesht e ndamë sistemin në 15 mikroshërbime sepse 20 persona nuk mund ta kuptojnë të gjithë sistemin.
Por duhet të monitorohet disi...
Cili është thelbi? Në fund të fundit, ekziston një person që mund të kuptojë gjithçka që një ekip i tërë zhvilluesish nuk mundet, dhe gjithashtu duhet të dijë dhe të jetë i aftë në gjithçka që kemi përmendur më sipër - infrastrukturën e harduerit, infrastrukturën e Kubernetes, etj.
Çfarë mund të them... Hjuston, kemi një problem.
Monitorimi i një projekti modern softuerik është një projekt softuerik në vetvete.
Besimi i gabuar se monitorimi është softuer na bën të besojmë në mrekulli. Por mrekullitë, për fat të keq, nuk ndodhin. Nuk mund të instaloni Zabbix dhe të prisni që gjithçka të funksionojë. Nuk ka kuptim të instaloni Grafana dhe të shpresoni që gjithçka do të jetë mirë. Pjesa më e madhe e kohës do të shpenzohet duke organizuar kontrolle mbi funksionimin e shërbimeve dhe ndërveprimet e tyre, duke kontrolluar se si funksionojnë sistemet e jashtme. Në fakt, 90% e kohës nuk do të shpenzohet për shkrimin e skripteve, por për zhvillimin e softuerëve. Dhe kjo duhet të bëhet nga një ekip që e kupton projektin.
Nëse një person caktohet për të monitoruar këtë situatë, do të ndodhë katastrofë. Dhe kjo është ajo që po ndodh kudo.
Për shembull, ka disa shërbime që komunikojnë me njëra-tjetrën nëpërmjet Kafkës. Mbërrin një porosi dhe ne i dërgojmë Kafkës një mesazh në lidhje me të. Ekziston një shërbim që dëgjon për informacionin e porosisë dhe dërgon mallrat. Një shërbim tjetër dëgjon për informacionin e porosisë dhe i dërgon një email përdoruesit. Dhe pastaj shfaqen një mori shërbimesh të tjera dhe ne fillojmë të ngatërrohemi.
Dhe nëse ua dorëzoni këtë administratorit dhe zhvilluesve pak para publikimit, ata do të duhet ta kuptojnë të gjithë protokollin. Kjo do të thotë që një projekt i kësaj shkalle kërkon një kohë të konsiderueshme dhe kjo duhet të merret parasysh në zhvillimin e sistemit.
Por shumë shpesh, veçanërisht në startup-et me nxitim, shohim monitorimin të shtyhet për më vonë. "Tani do të krijojmë një Proof of Concept, do ta lançojmë me të, do ta lëmë të rrëzohet - jemi të gatshëm ta sakrifikojmë. Dhe pastaj do ta monitorojmë të gjithën." Kur (ose nëse) një projekt fillon të fitojë para, biznesi dëshiron të ndërtojë edhe më shumë veçori - sepse po funksionon, kështu që ata duhet të vazhdojnë t'i shtojnë ato! Por ju jeni në një pikë ku së pari duhet të monitoroni gjithçka që ka ekzistuar më parë, gjë që zë dukshëm më shumë se 1% të kohës. Dhe, meqë ra fjala, monitorimi kërkon zhvillues, dhe është më e lehtë t'i vësh ata të punojnë në veçori të reja. Si rezultat, shkruhen veçori të reja, gjithçka ndërtohet dhe ju ngecni në një bllokim të pafund.
Pra, si e monitoroni një projekt nga e para dhe çfarë duhet të bëni nëse ju është caktuar një projekt që ka nevojë për monitorim dhe nuk dini nga t'ia filloni?
Së pari, duhet të planifikoni.
Një shmangie nga tema: njerëzit shpesh fillojnë me monitorimin e infrastrukturës. Për shembull, kemi Kubernetes. Do të fillojmë duke instaluar Prometheus dhe Grafana, dhe pastaj do të instalojmë plugin-e për monitorimin e "kubit". Jo vetëm zhvilluesit, por edhe administratorët kanë këtë zakon të pafat: "Ne do ta instalojmë këtë plugin, dhe plugin-i ndoshta e di si ta bëjë." Njerëzit kanë tendencë të fillojnë me veprime të thjeshta dhe të drejtpërdrejta, në vend të atyre më të rëndësishmeve. Dhe monitorimi i infrastrukturës është i thjeshtë.
Së pari, vendosni se çfarë dhe si doni të monitoroni, dhe pastaj zgjidhni një mjet, sepse njerëz të tjerë nuk mund ta bëjnë këtë për ju. Dhe a duhet ta bëjnë? Njerëz të tjerë po mendonin vetë, për një sistem universal - ose nuk po mendonin fare kur shkruan këtë plugin. Dhe vetëm pse ky plugin ka 5000 përdorues nuk do të thotë se është i dobishëm. Ju mund të bëheni i 5001-ti thjesht sepse 5 njerëz e kanë përdorur tashmë.
Nëse keni filluar të monitoroni infrastrukturën tuaj dhe sistemi i aplikacionit ndalon së përgjigjuri, të gjithë përdoruesit do të humbasin lidhjen me aplikacionin celular. Do të shfaqet një gabim. Dikush do të vijë tek ju dhe do t'ju thotë: "Aplikacioni nuk po funksionon, çfarë po bëni?" — "Po monitorojmë." — "Si mund të monitoroni nëse nuk mund ta shihni që aplikacioni nuk po funksionon?!"
- Unë besoj se monitorimi duhet të fillojë me pikën e hyrjes së përdoruesit. Nëse përdoruesi nuk e sheh që aplikacioni po funksionon, kjo është e gjitha, është një dështim. Dhe sistemi i monitorimit duhet të paralajmërojë për këtë para së gjithash.
- Dhe vetëm atëherë mund ta monitorojmë infrastrukturën. Ose ta bëjmë paralelisht. Është më e lehtë me infrastrukturën - atëherë më në fund mund të instalojmë Zabbix.
- Dhe tani duhet të shkoni në rrënjët e aplikacionit për të kuptuar se ku çfarë nuk funksionon.
Pika ime kryesore është se monitorimi duhet të zhvillohet paralelisht me procesin e zhvillimit. Nëse e shpërqendroni ekipin e monitorimit nga detyra të tjera (krijimi i CI/CD, sandbox-et, riorganizimi i infrastrukturës), monitorimi do të fillojë të vonojë dhe mund të mos e arrini kurrë zhvillimin (ose do t'ju duhet ta ndaloni atë herët a vonë).
Gjithçka është në nivele
Kështu e shoh unë organizimin e sistemit të monitorimit.
1) Niveli i aplikimit:
- monitorimi i logjikës së biznesit të aplikacionit;
- monitorimin e metrikave shëndetësore të shërbimeve;
- monitorimi i integrimit.
2) Niveli i infrastrukturës:
- monitorimi i nivelit të orkestrimit;
- monitorimi i softuerit të sistemit;
- monitorimi i nivelit të harduerit.
3) Përsëri niveli i aplikimit - por këtë herë si një produkt inxhinierik:
- mbledhjen dhe monitorimin e regjistrave të aplikacioneve;
- APM;
- duke gjurmuar.
4) Alarm:
- organizimi i një sistemi paralajmërues;
- organizimi i një sistemi detyrash;
- organizimi i një "baze njohurish" dhe rrjedhës së punës për trajtimin e incidenteve.
Është e rëndësishmeNe fillojmë të njoftojmë menjëherë, jo më vonë! Nuk ka nevojë të nisim monitorimin dhe pastaj të kuptojmë se kush do të marrë njoftime "disa kohë më vonë". Në fund të fundit, qëllimi i monitorimit është të kuptojmë se ku diçka në sistem po keqfunksionon dhe të njoftojmë njerëzit e duhur. Nëse e lini për në fund, njerëzit e duhur do të zbulojnë se diçka nuk shkon vetëm kur të dëgjojnë "asgjë nuk po funksionon këtu".
Shtresa e aplikacionit - monitorimi i logjikës së biznesit
Ajo për të cilën po flasim këtu është verifikimi i vetë faktit që aplikacioni funksionon për përdoruesin.
Kjo shtresë duhet të zbatohet gjatë fazës së zhvillimit. Për shembull, kemi një Prometheus hipotetik: ai qaset në serverin që trajton kontrollet, tërheq një pikë fundore dhe pika fundore shkon dhe kontrollon API-në.
Kur njerëzit kërkojnë shpesh të monitorojnë faqen kryesore për t'u siguruar që faqja po funksionon, programuesit u japin atyre një emërtim që mund ta përdorin sa herë që u nevojitet për t'u siguruar që API po funksionon. Ndërkohë, programuesit thjesht shkruajnë /api/test/helloworld.
E vetmja mënyrë për t'u siguruar që gjithçka funksionon? - Jo!
- Krijimi i kontrolleve të tilla është në thelb punë e zhvilluesve. Testet njësi duhet të shkruhen nga programuesit që shkruajnë kodin. Sepse nëse e hidhni te administratori, "Shoku, ja një listë e protokolleve API për të gjitha 25 funksionet, ju lutem monitorojini të gjitha!" - asgjë nuk do të ndodhë.
- Nëse shkruani "përshëndetje botë", askush nuk do ta dijë kurrë që API-ja supozohet të funksionojë dhe funksionon në të vërtetë. Çdo ndryshim në API duhet të sjellë ndryshime në kontrolle.
- Nëse jeni tashmë në telashe, ndaloni veçoritë dhe caktoni zhvilluesit të shkruajnë këto kontrolle, ose pranoni humbjet dhe pranoni që asgjë nuk po kontrollohet dhe do të rrëzohet.
Këshilla teknike:
- Sigurohuni që të konfiguroni një server të jashtëm për auditime - duhet të siguroheni që projekti juaj është i arritshëm për botën e jashtme.
- Organizoni testimin në të gjithë protokollin API, jo vetëm në pikat fundore individuale.
- Krijo një pikë fundore prometheus me rezultatet e kontrollit.
Niveli i aplikimit - monitorimi i metrikave shëndetësore
Tani po flasim për metrika të jashtme shëndetësore të shërbimeve.
Ne vendosëm të monitorojmë të gjitha "dorezat" e aplikacionit duke përdorur kontrolle të jashtme të thirrura nga një sistem monitorimi i jashtëm. Por këto janë vetëm "dorezat" që përdoruesi "sheh". Ne duam të jemi të sigurt se vetë shërbimet tona po funksionojnë. Kjo është një histori më e mirë: K8s ka kontrolle shëndetësore në mënyrë që të paktën vetë "kubi" të mund të verifikojë që shërbimi është duke funksionuar. Por gjysma e kontrolleve që kam parë janë e njëjta shtypje e vjetër "përshëndetje botë". Pra, ai ekzekutohet një herë pas vendosjes dhe sistemi përgjigjet se gjithçka është në rregull - dhe kaq. Por një shërbim, nëse ekspozon API-në e tij brenda vendit, ka një numër të madh pikash hyrjeje API, të cilat gjithashtu duhet të monitorohen sepse duam të dimë se po funksionon. Dhe ne e monitorojmë atë brenda vendit.
Mënyra e saktë për ta zbatuar këtë teknikisht është si më poshtë: çdo shërbim ekspozon një pikë fundore që tregon gjendjen e tij aktuale, dhe në grafikët e Grafana (ose çdo aplikacioni tjetër), ne shohim statusin e të gjitha shërbimeve.
- Çdo ndryshim në API duhet të çojë në një ndryshim në kontrolle.
- Krijo menjëherë një shërbim të ri me metrika shëndetësore.
- Një administrator mund t'u afrohet zhvilluesve dhe t'u kërkojë atyre "të shtojnë disa veçori për mua në mënyrë që të kuptoj gjithçka dhe të shtojnë informacion rreth tyre në sistemin tim të monitorimit". Por zhvilluesit zakonisht përgjigjen, "Nuk do të shtojmë asgjë dy javë para publikimit".
Le t’i dinë menaxherët e zhvillimit se humbje të tilla do të ndodhin, si dhe le t’i dinë edhe eprorët e menaxherëve të zhvillimit. Sepse kur gjithçka të shkojë keq, dikush do të telefonojë përsëri dhe do të kërkojë monitorimin e “shërbimit që dështon vazhdimisht”. (c) - Nga rruga, ju lutem caktoni zhvilluesit të shkruajnë shtojca për Grafana—kjo do të jetë një ndihmë e madhe për administratorët.
Shtresa e Aplikacionit - Monitorimi i Integrimit
Monitorimi i integrimit përqendrohet në monitorimin e komunikimit midis sistemeve kritike për biznesin.
Për shembull, ekzistojnë 15 shërbime që komunikojnë me njëra-tjetrën. Ato nuk janë më faqe interneti të ndara. Kjo do të thotë që nuk mund të hapim një shërbim më vete, të marrim /helloworld dhe të dimë se po funksionon. Sepse shërbimi në internet i përpunimit të porosive duhet të dërgojë informacionin e porosisë në autobus - nga atje, shërbimi i menaxhimit të magazinës duhet ta marrë këtë mesazh dhe ta përpunojë atë më tej. Dhe shërbimi i shpërndarjes së email-eve duhet ta përpunojë atë më tej e kështu me radhë.
Prandaj, nuk mund ta kuptojmë nëse gjithçka funksionon duke kontrolluar çdo shërbim individualisht. Sepse kemi një lloj autobusi përmes të cilit gjithçka komunikon dhe bashkëvepron.
Prandaj, kjo fazë duhet të përkufizohet si testimi i ndërveprimeve të shërbimeve me shërbime të tjera. Nuk mund të monitoroni komunikimin duke monitoruar një ndërmjetës mesazhesh. Nëse ka një shërbim që prodhon të dhëna dhe një shërbim që i merr ato, monitorimi i ndërmjetësit do të shohë vetëm të dhëna që fluturojnë para dhe mbrapa. Edhe nëse do të arrinim disi të monitoronim ndërveprimet e brendshme të këtyre të dhënave - që një prodhues po poston të dhëna, dikush po i lexon ato dhe kjo rrjedhë vazhdon të rrjedhë në Kafka - kjo prapë nuk do të na tregojë nëse një shërbim dërgoi një mesazh në një version, ndërsa një shërbim tjetër nuk e priste atë version dhe e anashkaloi atë. Ne nuk do ta dimë për këtë, pasi shërbimet do të na tregojnë se gjithçka po funksionon.
Si e rekomandoj ta bëj:
- Për komunikim sinkron, një pikë fundore bën kërkesa te shërbimet përkatëse. Kjo do të thotë, ne e marrim këtë pikë fundore, aktivizojmë një skript brenda shërbimit, i cili shkon te të gjitha pikat fundore dhe thotë: "Unë mund ta aktivizoj këtë, dhe unë mund ta aktivizoj atë, unë mund ta aktivizoj atë..."
- Për komunikim asinkron: mesazhe hyrëse - pika fundore kontrollon autobusin për mesazhe testimi dhe kthen statusin e përpunimit.
- Për komunikim asinkron: mesazhe dalëse - pika fundore dërgon mesazhe testimi në autobus.
Ja se si funksionon zakonisht: kemi një shërbim që shtyn të dhëna në autobus. Ne i afrohemi këtij shërbimi dhe i kërkojmë të raportojë mbi gjendjen e integrimit të tij. Dhe nëse shërbimi duhet të prodhojë një mesazh diku më tej (WebApp), atëherë ai prodhon këtë mesazh testimi. Dhe nëse e aktivizojmë shërbimin në anën e Përpunimit të Porosive, ai së pari poston atë që mund të postojë në mënyrë të pavarur, dhe nëse ka ndonjë gjë të varur, atëherë lexon një grup mesazhesh testimi nga autobusi, kupton se mund t'i përpunojë ato, të raportojë për këtë dhe, nëse është e nevojshme, t'i postojë ato më tej, dhe kjo është ajo që thotë: gjithçka është në rregull, unë jam gjallë.
Shpesh dëgjojmë pyetjen: "Si mund ta testojmë këtë në të dhënat e prodhimit?" Për shembull, merrni parasysh shërbimin e porosive. Një porosi dërgon mesazhe në depo, ku produktet shlyhen. Ne nuk mund ta testojmë këtë në të dhënat e prodhimit, sepse "produktet e mia do të shlyhen!" Zgjidhja: planifikoni të gjithë këtë test që nga fillimi. Keni teste njësie që kryejnë teste simuluese. Pra, bëjeni këtë në një nivel më të thellë, ku keni një kanal komunikimi që nuk do ta prishë biznesin tuaj.
Niveli i infrastrukturës
Monitorimi i infrastrukturës është diçka që prej kohësh konsiderohet si monitorim në vetvete.
- Monitorimi i infrastrukturës mund dhe duhet të kryhet si një proces i veçantë.
- Mos filloni duke monitoruar infrastrukturën në një projekt aktiv, edhe nëse dëshironi vërtet. Ky është një kurth i zakonshëm për të gjithë profesionistët e DevOps. "Së pari, do të monitoroj grumbullin, pastaj do të monitoroj infrastrukturën" - që do të thotë se ata do të monitorojnë atë që është poshtë, por nuk do të merren me aplikacionin. Sepse aplikacioni është një koncept i huaj për profesionistët e DevOps. Atyre u është dhënë, dhe ata nuk e kuptojnë se si funksionon. Megjithatë, ata e kuptojnë infrastrukturën dhe fillojnë me këtë. Por jo - gjithmonë duhet të monitoroni aplikacionin së pari.
- Mos e teproni me njoftimet. Duke pasur parasysh kompleksitetin e sistemeve moderne, alarmet vijnë vazhdimisht dhe ju duhet të përballeni me këtë breshëri alarmesh. Dhe një person në gatishmëri, pasi të shohë qindra alarme, do të vendosë: "Nuk dua të mendoj për këtë". Alarmet duhet t'ju njoftojnë vetëm për çështje kritike.
Shtresa e aplikacionit si një njësi biznesi
Pikat kryesore:
- ELK. Është standardi i industrisë. Nëse për ndonjë arsye nuk po i grumbulloni regjistrat, filloni ta bëni menjëherë.
- APM. APM-të e jashtme janë një mënyrë për të çaktivizuar shpejt monitorimin e aplikacioneve (NewRelic, BlackFire, Datadog). Mund ta instaloni përkohësisht këtë për të marrë të paktën një pasqyrë të asaj që po ndodh.
- Gjurmimi. Me dhjetëra mikroshërbime, duhet të gjurmoni gjithçka sepse kërkesat nuk ekzistojnë më vetë. Është shumë e vështirë t'i shtosh më vonë, kështu që është më mirë të planifikoni gjurmimin në zhvillim që nga fillimi - është puna dhe mjeti i zhvilluesit. Nëse nuk e keni zbatuar ende, bëjeni! Shih Jaeger/Zipkin
Alarmimi
- Organizimi i një sistemi alarmi: Kur monitorohen shumë gjëra, nevojitet një sistem i unifikuar alarmi. Grafana është një mundësi e mirë. Në Perëndim, të gjithë përdorin PagerDuty. Alarmet duhet të jenë të qarta (për shembull, nga kanë ardhur...). Dhe është gjithashtu një ide e mirë të siguroheni që alarmet të dorëzohen në të vërtetë.
- Organizoni një listë detyrash: alarmet nuk duhet të merren në mënyrë universale (ose të gjithë do të përgjigjen në masë, ose askush nuk do të përgjigjet). Zhvilluesit gjithashtu duhet të jenë në gatishmëri: sigurohuni që të përcaktoni fushat e përgjegjësisë, të krijoni udhëzime të qarta dhe të specifikoni se kë të telefononi të hënën dhe të mërkurën, dhe kë të telefononi të martën dhe të premten (përndryshe, ata nuk do të telefonojnë askënd edhe në rast të një emergjence të madhe - do të kenë frikë t'i zgjojnë ose t'i shqetësojnë: njerëzve në përgjithësi nuk u pëlqen të telefonojnë dhe të zgjojnë të tjerët, veçanërisht natën). Shpjegoni se kërkimi i ndihmës nuk është shenjë paaftësie ("Unë kërkoj ndihmë, kjo do të thotë se jam një punëtor i keq"); inkurajoni kërkesat për ndihmë.
- Organizoni një bazë njohurish dhe një rrjedhë pune për trajtimin e incidenteve: duhet të planifikohet një vlerësim pas incidentit për çdo incident serioz dhe veprimet për zgjidhjen e incidentit duhet të regjistrohen si një masë e përkohshme. Dhe vendosni një praktikë që alarmet e përsëritura janë mëkat; ato duhet të rregullohen në kod ose në punën e infrastrukturës.
Rafte teknologjike
Le të imagjinojmë që grumbulli ynë është si më poshtë:
- mbledhja e të dhënave — Prometeu + Grafana;
- analiza logaritmike - ELK;
- për APM ose Gjurmim - Jaeger (Zipkin).

Zgjedhja e opsioneve nuk është kritike. Nëse fillimisht e keni kuptuar se si ta monitoroni sistemin dhe keni hartuar një plan, atëherë mund të filloni të zgjidhni mjetet që plotësojnë nevojat tuaja. Pyetja është se çfarë zgjidhni të monitoroni së pari. Sepse mjeti që zgjodhët fillimisht mund të mos jetë aspak i përshtatshëm për nevojat tuaja.
Disa probleme teknike që kam parë kudo kohët e fundit:
Prometeu po futet në Kubernetes - kush e shpiku këtë ide?! Nëse klasteri juaj nuk funksionon, çfarë bëni? Nëse keni një klaster kompleks, duhet të keni një lloj sistemi monitorimi që funksionon brenda klasterit dhe një tjetër jashtë tij që mbledh të dhëna nga brenda klasterit.
Brenda grumbullit ne mbledhim trungje dhe gjithçka tjetër. Por sistemi i monitorimit duhet të jetë i jashtëm. Shpesh, një klaster me Promtheus të instaluar brenda ka edhe sisteme që kryejnë kontrolle të performancës së faqes së jashtme. Po sikur lidhjet tuaja me botën e jashtme të jenë të ndërprera dhe aplikacioni nuk po funksionon? Pra, gjithçka duket në rregull brenda, por kjo nuk i bën gjërat më të lehta për përdoruesit tuaj.
Gjetjet
- Zhvillimi i monitorimit nuk ka të bëjë me instalimin e programeve ndihmëse, por me zhvillimin e një produkti softuerik. 98% e monitorimit të sotëm është kodim. Kodimi në shërbime, kodimi në kontrolle të jashtme, kontrollimi i shërbimeve të jashtme dhe gjithçka midis tyre.
- Mos kurseni kohën e zhvilluesve tuaj për monitorim: kjo mund të kërkojë deri në 30% të punës së tyre, por ia vlen.
- DevOps, mos u shqetësoni nëse nuk jeni në gjendje të monitoroni diçka, sepse disa gjëra kërkojnë një mendësi krejtësisht të ndryshme. Ju nuk ishit programues dhe monitorimi është pikërisht kjo - puna e tyre.
- Nëse projekti është tashmë në proces dhe nuk monitorohet (dhe ju jeni menaxher), ndani burime për monitorim.
- Nëse produkti është tashmë në prodhim dhe ju jeni një DevOps të cilit i është thënë të "konfigurojë monitorimin", përpiquni t'i shpjegoni menaxhmentit se për çfarë shkrova.
Ky është një version i zgjeruar i fjalimit të mbajtur në konferencën Saint Highload++.
Nëse jeni të interesuar për idetë dhe mendimet e mia mbi të dhe temat e lidhura, atëherë mundeni 🙂
Burimi: www.habr.com
