

Pas historia
Есть торговые автоматы собственной разработки. Внутри Raspberry Pi и немного обвязки на отдельной плате. Подключены монетоприёмник, купюроприёмник, банковский терминал… Управляет всем самописная программа. Вся история работы пишется в журнал на флешке (MicroSD), который потом передаётся через интернет (с помощью USB-модема) на сервер, там складывается в БД. Информация о продажах загружается в 1с, также есть простенький веб-интерфейс для мониторинга и т.п.
То есть журнал жизненно необходим — для учёта (там выручка, продажи и т.д.), мониторинга (всевозможные сбои и другие форс-мажорные обстоятельства); это, можно сказать, вся информация, которая у нас об этом автомате.
Problemi
Флешки показывают себя как очень ненадёжные устройства. Они с завидной регулярностью выходят из строя. Это приводит как к простоям автоматов, так и (если по каким-то причинам журнал не мог быть передан онлайн) к потерям данных.
Это уже не первый опыт использования флешек, до этого был другой проект с более, чем сотней устройств, где журнал хранился на USB-флешках, там тоже были проблемы с надёжностью, временами число вышедших из строя за месяц исчислялось десятками. Пробовали разные флешки, в том числе и брендовые на SLC памяти, да некоторые модели надёжнее других, но замена флешек не решила проблему кардинально.
Kujdes! Лонгрид! Если вам неинтересно «почему», а интересно только «как», можете сразу идти të artikullit.
Zgjidhja
Первое, что приходит в голову: отказаться от MicroSD, поставить, например, SSD, и грузиться с него. Теоретически возможно, наверное, но относительно дорого, и не так уж надёжно (добавляется переходник USB-SATA; по бюджетным SSD статистика отказов тоже не радует).
USB HDD тоже не выглядит особо привлекательным решением.
Поэтому пришли к такому варианту: оставить загрузку с MicroSD, но использовать их в режиме read-only, а журнал работы (и другую уникальную для конкретной железки информацию — серийный номер, калибровки датчиков, etc) хранить где-то ещё.
Тема read-only ФС для малинки уже изучена вдоль и поперёк, я не буду останавливаться на деталях реализации в этой статье (но если будет интерес — быть может и напишу мини-статью на эту тему). Единственный момент, который хочется отметить: и по личном опыту, и по отзывам уже внедривших выигрыш в надёжности есть. Да, полностью избавиться от поломок невозможно, однако существенно снизить их частоту — вполне реально. Да и карточки становятся унифицированными, что заметно упрощает замену для обслуживающего персонала.
Аппаратная часть
С выбором типа памяти особых сомнений не было — NOR Flash.
Argumentet:
- простое подключение (чаще всего шина SPI, опыт использования которой уже есть, так что «железных» проблем не предвидится);
- смешная цена;
- стандартный протокол работы (реализация есть уже в ядре Linux, при желании можно взять стороннюю, которые тоже присутствуют, или даже написать свою, благо всё просто);
- надёжность и ресурс:
из типичного даташита: данные хранятся 20 лет, 100000 циклов erase для каждого блока;
из сторонних источников: крайне низкий BER, постулируется отсутствие необходимости в кодах коррекции ошибок (в некоторых работах рассматривается ECC для NOR, но обычно всё-таки там имеют в виду MLC NOR, бывает и такое).
Прикинем требования к объёму и ресурсу.
Хочется, чтобы гарантированно сохранялись данные за несколько дней. Нужно это для того, чтобы в случае каких-либо проблем со связью история продаж не была потеряна. Будем ориентироваться на 5 дней, за этот срок (даже с учётом выходных и праздников) можно решить проблему.
У нас сейчас за сутки набирается около 100кб журнала (3-4 тысячи записей), однако постепенно эта цифра растёт — увеличивается детализация, добавляются новые события. Плюс иногда бывают всплески (какой-нибудь датчик начинает спамить ложными срабатываниями, например). Будем рассчитать на 10 тысяч записей по 100 байт — мегабайт в сутки.
Итого выходит 5Мб чистых (хорошо сжимаемых) данных. К ним ещё (грубая прикидка) 1Мб служебных данных.
То есть нам нужна микросхема на 8Мб если не использовать сжатие, или 4Мб если использовать. Вполне реальные цифры для этого типа памяти.
Что же до ресурса: если мы планируем, что память целиком будет переписываться не чаще, чем раз в 5 дней, то за 10 лет службы мы получаем менее тысячи циклов перезаписи.
Напоминаю, производитель обещает сто тысяч.
Немного про NOR vs NAND
Сегодня, конечно, куда более популярна NAND память, однако для этого проекта я бы не стал её использовать: NAND, в отличие от NOR, обязательно требует использования кодов коррекции ошибок, таблицы сбойных блоков и т.д., да и ножек у микросхем NAND обычно куда больше.
В качестве недостатков NOR можно указать:
- малый объём (и, соответственно, высокая цена за мегабайт);
- невысокая скорость обмена (во многом из-за того, что используется последовательный интерфейс, обычно SPI или I2C);
- медленный erase (в зависимости от размера блока, он занимает от долей секунды, до нескольких секунд).
Вроде бы ничего критичного для нас, так что продолжаем.
Если интересны детали, была выбрана микросхема (впрочем, это несущественно, на рынке куча аналогов, совместимых по распиновке и системе команд; даже если мы захотим поставить микросхему одругого производителя и/или другого объёма, то всё заработает без изменения кода).
Я использую встроенный в ядро Linux драйвер, на Raspberry благодаря поддержке device tree overlay всё очень просто — нужно положить в /boot/overlays скомпилированный оверлей и немного модифицировать /boot/config.txt.
Пример dts файла
Честно говоря, не уверен, что написано без ошибок, но работает.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};И ещё строчка в config.txt
dtoverlay=at25:spimaxfrequency=50000000Описание самого подключения микросхемы к Raspberry Pi опущу. С одной стороны, я не специалист в электронике, с другой — тут всё банально даже для меня: у микросхемы всего 8 ног, из которых нам нужны земля, питание, SPI (CS, SI, SO, SCK); уровни совпадают с таковыми у Raspberry Pi, никакой дополнительной обвязки не требуется — просто соединить указанные 6 контактов.
Vendosja e detyrës
Как обычно, постановка задачи проходит несколько итераций, мне кажется, что пришло время для очередной. Так что давайте остановимся, соберём воедино то, что уже было написано, и проясним оставшиеся в тени детали.
Итак, мы определились с тем, что журнал будет храниться в SPI NOR Flash.
Что такое NOR Flash для тех, кто не знает
Это энергонезависимая память, с которой можно делать три операции:
- Leximi:
Самое обычное чтение: передаём адрес и читаем столько байт, сколько нам нужно; - Shkrimi:
Запись в NOR flash выглядит как обычная, но у неё есть одна особенность: можно только менять 1 на 0, но не наоборот. Например, если у нас в ячейке памяти лежало 0x55, то после записи в неё 0x0f там уже будет храниться 0x05 (см. таблицу чуть ниже); - Erase:
Разумеется, нам нужно уметь делать и обратную операцию — менять 0 на 1, именно для этого и существует операция erase. В отличие от первых двух, она оперирует не байтами, а блоками (минимальный erase block в выбранной микросхеме — 4кб). Erase уничтожает весь блок целиком и это единственный способ поменять 0 на 1. Поэтому, при работе с флеш-памятью часто приходится выравнивать структуры данных на границу erase block.
Запись в NOR Flash:
Двоичные данные
Ishte
01010101
Записали
00001111
Nisi
00000101
Сам журнал представляет последовательность записей переменной длины. Типичная длина записи около 30 байт (хотя иногда случаются и записи длиной в несколько килобайт). В данном случае мы работаем с ними просто как с набором байт, но, если интересно, внутри записей используется CBOR
Помимо журнала, нам нужно хранить некоторую «настроечную» информацию, как обновляемую, так и нет: некий ID аппарата, калибровки датчиков, флаг «аппарат временно отключен», etc.
Эта информация представляет из себя набор записей key-value, также хранится в CBOR.Этой информации у нас не очень много (максимум несколько килобайт), обновляется она нечасто.
В дальнейшем будем называть её контекстом.
Если вспомнить с чего начиналась эта статья, то очень важно обеспечить надёжность хранения данных и, по возможности, беспрерывную работу даже в случае аппаратных сбоев/повреждения данных.
Какие источники проблем можно рассмотреть?
- Отключение питания в момент операций write/erase. Это из разряда «против лома нет приёма».
Информация из на stackexchange: при отключении питания в момент работы с flash что erase (установка в 1), что write (установка в 0) приводят к undefined behavior: данные могут записаться, записаться частично (скажем, мы передали 10 байт/80 бит, а успели записаться только 45 бит), не исключено и то, что часть битов окажется в «промежуточном» состоянии (чтение может выдать как 0, так и 1); - Ошибки самой flash-памяти.
BER хоть и очень низок, но не может быть равным нулю; - Ошибки по шине
Данные, передаваемые по SPI никак не защищены, вполне могут случиться как одиночные битовые ошибки, так и ошибки синхронизации — потеря или вставка бит (что приводит к массовым искажениям данных); - Прочие ошибки/сбои
Ошибки в коде, «глюки» Raspberry, вмешательство инопланетян…
Я сформулировал требования, выполнение которых, на мой взгляд, необходимо для обеспечения надёжности:
- записи должны попадать во флеш-память сразу, отложенная запись не рассматривается;- если ошибка возникла, то она должна обнаруживаться и обрабатываться как можно раньше;- система должна по возможности восстанавливать работу после ошибок.
(пример из жизни «как не должно быть», с которым, думаю, все встречались: после аварийной перезагрузки «побилась» файловая система и операционная система не грузится)
Идеи, подходы, размышления
Когда я начал думать над этой задачей, то в голове проносилась куча идей, например:
- использовать сжатие данных;
- использовать хитрые структуры данных, например хранить заголовки записей отдельно от самих записей, чтобы при ошибке в какой-либо записи можно было без проблем прочитать остальные;
- использовать битовые поля для контроля завершённости записи при отключении питания;
- хранить контрольные суммы для всего и вся;
- использовать какую-либо разновидность помехоустойчивого кодирования.
Часть этих идей была использована, от части было решено отказаться. Давайте по порядку.
Сжатие данных
Сами события, которые мы фиксируем в журнале, достаточно однотипные и повторяемые («кинули монетку 5 рублей», «нажали на кнопку выдачи сдачи», …). Поэтому сжатие должно оказаться достаточно эффективным.
Накладные расходы на сжатие несущественны (процессор у нас достаточно мощный, даже на первом Pi было одно ядро с частотой 700МГц, на актуальных моделях несколько ядер с частотой свыше гигагерца), скорость обмена с хранилищем невысокая (несколько мегабайт в секунду), размер записей невелик. В общем, если сжатие и окажет влияние на производительность, то только положительное (абсолютно некритично, просто констатирую). Плюс у нас же не настоящий embedded, а обычный Linux — так что реализация не должна потребовать много усилий (достаточно просто прилинковать библиотеку и использовать несколько функций из неё).
Был взят кусок лога с работающего устройства (1.7Мб, 70 тысяч записей) и для начала проверен на сжимаемость с помощью имеющихся на компьютере gzip, lz4, lzop, bzip2, xz, zstd.
- gzip, xz, zstd показали близкие результаты (40Кб).
Удивило, что модный xz показал тут себя на уровне gzip или zstd; - lzip с настройками по умолчанию дал чуть худший результат;
- lz4 и lzop показали не очень хороший результат (150Кб);
- bzip2 показал на удивление хороший результат (18Кб).
Итак, данные сжимаются очень хорошо.
Так что (если мы не найдём фатальных недостатков) сжатию быть! Просто потому, что на ту же флешку поместится больше данных.
Давайте подумаем о недостатках.
Первая проблема: мы уже договорились, что каждая запись должна незамедлительно попасть на флеш. Обычно архиватор набирает данные из входного потока до тех пор, пока не решит, что пора писать в выходной. Нам же нужно сразу получить сжатый блок данных и сохранить его в энергонезависимой памяти.
Я вижу три пути:
- Сжимать каждую запись с помощью словарного сжатия вместо рассмотренных выше алгоритмов.
Вполне рабочий вариант, но мне он не нравится. Для обеспечения более-менее приличного уровня сжатия словарь должен быть «заточен» под конкретные данные, любое изменение приведёт к тому, что уровень сжатия катастрофически падает. Да, проблема решается созданием новой версии словаря, но это же головная боль — нам нужно будет хранить все версии словаря; в каждой записи нам нужно будет указывать с какой версией словаря она была сжата… - Сжимать каждую запись «классическими» алгоритмами, но независимо от других.
Рассматриваемые алгоритмы компрессии не рассчитаны на работу с записями такого размера (десятки байт), коэффициент сжатия будет явно меньше 1 (то есть увеличение объёма данных вместо сжатия); - Делать FLUSH после каждой записи.
Во многих библиотеках сжатия есть поддержка FLUSH. Это команда (или параметр к процедуре сжатия), получив которую архиватор формирует сжатый поток так, чтобы чтобы на его основании можно восстановить të gjitha несжатые данные, которые уже были получены. Такой аналогsyncв файловых системах илиcommitв sql.
Что важно, последующие операции сжатия смогут использовать накопленный словарь и степень сжатия не будет страдать так сильно, как в предыдущем варианте.
Думаю очевидно, что я выбрал третий вариант, остановимся на нём подробнее.
Нашлась про FLUSH в zlib.
Сделал по мотивам статьи наколенный тест, взял 70 тысяч записей журнала с реального устройства, при размере страницы в 60Кб (к размеру страницы мы ещё вернёмся) получил:
Të dhënat fillestare
Сжатие gzip -9 (без FLUSH)
zlib с Z_PARTIAL_FLUSH
zlib с Z_SYNC_FLUSH
Объём, Кб
1692
40
352
604
На первый взгляд цена, вносимая FLUSH чрезмерно высока, однако на самом деле у нас небогатый выбор — или не сжимать вовсе, или сжимать (и весьма эффективно) с FLUSH. Не надо забывать, что у нас 70 тысяч записей, избыточность, вносимая Z_PARTIAL_FLUSH составляет всего 4-5 байт на запись. А коэффициент сжатия оказался почти 5:1, что более, чем отличный результат.
Может показаться неожиданным, но на самом деле Z_SYNC_FLUSH — более эффективный способ делать FLUSH
В случае использования Z_SYNC_FLUSH 4 последних байта каждой записи всегда будут 0x00, 0x00, 0xff, 0xff. А если они нам известны — то мы можем их не хранить, таким образом итоговый размер оказывается всего 324Кб.
В статье, на которую я ссылаюсь, есть объяснение:
A new type 0 block with empty contents is appended.
A type 0 block with empty contents consists of:
- the three-bit block header;
- 0 to 7 bits equal to zero, to achieve byte alignment;
- the four-byte sequence 00 00 FF FF.
Как несложно заметить, в последнем блоке перед этими 4 байтами идёт от 3 до 10 нулевых бит. Однако практика показала, что нулевых бит на самом деле минимум 10.
Оказывается, столь короткие блоки данных обычно (всегда?) кодируются с помощью блока типа 1 (fixed block), который обязательно заканчивается 7 нулевыми битами, итого получаем 10-17 гарантированно нулевых бит (а остальные будут нулевыми с вероятностью около 50%).
Итак, на тестовых данных в 100% случаев перед 0x00, 0x00, 0xff, 0xff идёт один нулевой байт, а более, чем в трети случае — два нулевых байта (возможно, дело в том, что я использую бинарный CBOR, а при использовании текстового JSON чаще встречались бы блоки типа 2 — dynamic block, соответсвенно встречались бы блоки без дополнительных нулевых байт перед 0x00, 0x00, 0xff, 0xff).
Итого на имеющихся тестовых данных можно уложиться в менее, чем 250Кб сжатых данных.
Можно сэкономить ещё немного, занявшись жонглированием битами: сейчас мы игнорируем наличие нескольких нулевых бит в конце блока, несколько бит в начале блока также не меняются…
Но тут я принял волевое решение остановиться, иначе такими темпами можно дойти до разработки своего архиватора.
Итого, я из своих тестовых данных получил 3-4 байта на запись, коэффициент сжатия получился более 6:1. Честно скажу: я на такой результат и не рассчитывал, на мой взгляд всё, что лучше 2:1 — уже результат, оправдывающий использование сжатия.
Всё отлично, но zlib (deflate) — всё-таки архаичный заслуженный и немного старомодный алгоритм сжатия. Уже одно то, что в качестве словаря используются последние 32Кб из потока несжатых данных, сегодня выглядит странным (то есть если какой-то блок данных очень похож на то, что было во входном потоке 40Кб назад, то он начнёт архивироваться заново, а не будет ссылаться на прошлое вхождение). В модных современных архиваторах размер словаря чаще измеряется мегабайтами, а не килобайтами.
Так что продолжаем наше мини-исследование архиваторов.
Следующим был опробован bzip2 (напоминаю, без FLUSH он показал фантастическую степень сжатия, почти 100:1). Увы, с FLUSH он показал себя очень плохо, размер сжатых данных оказался больше, чем несжатых.
Мои предположения о причинах провала
Libbz2 предлагает всего один вариант flush, который, похоже, очищает словарь (аналог Z_FULL_FLUSH в zlib), говорить о каком-то эффективном сжатии после этого не приходится.
И последним был опробован zstd. В зависимости от параметров он сжимает или на уровне gzip, но гораздо быстрее, или же лучше gzip.
Увы, с FLUSH и он показал себя «не очень»: размер сжатых данных вышел около 700Кб.
Unë на странице проекта в github, получил ответ, что стоит рассчитывать на до 10 байт служебных данных на каждый блок сжатых данных, что близко к полученным результатам, догнать deflate никак не получится.
На этом я решил остановиться в экспериментах с архиваторами (напомню, xz, lzip, lzo, lz4 не показали себя ещё на этапе тестирования без FLUSH, а рассматривать более экзотические алгоритмы сжатия я не стал).
Возвращаемся к проблемам архивации.
Вторая (как говорится по порядку, а не по значению) проблема — сжатые данные представляют из себя единый поток, в котором постоянно идут отсылки на предыдущие участки. Таким образом, при повреждении какого-то участка сжатых данных мы теряем не только связанный с ним блок несжатых данных, но и все последующие.
Есть подхода к решению этой проблемы:
- Предупреждать появление проблемы — добавлять в сжатые данные избыточность, которая позволит определять и исправлять ошибки; об этом мы поговорим позже;
- Минимизировать последствия в случае возникновения проблемы
Мы уже говорили ранее, что можно каждый блок данных сжимать независимо, при этом проблема исчезнет сама собой (порча данных одного блока приведёт к потере данных только этого блока). Однако, это крайний случай, при котором сжатие данных будет неэффективно. Противоположная крайность: использовать все 4Мб нашей микросхемы как единый архив, что даст нам отличное сжатие, но катастрофические последствия в случае порчи данных.
Да, нужен компромисс с точки зрения надёжности. Но нужно помнить, что мы разрабатываем формат хранения данных для энергонезависимой памяти с крайне низким BER и декларируемым сроком хранения данных 20 лет.
В процессе экспериментов я обнаружил, что более-менее заметные потери уровня сжатия начинаются на блоках сжатых данных рамером менее 10Кб.
Ранее упоминалось, что используемая память имеет страничную организацию, я не вижу причин, по которым не стоит использовать соответствие «одна страница — один блок сжатых данных».
То есть минимальный разумный размер страницы равен 16Кб (с запасом на служебную информацию). Однако столь малый размер страницы накладывает существенные ограничения на максимальный размер записи.
Хоть у меня пока и не предвидится записей больше единиц килобайт в сжатом виде, я решил использовать страницы размером 32Кб (итого получается 128 страниц на микросхему).
Резюме:
- Данные мы храним сжатыми с помощью zlib (deflate);
- Для каждой записи устанавливаем Z_SYNC_FLUSH;
- У каждой сжатой записи обрезаем конечные байты (например, 0x00, 0x00, 0xff, 0xff); в заголовке указываем как много байт мы отрезали;
- Данные храним страницами по 32Кб; внутри страницы идёт единый поток сжатых данных; на каждой странице сжатие начинаем заново.
И, перед тем как закончить со сжатием, хотелось бы обратить внимание, что сжатых данных у нас получается всего несколько байт на запись, поэтому крайне важно не раздувать служебную информацию, каждый байт тут на счету.
Хранение заголовков данных
Так как у нас записи переменной длины, то нам нужно как-то определять размещение/границы записей.
Я знаю три подхода:
- Все записи хранятся в непрерывном потоке, сначала идёт заголовок записи, содержащий длину, а потом сама запись.
В этом варианте и заголовки, и данные могут иметь переменную длину.
По сути, у нас получается односвязный список, который используется сплошь и рядом; - Заголовки и сами записи хранятся в раздельных потоках.
Используя заголовки постоянной длины, мы добиваемся того, что порча одного заголовка не влияет на остальные.
Подобный подход используется, например, во многих файловых системах; - Записи хранятся в непрерывном потоке, граница записи определяется по некоторому маркеру (символу/последовательности символов, который/которая запрещены внутри блоков данных). Если внутри записи встречается маркер, то мы заменяем его на некоторую последовательность (экранируем его).
Подобный подход используется, например, в протоколе PPP.
Проиллюстрирую.
Вариант 1:

Тут всё очень просто: зная длину записи мы можем вычислить адрес следующего заголовка. Так мы перемещаемся по заголовкам, пока не встретим область, заполненную 0xff (свободную область) или конец страницы.
Вариант 2:

Из-за переменной длины записи мы не можем заранее сказать как много записей (а значит и заголовков) на страницу нам потребуется. Можно разнести заголовки и сами данные по разным страницам, но мне симпатичнее другой подход: и заголовки, и данные размещаем на одной странице, однако заголовки (постоянного размера) у нас идут от начала страницы, а данные (переменной длины) — от конца. Как только они «встретятся» (свободного места не хватит на новую запись) — считаем эту страницу заполненной.
Вариант 3:

Тут нет нужды хранить в заголовке длину или другую информацию о расположении данных, достаточно маркеров, означающих границы записей. Однако данные приходится обрабатывать при записи/чтении.
В качестве маркера я бы использовал 0xff (которым заполнена страница после erase), таким образом свободная область точно не будет трактоваться как данные.
Сравнительная таблица:
Mundësia 1
Variant 2
Varianti 3
Устойчивость к ошибкам
—
+
+
Компактность
+
—
+
Сложность реализации
*
**
**
Вариант 1 имеет фатальный недостаток: при повреждении какого-то из заголовков у нас разрушается вся последующая цепочка. Остальные варианты позволяют восстановить часть данных даже при массовых повреждениях.
Но тут уместно вспомнить, что мы решили хранить данные в сжатом виде, так и так мы теряем все данные на странице после «битой» записи, так что хоть в таблице и стоит минус, мы его не учитываем.
Компактность:
- в первом варианте нам нужно хранить в заголовке только длину, если использовать целые переменной длины, то в большинстве случаев можно обойтись одним байтом;
- во втором варианте нам нужно хранить начальный адрес и длину; запись должна быть постоянного размера, я оцениваю в 4 байта на запись (два байта на смещение, и два байта на длину);
- третьему варианту достаточно всего одного символа для обозначения начала записи, плюс сама запись из-за экранирования вырастет на 1-2%. В целом примерный паритет с первым вариантом.
Изначально я рассматривал второй вариант как основной (и даже написал реализацию). Отказался от него я только тогда, когда окончательно решил использовать сжатие.
Возможно, когда-нибудь я всё-таки буду использовать подобный вариант. Например, если мне придётся заниматься хранением данных для корабля, курсирующего между Землёй и Марсом — совсем другие требования к надёжности, космическое излучение, …
Что же до третьего варианта: я поставил ему две звёздочки за сложность реализации просто потому, что не люблю возиться с экранированием, изменением длины в процессе и т.п. Да, возможно, предвзято, но код писать придётся мне — зачем заставлять себя делать то, что не нравится.
Резюме: выбираем вариант хранения в виде цепочек «заголовок с длиной — данные переменной длины» из-за эффективности и простоты реализации.
Использование битовых полей для контроля успешности операций записи
Уже сейчас не помню, где я подсмотрел идею, но выглядит всё примерно так:
Для каждой записи выделяем несколько бит для хранения флагов.
Как мы говорили ранее, после erase все биты заполнены 1, и мы можем изменять 1 на 0, но не наоборот. Так что для «флаг не установлен» используем 1, для «флаг установлен» — 0.
Вот как может выглядеть помещение записи переменной длины во flash:
- Устанавливаем флаг “запись длины началась”;
- Записываем длину;
- Устанавливаем флаг “запись данных началась”;
- Записываем данные;
- Устанавливаем флаг “запись закончилась”.
Кроме этого, у нас будет флаг “произошла ошибка”, итого 4 битовых флага.
В этом случае у нас есть два стабильных состояния “1111” — запись не началась и “1000” — запись прошла успешно; в случае непредвиденного прерывания процесса записи получим промежуточные состояния, которые мы потом мы сможем обнаружить и обработать.
Подход интересный, но он защищает только от внезапного отключения питания и подобных сбоев, что, конечно, важно, однако это далеко не единственная (и даже не основная) причина возможных сбоев.
Резюме: идём дальше в поисках хорошего решения.
Контрольные суммы
Контрольные суммы тоже дают возможность удостовериться (с достаточной вероятностью) что мы читаем именно то, что должно было быть записано. И, в отличие от рассмотренных выше битовых полей, они работают всегда.
Если расматривать список потенциальных источников проблем, о которых мы говорили выше, то контрольная сумма способна распознать ошибку независимо от её происхождения (за исключением, пожалуй, злокозненных инопланетян — те могут подделать и контрольную сумму тоже).
Так что, если наша цель проверить, что данные целы, контрольные суммы — отличная идея.
Выбор алгоритма вычисления контрольной суммы вопросов не вызывал — CRC. С одной стороны, математические свойства позволяют в 100% ловить ошибки некоторых типов, с другой — на случайных данных обычно этот алгоритм показывает вероятность коллизий не сильно больше теоретического предела  . Пусть это не самый быстрый алгоритм, не всегда минимальный по числу коллизий, но у него есть очень важное качество: во встречавшися мне тестах не попадались паттерны, на которых он бы явно проваливался. Стабильность — это главное качество в данном случае.
. Пусть это не самый быстрый алгоритм, не всегда минимальный по числу коллизий, но у него есть очень важное качество: во встречавшися мне тестах не попадались паттерны, на которых он бы явно проваливался. Стабильность — это главное качество в данном случае.
Пример объёмного исследования: , (ссылки на narod.ru, извините).
Однако задача выбора контрольной суммы не завершена, CRC — это целое семейство контрольных сумм. Нужно определиться с длиной, а потом выбрать полином.
Выбор длины контрольной суммы не такой простой вопрос, как кажется с первого взгляда.
Проиллюстрирую:
Пусть у нас вероятность ошибки в каждом байте  и идеальная контрольная сумма, посчитаем среднее число ошибок на миллион записей:
и идеальная контрольная сумма, посчитаем среднее число ошибок на миллион записей:
Данные, байт
Контрольная сумма, байт
Необнаруженных ошибок
Ложных обнаружений ошибок
Итого неправильных срабатываний
1
0
1000
0
1000
1
1
4
999
1003
1
2
≈0
1997
1997
1
4
≈0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
≈0
1979
1979
10
4
≈0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
≈0
1469
1469
Казалось бы, всё просто — выбирай в зависимости от длины защищаемых данных длину контрольной суммы с минимумом неправильных срабатываний — и дело в шляпе.
Однако, с короткими контрольными суммами возникает проблема: они, хоть и хорошо обнаруживают единичные битовые ошибки, могут с достаточно большой вероятностью принять за верные совершенно случайные данные. На хабре уже была статья, описывающая .
Поэтому, чтобы сделать случайное совпадение контрольной суммы практически невозможным, нужно использовать контрольные суммы длиной 32 бита и более (для длин более 64 бит обычно используют криптографические хэш-функции).
Несмотря на то, что ранее я писал, что нужно экономить место всеми силами, всё-таки будем использовать 32-битную контрольную сумму (16 бит мало, вероятность коллизии больше 0.01%; а 24 бита, как говорится, ни туда и ни сюда).
Тут может возникнуть возражение: для того ли мы экономили каждый байт при выборе сжатия, чтобы сейчас отдать 4 байта сразу? не лучше ли было не сжимать и не добавлять контрольную сумму? Конечно нет, отсутствие сжатия не означает, что проверка целостности нам не нужна.
По выбору полинома не будем изобретать велосипед, а возьмём популярный сейчас CRC-32C.
Этот код обнаруживает 6 битовых ошибок на пакетах до 22 байт (пожалуй, самый частый случай для наc), 4 битовые ошибки на пакетах до 655 байт (тоже частый случай для нас), 2 или любое нечётное число битовых ошибок на пакетах любой разумной длины.
Если кому интересны детали
про CRC.
në — пожалуй, главного специалиста по CRC на планете.
Në ka , обеспечивающий чуть лучшие параметры для актуальных для нас длин пакетов, но я не посчитал разницу существенной, а себя достаточно компетентным, чтобы выбрать кастомный код вместо стандартного и хорошо исследованного.
Ещё, так как у нас данные сжаты, возникает вопрос: считать контрольную сумму сжатых или несжатых данных?
Аргументы «за» подсчёт контрольной суммы несжатых данных:
- нам в конечном итоге нужно проверить сохранность хранения данных — вот мы её напрямую и проверяем (при этом будут заодно проверены возможные ошибки в реализации компрессии/декомпрессии, повреждения, вызванные битой памятью и т.п.);
- алгоритм deflate в zlib имеет достаточно зрелую реализацию и не должен падать при «кривых» входных данных, более того, зачастую он способен самостоятельно обнаружить ошибки во входном потоке, снизив общую вероятность необнаружения ошибки (провёл тест с инвертированием одиночного бита в короткой записи, zlib обнаружил ошибку примерно в трети случаев).
Аргументы «против» подсчёта контрольной суммы несжатых данных:
- CRC «заточен» именно под немногочисленные битовые ошибки, которые характерны для флеш-памяти (битовая ошибка в сжатом потоке может дать массовое изменение выходного потока, на котором, чисто теоретически, мы можем «поймать» коллизию);
- мне не очень нравится идея передавать декомпрессору потенциально битые данные, , как он отреагирует.
В данном проекте я решил отойти от общепринятой практики хранения контрольной суммы несжатых данных.
Резюме: используем CRC-32C, контрольную сумму считаем от данных в том виде, в котором они записываются во flash (после сжатия).
Избыточность
Использование избыточного кодирования не позволяет, конечно, исключить потерю данных, однако, оно может существенно (зачастую на многие порядки) снизить вероятность невосстановимой потери данных.
Мы можем использовать разные виды избыточности для того, чтобы исправлять ошибки.
Коды Хэмминга могут исправлять одиночные битовые ошибки, коды Рида-Соломона символьные, несколько копий данных совместно с контрольными суммами или кодирование вроде RAID-6 могут помочь восстановить данные даже в случае массовых повреждений.
Изначально я был настроен на широкое использование помехоустойчивого кодирования, но потом понял, что сначала нужно иметь представление от каких ошибок мы хотим защититься, а потом уже выбирать кодирование.
Мы говорили ранее, что ошибки нужно выявлять как можно быстрее. В какие моменты мы можем столкнуться с ошибками?
- Незаконченная запись (по каким-либо причинам в момент записи отключилось питание, завис Raspberry, …)
Увы, в случае подобной ошибки остаётся только игнорировать невалидные записи и считать данные потерянными; - Ошибки записи (по каким-либо причинам в flash-память записалось не то, что записывалось)
Подобные ошибки мы можем сразу обнаружить, если мы непосредственно после записи будем делать контрольное чтение; - Искажение данных в памяти в процессе хранения;
- Ошибки чтения
Для исправления достаточно в случае несовпадения контрольной суммы несколько раз повторить чтение.
То есть только ошибки третьего типа (самопроизвольная порча данных при хранении) не могут быть исправлены без помехоустойчивого кодирования. Думается, подобные ошибки всё-таки крайне маловероятны.
Резюме: было решено отказаться от избыточного кодирования, но, если эксплуатация покажет ошибочность этого решения, то вернуться к рассмотрению вопроса (с уже накопленной статистикой по сбоям, которая позволит выбрать оптимальный вид кодирования).
Të tjera
Разумеется, формат статьи не позволяет обосновать каждый бит в формате (да и у меня уже иссякли силы), поэтому кратко пробегусь по некоторым моментам, не затронутым ранее.
- Решено делать все страницы «равноправными»
То есть не будет каких-то специальных страниц с метаданными, отдельными потоками и т.п., вместо этого единый поток, который переписывает все страницы по очереди.
Это обеспечивает равномерный износ страниц, остутствие единой точки отказа, ну и просто нравится; - Обязательно нужно предусмотреть версионность формата.
Формат без номера версии в заголовке — зло!
Достаточно добавить в заголовок страницы поле с неким Magic Number (сигнатурой), которое будет указывать на используемую версию формата (не думаю, что их на практике будет даже десяток); - Использовать для записей (которых очень много) заголовок переменной длины, стараясь для большинства случаев сделать его длиной в 1 байт;
- Для кодирования длины заголовка и длины обрезаемой части сжатой записи использовать бинарные коды переменной длины.
Очень помог кодов Хаффмана. Буквально за несколько минут удалось подобрать нужные коды переменной длины.
Описание формата хранения данных
Byte order
Поля, размером превышающие один байт, хранятся в big-endian формате (network byte order), то есть 0x1234 записывается как 0x12, 0x34.
Деление на страницы
Вся флеш-память разбита на страницы равного размера.
Размер страницы по умочанию 32Кб, но не более, чем 1/4 от общего размера микросхемы памяти (для микросхемы на 4Мб получается 128 страниц).
Каждая страница хранит данные независимо от других (то есть данные одной страницы не ссылаются на данные другой страницы).
Все страницы пронумерованы в естественном порядке (в порядке возрастания адресов), начиная с номера 0 (нулевая страница начинается с адреса 0, первая — с 32Кб, вторая — с 64Кб и т.д.)
Микросхема памяти используется как циклический буфер (ring buffer), то есть сначала запись идёт в страницу с номером 0, потом с номером 1, …, когда мы заполняем последную страницу, то начинается новый цикл и запись продолжается с нулевой страницы.
Внутри страницы

В начале страницы хранится 4-байтный заголовок страницы, потом контрольная сумма заголовка (CRC-32C), далее хранятся записи в формате «заголовок, данные, контрольная сумма».
Заголовок страницы (на схеме грязно-зелёный) состоит из:
- двухбайтного поля Magic Number (он же — признак версии формата)
для текущей версии формата он считается как0xed00 ⊕ номер страницы; - двухбайтного счётчика «Версия страницы» (номер цикла перезаписи памяти).
Записи на странице хранятся в сжатом виде (используется алгоритм deflate). Все записи на одной странице сжимаются в одном потоке (используется общий словарь), на каждой новой странице сжатие начинается заново. То есть для декомпрессии любой записи требуются все предыдущие записи с этой страницы (и только с этой).
Каждая запись сжимется с флагом Z_SYNC_FLUSH, при этом в конце сжатого потока оказываются 4 байта 0x00, 0x00, 0xff, 0xff, предварённые, возможно, ещё одним или двумя нулевыми байтами.
Эту последовательность (длиной 4, 5 или 6 байт) мы отбрасываем при записи в флеш-память.
Заголовок записи представляет из себя 1, 2 или 3 байта, хранящие:
- один бит (T), означающий тип записи: 0 — контекст, 1 — журнал;
- поле переменной длины (S) от 1 до 7 бит, определящее длину заголовка и «хвост», который нужно добавить к записи для распаковки;
- длину записи (L).
Таблица значений S:
S
Длина заголовка, байт
Отбрасывается при записи, байт
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
Попробовал проиллюстрировать, не знаю, насколько наглядно получилось:
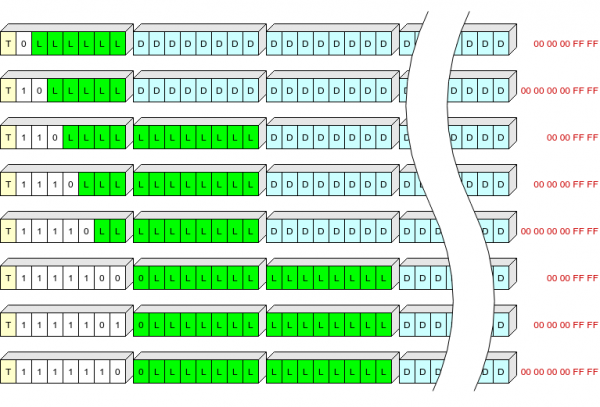
Жёлтым тут обозначено поле T, белым — поле S, зелёным L (длина сжатых данных в байтах), голубым — сжатые данные, красным — конечные байты сжатых данных, которые не пишутся во флеш-память.
Таким образом, заголовки записей самой распространённой длины (до 63+5 байт в сжатом виде) мы сможем записать одним байтом.
После каждой записи хранится контрольная сумма CRC-32C, у которой в качестве начального значения (init) используется инвертированное значение предыдущей контрольной суммы.
CRC обладает свойством «продолжательности», действует (плюс-минус инвертирование бит в процессе) такая формула:  .
.
То есть фактически мы высчитываем CRC всех предыдущих байт заголовков и данных на этой странице.
Непосредственно за контрольной суммой лежит заголовок следующей записи.
Заголовок сконструирован таким образом, чтобы первый его байт был всегда отличен от 0x00 и 0xff (если вместо первого байта заголовка мы встречаем 0xff, то значит это пока неиспользуемая область; 0x00 же сигнализирует об ошибке).
Примерные алгоритмы
Чтение из флеш-памяти
Любое чтение идёт с проверкой контрольной суммы.
Если контрольная сумма не сошлась — чтение повторяется несколько раз в надежде прочитать-таки верные данные.
(это имеет смысл, Linux не кэширует чтение из NOR Flash, проверено)
Запись в флеш-память
Записываем данные.
Читаем их.
Если прочитанные данные не совпадают с записанными — заполняем область нулями и сигнализируем о ошибке.
Подготовка новой микросхемы к работе
Для инициализации в первую (точнее нулевую) страницу записывается заголовок с версией 1.
После этого в эту страницу записывается начальный контекст (содержит UUID автомата и дефолтные настройки).
Всё, флеш-память готова к работе.
Загрузка автомата
При загрузке читаются первые 8 байт каждой страницы (заголовок + CRC), страницы с неизвестным Magic Number или неверным CRC игнорируются.
Из «правильных» страниц выбираются страницы с максимальной версией, из них берётся страница, имеющая наибольший номер.
Считывается первая запись, проверяется корректность CRC, наличие флага «контекст». Если всё нормально — эта страница считается текущей. Если нет — откатываемся на предыдущую, пока не найдём «живую» страницу.
а найденной странице считываем все записи, те, которые с флагом «контекст» применяем.
Сохраняем словарь zlib (нужен будет для дозаписи в эту страницу).
Всё, загрузка завершена, контекст восстановлен, можно работать.
Добавление записи в журнал
Сжимаем запись с правильным словарём, указывая Z_SYNC_FLUSH.Смотрим, помещается ли сжатая запись на текущей странице.
Если не помещается (или на странице были ошибки CRC) — начинаем новую страницу (см. ниже).
Записываем запись и CRC. Если произошла ошибка — начинаем новую страницу.
Новая страница
Выбираем свободную страницу с минимальным номером (свободной мы считаем страницу с неправильной контрольной суммой в заголовке или с версией меньше текущей). Если таких страниц нет — выбираем страницу с минимальным номером из тех, что имеют версию равную текущей.
Делаем выбранной странице erase. Сверяем содержимое с 0xff. Если что-то не так — берём следующую свободную страницу, и т.д.
На стёртую страницу записываем заголовок, первой записью текущее состояние контекста, следующей — незаписанную запись журнала (если она есть).
Применимость формата
По моему мнению, получился неплохой формат для хранения любых более-менее сжимаемых потоков информации (простой текст, JSON, MessagePack, CBOR, возможно, protobuf) в NOR Flash.
Конечно, формат «заточен» под SLC NOR Flash.
Его не стоит использовать с носителями с высоким BER, например NAND или MLC NOR (а такая память вообще есть в продаже? встречал упоминания только в работах по кодам коррекции).
Тем более, его не стоит использовать с устройствами, имеющими свой FTL: USB flash, SD, MicroSD, etc (для такой памяти я делал формат с размером страницы в 512 байт, сигнатурой в начале каждой страницы и уникальными номерами записей — иногда из «глюкнувшей» флешки удавалось простым последовательным чтением восстановить все данные).
В зависимости от задач формат без изменений можно использовать на флешках от 128Кбит (16Кб) до 1Гбит (128Мб). При желании можно использовать и на микросхемах большего объёма, только, наверное, нужно скорректировать размер страницы (Но тут уже встаёт вопрос экономической целесообразности, цена на NOR Flash большого объёма не радует).
Если кому-то формат показался интересным, и он захочет использовать его в открытом проекте — пишите, постараюсь найти время, причесать код и выложить на github.
Përfundimi
Как видим, в итоге формат оказался простым и даже скучным.
В статье сложно отразить эволюцию своей точки зрения, но поверьте: изначально мне хотелось создать что-то навороченное, неубиваемое, способное выжить даже после ядерного взрыва в непосредственной близости. Однако, разум (надеюсь) всё-таки победил и постепенно приоритеты сдвинулось к простоте и компактности.
Может ли получиться так, что я ошибся? Да, конечно. Вполне может оказаться, например, что мы закупили партию некачественных микросхем. Или по какой-то другой причине оборудование не оправдает ожидания по надёжности.
Есть ли у меня план на этот случай? Я думаю, что по прочтению статьи вы не сомневаетесь, что план есть. И даже не один.
Если чуть более серьёзно, формат разработан одновременно и как рабочий вариант, и как «пробный шар».
На сегодняшний момент на столе всё работает нормально, буквально на днях решение будет развёрнуто (примерно) на сотне устройств, посмотрим, что будет в «боевой» эксплуатации (благо, надеюсь, формат позволяет надёжно детектировать сбои; так что получится собрать полноценную статистику). Через несколько месяцев можно будет делать выводы (а если не повезёт — то и раньше).
Если по итогам использования обнаружатся серьёзные проблемы и потребуются доработки, то я обязательно об этом напишу.
Literatura
Не хотелось составлять длинный нудный список использованных работ, в конце концов гугл есть у всех.
Тут я решил оставлять список находок, которые мне показались особенно интересными, однако постепенно они перекочевали непосредственно в текст статьи, и в списке остался один пункт:
- Utilitari от автора zlib. Умеет в понятном виде отображать содержимое архивов deflate/zlib/gzip. Если вам приходится разбираться с внутренним устройством формата deflate (или gzip) — настоятельно рекомендую.
Burimi: habr.com
