

Procesi i përditësimit për klasterin tuaj Kubernetes
Në një moment gjatë përdorimit të klasterit Kubernetes, lind nevoja për të përditësuar nodet në funksion. Kjo mund të përfshijë përditësime paketash, përditësimin e bërthamës ose shpërndarjen e imazheve të reja të makinerive virtuale. Në terminologjinë e Kubernetes, kjo quhet .
Ky post është pjesë e një cikli prej 4 postimesh:
- Ky post.
- Përfundimi korrekt i pod’ave në klasterin Kubernetes
- Përfundimi i vonuar i pod’it në momentin e fshirjes
- Si të shmangni ndërprerjet në funksionimin e klasterit Kubernetes me ndihmën e PodDisruptionBudgets
(shën. përk. përkthimet e artikujve të tjerë të ciklit prisni së shpejti)
Në këtë artikull do të përshkruajmë të gjitha mjetet që ofron Kubernetes për të arritur zero kohë ndërprerjeje për nodet që punojnë në klasterin tuaj.
Pëdefinedimi i problemit
Në fillim, do të përdorim një qasje naive, duke identifikuar problemet dhe duke vlerësuar rreziqet e mundshme të kësaj qasjeje dhe duke mbledhur njohuri për të zgjidhur çdo problem që do të hasim gjatë gjithë ciklit. Si rezultat, do të arrijmë një konfigurim që përdor lifecycle hooks, readiness probes dhe Pod disruption budgets për të arritur kohën tonë zero të pushimit.
Për të nisur rrugëtimin tonë, le të marrim një shembull konkret. Supozoni se kemi një klaster Kubernetes me dy node, në të cilin është duke ecuar një aplikacion me dy podë, që ndodhen pas Shërbimi:
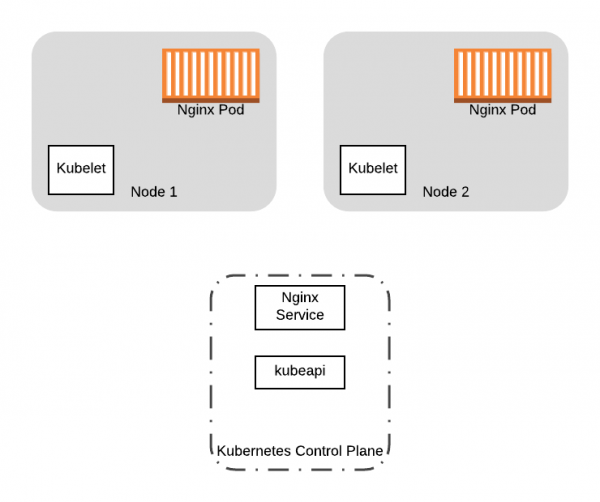
Le të fillojmë me dy podë me Nginx dhe Service të nisur në dy node të klasterit tonë Kubernetes.
Ne duam të përditësojmë versionin e bërthamës së dy nodeve punuese në klasterin tonë. Si do ta bëjmë këtë? Një zgjidhje e thjeshtë do të ishte të ngarkonim node të reja me konfigurim të përditësuar dhe më pas të fiknim node të vjetra, duke filluar njëkohësisht të rejat. Megjithatë, kjo do të sjellë disa probleme me një qasje të tillë:
- Kur të çaktivizoni nodet e vjetra, pod'ët që janë të ekzekutuar në to gjithashtu do të çaktivizohen. Çfarë ndodh nëse pod'ët duhet të pastrohen për një çaktivizim të saktë? Sistemi i virtualizimit që po përdorni mund të mos presë për të përfunduar procesin e pastrimit.
- Çfarë ndodh nëse çaktivizoni të gjitha nodet njëkohësisht? Do të keni një periudhë të konsiderueshme prapa derisa pod'ët të transferohen në nodet e reja.
Na nevojitet një mënyrë e saktë për migrimin e pod'ëve nga nodet e vjetra dhe nga ana tjetër duhet të jemi të sigurt që asnjë nga proceset tona të punës nuk është në ekzekutim ndërsa ne bëjmë ndryshime në nodë. Ose kur ne bëjmë një zëvendësim të plotë të klasterit, si në shembull (dmth. zëvendosim imazhet e VM), ne duam të transferojmë aplikacionet funksionuese nga nodet e vjetra në ato të reja. Në të dyja rastet, ne duam të parandalojmë planifikimin e pod'ëve të rinj në nodet e vjetra dhe pastaj të largohemi nga të gjitha pod'ët e ekzekutuar. Për të arritur këto qëllime mund të përdorim komandën kubectl drain.
Rredistribuimi i të gjitha pod'ëve nga nodë
Operacioni drain lejon rredistribuimin e të gjitha pod'ëve nga nodë. Gjatë procesit të ekzekutimit të drain, nodëja shënohet si e pa-planifikueshme (flamuri NoSchedule). Kjo parandalon shfaqjen e podëve të rinj. Pastaj, procesi i shkarkimit fillon të zhvendosë pod’ët nga nodet, përfundon funksionimin e konteinerëve që aktualisht janë të aktivizuar në nodën duke dërguar sinjalin TERM konteinerëve në pod.
Megjithatë kubectl drain ndonëse ai do të përballet mirë me zhvendosjen e podëve, ka edhe dy faktorë të tjerë që mund të shkaktojnë dështim gjatë operacionit të shkarkimit:
- Aplikacioni juaj duhet të jetë në gjendje të përfundojë siç duhet kur të dërgohet
TERMsinjali. Kur pod’ët zhvendosen, Kubernetes dërgon sinjalinTERMkonteinerëve dhe pret ndalimin e tyre për një periudhë të caktuar kohore, pas së cilës, nëse ata nuk janë ndaluar, i përfundon ato me forcë. Në çdo rast, nëse konteineri juaj nuk e kupton saktësisht sinjalin, ju still mund të fikni pod’ët në mënyrë jo korrekte, nëse ata janë aktivë në atë moment të caktuar (për shembull, nëse një transaksion është në zhvillim në DB). - Ju humbni të gjithë pod’ët në të cilët ndodhet aplikacioni juaj. Ai mund të jetë i paqasjeur në momentin e fillimit të konteinerëve të rinj në nodat e reja ose, nëse pod’ët tuaj janë shpërndarë pa kontrollet, ato mund të mos rifillojnë në parim.
Shmangim ndalimin
Për të minimizuar kohën e ndaljes nga ndërprerjet vullnetarë, siç është operacioni drain për node, Kubernetes ofron këto mundësi për trajtimin e dështimeve:
Në pjesët e tjera të ciklit, ne do të përdorim këto funksione të Kubernetes për të zbutur pasojat e zhvendosjes së pod’ave. Për ta bërë më të lehtë ndjekjen e ideve kryesore, ne do të përdorim shembullin tonë më lart me këtë konfigurim të burimeve:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.15
ports:
- containerPort: 80
---
kind: Service
apiVersion: v1
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
targetPort: 80
port: 80Kjo konfigurim është një shembull minimal Deployment, i cili menaxhon pod’ët nginx në klaster. Për më tepër, konfigurimi përshkruan burimin Shërbimi, i cili mund të përdoret për të aksesuar pod’ët nginx në klaster.
Gjatë gjithë ciklit, ne do të zgjerim iterativ këtë konfigurim, në mënyrë që në fund të përfshijë të gjitha mundësitë që ofron Kubernetes për të ulur kohën e ndaljes.
Për të marrë një version të plotë të integruar dhe të testuar të përditësimeve të klasterit Kubernetes me zero kohë pezullimi në AWS dhe burime të tjera, vizitoni .
Shihni gjithashtu artikuj të tjerë në blogun tonë:
Burimi: habr.com
