

Arkitektura mikroserve, si çdo gjë tjetër në këtë botë, ka avantazhet dhe disavantazhet e saj. Disa procese bëhen më të lehta me të, ndërsa të tjerat bëhen më të komplikuara. Për t'u përshtatur me shpejtësinë e ndryshimeve dhe për shkak të shkallëzueshmërisë më të mirë, është e nevojshme të bëhen disa sakrifica. Një prej tyre është komplikuar analiza. Në një arkitekturë monolite, gjithë analiza operative mund të reduktohet në pyetje SQL për replikën analitike, por në arkitekturën me shumë shërbime, çdo shërbim ka bazën e vet, dhe duket se nuk mjafton një pyetje (apo ndoshta mjafton?). Për ata që janë të interesuar se si e zgjidhëm problemin e analizës operative në kompaninë tonë dhe si mësuam të jetojmë me këtë zgjidhje — mirëserdhët.

Më quajnë Pavel Sivaš, në DomClick punoj në ekipin që është përgjegjës për mbështetje të depozitës analitike të të dhënave. Në mënyrë të kushtëzuar, aktiviteti ynë mund të klasifikohet si inxhinieri e të dhënave, por në të vërtetë, spektri i detyrave është shumë më i gjerë. Ka standardet e zakonshme për inxhinierinë e të dhënave ETL/ELT, mbështetje dhe adaptim të mjeteve për analizën e të dhënave dhe zhvillimi i mjeteve tona. Në veçanti, për raportimin operativ kemi vendosur të "pretendojmë" se kemi një monolit dhe t'u japim analistëve një bazë, ku do të jenë të gjitha të dhënat e nevojshme për ta.
Në të vërtetë, ne shqyrtuam disa mundësi. Mund të ishim ndërtuar një depo të plotë — madje e provuam, por, për të qenë të sinqertë, nuk arritëm ta pajtonim ndryshimet e shpeshta në logjikë me procesin mjaft të ngadaltë të ndërtimit të depo dhe përfshirjes së ndryshimeve në të (nëse dikush e arriti këtë, na shkruani në komentet si). Mund të kishim thënë analistëve: "Djem, mësoni python dhe shkoni në replikat analitike", por kjo do të ishte një kërkesë shtesë për punësimin e personelit, dhe dukej se duhej ta evitonim këtë, nëse ishte e mundur. Vendosëm të provonim teknologjinë FDW (Foreign Data Wrapper): në thelb, është një dblink standard që ekziston në standardin SQL, por me një ndërfaqe shumë më të përshtatshme. Në bazë të saj ne krijuam një zgjidhje, e cila përfundimisht mbeti në përdorim. Detajet e saj janë një temë për një artikull të veçantë, ndoshta edhe për më shumë se një, pasi dua të flas mbi shumë aspekte: nga sinkronizimi i skemave të bazave deri te menaxhimi i aksesit dhe anonimizimi i të dhënave personale. Gjithashtu, duhet të saktësoj se kjo zgjidhje nuk është një zëvendësim për bazat analitike të vërteta dhe depo, ajo zgjidh vetëm një problem të caktuar.
Kështu duket në nivelin më të lartë:
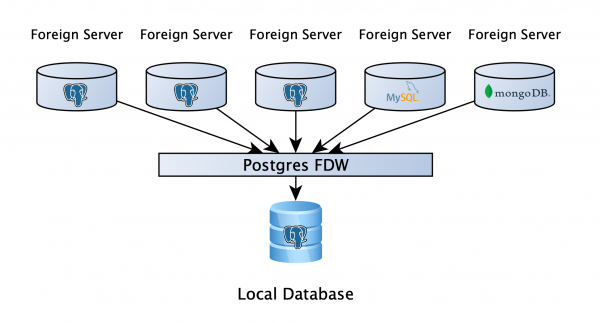
Ka një bazë PostgreSQL, ku përdoruesit mund të ruajnë të dhënat e tyre të punës, dhe më e rëndësishmja — në këtë bazë janë të lidhura replikat analitike të të gjitha shërbimeve nëpërmjet FDW. Kjo jep mundësinë për të shkruar një kërkesë për disa baza, pa marrë parasysh se çfarë janë ato: PostgreSQL, MySQL, MongoDB, ose diçka tjetër (skedar, API, nëse ndonjëherë nuk ka një vrapues të përshtatshëm, mund të shkruajmë një tonin tonin tonin të vetin). E duket se është gjithçka, super! A do të dalë të gjithë?
Nëse gjithçka do të përfundonte aq shpejt dhe thjesht, ndoshta nuk do të kishte artikuj.
Është e rëndësishme të kuptohet qartë se si PostgreSQL përpunon kërkesat për serverë të largët. Kjo duket logjike, megjithatë shpesh nuk i kushtohet vëmendje: PostgreSQL ndan kërkesën në pjesë që ekzekutohen në serverë të largët në mënyrë të pavarur, mbledh të dhënat dhe kryen llogaritjet përfundimtare vetë, prandaj shpejtësia e ekzekutimit të kërkesës do të varet shumë nga mënyra se si është shkruar ajo. Duhet gjithashtu të theksohet: kur të dhënat vijnë nga një server i largët, ato nuk kanë më indekse, nuk ka asgjë që i ndihmon planifikuesit, përveçse ne vetë. Dhe pikërisht për këtë do të dëshironim të flasim më shumë.
Kërkesë e thjeshtë dhe plani me të
Për të ilustruar se si Postgres ekzekuton një kërkesë në një tabelë me 6 milion rreshta në distancë serveri, le të shikojmë një plan të thjeshtë.
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table;
Aggregate (cost=418383.23..418383.24 rows=1 width=8) (actual time=3857.198..3857.198 rows=1 loops=1)
Output: count(1)
-> Foreign Scan on fdw_schema."table" (cost=100.00..402376.14 rows=6402838 width=0) (actual time=4.874..3256.511 rows=6406868 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Remote SQL: SELECT NULL FROM fdw_schema.table
Planning time: 0.986 ms
Execution time: 3857.436 msPërdorimi i instrukcionit VERBOSE lejon të shohim kërkesën që do të dërgohet në serverin e largët dhe rezultatet të cilat do të marrim për përpunim të mëtejshëm (rreshti RemoteSQL).
Le të shkojmë pak më tutje dhe të shtojmë disa filtra në kërkesën tonë: një për boolean fushën, një për përfshirjen timestamp në interval dhe një për jsonb.
shpjegoni analizën verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active është True
AND created_dt MIDIS CURRENT_DATE - INTERVAL '7 muaj'
AND CURRENT_DATE - INTERVAL '6 muaj'
AND meta->>'source' = 'test';
Agregati (kost=577487.69..577487.70 rreshta=1 gjerësi=8) (koha aktuale=27473.818..25473.819 rreshta=1 loops=1)
Shkarkimi: count(1)
-> Skanohet e jashtme në fdw_schema."table" (kost=100.00..577469.21 rreshta=7390 gjerësi=0) (koha aktuale=31.369..25372.466 rreshta=1360025 loops=1)
Shkarkimi: "table".id, "table".is_active, "table".meta, "table".created_dt
Filtri: (("table".is_active IS TRUE) AND (("table".meta ->> 'source'::text) = 'test'::text) AND ("table".created_dt >= (('now'::cstring)::date - '7 mons'::interval)) AND ("table".created_dt <= ((('now'::cstring)::date)::timestamp me zonë kohore - '6 mons'::interval)))
Rreshta të hequra nga Filtri: 5046843
SQL e largët: SELECT created_dt, is_active, meta FROM fdw_schema.table
Koha e planifikimit: 0.665 ms
Koha e ekzekutimit: 27474.118 msPikërisht këtu është momenti, për të cilin duhet të kushtohet vëmendje gjatë hartimit të kërkesave. Filtrit nuk iu kaluan në serverin e largët, që do të thotë se për ekzekutimin e tij, Postgres merr të gjitha 6 milion rreshta për të filtruar më pas lokal (rreshti Filtri) dhe për të kryer agregimin. Sekreti i suksesit është të shkruhet kërkesa në mënyrë që filtrat të kalojnë në makinën e largët, dhe ne të marrim dhe agregojmë vetëm rreshtat e nevojshëm.
Kjo është disa booleanshit
Me fushat boolean — gjithçka është e thjeshtë. Në kërkesën origjinale problemi lindte për shkak të operatorit është. Nëse e ndryshojmë atë në =, do të marrim rezultatin e mëposhtëm:
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active = True
AND created_dt BETWEEN CURRENT_DATE - INTERVAL '7 month'
AND CURRENT_DATE - INTERVAL '6 month'
AND meta->>'source' = 'test';
Aggregate (cost=508010.14..508010.15 rows=1 width=8) (actual time=19064.314..19064.314 rows=1 loops=1)
Output: count(1)
-> Foreign Scan on fdw_schema."table" (cost=100.00..507988.44 rows=8679 width=0) (actual time=33.035..18951.278 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Filter: ((("table".meta ->> 'source'::text) = 'test'::text) AND ("table".created_dt >= (('now'::cstring)::date - '7 mons'::interval)) AND ("table".created_dt <= ((('now'::cstring)::date)::timestamp with time zone - '6 mons'::interval)))
Rows Removed by Filter: 3567989
Remote SQL: SELECT created_dt, meta FROM fdw_schema.table WHERE (is_active)
Planning time: 0.834 ms
Execution time: 19064.534 msSiç e shihni, filtri shkoi në serverin e largët, dhe koha e ekzekutimit u ul nga 27 në 19 sekonda.
Vlen të theksohet se operatori është diferon nga operatori = për faktin se di të punojë me vlerën Null. Kjo do të thotë se is not True në filtrin do të lërë vlerat False dhe Null, ndërsa != True do të lërë vetëm vlerat False. Prandaj, kur zëvendësohet operatori is not duhet të kaloni dy kushte në filtrin me operatorin OR, për shembull, WHERE (col != True) OR (col is null).
Me boolean jemi zotuar, le të vazhdojmë. Ndërkohë, do ta kthejmë filtrin e vlerës boolean në formën e tij origjinale, për të shqyrtuar veprimin e ndryshimeve të tjera.
timestamptz? hz
Në të vërtetë, shpesh na duhet të eksperimentojmë se si të shkruajmë siç duhet një kërkesë që përfshin servera të largët, dhe më pas të gjejmë shpjegimin pse ndodhin veçanërisht kështu. Informacione shumë të pakta për këtë çështje mund të gjenden në internet. Kështu, në eksperimente ne zbuluam se filtri për datë fikse funksionon mirë në serverin e largët, por kur duam të përcaktojmë datën në mënyrë dinamike, për shembull, now() ose CURRENT_DATE, kjo nuk ndodh. Në shembullin tonë, ne e shtuam një filtrim të tillë, që kolona created_at përmbante të dhëna pikërisht për 1 muaj në të kaluarën (BETWEEN CURRENT_DATE — INTERVAL ‘7 month’ AND CURRENT_DATE — INTERVAL ‘6 month’). Çfarë krova për këtë rast?
shpjego analizo verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active is True
AND created_dt >= (SELECT CURRENT_DATE::timestamptz - INTERVAL '7 month')
AND created_dt >'source' = 'test';
Aggregat (cost=306875.17..306875.18 rows=1 width=8) (actual time=4789.114..4789.115 rows=1 loops=1)
Dalja: count(1)
InitPlan 1 (kthen $0)
-> Rezultati (cost=0.00..0.02 rows=1 width=8) (actual time=0.007..0.008 rows=1 loops=1)
Dalja: ((('tani'::cstring)::date)::timestamp with time zone - '7 muaj'::interval)
InitPlan 2 (kthen $1)
-> Rezultati (cost=0.00..0.02 rows=1 width=8) (actual time=0.002..0.002 rows=1 loops=1)
Dalja: ((('tani'::cstring)::date)::timestamp with time zone - '6 muaj'::interval)
-> Skanohu i Huaj për fdw_schema."table" (cost=100.02..306874.86 rows=105 width=0) (actual time=23.475..4681.419 rows=1360025 loops=1)
Dalja: "table".id, "table".is_active, "table".meta, "table".created_dt
Filtri: (("table".is_active IS TRUE) AND (("table".meta ->> 'source'::text) = 'test'::text))
Rreshtat e hequra nga Filtri: 76934
SQL i Largë: SELECT is_active, meta FROM fdw_schema.table WHERE ((created_dt >= $1::timestamp with time zone)) AND ((created_dt < $2::timestamp with time zone))
Koha e planifikimit: 0.703 ms
Koha e ekzekutimit: 4789.379 msI kemi sugjeruar planifikuesit të llogarisë paraprakisht datën në nënkërkesë dhe të kalojë tashmë një ndryshor të gatshëm në filtrin. Dhe kjo sugjerim na dha një rezultat të shkëlqyer, kërkesa u bë më e shpejtë pothuajse 6 herë!
Përsëri, është e rëndësishme të jemi të kujdesshëm: tipi i të dhënave në nënpyetje duhet të jetë i njëjtë me atë të fushës, mbi të cilën po filtrojmë, nd otherwise the scheduler will decide that since the types are different, it is necessary to first fetch all the data and then filter it locally.
Le ta kthejmë filtrin sipas datës në vlerën origjinale.
Freddy vs. Jsonb
Në thelb, fushat logjike dhe datat tashmë e kanë përshpejtuar kërkesën tonë, megjithatë kishte ende një lloj të dhënash. Lufta me filtrimin për të, sinqerisht, ende nuk ka përfunduar, megjithëse këtu ka edhe suksese. Pra, ja si arritëm ta kalojmë filtrin për jsonb fushën në serverin e largët.
shpjego analiza verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active is True
AND created_dt BETWEEN CURRENT_DATE - INTERVAL '7 muaj'
AND CURRENT_DATE - INTERVAL '6 muaj'
AND meta @> '{"source":"test"}'::jsonb;
Agregate (cost=245463.60..245463.61 rows=1 width=8) (actual time=6727.589..6727.590 rows=1 loops=1)
Output: count(1)
-> Skanoj të Huaj në fdw_schema."table" (cost=1100.00..245459.90 rows=1478 width=0) (actual time=16.213..6634.794 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Filter: (("table".is_active IS TRUE) AND ("table".created_dt >= (('now'::cstring)::date - '7 muaj'::interval)) AND ("table".created_dt '{"source": "test"}'::jsonb))
Koha e planifikimit: 0.747 ms
Koha e ekzekutimit: 6727.815 msNë vend të operatorëve të filtrimit, duhet të përdoret operatori i pranisë së një jsonb në tjetrin. 7 sekonda në vend të 29. Deri tani, ky është varianti i vetëm i suksesshëm i kalimit të filtrave për jsonb në serverin e largët, por këtu është e rëndësishme të merret parasysh një kufizim: ne po përdorim versionin e bazës 9.6, megjithatë deri në fund të prillit planifikojmë të përfundojmë testet e fundit dhe të kalojmë në versionin 12. Pasi të përditësohemi, do t'ju njoftojmë se si ndikon kjo, sepse ka shumë ndryshime për të cilat kemi shumë shpresë: json_path, sjellje të reja CTE, push down (i pranishëm që nga versioni 10). Na pëlqen të provojmë sa më shpejt.
Finish him
Ne kemi verifikuar se si çdo ndryshim ndikon në shpejtësinë e kërkimit në veçanti. Tani le të shohim se çfarë do të ndodhë kur të tre filtrat të shkruhen siç duhet.
shpjego analizo me detaje
Zgjidh numrin(1)
Nga fdw_schema.tabela
Ku është_aktive = True
Dhe dat_created >= (Zgjidh DATE::timestamptz - INTERVAL '7 muaj')
Dhe dat_created <(Zgjidh DATE::timestamptz - INTERVAL '6 muaj')
Dhe meta @> '{"source":"test"}'::jsonb;
Agregati (kostot=322041.51..322041.52 rreshta=1 gjerësi=8) (koha aktuale=2278.867..2278.867 rreshta=1 loops=1)
Dalja: numri(1)
Planifikimi inicial 1 (kthen $0)
-> Rezultati (kostot=0.00..0.02 rreshta=1 gjerësi=8) (koha aktuale=0.010..0.010 rreshta=1 loops=1)
Dalja: ((('tani'::cstring)::date)::timestamp me zonë të caktuar - '7 muaj'::interval)
Planifikimi inicial 2 (kthen $1)
-> Rezultati (kostot=0.00..0.02 rreshta=1 gjerësi=8) (koha aktuale=0.003..0.003 rreshta=1 loops=1)
Dalja: ((('tani'::cstring)::date)::timestamp me zonë të caktuar - '6 muaj'::interval)
-> Skanoimi i jashtëm mbi fdw_schema."tabela" (kostot=100.02..322041.41 rreshta=25 gjerësi=0) (koha aktuale=8.597..2153.809 rreshta=1360025 loops=1)
Dalja: "tabela".id, "tabela".është_aktive, "tabela".meta, "tabela".dat_created
SQL-i i largët: Zgjidh NULL Nga fdw_schema.tabela Ku (është_aktive) Dhe ((dat_created >= $1::timestamp me zonë të caktuar)) Dhe ((dat_created < $2::timestamp me zonë të caktuar)) Dhe ((meta @> '{"source": "test"}'::jsonb))
Koha e planifikimit: 0.820 ms
Koha e ekzekutimit: 2279.087 msPo, pyetja duket më e ndërlikuar; kjo është një çmim i detyruar, por shpejtësia e ekzekutimit është 2 sekonda, që është më shumë se 10 herë më shpejt! Dhe ne po flasim për një pyetje të thjeshtë ndaj një grupi të dhënash relativisht të vogël. Në pyetje reale kemi marrë rritje deri në disa qindra herë.
Të japim disa përmbledhje: nëse përdorni PostgreSQL me FDW, kontrolloni gjithmonë nëse të gjitha filtrat dërgohen në serverin e largët, dhe do të keni fat… Të paktën, derisa të arrini deri te bashkimet midis tabelave të ndryshme. serverëvePor kjo është një histori për një artikull tjetër.
Faleminderit për vëmendjen! Do të isha i lumtur të dëgjoja pyetje, komente dhe histori për përvojën tuaj në komentet.
Burimi: habr.com
