

Shënim. përkth.: Në këtë artikull, Banzai Cloud ndan një shembull se si mund të përdoren mjetet e tij të personalizuara për ta bërë Kafkën më të lehtë për t'u përdorur brenda Kubernetes. Udhëzimet e mëposhtme ilustrojnë se si mund të përcaktoni madhësinë optimale të infrastrukturës suaj dhe të konfiguroni vetë Kafkën për të arritur xhiron e kërkuar.

Apache Kafka është një platformë transmetimi e shpërndarë për krijimin e sistemeve të transmetimit të besueshëm, të shkallëzuar dhe me performancë të lartë në kohë reale. Aftësitë e tij mbresëlënëse mund të zgjerohen duke përdorur Kubernetes. Për këtë ne kemi zhvilluar dhe një mjet i quajtur . Ato ju lejojnë të ekzekutoni Kafka në Kubernetes dhe të përdorni veçoritë e tij të ndryshme, të tilla si rregullimi i mirë i konfigurimit të ndërmjetësit, shkallëzimi i bazuar në metrikë me ribalancim, ndërgjegjësimi i raftit, "i butë" (i këndshëm) nxjerrja e përditësimeve, etj.
Provoni Supertubes në grupin tuaj:
curl https://getsupertubes.sh | sh и supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>Ose kontaktoni . Ju gjithashtu mund të lexoni për disa nga aftësitë e Kafkës, puna me të cilën është e automatizuar duke përdorur Supertubes dhe operatorin Kafka. Ne kemi shkruar tashmë për to në blog:
- ;
- ;
- ;
- ;
- ;
- ;
- .
Kur vendosni të vendosni një grup Kafka në Kubernetes, ka të ngjarë të përballeni me sfidën e përcaktimit të madhësisë optimale të infrastrukturës themelore dhe nevojën për të rregulluar mirë konfigurimin tuaj të Kafkës për të përmbushur kërkesat e xhiros. Performanca maksimale e çdo ndërmjetësi përcaktohet nga performanca e komponentëve themelorë të infrastrukturës, si memoria, procesori, shpejtësia e diskut, gjerësia e brezit të rrjetit, etj.
Në mënyrë ideale, konfigurimi i ndërmjetësit duhet të jetë i tillë që të gjithë elementët e infrastrukturës të përdoren në kapacitetet e tyre maksimale. Sidoqoftë, në jetën reale, ky konfigurim është mjaft kompleks. Ka më shumë gjasa që përdoruesit të konfigurojnë ndërmjetësit për të maksimizuar përdorimin e një ose dy komponentëve (disku, memoria ose procesori). Në përgjithësi, një ndërmjetës tregon performancën maksimale kur konfigurimi i tij lejon që komponenti më i ngadalshëm të përdoret në masën e tij të plotë. Në këtë mënyrë mund të kemi një ide të përafërt të ngarkesës që mund të përballojë një ndërmjetës.
Teorikisht, ne gjithashtu mund të vlerësojmë numrin e ndërmjetësve të nevojshëm për të trajtuar një ngarkesë të caktuar. Megjithatë, në praktikë ka kaq shumë opsione konfigurimi në nivele të ndryshme sa që është shumë e vështirë (nëse jo e pamundur) të vlerësohet performanca e mundshme e një konfigurimi të caktuar. Me fjalë të tjera, është shumë e vështirë të planifikosh një konfigurim bazuar në disa performanca të dhëna.
Për përdoruesit e Supertubes, ne zakonisht marrim qasjen e mëposhtme: fillojmë me disa konfigurime (infrastruktura + cilësimet), më pas matim performancën e tij, rregullojmë cilësimet e ndërmjetësit dhe përsërisim procesin përsëri. Kjo ndodh derisa komponenti më i ngadalshëm i infrastrukturës të përdoret plotësisht.
Në këtë mënyrë, ne kemi një ide më të qartë se sa ndërmjetësues i duhen një grupi për të trajtuar një ngarkesë të caktuar (numri i ndërmjetësve varet gjithashtu nga faktorë të tjerë, si numri minimal i kopjeve të mesazheve për të siguruar qëndrueshmëri, numri i ndarjeve liderët, etj.). Përveç kësaj, ne fitojmë njohuri se cilët komponentë të infrastrukturës kërkojnë shkallëzim vertikal.
Ky artikull do të flasë për hapat që ndërmarrim për të përfituar sa më shumë nga komponentët më të ngadaltë në konfigurimet fillestare dhe për të matur xhiron e një grupi Kafka. Një konfigurim shumë elastik kërkon të paktën tre ndërmjetës që funksionojnë (min.insync.replicas=3), e shpërndarë në tre zona të ndryshme aksesueshmërie. Për të konfiguruar, shkallëzuar dhe monitoruar infrastrukturën Kubernetes, ne përdorim platformën tonë të menaxhimit të kontejnerëve për retë hibride - . Ai mbështet në premisa (metal i zhveshur, VMware) dhe pesë lloje resh (Alibaba, AWS, Azure, Google, Oracle), si dhe çdo kombinim të tyre.
Mendime mbi infrastrukturën dhe konfigurimin e grupimeve Kafka
Për shembujt më poshtë, ne zgjodhëm AWS si ofrues të resë kompjuterike dhe EKS si shpërndarje Kubernetes. Një konfigurim i ngjashëm mund të zbatohet duke përdorur - Shpërndarja e Kubernetes nga Banzai Cloud, e çertifikuar nga CNCF.
Диск
Amazon ofron të ndryshme . Në thelb gp2 и io1 ka disqe SSD, megjithatë, për të siguruar qarkullim të lartë gp2 konsumon kredite të akumuluara (Kreditet I/O), ndaj preferuam llojin io1, i cili ofron xhiro të qëndrueshme të lartë.
Llojet e shembullit
Performanca e Kafkës varet shumë nga cache e faqeve të sistemit operativ, kështu që ne kemi nevojë për raste me memorie të mjaftueshme për ndërmjetësit (JVM) dhe cache të faqeve. shembull c5.2x i madh - një fillim i mbarë, pasi ka 16 GB memorie dhe . Disavantazhi i tij është se është në gjendje të sigurojë performancë maksimale vetëm për jo më shumë se 30 minuta çdo 24 orë. Nëse ngarkesa juaj e punës kërkon performancën maksimale për një periudhë më të gjatë kohore, mund të merrni në konsideratë lloje të tjera shembulli. Kjo është pikërisht ajo që bëmë, duke u ndalur në c5.4x i madh. Ofron xhiro maksimale brenda 593,75 Mb/s. Rrjedha maksimale e një vëllimi EBS io1 më i lartë se shembulli c5.4x i madh, kështu që elementi më i ngadalshëm i infrastrukturës ka të ngjarë të jetë xhiroja e hyrjes/daljes së këtij lloji të shembullit (të cilin duhet ta konfirmojnë edhe testet tona të ngarkesës).
Сеть
Rrjedha e rrjetit duhet të jetë mjaft e madhe në krahasim me performancën e shembullit të VM dhe diskut, përndryshe rrjeti bëhet një pengesë. Në rastin tonë, ndërfaqja e rrjetit c5.4x i madh mbështet shpejtësi deri në 10 Gb/s, që është dukshëm më e lartë se xhiroja hyrëse/dalëse e një shembulli VM.
Vendosja e ndërmjetësit
Ndërmjetësuesit duhet të vendosen (të planifikuar në Kubernetes) në nyje të dedikuara për të shmangur konkurrencën me proceset e tjera për CPU, memorie, rrjet dhe burime të diskut.
Versioni Java
Zgjedhja logjike është Java 11 sepse është e pajtueshme me Docker në kuptimin që JVM përcakton saktë procesorët dhe memorien e disponueshme për kontejnerin në të cilin po funksionon ndërmjetësi. Duke ditur që kufijtë e CPU-së janë të rëndësishëm, JVM vendos brenda dhe në mënyrë transparente numrin e thread-ve GC dhe thread-ve JIT. Ne përdorëm imazhin e Kafkës banzaicloud/kafka:2.13-2.4.0, i cili përfshin Kafka versionin 2.4.0 (Scala 2.13) në Java 11.
Nëse dëshironi të mësoni më shumë rreth Java/JVM në Kubernetes, shikoni postimet tona të mëposhtme:
- ;
- .
Cilësimet e kujtesës së ndërmjetësit
Ekzistojnë dy aspekte kryesore për konfigurimin e kujtesës së ndërmjetësit: cilësimet për JVM dhe për Kubernetes pod. Kufiri i memories i vendosur për një pod duhet të jetë më i madh se madhësia maksimale e grumbullit në mënyrë që JVM të ketë vend për metaspace Java, e cila qëndron në memorien e saj, dhe për cache-in e faqeve të sistemit operativ, të cilën Kafka e përdor në mënyrë aktive. Në testet tona ne lançuam ndërmjetësit Kafka me parametra -Xmx4G -Xms2G, dhe kufiri i kujtesës për pod ishte 10 Gi. Ju lutemi vini re se cilësimet e kujtesës për JVM mund të merren automatikisht duke përdorur -XX:MaxRAMPercentage и -X:MinRAMPercentage, bazuar në kufirin e kujtesës për podin.
Cilësimet e procesorit të ndërmjetësit
Në përgjithësi, ju mund të përmirësoni performancën duke rritur paralelizmin duke rritur numrin e fijeve të përdorura nga Kafka. Sa më shumë procesorë të disponueshëm për Kafkën, aq më mirë. Në testin tonë, ne filluam me një limit prej 6 procesorë dhe gradualisht (nëpërmjet përsëritjeve) e rritëm numrin e tyre në 15. Përveç kësaj, vendosëm num.network.threads=12 në cilësimet e ndërmjetësit për të rritur numrin e temave që marrin të dhëna nga rrjeti dhe i dërgojnë ato. Menjëherë duke zbuluar se ndërmjetësit e ndjekësve nuk mund të merrnin kopje të mjaftueshme shpejt, ata ngritën num.replica.fetchers në 4 për të rritur shpejtësinë me të cilën ndërmjetësit e ndjekësve replikuan mesazhet nga drejtuesit.
Vegla e gjenerimit të ngarkesës
Duhet të siguroheni që gjeneratori i zgjedhur i ngarkesës të mos mbarojë kapacitetin përpara se grupi Kafka (i cili është duke u krahasuar) të arrijë ngarkesën e tij maksimale. Me fjalë të tjera, është e nevojshme të kryhet një vlerësim paraprak i aftësive të mjetit të gjenerimit të ngarkesës, dhe gjithashtu të zgjidhen llojet e shembullit për të me një numër të mjaftueshëm procesorësh dhe memorie. Në këtë rast, mjeti ynë do të prodhojë më shumë ngarkesë sesa mund të përballojë grupi Kafka. Pas shumë eksperimentesh, u vendosëm në tre kopje c5.4x i madh, secila prej të cilave kishte një gjenerator që punonte.
Benchmarking
Matja e performancës është një proces përsëritës që përfshin fazat e mëposhtme:
- ngritja e infrastrukturës (grupi EKS, grupi Kafka, mjeti i gjenerimit të ngarkesës, si dhe Prometheus dhe Grafana);
- gjenerimi i një ngarkese për një periudhë të caktuar për të filtruar devijimet e rastësishme në treguesit e grumbulluar të performancës;
- rregullimi i infrastrukturës dhe konfigurimit të ndërmjetësit bazuar në treguesit e performancës së vëzhguar;
- duke përsëritur procesin derisa të arrihet niveli i kërkuar i xhiros së grupit Kafka. Në të njëjtën kohë, ai duhet të jetë vazhdimisht i riprodhueshëm dhe të demonstrojë ndryshime minimale në xhiro.
Seksioni tjetër përshkruan hapat që janë kryer gjatë procesit të krahasimit të grupeve të testimit.
Mjete
Mjetet e mëposhtme janë përdorur për të vendosur shpejt një konfigurim bazë, për të gjeneruar ngarkesa dhe për të matur performancën:
- për organizimin e një grupi EKS nga Amazon c (për të mbledhur treguesit e Kafkës dhe infrastrukturës) dhe (për të vizualizuar këto metrika). Ne përfituam të integruara в shërbime që ofrojnë monitorim të bashkuar, grumbullim të centralizuar të regjistrave, skanim të cenueshmërisë, rikuperim nga fatkeqësitë, siguri të shkallës së ndërmarrjes dhe shumë më tepër.
- — një mjet për testimin e ngarkesës së një grupi Kafka.
- Paneli i Grafana për vizualizimin e metrikës dhe infrastrukturës së Kafkës: , .
- Supertubes CLI për mënyrën më të lehtë për të ngritur një grup Kafka në Kubernetes. Zookeeper, operatori Kafka, Envoy dhe shumë komponentë të tjerë janë instaluar dhe konfiguruar siç duhet për të drejtuar një grup Kafka të gatshëm për prodhim në Kubernetes.
- Për instalim supertuba CLI përdorni udhëzimet e dhëna .
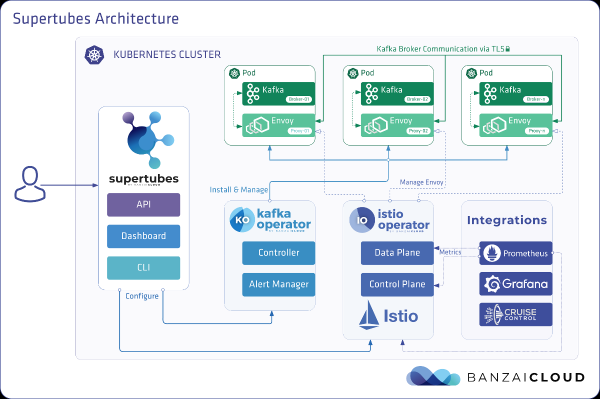
Grupimi EKS
Përgatitni një grup EKS me nyje të dedikuara punëtorësh c5.4x i madh në zona të ndryshme disponueshmërie për pods me ndërmjetësit Kafka, si dhe nyje të dedikuara për gjeneratorin e ngarkesës dhe infrastrukturën e monitorimit.
banzai cluster create -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/cluster_eks_202001.jsonPasi grupi EKS të funksionojë dhe të funksionojë, aktivizoni integrimin e tij - ajo do të vendosë Prometeun dhe Grafanën në një grup.
Komponentët e sistemit Kafka
Instaloni komponentët e sistemit Kafka (Zookeeper, kafka-operator) në EKS duke përdorur supertubat CLI:
supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>Grup Kafka
Si parazgjedhje, EKS përdor vëllime të tipit EBS gp2, kështu që ju duhet të krijoni një klasë të veçantë ruajtjeje bazuar në vëllime io1 për grupin Kafka:
kubectl create -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "50"
fsType: ext4
volumeBindingMode: WaitForFirstConsumer
EOF Vendosni parametrin për ndërmjetësit min.insync.replicas=3 dhe vendosni pods ndërmjetësues në nyje në tre zona të ndryshme disponueshmërie:
supertubes cluster create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/kafka_202001_3brokers.yaml --wait --timeout 600Temat
Ne ekzekutuam tre raste të gjeneratorëve të ngarkesës paralelisht. Secili prej tyre shkruan në temën e tij, domethënë, ne kemi nevojë për tre tema në total:
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest1
spec:
name: perftest1
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest2
spec:
name: perftest2
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest3
spec:
name: perftest3
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOFPër çdo temë, faktori i përsëritjes është 3 - vlera minimale e rekomanduar për sistemet e prodhimit shumë të disponueshme.
Vegla e gjenerimit të ngarkesës
Ne lëshuam tre kopje të gjeneratorit të ngarkesës (secila shkroi në një temë të veçantë). Për podat e gjeneratorit të ngarkesës, duhet të vendosni afinitetin e nyjeve në mënyrë që ato të planifikohen vetëm në nyjet e alokuara për to:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: loadtest
name: perf-load1
namespace: kafka
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: loadtest
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: loadtest
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodepool.banzaicloud.io/name
operator: In
values:
- loadgen
containers:
- args:
- -brokers=kafka-0:29092,kafka-1:29092,kafka-2:29092,kafka-3:29092
- -topic=perftest1
- -required-acks=all
- -message-size=512
- -workers=20
image: banzaicloud/perfload:0.1.0-blog
imagePullPolicy: Always
name: sangrenel
resources:
limits:
cpu: 2
memory: 1Gi
requests:
cpu: 2
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30Disa pika për t'u theksuar:
- Gjeneratori i ngarkesës gjeneron mesazhe me gjatësi 512 bajt dhe i publikon ato te Kafka në grupe prej 500 mesazhesh.
- Duke përdorur një argument
-required-acks=allPublikimi konsiderohet i suksesshëm kur të gjitha kopjet e sinkronizuara të mesazhit merren dhe konfirmohen nga ndërmjetësit e Kafkës. Kjo do të thotë se në pikë referimi ne kemi matur jo vetëm shpejtësinë e drejtuesve që marrin mesazhe, por edhe ndjekësit e tyre që replikojnë mesazhe. Qëllimi i këtij testi nuk është të vlerësojë shpejtësinë e leximit të konsumatorit (konsumatorët) mesazhet e marra së fundmi që mbeten ende në cache-in e faqeve të OS dhe krahasimi i tij me shpejtësinë e leximit të mesazheve të ruajtura në disk. - Gjeneratori i ngarkesës drejton 20 punëtorë paralelisht (
-workers=20). Çdo punëtor përmban 5 prodhues që ndajnë lidhjen e punëtorit me grupin Kafka. Si rezultat, çdo gjenerator ka 100 prodhues dhe të gjithë dërgojnë mesazhe në grupin Kafka.
Monitorimi i shëndetit të grupit
Gjatë testimit të ngarkesës së grupit Kafka, ne monitoruam gjithashtu shëndetin e tij për t'u siguruar që nuk kishte rinisje të pod, nuk kishte kopje të jashtë sinkronizuara dhe xhiro maksimale me luhatje minimale:
- Gjeneruesi i ngarkesës shkruan statistika standarde për numrin e mesazheve të publikuara dhe shkallën e gabimit. Shkalla e gabimit duhet të mbetet e njëjtë
0,00%. - , i vendosur nga kafka-operatori, ofron një panel kontrolli ku mund të monitorojmë gjithashtu gjendjen e grupit. Për të parë këtë panel bëni:
supertubes cluster cruisecontrol show -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> - Niveli ISR (numri i kopjeve "në sinkronizim") tkurrja dhe zgjerimi janë të barabarta me 0.
Rezultatet e matjes
3 ndërmjetës, madhësia e mesazhit - 512 bajt
Me ndarje të shpërndara në mënyrë të barabartë në tre ndërmjetës, ne ishim në gjendje të arrinim performancën ~ 500 Mb/s (afërsisht 990 mijë mesazhe në sekondë):



Konsumi i memories së makinës virtuale JVM nuk i kaloi 2 GB:



Rrjedha e diskut arriti xhiron maksimale të nyjes I/O në të tre rastet në të cilat funksiononin ndërmjetësit:
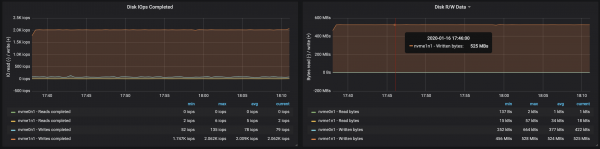
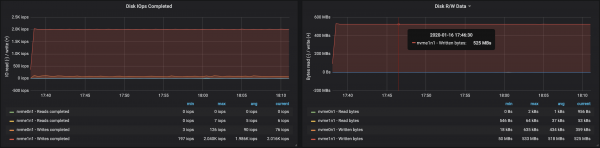
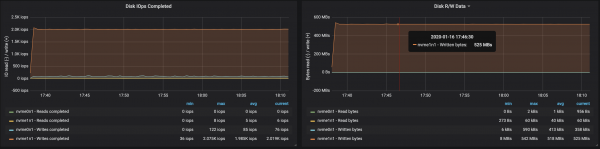
Nga të dhënat për përdorimin e memories nga nyjet, rrjedh se buferimi dhe memoria e sistemit mori ~ 10-15 GB:



3 ndërmjetës, madhësia e mesazhit - 100 bajt
Ndërsa madhësia e mesazhit zvogëlohet, xhiroja bie përafërsisht me 15-20%: koha e kaluar për përpunimin e secilit mesazh ndikon në të. Përveç kësaj, ngarkesa e procesorit është pothuajse dyfishuar.



Meqenëse nyjet e ndërmjetësit kanë ende bërthama të papërdorura, performanca mund të përmirësohet duke ndryshuar konfigurimin Kafka. Kjo nuk është një detyrë e lehtë, kështu që për të rritur xhiron është më mirë të punoni me mesazhe më të mëdha.
4 ndërmjetës, madhësia e mesazhit - 512 bajt
Mund të rrisni lehtësisht performancën e një grupi Kafka thjesht duke shtuar ndërmjetës të rinj dhe duke mbajtur një ekuilibër të ndarjeve (kjo siguron që ngarkesa të shpërndahet në mënyrë të barabartë midis ndërmjetësve). Në rastin tonë, pas shtimit të një ndërmjetësi, xhiroja e grupit u rrit në ~580 Mb/s (~1,1 milion mesazhe në sekondë). Rritja doli të ishte më e vogël se sa pritej: kjo shpjegohet kryesisht nga çekuilibri i ndarjeve (jo të gjithë ndërmjetësit punojnë në kulmin e aftësive të tyre).




Konsumi i memories së makinës JVM mbeti nën 2 GB:




Puna e ndërmjetësve me disqe u ndikua nga çekuilibri i ndarjeve:
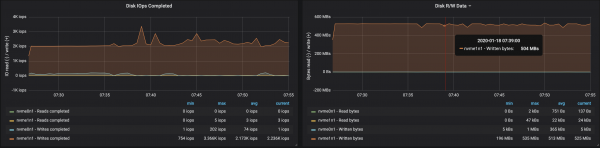
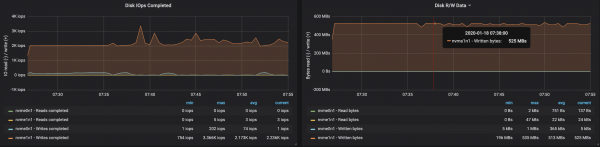
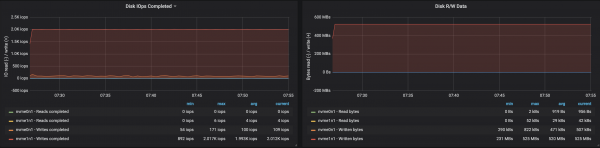
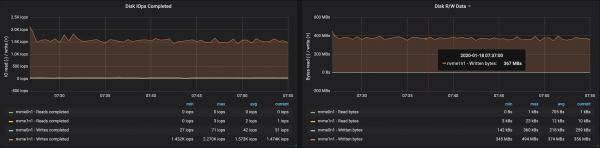
Gjetjet
Qasja përsëritëse e paraqitur më sipër mund të zgjerohet për të mbuluar skenarë më kompleksë që përfshijnë qindra konsumatorë, rindarje, përditësime të përsëritura, rinisje të pod, etj. E gjithë kjo na lejon të vlerësojmë kufijtë e aftësive të grupit Kafka në kushte të ndryshme, të identifikojmë pengesat në funksionimin e tij dhe të gjejmë mënyra për t'i luftuar ato.
Ne projektuam Supertubes për të vendosur shpejt dhe me lehtësi një grup, për ta konfiguruar atë, për të shtuar/hequr ndërmjetës dhe tema, për t'iu përgjigjur sinjalizimeve dhe për të siguruar që Kafka në përgjithësi të funksionojë siç duhet në Kubernetes. Qëllimi ynë është t'ju ndihmojmë të përqendroheni në detyrën kryesore ("gjeneroni" dhe "konsumoni" mesazhet e Kafkës) dhe t'ia lini të gjithë punën e vështirë Supertubes dhe operatorit Kafka.
Nëse jeni të interesuar për teknologjitë Banzai Cloud dhe projektet me burim të hapur, regjistrohuni në kompaninë në , ose .
PS nga përkthyesi
Lexoni edhe në blogun tonë:
- «"?
- «"?
- «'.
Burimi: www.habr.com
